


There is a pattern playing out inside hundreds of enterprises right now. A product team builds a compelling AI agent demo — maybe it triages support tickets, drafts code reviews, or pulls vendor data into a report. The demo impresses leadership. The team gets informal sign-off to “move forward.” They push the agent into a production adjacent environment, wire it to a few internal APIs, and then move on to the next priority.
Six months later, the security team audits their cloud environment and finds an agent with standing admin-level credentials, touching six datastores, emitting no logs, and owned by a developer who left the company in March. Nobody decommissioned it. Nobody even knew it was still running.
That is the Shadow IT hangover — and it is not a future risk. It is happening right now, at scale, across virtually every enterprise that is shipping AI agents with urgency but without architecture.
This post is not a warning against moving fast. Enterprise AI adoption is real, the competitive pressure is real, and the teams building agents are, for the most part, doing exactly what they were hired to do. The problem is structural: the governance frameworks most organizations have in place were designed for software deployments, not for autonomous agents that hold credentials, make decisions, call external services, and act on live data without a human in the loop. Adapting that governance is less about adding bureaucracy and more about building the right abstractions — ones that let engineering teams ship quickly inside a clearly marked safety envelope.
This is a practical guide to doing exactly that.
Why AI Agents Are Fundamentally Different From Every Previous Shadow IT Problem
Enterprise IT has dealt with shadow software before. Employees spinning up unauthorized SaaS tools, developers running unapproved cloud instances, finance teams building elaborate macros that nobody else can maintain — the problem is decades old. But there are three qualities of AI agents that make the current wave categorically different, and understanding them is essential before you can design governance that actually works.
Agents Act, Not Just Process
Traditional shadow IT is mostly passive: a tool that reads data, stores data, or displays data. An AI agent is architecturally designed to take actions — sending emails, modifying database records, calling payment APIs, committing code, creating calendar events. When an unapproved SaaS tool leaks data, that is a breach. When an ungoverned AI agent misconfigures infrastructure or sends 40,000 customer emails based on a flawed prompt, that is an operational incident. The blast radius is orders of magnitude larger.
Agents Hold Identities and Credentials
Every meaningful AI agent needs access to something — a database, a file store, an internal API, a third-party service. That means every agent is, effectively, a non-human identity (NHI) holding credentials. When agents are built without proper governance, they tend to acquire credentials the quick way: either long-lived API keys committed into environment variables, or developer-level OAuth tokens that grant far more access than the agent actually needs. Both patterns are time bombs.
Agents Are Persistent and Self-Perpetuating
A rogue SaaS subscription is visible on a credit card statement. An AI agent running inside your cloud environment can persist indefinitely at near-zero incremental cost, continuing to act, accumulate permissions, and interact with other services long after the person who built it has moved on. The lifecycle problem — knowing what agents exist, who owns them, and when they should be decommissioned — is entirely new territory for most enterprise IT teams.
The Scale of the Problem in 2026
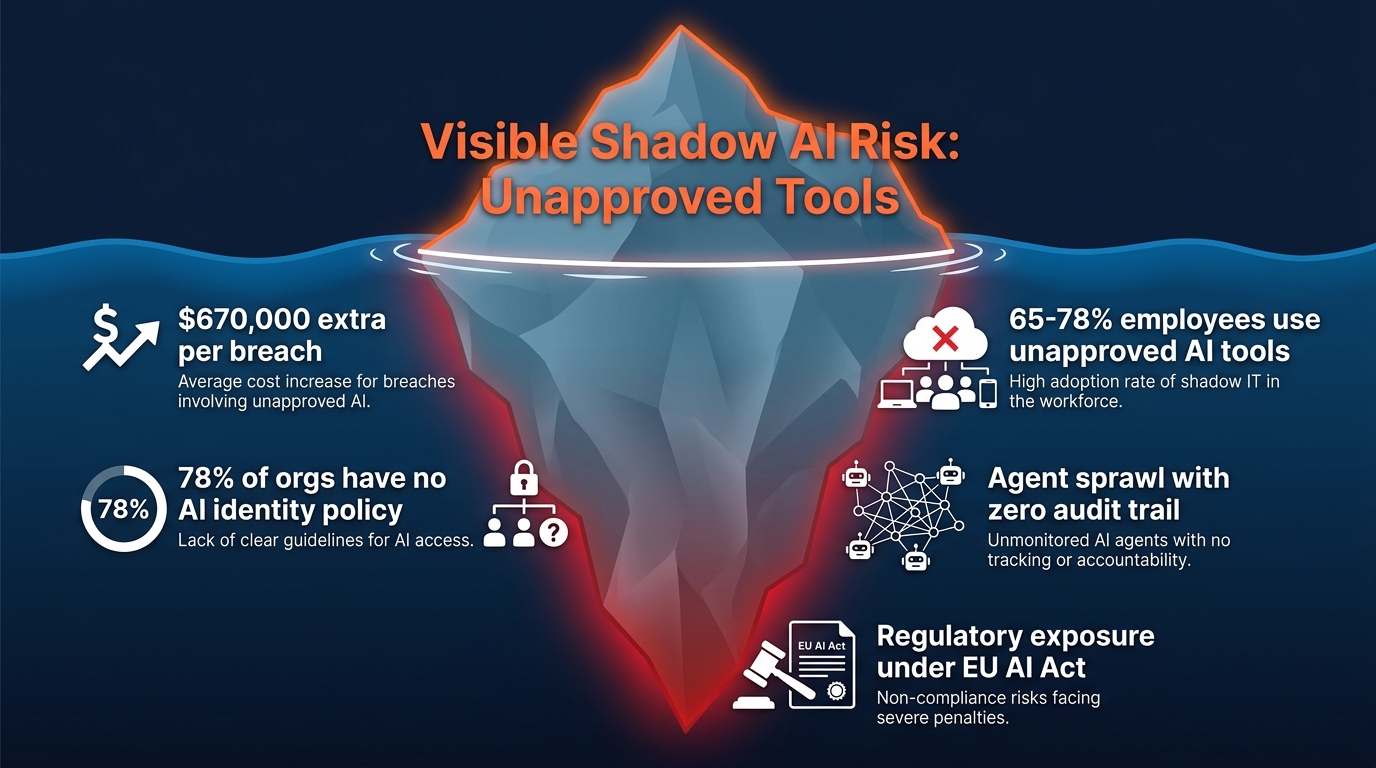
Between 65% and 78% of enterprise employees now use at least one unapproved AI tool at work, according to 2026 survey data aggregated across multiple research firms. The migration from unapproved tools to unapproved agents is already underway. What started as “I use ChatGPT for drafting” is now “I built an agent that monitors our Slack channel and automatically escalates tickets.” Both are technically shadow AI. Only the second one can do real damage to production systems.
Counting the Cost: What the Shadow IT Hangover Actually Charges You
Governance conversations often get framed as bureaucracy versus speed. The productive reframe is debt versus investment. Every AI agent shipped without proper controls is incurring debt — and the interest rate on that debt is not theoretical.
The Breach Premium
IBM’s Cost of a Data Breach research, updated for 2026, establishes a clear premium: data breaches involving shadow AI or unauthorized AI tooling cost enterprises approximately $670,000 more per incident than comparable breaches without AI involvement. The global average breach cost already sits at roughly $4.44 million. Add the shadow AI multiplier and you are looking at incidents that regularly clear $5 million before legal, regulatory, and reputational costs are factored in.
That figure is not a worst-case projection. It is an average. The tail risks — regulatory fines under GDPR or the EU AI Act, class action exposure from customer data mishandled by an ungoverned agent, and supply chain incidents where a compromised agent credential becomes an entry vector — can push individual events into eight-figure territory.
The Identity Governance Gap
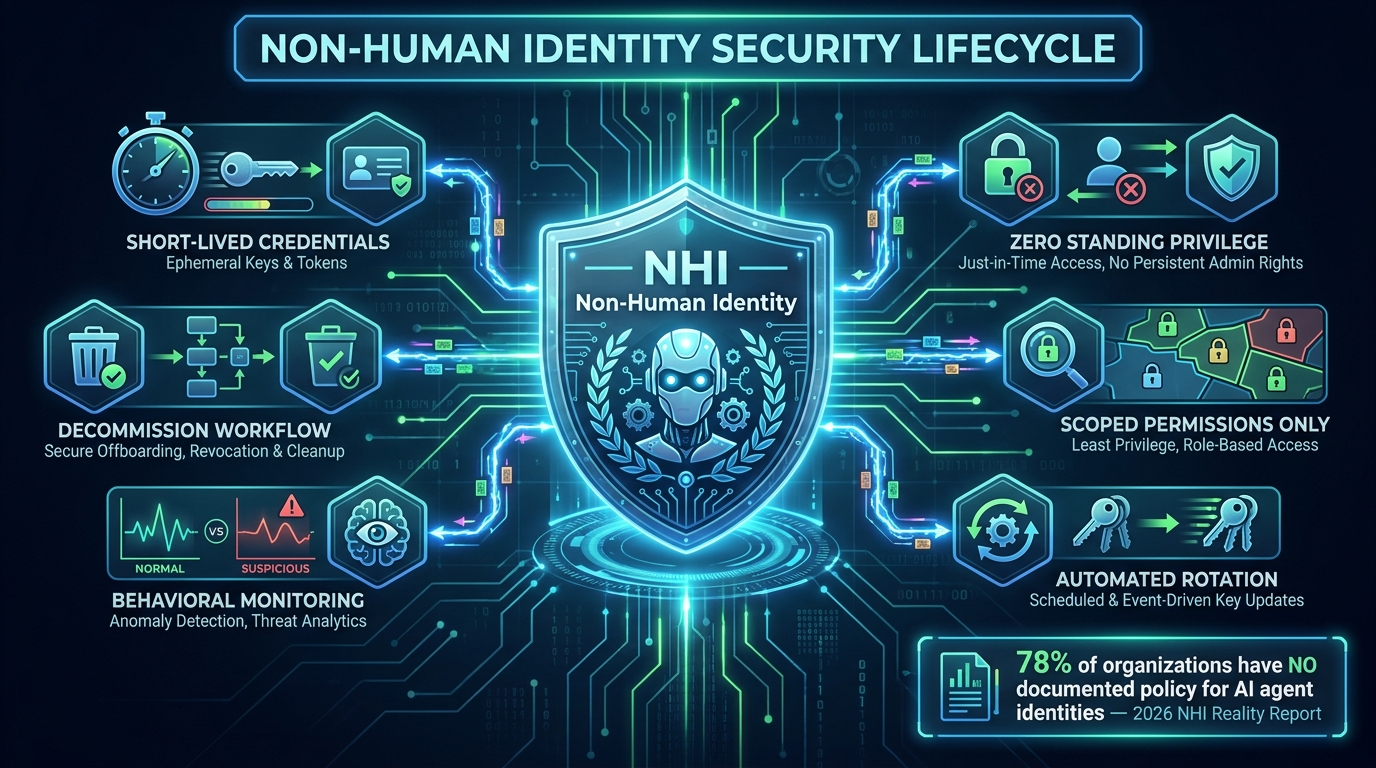
The 2026 NHI Reality Report, cited by the Cloud Security Alliance, found that 78% of organizations have no documented policy for creating or removing AI agent identities. That is not a gap in their AI strategy. It is a gap in their identity and access management (IAM) program — a function that most large enterprises consider mature. The arrival of AI agents has exposed the assumption baked into virtually every enterprise IAM program: that identities are human.
When you have no policy for creating agent identities, you inevitably end up with agents running on developer credentials, service accounts with inherited permissions from previous projects, or hardcoded keys with no rotation schedule. Any of these is a critical finding in a security audit. All of them are common practice in organizations that are shipping agents quickly without governance infrastructure.
The Operational Debt Compounds
Beyond security costs, ungoverned agents create operational debt that compounds over time. Agents without audit trails cannot be debugged when they behave unexpectedly. Agents without documented owners cannot be updated when the underlying model or API they depend on changes. Agents without staged rollout processes cannot be rolled back when a regression causes incorrect outputs. Each of these gaps translates directly into engineering hours — often belonging to people who were not the original builders and who have no context for what the agent was supposed to do.
Governance is not the enemy of velocity. Ungoverned agent sprawl is.
The Paved Path vs. the Cowboy Path
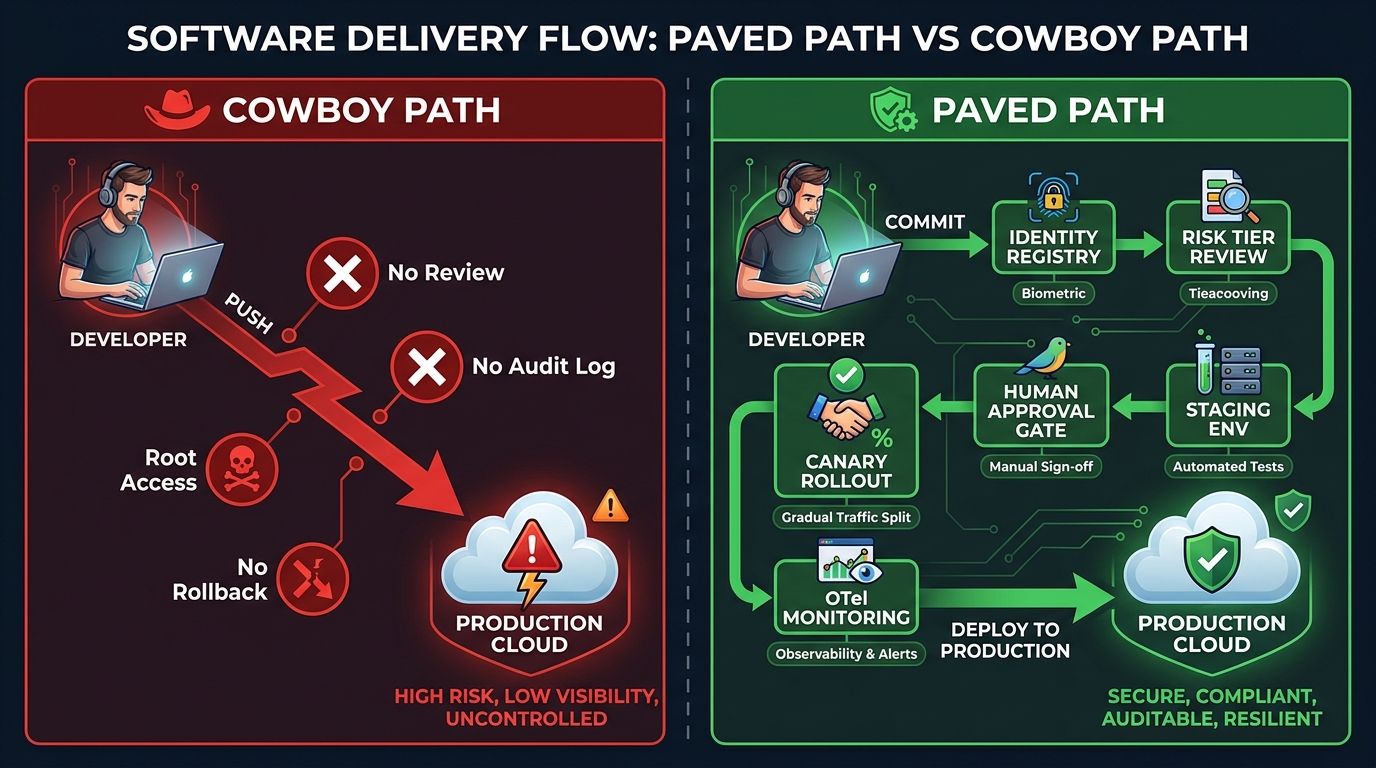
The concept of a “paved path” in platform engineering is well established: rather than telling developers what they cannot do, you make the right way to do things so much easier than the wrong way that compliance becomes the path of least resistance. The same principle applies directly to AI agent governance.
The cowboy path — spinning up an agent using personal credentials, pushing directly to production, with no registry entry, no approval gate, and no monitoring — is not taken because developers are reckless. It is taken because, in most organizations, it is genuinely the easiest path available. There is no easy alternative. The approval process involves submitting a ticket to a queue that may not prioritize AI requests. The security review process was designed for software releases, not autonomous agents. The IAM team does not have a template for non-human agent identities.
Building a paved path means eliminating those friction points by offering developers something better: a standardized, self-service workflow that bundles identity provisioning, risk classification, approval routing, and observability into a single cohesive experience. When registering an agent is as simple as filling out a structured form that auto-provisions a scoped service account, creates a monitoring dashboard, and routes the request to the right approver based on the risk tier — the paved path wins on convenience alone.
What a Paved Path Includes
A well-designed paved path for AI agent deployment in 2026 typically includes the following components, working together as an integrated system rather than as separate checkboxes:
- A developer-facing agent registration interface — ideally embedded inside the tooling developers already use (an internal developer portal, a CI/CD pipeline step, or a Slack workflow) that collects the minimum necessary information to generate an identity, scope permissions, and classify risk.
- A standardized identity provisioning template — automatically generating a scoped service account or workload identity with the minimum permissions required for the declared use case, and with built-in credential rotation enabled by default.
- A risk classification engine — a lightweight decision tree or scoring model that categorizes the agent into a risk tier (low, medium, high) based on the data it accesses, the actions it can take, and the user population it affects. Risk tier determines the approval path and the runtime controls applied.
- Pre-wired observability — an OpenTelemetry instrumentation layer that begins collecting traces, metrics, and logs from the moment the agent is registered, rather than being added after the fact.
- An approval workflow appropriate to the risk tier — lightweight peer review for low-risk agents, formal risk board sign-off for high-risk agents, with clear SLAs for each tier so developers know what to expect.
The key design principle is that none of these components should require a separate request to a separate team. They should be integrated into a single flow that a developer completes in the same session they use to build and test the agent.
Non-Human Identity: The Governance Gap Nobody Talks About
Non-human identities have existed in enterprise systems for years — service accounts, API keys, machine certificates. But the AI agent generation has caused NHIs to explode in number and in capability, while most enterprise IAM programs have not yet adapted their governance models to account for the difference.
The critical distinction is that AI agent NHIs are not static identities performing predictable, scripted tasks. They are dynamic actors that may, in the course of completing a goal, interact with systems and data that the original developer never anticipated. A customer support agent that starts out reading a CRM might, over time, be given access to a billing system, a refund API, and an internal knowledge base. Each incremental permission grant feels reasonable at the time. The cumulative result is an agent with a privilege footprint far larger than any single human user would be granted, operating without the contextual judgment that a human would apply.
Zero Standing Privilege as the Default
The principle that enterprise security teams are converging on is zero standing privilege for AI agent identities. Rather than provisioning an agent with a service account that holds permissions continuously, the agent’s permissions are granted dynamically at the moment they are needed for a specific task and revoked automatically when the task completes.
This is technically more complex than the traditional approach, but the tools to implement it are now mature. Workload identity federation, short-lived token issuance via systems like HashiCorp Vault or cloud-native equivalents, and attribute-based access control (ABAC) policies that scope permissions to specific task contexts are all production-ready in 2026. The barrier is not technical sophistication — it is the organizational habit of treating agents like traditional service accounts.
The Lifecycle Problem
Even organizations that provision agent identities correctly often fail at lifecycle management. The question of who owns an agent identity — and what happens to it when the agent is deprecated, when the owning team is reorganized, or when the system the agent was built for is decommissioned — is rarely answered at provisioning time.
The answer needs to be embedded in the registration process itself. Every agent should have a designated technical owner, a designated business owner, and a documented review cadence. The agent registry (discussed in the next section) should surface agents that have not had their ownership confirmed in the last 90 days. Agents that fail an ownership review should have their permissions automatically scoped down to read-only until ownership is re-established — a pattern borrowed from access management for human identities that translates cleanly to agents.
Behavioral Drift Monitoring
Beyond initial provisioning, agent NHIs require ongoing behavioral monitoring. An agent that suddenly begins accessing systems it has not previously touched, making API calls at unusual hours, or elevating its own permissions through a misuse of granted capabilities represents an active security incident — whether caused by a prompt injection attack, a compromised upstream dependency, or a model regression that changes the agent’s behavior.
Runtime behavioral monitoring for NHIs is an emerging discipline in 2026, with dedicated tooling from vendors including Silverfort, CyberArk, and cloud-native SIEM integrations. The pattern is similar to user behavior analytics (UBA) for human identities: establish a behavioral baseline, define acceptable deviation thresholds, and alert when the agent’s behavior falls outside the envelope.
The Agent Registry: Your Single Source of Truth
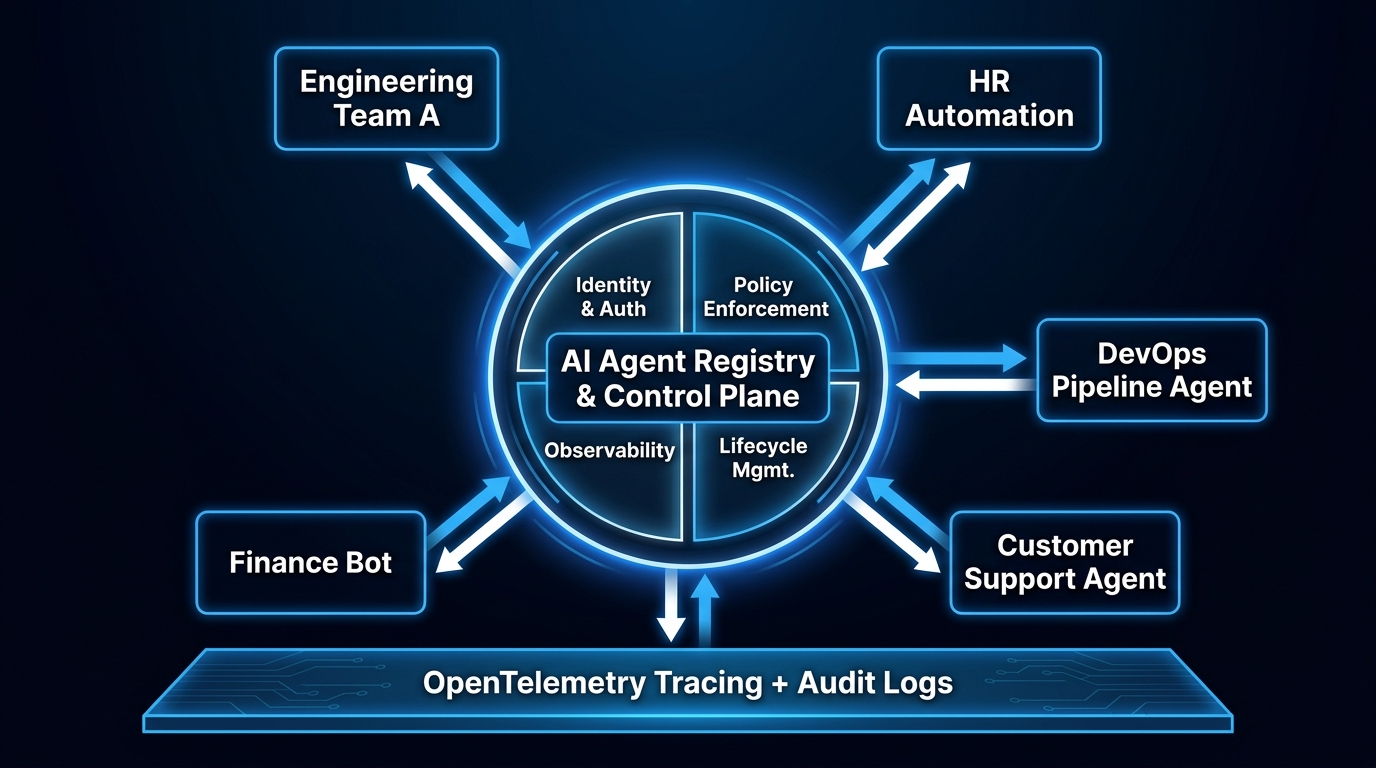
The agent registry is the foundational governance primitive that makes everything else possible. It is, in the simplest terms, an authoritative catalog of every AI agent in the organization: what it does, who owns it, what permissions it holds, what systems it interacts with, when it was last reviewed, and what its current operational status is.
Without a registry, governance is reactive. With one, it becomes proactive — and, critically, self-service. Developers consult the registry before building a new agent to see if something similar already exists. Security teams use the registry to audit permission footprints. Compliance teams use it to demonstrate to regulators that the organization has full visibility into its AI actor population. Operations teams use it to trace incidents back to specific agents and their owners.
What the Registry Needs to Capture
A minimal viable agent registry entry should include:
- Agent identity — a unique identifier, the associated service account or workload identity, and the environment (dev, staging, production).
- Purpose and scope — a plain-language description of what the agent does and a machine-readable declaration of what tools and data sources it is authorized to access.
- Ownership — technical owner (individual or team), business owner (accountable for the agent’s outcomes), and escalation contact.
- Risk tier — the classification assigned during onboarding, with the criteria that determined it documented.
- Dependency map — the upstream models, APIs, data stores, and downstream systems the agent interacts with, so that when any of those dependencies change, the registry can surface affected agents automatically.
- Review schedule — when the agent was last reviewed, when the next review is due, and the review outcome.
- Operational status — active, inactive, deprecated, or under investigation.
The registry is not a static document. It needs to be a live system, ideally backed by automation that discovers agents running in the environment and flags any that are not registered — the same way a CMDB discovers unmanaged infrastructure. Several vendors, including Google (with Agent Space), Microsoft (with Azure AI Foundry’s agent catalog features), and emerging startups in the AIOps space, are building managed registry capabilities into their platforms. For organizations not using those platforms, a well-structured internal developer portal with a custom agent catalog module can achieve the same outcome.
The Registry as a Governance Forcing Function
The registry is most powerful when it is made a prerequisite for production access. If an agent’s credentials cannot be provisioned without a corresponding registry entry, and if the deployment pipeline checks registry status before promoting to production, then the registry becomes self-populating. The paved path and the registry reinforce each other: you cannot get to production without going through the registry, and the registry provides the information the governance team needs to make informed approval decisions.
This is the difference between a registry that is an aspiration and one that is operationally effective. The enforcement mechanism is the key.
Building the Approval Workflow That Does Not Choke Velocity
The most common objection to AI agent governance is that it will slow teams down. This objection is valid when governance is designed as a monolithic gate — a single queue, managed by a single team, reviewing every agent regardless of risk level. It is not valid when approval is tiered, and when the approval process is designed around the developer experience.
Risk Tiering as the Foundation
Not all agents are equal, and approval workflows should reflect that. A practical risk tiering model for 2026 recognizes three distinct tiers:
Tier 1 — Low Risk: Agents that operate in read-only mode on non-sensitive data, affect only internal tools with no customer-facing outputs, and have no ability to trigger financial transactions or communications. Example: an agent that reads internal Confluence docs and summarizes them for developers. Approval: peer review by one senior engineer. SLA: 24 hours.
Tier 2 — Medium Risk: Agents that write to internal systems, interact with customer data, send communications, or trigger workflows that have downstream financial or operational effects. Example: a support ticket triage agent that categorizes and routes inbound tickets. Approval: technical lead review plus security review of permission scope. SLA: 3 business days.
Tier 3 — High Risk: Agents with broad permissions, access to sensitive personal or financial data, ability to take high-consequence autonomous actions (executing payments, modifying production infrastructure, sending large-scale communications), or operating in regulated domains. Example: an agent that processes refund requests and triggers API calls to the payment processor. Approval: cross-functional risk board including security, legal, compliance, and the accountable business owner. SLA: 7 business days with pre-review checklist.
The tier assignment should be automatic, driven by the registration form. The developer declares what the agent does and what it accesses; the classification engine assigns the tier; the approval workflow routes accordingly. There should be no ambiguity about which tier applies, and developers should be able to see the expected timeline before they start building.
Making Approvals Fast
Even within Tier 3, the process can be fast if it is structured correctly. Pre-defined checklists, standardized risk assessment templates, and asynchronous review (rather than scheduled meetings) dramatically reduce cycle time. The goal for even the most complex agent approval should be a maximum of two weeks from registration to production clearance. Teams that are regularly waiting longer than that should treat it as a process failure, not an acceptable cost of governance.
Critically, approved agents should not need to go back through full review for iterative updates. A change management process that distinguishes between substantive changes (new data access, new action capabilities, changed ownership) and non-substantive changes (prompt refinements, model version updates within an approved family, UI changes) allows teams to iterate quickly within an approved envelope without re-triggering the full approval cycle.
Runtime Observability: If You Cannot See It, You Cannot Govern It
Approval gates answer the question of whether an agent should be allowed to run. Runtime observability answers the question of whether it is running correctly, safely, and within its declared scope. Both are necessary. Neither is sufficient alone.
The OpenTelemetry Foundation
Enterprise AI agent observability in 2026 is converging rapidly on OpenTelemetry (OTel) as the instrumentation layer of choice. The OTel project has defined GenAI semantic conventions that standardize how AI agents emit traces, metrics, and logs — covering model calls, tool invocations, token usage, latency, and error rates in a way that is framework-agnostic and backend-agnostic.
The practical implication is that teams building agents on LangChain, LlamaIndex, CrewAI, Microsoft Semantic Kernel, or any other major agentic framework can instrument with OTel and route their telemetry to any compatible backend — Grafana, Datadog, Honeycomb, Dynatrace, or cloud-native equivalents — without vendor lock-in. This is a significant improvement over the fragmented, framework-specific observability tooling that existed even 18 months ago.
What Agent Telemetry Should Capture
Standard application observability (errors, latency, uptime) is necessary but not sufficient for AI agents. A complete agent observability stack should also capture:
- Reasoning traces — the full chain of thought that the agent executed to reach a decision or take an action, including the prompts issued, the model responses at each step, and the tool calls made. This is essential for debugging unexpected behavior and for demonstrating to auditors that the agent’s decision-making is traceable.
- Tool call audit logs — a structured record of every external action the agent took (API calls, database writes, file system operations), with the input parameters, the output, and the identity context under which the action was performed.
- Input and output quality metrics — automated evaluation of whether the agent’s outputs meet quality standards, using metrics appropriate to the use case (factual accuracy scores, format compliance, sentiment analysis for customer-facing outputs).
- Permission access patterns — which permissions the agent used in each session, to detect scope creep or unusual access patterns that might indicate compromise or model drift.
- Human escalation events — when the agent triggered a human-in-the-loop checkpoint, what decision was presented for human review, and what the human decided.
Alerting and Response
Collecting telemetry is only valuable if it drives action. The observability layer should feed a set of alerts that trigger automated responses for defined anomaly patterns. An agent accessing a data source outside its declared scope should trigger an automatic permission suspension and an alert to the security team. An agent whose error rate exceeds a threshold should trigger automatic rollback to the previous version. An agent that has not emitted telemetry for an expected period should trigger an availability alert to the technical owner.
This closed-loop design — telemetry feeding alerts feeding automated responses — is what separates a mature observability practice from a data collection exercise. The data is only valuable if it causes something to happen.
The Developer Autonomy Equation: Speed With Guardrails
The tension between developer autonomy and centralized IT control is the political reality that any AI agent governance program has to navigate. Engineering teams building agents are not adversaries of the governance function — they are users of it. And like any product, a governance product that creates more friction than it removes will be worked around.
Governance as a Product, Not a Policy
The most successful enterprise AI governance programs in 2026 are the ones that have been designed with a product mindset. The platform team or security team responsible for agent governance treats developers as their primary customers and designs accordingly: rapid onboarding, self-service where possible, clear documentation, SLA commitments, and feedback loops that allow the governance process to improve based on developer experience.
This means investing in the developer portal, the registration interface, and the feedback mechanisms — not just in the policy documents. A governance framework that lives in a Confluence wiki and requires navigating five separate JIRA queues will be ignored. A governance framework embedded in the CI/CD pipeline, with auto-generated compliance reports and one-click escalation to the right approver, will be adopted.
Inner Loop vs. Outer Loop
A useful framing for balancing autonomy and control is the distinction between the inner loop and the outer loop of agent development:
The inner loop — everything that happens on a developer’s workstation or in a sandbox environment during active development — should be nearly frictionless. Developers should be able to build, test, and iterate on agents as freely as they can write and test any other software. The governance layer does not touch the inner loop.
The outer loop — the transition from sandbox to staging, and from staging to production — is where governance applies. This is the right moment: the agent is at the boundary between individual experimentation and shared system impact. Governance at this boundary is not an interruption to development; it is a quality gate that protects the production environment without interfering with the creative process.
Organizations that place governance earlier (requiring approval before any development begins) or more broadly (applying production-level review to sandbox experiments) create unnecessary friction that drives developers toward the cowboy path. Organizations that place governance only at this outer loop boundary — and make the outer loop experience smooth — achieve both velocity and safety.
Expanding Autonomy Incrementally
The right model for developer autonomy in AI agent deployment is not a binary: either you need approval for everything, or you do not. It is a graduated expansion based on demonstrated track record. A team that has shipped three Tier 1 agents with clean audit trails and zero security incidents earns a simplified approval path for their next Tier 1 submission. A team that has shipped a successful Tier 2 agent earns a faster track for subsequent Tier 2 submissions in the same domain.
This mirrors how zero-trust network access works for humans: trust is earned contextually, not granted broadly. Applied to AI agent governance, it gives developers a clear incentive to follow the paved path from the start — doing so builds institutional credibility that translates into real-time savings on future submissions.
Rolling Out Incrementally: From Sandbox to Production Without Drama
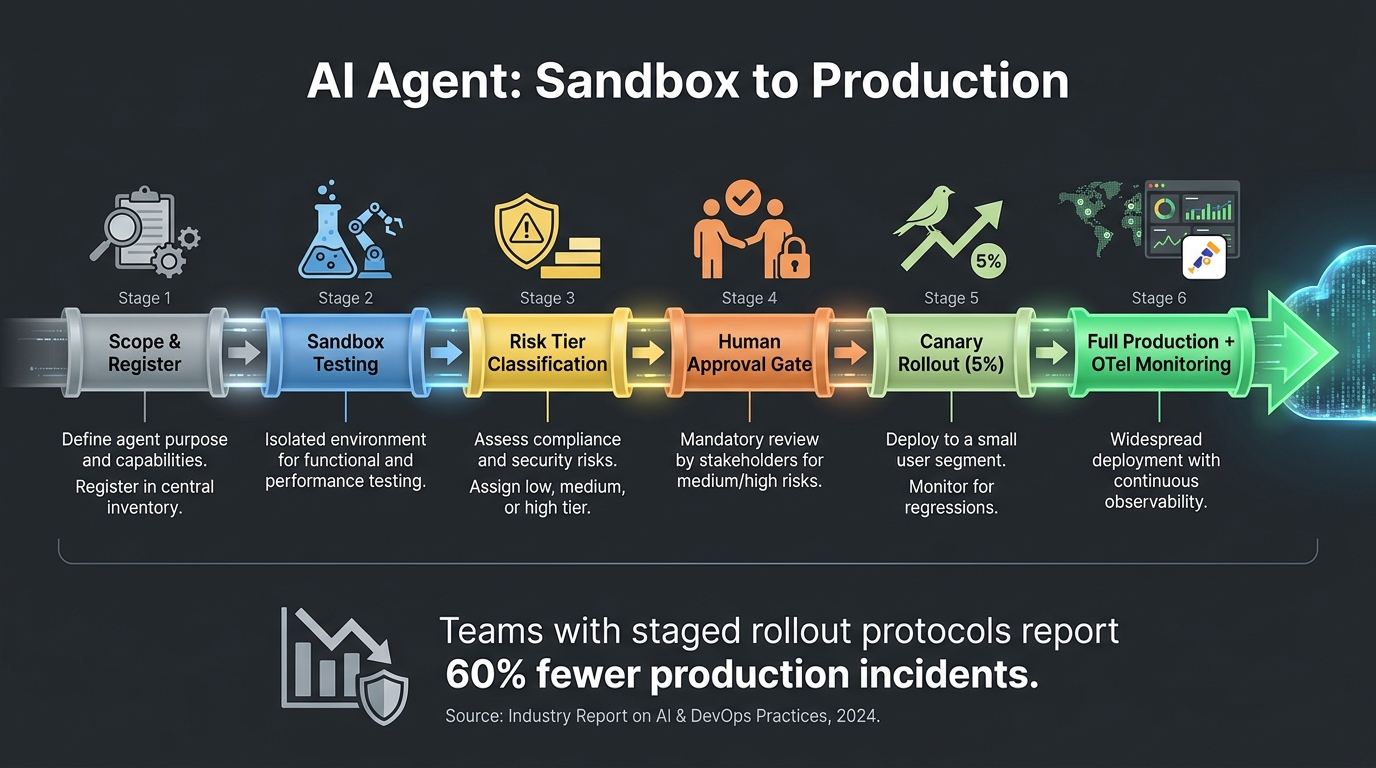
Even a fully approved agent should not go from zero to full production traffic in a single step. Staged rollout is a standard practice in software deployment that applies with even greater force to AI agents, because the behavior of an AI system can degrade in production in ways that are not visible in staging — due to data distribution shifts, prompt injection from real user inputs, or interaction effects with other systems that the staging environment does not replicate.
The Six-Stage Deployment Model
Leading engineering teams in 2026 are converging on a six-stage model for agent deployment:
Stage 1 — Scope and Register: Define the agent’s purpose, data access, action capabilities, and risk tier. Complete the registry entry. This stage produces the formal specification that all subsequent stages are evaluated against.
Stage 2 — Sandbox Development and Testing: Build and test the agent in an isolated environment with no production data and no production credentials. Use synthetic data that reflects the structure and complexity of real data. Evaluate the agent against a defined test suite covering both happy-path scenarios and adversarial inputs (including prompt injection attempts, malformed inputs, and edge cases).
Stage 3 — Risk Tier Classification and Approval: Submit the registered agent for tier-appropriate approval. The approval review should include a walkthrough of the test results, the permission scope rationale, and the operational runbook. Approval clears the agent for staging deployment.
Stage 4 — Staging with Production-Adjacent Data: Deploy to a staging environment with production-like data (appropriately anonymized where required) and production-level observability configured. Run the agent under realistic load for a defined observation period — typically one to two weeks for Tier 2 and Tier 3 agents. Review telemetry for any anomalies before proceeding.
Stage 5 — Canary Rollout: Promote to production with a traffic split — typically starting at 5% of the intended traffic volume. Monitor closely for the first 48 to 72 hours. Expand traffic allocation in increments (5% → 25% → 50% → 100%) with defined observation periods and automatic rollback triggers between each increment. For high-risk agents, maintain human oversight of a representative sample of agent decisions during the canary period.
Stage 6 — Full Production with Continuous Monitoring: Full traffic allocation, with the ongoing observability, alerting, and review cadence defined at registration active and enforced. Ownership confirmed in the registry. Next scheduled review date set.
The discipline here is not about slowing down deployment. The full six-stage process, run efficiently, should take two to four weeks for a Tier 2 agent and four to six weeks for a Tier 3 agent. That timeline is not excessive for a system that will operate autonomously on live production data and take real-world actions. It is appropriate.
Rollback Is Not Failure
One cultural adjustment that governance programs need to actively cultivate is the normalization of rollback. In traditional software deployment, rolling back a release is sometimes treated as a failure. For AI agent deployment, it should be treated as the system working as designed. An agent that is rolled back because observability detected an anomaly during canary is not a problem — it is a success. The alternative (detecting the anomaly after full production rollout, when the blast radius is much larger) is the actual failure mode the staged process exists to prevent.
The Governance Stack: Tools and Patterns for 2026
The infrastructure for AI agent governance has matured considerably over the last 18 months. Teams no longer need to build all of these capabilities from scratch. The 2026 governance stack for AI agents draws on a combination of established enterprise tooling and emerging AI-specific platforms.
Identity and Access Management Layer
For NHI management, the foundational tools are the major cloud providers’ workload identity federation systems (AWS IAM Roles for Service Accounts, GCP Workload Identity Federation, Azure Managed Identities) combined with a secrets management system like HashiCorp Vault or AWS Secrets Manager for short-lived credential issuance. For organizations with more complex multi-agent architectures, dedicated NHI management platforms from vendors like Astrix Security, Natoma, or Entro Security provide centralized visibility into machine identity sprawl across cloud and SaaS environments.
Agent Registry and Control Plane
At the infrastructure level, agent registries are being built on top of internal developer portals (Backstage is the most common open-source foundation), extended with custom agent catalog plugins. At the platform level, Google’s Agent Space, Microsoft’s Azure AI Foundry agent catalog, and Salesforce’s AgentForce governance features provide managed registry capabilities within their respective ecosystems. Organizations running heterogeneous multi-platform environments typically need a custom integration layer to aggregate registry data across these sources.
The agent control plane — the enforcement layer that routes requests through policy before they reach production systems — is increasingly being built using API gateway patterns, with tools like Kong, AWS API Gateway, or Apigee acting as the policy enforcement point through which all agent tool calls must pass. This architecture means that policy changes (scoping down permissions, adding rate limits, blocking specific tool calls) can be applied at the gateway layer without modifying the agent code.
Observability and Evaluation Layer
OpenTelemetry instrumentation, feeding into a backend of choice, handles the infrastructure observability layer. For AI-specific observability — reasoning traces, prompt audit logs, quality evaluations — dedicated platforms including LangSmith (from LangChain), Arize AI, Evidently AI, and the Braintrust platform provide specialized capabilities. The choice between these tools depends largely on the agentic framework in use and the specific evaluation needs of the deployment.
An important pattern emerging in 2026 is the separation of observability from evaluation: the observability layer (OTel-based) captures raw telemetry in real time, while an asynchronous evaluation layer processes a sample of that telemetry against quality and safety criteria on a continuous basis. This distinction prevents evaluation latency from adding to the agent’s response time while still ensuring continuous quality monitoring.
Policy and Compliance Layer
For organizations operating under regulatory frameworks — GDPR, HIPAA, SOC 2, or the EU AI Act (which applies to high-risk AI systems in EU markets) — the governance stack needs a compliance documentation layer that generates evidence of control operation from the telemetry and registry data. Tools like Vanta, Drata, or Secureframe, which already handle continuous compliance monitoring for software systems, are extending their integrations to cover AI agent governance evidence in 2026.
The EU AI Act in particular is worth noting for enterprises with EU operations: agents that interact with customers, make decisions affecting employment, access control systems, or critical infrastructure may be classified as high-risk AI systems under the Act, requiring conformity assessments, technical documentation, human oversight mechanisms, and post-market monitoring. The governance stack described in this post is largely aligned with those requirements — but compliance teams should map their specific agent inventory against the Act’s risk categories explicitly.
Conclusion: The Real Trade-Off Is Not Speed vs. Safety
The frame that positions AI agent governance as a trade-off between speed and safety is a false one. The real trade-off is between paying governance costs now, in a structured and manageable way, or paying them later, in the form of security incidents, operational failures, regulatory penalties, and the engineering debt of retroactively governing a sprawling population of ungoverned agents.
The evidence on which side of that trade-off is more expensive is not ambiguous. Shadow AI breaches cost $670,000 more per incident. Ungoverned agent populations require expensive reactive cleanup. Regulatory exposure under emerging AI governance frameworks can produce fines that dwarf any productivity gains from shipping without oversight. And the reputational cost of a publicly disclosed AI incident — an agent that sent inappropriate customer communications, made discriminatory automated decisions, or was compromised and used as an attack vector — is not easily quantified but is very real.
The teams that are winning with AI agents in 2026 are not the ones that are moving fastest in absolute terms. They are the ones that have built the infrastructure to move fast sustainably — shipping agents quickly into a structured environment that gives them full visibility, control, and the ability to iterate without fear of uncontrolled failure.
Actionable Starting Points
If your organization is early in this journey, the most impactful first steps are:
- Conduct an agent inventory audit. Before building governance, understand the current state. Scan your cloud environments, API gateway logs, and OAuth token issuances for evidence of agents already running. The number will likely surprise you.
- Define your NHI identity policy. Establish how agent identities are created, scoped, rotated, and decommissioned. This single policy change addresses the most acute security vulnerability in most enterprise agent deployments.
- Stand up a minimal viable registry. Even a well-structured spreadsheet is better than no registry. The goal is to have a defined location where all agents are cataloged, with a committed owner for each entry.
- Design the paved path before writing the policy. Start from the developer experience you want to create, then design the policy controls that support it. A policy that developers will actually follow is worth infinitely more than a comprehensive policy that will be bypassed.
- Start instrumenting today. Add OpenTelemetry instrumentation to any agent currently in development. Even if the full governance stack is months away, having telemetry data from day one means you will have a behavioral baseline to measure against when the monitoring layer arrives.
Building governance for AI agents is not a project with a completion date. It is a capability that an organization develops and matures over time, responding to the agents it ships, the incidents it encounters, and the regulatory environment it operates in. The organizations that start building that capability now — even imperfectly — will be in a fundamentally stronger position than those that wait until the hangover makes it unavoidable.
Ship fast. Ship governed. The two are not opposites.


