
Somewhere in the last eighteen months, “AI for RevOps” quietly split into two different conversations. The first is the vendor conversation — demonstrations, dashboards, and slides showing AI-generated pipeline summaries, automated outreach sequences, and forecast confidence scores. The second is the practitioner conversation, which is much quieter, considerably less polished, and almost entirely focused on one problem: why does none of this work reliably in production?
The gap between those two conversations is not a technology problem. It is an architecture problem. Teams are bolting AI features onto revenue workflows without building the underlying system that would make those features behave consistently, safely, and at scale. The result is a familiar pattern: impressive demos in controlled conditions, brittle outputs in live environments, and CRM data that gets worse, not better, after an AI agent touches it.
This article is about the second conversation. It is a practical, layer-by-layer examination of what a real AI agent stack for Revenue Operations actually looks like — not as a vendor pitch, but as an engineering and operational decision. It covers the three architectural layers every RevOps stack requires, the five agents worth building first (and in what order), the build-versus-buy decisions that matter most, the governance design that keeps autonomous agents from doing damage, and the failure patterns that derail deployments before they ever reach production value.
The goal is not to describe what AI can theoretically do for revenue teams. It is to give you a working map of how to build something that actually runs.
Why “Adding AI” Is Not the Same as Building an Agent Stack
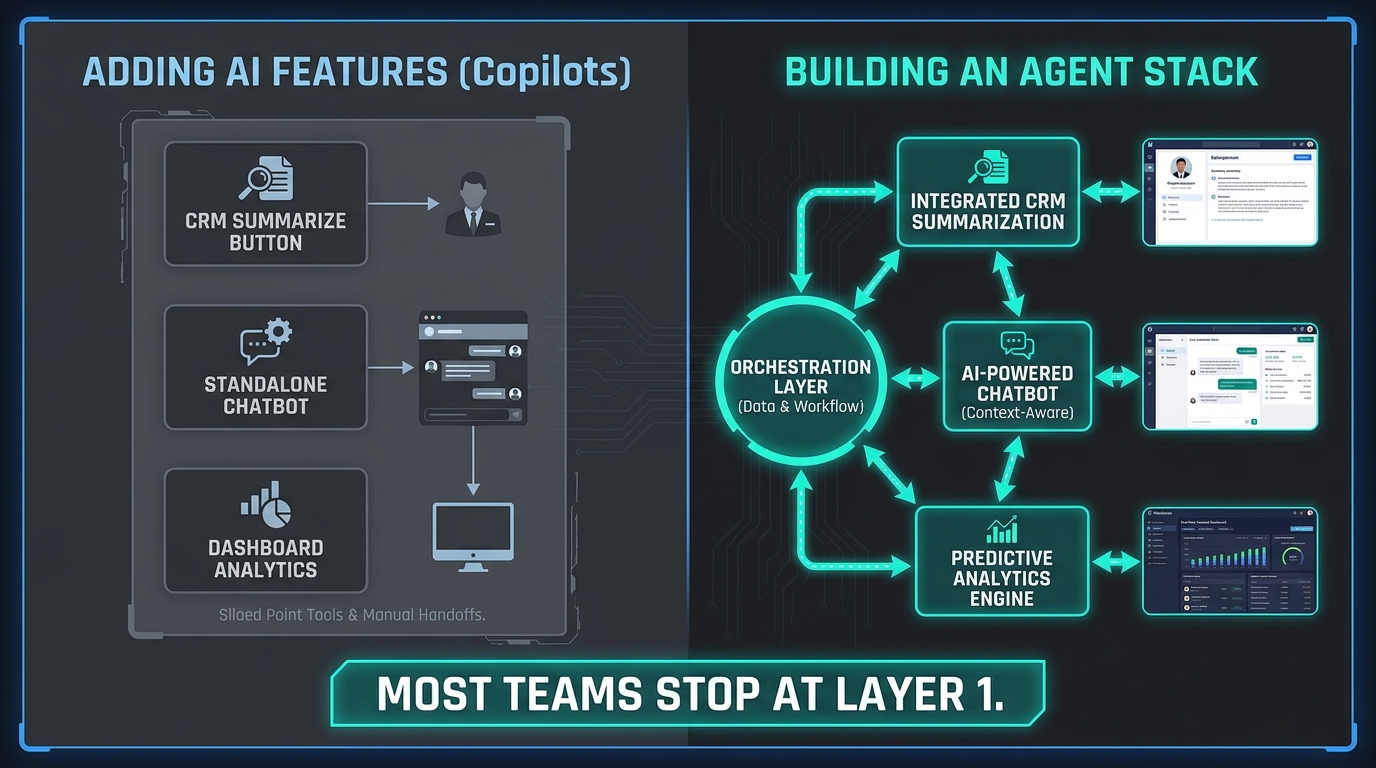
The terminology matters here because it shapes what gets built. Most revenue teams in 2026 have already “added AI” in some form. They have a call recording tool that summarizes meetings. They have a CRM plugin that scores inbound leads. They have a sequence tool that personalizes email subject lines. These are AI features — discrete, helpful, often genuinely time-saving. They are not an agent stack.
The Core Distinction: Isolated vs. Orchestrated
An AI feature responds to a specific prompt within a specific tool boundary. An AI agent takes initiative — it monitors conditions, makes decisions based on multi-source data, executes actions across system boundaries, and produces an output that may trigger further downstream steps. An agent stack is what you get when multiple agents are connected by a shared data foundation and an orchestration layer, so that the output of one agent becomes the reliable input of another.
That orchestration layer is what most teams are missing. Without it, you have a collection of independent AI features that each behave well in isolation but cannot coordinate with one another. The call summary agent does not know that the lead scoring agent just downgraded that account. The pipeline health agent does not know what the deal prep agent flagged in yesterday’s preparation notes. Every agent is working from its own slice of context, and the fragmentation shows up downstream as inconsistent decisions and siloed data writes.
The Copilot Trap
The dominant AI deployment pattern in revenue operations through 2024 and into 2026 has been what practitioners now call the “copilot trap.” A copilot surfaces insights but requires a human to act on them. It might flag that a deal is at risk — but the rep has to update the CRM. It might suggest a follow-up sequence — but the manager has to approve and launch it. Copilots reduce cognitive load. They do not reduce operational drag.
The shift from copilot to agent is the shift from insight to action. An agent does not just tell a rep that a CRM record is missing key fields — it updates those fields, logs the source, and flags exceptions for human review. That shift requires a fundamentally different architecture: one that is wired for action, not just for surfacing information.
Why the Gap Exists
The reason most teams stop at copilots is not that agents are too technically complex. It is that agents require an operational foundation that copilots can skip. You can build a meeting summary copilot without clean CRM data. You cannot build a reliable pipeline health agent without it. The data foundation, the governance model, the error handling, the observability tooling — all of this is invisible in a copilot deployment and essential in an agent deployment. Teams that skip it discover the problem the hard way, usually when an agent makes a bad decision at scale and there is no audit trail to explain why.
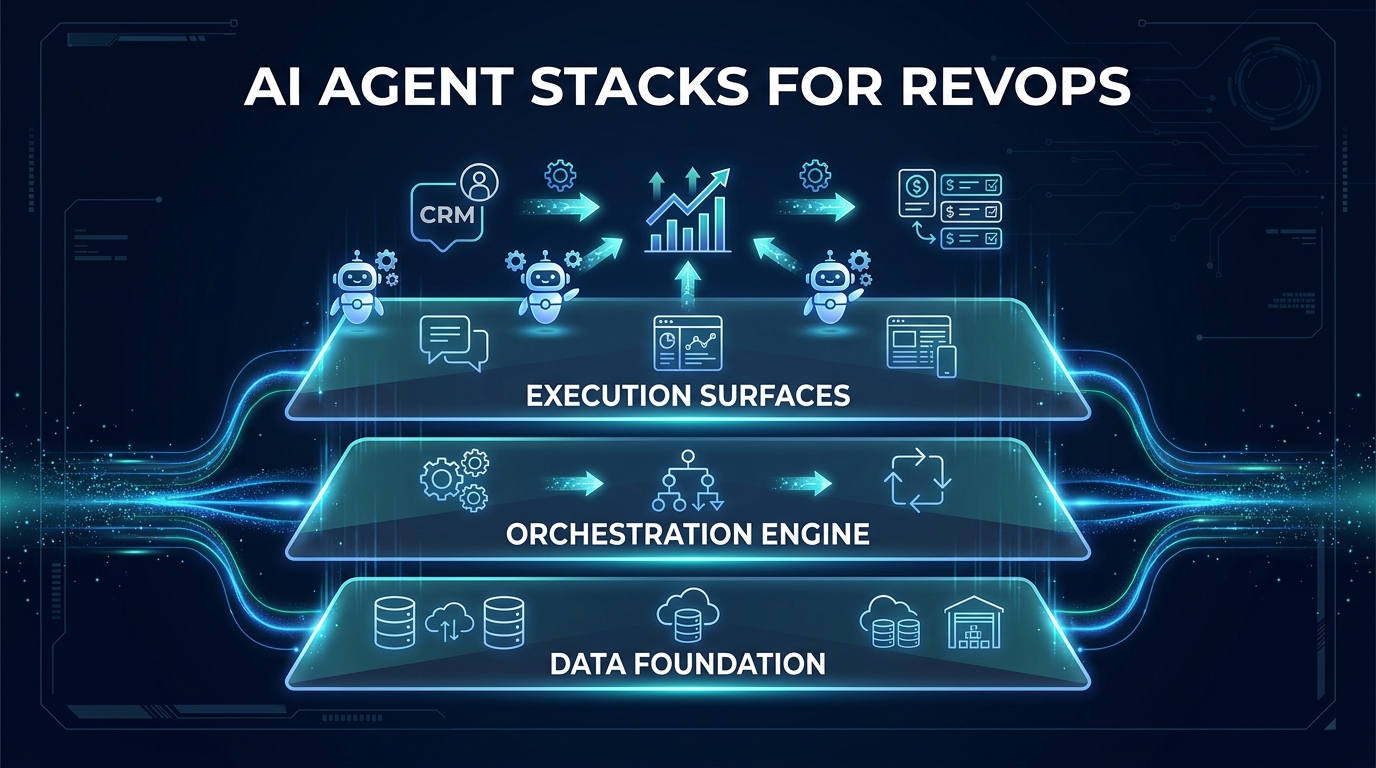
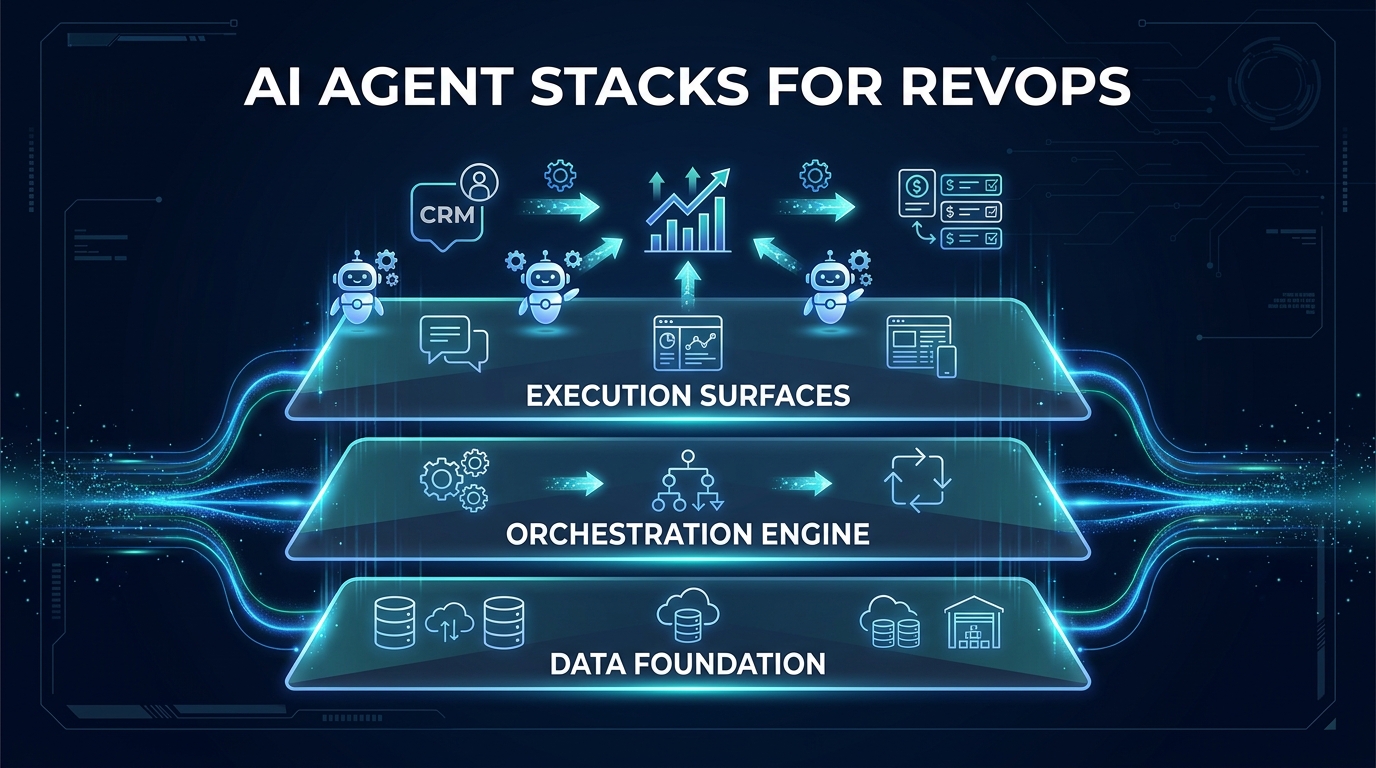
The Three-Layer Architecture Every RevOps AI Stack Needs
Regardless of which tools you choose, which agents you build first, or how large your revenue team is, every functional AI agent stack for RevOps sits on the same three-layer architecture. Understanding this framework before you buy or build anything is the single decision that most separates successful deployments from failed ones.
Layer One: The Data Foundation
This is the bedrock — and it is the most underbuilt component in the majority of RevOps AI stacks. The data foundation is not your CRM. It is the governed, standardized, integrated representation of your GTM data that your agents read from and write to. It includes identity resolution (the same company must be the same company across your CRM, MAP, product, billing, and enrichment tools), canonical definitions (what “qualified pipeline” means, precisely, across your entire tech stack), and strict data contracts that govern what an agent is allowed to write.
Layer Two: The Orchestration Engine
This is the decision layer — the part of the stack that determines which agent fires when, with what context, under what conditions, and with what constraints. The orchestration layer owns routing logic, conflict resolution between competing agents, confidence-based handoffs to humans, and the audit log of every agent action. In most mature RevOps stacks, this layer is owned by the RevOps team rather than engineering — it is where operational policy lives.
Layer Three: Execution Surfaces
These are the tools where agents take action and where humans see the outputs: CRM, Slack, email sequencers, CPQ systems, dashboards. The execution surface layer is usually the first place teams start building because it is visible and tangible. It should be the last layer fully wired up, because agents writing to execution surfaces without a clean data foundation or a governed orchestration layer is exactly the condition that produces the bad outcomes everyone worries about — wrong data written to the wrong record, at scale, with no rollback.
Layer One in Detail: The Data Foundation Nobody Wants to Build
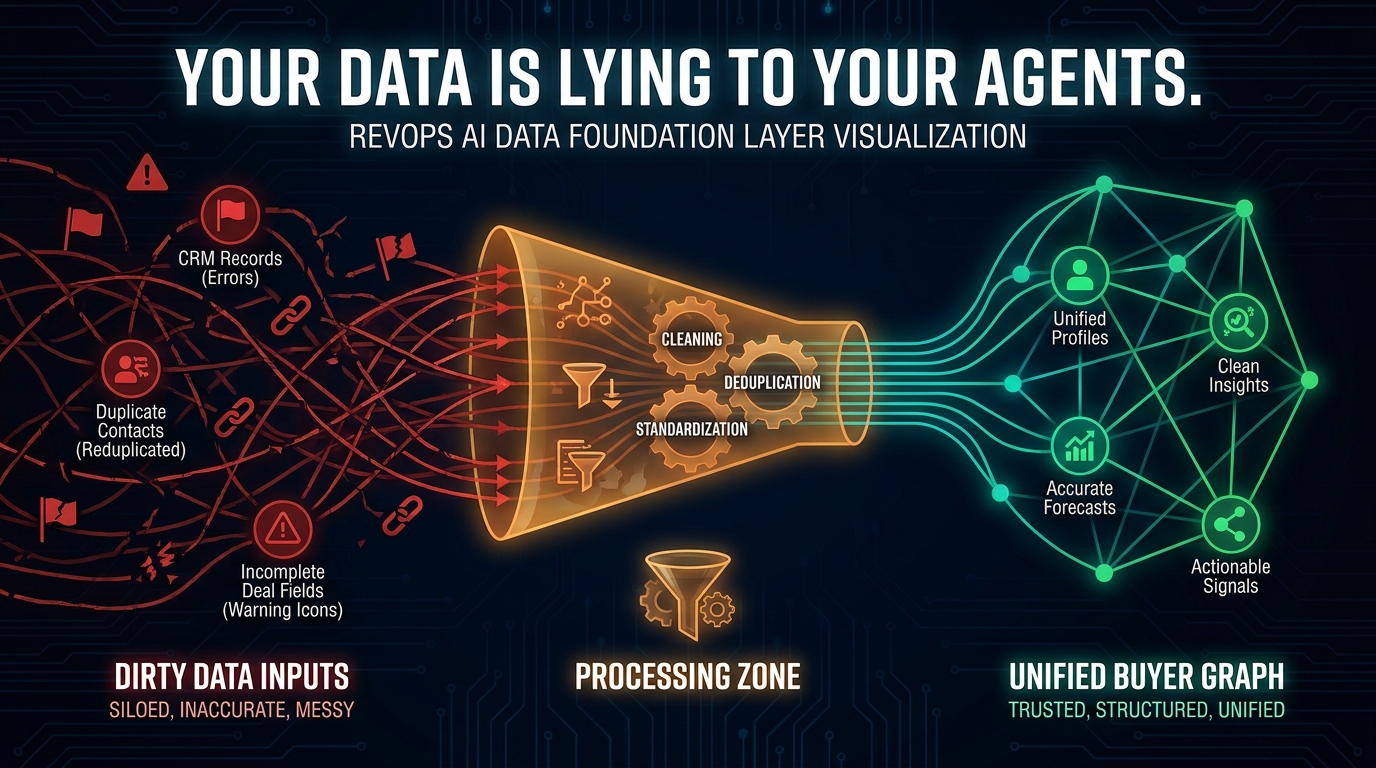
Every RevOps practitioner agrees that data quality is critical to AI agent performance. Almost nobody actually builds the data foundation before deploying the first agent. The result is predictable: agents trained on incomplete or inconsistent data produce confident-sounding but wrong outputs, and the team loses trust in the system faster than they built it.
The Scale of the Problem
Research across B2B RevOps teams consistently shows that CRM data accuracy rates hover around 30% for many organizations — meaning the majority of records have meaningful quality issues: duplicate accounts, missing contact fields, incorrect deal stages, outdated firmographics, and closed-lost opportunities still appearing as open in pipeline reports. When an AI agent reads from that data and takes action based on it, it amplifies the existing debt rather than cleaning it.
The practical impact is significant. Forecasting agents built on pipeline data that contains phantom deals will produce forecasts that miss consistently in one direction. Lead scoring agents using contact data with outdated job titles will misroute leads at scale. CRM hygiene agents that write back to a poorly structured data model will create new inconsistencies while trying to fix old ones. Each of these is a failure mode that emerges not from a broken agent but from a broken data foundation.
What a Real Data Foundation Requires
Building a data foundation for an agent stack is not the same as running a data cleanup sprint. It is an ongoing system with four components:
- Identity resolution: A single canonical identifier for each account, contact, and opportunity that persists across every system in your stack. This is harder than it sounds — the same company may appear as “Acme Corp,” “Acme Corporation,” and “Acme Corp. Inc.” across CRM, enrichment, and billing systems. Agents that cannot resolve identity will work on duplicate records, double-count pipeline, and route leads incorrectly.
- Canonical definitions: A shared, documented definition of every key field that an agent will read or write. “Stage 3” in your CRM needs a precise, written definition tied to observable criteria, not a tribal-knowledge understanding that varies by rep. If an agent is going to update deal stages autonomously, that definition needs to be machine-readable, not just understood by experienced sellers.
- Data contracts: Explicit specifications of what each agent is permitted to read, what it is permitted to write, and under what conditions a write requires human review. A data contract for a CRM hygiene agent might specify: can read all contact fields, can write to company name, phone, industry, and employee count fields when confidence exceeds 0.85, must flag address and ownership changes for human review. Data contracts are your governance mechanism at the data layer — and they are the component most frequently skipped.
- Enrichment integration: A live connection to at least one third-party enrichment source (Clearbit, ZoomInfo, Apollo, or equivalent) that keeps firmographic data current. Agents scoring or routing leads based on stale company size or industry data will produce systematically biased outputs that are difficult to diagnose.
The Unified Buyer Graph Concept
The most operationally mature teams are moving beyond “clean CRM data” toward what practitioners call a unified buyer graph — a structured representation of all signals associated with an account or contact: firmographic data, behavioral signals (web visits, content downloads, product usage), intent signals (third-party intent data, search behavior), and relationship signals (call history, email thread sentiment, deal velocity). The buyer graph is what agents read when making decisions, and its quality directly determines the quality of agent outputs. It is also what makes your agent stack defensible over time — because it is specific to your customers, your history, and your context in a way that no purchased AI product can replicate.
Layer Two in Detail: The Orchestration Engine
If the data foundation is what agents know, the orchestration engine is how they decide. It is the control plane of your agent stack — and in most RevOps deployments, it is where the gap between “agents that work in demos” and “agents that work in production” is determined.
What Orchestration Actually Does
An orchestration layer sits between your data foundation and your individual agents. It performs several critical functions that individual agents cannot perform for themselves:
Routing and triggering: When a qualifying event occurs — a new inbound lead, a deal moving to a new stage, a support ticket from an expansion account — the orchestration layer determines which agents should activate, in what order, with what data context. Without this, you either have agents that fire independently and potentially conflict with one another, or agents that require manual activation and therefore fail to capture time-sensitive signals.
Conflict resolution: Two agents acting on the same record at the same time will produce unpredictable results without arbitration. The orchestration layer maintains awareness of in-flight agent actions and prevents concurrent writes to the same fields by different agents. This is not a hypothetical edge case — in any reasonably active RevOps environment, a CRM hygiene agent and a deal prep agent will frequently want to update the same opportunity record simultaneously.
Confidence routing: Not all agent outputs warrant the same level of autonomy. The orchestration layer should implement confidence thresholds that determine whether an agent action is auto-approved, queued for human review, or blocked entirely. A lead routing decision with 92% model confidence might be auto-executed. The same decision at 67% confidence might surface to a RevOps manager queue for a 30-second approval.
Audit logging: Every agent action — every read, every write, every decision, every human override — should produce a structured log entry. This is not optional. Without audit logs, you cannot debug agent behavior, prove compliance, retrain models on real outcomes, or build the organizational trust required for agents to operate with increasing autonomy over time.
Who Owns the Orchestration Layer?
This is a frequently contested question, and the right answer has become clearer as teams have accumulated production experience. The orchestration layer should be owned by RevOps, not by engineering and not by a single department head. The orchestration layer encodes operational policy — when to route a lead, which criteria trigger a deal review, what defines a forecasting anomaly worth escalating. These are RevOps decisions. Engineering can build and maintain the infrastructure, but the logic should be specified and owned by the people closest to the revenue process.
Teams that hand the orchestration layer to engineering alone end up with technically correct but operationally misaligned systems. Teams that try to build it without engineering support end up with systems that cannot scale. The model that works is a RevOps-owned specification implemented with engineering partnership — and it requires RevOps professionals who understand at least the basic concepts of workflow logic, event-driven triggers, and data dependencies.
The Five High-Value Agents to Build First (And Why the Order Matters)
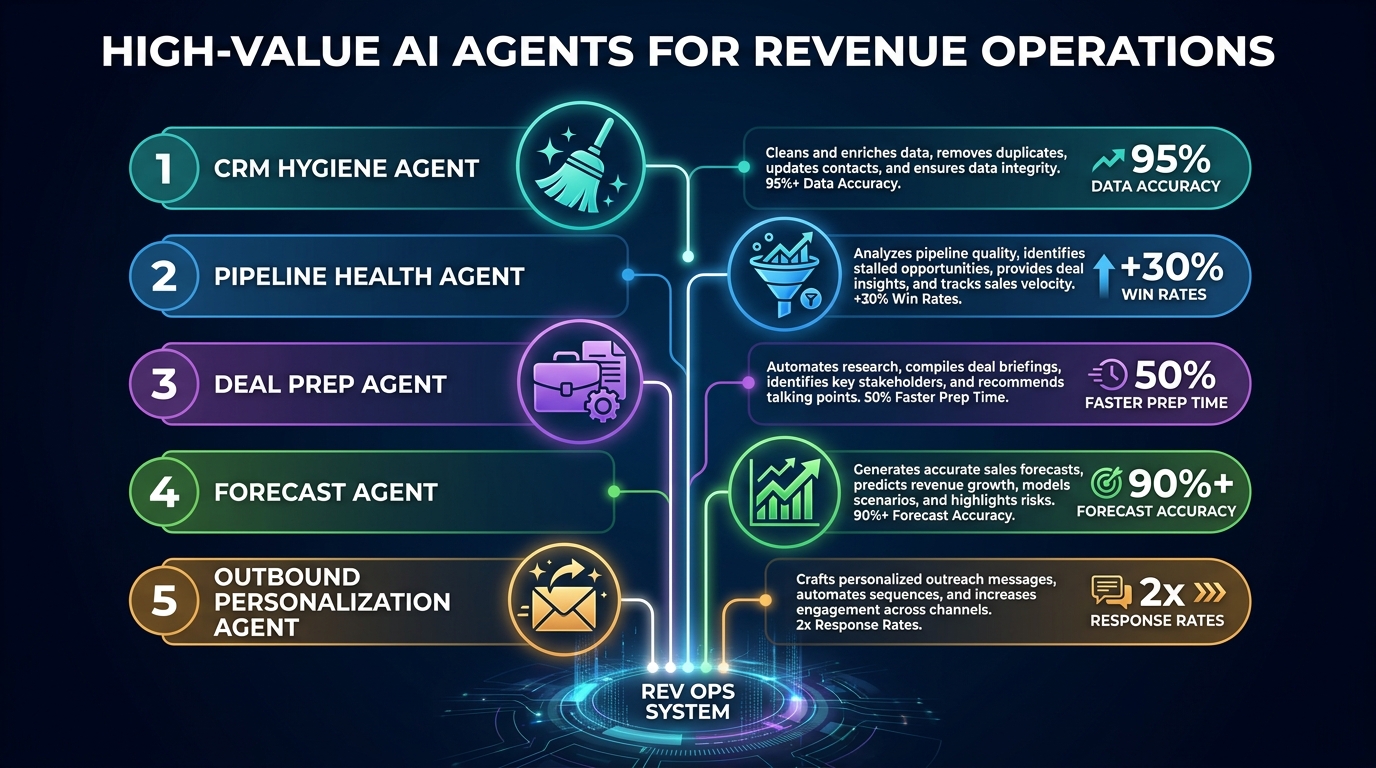
Given the three-layer architecture, the natural question becomes: which agents should you actually build? There are dozens of potential use cases. The following five deliver the highest return in the shortest time for most revenue teams — but the sequencing matters as much as the selection.
Agent 1: The CRM Hygiene Agent
Build this one first, always. The CRM hygiene agent monitors your CRM for data quality issues — duplicates, incomplete records, stale opportunities, missing required fields, and fields that contradict external enrichment data — and either corrects them autonomously or queues them for human review based on confidence and risk.
The reason this is the first agent to build is not that it is the most exciting. It is that every other agent in your stack depends on the quality of CRM data. Building a forecasting agent before a hygiene agent is building on quicksand. The hygiene agent is also an excellent first production deployment because its failure modes are visible and bounded — a badly written update to a contact field is bad, but it is recoverable. A badly written forecast is a business decision.
Practical scope for a first hygiene agent: contact deduplication, company data enrichment against a third-party source, opportunity stage validation against defined criteria, and missing required field flagging. Keep write permissions narrow and review thresholds conservative in the first 30 days.
Agent 2: The Pipeline Health Agent
The pipeline health agent runs continuously against your open pipeline and identifies risk signals: deals that have gone quiet (no activity in the last X days based on deal stage benchmarks), deals where the last contact was with a champion who has since departed the company, deals where the stated close date has slipped more than twice, and deals where multi-threader score has dropped below threshold. It surfaces these signals in a structured format — either directly to the relevant rep, or aggregated to a manager dashboard, or both.
This agent can start as a read-only reporting agent (no CRM writes) and graduate to action-taking once the team has calibrated its signal accuracy. Early wins from this agent tend to be significant and visible — managers frequently report recovering a meaningful portion of slipping deals when risk signals are surfaced early enough, versus the current pattern of discovering at forecast call that a deal has already been lost in practice.
Agent 3: The Deal Preparation Agent
The deal prep agent activates ahead of customer meetings and produces a structured briefing: account history summary, recent news about the prospect company, stakeholder engagement history, open risks, competitive context if known, and recommended discussion points based on deal stage. It synthesizes data from your CRM, call recordings, email history, and external news sources.
This is the agent most immediately appreciated by sellers — it directly reduces the 20–40 minutes of manual pre-call research that experienced reps do for every significant meeting. But it is also the agent most sensitive to data quality issues, which is why it should not be deployed before the hygiene agent has run for at least two to three weeks.
Agent 4: The Forecast Agent
The forecast agent ingests pipeline data, deal health signals, historical close rates by stage and deal type, rep performance patterns, and seasonal factors to produce a structured forecast range. It is not replacing the forecast call — it is providing a quantitative baseline that managers can challenge and adjust with qualitative context that the agent cannot access.
The documented impact of AI-assisted forecasting in RevOps environments is meaningful: teams report forecast accuracy improvements of 20–30% when moving from rep-self-reported forecasting to AI-assisted models with clean data inputs. The key qualifier is “with clean data inputs” — the forecast agent is the one most directly broken by poor data quality, and it is the one most likely to be blamed for model failures that are actually data failures.
Agent 5: The Outbound Personalization Agent
This agent generates personalized outreach content for prospecting and follow-up sequences, using account research, intent signals, recent company news, and previous interaction history. It operates at the top of the funnel where volume is highest and personalization payoff is largest.
Build this one last of the five because it touches external parties — prospects and customers — in a way the other four do not. An error by your CRM hygiene agent stays internal. An error by your outbound agent goes to a prospect’s inbox. The governance requirements are higher, the reputational stakes are higher, and the quality bar needs to be set accordingly.
Build vs. Buy: A Practical Decision Framework
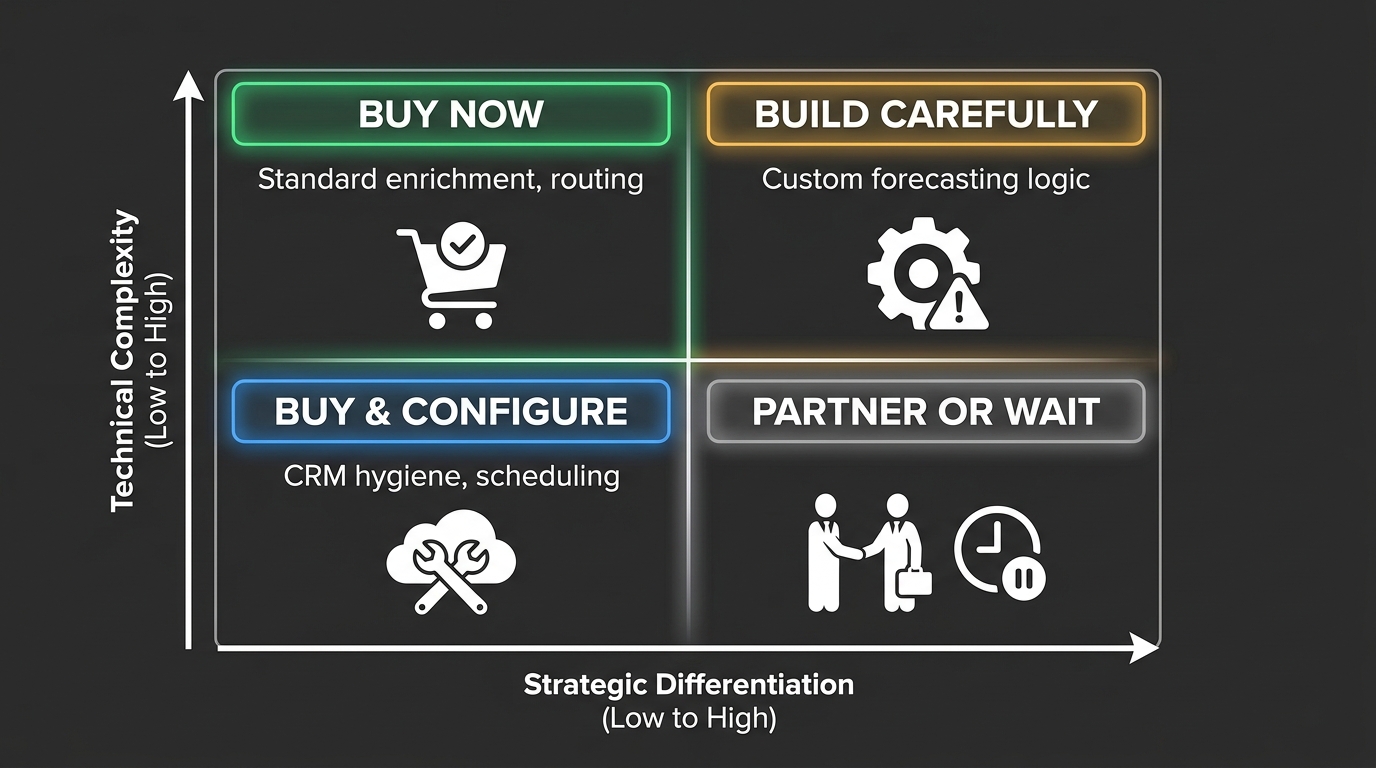
The build-versus-buy question in RevOps AI stacks is not a binary one, and treating it as such leads to expensive mistakes in both directions. The practical framework that emerges from 2026 deployments is: buy the infrastructure, configure the standard workflows, and build selectively for competitive differentiation.
What to Buy Without Hesitation
Standard capabilities with well-defined inputs and outputs are poor candidates for custom builds. These include:
- Data enrichment: Third-party firmographic and intent data providers (Apollo, ZoomInfo, Clearbit, or equivalent). No proprietary advantage in building your own enrichment pipeline from scratch.
- Meeting intelligence: Call recording, transcription, and summary generation (Gong, Chorus, or equivalent). The models in best-in-class tools here are trained on billions of sales calls — custom-built alternatives are not competitive.
- Workflow automation infrastructure: iPaaS connectors (Make, Workato, Zapier enterprise tier) for wiring your tech stack together. The plumbing, not the decision logic.
- Agent frameworks: LangGraph, CrewAI, or similar open-source orchestration frameworks as the technical substrate for your custom agents. You are configuring and extending these, not building competing frameworks.
What to Configure (Not Build)
Many enterprise CRM platforms and emerging RevOps platforms now offer configurable AI features that sit between “out of the box” and “custom built.” Salesforce’s Agentforce, for example, provides a framework for building agents that operate within the Salesforce data model — if your CRM is Salesforce and your process fits its data model well, this is worth exploring seriously before committing to custom agent development. The configuration investment is significantly lower than a custom build, and the integration is native.
The caveat: configurable platform agents are only as good as your CRM data model and process hygiene. If either is a mess, platform agents will surface that mess faster and at larger scale.
What to Build (With a Clear ROI Case)
Build custom agents for workflows that are specific to your business model, your buyer motion, or your product — where off-the-shelf tools cannot be configured to fit and where the competitive advantage of a custom solution is material. Examples that typically warrant custom builds:
- Forecast models that incorporate product usage data from a proprietary data warehouse not natively supported by CRM platform agents
- Routing logic that implements complex territory or specialization rules specific to your go-to-market organization design
- Deal risk models trained on your historical win/loss data, incorporating deal patterns specific to your industry or buyer type
- Churn prediction agents that combine CS signals, product usage, NPS data, and financial signals in configurations unique to your customer success motion
Tools That Matter in 2026
The tooling landscape has consolidated meaningfully. The clearest pattern: Clay for data enrichment and outbound personalization workflows at the top of the funnel; LangGraph or CrewAI for custom multi-agent orchestration where you are building something proprietary; Salesforce Agentforce or HubSpot’s AI agent suite for teams already deeply embedded in those platforms; and a growing category of purpose-built RevOps agent platforms (Clari for forecasting, Outreach for sequence intelligence, Gong for conversation intelligence) for domain-specific agent capabilities. The orchestration layer connecting these is the part that most teams still need to build themselves — no single vendor has solved the cross-platform orchestration problem at a level of maturity that eliminates the need for custom integration work.
Human-in-the-Loop Governance: Where Humans Stay in the Decision Chain
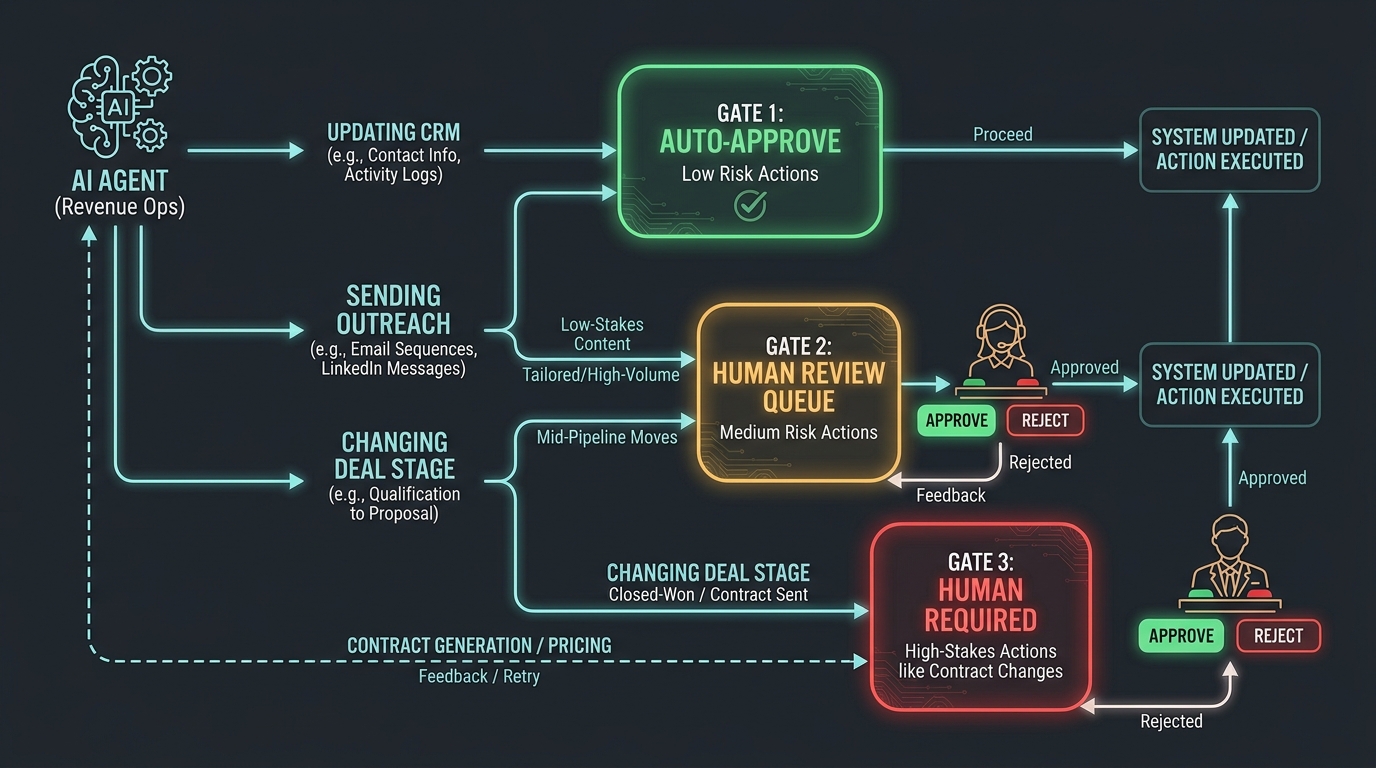
One of the most consequential design decisions in any RevOps agent stack is where humans remain in the loop — and where agents are permitted to act autonomously. Get this wrong in one direction, and you have built a very expensive human-approval queue that saves no time. Get it wrong in the other direction, and you have agents making consequential decisions without oversight, with no mechanism to catch or explain errors.
Designing the Risk Taxonomy
The starting point is a clear taxonomy of agent actions by risk level. Not all agent writes are equal. Updating a contact’s phone number from an enrichment source is low-risk and highly reversible. Sending a proposal to a prospect on behalf of a rep is high-risk and not reversible. Changing a deal’s close date in CRM is medium-risk — it will affect forecast reports that others are reading, but it can be corrected quickly.
A practical three-tier risk taxonomy for RevOps agents:
- Tier 1 — Auto-execute: Low-risk, high-confidence, easily reversible actions. Examples: enriching empty firmographic fields, updating last-activity timestamps, tagging inbound leads with routing attributes. These should execute automatically with no human review and be logged for audit purposes.
- Tier 2 — Human review queue: Medium-risk actions, or low-risk actions where agent confidence is below threshold. Examples: reassigning a lead to a different territory, updating deal stage, merging suspected duplicate accounts. These surface to a named reviewer with one-click approve/reject and a short explanation of the agent’s reasoning.
- Tier 3 — Human required: High-risk or irreversible actions. Examples: sending external communications, modifying contract terms in CPQ, closing or archiving opportunities. Agents propose these actions but cannot execute them — execution always requires explicit human action.
The Trust Ramp
Governance is not a static configuration. The most effective deployments implement a “trust ramp” — they start with very conservative thresholds (more actions routed to human review than strictly necessary) and expand autonomy as agent accuracy is demonstrated empirically. This serves two purposes: it catches edge cases early while the agent is still being calibrated, and it builds the organizational trust that is required for teams to accept autonomous agent actions without second-guessing every output.
A practical trust ramp operates on 30-day cycles. In month one, every Tier 2 action goes to a human reviewer. The reviewer logs decisions, including overrides. At the 30-day mark, the team reviews: what percentage of agent-proposed actions were approved without modification? For which action types? Based on that data, some action types graduate from Tier 2 to Tier 1. Others remain in review, or their criteria are refined. By month three, a well-designed agent should be handling 70–80% of its intended workload autonomously, with the remainder routed appropriately.
Override Logging as Training Data
Every time a human overrides an agent decision, that override is a training signal. A human reviewer who changes an agent-proposed deal stage from “Stage 3” to “Stage 2” with a note that says “missing legal approval” is telling you exactly what signal the agent’s model is not capturing. Override logs should be reviewed systematically — not to blame the agent, but to identify the patterns that should feed into model retraining or criteria adjustment. This feedback loop is what allows an agent stack to improve over time rather than decay.
The Failure Patterns That Kill RevOps Agent Deployments
Field data from 2026 RevOps deployments consistently shows that agent failures are almost never caused by fundamental model inadequacy. The models in use today are capable of performing the RevOps tasks being asked of them. Failures are operational, organizational, and architectural. Understanding the most common patterns is as valuable as understanding the success patterns.
Failure Pattern 1: Scope Creep Before Stability
The most common cause of RevOps agent failure is expanding what an agent does before confirming it does the original thing reliably. A team deploys a CRM hygiene agent that works reasonably well on contact deduplication. Three weeks later, someone in the meeting says “could it also update account ownership when reps change territories?” — and before the original agent has been validated in production, it is handling three more use cases it was not designed for. Scope creep is not just a project management problem — it is an agent reliability problem. Agents handling more cases than they were designed for will fail on the new cases in ways that often corrupt the work they were doing on the original ones.
Failure Pattern 2: No Observability
Agents without observability infrastructure are black boxes. When they work, nobody knows why. When they fail, nobody can diagnose the cause. Production agents require logging of every decision point: what input did the agent receive, what did it decide, what was the confidence score, what action did it take, what was the outcome? Without this, your only diagnostic tool is noticing that something went wrong after the fact — and in RevOps, by the time you notice that pipeline data was corrupted by an agent three weeks ago, the damage to forecast accuracy is already done.
Failure Pattern 3: Cascading Errors
Multi-agent systems introduce a failure mode that single-agent systems do not have: cascading errors. If Agent A produces bad output and Agent B uses that output as its input, Agent B will produce bad output too — and may amplify the original error rather than containing it. In a RevOps context, this looks like: a hygiene agent that incorrectly enriches a company’s industry classification, followed by a lead routing agent that routes the lead to the wrong team based on that incorrect classification, followed by a deal prep agent that prepares industry-specific talking points for the wrong vertical. Each agent in the chain behaved exactly as designed. The error was in the upstream data contract.
The defense against cascading errors is validation checks at every data handoff point — agents should confirm that the inputs they receive meet expected schemas and confidence thresholds before acting on them, rather than assuming upstream agents are always correct.
Failure Pattern 4: Organizational Non-Adoption
A technically sound agent stack that the revenue team does not trust or use is a failed deployment. Non-adoption is a real and common outcome, and it is driven by specific, predictable behaviors: agents that make confident-sounding errors early in the deployment create negative impressions that persist long after accuracy has improved. Reps who see an agent update a CRM field incorrectly once will manually check every agent-written field for months.
The mitigation is a deliberate adoption strategy that begins before deployment: communicate what the agent will do and will not do, show the uncertainty — surface confidence scores, not just recommendations — and create a visible feedback channel so that skeptical users can flag issues and see them addressed. Teams that treat agent adoption as a change management problem from the start see significantly higher utilization rates than teams that treat it as a technical rollout.
Failure Pattern 5: Missing Rollback Capability
Any agent with write access to your CRM must be paired with a rollback mechanism. This is not negotiable. Before deploying an agent that writes data, confirm that you can identify every record it touched in a given time window and restore previous field values. The need for rollback is not hypothetical — even well-designed agents encounter unexpected data conditions and produce erroneous writes. The question is not whether you will need to roll back; it is how quickly you can do it when the need arises.
Measuring What Your Agent Stack Is Actually Doing
Revenue teams are accustomed to measuring people and processes. Measuring AI agents requires a slightly different approach — one that connects agent-level performance metrics to business-level outcomes, rather than treating them as separate measurements.
Two Tiers of Metrics
Every agent should be measured on two tiers simultaneously. The first tier is agent-level metrics: accuracy rates for the specific task (what percentage of enrichment updates were correct when spot-checked?), action volume (how many records did it process this week?), human override rate (what percentage of Tier 2 proposed actions were overridden?), and latency (how quickly did it complete its task from trigger to action?). These tell you whether the agent is performing its function correctly.
The second tier is outcome metrics: how has the business metric the agent was built to influence actually moved? A CRM hygiene agent should be correlated with improvement in data quality scores. A pipeline health agent should be correlated with improvement in forecast accuracy and reduction in late-stage slippage. A deal prep agent should be correlated with increased pre-call engagement and, downstream, improved win rates on deals where reps used the briefings versus those where they did not.
Key Metrics by Agent Type
For practical tracking, here are the metrics that matter most per agent type:
- CRM Hygiene Agent: Data completeness score (percentage of required fields populated), duplicate account rate, field accuracy rate on spot-check sample, weekly records processed.
- Pipeline Health Agent: Deals flagged for risk vs. deals that actually slipped or were lost (precision and recall on risk signals), time-from-flag to rep action, change in late-stage slippage rate.
- Deal Prep Agent: Briefing utilization rate (did the rep open it?), post-meeting CRM update rate (proxy for whether the briefing was useful), win rate on briefed vs. unbriefed opportunities.
- Forecast Agent: Forecast accuracy (Mean Absolute Percentage Error versus actuals), bias direction (consistently high or consistently low), improvement over previous human-only baseline.
- Outbound Personalization Agent: Reply rate vs. non-AI-personalized baseline, quality score from sales managers (sample review), bounce and spam complaint rate.
The Stack-Level Health Dashboard
Beyond individual agent metrics, you need a stack-level health view that tracks the cumulative operational contribution of all agents. The most useful stack-level metrics: total hours of manual work automated per week (derive this from task volume multiplied by average manual completion time), percentage of CRM records touched by at least one agent in the last 30 days, human override rate trend (declining override rate suggests improving accuracy; sudden spike suggests a data or model issue), and agent uptime and error rate.
This dashboard belongs in RevOps’ weekly review, not in an engineering incident tracker. The operational team should own interpretation of these numbers and drive the prioritization of improvements.
The 90-Day Sequencing Map for Building Your Stack
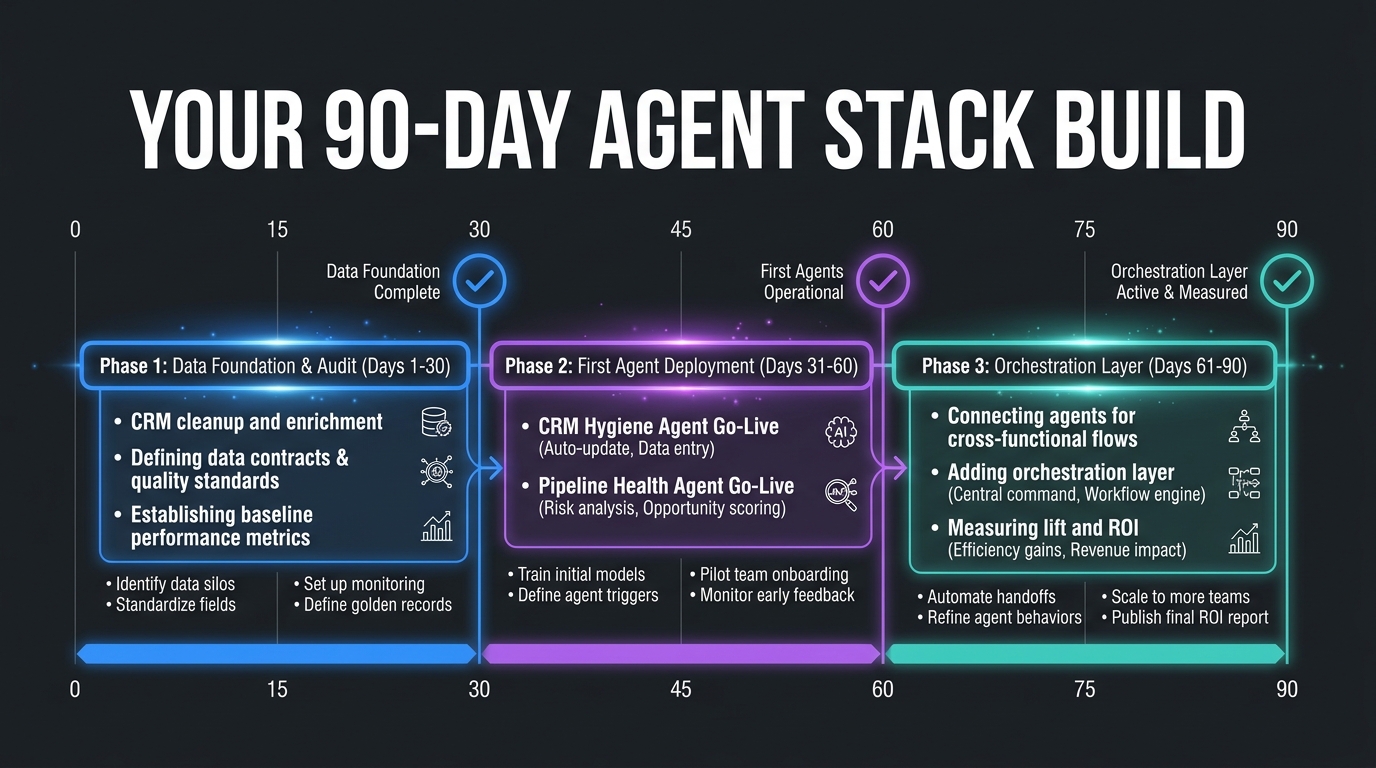
The most common question from RevOps teams moving from intent to implementation: where do we actually start? The following 90-day sequence is derived from the deployment patterns that consistently produce functional stacks versus the patterns that result in expensive restarts.
Days 1–30: Foundation Before Agents
The first 30 days contain zero agent deployments. They contain the work that makes agent deployments possible. Specifically:
- Data audit: Run a systematic CRM data quality assessment. Document completeness rates by object (contacts, companies, opportunities), duplicate rates, field definition inconsistencies, and integration gaps. This audit becomes your baseline for measuring the hygiene agent’s impact.
- Definition standardization: Convene the revenue leadership team to document canonical definitions for your five to ten most critical GTM terms: qualified pipeline, sales-qualified lead, deal stage criteria, at-risk opportunity, and so on. Turn these into written, machine-readable criteria that can be embedded in agent logic.
- Data contract drafting: For each of the five agents you plan to deploy, write a data contract: what it reads, what it writes, under what conditions, with what confidence thresholds. These do not need to be final — they will iterate — but they must exist before an agent touches production data.
- Tooling selection: Finalize your build-versus-buy decisions and begin procurement or setup for the enrichment provider, orchestration framework, and observability tooling you have chosen. Do not begin agent development without this infrastructure in place.
Days 31–60: First Agent in Production
The CRM hygiene agent goes to production in week five, with narrow scope and conservative review thresholds. For the first two weeks, it runs in shadow mode — it logs what it would do but does not write to production systems. This lets you validate its logic against real data before giving it write access.
In week seven, enable writes for Tier 1 actions only, with full logging. Route all Tier 2 proposals to a named RevOps reviewer who checks them daily. Run the first 14-day review at the end of this phase: what was the override rate? Which action types had high override rates (indicating the logic needs refinement)? Which action types had zero overrides (candidates for graduation to Tier 1)?
The pipeline health agent can go into shadow mode in week six, running read-only signal analysis that gets emailed to managers as a “here is what the agent would have flagged” digest. This builds familiarity and lets managers calibrate their expectations before the agent’s outputs are used operationally.
Days 61–90: Orchestration Layer and Second Agent
With the hygiene agent in stable production and the pipeline health agent validated in shadow mode, the focus shifts to two things: wiring the orchestration layer between them, and moving the pipeline health agent to live operational use.
The orchestration layer at this stage does not need to be sophisticated. Its minimum viable version routes events between the two agents, prevents concurrent writes, and aggregates the audit log. It can be built on a lightweight iPaaS connector (Make, Workato) with event triggers and a simple decision table. Sophistication can come later. What matters now is that the concept of an orchestrated stack exists and that you have the operational experience to extend it.
By day 90, you should have: one agent (CRM hygiene) in full production with a 30-day track record, one agent (pipeline health) in live operational use for at least two weeks, a functioning orchestration layer between them, a stack-level health dashboard, and a documented set of criteria for deploying agents 3 and 4 (deal prep and forecast). This is not the finished stack — it is the foundation that makes the rest buildable without the risk of starting over.
What Comes After the First 90 Days
The 90-day mark is not the finish line — it is where the real work of running an agent stack begins. The first three months establish the architecture and the habits. The next 12 months determine whether the stack actually delivers sustained operational value or becomes another piece of revenue tech that gets quietly deprioritized when the initial excitement fades.
The Compounding Effect of Agent-Generated Data
One of the most underappreciated dynamics of a mature agent stack is what happens to your data quality over time. A hygiene agent running daily for six months will have processed and corrected thousands of records. That history — every write, every correction, every human override — is itself a dataset. A team that captures and organizes this data correctly can use it to retrain and improve agent models, build increasingly precise routing rules, and identify systematic process failures that no human would catch in the volume.
The unified buyer graph becomes more valuable with every month of agent operation, because each agent action adds a new signal to the graph: what happened to this account, what stage it was at when it was flagged, how long it took to close or churn, what the deal prep briefing contained when the deal was won. Over time, this data advantage compounds in a way that becomes genuinely difficult for competitors to replicate, because it is built from your specific customer and deal history.
Organizational Design Changes That Follow
Mature agent stacks change what RevOps professionals actually do. Tasks that consumed significant RevOps bandwidth — manual CRM audits, pipeline scrubs, pre-forecast data gathering, territory assignment reviews — are largely automated. The RevOps function shifts toward higher-order work: designing agent logic, interpreting override patterns as diagnostic signals, building the agent governance framework, and translating business requirements into data contracts that agents can act on.
This is a genuine skill transition, and teams that plan for it deliberately will outpace those that assume their existing RevOps team will naturally upskill into this mode. The RevOps operators who thrive in an agent-enabled environment are the ones who understand both the business process deeply and the agent architecture well enough to specify precisely what they need from an automated system.
The Agent Registry
As agent count grows past five, the orchestration layer’s complexity grows significantly. Agents that were independent in the early stack now share data, trigger one another, and need to coordinate on actions affecting the same records. This is where investment in the orchestration layer pays its largest dividends — teams that built it properly early can extend it to handle five, ten, or fifteen agents without fundamental rebuilds.
The practical pattern that emerges in mature stacks is an agent registry — a centralized directory of all agents, their defined scopes, their data contracts, their current performance metrics, and their dependency relationships. The agent registry serves as both operational documentation and the governance mechanism that prevents individual teams from deploying rogue agents that conflict with established ones. It is the organizational layer that makes a collection of individual agents into a coherent, managed system.
Building Something That Actually Runs
Revenue Operations has always been the function responsible for making the revenue engine operate reliably at scale. That responsibility does not change when AI agents enter the picture — it expands. The revenue team’s job is no longer just to design the process and measure its outcomes. It is to design, deploy, govern, and continuously improve a system of autonomous agents that execute the process on their behalf.
That expanded scope requires a different relationship to technology, data, and organizational change. But the underlying principle remains the same: agents that run on bad data, without governance, without measurement, and without organizational adoption are not an AI strategy — they are a sophisticated way to automate failure at scale.
The teams that are building agent stacks that actually work in 2026 share a set of consistent behaviors: they built the data foundation before the agents, they kept initial scope narrow and expanded only based on evidence, they invested in observability and governance infrastructure before deploying to production, and they managed agent adoption as seriously as they managed agent development. None of these behaviors is technically sophisticated. All of them require discipline that is easy to shortcut under organizational pressure to move faster with AI.
The architecture described in this article is not a vendor prescription or a one-size-fits-all template. It is a set of decisions — about sequencing, about governance, about what to build and what to buy — that give your RevOps AI investments the structural foundation to compound rather than collapse. The agents themselves are replaceable as models and tools improve. The data foundation, the orchestration layer, and the governance habits are what make the stack durable.
Key takeaways for RevOps teams building their first agent stack:
- Build the data foundation before the first agent — not after the first failure
- Own the orchestration layer in RevOps, not just in engineering
- Deploy the CRM hygiene agent first; every other agent’s quality depends on it
- Use a three-tier risk taxonomy to calibrate autonomy: auto-execute, human review, human required
- Build a trust ramp over 30-day cycles rather than launching with full autonomy
- Log every agent action, every override, and every outcome — this is your improvement mechanism
- Treat adoption as a change management problem from day one, not a post-launch discovery
- Measure agent performance at both the task level and the business outcome level


