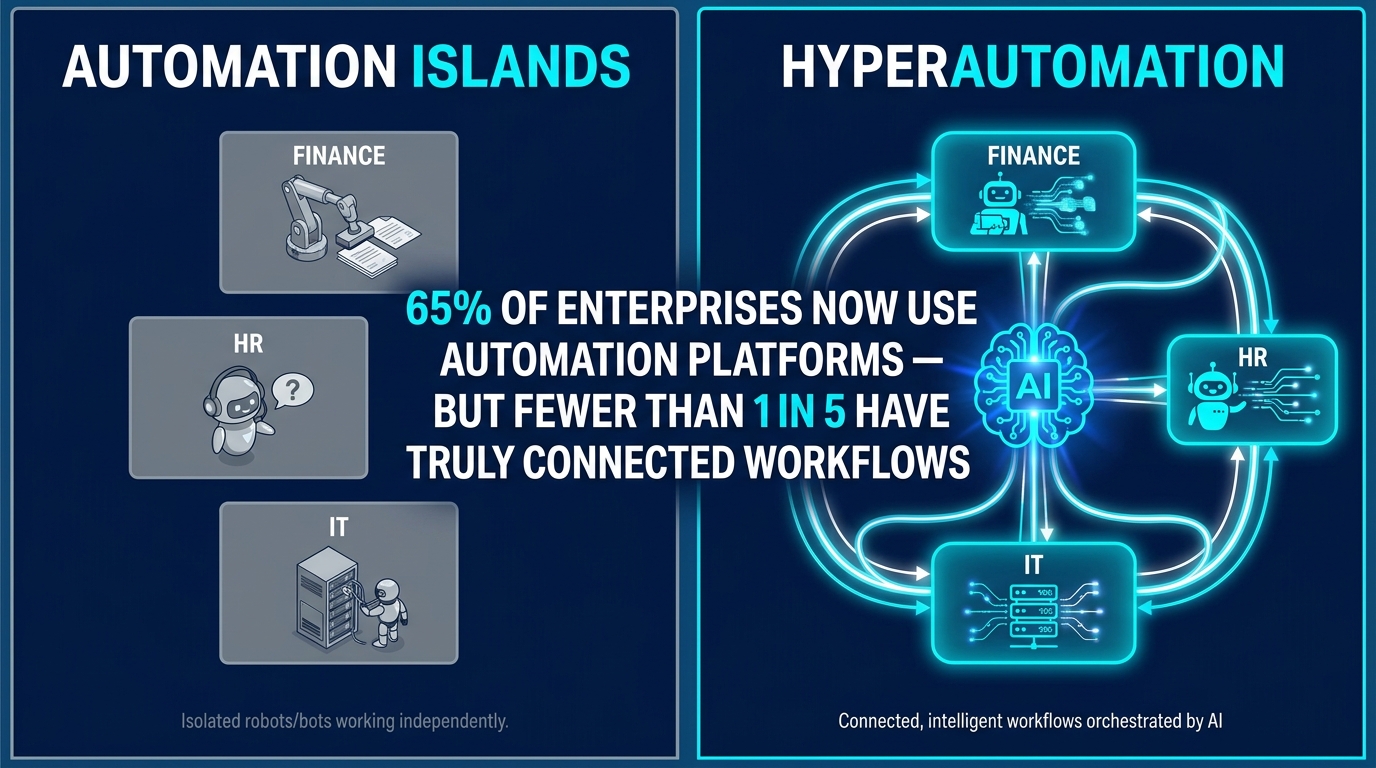
Most organizations that describe themselves as “automated” aren’t. They’ve built automation islands — isolated bots and scripts doing useful work inside Finance, or IT, or HR, but never talking to one another. The sales team closes a deal and somebody in operations manually re-enters the data into a different system. A new hire gets an offer letter and then waits four days for IT to provision their laptop because the connection between HR and IT simply doesn’t exist at the process level.
This is the seam problem. And it’s where the majority of enterprise efficiency bleeds out.
Hyperautomation is the discipline of closing those seams. Not just automating tasks within departments, but wiring the entire organization together so that information, decisions, and actions flow automatically across every function — Finance to Operations, HR to IT, Sales to Fulfillment — with AI handling the complexity in between.
The market numbers validate the urgency. The global hyperautomation market sat at roughly $65.67 billion in 2025 and is on a trajectory toward $306 billion by 2035, growing at a compound annual rate above 17%. Gartner reports that 90% of large enterprises have named hyperautomation a strategic priority. Yet adoption data tells a more sobering story: while 65% of organizations are using automation platforms of some kind, genuine cross-department workflow integration remains the exception, not the rule.
This article is about the gap between having automation and having connected automation — what causes it, how to close it, and what the organizations that have done it well learned along the way.
What Hyperautomation Actually Is (And What It Isn’t)
The term gets used loosely enough that it’s worth being precise. Hyperautomation is not simply “more automation.” It’s a fundamentally different operating philosophy — one that treats the enterprise as a single interconnected system rather than a collection of departments that each happen to use software.
The Scope Difference
Traditional automation — particularly Robotic Process Automation (RPA) — targets discrete, rule-based tasks. A bot extracts invoice data from a PDF and enters it into an ERP system. Another bot monitors a queue and routes tickets. These are valuable, but they’re local solutions. They don’t inherently know anything about what happens before or after their specific task, and they certainly don’t coordinate with automations running in other departments.
Hyperautomation addresses end-to-end processes that cross organizational boundaries. It integrates RPA with artificial intelligence, machine learning, process mining, low-code platforms, workflow orchestration engines, and business process management to create self-aware, adaptive workflows. When the invoice bot encounters an exception — say, a vendor invoice that doesn’t match a purchase order — a hyperautomated system doesn’t just flag it. It routes it to the right approver, pulls context from the procurement system, cross-references the vendor’s history, and logs the resolution for audit purposes. Automatically.
The Technology Combination
The “hyper” prefix refers to the synthesis of technologies that individually are limited, but together create something qualitatively different:
- RPA handles structured, repetitive tasks across applications
- AI and machine learning handle unstructured data, decisions, and pattern recognition
- Process mining discovers and maps actual workflow behavior from system event logs
- Natural language processing (NLP) interprets documents, emails, and communications
- Low-code/no-code platforms enable faster automation development and citizen development
- Workflow orchestration engines coordinate the sequence, routing, and exception handling across all components
- Digital process twins model and simulate workflows before deployment
None of these is hyperautomation on its own. Together, coordinated through an orchestration layer, they form a system that can observe, adapt, and improve — not just execute.
The Hidden Cost of Departmental Silos
Before examining how to fix the seam problem, it’s worth quantifying why it matters. The costs of siloed automation are real, measurable, and in most organizations, dramatically underestimated.
The Manual Handoff Tax
Every time a process crosses a departmental boundary without automation, it typically involves a manual handoff: someone downloads a report, sends an email, re-enters data, or waits for someone else to do all of the above. These handoffs are invisible in most process maps because they happen in email inboxes and spreadsheets rather than in the formal systems that get analyzed.
The compounding effect is significant. Research on order-to-cash cycles — the end-to-end process from a customer placing an order to cash being received — consistently finds that manual handoffs between Sales, Finance, Fulfillment, and Customer Service account for between 40% and 70% of total cycle time. The actual work steps (checking credit, picking inventory, raising an invoice) can each take minutes. The waiting between them takes days.
The Data Inconsistency Problem
Siloed systems create siloed data. When each department maintains its own version of customer records, inventory counts, or employee status, discrepancies inevitably accumulate. A customer who updated their billing address with Sales still gets invoices sent to the old address by Finance — because the two systems don’t talk. A terminated employee retains system access for three days after their last day because HR’s offboarding process and IT’s access revocation process operate on separate timelines.
These aren’t edge cases. Data fragmentation is consistently cited as the primary blocker for enterprise-scale hyperautomation. When AI models are trained on inconsistent data across departments, they learn from contradictory signals — and the resulting automations execute quickly while operating on flawed logic. Fast and wrong is often worse than slow and right.
The Compliance Exposure
In regulated industries, siloed automation creates a specific and serious risk: audit trails that stop at departmental boundaries. When a loan approval process spans customer service, credit analysis, compliance review, and operations — but each of those steps happens in a different system with no connecting record — reconstructing the decision history for a regulator becomes a forensic exercise. Manual re-entry during handoffs introduces the additional risk of undocumented changes. In financial services, healthcare, and any industry subject to data privacy regulations, this exposure isn’t theoretical.
Process Mining: The X-Ray Your Workflows Need First
Most hyperautomation initiatives start in the wrong place. Teams identify processes they think are inefficient — usually based on department manager intuition or anecdotal complaints — and begin automating them. The problem is that intuition about how processes work is notoriously unreliable. What managers believe happens in a workflow and what actually happens, step by step, in the systems of record, often bear little resemblance to each other.
Process mining solves this by replacing assumption with evidence.
How Process Mining Works
Every enterprise system — ERP, CRM, HRIS, ticketing systems — generates event logs. Every time a record is created, modified, approved, or transferred, that action is timestamped and logged. Process mining tools consume these logs and reconstruct the actual, empirical flow of work through an organization.
The resulting visualizations frequently produce what practitioners describe as “uncomfortable moments” in leadership reviews. Processes that were assumed to be linear turn out to have dozens of variants. Steps that were supposed to happen in sequence happen in parallel — or in reverse order. Exception handling that was supposed to be rare turns out to account for 30% or more of all cases. Rework loops — where work is completed, fails some check, and cycles back to an earlier stage — consume hours that nobody knew were being lost.

What Good Process Mining Surfaces
A mature process mining implementation across cross-department workflows typically surfaces four categories of insight:
- Bottlenecks: Specific steps or handoffs where work queues up disproportionately. These are the highest-value automation targets because reducing a bottleneck improves the entire downstream flow.
- Deviations: Cases that follow unexpected paths. High deviation rates often signal either unclear process design or workarounds that employees have developed to handle gaps in the official process.
- Wait time concentration: In most cross-department workflows, 70-90% of total process time is waiting — for approvals, for data from another system, for someone to pick up a task. Process mining makes this visible and quantifies it.
- Automation fit scores: Modern process mining tools don’t just map — they score each process step on its suitability for automation based on frequency, consistency, and system touchpoints.
Process Mining as a Continuous Layer
The most sophisticated implementations treat process mining not as a one-time discovery exercise but as a continuous monitoring layer. Once automations are deployed, process mining watches the event logs to detect drift — cases where the automated process is deviating from its intended behavior, or where new exception patterns are emerging that weren’t present at deployment. This creates a feedback loop that keeps hyperautomation programs adaptive rather than static.
Tools like SAP Signavio, Celonis, UiPath Process Mining, and IBM Process Mining now integrate directly with orchestration layers, meaning process insights can trigger automatic workflow adjustments without requiring a human to interpret a dashboard and initiate a change.
The Four Technology Layers of a Hyperautomation Stack
Mature hyperautomation implementations don’t deploy all technologies simultaneously. They build in layers, with each layer adding capability and intelligence to what came before. Understanding this architecture helps organizations both sequence their investments and diagnose why existing programs may be underperforming.
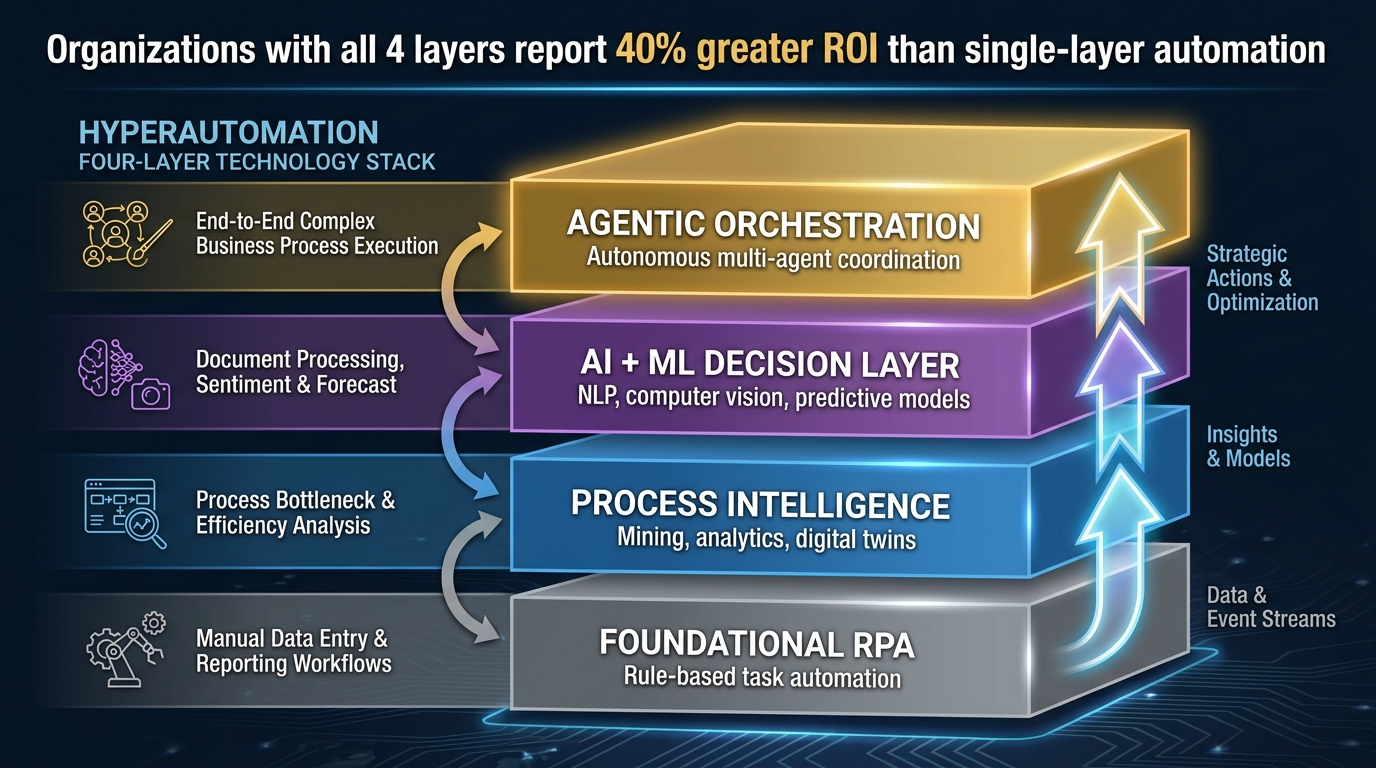
Layer 1: Foundational Automation (RPA + Integration)
This is where most organizations start. RPA bots handle structured, rule-based tasks: data extraction, form filling, record updates, report generation. API integrations connect systems directly where possible, eliminating screen-scraping entirely. The value is real but bounded — you’re eliminating manual work, not redesigning processes.
The critical discipline at this layer is standardization before automation. Automating a broken process makes it faster and breaks things faster. Before deploying RPA on any cross-department workflow, the process needs to be stable, documented, and agreed upon by all departments that touch it.
Layer 2: Process Intelligence (Mining, Analytics, Digital Twins)
The intelligence layer adds the ability to observe, measure, and model. Process mining maps actual workflow behavior. Analytics dashboards surface performance against KPIs in real time. Digital process twins allow teams to simulate changes before deploying them — testing, for example, how adding a parallel approval path would affect total cycle time under different volume scenarios.
This layer transforms automation from a static deployment into a managed program. Without it, organizations can’t answer basic questions: Is our automation actually working? Where did the time savings go? Which processes have drifted since deployment?
Layer 3: AI and Machine Learning Decision Capability
The AI layer adds the capacity to handle complexity that rule-based systems can’t address. Natural language processing reads and classifies unstructured documents — contracts, emails, claim forms — and routes them to the appropriate workflow. Machine learning models score risk, predict approval outcomes, or flag anomalies in financial transactions. Computer vision reads physical documents, images, or screens that aren’t machine-readable in a traditional sense.
This is the layer that allows automation to move from “if X then Y” logic into genuine decision-making. An invoice processing workflow without AI can handle clean, structured invoices automatically. With AI, it can also handle the 15-20% of invoices that are ambiguous, non-standard, or exception-triggering — which is precisely where the manual effort concentrates.
Layer 4: Agentic Orchestration
The newest and most consequential layer is agentic AI — systems that don’t just execute predefined workflows but pursue goals by decomposing objectives, selecting the appropriate tools and workflows, and adapting based on results. Where traditional orchestration coordinates predefined sequences, agentic orchestration can reason about what needs to happen next in a novel situation.
This is explored in more depth in the next section, but the key architectural point is that agentic AI works best on top of the first three layers — it needs stable foundational automation, process intelligence to inform its decisions, and AI models to handle complexity. Organizations that attempt to deploy agentic AI without the lower layers typically find that their agents have nothing reliable to orchestrate.
Wiring the Enterprise: Cross-Department Workflow Blueprints
Abstract principles only go so far. The most useful way to understand cross-department hyperautomation is to examine specific workflow categories where the seam problem is most acute — and how organizations are closing those seams in practice.
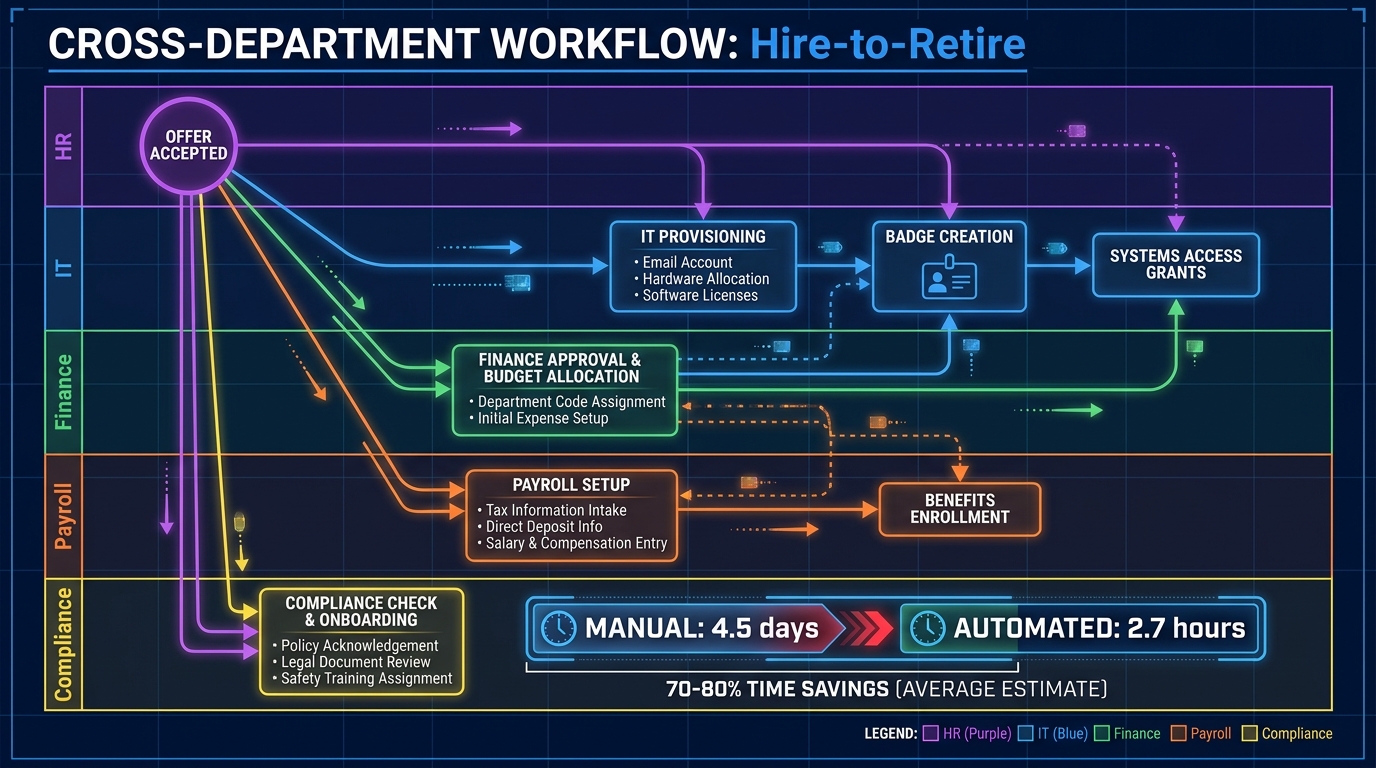
Hire-to-Retire: The HR-IT-Finance-Compliance Chain
The hire-to-retire workflow is the canonical example of a cross-department process that almost every organization handles badly. When a candidate accepts an offer, what follows is a cascade of tasks that span HR (employment record creation, benefits enrollment), IT (device provisioning, system access, email setup), Finance (payroll configuration, cost center allocation), and Compliance (background verification, regulatory onboarding requirements).
In a conventional organization, this happens sequentially and largely via email. The average time from offer acceptance to a fully productive employee — with all systems configured, all access granted, all compliance steps completed — is measured in days to weeks. And because each department works from its own system with its own timeline, errors and omissions are common: IT provisions access to the wrong role profile, Finance configures payroll with the wrong start date, Compliance doesn’t receive notification that the process has started.
A hyperautomated hire-to-retire workflow triggers all downstream tasks in parallel the moment an offer is accepted. An orchestration engine coordinates across all four departments simultaneously, with dependencies enforced automatically: IT access provisioning, for example, can be configured but not activated until background verification is confirmed. The employee arrives on day one to a fully provisioned environment. Organizations that have implemented this typically report reducing total onboarding time from four-plus days to under three hours for the administrative component.
The same logic applies in reverse to offboarding. When an employee departure is logged in HR, the orchestration engine simultaneously triggers IT access revocation, payroll cutoff configuration, equipment return workflows, and compliance record archiving. The security exposure of an active user account after employment ends — a surprisingly common risk — is eliminated.
Order-to-Cash: The Sales-Finance-Operations-Service Chain
Order-to-cash (O2C) is typically the highest-revenue-impact cross-department workflow in any commercial enterprise. It spans Sales (deal closure, order entry), Operations (fulfillment, logistics), Finance (invoicing, credit control, collections), and Customer Service (delivery confirmation, issue resolution). Each handoff in this chain is a potential delay and a potential error point.
The data on O2C performance in organizations without hyperautomation is stark: Days Sales Outstanding (DSO) — the average time between raising an invoice and receiving payment — is frequently two to four times longer than it needs to be, primarily due to manual handoffs and invoice errors that require correction cycles before the customer will pay.
In hyperautomated O2C workflows, a closed-won deal in the CRM triggers automatic credit checking against the customer’s history, inventory reservation in the warehouse management system, order acknowledgment to the customer, and invoice generation scheduled against the delivery confirmation trigger. If an invoice exception is flagged — a quantity discrepancy or a pricing variance — the system routes it to the correct approver, records the decision, and updates both the customer portal and the internal ERP simultaneously. Organizations implementing this approach report DSO reductions of 25-40%, which at enterprise scale translates directly to significant working capital improvement.
Procure-to-Pay: The Procurement-Finance-Compliance Chain
Procure-to-pay (P2P) — from purchase requisition through supplier invoice payment — is one of the most data-intensive and compliance-sensitive cross-department workflows in most organizations. It involves Procurement (requisitions, vendor selection, purchase orders), Finance (budget checking, invoice processing, payment), and Compliance (vendor due diligence, three-way matching, audit trail).
Manual P2P processes are characterized by high exception rates: industry benchmarks suggest that between 15% and 25% of supplier invoices require some form of manual intervention, whether because they don’t match the purchase order, arrive in non-standard formats, or require additional approval due to budget rules. Each exception costs time and money to resolve.
Hyperautomated P2P uses AI-powered document processing to handle non-standard invoice formats, machine learning to perform three-way matching with higher accuracy than manual review, and rule-based escalation to route genuine exceptions to the right approver with all relevant context pre-loaded. Accesa’s implementation of this pattern eliminated manual effort for invoice posting, boosted data accuracy, and delivered ROI through a combination of error reduction and staff time reallocation — with one RPA bot managing roughly 7,000 monthly processing events and saving over 230 staff hours per month.
IT Service Management: The IT-HR-Security-Finance Chain
IT service management is frequently treated as a purely internal IT function, but in reality it spans multiple departments. Access provisioning depends on HR data about roles and employment status. Incident response often requires Finance authorization for emergency procurement. Security operations crosses every department when a threat is detected and access needs to be locked down organization-wide.
In hyperautomated IT service management, an employee role change in the HRIS automatically triggers access reconfiguration in all connected systems — no IT ticket required. A security alert at severity level three triggers automatic containment actions (access revocation, network segmentation) while simultaneously notifying the relevant department heads and initiating the incident log. The savings in response time alone — moving from manual incident response that takes minutes or hours to automated response that takes seconds — has significant security value.
Agentic AI: The New Orchestration Layer Changing Everything
The most significant development in hyperautomation over the past eighteen months is the emergence of agentic AI as a genuine enterprise capability. Unlike conventional workflow orchestration, which executes predefined sequences, agentic AI systems pursue goals by reasoning, planning, and adapting — choosing which tools and workflows to invoke based on the current situation rather than following a fixed script.
What Makes an AI Agent Different
A conventional automation workflow is deterministic: given input A, produce output B by following steps 1 through 7 in sequence. This works well for stable, high-volume processes with predictable inputs. It struggles when the situation is novel, when inputs are ambiguous, or when the right action depends on context that wasn’t anticipated when the workflow was designed.
An agentic AI system receives a goal — “resolve this supplier dispute” — and reasons through what needs to happen: retrieve the original purchase order, compare it to the invoice, check the supplier’s communication history, assess whether the discrepancy falls within standard tolerance, and either resolve autonomously or escalate with a full context summary. It can use multiple tools, handle intermediate results, and adjust its approach based on what it finds. This is qualitatively closer to how a skilled human analyst works than anything traditional RPA can achieve.
Enterprise Deployments in 2026
Real-world agentic AI deployments are already generating significant results across industries. Walmart’s agentic supply chain workflow anticipates demand, adjusts replenishment orders, and reroutes inventory autonomously across stores and distribution facilities — adapting in real time to demand signals and supply disruptions. DHL partnered with HappyRobot to deploy AI agents that handle warehouse scheduling calls, driver follow-up communications, and appointment coordination autonomously, with human oversight maintained for high-stakes decisions.
Danfoss, the industrial conglomerate, implemented agentic order management that handles 80% of order-related customer queries without human involvement. TELUS reported saving 40 minutes per AI interaction across its workforce using agentic workflows. Suzano, the paper and pulp company, reduced supply chain query resolution time by 95% using Google Cloud’s Gemini-based agents. The pattern across these implementations: agents don’t replace entire processes, but they dramatically compress the time and cost of the decision-making and exception-handling steps that sit at the center of every cross-department workflow.
The Human-in-the-Loop Design Principle
Effective agentic AI deployment isn’t about removing humans from workflows — it’s about repositioning where and when human judgment is applied. The goal is to have AI handle the high-volume, lower-stakes decisions automatically, surface the genuinely complex cases to human experts with all relevant context already prepared, and log every action for auditability.
The organizations making the most progress on agentic AI in 2026 are those that have been deliberate about defining their human-in-the-loop boundaries upfront — specifying exactly which categories of decisions require human confirmation, what confidence thresholds trigger escalation, and how exceptions are recorded and reviewed. This isn’t a technical question; it’s a governance question that requires input from Legal, Compliance, HR, and senior leadership before a single agent is deployed.
Building a Center of Excellence That Actually Governs
The most common structural failure in enterprise hyperautomation programs isn’t technical — it’s organizational. Without a governing body that has real authority, cross-department automation initiatives fragment into departmental projects that duplicate effort, create integration conflicts, and generate governance gaps that expose the organization to compliance and security risk.
Why Most CoEs Fail
Organizations set up automation Centers of Excellence with the right intentions and then watch them gradually lose influence. The typical failure pattern: the CoE starts with a mandate to govern automation across the enterprise, but lacks the authority to enforce standards. Individual departments, impatient with approval processes, start deploying their own automation tools — low-code platforms, point solutions, vendor-specific automation features — without CoE oversight. Within eighteen months, the organization has a proliferation of automation islands again, plus a CoE that exists largely on paper.
The problem is almost always a governance model mismatch. CoEs are set up as advisory bodies when they need to be decision-making bodies. They’re staffed with technologists when they need to include compliance, legal, and business operations. They measure outputs (number of automations deployed) rather than outcomes (cycle time reduction, error rate improvement, audit trail completeness).
What Effective Governance Looks Like
Effective hyperautomation CoEs share several structural characteristics. First, they operate under a federated governance model: a central governing body sets standards, architecture requirements, security controls, and compliance frameworks — but execution happens within departments, by teams that the CoE has trained and certified. This preserves departmental autonomy while ensuring that all automation is built to common standards that allow it to be integrated and governed at the enterprise level.
Second, they maintain a process registry: a centralized inventory of every automation in production, what it does, which systems it touches, who owns it, and when it was last audited. This sounds bureaucratic, but it’s essential for cross-department workflows. When you need to change a downstream system that’s integrated into fifteen different automations, you need to know what those fifteen automations are and who to notify.
Third, they enforce automation retirement policies. Automations that were built for a specific system version or process configuration don’t automatically stay current when those systems change. Without a lifecycle management policy, organizations accumulate brittle automations that break in production and require emergency remediation — burning the trust of the business stakeholders who depend on them.
The Governance Metrics That Matter
A CoE that can’t measure its own impact loses its case for continued investment. The most meaningful governance metrics are:
- Automation health rate: percentage of production automations that are running within their defined SLA, versus flagged for errors, drift, or maintenance
- Integration coverage: percentage of cross-department handoffs that are automated versus manual
- Exception rate trend: whether automated processes are generating fewer or more exceptions over time (upward trend signals drift or poor design)
- Time-to-deploy: how long it takes to move a new automation from concept to production — a proxy for organizational maturity and process discipline
- Compliance audit pass rate: whether automation audit trails are complete and retrievable when needed
Measuring What Matters: ROI Frameworks and KPIs
One of the persistent failures in hyperautomation programs is measurement. Teams deploy automations, declare success based on the fact that the bot is running, and then struggle six months later to explain the business value when budget reviews come around. A rigorous measurement framework is what separates programs that sustain investment from those that get quietly defunded.
The Three Value Categories
Hyperautomation value breaks down into three categories, and all three should be tracked:
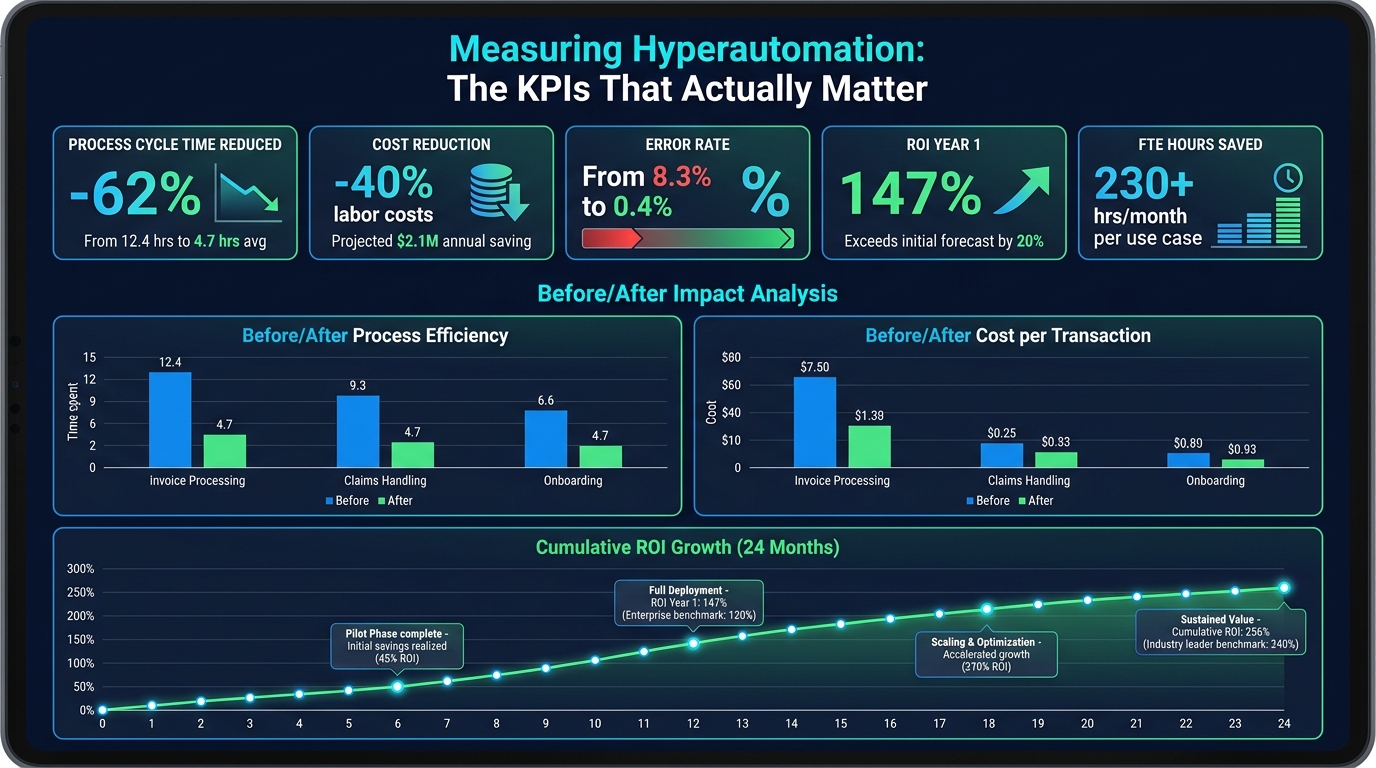
Efficiency value is the most straightforward: time saved, labor cost avoided, and cycle time reduced. This is the category that gets attention in early business cases — “this automation saves 230 hours per month across the accounts payable team.” It’s real, it’s measurable, and it should be tracked against the pre-automation baseline with discipline.
Quality value is often underestimated: error rates reduced, rework eliminated, compliance incidents avoided. In industries where a single regulatory failure can result in seven-figure penalties, the quality value of automation often exceeds the efficiency value — but it’s harder to quantify because it’s measuring things that didn’t happen. The framework here is to baseline error rates before automation, track them after, and apply the cost-per-error metric (including remediation time, rework, and any regulatory exposure) to the error reduction delta.
Strategic value is the hardest to measure but often the most significant: faster decision cycles, improved customer experience from faster order processing or issue resolution, better data quality enabling better business intelligence, and risk reduction from improved audit trails. These require longer observation windows and often need to be captured through proxy metrics (customer satisfaction scores, DSO improvement, audit finding rates) rather than direct measurement.
ROI Benchmarks From Enterprise Implementations
The numbers that appear consistently across enterprise hyperautomation implementations:
- First-year ROI: 30-200%, depending on process complexity and automation scope. Higher ROI cases typically involve high-volume processes with significant manual labor content and clear error costs.
- Cost reduction: 10-50% across automated process areas, with the higher end of the range typically in Finance and HR back-office functions
- Labor cost specifically: organizations implementing enterprise-wide hyperautomation programs report labor cost reductions of approximately 40% in affected functions
- Processing time: 60-80% reduction in total process cycle time for fully automated cross-department workflows (though the actual work steps may only account for 15-20% of the original time — the rest is eliminated waiting and handoff time)
- Error rates: reduction from typical manual-process error rates of 5-15% to automated-process rates below 1%
These are real enterprise benchmarks — not theoretical projections. But they require well-designed implementations with proper governance and measurement discipline. Organizations that deploy automation reactively, without process mining, proper architecture, or CoE governance, typically achieve a fraction of these results and struggle to sustain them.
The Governance Gap: What Most Organizations Get Badly Wrong
Beyond CoE structure, there are several specific governance failures that appear with striking regularity in hyperautomation programs — and understanding them is as practically useful as understanding best practices.
Shadow Automation
Low-code and no-code platforms have democratized automation development. Business users can now build workflows in tools like Power Automate, Zapier, or vendor-embedded automation features without writing a line of code. This is genuinely valuable — it brings automation capability to people who understand the processes best. But it also creates a shadow automation ecosystem that the CoE doesn’t know about, hasn’t reviewed for security or compliance, and can’t maintain or integrate with enterprise-wide workflows.
The governance response isn’t to ban citizen development — that will simply drive it further underground. It’s to create a sanctioned citizen development program: a library of approved tools, training for business developers, a lightweight review process for business-built automations that flags compliance or integration risks, and a registration requirement that puts all automations into the process registry.
Over-Automation Without Human Judgment
The urgency to automate can push organizations toward automating decisions that genuinely benefit from human judgment. A credit approval workflow that’s fully automated might handle 80% of cases well — but the 20% that represent genuine credit risk may be precisely the cases where the automated model’s training data doesn’t apply. Removing human review from those cases in the name of efficiency can create material financial risk that takes time to surface.
The principle is: automate the execution, keep humans in the decisions where context, ethics, or business relationship factors matter. This is not a technical limitation — it’s a deliberate design choice that should be made explicitly, with input from the business owners of each workflow, not defaulted to by the automation team.
Brittle Integrations
Cross-department workflows depend on integrations between systems that are maintained by different teams, on different release cycles, with different upgrade schedules. An integration that works today may break when the HR system upgrades its API, when the ERP vendor changes a data schema, or when IT migrates a service to a new platform. Without integration resilience built into the architecture — error handling, retry logic, fallback paths, and change notification protocols — cross-department hyperautomation programs become fragile in proportion to their complexity.
The architectural best practice is to build integrations through an integration layer (an API management platform or enterprise service bus) rather than point-to-point connections. Changes to any single system are then handled at the integration layer without requiring changes to every automation that depends on that system.
Implementation Roadmap: Building in 90-Day Sprints
Hyperautomation at enterprise scale is a multi-year journey, not a project. But multi-year journeys get derailed when they don’t produce visible business value early enough to sustain organizational commitment. A sprint-based roadmap that balances quick wins with structural investment is consistently more successful than big-bang implementation approaches.
Days 1-30: Discovery and Foundation
The first month is not about deploying automation. It’s about understanding what you’re working with and establishing the governance structures that will determine whether the program scales or fragments.
Deploy process mining across your three or four highest-priority cross-department workflows. Don’t start with the processes you think are most broken — start with the ones that have the most business impact when they work well, because those are where automation value will be most visible and best sustained. Let the mining run for at least two to three weeks before drawing conclusions; short observation windows miss seasonal patterns and exception peaks.
Simultaneously, establish or formalize your CoE structure. Define the governance model, assign ownership, set up the process registry, and — critically — establish the standards that all automations will be required to meet before going to production. This last point is where many organizations skip ahead and pay for it later.
Days 31-60: First Automation Sprint
Select two or three high-impact, relatively contained automation targets identified by process mining. These should be processes where you have complete data on the current state (from the mining), clear agreement across departments on what the automated state should look like, and enough transaction volume to generate measurable results within thirty days.
Build and deploy these automations in full compliance with the CoE standards established in month one. Measure against your pre-automation baselines from day one of go-live. Make the results visible — share the metrics with the business stakeholders who will either champion or undermine the broader program based on what they see in these early implementations.
Days 61-90: Integration and Scale
With two or three proven automations in production and measurable results in hand, begin the integration work that connects these automations into the first cross-department workflow chain. This is where the real complexity and the real value both emerge. A single automated invoice processing step is useful; an integrated procure-to-pay workflow that coordinates across Procurement, Finance, and Compliance is transformative.
Use the results from the first sprint to refine your process mining framework and begin identifying the next tier of automation targets. At the same time, run your first citizen development training cohort — equipping business-side employees to contribute to automation development within the governance framework you’ve established.
Months 4 Through 12: Expanding the Connected Enterprise
By the end of the first quarter, you should have measurable results, an established governance structure, a process registry with real entries, and organizational knowledge of how to move from discovery to production. The subsequent three quarters are about systematically expanding automation coverage across the priority cross-department workflows — hire-to-retire, order-to-cash, procure-to-pay, and IT service management — while beginning to evaluate where agentic AI can add value on top of the foundational automation layer.
The 12-month target for a well-resourced program: 30-40% of identified cross-department handoffs automated, process mining running continuously across all major workflows, CoE established with active governance, and a measurable business case that justifies the Year 2 investment in AI and agentic orchestration layers.
The Seam Problem, Solved: What the Connected Enterprise Actually Looks Like
It’s worth painting a concrete picture of what organizations are working toward, because the incremental nature of implementation can obscure the destination.
In a genuinely connected enterprise, a customer signs a contract and the entire organization responds in orchestrated sequence: the CRM triggers order processing, which triggers inventory reservation and fulfillment scheduling, which triggers invoice generation on delivery confirmation, which triggers the collections workflow if payment isn’t received within terms. The customer service team, in real time, can see exactly where any order is in its lifecycle without calling anyone or querying a different system. The CFO’s working capital dashboard updates continuously as orders move through the cycle.
A new employee joins and finds a fully configured work environment waiting for them. They have the system access their role requires — no more, no less — and their payroll, benefits, and compliance records are already in order. Their manager didn’t need to submit five separate requests to five separate departments.
A supplier sends an invoice in a non-standard format. AI extracts and validates the data, performs three-way matching, identifies a small discrepancy, routes it to the purchasing manager with full context, receives approval, updates both the ERP and the supplier portal, and schedules payment — all without a single human touching a keyboard except to approve the one genuinely ambiguous decision.
This isn’t a vision of a fully automated organization — humans remain central, focused on the decisions and relationships that benefit from human judgment. What’s different is that the operational machinery surrounding those decisions works without friction, without handoff delays, and without the data inconsistencies that make good decisions harder to make.
The Competitive Reality
The organizations that build connected operational infrastructure in 2026 will have structural advantages over those that don’t — not just in cost efficiency, but in speed, data quality, customer experience, and the ability to deploy AI meaningfully. AI systems are only as good as the data and processes they operate on. Organizations with fragmented, manually-mediated workflows will find that their AI investments consistently underperform because the data feeding them is incomplete, inconsistent, and stale.
The hyperautomation market growing toward $306 billion by 2035 isn’t just a market trend — it’s a signal about where operational competitive advantage is moving. Early movers in cross-department workflow integration are compounding advantages in data quality, decision speed, and organizational capability that will be difficult for later adopters to close.
Conclusion: Start with the Seams
The most important insight from enterprises that have built successful hyperautomation programs is also the most counterintuitive: the technology is rarely the hard part. The technology to close most cross-department workflow gaps exists today, at accessible price points, with mature tooling and extensive implementation experience in the vendor ecosystem.
The hard part is organizational. It’s agreeing across departments on what the right process looks like before automating it. It’s building governance structures with real authority before automation complexity outpaces governance capacity. It’s measuring business outcomes rather than automation activity. It’s keeping humans in the decisions that require human judgment while removing them from the execution steps that don’t.
The organizations that have closed the seams — that have moved from automation islands to genuinely connected workflows — share a common starting point: they stopped looking at individual departments and started looking at the handoffs between them. That’s where the time goes. That’s where the errors concentrate. That’s where the compliance exposure lives.
Start with the seams. Map them with process mining before you touch a line of code. Build your governance framework before your first cross-department automation goes live. And measure everything against baselines so that business value stays visible throughout a journey that will take years to complete.
The connected enterprise isn’t a destination you arrive at. It’s a capability you build, sprint by sprint, seam by seam. The organizations that start now will be the ones setting the operational benchmark that every other enterprise will be measured against in the years ahead.
Key Takeaways
- Audit your seams first: The value in hyperautomation lies at departmental handoffs, not inside individual departments. Process mining is the essential first step.
- Build governance before scale: A CoE with real authority and a process registry is a prerequisite for cross-department automation that stays connected, compliant, and maintainable.
- Layer your technology stack: RPA → process intelligence → AI decision-making → agentic orchestration. Each layer needs the one below it to function well.
- Measure outcomes, not activities: Cycle time, error rate, and cost per transaction — not number of bots deployed — are the metrics that justify continued investment.
- Keep humans in the right decisions: Automate execution, preserve human judgment for genuinely complex or ethically significant decisions. This is a governance choice, not a technical limitation.
- Sprint, don’t big-bang: Ninety-day sprint cycles that deliver visible business value while building long-term infrastructure sustain organizational commitment across a multi-year journey.