In April 2025, a Zoox robotaxi collided with another vehicle at 43 miles per hour. The cause wasn’t a sensor failure, a software bug in the traditional sense, or a freak edge case. The autonomous decision system made a judgment call about the situation in front of it — and that judgment was wrong. The recall that followed wasn’t just a product issue. It was an accountability crisis in a system that had no clear human to blame.
That story is about to become far more familiar in enterprise settings. Not with robotaxis necessarily, but with the autonomous AI systems that are right now being wired into supply chains, financial compliance workflows, patient scheduling systems, and procurement engines. Gartner forecasts that by 2028, 33% of enterprise software will incorporate agentic AI — systems capable of making decisions and executing actions with minimal human involvement. More immediately, over 40% of these projects are predicted to fail by 2027, not because the AI wasn’t capable, but because the organizations deploying them hadn’t built the architecture to support autonomous decision-making responsibly.
This isn’t a guide about whether AI can make good decisions. The research on that is increasingly clear: in narrow, well-defined domains, it often can. This is a guide about the harder problem — how to build the decision architecture, accountability structures, and governance layers that let autonomous AI systems operate reliably in production, at scale, without creating organizational liability black holes.
The distinction matters. Most implementation guides start with capabilities. This one starts with consequences — because that’s where every serious deployment ultimately ends up.
What “Autonomous” Actually Means — and the Spectrum Nobody Talks About Honestly

The word “autonomous” has done a lot of damage in boardroom presentations. When executives hear it, many imagine a binary: either the AI decides, or a human decides. In reality, autonomy exists on a spectrum — and where your system sits on that spectrum has profound implications for governance, liability, and design.
Multiple frameworks have emerged in 2026 to formalize these levels. The most widely cited define between four and six tiers, but the underlying logic is consistent across all of them:
The Six Levels of AI Decision Autonomy
L0 — No Autonomy: The AI generates output, but a human executes every action. Think of a report generator or a dashboard that surfaces data. The human reads it, interprets it, and acts. The AI is purely advisory with zero execution capability.
L1 — Assisted: The AI makes recommendations and can pre-populate actions, but every individual action requires explicit human approval before execution. A content moderation system that flags posts for human review lives here. Coding assistants that suggest completions but wait for the developer to accept them live here.
L2 — Supervised: The AI executes actions within a clearly defined boundary. Humans monitor outputs and intervene when exceptions arise. An inventory reordering system that can place orders up to $5,000 without approval, but requires sign-off above that threshold, is operating at L2.
L3 — Conditional Autonomy: The AI handles complex, multi-step decision sequences within an established policy framework. Humans review outputs periodically rather than per-decision. A financial compliance agent that autonomously reviews contracts, flags issues, proposes resolutions, and queues them for batch human review operates here.
L4 — High Autonomy: The AI acts independently across broad domains and only escalates genuinely novel or high-consequence situations. Humans set strategic objectives and review outcomes, but rarely touch individual decisions. JPMorgan’s agentic compliance systems operate in this zone for certain process types.
L5 — Full Autonomy: The AI sets its own goals, resources itself, and executes without human intervention except for hard system stops. In enterprise settings in 2026, true L5 deployment is largely theoretical for any consequential domain. Most organizations claiming L5 are actually running L4 with minimal oversight — which is a problem.
The Stakes Mapping Error
The most common mistake organizations make is applying the same autonomy level to decisions with wildly different consequence profiles. A system that’s appropriate at L3 for approving expense reports under $500 is catastrophically wrong at L3 for authorizing vendor contracts worth six figures. The rule that experienced architects follow: as decision consequence increases, required autonomy level decreases. High-stakes decisions should always trend toward lower autonomy levels, not higher ones, regardless of how capable the underlying model appears to be.
Before any implementation decision gets made, every decision type your system will handle needs to be explicitly mapped against this spectrum — with the mapping signed off by both technical leads and business stakeholders, not just engineers.
The Four Structural Failure Modes You Need to Design Around — Not React To
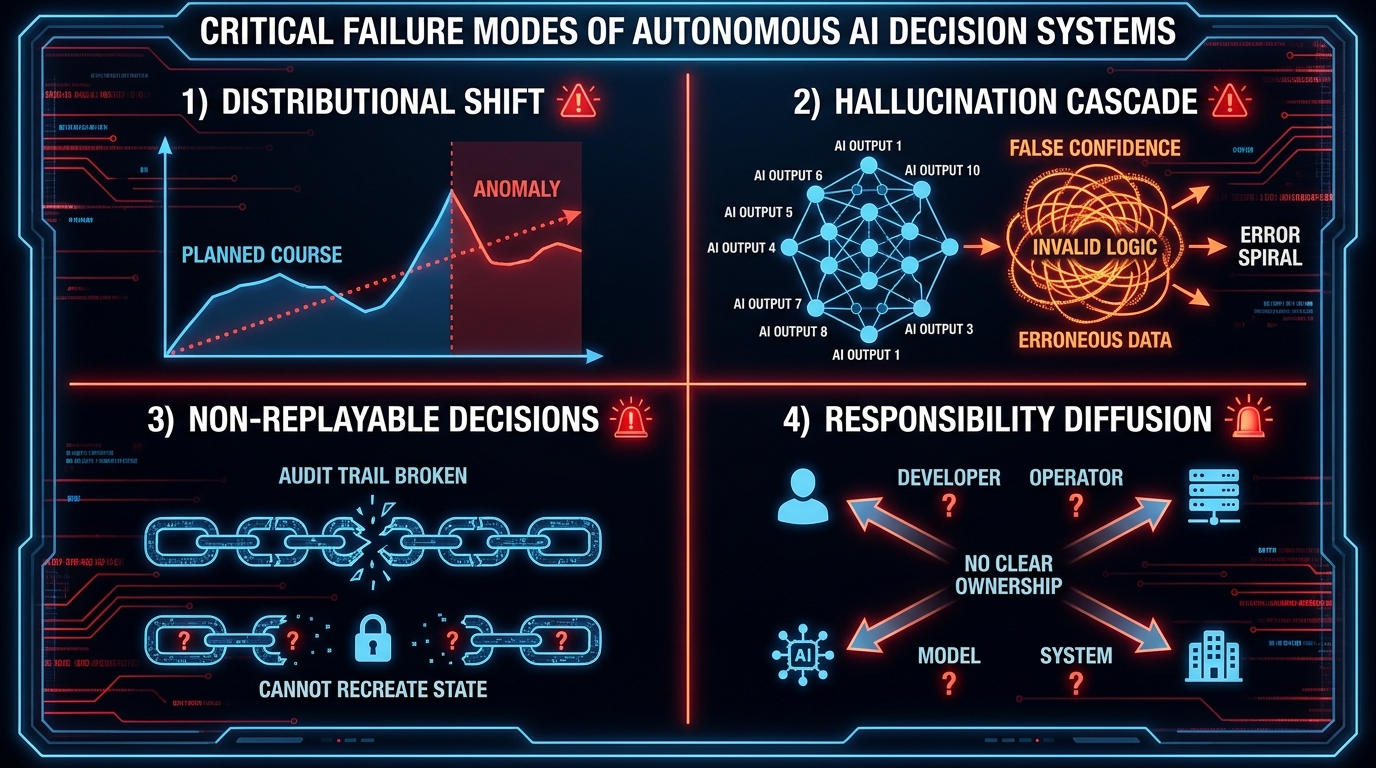
Autonomous AI systems fail in patterns. Studying those patterns before you design your system is not pessimism — it’s the only engineering approach that produces systems that survive contact with real-world conditions. Here are the four structural failure modes that account for the majority of autonomous AI decision system failures in production:
Failure Mode 1: Distributional Shift and Model Drift
Models are trained on historical data that reflects a particular slice of reality. The moment that reality changes — new customer behavior, a shift in market conditions, a regulatory change, a supply chain disruption — the model’s assumptions begin to erode. The insidious part: this erosion is typically silent. The system keeps operating. Confidence scores may stay high. Decisions keep getting made. But they’re increasingly wrong decisions, based on a model of the world that no longer matches the world.
In financial services, a credit risk model trained on pre-2020 data made systematically different assumptions about employment stability than post-pandemic reality warranted. In supply chain, demand forecasting models trained on stable periods dramatically underestimated volatility during subsequent disruptions. The answer isn’t to retrain constantly (though monitoring for drift is essential). The answer is to design explicit drift-detection triggers that automatically reduce the system’s autonomy level when statistical drift is detected — pushing decisions that would normally be auto-executed toward human review queues until the model is validated against current conditions.
Failure Mode 2: Hallucination Cascades in Multi-Step Decisions
In a single-step AI interaction, a hallucination — a confident but factually wrong output — is a contained problem. In an autonomous decision system that executes multiple sequential actions, a hallucination in step one becomes the input assumption for step two. That compound error then feeds step three. By step six or seven in a complex agentic workflow, the system may be executing actions based on premises that bear no relationship to reality, with no human having reviewed any of them.
This cascade failure mode is why agentic system designers insist on what are called “verification checkpoints” — mandatory validation gates at defined intervals in multi-step workflows where outputs are cross-checked against source data before the next step proceeds. The computational cost of these checkpoints is real. The cost of a hallucination cascade that authorizes a $2 million purchase order based on fabricated supplier terms is higher.
Failure Mode 3: Non-Replayable Decisions and the Audit Crisis
Regulatory environments increasingly require that consequential automated decisions be explainable and auditable — meaning you need to be able to reconstruct exactly what data the system saw, what logic it applied, and why it made the choice it did. Many autonomous AI systems, particularly those built on large language model foundations, produce probabilistic outputs that cannot be replayed deterministically. Run the same input through the system twice and you may get different decisions. That’s acceptable in a generative content context. It’s potentially illegal in a credit decisioning, healthcare triage, or financial compliance context.
Designing for auditability means explicitly logging every input, every intermediate reasoning step, every confidence score, and every output — in a format that can be presented to a regulator who may not be technical. This isn’t optional infrastructure. Under the EU AI Act (which enters full enforcement for high-risk systems in August 2026), conformity assessments require documented human oversight mechanisms and technical records of decision logic. Organizations that built their agentic systems without this layer are now racing to retrofit it — an expensive and error-prone process.
Failure Mode 4: Responsibility Diffusion — The Accountability Black Hole
When an autonomous AI system makes a wrong decision, there is almost always a moment where multiple parties — the AI vendor, the systems integrator, the internal team that deployed it, the business unit that approved the use case, the executive who set the risk parameters — all look at each other. Analysis of AI accountability failures consistently identifies what researchers call “responsibility gaps”: no single party feels fully responsible because each can point to some other party’s contribution to the outcome.
This isn’t a hypothetical risk. The Zoox case, financial algorithm trading incidents, and multiple healthcare AI diagnostic failures have all produced the same dynamic. The solution isn’t to find someone to blame — it’s to design accountability into the system architecture before deployment, so that when something goes wrong, the chain of responsibility is explicit, documented, and auditable. This is covered in depth later in this guide, but the critical point is that responsibility diffusion is a design failure, not a legal technicality to work out after the fact.
Building the Decision Architecture: Before You Write a Single Line of Code
The most common mistake in autonomous AI deployment is treating it as a software engineering problem. It isn’t — or rather, it isn’t only that. Before any code gets written, any model gets selected, or any vendor gets evaluated, a rigorous decision architecture process needs to happen. This process has three components:
Step 1: The Decision Taxonomy Audit
Start by cataloging every category of decision your system will make or influence. For each decision type, document: the trigger that initiates it, the data inputs it requires, the action it produces, the reversibility of that action (can a bad decision be undone?), the consequence magnitude if wrong, and the current frequency of this decision type.
This audit typically takes two to four weeks for a complex enterprise system and involves both technical and business stakeholders. The output isn’t a design document — it’s a prioritization map. You will discover that the vast majority of decision volume concentrates in a small number of high-frequency, low-consequence categories. These are your starting points for autonomous deployment. The low-frequency, high-consequence decisions — the ones that feel most impressive to automate — are the ones to approach last, if at all.
Step 2: Consequence-Frequency Mapping
Plot every decision type on a two-axis grid: frequency (how often this decision type occurs) on one axis, and consequence magnitude (how bad can a wrong decision be) on the other. This creates four quadrants that directly map to implementation strategy:
- High frequency, low consequence: Strong candidates for L3-L4 autonomy. Routine approvals, ticket routing, initial document classification, threshold-based alerts. Start here.
- High frequency, high consequence: Candidates for L2 with robust confidence thresholds. Frequent but costly mistakes demand guardrails at scale.
- Low frequency, low consequence: L2-L3 is appropriate. These decisions don’t demand high investment in oversight infrastructure.
- Low frequency, high consequence: L0-L1 maximum. No autonomous execution should happen in this quadrant without extremely mature system performance data. This is where the most vocal internal champions push hardest — and where the most catastrophic failures originate.
Step 3: Reversibility Classification
For every decision type in your taxonomy, explicitly classify it as reversible, partially reversible, or irreversible. This classification should act as a hard constraint on autonomy level. An autonomous system sending an internal email notification (reversible: send a correction) can operate at higher autonomy than a system releasing payment to a vendor (partially reversible: takes days), which must operate at lower autonomy than a system deleting customer data (irreversible). The engineering team rarely makes this judgment well in isolation — it requires legal, operations, and business stakeholder input. Build those conversations into the pre-implementation process.
Confidence Thresholds and Escalation Paths: Engineering Decisions That Actually Protect You
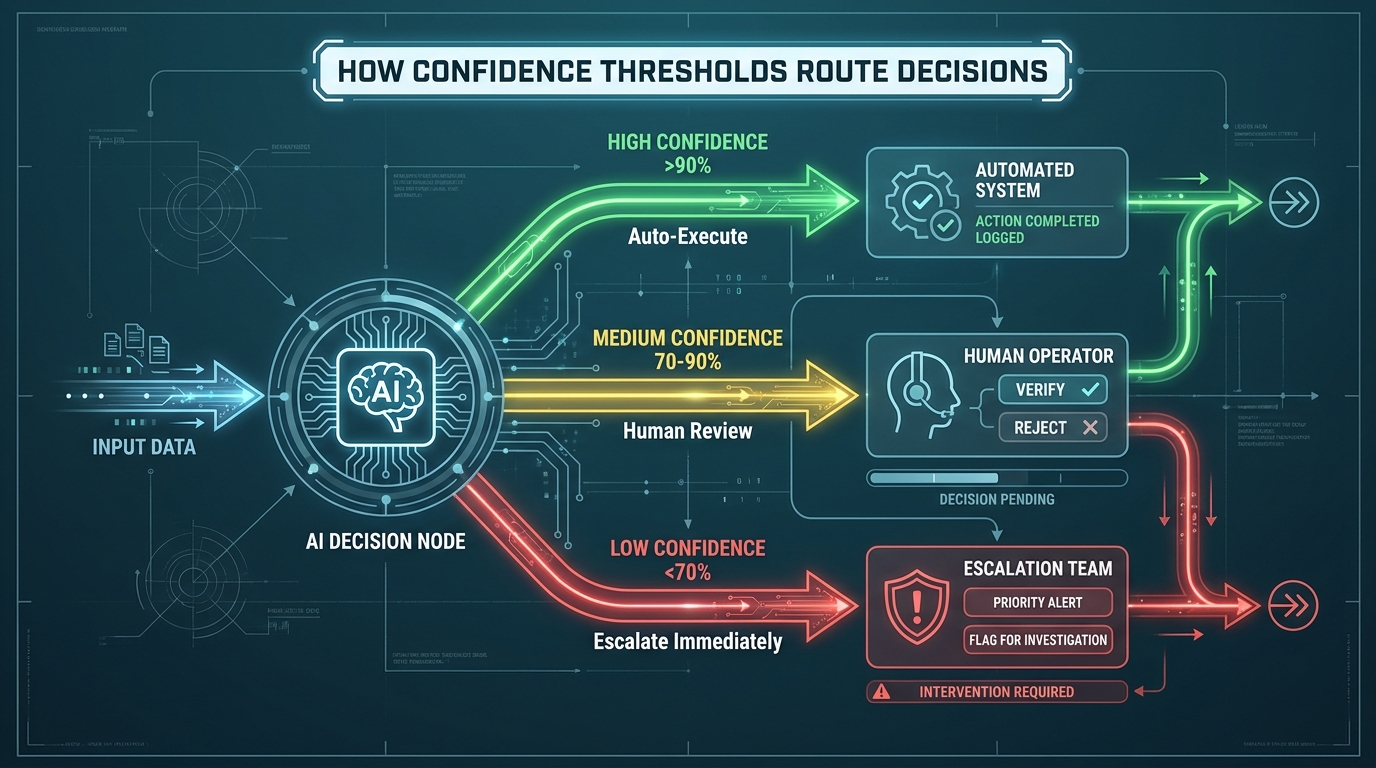
Once decision taxonomy and autonomy levels are established, the engineering layer that actually enforces those decisions is confidence threshold architecture. This is one of the most underbuilt components in most autonomous AI systems — teams spend enormous effort on the model and almost none on the routing logic that determines when the model’s output should be trusted enough to act on.
How Confidence Scoring Works in Practice
Modern AI systems can be instrumented to produce confidence scores alongside their primary outputs — numerical estimates of how certain the model is about its decision. A lead qualification agent might score a contact as “high probability conversion: 0.94.” A compliance review agent might flag a contract clause with “potential violation: 0.71 confidence.” These scores are outputs to be treated as data, not as final verdicts.
The implementation approach that works in production — validated across multiple enterprise deployments — uses three-tier routing:
- Above the high threshold (e.g., >90%): Auto-execute. Log the decision, continue the workflow. No human gate.
- Between thresholds (e.g., 70-90%): Queue for human review. The action is not taken until a designated reviewer approves, rejects, or modifies the AI’s recommendation within a defined SLA window.
- Below the low threshold (e.g., <70%): Immediate escalation. The case bypasses the standard review queue and gets flagged as requiring expert attention. The AI’s output is surfaced as context, not as a recommendation.
The specific threshold values are not universal — they need to be calibrated against your organization’s false-positive tolerance, the cost of human review time, and the consequence magnitude of the decision type. A payment release system might set the auto-execute threshold at 97%. A content routing system might set it at 85%. These numbers require empirical calibration during a controlled pilot phase, not pre-deployment guesswork.
Hard Guardrails vs. Soft Guardrails
Confidence thresholds are soft guardrails — they influence routing but can theoretically be overridden or bypassed. Hard guardrails are absolute constraints that the system cannot bypass regardless of confidence score. Examples include: never release payments over $50,000 without dual human sign-off regardless of AI confidence; never modify records in a regulatory-compliant system without generating an audit log entry; never take irreversible actions on data marked as PII without explicit authorization.
Hard guardrails should be implemented at the infrastructure level — not as prompts or instructions to the AI model, but as enforcement logic in the surrounding system that the model cannot influence. This is a critical distinction. Prompt-based instructions to “never do X” can be bypassed by sufficiently clever prompting, adversarial inputs, or model updates. Infrastructure-level hard stops cannot.
The RACI Model for AI Decision Ownership
Every autonomous decision type needs an explicit ownership assignment. The framework that has emerged in 2026 enterprise deployments applies a RACI matrix specifically to AI decision architecture:
- Accountable (A): The AI Product Owner — owns the definition of escalation thresholds and is organizationally answerable for the system’s decision quality. One person, not a committee.
- Responsible (R): AI Operations — monitors decision patterns, detects anomalies, adjusts threshold settings based on observed performance data.
- Consulted (C): Business domain experts — provide context on consequence magnitude and acceptable error rates for each decision type.
- Informed (I): Human supervisors who handle escalated decisions — receive escalations and need context about why a case was flagged, not just the case itself.
The absence of clear RACI ownership is one of the strongest predictive indicators that an autonomous AI system will fail in production. When something goes wrong — and at scale, something always does — organizations without clear ownership enter a blame distribution cycle that delays remediation and deepens the damage.
What’s Actually Working: Real-World Deployments and the Outcomes Behind the Numbers
Behind the projections and frameworks, there are organizations that have made autonomous AI decision-making work at scale. What they have in common is more instructive than the individual outcomes.
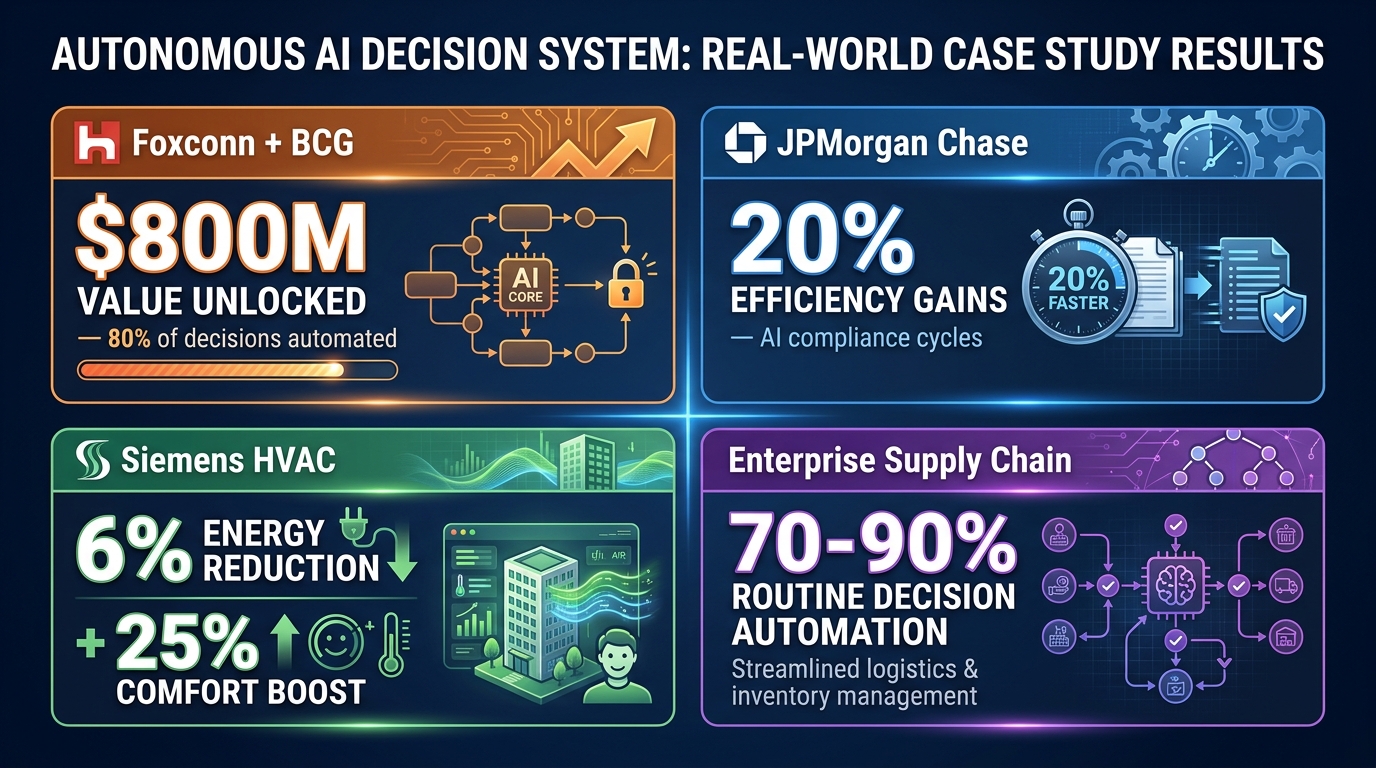
Foxconn and BCG: Manufacturing Decision Automation at Scale
Foxconn, in partnership with BCG, deployed an AI agent ecosystem that automates approximately 80% of its operational decision-making processes across manufacturing workflows. The reported value unlock is approximately $800 million — a figure that covers reduced defect rates, faster production adjustments, optimized logistics scheduling, and reduced managerial overhead on routine operational decisions.
What made this work wasn’t the sophistication of the individual AI models. Foxconn’s manufacturing environment generates extraordinarily structured, high-quality data from its production lines. The decision types being automated — quality threshold assessments, production scheduling adjustments, parts ordering triggers — are high-frequency, moderate-consequence, and historically well-understood. The AI was given decision authority in domains where human performance benchmarks were already well-established, making model validation straightforward.
JPMorgan Chase: Compliance at L3-L4 Autonomy
JPMorgan’s deployment of agentic AI for legal and compliance processes targets one of the most consequential decision environments in financial services. The system autonomously plans review workflows, detects potential compliance issues, replans when new information surfaces, and delivers final outputs — with reported efficiency gains of up to 20% in compliance cycle times.
The critical detail is that JPMorgan did not apply L4 autonomy to the compliance decisions themselves — the final sign-off on regulatory findings still involves human review. What operates autonomously is the orchestration of the review process: data gathering, cross-referencing against regulatory frameworks, preliminary flagging, and workflow routing. The AI handles the cognitive labor of preparation; humans own the final determination. This is a sophisticated and deliberate autonomy architecture, not a binary “AI handles compliance” deployment.
Siemens: Physical World Autonomous Control
Siemens deployed an autonomous AI system to control HVAC infrastructure in commercial buildings in Switzerland. The system independently adjusts heating, ventilation, and air conditioning parameters based on occupancy data, weather forecasts, energy pricing signals, and comfort metrics. Outcomes include a 25% improvement in occupant comfort scores and over 6% reduction in energy consumption.
This deployment illustrates an important principle: physical world autonomous control often has cleaner feedback loops than organizational decision-making. The HVAC system receives continuous, measurable feedback (temperature, energy draw, occupancy) that makes model performance evaluation immediate and objective. Organizations implementing autonomous AI in less measurable domains — strategic planning, talent decisions, customer relationship management — face the harder challenge of defining feedback signals that are meaningful and timely enough to support model validation.
Healthcare: Patient Flow Coordination
Across multiple health systems, AI agents are now managing patient flow decisions: scheduling coordination, initial triage routing, bed assignment, and care pathway recommendations. The systems operating most successfully are those that placed autonomous execution in administrative coordination decisions (scheduling, routing, resource allocation) while keeping clinical decisions firmly in human hands.
The lesson from healthcare is the clearest articulation of the framework this guide advocates: autonomous AI performs well when it is given precise, well-scoped decision authority in domains where its performance can be validated continuously. It creates liability and patient risk when autonomy boundaries are drawn around domains where the feedback loop is slow, ambiguous, or where errors have irreversible consequences.
The Governance Layer That Actually Scales — and the Regulations You Can’t Ignore
Governance frameworks for AI have existed in some form since the first machine learning systems reached enterprise deployment. What’s different in 2026 is that governance is no longer voluntary guidance — it’s enforcement infrastructure with real legal teeth, and the organizations that treated it as optional are now facing compliance timelines they cannot meet without significant remediation effort.
The EU AI Act: August 2026 Enforcement and What It Actually Requires
The EU AI Act’s major enforcement provisions for high-risk AI systems take effect in August 2026. For organizations operating autonomous AI decision systems that fall into regulated categories — which include systems used in critical infrastructure, employment decisions, credit scoring, educational assessment, law enforcement, and healthcare — the requirements are explicit and non-negotiable:
- Technical documentation that describes the system’s intended purpose, components, logic, and performance characteristics
- Human oversight mechanisms that can actually intervene in production decisions — not just theoretical overrides, but tested, operational controls
- Conformity assessments conducted before deployment, not after
- Post-market monitoring plans that define how model performance will be tracked and how drift will be detected and addressed
Colorado’s AI Act, which takes effect June 30, 2026, adds state-level requirements for consequential decisions affecting Colorado residents — specifically around transparency and opportunity for consumers to appeal automated decisions. Singapore’s updated Model AI Governance Framework, revised specifically for agentic AI in 2026, mandates risk assessments pre-deployment, technical safeguards, and explicit human accountability assignment.
Human-in-the-Loop vs. Human-on-the-Loop: A Distinction That Matters Legally
“Human oversight” is a phrase that gets used loosely in AI governance conversations in ways that create false compliance confidence. There is a meaningful operational and legal difference between two oversight models:
Human-in-the-Loop (HITL): A human reviews and approves every individual decision before it is executed. The human is a gate in the decision flow. This model provides maximum oversight but doesn’t scale for high-frequency decisions. It’s appropriate for L1-L2 autonomy systems handling consequential decisions.
Human-on-the-Loop (HOTL): The system executes decisions autonomously, but a human monitors the decision stream and can intervene to halt or reverse decisions. The human is a supervisor, not a gate. This model scales to high-frequency decisions but requires robust monitoring infrastructure and clear intervention protocols — including SLA commitments for how quickly a human can actually respond to anomalies.
The EU AI Act’s requirement for human oversight that “can intervene in production” is deliberately ambiguous on which model is required — it specifies that the oversight mechanism must be functional and tested, not just documented. Organizations claiming HOTL compliance must demonstrate that their monitoring systems actually detect anomalies in time for intervention to prevent harm. This is a much higher bar than simply having a dashboard that a human theoretically monitors.
Building an AI Governance Structure That Functions Operationally
Governance structures that work at scale in 2026 share a three-body architecture:
AI Steering Committee: Makes strategic decisions about AI investment priorities, sets organizational risk appetite for autonomous AI deployment, approves deployments that exceed defined consequence thresholds (often set at $100,000+ decisions or decisions affecting personal data). Meets quarterly or when triggered by significant incidents.
AI Operations Function: The operational layer responsible for model performance monitoring, drift detection, threshold calibration, and escalation management. This is a standing function, not a project team — it requires dedicated ongoing staffing proportional to the scale of autonomous AI deployment.
Domain Review Boards: Business-unit-specific review bodies for the highest-consequence autonomous decisions in each domain. Legal reviews automated contract analyses. Clinical teams review AI-generated patient pathway recommendations. Finance approves autonomous trading or payment logic changes. These boards sit between the operational function and the steering committee in the governance hierarchy.
Organizational Readiness: The 6-Pillar Assessment Before You Commit
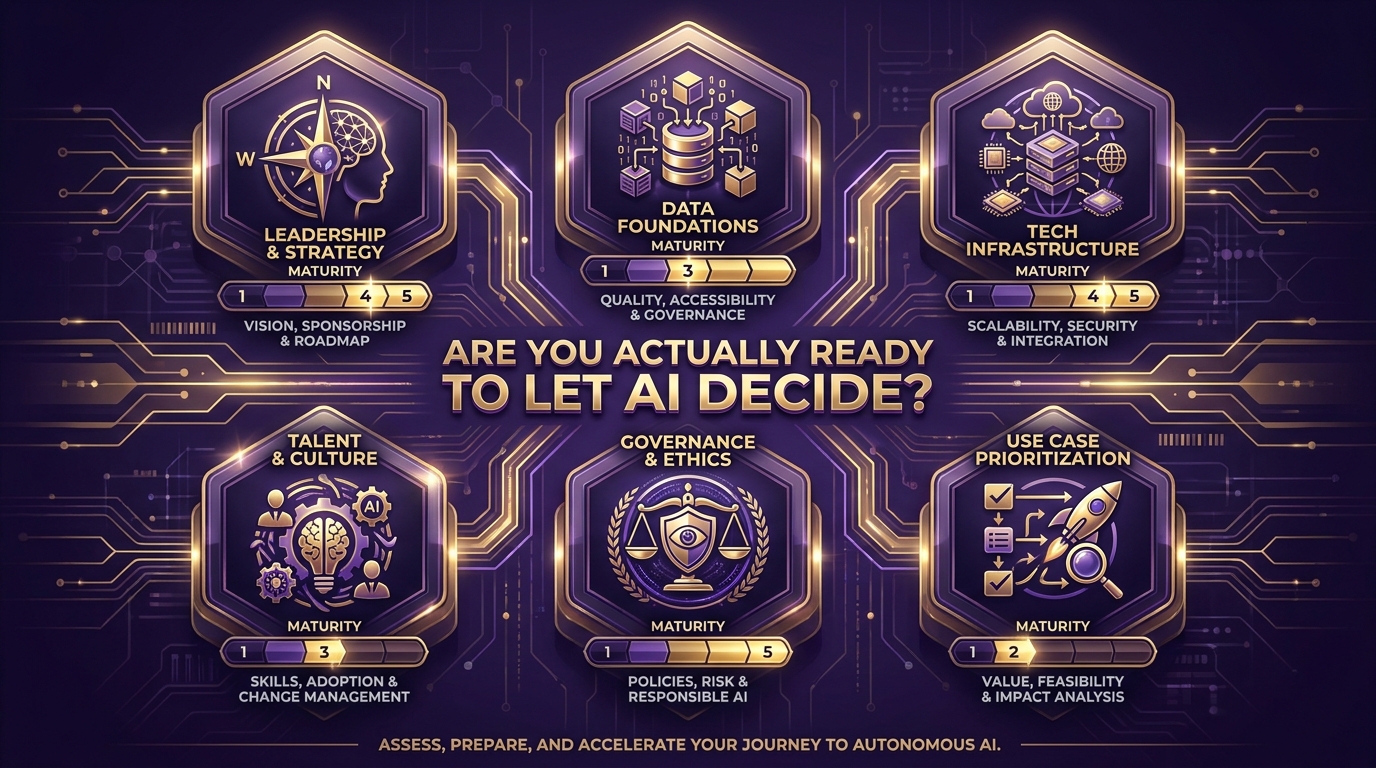
Only 33% of companies have successfully scaled AI beyond pilots. The failure isn’t technical — the underlying models are increasingly capable. The failure is organizational. Before committing to an autonomous AI decision system implementation, evaluate your organization honestly across six dimensions:
Pillar 1: Leadership and Strategic Clarity
Do you have executive sponsorship that extends beyond enthusiasm? Specifically: has a named executive accepted accountability for the system’s decisions and outcomes? Is there a documented business case with defined KPIs that will determine whether the system is working? Are risk tolerance levels explicitly stated in writing — not implied by the absence of objection?
The most common leadership gap isn’t lack of support for AI. It’s lack of willingness to own the downside of AI decisions. If your sponsors are enthusiastic about the upside but haven’t agreed to be accountable for the errors, the governance structure is already broken before implementation begins.
Pillar 2: Data Foundations
Data quality is the top barrier to AI implementation cited by 45% of enterprise AI leaders. For autonomous decision systems specifically, the data requirements are more demanding than for advisory AI, because errors don’t get caught by a human reviewer before they cause harm. Assess: Is the data your system will consume consistently structured, labeled, and validated? Is there a data governance process that catches quality degradation before it reaches the model? Are data provenance and lineage tracked — so that when a decision is audited, you can trace exactly what data informed it?
If the honest answer to any of these is “no” or “sometimes,” that’s a Phase 0 item — a prerequisite to be addressed before autonomous AI implementation begins, not alongside it.
Pillar 3: Technology Infrastructure
86% of CIOs report their networks are unprepared for the integration demands of agentic AI deployment. The infrastructure requirements for autonomous decision systems are substantially more demanding than for standard AI deployments because they include real-time data ingestion, low-latency execution environments, audit logging at scale, monitoring dashboards, and secure inter-system integration. Assess your current infrastructure against these requirements honestly — not against what your vendors say is easy to integrate.
Pillar 4: Talent and Culture
Who in your organization understands both the technical architecture of autonomous systems and the business context of the decisions being automated? This intersection — people who can reason about model behavior and decision consequence simultaneously — is where the talent shortage is most acute in 2026. If this expertise doesn’t exist internally, it needs to be built or sourced before deployment, not during it.
Culture matters equally. Organizations with cultures of blame rather than learning will suppress the reporting of AI errors — which is operationally catastrophic for systems that depend on continuous feedback to maintain calibration. An environment where the first instinct when the AI makes a wrong call is to hide it rather than investigate it is an environment where model drift will go undetected until it becomes a crisis.
Pillar 5: Governance and Ethics Readiness
Fewer than 20% of organizations have mature AI governance frameworks in place. This pillar asks: Do you have a documented process for approving autonomous AI deployments? Is there a defined incident response protocol for when the system makes a materially harmful decision? Have you conducted a bias assessment for the decision types the system will handle? Have your legal and compliance teams reviewed the implementation against applicable regulations — specifically including EU AI Act requirements if you have EU operations?
Pillar 6: Use Case Prioritization Discipline
The final readiness question is the one most organizations skip: have you actually prioritized the right use cases to start with, based on technical feasibility, organizational readiness, and consequence profile — rather than whatever was most exciting in the boardroom? The organizations that succeed with autonomous AI almost universally started with use cases that were narrower, less glamorous, and more tractable than what the initial strategy deck envisioned. Starting with the right problem is not a compromise on ambition. It’s the reason the ambition eventually gets realized.
The Accountability Architecture: Engineering Who Owns What When the AI Gets It Wrong
When an autonomous AI system makes a harmful decision, the accountability question is not theoretical. It affects legal liability, regulatory compliance, organizational response, and the technical remediation path. Organizations that haven’t designed accountability architecture before deployment discover this at the worst possible moment — in the middle of an incident.
The Responsibility Diffusion Problem
Research on AI accountability failures consistently identifies a cascade pattern: the AI vendor points to the deploying organization’s configuration choices. The systems integrator points to the model vendor’s training data. The business unit that commissioned the deployment points to the technical team that built it. The technical team points to the AI Product Owner who set the risk parameters. The AI Product Owner points to the executive who approved the deployment with insufficient governance structure. Everyone is partially responsible. No one is fully accountable.
This diffusion is structurally predictable in complex systems with multiple contributors. The solution is to preemptively collapse the diffusion through explicit documentation of accountability assignments before deployment — not after an incident forces the question.
The Multi-Level Accountability Matrix
Effective accountability architecture assigns ownership at four levels:
System-level accountability: Who is organizationally answerable for the system’s overall decision quality? This must be a specific named individual in a specific role — not “the AI team” or “business operations.” This person has the authority to halt the system and the accountability for decisions it makes within approved parameters.
Decision-type accountability: For each category of autonomous decision, who is the domain authority who approved that decision type being automated and accepts responsibility for defining appropriate parameters? Procurement decisions: the CPO or their delegate. Credit decisions: the Chief Risk Officer. Patient routing: the Chief Medical Officer. These sign-offs should be documented formally, not casually agreed in a meeting.
Operational accountability: Who monitors the system in production and is responsible for detecting and responding to anomalies? This is the AI Operations function. They are accountable for the speed and quality of incident response — not for the system’s strategic decisions, but for its day-to-day operational health.
Vendor accountability: What specific performance and safety commitments has your AI vendor contractually made? What are their obligations when model behavior degrades below agreed standards? Vendor accountability agreements in 2026 are increasingly being negotiated with specificity around model performance SLAs, incident notification timelines, and remediation responsibilities. If your vendor contracts don’t address these points, renegotiate them before production deployment.
Making Accountability Auditable
Accountability architecture only functions if it’s auditable — meaning an external reviewer (a regulator, an auditor, a board member) can verify that accountability assignments exist, that they are being honored, and that incidents are being reported and remediated through the defined accountability structure. This requires:
- Written accountability assignments stored in a governance repository (not a Slack thread)
- Formal incident log that records every decision that resulted in escalation or human override
- Post-incident review documentation that records what happened, who was notified, what remediation was taken, and what threshold or parameter changes resulted
- Regular governance reviews (at minimum quarterly) that formally assess whether the accountability structure remains appropriate as the system evolves
Measuring What Actually Matters: KPIs for Autonomous Decision Systems
Most teams deploying autonomous AI systems measure what’s easy to measure: API call volumes, model latency, uptime percentage. These are infrastructure metrics. They tell you the system is running. They don’t tell you whether it’s making good decisions. Effective autonomous decision system measurement requires a different metric architecture:
Decision Quality Metrics
Decision accuracy rate: The percentage of autonomous decisions that, when subsequently reviewed (either via routine audit or post-incident), are evaluated as correct by domain experts. This requires building review sampling into operations — randomly auditing a percentage of auto-executed decisions to maintain a current accuracy baseline, not just relying on escalations as the feedback signal.
Escalation rate by decision type: What percentage of decisions in each category are triggering escalation (falling below confidence thresholds)? A rising escalation rate is often the first detectable signal of model drift — the system is encountering inputs that increasingly don’t match its training distribution. A falling escalation rate in a newly deployed system often indicates that thresholds are miscalibrated — set too loosely rather than reflecting genuine performance improvement.
Override rate: When human reviewers receive escalated decisions, what percentage are they overriding versus approving? High override rates indicate the model’s recommendations are consistently poor in the domain — a fundamental calibration problem. Low override rates in a Human-in-the-Loop system may indicate that reviewers are rubber-stamping AI recommendations rather than genuinely reviewing them, which defeats the oversight purpose.
System Health Metrics
Confidence score distribution drift: Track the distribution of confidence scores over time. A distribution that shifts left (more decisions falling into lower confidence ranges) is a leading indicator of model performance degradation — detectable before accuracy metrics degrade visibly. This is one of the most valuable early-warning signals available and is underused in most deployments.
Decision latency by autonomy tier: How long does each tier of decision (auto-execute vs. human review vs. escalation) actually take? If human review decisions are taking three times the stated SLA, your oversight mechanism is slower than designed — which means high-consequence decisions that require review are effectively being delayed rather than genuinely supervised.
Business Outcome Metrics
Technical metrics must ultimately connect to business outcomes. Define, before deployment, the specific business metrics that the system is expected to improve — cost per decision, cycle time for a given process, error rate compared to the previous human-operated baseline, customer satisfaction in affected touchpoints. Measure these from day one. If they’re not improving on the timeline the business case projected, that’s a signal requiring investigation, not explanation-away.
The 90-Day Roadmap: From Architecture to Controlled Deployment
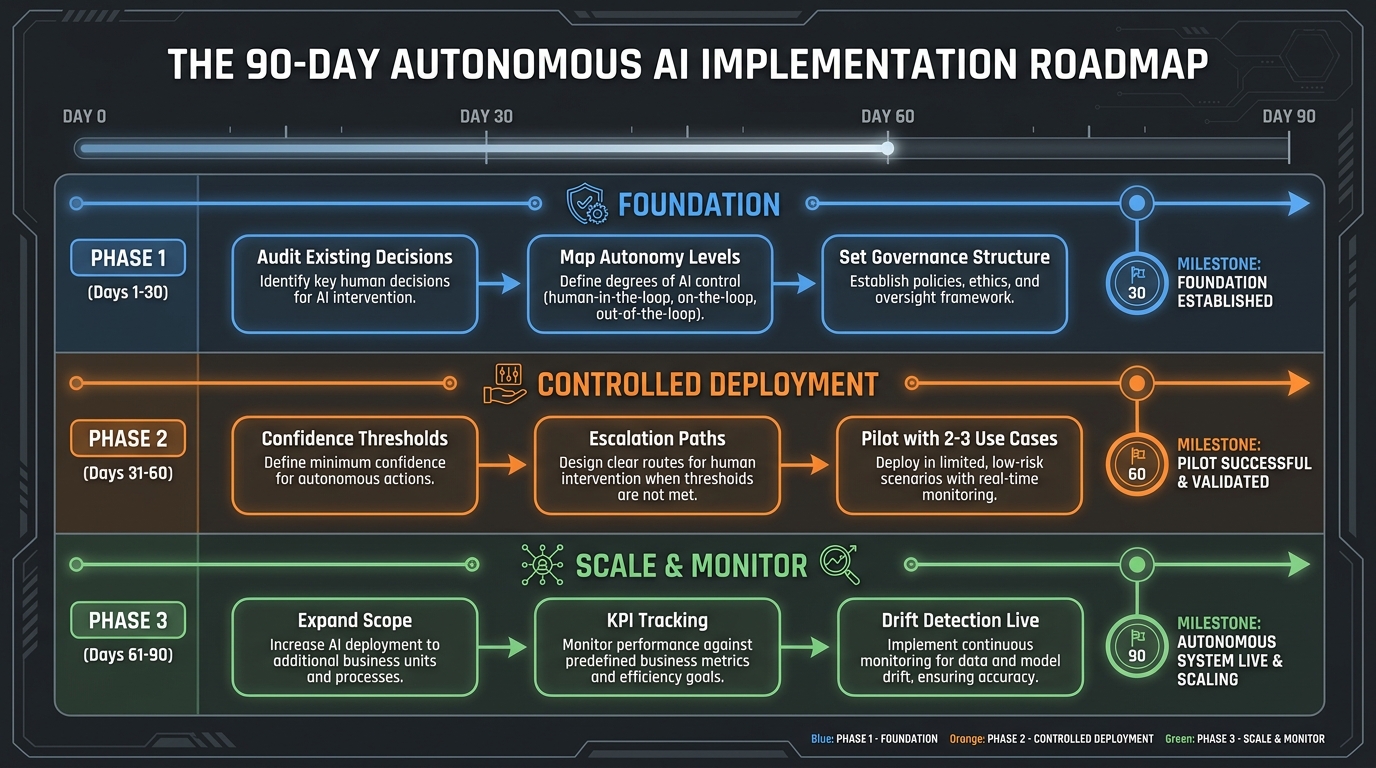
Implementation timelines for autonomous AI decision systems vary widely based on organizational complexity, use case scope, and existing infrastructure maturity. What follows is a structured 90-day framework for moving from architecture to a functioning, monitored, governed production deployment — not a complete enterprise transformation, but a defensible first deployment with the infrastructure to scale responsibly.
Phase 1: Foundation (Days 1–30)
The first thirty days are entirely pre-deployment. No model is selected. No code is written. This phase is about building the decision architecture that everything else will rest on.
Week 1-2 — Decision Taxonomy Audit: Conduct the decision type catalog described earlier. Involve technical leads, business stakeholders, legal, and compliance. Output: a complete inventory of decision types with consequence magnitude, frequency, reversibility, and data requirements documented for each.
Week 3 — Consequence-Frequency Mapping and Autonomy Level Assignment: Plot every decision type on the consequence-frequency grid. Assign a maximum autonomy level to each category. Have these assignments reviewed and approved by both technical and business leadership — with explicit sign-off that they understand what each autonomy level means operationally.
Week 4 — Governance Structure and Accountability Matrix: Establish the three-body governance structure. Document accountability assignments at all four levels. Define the incident response protocol. Confirm regulatory compliance requirements specific to your deployment scope. Have legal review the accountability documentation.
Phase 2: Controlled Deployment (Days 31–60)
Phase two deploys the system in a controlled environment — real data, real decisions, but with enhanced human oversight that will be systematically relaxed as performance is validated.
Week 5-6 — Infrastructure and Threshold Calibration: Deploy monitoring infrastructure, audit logging, and escalation routing before the decision system itself goes live. Configure initial confidence thresholds conservatively (higher thresholds than your ultimate targets, meaning more decisions go to human review initially). Deploy hard guardrails at the infrastructure level.
Week 7-8 — Pilot with Two to Three Use Cases: Select the two or three highest-frequency, lowest-consequence decision types from your taxonomy. Deploy with HITL oversight initially — every auto-executed decision is also reviewed by a human in parallel (shadow mode). Compare AI decisions to human decisions. Measure accuracy and calibrate confidence thresholds based on real performance data.
Week 9 — Threshold Refinement and Escalation Path Testing: Based on shadow mode data, refine confidence thresholds toward operational targets. Deliberately test escalation paths by injecting edge case inputs. Verify that escalations actually reach the designated reviewers within SLA. Document any infrastructure gaps identified during testing.
Phase 3: Scale and Monitor (Days 61–90)
Phase three transitions from controlled pilot to monitored production and begins building the infrastructure for responsible scope expansion.
Week 10-11 — Production Transition: Move pilot use cases from shadow mode to live autonomous execution with HOTL oversight. Activate confidence score distribution monitoring. Set up automated alerts for distribution drift. Begin collecting decision quality metrics against defined baselines.
Week 12-13 — Scope Expansion Assessment and Documentation: Review performance data from the initial deployment. Assess whether the system is meeting the KPIs defined in the business case. Identify the next set of decision types ready for autonomous deployment based on the taxonomy map. Document all findings, decisions, and threshold changes in the governance repository for compliance record-keeping.
At day 90, you don’t have a fully autonomous AI decision system across your entire operation — that’s not what day 90 looks like. What you have is a production system making real decisions in a defined scope, a functioning governance structure with tested escalation paths, a calibrated confidence architecture, and a documented roadmap for expanding scope based on validated performance rather than confidence in capability.
That’s a significantly more valuable and durable asset than a wider deployment built on untested assumptions.
The Decision You Have to Make Before AI Makes Any Decisions
There’s a question that every organization deploying autonomous AI decision systems eventually faces, and it’s more philosophical than technical: What level of AI error are you prepared to accept in exchange for the speed, scale, and efficiency gains?
This question has no universal answer. For low-consequence, high-frequency decisions — routing support tickets, classifying documents, scheduling non-critical appointments — a meaningfully higher error rate than human performance may be entirely acceptable because the scale gains outweigh the individual error costs. For high-consequence decisions — ones affecting patient safety, financial stability, regulatory compliance, or civil rights — even error rates that look small on a percentage basis translate into unacceptable absolute harm at enterprise scale.
The organizations that get this right are the ones that refuse to let this question be answered by default — by technical teams who assume the AI is good enough, by business units excited about efficiency gains, or by vendors whose incentives favor deployment over caution. The answer needs to come from a deliberate organizational process that involves stakeholders who understand both the upside and the downside, and that produces a documented, signed position that can be defended to a regulator, a board, or a journalist.
Autonomous AI decision systems are not inherently dangerous and they are not inherently safe. They are powerful tools whose impact is largely determined by the quality of the architecture that surrounds them — the decision taxonomy, the confidence thresholds, the governance structure, the accountability assignments, the escalation paths, and the continuous monitoring that keeps all of it calibrated against reality.
Build the architecture first. Then let the AI make decisions inside it.
Key Takeaways for Implementers:
- Map every decision type against consequence magnitude and frequency before assigning autonomy levels. High-consequence decisions require lower autonomy, regardless of model capability.
- Design for the four structural failure modes — distributional shift, hallucination cascades, non-replayable decisions, and responsibility diffusion — before writing a line of production code.
- Confidence thresholds are not optional. Three-tier routing (auto-execute, human review, escalate) is the minimum viable architecture for any consequential autonomous decision flow.
- Hard guardrails must be implemented at the infrastructure level, not as instructions to the AI model.
- Accountability is a design decision, not a legal technicality. Assign it explicitly before deployment, at system, decision-type, operational, and vendor levels.
- The EU AI Act enforcement in August 2026 and Colorado’s AI Act effective June 2026 create non-negotiable compliance requirements for high-risk AI applications in affected jurisdictions.
- Start the 90-day roadmap with the most boring use cases on your list. The ones you’ll learn the most from are rarely the most impressive ones to demo.