


The pitch sounds irresistible: autonomous AI agents that plan, reason, and execute complex multi-step work without constant human hand-holding. An AI that doesn’t just answer questions but actually does things — calls APIs, checks inventory, drafts contracts, flags anomalies, and hands work off to the next agent in the chain. No babysitting required.
So why do 88% of agentic AI projects never reach production?
The gap between the demo and the deployment is where most organizations quietly lose months of time, significant budget, and a team’s enthusiasm for the entire initiative. Agentic workflows are not simply “more powerful automation.” They require a fundamentally different approach to architecture, trust, governance, and change management — and most of the frameworks, vendor decks, and LinkedIn thought pieces skip over the hard parts in favor of showcasing the impressive parts.
This guide is written for people who are actually building these systems. Whether you’re a technical lead evaluating frameworks, an operations director wondering if agents are ready for your finance department, or a founder trying to figure out whether to run a pilot now or wait — this is the honest, data-backed account of what works, what breaks, and what the first 90 days of a real agentic implementation actually looks like in 2026.
The good news: the 12% that do reach production are generating an average 171% ROI. Some enterprise deployments are clocking returns that exceed $340,000 in annual savings per deployed agent. The upside is real. The path to it just requires more rigor than the hype suggests.
What Actually Separates Agentic Workflows from Plain Automation
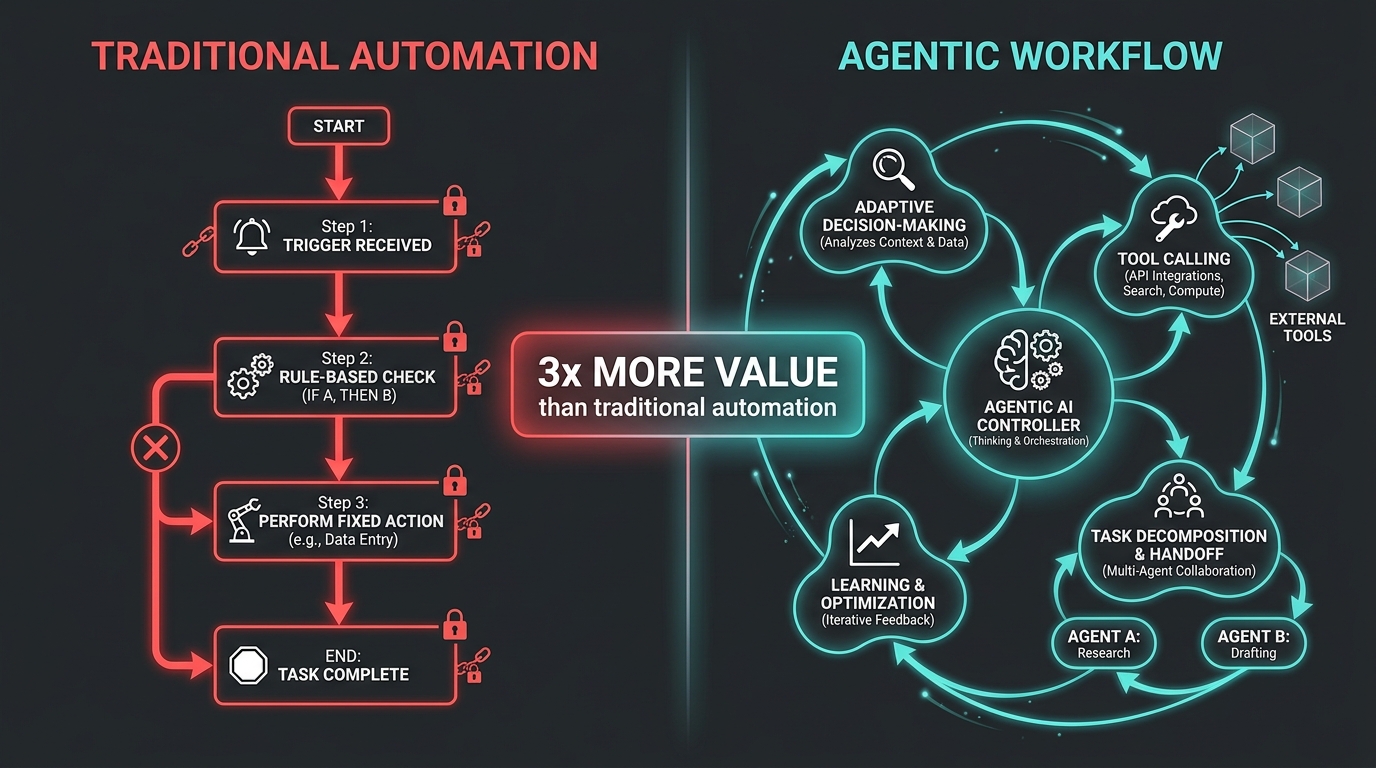
Most business software automates by following instructions. An RPA bot fills a form because it was told exactly which fields to target and in which order. A traditional workflow tool fires off a webhook when a trigger condition is met. The logic is deterministic and the outputs are predictable — which is both the strength and the ceiling of rule-based automation.
Agentic workflows operate on a different principle. An agent receives a goal, not a script. It plans its own path to that goal, selects tools, takes actions, evaluates results, and decides what to do next — all iteratively, within the scope it’s been given. When something unexpected happens mid-task, it doesn’t throw an error and stop. It reasons about the unexpected situation and adapts.
The Four Properties That Make a Workflow Truly Agentic
IBM’s framework for agentic AI identifies four core properties that distinguish genuine agent-driven processes from their traditional counterparts:
- Autonomy: The system can pursue a goal without step-by-step human instruction. It decides how to proceed, not just what to do next in a predefined sequence.
- Goal-driven behavior: Rather than following a rigid script, the agent evaluates its current state against a target outcome and works backwards to fill the gap.
- Adaptability: When the environment changes — a database returns unexpected data, an API is down, a document format doesn’t match expectations — the agent adjusts its strategy in real time.
- Tool use: Agents can call external systems, search the web, write and execute code, query databases, send messages, and interact with APIs. They’re not limited to what’s in their training data.
Why the Business Impact Gap Is So Large
These four properties combine to produce something qualitatively different from automation: a system that handles variance. Traditional automation thrives in stable, predictable environments. Agentic workflows are designed for messy reality — the purchase order that arrives in a non-standard format, the customer escalation that requires cross-referencing three different systems, the supply chain alert that needs context before someone can act on it.
This variance-handling capability is why agentic workflows are delivering 3x the value of traditional automation in comparable deployments. A support ticket workflow built with RPA might handle 60% of cases automatically — the straightforward ones. The same process rebuilt as an agentic workflow can handle 85–90%, because the agent can reason through the edge cases rather than failing on them.
The distinction matters enormously for implementation planning. If you’re evaluating whether to use an agentic approach or a conventional automation approach for a given process, the key question isn’t “which is more sophisticated?” It’s “how much variance does this process contain, and what is the cost of that variance hitting a human queue?”
Key distinction: Traditional automation fails loudly on variance. Agentic workflows are designed to reason through it. That single difference accounts for most of the ROI gap between the two approaches.
The Architecture Decision That Determines Everything
There is no single “agentic workflow architecture.” There are several, and choosing the wrong one for your use case is one of the most common sources of cost overruns and production failures in 2026. The three primary patterns each have distinct tradeoffs.
Single-Agent Loops
The simplest agentic architecture is a single agent with access to a set of tools, running in a loop until the task is complete or a stopping condition is met. The agent receives a goal, plans a sequence of actions, executes them one at a time, evaluates the result, and either continues or terminates.
Single-agent loops are underrated. Many organizations reach for multi-agent architectures prematurely because they seem more capable, when in reality a well-designed single agent with the right tools handles a large proportion of business use cases more reliably, more cheaply, and with far less coordination overhead. Document processing, research synthesis, data extraction, and routine analysis tasks frequently perform better as single-agent loops than as multi-agent pipelines.
The governing principle from practitioners: give the system the smallest amount of freedom that still delivers results. Adding agents adds complexity — and complexity compounds failure rates.
Sequential Multi-Agent Pipelines
When a task can be cleanly divided into sequential stages — where the output of one clearly defined step becomes the input of the next — a sequential pipeline architecture works well. Agent A handles research and passes structured findings to Agent B, which handles drafting, which passes to Agent C for quality review.
The critical requirement for sequential pipelines is clean handoffs. Each agent must have a clearly scoped role, a defined input format, and a defined output format. Where these seams break down — ambiguous output formats, missing context, state that doesn’t fully transfer — is precisely where sequential pipelines fail in production. Coordination overhead is real: four agents create 6 potential failure points, but ten agents create 45.
Hierarchical Orchestrator-Subagent Systems
The most complex pattern involves an orchestrator agent that receives a goal, decomposes it into subtasks, delegates those subtasks to specialized subagents, receives their outputs, synthesizes results, and manages error recovery. This is the architecture that appears in most marketing materials for agentic AI — and it’s also the one that most frequently fails in production.
Hierarchical systems are appropriate when: (a) the task genuinely requires parallel execution of independent subtasks, (b) specialization meaningfully improves quality, or (c) the system needs robust fault tolerance for mission-critical processes. They are not appropriate when those conditions aren’t met — which is often. The exponential scaling of interaction points, and the 10–15x cost increase per task that can result from poor orchestration, makes hierarchical systems a poor choice for anything that doesn’t genuinely require that complexity.
The pragmatic architecture guidance for 2026: start with a single-agent loop, graduate to sequential only when the use case demands handoff, and reach for hierarchical systems only when parallelism or specialization provides a measurable advantage you can’t get otherwise.
Where the Real Failures Happen

The statistics are blunt: 88% of agentic AI projects fail to reach production. Among those that do go live, another 40% are projected to fail at scale by 2027, according to Gartner’s analysis. Understanding the failure taxonomy isn’t pessimistic — it’s the most practical preparation a builder can do.
Infrastructure Failures (40% of Projects)
The most common single cause of agentic project failure is infrastructure that wasn’t designed for agent workloads. Agentic systems are stateful — they maintain context across many steps, sometimes over long time horizons. They’re often bursty — triggering many tool calls in parallel during intensive tasks. And they’re unpredictable in ways that rule-based automation isn’t, making capacity planning harder.
Organizations with data infrastructure built around traditional business intelligence or basic API integrations frequently discover that agents expose architectural debt they hadn’t prioritized. Stale data returned by a database becomes a critical problem when an agent is making decisions based on it. API rate limits that were fine for human-paced workflows become bottlenecks when an agent is making dozens of calls per minute. Memory and state management that worked for simple chatbots breaks down for long-running multi-step tasks.
Coordination Breakdowns at the Seams
For multi-agent systems specifically, the seams between agents — the handoff points — are where the majority of production failures originate. This is not an algorithmic problem. It’s an architectural one. When Agent A produces output that Agent B wasn’t designed to handle, the downstream agent either misinterprets context, loses state, or fails silently in ways that aren’t caught until much later in the pipeline — or not at all.
Silent failures are particularly dangerous in agentic systems. Unlike a traditional software error that throws an exception and stops execution, an agent that receives garbled context might simply continue operating with incorrect assumptions — producing confident, coherent-sounding output that is factually wrong. Without comprehensive observability tooling, these failures can propagate through an entire workflow before being caught.
Vague Task Definition and Infinite Loops
Many agentic projects fail not because of infrastructure or coordination problems, but because the task was never clearly defined. Agents given ambiguous goals will attempt to pursue them — often generating thousands of dollars in API costs through runaway loops before someone notices. A task without a clear stopping condition, or with a goal that the agent interprets more broadly than intended, can spiral into expensive behavior very quickly.
The discipline of task definition — specifying what “done” looks like, setting explicit loop limits, defining the scope of tool access — is not glamorous work, but it separates production systems from expensive demos. Practical builders treat this as a design phase deliverable, not an afterthought.
Governance and Cultural Resistance
Beyond the technical failures, a meaningful proportion of agentic projects stall because organizations haven’t built the internal governance to support them. Employees in departments targeted for agentic deployment frequently push back when they don’t understand what the agents are doing or why. Legal and compliance teams raise concerns that don’t have ready answers. IT security flags access requirements that weren’t anticipated. These aren’t irrational responses — they’re reasonable questions that should have been answered earlier in the process.
The organizations that navigate governance well treat it as a first-class design concern from day one, not something to address when the lawyers ask. That means defining the agent’s scope of authority before building, determining what decisions require human sign-off before deploying, and establishing audit trail requirements before the system touches production data.
The Trust Gap: Why Only 13% of Enterprises Run Fully Autonomous Agents

Dynatrace’s 2026 Pulse of Agentic AI survey — drawn from 919 enterprise executives — paints a revealing picture of where organizations actually stand on autonomy. Despite all the coverage of AI agents “taking over” business processes, the operational reality is far more measured:
- 69% of agentic AI-powered decisions are still verified by humans
- 64% of enterprises use a mixed approach (some autonomous, some supervised agents)
- 87% are actively building or deploying agents that require human supervision
- Only 13% use fully autonomous agents
- Executive trust in fully autonomous agents dropped from 43% to 27% year-over-year
This isn’t a story of timid organizations failing to embrace the technology. It’s a story of organizations that tried more aggressive autonomy and pulled back after seeing what can go wrong. The drop in executive trust is particularly telling — the 43% who trusted fully autonomous agents a year ago included many who have since experienced the failure modes firsthand.
The Human-in-the-Loop Is Not a Weakness
There’s a tendency in technical circles to treat human-in-the-loop (HITL) as a crutch — a stopgap until the models get good enough to remove the human entirely. This framing is both inaccurate and counterproductive. HITL, when implemented thoughtfully, is an architectural component that improves system reliability, not a limitation on it.
The practical approach is to identify decision points within a workflow where the cost of an agent error outweighs the cost of human review time, and place checkpoints there. High-stakes decisions — a financial transaction above a threshold, a customer-facing communication on a sensitive topic, a change to production infrastructure — typically warrant a checkpoint. Routine data processing, pattern recognition, and draft generation typically don’t.
The 64% of enterprises running mixed architectures have implicitly figured this out. They’re not trying to maximize autonomy for its own sake. They’re deploying autonomy where it’s trustworthy and inserting humans where errors are consequential.
Building Trust Through Observability
The single most effective way to expand the scope of autonomous operation over time is to build comprehensive observability into the system from day one. When operators can see exactly what an agent did, why it made each decision, what tools it called, and what context it was working with, the system becomes auditable. And auditable systems earn trust faster than opaque ones.
Organizations that built HITL checkpoints and observability dashboards in their initial deployments consistently report being able to expand the agent’s autonomous scope within 6–12 months as the audit trail demonstrated reliable behavior. Those that skipped observability and trusted the model’s outputs directly rarely expand their agent’s scope — and often roll back to narrower configurations after incidents.
The lesson is straightforward: design for auditability first, autonomy second. The trust that enables broader autonomous operation is earned through demonstrated reliability, and demonstrated reliability requires the ability to see what the agent is doing.
The Framework Landscape: Choosing Without Getting Burned
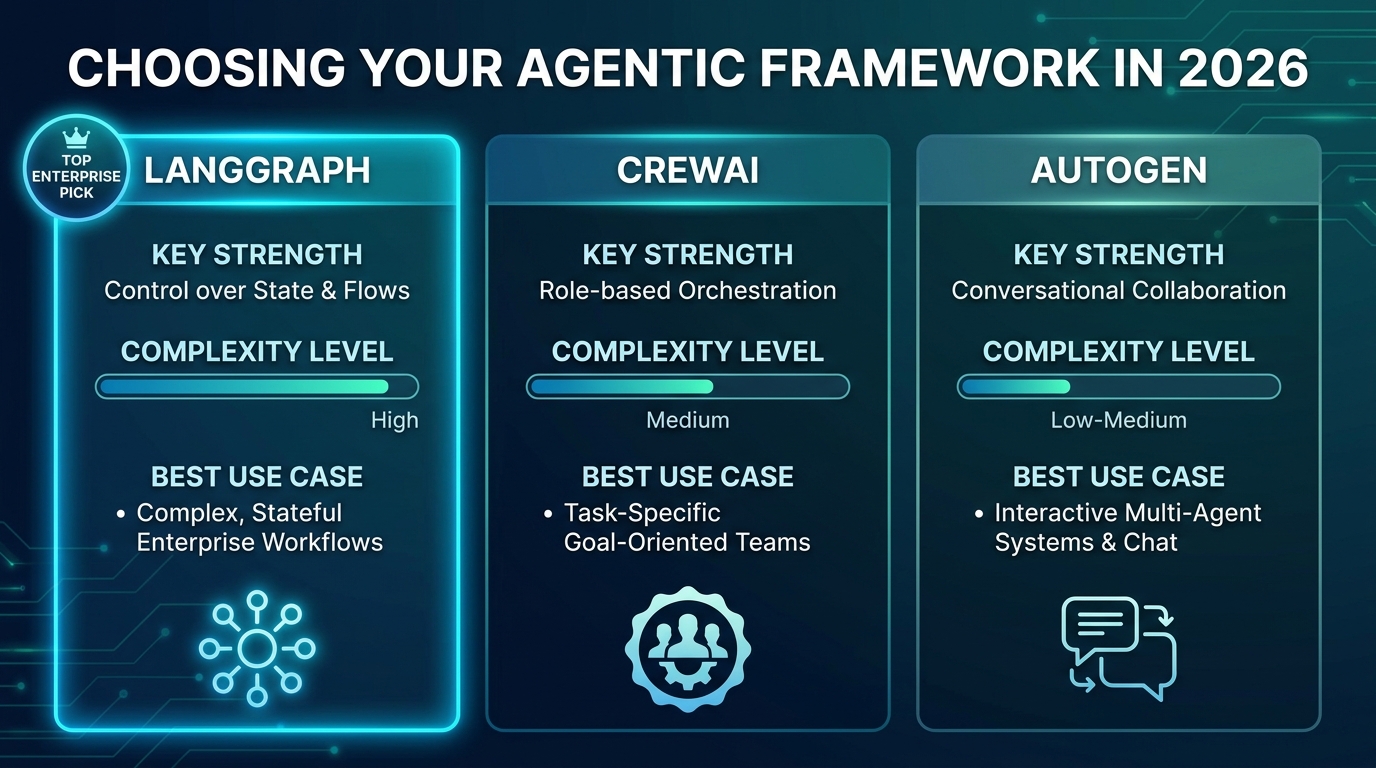
The agentic AI framework landscape in 2026 has largely consolidated around three primary options for enterprise use: LangGraph, CrewAI, and AutoGen. Each has a distinct philosophy, architectural approach, and strengths profile. Choosing based on hype or GitHub stars alone is a costly mistake — the right framework depends on your specific use case, team skills, and operational requirements.
LangGraph: The Enterprise Production Standard
LangGraph has emerged as the de facto standard for production enterprise deployments in 2026, surpassing CrewAI in GitHub stars and seeing the widest adoption among teams that need their agents to actually ship to production. Its core distinguishing feature is graph-based state management — workflows are defined as explicit state machines where nodes represent operations and edges represent transitions.
This explicit state management creates the audit trails that enterprise production environments require. Every state transition is trackable, every tool call is logged, and the system’s behavior at any point in a workflow can be reconstructed from the state history. For organizations with compliance requirements — financial services, healthcare, legal — this auditability often makes LangGraph the only viable option.
The tradeoff is complexity. A simple LangGraph agent requires substantially more code than equivalent implementations in CrewAI or AutoGen. Teams without Python expertise, or those building for rapid iteration rather than production durability, frequently find the overhead frustrating. LangGraph rewards teams that invest in understanding it; it punishes teams that want to move fast without building that foundation.
Best for: Complex, stateful workflows; compliance-sensitive deployments; production systems requiring full observability and audit trails; teams with Python engineering depth.
CrewAI: Speed to Prototype, Then Evaluate Carefully
CrewAI’s role-based model — where you define agents with named roles, goals, and backstories, then assign them tasks within a crew — is genuinely fast to prototype with. The abstraction layer hides much of the orchestration complexity and allows non-specialist developers to get a multi-agent system running quickly.
The risk with CrewAI lies in that same abstraction layer. When things go wrong in production — and they will — the opacity of the framework makes debugging significantly harder than in LangGraph. Teams frequently find themselves unable to trace why an agent made a particular decision because the state management is less explicit. For complex workflows or systems handling sensitive data, this can be a serious liability.
CrewAI’s strongest use case is for prototyping and proof-of-concept work where speed of iteration matters more than production durability. Many teams build their first agent in CrewAI to demonstrate the concept internally, then rebuild in LangGraph for production.
Best for: Rapid prototyping; smaller teams; use cases where role-based agent definitions map naturally to the task; non-production experiments.
AutoGen: Microsoft’s Conversational Multi-Agent Approach
AutoGen, maintained by Microsoft Research, takes a conversational approach to multi-agent coordination — agents communicate with each other through structured conversations rather than explicit state machines. This maps well to workflows that naturally involve negotiation, critique, and refinement between agents (a writer agent and a critic agent, for example, or a planner and an executor that argue back and forth until a plan meets quality criteria).
AutoGen’s integration with Azure services makes it the natural choice for organizations heavily invested in the Microsoft ecosystem. Its strengths in multi-agent conversation dynamics are also a limitation: for workflows that aren’t conversational in nature, the conversational overhead adds latency and cost without corresponding benefit.
Best for: Azure-integrated environments; workflows involving critique/refinement loops; teams familiar with Microsoft tooling; multi-agent conversations where back-and-forth reasoning is intrinsic to the task.
Framework Selection Criteria That Matter
Beyond the framework-specific tradeoffs, the selection decision should be driven by four practical criteria:
- Observability requirements: If you need full state visibility and audit trails, LangGraph is the only production-ready option.
- Team capabilities: CrewAI and AutoGen require less engineering depth upfront; LangGraph rewards investment.
- Infrastructure context: Azure shops should evaluate AutoGen seriously. Multi-cloud or cloud-agnostic environments lean toward LangGraph or CrewAI.
- Timeline: If you need a working prototype in a week, CrewAI. If you’re building a system that needs to be running reliably in 18 months, LangGraph.
How to Design Your First Agentic Workflow: The 5-Phase Build Process
The teams that successfully deploy agentic workflows tend to follow a consistent build process, even if they don’t all articulate it the same way. The following five phases capture the pattern that distinguishes successful deployments from the majority that stall.
Phase 1: Process Selection and Scoping
Not every business process is a good candidate for an agentic approach. The processes that work best share several characteristics: they involve multiple steps with decision points, they contain meaningful variance that defeats rule-based automation, they currently require skilled human time to execute, and they have a clear, measurable outcome definition.
A useful diagnostic framework: map the process you’re considering, mark every decision point where a human currently uses judgment, and estimate the consequence of each judgment being wrong. If most of the decision points have low consequences for individual errors (they can be corrected downstream) and the process is executed frequently, it’s a strong candidate. If several decision points have high consequences that can’t be reversed, plan for HITL checkpoints at those specific moments rather than avoiding the process entirely.
Equally important is the scoping boundary. Define the process’s inputs and outputs explicitly, including what “successful completion” looks like in machine-readable terms. Vague success criteria are one of the most consistent precursors to runaway agent behavior and cost overruns.
Phase 2: Tool Inventory and Access Design
An agent is only as capable as the tools it can access. Before writing any agent code, build a complete inventory of the systems, APIs, and data sources the agent will need to accomplish its goal. For each, document the authentication requirements, rate limits, data format, and failure modes.
The access design principle that experienced builders follow: grant the agent the minimum tool access required to accomplish the task, then justify adding more access rather than removing it. Agents with broad access to production systems that they don’t strictly need create unnecessary blast radius when things go wrong. An agent that can only read from a database is far safer than one that can read and write — until you’ve validated the read-only behavior in production and established the governance for write access.
Phase 3: Architecture Selection and Prompt Engineering
With the process scoped and tools inventoried, select your architecture (single-agent, sequential, or hierarchical) based on the criteria from the earlier section. Most first workflows should start as single-agent loops, graduating to sequential only if the process naturally divides into stages with clean handoff points.
Prompt engineering for agentic systems is substantially different from prompt engineering for conversational AI. The system prompt for an agent needs to define: the agent’s goal in precise terms, the tools available and when to use them, the explicit stopping conditions, what to do when a tool call fails, and the format for any outputs that will be consumed by other systems or humans. Vague system prompts are consistently the root cause of the “infinite loop” failure mode — the agent that keeps trying approaches because the definition of success was never made clear.
Phase 4: HITL Checkpoint Design
Before deploying, map the decision points in your workflow against a simple risk matrix: probability of error multiplied by consequence of error. Any decision that scores high on this matrix gets a human checkpoint. The checkpoint doesn’t need to be a manual approval — it can be a notification, a confidence threshold, or a quick-review interface — but it needs to exist before the system handles production traffic.
The checkpoint design should also include escalation paths. What happens when an agent repeatedly reaches a checkpoint that the human reviewer isn’t available for? Queuing logic, timeout behavior, and fallback routing are not optional — they determine whether your workflow degrades gracefully or fails completely when human reviewers are slow to respond.
Phase 5: Observability Before Scale
The final phase before production is instrumentation. At minimum, every production agentic workflow should log: each tool call with inputs and outputs, the reasoning chain the agent used to decide on each action, the time and cost of each step, error rates and retry counts, and any HITL checkpoint triggers and their resolution.
This logging infrastructure serves three purposes: it lets you debug failures when they happen, it lets you measure the KPIs that justify the system’s existence, and it builds the audit trail that compliance teams and executives need before expanding the system’s scope.
Instrumenting for Accountability: KPIs That Actually Matter
The measurement framework for agentic workflows requires more nuance than traditional automation metrics. Because agents handle variance and make judgment calls, the right KPIs capture both operational performance and decision quality — not just throughput.
Operational KPIs
The core operational metrics for agentic workflows track how reliably and efficiently the system completes its assigned work:
- Task success rate: The percentage of initiated tasks that complete successfully, without human intervention. Industry benchmarks suggest targeting ≥90% for stable production workflows, with 95%+ as the threshold for expanding autonomous scope.
- Average handling time: End-to-end completion time per task, compared to the pre-agentic baseline. The average time-per-task reduction across enterprise deployments is 37% — use your pre-deployment baseline as the denominator.
- Human escalation rate: How often does the agent transfer work to a human because it can’t complete the task? A rising escalation rate is an early warning sign of model drift, data quality degradation, or process change that the agent hasn’t adapted to.
- Error and rework rate: How frequently does agent-completed work require correction? The average error rate reduction in successful agentic deployments is 44% — but that requires measuring the baseline error rate before deployment.
Business KPIs
Operational KPIs tell you the system is working. Business KPIs tell you it’s worthwhile. The ROI measurement framework that practitioners use in 2026 evaluates improvement across four pillars — and successful deployments typically show measurable improvement on at least two:
- Cost reduction per transaction: The direct labor cost displaced by the agent, minus the cost of running the agent (model API costs, infrastructure, oversight time).
- Revenue impact: For customer-facing workflows, the revenue attribution from improved speed, quality, or personalization. Customer-facing agentic agents generate an average $420,000 in revenue uplift per deployment at the Fortune 500 level.
- Cycle time reduction: How much faster are outcomes being achieved? Faster cycle times compound — a procurement process that moves 40% faster frees working capital, reduces carrying costs, and improves supplier relationships.
- Quality and risk reduction: For compliance-sensitive processes, error reduction has a direct dollar value in avoided penalties, rework costs, and reputational exposure.
Governance Metrics
Beyond performance and business value, governance metrics track the health of the system’s oversight structure:
- Audit trail completeness: What percentage of agent decisions are fully traceable in the observability log?
- HITL checkpoint response time: How quickly are human reviewers processing checkpoint requests? Bottlenecks here create the incentive to remove checkpoints — which usually precedes incidents.
- Drift indicators: Are model outputs degrading over time as data distributions shift? Regular evaluation runs against a held-out test set catch drift before it affects production.
Real Results From Real Deployments

The case studies from enterprises that have successfully deployed agentic workflows share common structural features: they started with a narrowly scoped, high-frequency process; they built observability before expanding scope; and they measured rigorously against pre-deployment baselines. The results are substantial — and instructive.
JPMorgan Chase: Compressing Analyst Work in Investment Banking
JPMorgan’s agentic AI deployment across investment banking operations is one of the most documented enterprise cases. The bank now runs more than 450 agentic AI use cases in daily operation, with applications ranging from M&A memo drafting to trade settlement and fraud detection.
The headline result: investment banking presentations that previously required hours of junior analyst time are now generated in 30 seconds. This isn’t simply a productivity gain — it changes the economics of how many client relationships can be actively serviced and how quickly analysts can respond to live deal situations. The bank has also documented more than $5 million in avoided outside counsel costs through contract review and legal research automation.
The operational approach that made this work: JPMorgan built internal infrastructure for agent observability before scaling to 450+ use cases. Each agent’s decisions are logged, auditable, and subject to regular review. Human oversight wasn’t removed — it was restructured. Senior analysts now review agent-generated content rather than producing first drafts, which is a fundamentally different (and more valuable) use of their expertise.
Walmart: Real-Time Supply Chain Coordination at Scale
Walmart’s supply chain agentic deployment addresses the fundamental challenge of coordinating inventory across 4,700 stores and distribution centers in real time. The system continuously monitors demand signals, detects surges before they become stockouts, adjusts replenishment orders autonomously, and reroutes around supply disruptions — all without requiring human sign-off for routine adjustments.
The key design decision that enabled this level of autonomy: Walmart defined clear action thresholds below which agents act independently and above which they escalate. Routine replenishment adjustments below a dollar threshold are fully autonomous. Significant changes to supplier orders or logistics routing trigger a human review queue. This tiered autonomy model is increasingly the standard approach for supply chain operations — it captures most of the efficiency gains from full autonomy while maintaining human control over decisions that could have meaningful downstream consequences.
Siemens: Predictive Maintenance and Production Line Management
Siemens deployed agentic AI across manufacturing production lines to monitor sensor data, predict equipment failures before they occur, and adjust workflows in response to real-time anomalies. The system processes continuous sensor feeds that no human operator could monitor at the required frequency and resolution.
The documented outcome is a 30% reduction in production downtime — a figure that, in manufacturing, translates to a substantial financial impact given the cost of line stoppages. The architecture is sensor-data-first: the agents are not making high-level strategic decisions. They’re doing pattern recognition on time-series data and triggering specific, pre-defined responses when anomaly thresholds are crossed. This tight scope definition is precisely why the deployment works reliably in a high-stakes environment.
General Mills: $20M+ in Supply Chain Savings
General Mills’ agentic supply chain deployment generated more than $20 million in documented savings through improved demand forecasting, reduced waste, and optimized logistics routing. The system’s core advantage is its ability to synthesize data from many different sources — point-of-sale signals, weather forecasts, commodity price feeds, promotional schedules — and act on that synthesis faster than traditional planning cycles allow.
The lesson from General Mills for mid-market organizations without Fortune 500 AI budgets: the value driver here is data integration and response speed, not raw model capability. The agents are valuable because they connect information sources that weren’t previously connected and act on that information before conditions change. Smaller organizations can achieve similar structural benefits at lower cost by starting with fewer data sources and a narrower decision scope.
The 90-Day Agentic Implementation Roadmap

The organizations that ship agentic workflows successfully treat the first 90 days as a structured learning exercise, not a race to production. The following roadmap reflects the approach that practitioners report working consistently across organization sizes and industry sectors.
Days 1–30: Foundation
The foundation phase is entirely pre-build. No agents are written. The work is discovery, design, and stakeholder alignment — the work that, when skipped, causes the late-stage failures.
Process audit: Map the two or three candidate processes that might benefit most from agentic automation. For each, document the current state in detail: steps, decision points, tools accessed, average handling time, error rate, frequency, and the cost of errors. Without this baseline, you can’t prove ROI later.
Infrastructure readiness review: Audit your data infrastructure against agent requirements. Identify stale data sources, API rate limits, authentication gaps, and state management requirements. The 40% of projects that fail due to infrastructure do so because this audit was skipped or deferred.
Governance design: Define the agent’s scope of authority before writing code. Document which decisions are autonomous, which require HITL, and what the escalation path looks like. Get legal, compliance, and IT security involved now — not during the pilot.
Framework selection: Use the criteria from the earlier section to select your framework. If your team is new to agentic development, build a small exploratory prototype in CrewAI to understand agent behavior before committing to the production framework.
Days 31–60: Pilot
The pilot phase builds and deploys a single-agent system on a single, narrowly scoped process. The goal is not to prove the technology at scale. It’s to validate the architecture, discover the failure modes, calibrate the HITL thresholds, and generate the first measurements against baseline.
Build the single agent: Scope aggressively. The first production agent should handle a subset of the target process — the highest-frequency, most predictable subset — not the full process. You can expand scope after validating the foundation.
Instrument from day one: Stand up your observability dashboard before the agent touches real data. Every tool call logged, every decision traceable, every cost tracked. This is not optional infrastructure to add later.
Run in shadow mode: Before routing live traffic to the agent, run it in parallel with the human process for one to two weeks. Compare outputs. Identify divergence points. The cases where the agent would have diverged from the human judgment are your training data for calibrating HITL thresholds.
Measure against baseline: After two to four weeks of live operation, measure task success rate, average handling time, error rate, and human escalation rate against the pre-deployment baseline. If the numbers support continuing, proceed to scale. If they don’t, diagnose before expanding.
Days 61–90: Scale
If the pilot met its success criteria, the scale phase expands scope, increases throughput, and begins the process of expanding autonomous operation based on validated performance data.
Expand process scope: Add the more complex cases that were excluded from the pilot. Monitor escalation rates carefully — a spike in escalations when complex cases are added indicates that the agent’s judgment is less reliable on those cases and that the HITL thresholds need recalibration.
Expand autonomous operation selectively: For decision points where the pilot demonstrated consistent reliability, review whether the HITL checkpoint is still needed. Remove it only when the audit trail supports doing so — not based on confidence or schedule pressure.
Plan the next workflow: With one successful deployment in production, the team now has the knowledge to apply the process to a second candidate. The second deployment moves faster because the infrastructure, governance processes, and observability tooling are already in place.
What Changes When Agents Start Managing Agents
As organizations scale from one or two agentic workflows to a portfolio of many, a new set of challenges emerges that the 90-day roadmap doesn’t fully address. The transition from single-workflow deployments to multi-workflow agent ecosystems is where the more sophisticated operational questions arise.
Resource Contention and Prioritization
When multiple agentic workflows are running simultaneously, they compete for shared resources: LLM API capacity, database connections, human reviewer attention at HITL checkpoints, and infrastructure compute. Without explicit resource management, high-priority workflows can be starved by lower-priority ones simply because they were initiated later in a queue.
The solution is to build resource prioritization logic into the orchestration layer from the start. Define priority tiers for workflows, implement rate limiting and queuing that respects those tiers, and instrument resource utilization as a first-class metric. The organizations that skip this step discover it when a mission-critical workflow is delayed because a lower-priority research task consumed all available API capacity.
Cross-Workflow Coordination and Data Consistency
When agents from different workflows read from and write to shared data systems, consistency becomes a concern. Agent A might be updating a customer record at the same time Agent B is reading it to generate a recommendation. Without coordination, Agent B’s recommendation is based on stale data, and the resulting action may conflict with what Agent A is doing.
This is not a new problem — distributed systems engineers have solved it many times. But it’s frequently overlooked in agentic deployments because the teams building agents don’t always have distributed systems backgrounds. The practical mitigation is to treat shared data stores as sources of truth with explicit read/write locking where consistency matters, and to design agent workflows to minimize the window between reading state and acting on it.
Emergent Behavior in Agent Ecosystems
The most counterintuitive challenge at scale is emergent behavior — agents doing things the designers didn’t anticipate, not because the agents are malfunctioning, but because the interaction between multiple independently rational agents produces system-level behavior that wasn’t designed for. An agent that’s optimizing for its local objective might trigger conditions that cause another agent to act suboptimally, even though neither agent is making a mistake in isolation.
This is an active area of research and practice. The current state of the art is to monitor for emergent behaviors through comprehensive logging and periodic adversarial testing, define clear ownership boundaries between agents to minimize unintended interactions, and maintain a human escalation path that can intervene when system-level behavior diverges from intent. It’s not a solved problem — but awareness of it, and investment in the observability that surfaces it, is the first line of defense.
Conclusion: Building for the Long Game
Agentic workflows are not a technology to adopt because competitors are talking about them. They’re an operational capability to build because specific business processes have specific pain points that the agentic approach is uniquely suited to address — and because the organizations that build this capability well are accumulating a structural advantage that compounds over time.
The builders who succeed in 2026 share a common orientation. They’re not chasing the most autonomous system possible — they’re building the most reliable system possible and then expanding autonomy as reliability is demonstrated. They instrument before they scale. They define governance before they deploy. They measure against baselines before they claim ROI. They treat the seams between agents — the handoffs — as the primary risk surface and design those seams with the same rigor they apply to the agents themselves.
The 88% failure rate is not a reflection of bad technology. It’s a reflection of implementation approaches that prioritize demonstration over durability. The 12% that reach production and generate 171% average ROI are doing the same thing any good engineering team does: they’re doing the unsexy foundational work before the impressive visible work.
Your Actionable Starting Points
- Identify your first candidate process using the scoping criteria: high frequency, significant variance, measurable baseline, and clear success criteria.
- Audit your infrastructure before writing any agent code. The 40% of projects that fail due to infrastructure almost always failed because this step was skipped.
- Design HITL checkpoints around your highest-risk decision points before selecting a framework or writing a prompt.
- Choose LangGraph for production if your use case requires audit trails, compliance, or complex stateful workflows. Use CrewAI for rapid prototyping only.
- Measure against your baseline from the first day of shadow operation. ROI claims without pre-deployment baselines are guesses, not evidence.
- Expand autonomy as a reward for demonstrated reliability — not as an assumption baked into the initial deployment plan.
The organizations building durable agentic capability now will be operating with structural efficiency advantages that are difficult to replicate in two or three years. The window isn’t closing, but the learning curve is real — and the teams starting today, building carefully, will be years ahead of those who wait for the technology to become more forgiving of shortcuts.
Build the foundation. Earn the autonomy. Measure everything. That’s what the successful 12% are doing — and it’s replicable.


