There is a version of this story that sounds deceptively simple: you have SOPs, you have an LLM, you hand one to the other, and agents run your business. That version is wrong — and the gap between it and reality is costing enterprises months of wasted sprints, broken pilots, and agents that hallucinate their way through critical workflows at 3am.
The actual story is an engineering problem, an organizational problem, and a documentation problem, all layered on top of each other. And it is one that most teams only discover after they have already committed to a delivery date.
The global agentic AI market is valued at approximately $7.6 billion in 2026 and growing at a 40%+ compound annual growth rate. Analysts estimate that by 2026, roughly 40% of enterprise applications will include some form of embedded AI agent capability. The demand signal is clear. The execution track record is not: most estimates suggest that 70–80% of agent deployments encounter significant failure modes before reaching stable production, and somewhere between 10–30% of enterprise agent programmes ever scale beyond a single workflow.
The bottleneck is almost never the model. It is the translation layer — the messy, unglamorous work of taking human-authored process documents and rebuilding them into something a machine can actually operate. That translation is what this article is about.
We will walk through the full journey: how to audit your SOPs for agent readiness before touching a model, how to structurally rewrite procedures so an LLM can execute them, how AWS’s open-source Agent SOPs specification approaches the problem, how to decompose complex playbooks into multi-agent architectures, what will go wrong in production and how to engineer around it, and what the human role looks like on the other side of a successful conversion.
This is not a framework overview. This is the engineering work nobody talks about.
The Gap Between “We Have SOPs” and “We Have Agents”
Most organisations that want to build AI agents already have something valuable in the drawer: years of accumulated process knowledge encoded in SOPs, runbooks, policy documents, training manuals, and workflow wikis. The instinct is to use that material directly — to upload the SOP, wrap it in a system prompt, and let the LLM handle execution.
That instinct collides with a hard structural reality: SOPs are written for humans, and humans are extraordinary at filling gaps. A human reading “review the customer complaint and respond appropriately” automatically applies years of judgment, context, institutional knowledge, and social inference that are entirely invisible to the text. They know what “appropriately” means because they were onboarded by a manager, observed senior colleagues, and absorbed the unwritten culture of the organisation over time.
An LLM has none of that implicit context. It will execute on what is written, and it will hallucinate or make arbitrary decisions everywhere the text is silent. The silence in a human SOP is not an omission — it is a reasonable expectation that the reader will fill the gaps intelligently. When you feed that SOP to an agent, every silence becomes a liability.
The Tacit Knowledge Debt
Cognitive scientists and knowledge management researchers have long documented the concept of tacit knowledge — the know-how that practitioners carry in their heads but never fully articulate. In process documentation, this manifests as assumed context that never makes it into the SOP. Things like:
- Threshold judgments — “if the case looks unusual” (what is unusual?)
- Tool preferences — “check the system” (which system? in what order?)
- Relationship logic — “coordinate with the account team” (when? how? what information?)
- Exception handling — “escalate if needed” (what triggers escalation? to whom? in what format?)
When an experienced human encounters any of these phrases, they retrieve the missing information from memory. When an LLM encounters them, it either makes a plausible-sounding guess — which may be catastrophically wrong — or it stalls, loops, or returns an unhelpful generic response.
The first step in any SOP-to-agent programme is honestly accounting for this tacit knowledge debt. It does not disappear just because you are automating the process. It has to be made explicit, documented, and encoded — either into the agent’s instructions, its toolset, or its escalation logic.
The Structural Mismatch
Beyond tacit knowledge, there is a structural problem. Human SOPs are typically written as narrative prose or at best as numbered lists. They are sequential in presentation but non-linear in practice — they assume the reader can jump between steps, refer back to earlier sections, apply parallel judgment across multiple criteria simultaneously, and exercise discretion about which steps are even relevant in a given situation.
LLMs, especially when used as agents with tool access, operate in a fundamentally different execution model. They process instructions sequentially within a context window, they need explicit branching logic (if X, then Y, else Z), they require clearly defined tool contracts (exactly what parameters to pass, exactly what to do with the output), and they need bounded scope (what is in scope for this agent and what is not).
The mismatch between human SOP structure and agent execution architecture is not a minor formatting issue. It requires a substantive rewrite of the underlying process logic.
Why Most SOPs Fail the Agent Readiness Test
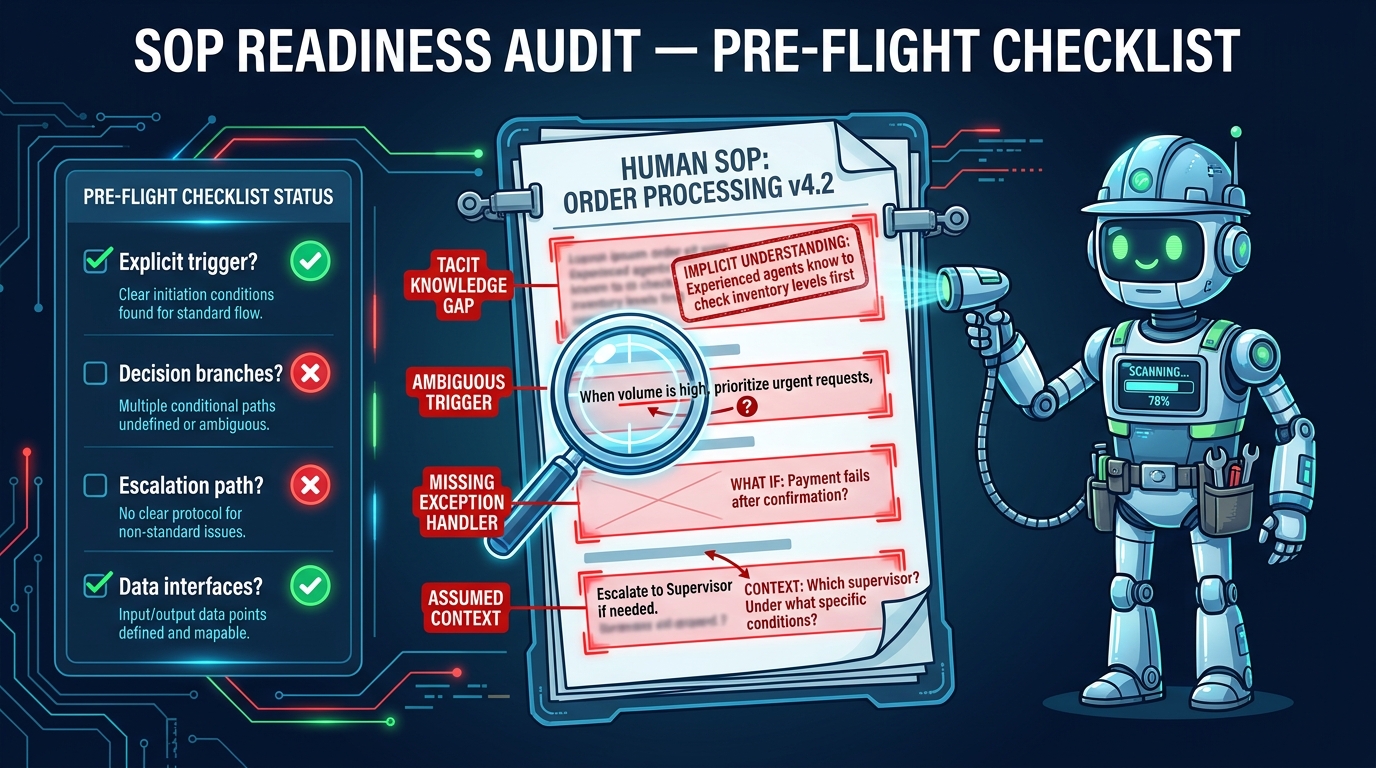
Before any team should write a single line of agent code, they need to run an honest audit of the source material. The SOP readiness audit is not glamorous work — it is more process archaeology than software engineering — but it is the single most effective intervention for reducing agent failure rates downstream.
The Five Dimensions of Agent Readiness
A robust pre-flight audit examines SOPs across five dimensions. Each dimension represents a category of information that an agent needs to execute reliably but that human-authored SOPs routinely leave implicit or incomplete.
1. Trigger Clarity. Does the SOP specify exactly what event or condition initiates the workflow? Vague triggers like “when there is a customer issue” are operationally meaningless for an agent. A ready trigger is specific, observable, and machine-detectable: “when a support ticket with priority flag P1 is created in the ticketing system AND the assigned customer tier is Enterprise.”
2. Decision Branch Completeness. Every decision point in an SOP must have explicit paths for all anticipated outcomes, including edge cases. Most human SOPs cover the happy path and gesture vaguely at exceptions. Agents need the full decision tree: what happens if the API call fails, what happens if the customer is not found in the system, what happens if the response is ambiguous.
3. Data Interface Specification. What data does each step need, where does it come from, and what format should it be in? “Check the customer record” is not a data interface specification. A ready specification identifies the source system, the query parameters, the expected data schema, and what to do if the data is missing or malformed.
4. Escalation and Failure Handling. Human SOPs often treat escalation as an afterthought. Agents need escalation logic that is at least as detailed as the happy path — precise conditions that trigger escalation, the designated escalation target (human queue, different agent, notification system), the information to include in the escalation, and what the agent should do while waiting for resolution.
5. Scope and Authority Bounds. What can this agent do, and what is it explicitly prohibited from doing? Agents without clear authority bounds will attempt to solve problems using any tool available to them, which can lead to unintended actions — sending emails that should not be sent, updating records that should remain locked, or initiating transactions that require human approval.
Running the Audit in Practice
The most effective audit technique is to walk the SOP step by step and ask the question: “If I were a robot with no prior context, could I execute this instruction exactly?” Every step that requires judgment, assumed knowledge, or contextual interpretation is a gap that must be addressed before conversion.
Map the gaps into three categories: things that can be made explicit through documentation, things that require tool access to resolve at runtime, and things that genuinely require human judgment and should be modelled as escalation points. The last category is the most important — not every gap needs to be automated away. Some gaps exist because the decisions are genuinely complex, high-stakes, or variable, and the right answer is to escalate to a human, not to ask the LLM to guess.
Teams that complete this audit rigorously typically find that their SOPs are 30–50% incomplete in the ways that matter for agent execution. That is not a failure of the SOP authors — it is a natural consequence of writing for human readers. Completing the gaps before conversion is the single most important quality gate in the entire process.
Rewriting SOPs Into Agent-Shaped Procedures
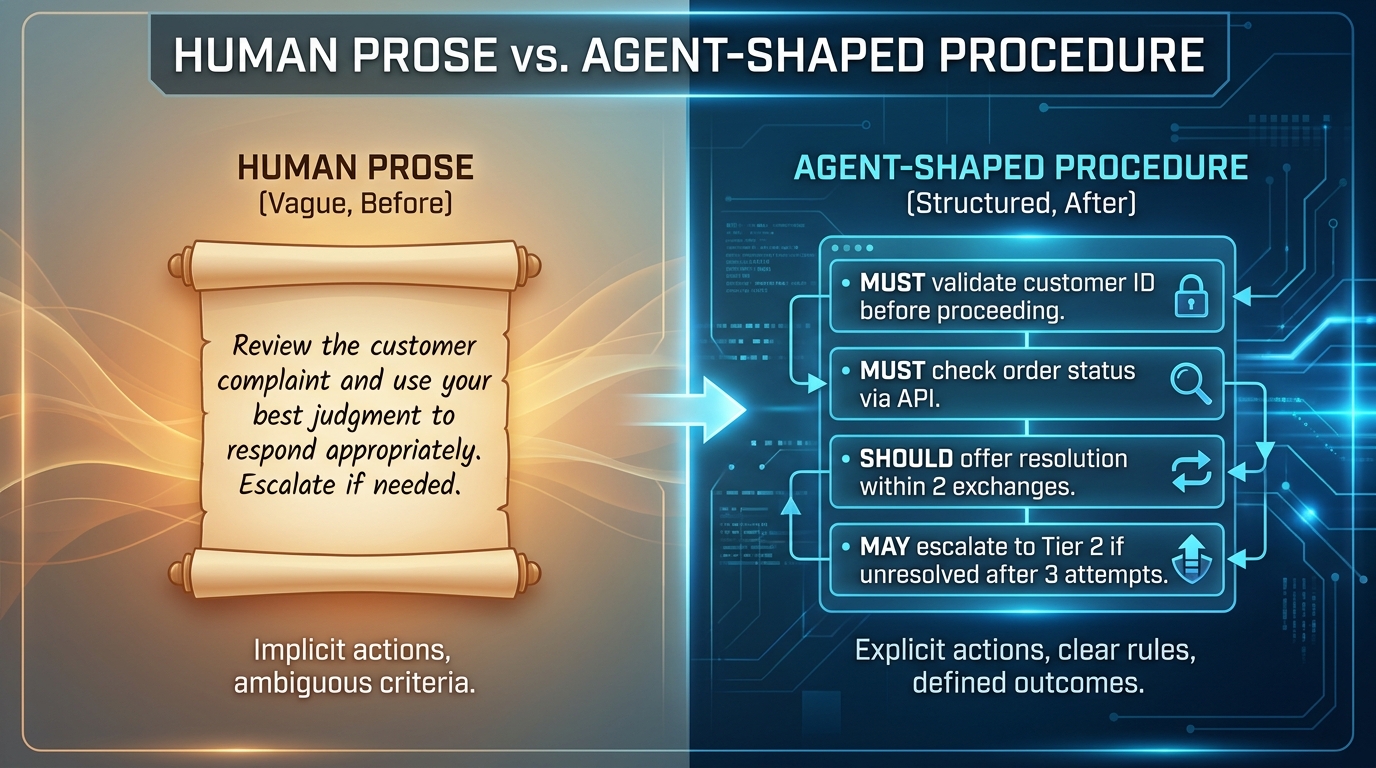
Once the readiness audit is complete and the gaps have been documented, the next task is the structural rewrite. This is where human-authored prose gets rebuilt into what practitioners are beginning to call Agent Operating Procedures (AOPs) — a more precise, machine-executable form of process documentation.
The distinction matters. A Standard Operating Procedure tells a human what to do. An Agent Operating Procedure tells an agent system how to behave, including what tools to use, what constraints to respect, how to branch at decision points, and what to do when things go wrong. They look superficially similar but serve fundamentally different execution models.
The Anatomy of a Well-Formed Agent Operating Procedure
A well-formed AOP has six structural components, each serving a specific function in agent execution:
- Header block: Purpose, scope, version, owning team, and last validated date. Agents need to know what problem they are solving and within what boundaries.
- Trigger definition: The precise conditions that initiate this procedure, including all input parameters and their expected formats.
- Precondition checks: What must be true before the agent begins executing the main procedure. Missing precondition checks are a major source of mid-workflow failures.
- Step sequence with explicit branching: Each step specifies the action, the tool or system to use, the expected output, and the branch condition that determines the next step.
- Exception and escalation handlers: Explicit procedures for every anticipated failure mode, including what information to surface and what state to preserve for handoff.
- Postcondition and completion: What must be true when the procedure is complete, what output or artefact to produce, and where to route it.
Writing for Execution, Not Explanation
The most common mistake in the rewrite phase is confusing explanation with instruction. Human SOPs are often written to explain why a process works a certain way — they include rationale, background, and contextual colour. For agents, this material is noise. The AOP should contain only instructions that the agent must act on.
Remove all explanatory prose. Convert every passive or ambiguous verb (“should consider,” “may need to,” “it is important to check”) into a specific, imperative action with a defined actor, tool, and success criterion. If a step cannot be rewritten this way, it is a signal that the step contains hidden judgment that needs to be made explicit or escalated.
One useful test: if you removed every human being from the loop, could the agent complete the procedure correctly using only the AOP and its tool access? If the answer is “no,” you have not finished the rewrite.
The RFC 2119 Model: MUST, SHOULD, and MAY as Agent Policy
One of the most practically useful developments in agent SOP design in 2026 has been the adoption of RFC 2119 requirement keywords as a control layer within agent instructions. Originally developed for internet standards specification, the MUST/SHOULD/MAY framework maps surprisingly well onto agent policy design.
AWS’s open-source Agent SOPs specification — integrated with the Strands Agents framework released in 2026 — uses this approach explicitly. SOPs are authored in structured Markdown with RFC 2119 keywords embedded as policy tiers:
- MUST / MUST NOT — Hard constraints, non-negotiable. These map to code-enforced guardrails. If the agent cannot comply, it must halt and escalate. Example: “The agent MUST verify customer identity before accessing account data.”
- SHOULD / SHOULD NOT — Default behaviour with documented exceptions. The agent is expected to follow these unless there is a specific reason not to, and deviations must be logged. Example: “The agent SHOULD offer a resolution within two conversational exchanges.”
- MAY — Optional actions, model-assisted choices. The agent has discretion here and can use LLM reasoning to decide. Example: “The agent MAY offer a complimentary discount on the next order if the customer expresses dissatisfaction.”
Why This Framing Works for Enterprise Agents
The MUST/SHOULD/MAY structure solves a problem that purely free-form prompting cannot: it gives the orchestration layer a machine-readable policy hierarchy that can be enforced independently of the model’s outputs. MUST constraints can be implemented as pre- and post-execution validators — deterministic code that verifies the agent’s actions before they take effect, regardless of what the model decided.
This matters enormously in regulated industries. A financial services firm running an agent on account modification workflows cannot rely on the model to reliably remember that it must not modify accounts above a certain value without a second approval. That constraint needs to live in code, not in the system prompt. The MUST/SHOULD/MAY framework makes this separation explicit and auditable.
The SHOULD tier is where most of the practical work happens. These are the behaviours you want by default but that need to flex in certain conditions — the “use your judgment but within these rails” category. For audit and compliance purposes, logging every SHOULD deviation is valuable: it creates a traceable record of every time the agent made an exception and why.
The MAY tier is where genuine LLM reasoning adds value. These are the decisions that benefit from natural language understanding, contextual inference, and creative problem-solving — exactly the things LLMs are good at. By explicitly carving out a space for model discretion, the RFC 2119 approach lets you use the model’s capabilities where they are appropriate without letting them bleed into territory that requires determinism.
Implementing the Framework in Practice
Teams adopting this approach typically author their AOPs in Markdown, using section headers to define procedure phases and inline MUST/SHOULD/MAY annotations to mark policy tiers. These documents can then be injected as structured system prompts into agent frameworks like Strands, LangGraph, or AutoGen — or parsed programmatically to generate validation logic.
The key implementation detail is ensuring that MUST constraints are enforced by something other than the model itself. The model is a probabilistic system; it will occasionally fail to follow even clearly stated instructions. Hard constraints need to live in a deterministic wrapper — a validator that checks agent actions before they execute and blocks non-compliant behaviour regardless of model output.
Decomposing Playbooks into Multi-Agent Architectures
Once you have a well-formed AOP, the next architectural question is whether to implement it as a single agent or decompose it across multiple specialised agents. For simple, linear workflows with fewer than six or seven distinct steps and a single tool domain, a single agent is often the right answer. For anything more complex — and most enterprise SOPs are more complex — a multi-agent architecture will be more reliable, more maintainable, and easier to test.
The decomposition decision is driven by three factors: task heterogeneity (does the SOP span multiple tool domains or data sources?), decision complexity (does it contain multiple high-stakes decision points that benefit from isolation?), and parallelisation opportunity (can multiple steps run concurrently to improve throughput?).
The Standard Decomposition Pattern
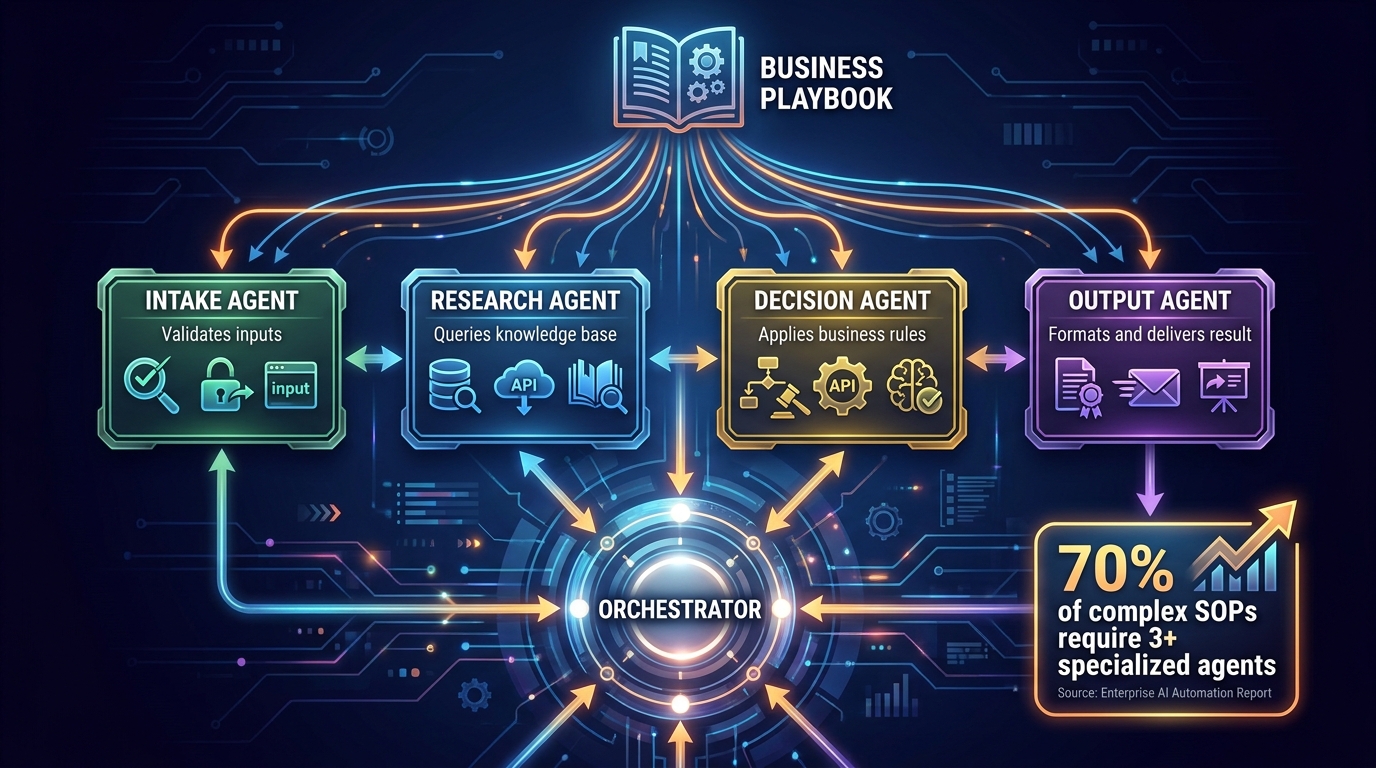
Most complex enterprise playbooks decompose naturally into a four-agent pattern:
The Intake Agent handles the entry point of the workflow: validating the trigger, checking that all required inputs are present and correctly formatted, performing identity or authentication verification where required, and routing to the appropriate workflow branch. The intake agent never executes business logic — it is purely concerned with “can we start, and what kind of start is this?”
The Research Agent (or set of agents) handles information gathering: querying internal systems, retrieving customer records, checking policy databases, calling external APIs, or reading from knowledge bases. Research agents are typically read-only and operate within tightly scoped tool permissions. They produce structured data outputs that downstream agents consume.
The Decision Agent applies business rules and logic to the data gathered by the research phase. This is typically the agent that does the most LLM-heavy reasoning — weighing conditions, applying policy, generating recommendations or responses. The decision agent’s outputs are usually structured artefacts (JSON objects with specific fields) rather than free-form text.
The Output Agent takes the decision agent’s structured output and translates it into the appropriate format and destination: a customer-facing email, a CRM record update, a ticket status change, a notification to a human queue. The output agent is where personalisation and tone happen — where natural language generation is genuinely useful.
The Orchestrator Layer
Coordinating this multi-agent system is an orchestrator — a component (which may itself be an LLM or a deterministic state machine) responsible for managing the sequence of agent calls, passing state between agents, handling inter-agent errors, and enforcing the overall policy constraints of the original playbook.
A key design decision is whether the orchestrator should be model-based (an LLM that reasons about what to do next) or rule-based (a deterministic state machine that follows a predefined flow graph). For compliance-sensitive workflows, rule-based orchestration is almost always preferable: it is auditable, predictable, and cannot be “persuaded” by the model to deviate from the approved process. Model-based orchestrators are appropriate for genuinely open-ended workflows where the sequence of steps cannot be determined in advance.
State management between agents deserves particular attention. Each agent transition should produce a structured context object containing the current state of the workflow, the data gathered so far, and any flags or conditions set by upstream agents. Passing state through natural language (agent A writes a summary that agent B reads) is a reliability anti-pattern — it introduces interpretation errors at every handoff. Use structured data objects with defined schemas.
The Failure Modes Nobody Warns You About

Production agent deployments encounter failure in ways that rarely appear in demos or pilot environments. The demo environment has clean data, cooperative APIs, limited scope, and a human engineer nearby to intervene. Production has none of these luxuries. Understanding the failure mode taxonomy before you ship is the difference between a recoverable incident and a catastrophic one.
Research into 2026-era production agent deployments suggests that 70–95% of production agent runs encounter at least one meaningful failure mode. The question is not whether your agent will fail but whether your architecture contains that failure before it causes harm.
Hallucinated Tool Calls
This is the failure mode that gets the most attention and the least effective engineering response. When an LLM agent cannot find a clear path to completing a task, it will sometimes invoke tools that do not exist, pass parameters that make no sense, or construct API calls that are syntactically plausible but semantically wrong.
The engineering response is not better prompting — it is structural. Tool schemas should be designed with the principle of minimum necessary surface area: expose only the tools the agent needs for this specific workflow, with parameter validation that rejects malformed calls before they reach the downstream system. Implement a tool call sandbox in staging that logs every tool invocation and allows manual review before equivalent patterns are permitted in production.
Runaway Loops
Agents can get stuck in loops — attempting an action, receiving an error, re-attempting in a slightly different way, receiving another error, and repeating indefinitely. Without explicit loop detection and circuit breakers, these loops can run until they exhaust your token budget, hammer a downstream API into rate limiting, or corrupt state that other workflows depend on.
The mitigation is architectural: every agent workflow needs a maximum iteration count, a time-to-live, and an explicit failure state that escalates to a human queue rather than retrying. The failure state should preserve the complete workflow context so that a human reviewer can understand exactly what the agent attempted and where it got stuck.
Context Window Overflow
Complex multi-step workflows accumulate context — conversation history, tool outputs, intermediate results, error messages. As this context grows, it can exceed the model’s context window, causing earlier instructions to be silently dropped. The agent then operates without its original instructions, producing behaviours that are difficult to diagnose because there is no error — the model simply forgets its constraints.
The design response is aggressive context management: summarise completed steps rather than carrying their full outputs, use structured state objects rather than conversation history to pass information between steps, and implement context length monitoring that triggers a checkpoint-and-resume behaviour before the window is exhausted.
Missing Escalation Paths
One of the most insidious failure modes is the agent that encounters a situation it cannot handle and defaults to a plausible-sounding response rather than escalating. From the outside, this looks like successful task completion. The customer gets an answer, the ticket gets closed, the CRM gets updated — but the answer was wrong, the resolution was inappropriate, and the update introduced an error into the record.
Every AOP needs explicit escalation criteria — not just a general instruction to “escalate when needed” but specific, machine-detectable conditions that trigger escalation. If the conditions for escalation are not deterministic, the model will judge on a case-by-case basis, and that judgment will be inconsistent.
Silent Failures
The most dangerous failure mode is the one you do not detect. Silent failures occur when an agent completes a workflow, produces output, and records success — but the output is subtly wrong in a way that does not trigger any error condition. These accumulate over time and surface as data quality problems, customer complaints, or compliance failures weeks or months later.
The only effective defence against silent failures is output validation: structured checks that compare agent outputs against expected formats, value ranges, business rules, and consistency constraints. For high-stakes workflows, this means implementing a separate evaluation agent or rule-based validator that reviews each output before it is committed to the system of record.
The Agent Control Plane: Guardrails, Observability, and Governance

The single biggest differentiator between teams that successfully operationalise agent systems and those that cycle endlessly through failed pilots is the presence — or absence — of an agent control plane. This is the layer of infrastructure above the agents themselves that provides observability, policy enforcement, cost management, and governance. It is not optional for production workloads. It is the foundation everything else runs on.
Structured Logging and Trace Trees
Every agent action must be logged in a structured, queryable format. Not natural language summaries — structured event records with timestamps, agent IDs, tool names, input parameters, output values, token counts, latency, and any policy flags triggered. These logs serve three functions: debugging (understanding what happened in a failed run), auditing (demonstrating to compliance teams that the agent operated within its defined boundaries), and evaluation (measuring drift from expected behaviour over time).
Trace trees — visualisations that show the complete execution path of a workflow run — are particularly valuable for multi-agent architectures. When a complex workflow fails, understanding exactly which agent at which step produced the problematic output is the first step toward resolution. Without trace trees, debugging a multi-agent system is an exercise in guesswork.
Teams with mature observability infrastructure report catching failures approximately six times faster than teams relying on downstream symptom detection (customer complaints, data quality alerts). The investment in logging infrastructure pays back in the first serious incident.
Policy Enforcement and Circuit Breakers
Guardrails need to live in the control plane, not in the model prompt. Prompt-based guardrails — “do not do X” — are unreliable because the model can be distracted, confused, or simply probabilistically off-target on any given run. Control plane guardrails are deterministic checks that run before and after each significant agent action.
Pre-execution guardrails check that the proposed action (tool call, record update, communication send) is within the defined policy bounds before allowing it to proceed. Post-execution guardrails check that the actual output conforms to expected format, scope, and value constraints before committing it.
Circuit breakers are the control plane’s emergency shutoff: conditions that, when triggered, pause the agent, preserve state, and route to a human queue. Common circuit breaker conditions include consecutive error rates above threshold, anomalous token consumption, unexpected tool call patterns, and output values outside expected ranges. Circuit breakers should be designed to be triggered conservatively — it is better to escalate a case that the agent could have handled than to let a runaway agent cause harm.
Evaluation Suites and Continuous Quality Management
Agent behaviour drifts. Models get updated, downstream APIs change, business rules evolve, and edge cases accumulate in production that were never anticipated in design. Without systematic evaluation, this drift goes undetected until it causes a meaningful failure.
An evaluation suite for a SOP-derived agent should include: a library of representative test cases drawn from historical workflow data, including a healthy representation of edge cases and exception scenarios; automated scoring against expected outputs; regression tests that run on every deployment; and a monitoring dashboard that surfaces statistical changes in output distributions over time.
The most sophisticated teams treat agent evaluation as a continuous process, not a pre-launch gate. They measure not just task success rates but output quality dimensions: adherence to policy, appropriate escalation rate, resolution consistency, and downstream outcome metrics (did the customer problem actually get resolved?). These downstream metrics are the hardest to instrument but the most informative about real-world performance.
What Actually Happened: Enterprise Conversion in Practice
The ROI evidence from enterprises that have completed SOP-to-agent conversions in 2025–2026 is real but highly variable. The range reported across customer service and finance operations spans 20–60% cost reduction on targeted workflows, 30–80% cycle time reduction on automatable steps, and payback periods ranging from three months to over a year. The variance is almost entirely explained by how thoroughly teams completed the upfront work — the audit, the rewrite, the control plane — before shipping.
Customer Service: Where the Conversion Is Most Mature
Customer service has become the canonical domain for SOP-to-agent conversion, and the patterns are well-established enough to generalise. The most successful deployments follow a consistent architecture: agents handle the 50–65% of inquiries that fall within well-defined procedural scope (order status, return initiation, standard account changes, billing clarification), while human agents handle the remainder. Resolution time on agent-handled cases drops by 25–40%. Customer satisfaction scores typically show a very small delta — approximately 0.2 points on a 5-point scale — compared to human resolution, well within acceptable tolerance for most organisations.
The critical success factor in customer service deployments is the clarity of the routing logic at the intake layer. Agents that attempt to handle cases outside their competency scope cause disproportionate damage — a customer who receives a wrong or inappropriate agent response is significantly harder to recover than one who waited in a human queue. The intake agent’s conservatism is a feature, not a limitation.
Finance Operations: High Stakes, High Structure
Finance operations present a different profile: lower volume than customer service but much higher per-transaction stakes. SOPs in accounts payable, invoice processing, reconciliation, and exception handling are typically well-documented (finance teams tend to have strong process hygiene), but they carry regulatory and audit requirements that make the control plane non-negotiable.
Finance deployments that succeed tend to use agents for the structured, rule-based portions of workflows — invoice data extraction, matching against purchase orders, flagging discrepancies, routing for approval — while keeping humans in the loop for any action that commits funds or modifies authoritative financial records. The automation rates are typically lower (40–60% of workflow steps automated), but the cycle-time improvements are significant: organisations report 5–6x throughput improvements on processing tasks, and dramatic reductions in processing backlogs.
The most commonly reported failure pattern in early finance deployments is insufficient exception taxonomy. Finance workflows have a large and unpredictable tail of exception types — unusual vendor formats, multi-currency edge cases, partial payments against split invoices. Agents trained on the happy-path SOP perform well on standard cases and fail unpredictably on exceptions unless the exception handlers are as carefully designed as the main flow.
The Quiet Wins: Internal Operations and Knowledge Work
Beyond customer service and finance, a quieter category of SOP-to-agent conversion is delivering consistent returns: internal operations workflows. HR onboarding steps, IT provisioning sequences, compliance reporting workflows, and document routing procedures are all highly procedural, relatively low-risk (errors are usually correctable), and plagued by manual effort. Organisations converting these workflows report savings of 2,000–5,000 staff hours per year per workflow — numbers that are unsexy to announce but compound meaningfully across a portfolio of ten or twenty automations.
The Human Role After the Conversion

One of the most important — and consistently underplanned — aspects of any SOP-to-agent programme is what happens to the humans who previously executed the SOP. The answer is more interesting, and more constructive, than the standard anxiety narrative suggests.
In successful deployments, the human role does not disappear. It shifts. And the shift is significant: from execution to design, supervision, and exception handling. This is not a euphemism for workforce reduction — it is a genuine change in the nature of the work, and organisations that plan for it deliberately tend to see faster adoption and better outcomes than those that treat it as a post-launch concern.
The Process Designer Role
Someone has to maintain the AOPs that drive the agents. As business conditions change, regulations update, systems evolve, and edge cases accumulate in production, the AOPs need to be revised, tested, and redeployed. This is skilled work — it requires an understanding of both the business process and the execution constraints of the agent system.
The most effective approach is to train domain experts (who understand the business process) to work alongside engineers (who understand the execution architecture) in maintaining and evolving the AOPs. Domain experts contribute the process knowledge that engineers lack; engineers contribute the technical constraints that domain experts need to understand. Neither can do this work effectively alone.
Organisations that invest in this hybrid role — variously called AI process owners, agent operators, or automation architects — report significantly faster iteration cycles and fewer production incidents than those who leave AOP maintenance solely to engineering teams.
The Escalation Handler Role
Well-designed agents surface their hard cases to humans rather than guessing through them. The escalation queue — the stream of cases the agent cannot confidently handle — becomes a new type of work queue for human operators. Critically, this queue tends to be more cognitively demanding than the general case volume it replaces: the easy, repetitive cases are handled by the agent, and what arrives for human review is the genuinely complex, unusual, or high-stakes subset.
This is a meaningful change in the skill profile required for the role. Handling escalations from an agent requires the ability to quickly understand what the agent attempted, what it found, why it escalated, and what the appropriate resolution is — often drawing on institutional knowledge and judgment that is precisely the tacit knowledge that could not be encoded in the AOP. Escalation handlers need training in how to read agent trace data, how to communicate resolutions back into the system, and how to identify patterns in escalations that suggest the AOP needs updating.
The Continuous Improvement Loop
The most valuable human contribution to an agent system is not execution — it is feedback. Every escalation represents a data point about a gap in the AOP. Every output quality review surfaces a pattern about agent behaviour. Every production incident teaches something about failure modes that were not anticipated in design.
Organisations that build systematic feedback loops from human reviewers back into AOP development turn their agent systems into continuously improving assets rather than static automations. The agents get better as the AOPs improve; the AOPs improve as humans review agent behaviour; the humans get better at reviewing as they develop deeper familiarity with the system. This is the compounding return that justifies the upfront investment in doing the conversion properly.
Building Your Conversion Roadmap: Where to Start and What to Prioritise
With the full picture in view, a practical question remains: how should an organisation sequence this work? The temptation is to start with the most complex, high-value workflow — the one that will generate the biggest headline ROI if it succeeds. That temptation should be firmly resisted.
Start with the Highest-Volume, Lowest-Variance Workflow
The first SOP-to-agent conversion should be chosen for learnability, not impact. Pick a workflow that is high volume (so you get lots of evaluation data quickly), low variance (the happy path is the overwhelming majority of cases), and low-stakes-per-error (mistakes are visible, correctable, and do not have irreversible consequences). This combination lets your team build competency in every phase of the conversion process — audit, rewrite, architecture, control plane, evaluation — while the blast radius of errors remains manageable.
The institutional knowledge gained from one successful conversion is more valuable than any ROI number from a single workflow. Teams that complete a clean first conversion develop the muscle memory, the tooling, and the cross-functional trust that makes every subsequent conversion faster and more reliable.
Build the Control Plane Once, Use It Everywhere
The logging infrastructure, the evaluation framework, the guardrail pattern, and the escalation queue are not workflow-specific — they are platform assets. Investing in building them properly for the first conversion means every subsequent workflow gets them for free. This is the leverage point that separates teams running a portfolio of effective agents from teams running a collection of isolated automations.
Treat your control plane as a product with its own roadmap, ownership, and quality standards. It is the infrastructure that makes your agent programme scale.
Sequence Toward Complexity, Not Toward It
After the first successful conversion, sequence subsequent workflows in order of increasing complexity — more decision branches, more tool integrations, higher per-error stakes. By the time your team reaches the workflows that genuinely require sophisticated multi-agent orchestration, they will have the skills, the infrastructure, and the institutional confidence to execute them well.
Organisations that try to start with complex, high-stakes workflows often spend six to twelve months in a struggling pilot that eventually gets shelved. The same organisations, had they started with lower-complexity conversions and built toward the complex case, typically deliver the sophisticated workflow successfully within the same timeframe.
Conclusion: The Unglamorous Work That Determines Everything
The promise of turning SOPs into executable agents is real. The 20–60% cost reductions, the 30–80% cycle time improvements, the 5,000 hours of saved staff time per year — these numbers exist in production deployments. They are not marketing projections.
But they are the output of a process that is far more demanding than the demo suggests. Before you write your first line of agent code, you need to audit your SOPs for the gaps that human readers fill with tacit knowledge. Before you ship your first agent, you need to rewrite that SOP into an agent-shaped procedure with explicit triggers, decision trees, tool contracts, and escalation logic. Before you call your first deployment a success, you need a control plane that can observe, constrain, and evaluate agent behaviour over time.
None of this is the part of the story that gets told at conferences. The part that gets told is the demo — the smooth agent that walks through a workflow on clean test data with a human engineer nearby. The part that does not get told is the four weeks of SOP archaeology that preceded it, the three redesigns of the exception handling logic, and the three incidents in staging that shaped the circuit breaker thresholds.
The teams winning with agentic AI in 2026 are not necessarily the ones with access to better models or better frameworks. They are the ones who understood that the hard work is in the translation — and who did that work before they shipped.
Key Takeaways
- Audit before you automate. Run a five-dimension readiness check on every SOP before converting it — trigger clarity, decision completeness, data interfaces, escalation logic, and authority bounds. Expect to find 30–50% incompleteness.
- Rewrite for execution, not explanation. Convert prose SOPs into Agent Operating Procedures with explicit steps, branching logic, and tool contracts. Remove all explanatory context that does not drive agent action.
- Use RFC 2119 tiers as policy architecture. MUST constraints go in code. SHOULD behaviours are logged defaults. MAY decisions are the space for genuine LLM reasoning.
- Decompose complex workflows into specialised agents. Intake, research, decision, and output agents each do one thing well. State passes between them as structured data, never as natural language summaries.
- Design for failure, not just success. Build explicit handlers for hallucinated tool calls, loops, context overflow, missing escalation paths, and silent failures before you ship.
- Build the control plane first. Logging, guardrails, evaluation, and circuit breakers are platform infrastructure, not per-workflow add-ons. Invest in them once and every subsequent conversion benefits.
- Sequence toward complexity. Start with high-volume, low-variance, low-stakes workflows. Build competency before you build ambition.
- Invest in the human role transition. Process designers and escalation handlers are new roles, not old roles with less work. Plan for them deliberately and train for them specifically.