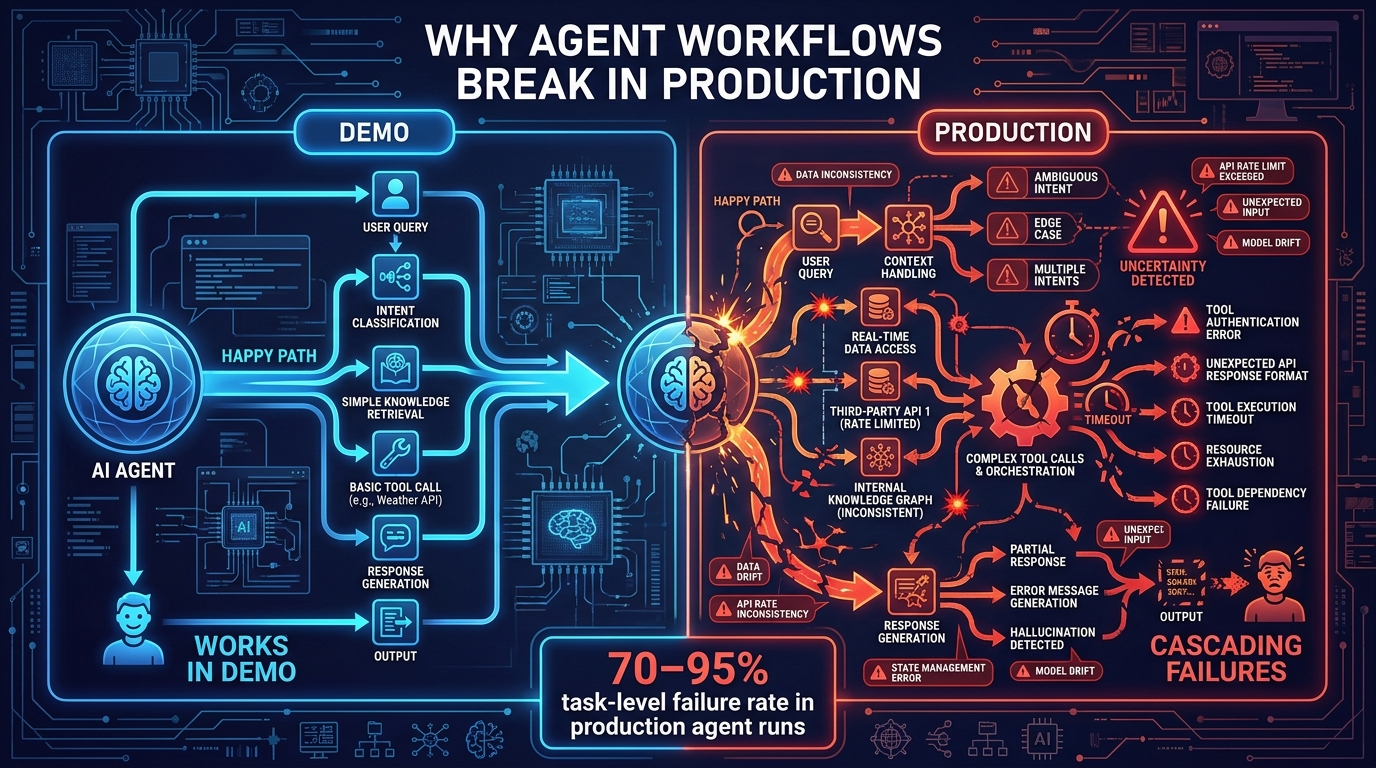

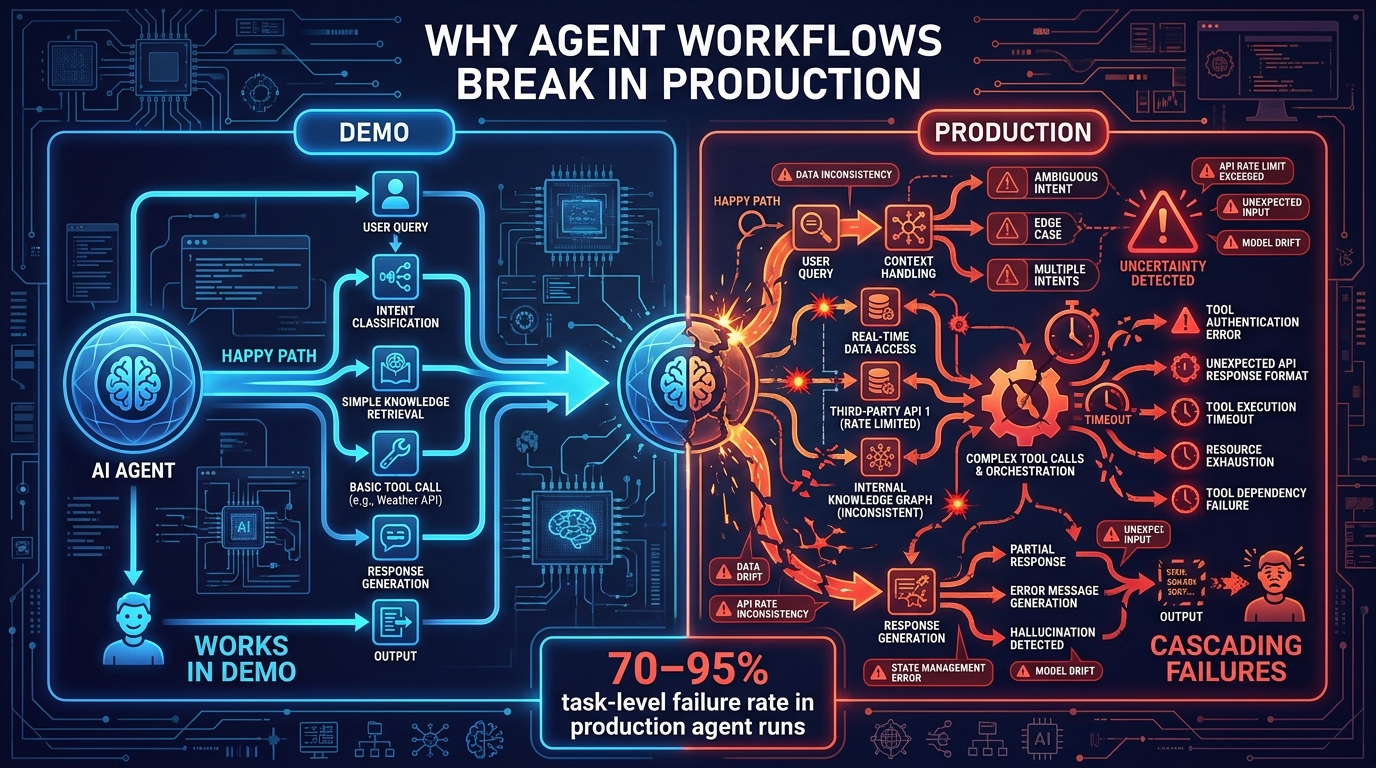
There is a moment almost every engineering team encounters after shipping their first AI agent workflow to production. The demo worked. The internal pilot looked promising. Then real traffic arrived — unpredictable inputs, slow external APIs, unexpected tool responses, edge cases the prompt never anticipated — and the whole thing quietly fell apart. Not with a loud error. With a silent, uneventful non-answer that cost the business hours, or money, or both.
This is the central problem of agentic AI in 2026: the gap between what works in a notebook and what works under real operating conditions is wider than most teams expect, and it is not primarily a model quality problem. Analysis from across the industry now attributes 30–40% of abandoned agentic AI projects to orchestration and architecture failures — not to the underlying LLMs themselves. The models have gotten good enough. The engineering discipline around them frequently hasn’t.
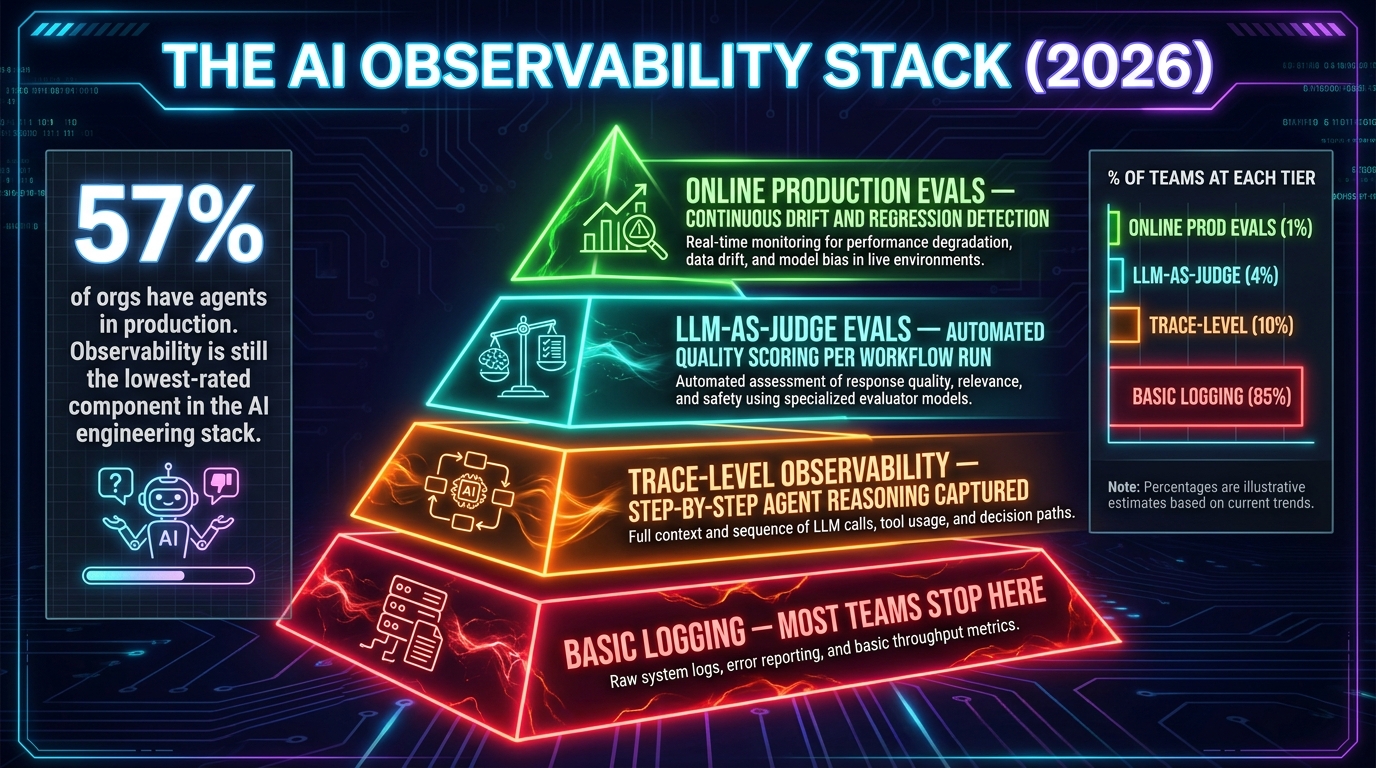
According to recent industry surveys, 57% of organisations now have AI agents running in some form of production. Yet when engineering leaders are asked to rate the maturity of different components in their AI stack, observability consistently ranks lowest. Teams are deploying faster than they are learning to watch what they deployed. The result is a generation of agent workflows that work well on average but fail badly at the edges — which is exactly where production lives.
This article is a practitioner-focused breakdown of what actually causes agent workflows to fail, and the specific engineering disciplines — architecture patterns, state management strategies, testing approaches, escalation design, and governance layers — that separate systems which hold up in production from those that don’t. This is not about which LLM to use. It’s about how to build the harness around it.
The Distributed Systems Problem Nobody Warned You About
The framing most teams bring to agent workflows is fundamentally wrong. They think about agents as smart software — more capable than a script, more flexible than a rule engine — and they test and deploy them accordingly. What they should be thinking about is distributed systems, because that is what an agent workflow actually is.
An agent that calls tools, manages context across multiple steps, retrieves data from external sources, and hands off work to other agents has all the complexity of a microservice mesh. It has network calls that can fail. It has external dependencies with their own reliability profiles. It has state that needs to be consistent across steps. It has timing constraints, concurrency issues, and the possibility of partial failure at any node in the chain. The only difference is that instead of explicit service contracts, the “protocol” between components is a natural language prompt and a JSON schema — both of which are considerably softer guarantees than a typed API.
Why non-determinism compounds the problem
Traditional distributed systems fail in predictable ways. An API returns a 500, a database connection times out, a queue backs up — these are known failure modes with known mitigations. Agent workflows introduce a new class of failure: non-deterministic reasoning errors. The same input, on the same day, can produce a different tool call sequence. The model might interpret an ambiguous instruction differently under different context loads. A slight variation in the retrieved documents can change the final action taken.
This non-determinism doesn’t just make testing harder. It makes failure attribution harder. When a multi-step agent workflow produces a wrong output, determining whether the error originated in the model’s reasoning, the tool call, the retrieved context, or the orchestration layer requires a level of observability that most teams simply don’t have instrumented. You end up debugging a black box that doesn’t fail consistently enough to reproduce reliably.
The compounding failure problem
In a five-step agent pipeline, if each step has a 95% success rate — which sounds high — the probability of the entire pipeline completing successfully is roughly 77%. At ten steps with the same per-step reliability, that drops to 60%. At twenty steps, it falls below 36%. This is not a hypothetical. It’s basic probability applied to chained operations, and it explains why production failure rates in complex agent tasks are so dramatically higher than teams expect.
The implication is that you cannot treat agent reliability as a model problem. Even a perfect model produces cascading failure when it is operating inside a poorly engineered workflow. Reliability has to be engineered at the system level, not hoped for at the model level.
Why Single-Responsibility Agents Outperform “Do-Everything” Designs

One of the most consistent findings across teams building production agent systems in 2026 is that the “mega-agent” approach — a single, broadly-scoped agent given access to dozens of tools and asked to autonomously handle complex tasks end-to-end — reliably underperforms architectures that use multiple narrowly-scoped agents working in coordination. This is not an intuitive conclusion. It feels like more capability should produce better results. In practice, it produces worse results and dramatically harder debugging.
The cognitive load problem for LLMs
When you give a single agent access to twenty tools and a complex, multi-part goal, you are asking the model to hold an enormous amount of context and make sequencing decisions across a very wide state space. The model’s ability to reason well degrades with prompt complexity. Tool selection accuracy drops when the tool list is long. Errors in early steps compound through later steps because the agent is responsible for its own error recovery, and recovering from an error while also executing the primary task is genuinely hard to do well.
Narrow agents don’t face this problem. A Researcher agent with three retrieval tools and a clear, single objective — find relevant documents on a specific topic — can execute that task with high reliability. A Writer agent given clean, structured input from the Researcher can produce high-quality output without needing to understand the retrieval process. A Verifier agent checking the Writer’s output against a rubric doesn’t need to know anything about either of the previous steps. Each agent is doing one thing, and doing it well.
Isolation as a reliability property
Beyond task quality, modular agent design has a structural reliability advantage: failure isolation. When a Researcher agent fails because its web search tool timed out, that failure is contained. The orchestrating workflow knows exactly which step failed, can retry just that step, and can report the failure with full context. When a mega-agent fails mid-task, you have to reconstruct from opaque reasoning traces what it was attempting when the failure occurred and why, which is dramatically harder.
Teams that have moved from mega-agent to modular designs consistently report two improvements: higher task completion rates (because the narrower scope reduces reasoning errors) and much faster debugging cycles (because failures are localised and attributable). The UiPath engineering team, among others, has publicly recommended single-responsibility agent design as a core production principle, citing debugging complexity as the primary argument.
The handoff design problem
The tradeoff with modular design is handoff quality. When Agent A passes output to Agent B, the format, completeness, and semantic accuracy of that handoff determines whether Agent B can do its job. Poor handoff design is one of the most common failure modes in multi-agent systems: Agent A produces output that is technically correct but insufficiently structured for Agent B to parse reliably, and the error only manifests several steps downstream.
The mitigation is to treat handoffs as explicit contracts: schema-defined output structures, validated at the point of handoff, with clear specification of what “done” means for each upstream agent. This is more work upfront than just letting agents talk to each other, but it is the design discipline that makes modular agent systems actually reliable rather than just theoretically modular.
State Management — The Silent Killer of Long-Running Agents
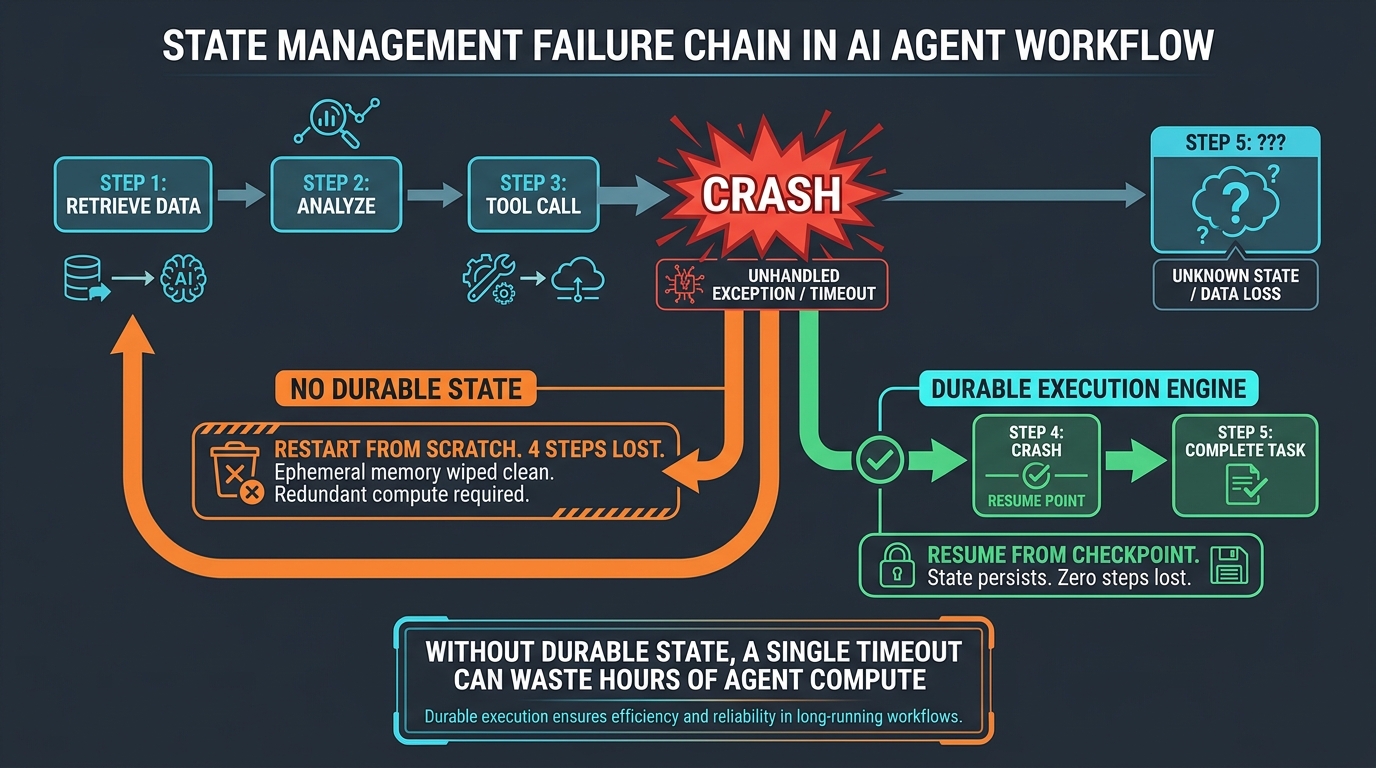
If you ask most engineering teams how their agent workflows handle a mid-run failure — a server restart, a network interruption, a timeout on step seven of a fifteen-step pipeline — the answer is usually some version of “we restart it.” That answer conceals an enormous amount of wasted compute, inconsistent results, and in some cases, serious operational risk.
State management is arguably the most underengineered dimension of agentic systems. It’s the area where the gap between what teams intend (“the workflow will be resilient”) and what they actually build (“the workflow will restart from the beginning if anything goes wrong”) is largest. And for long-running agents — workflows that might take minutes or hours to complete, that involve dozens of tool calls, that interact with external systems — the consequences of poor state management are not minor.
What “lost state” actually costs
Consider an agent workflow handling a complex procurement process: it has retrieved vendor data, run comparisons, generated a shortlist, and is mid-way through a compliance check when the instance running it crashes. Without durable state, that entire sequence must restart. The tool calls that already completed are executed again — potentially producing different results if any retrieved data has changed. Time is lost. Token spend is doubled or tripled. And in workflows that interact with external systems, restarting from scratch can mean duplicate actions: duplicate API calls, duplicate database writes, or duplicate messages sent to downstream systems.
The principle of idempotency — designing each step so that running it twice produces the same result — is necessary but not sufficient. Some steps are inherently non-idempotent. Some are expensive to repeat. Some have side effects. The right solution isn’t to make every step safe to repeat; it’s to make restarting from scratch unnecessary.
Checkpointing and durable state patterns
The production pattern that solves this is explicit checkpointing: persisting the state of the workflow after each significant step to a durable store (a database, an object store, or a purpose-built workflow state backend). If the workflow fails, it resumes from the last checkpoint rather than the beginning. This requires some upfront work — deciding what state to persist, when to checkpoint, and how to reconstruct context from a checkpoint — but it fundamentally changes the failure profile of long-running agents.
For teams dealing with particularly high-stakes or complex workflows, durable execution engines like Temporal provide this guarantee at the infrastructure level. Rather than manually managing checkpoints, Temporal automatically persists workflow state as an event log. If a worker crashes, the workflow resumes exactly where it stopped, with all prior context intact. The tradeoff is operational overhead: Temporal is a non-trivial piece of infrastructure to run. But for workflows where correctness and completion guarantees matter more than simplicity, the tradeoff is increasingly justified.
Context window management as a state problem
There is a subtler state management problem specific to LLM-based agents: context window management. Each LLM call has a finite context window. Long-running agents accumulate conversation history, tool outputs, and intermediate reasoning across many steps. At some point, the relevant context exceeds what fits in a single call. How you handle this — what you summarise, what you discard, what you persist to external memory and retrieve selectively — has a direct impact on the quality of the agent’s reasoning in later steps.
Teams that ignore this problem find that their agents produce lower-quality outputs as tasks progress — not because the model has degraded, but because the context available to it is increasingly stale or truncated. Explicit context management strategies (rolling summarisation, selective retrieval from an external memory store, structured context schemas) are a necessary part of any long-running agent design.
Tool Contracts, Schema Versioning, and Why Brittle Integrations Cascade
Every tool call in an agent workflow is a trust boundary. The agent sends a request to some external capability — an API, a database query, a code executor, a web scraper — and trusts that the response will conform to a schema it understands. When that trust is violated — when the API changes its response format, when a tool returns an unexpected type, when a field is missing that the agent expected — the effects propagate downstream with remarkable speed.
Tool integration brittleness is one of the most practically painful failure modes in production agent systems, and it is almost entirely avoidable with the right design discipline. The problem is that most teams think of tools as reliable external services and don’t invest in the same contract-management rigor they would apply to internal service APIs.
The MCP shift and why it matters
In 2026, the Model Context Protocol (MCP) has emerged as a standard interface layer for agent tool integrations. MCP provides a structured, typed way for agents to discover and call tools, with explicit schemas for inputs and outputs. This is a significant improvement over ad-hoc tool integration approaches where the schema lived in the system prompt as natural language description.
With explicit schemas, you can validate tool call inputs before sending them, validate responses before passing them to the next step, and detect schema drift automatically when a tool is updated. This shifts tool failures from silent runtime errors — where the agent receives an unexpected response and quietly produces wrong output — to explicit, catchable exceptions that can be handled gracefully.
Schema versioning in practice
Tools change. External APIs add fields, remove fields, change types, and alter the semantics of existing fields. Without a versioning strategy, any tool update is a potential breaking change that the agent has no way to detect until it fails at runtime. The mitigation is to treat tool schemas with the same versioning discipline you would apply to a public API: pin to specific versions, test against schema changelogs, and build a CI gate that fails if a tool’s response schema changes in a backward-incompatible way.
This is more disciplined than how most teams handle it today. The typical approach is to update tools informally and discover breakage through production failures. Shifting that discovery left — into the CI pipeline — dramatically reduces the blast radius of tool changes. A schema mismatch caught in CI costs minutes to fix. The same mismatch discovered in production, after it has silently corrupted several hours of agent output, is a much more expensive problem.
Fallback design for tool failures
Even well-managed tools fail. External APIs go down. Rate limits are hit. Third-party services have outages. For each tool in a production agent workflow, the design question is: what happens when this tool is unavailable? The options are explicit: fail the workflow immediately, retry with backoff and potentially circuit break, attempt a degraded alternative, or return a structured “unavailable” signal that downstream agents can handle gracefully.
The worst option, which is also the most common, is to allow the failure to propagate silently — where the agent receives an empty or error response, continues processing as if it had valid data, and produces confidently wrong output several steps later. Explicit failure handling, even if the decision is “fail loudly,” is always better than silent propagation.
Retry Logic, Circuit Breakers, and the Art of Graceful Degradation
Retry logic is the most widely implemented resilience pattern in agent workflows, and also one of the most widely misimplemented. Done wrong, retries don’t improve reliability — they amplify failure. A naive retry loop on a failing API doesn’t fix the underlying problem; it generates three or five times the load on an already-struggling system, extends the failure duration, burns tokens on repeat LLM calls, and can turn a localised timeout into a cascading system-wide problem.
The engineering discipline here is well-established from distributed systems practice, but it needs to be adapted for the specific failure modes of agent workflows — where failures are not just transient network errors but also include model quality issues, context overflow, and tool schema mismatches that retrying won’t help.
What to retry and what not to
The basic rule: retry only on clearly transient errors. HTTP 429 (rate limited), 500, 502, 503, and 504 responses are candidates for retry with exponential backoff. HTTP 400 (bad request) is not — it means the request is malformed, and retrying the same request will fail again. Model-generated wrong outputs are not candidates for simple retry — retrying the same prompt with the same context will usually produce the same error, because the problem is in the reasoning, not in the execution.
For rate limit errors specifically, exponential backoff with jitter is the standard pattern: wait progressively longer between retries, add randomness to prevent thundering herd effects, and cap the total retry time to avoid workflows hanging indefinitely. Most LLM provider clients now include this as a built-in option, but teams using custom tooling need to implement it explicitly.
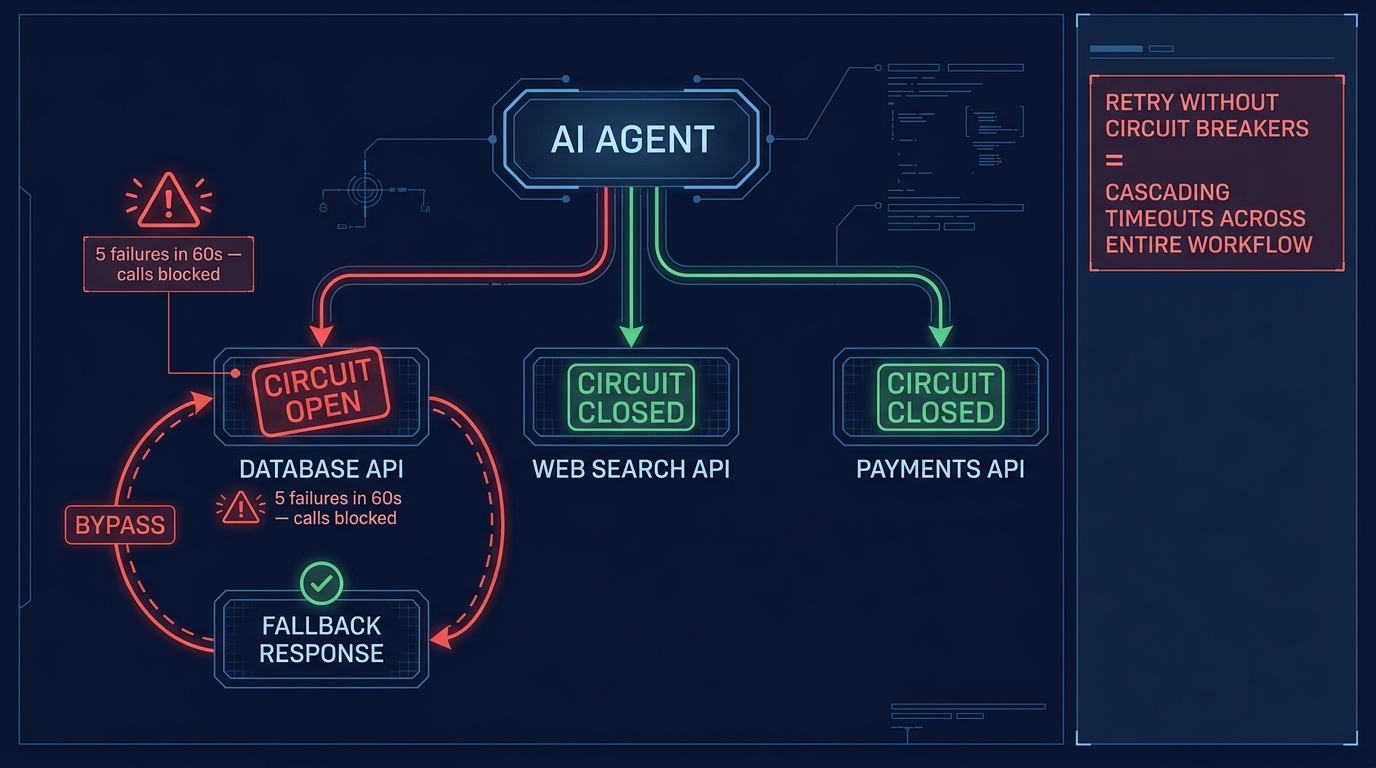
Circuit breakers for agent tool calls
Circuit breakers are the resilience pattern that retries don’t provide: instead of repeatedly attempting calls to a failing dependency, a circuit breaker tracks failure rates and “opens” the circuit when a threshold is exceeded — temporarily blocking further calls to that tool to allow the dependency to recover. After a configured timeout, the circuit enters a “half-open” state, allowing a test call through. If that succeeds, the circuit closes and normal operation resumes.
For agent workflows, circuit breakers prevent the failure of one tool from consuming the entire workflow’s retry budget and execution time. If a database tool is timing out consistently, the circuit breaker blocks new calls immediately, returns a structured failure signal, and allows the agent workflow to either degrade gracefully (using cached data or a fallback) or halt cleanly rather than thrashing against an unavailable dependency for minutes.
Graceful degradation as a design requirement
The highest-reliability agent systems are designed with explicit degradation paths. For each tool failure, there is a defined fallback: use cached results from a previous run, invoke an alternative tool that provides a lower-fidelity but acceptable result, or produce a partial output with clear indication of what’s missing. This requires more upfront design — you have to think through failure scenarios during architecture, not just during incident response — but it produces systems that continue delivering value even under partial failures rather than failing completely.
The practical test: for every tool in your agent workflow, ask “what does the user experience if this tool is unavailable for thirty minutes?” If the honest answer is “the entire workflow stops working,” that’s a reliability risk that needs a mitigation. It doesn’t have to be a perfect mitigation — sometimes the right fallback is a clear error message — but it has to be intentional, not accidental.
Observability Is the Weakest Link in the 2026 AI Stack
The most striking finding from 2026 AI engineering surveys is the gap between deployment ambition and observability maturity. As noted earlier, 57% of organisations have AI agents in production. When those same organisations rate the components of their AI engineering stack, observability consistently ranks at the bottom. Teams are flying agents in production essentially blind — unable to see what the agent is reasoning, why it made a particular tool call, where time is being spent, or when output quality has silently degraded.
This is not a minor operational inconvenience. It is the primary reason that most organisations cannot confidently answer the question “is our agent workflow performing well today?” The data to answer that question either doesn’t exist or isn’t instrumented in a way that makes it accessible.
The four layers of agent observability
Effective agent observability is not just application logging. It has four distinct layers, each capturing different signals, and most teams only have the first one.
Layer 1: Basic operational logging. This is what most teams have — request/response logs, error counts, latency metrics. It tells you that something went wrong but rarely tells you why, because agent failures often aren’t exceptions; they’re the agent successfully executing the wrong reasoning chain and producing confidently wrong output. Basic logging doesn’t capture that.
Layer 2: Trace-level observability. This captures the complete step-by-step trace of an agent run: every LLM call with its full prompt and response, every tool call with its inputs and outputs, every routing decision. With trace-level data, you can replay a specific run and understand exactly what the agent was doing at each step. This is the minimum viable observability layer for debugging agent failures. Emerging standards like OpenTelemetry for AI agents are pushing this toward interoperability across frameworks.
Layer 3: LLM-as-judge evaluation. At this layer, you’re not just capturing what happened — you’re automatically scoring whether what happened was good. LLM-as-judge systems use a separate model to evaluate the quality of an agent’s output against defined criteria: was the reasoning sound? Did the agent call the right tools? Was the final response accurate and on-topic? This allows quality monitoring at scale without requiring human review of every run.
Layer 4: Online production evals. The most mature layer continuously monitors production traffic for quality drift, regression, and distributional shift. When the characteristics of inputs change — users asking about topics the agent wasn’t designed for, or new edge cases emerging from real usage patterns — online evals can surface this before it becomes a visible customer-facing problem.
Multi-model sprawl and the observability ceiling
A specific 2026 challenge: teams running multiple models in a single agent system (one model for planning, another for summarisation, a third for tool call generation) are hitting a new observability ceiling. Each model provider has different logging formats, different trace structures, and different metrics. Correlating traces across providers into a single coherent picture of a workflow run requires either a standardised instrumentation layer or significant manual integration work.
The practical implication is that observability has to be designed into the architecture, not added as an afterthought. By the time a team is debugging a production incident and realises they can’t trace a workflow across two model providers, it’s too late to quickly retrofit the instrumentation they need.
Eval-Driven Development: Testing Agents Like Distributed Systems
The standard software testing intuition — write unit tests, write integration tests, run them in CI, ship if they pass — breaks down for agent workflows in fundamental ways. Agent outputs are non-deterministic. There is no single “correct” output for most agent tasks. Traditional exact-match assertions fail immediately. And because agents reason across multiple steps, component-level tests don’t surface the class of failures that only emerge when all the components interact.
The engineering discipline that is emerging in 2026 to replace this intuition is eval-driven development: a testing philosophy that treats agent evaluation as a continuous, multi-layered process running in both offline development and online production environments, using probabilistic quality metrics rather than exact-match assertions.
Component evals versus workflow evals
The first distinction to make is between component-level evaluation — testing an individual agent or tool in isolation — and workflow-level evaluation — testing the complete end-to-end pipeline with realistic inputs. Both are necessary, but they catch different failures.
Component evals for a Researcher agent might test: does it call the right search tool for this type of query? Does it retrieve relevant documents? Does it produce a structured output that matches the expected schema? These tests can be deterministic and run quickly. They catch regressions in a specific agent’s behavior when its prompt or its tools change.
Workflow evals test the integrated system: given a realistic input, does the complete pipeline produce a correct, high-quality output? These tests are necessarily probabilistic — you need enough runs to establish a distribution rather than a single pass/fail — and they’re slower and more expensive to run. But they’re the only test that catches the class of failures that emerge from agent interactions: cases where each agent performs reasonably in isolation but the combination produces unexpected behavior.
Ground truth datasets and scenario coverage
The quality of eval-driven development depends entirely on the quality of the evaluation dataset. A ground truth dataset for an agent workflow should include: examples of correct inputs and expected outputs (or expected reasoning patterns), examples of edge cases and adversarial inputs, examples of the types of inputs that have caused past failures, and a representative sample of realistic production inputs.
Building this dataset is work that teams consistently underinvest in. The tendency is to build a handful of “happy path” examples, confirm the agent works on those, and ship. The failures that actually happen in production come from the long tail of inputs that don’t look like the happy path examples. Investing in a comprehensive ground truth dataset — including failure cases, edge cases, and realistic variation — is the most high-leverage testing investment a team building agent workflows can make.
CI/CD gates for agent quality
In 2026, the teams with the most mature agent testing pipelines are treating eval scores as first-class CI/CD gates. A PR that changes an agent’s prompt, tool list, or model cannot merge if it reduces the task completion rate below a defined threshold, or increases the rate of tool selection errors above a defined limit, or decreases quality scores on the evaluation dataset. This discipline — eval scores as shipping criteria — is what keeps agent quality from silently degrading across releases as teams iterate quickly.
Human-in-the-Loop as an Engineered Subsystem, Not an Afterthought
Human-in-the-loop is one of those phrases that means almost nothing in practice until it’s operationalised. “We have a human review things when needed” is not a reliability design. It is a vague intention that provides no meaningful guarantee during a production incident. The engineering discipline that makes human oversight actually work is treating escalation as a designed subsystem with explicit policies, defined SLAs, and tested handoff mechanisms — not as a fallback that exists somewhere in the background.
The shift that is visible across the industry in 2026 is from ad-hoc HITL — “a human can always intervene if something goes wrong” — to engineered escalation systems with risk-tiered gates, confidence-based routing, identity-bound approvals, and documented audit trails. This shift is being driven partly by regulatory pressure in high-stakes domains and partly by painful experience with agent systems that produced significant damage before a human noticed something was wrong.
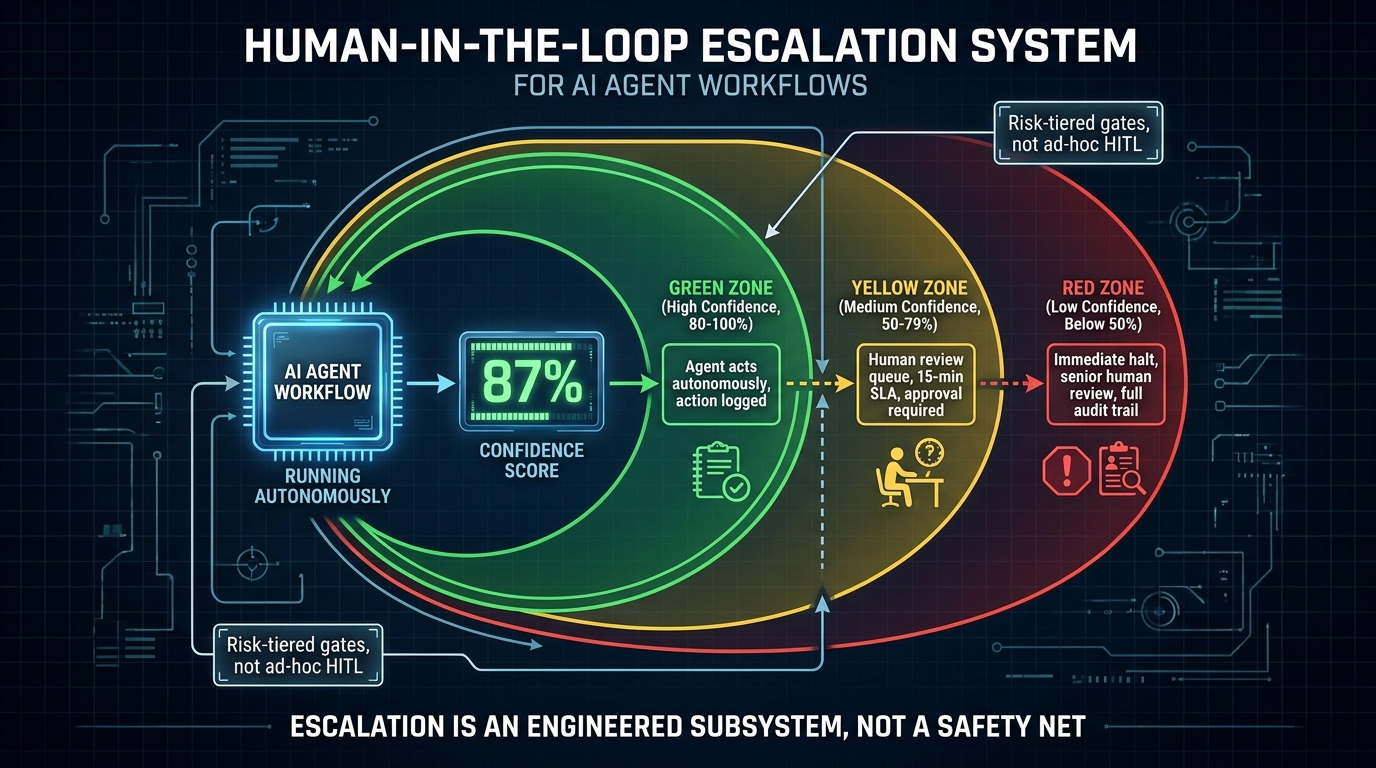
Risk-tiered escalation architecture
The foundational design is a risk tier model. Every action an agent might take is pre-classified by risk level, and the risk level determines what oversight is required before that action executes:
Low risk (autonomous execution): The agent acts and logs. A human might review the log periodically, but no approval is required before action. Example: retrieving data, generating a draft document, running a read-only database query.
Medium risk (human review queue): The agent proposes the action and queues it for human approval with a defined SLA (fifteen minutes, one hour, end of business day — depending on the use case). If no approval arrives within the SLA window, the workflow escalates or halts. Example: sending a customer-facing communication, updating a pricing rule, creating a new supplier record.
High risk (immediate halt): The agent stops entirely and triggers an alert to a human reviewer. No autonomous action is taken. The workflow resumes only after explicit human decision. Example: deleting data, transferring funds, any irreversible action above a defined financial threshold.
Confidence scoring as an escalation trigger
Beyond pre-classified risk tiers, many mature implementations add a dynamic escalation layer based on the agent’s own confidence in its output. When an agent’s confidence score for a decision falls below a threshold — because the input is ambiguous, the retrieved context is contradictory, or the reasoning chain produced multiple plausible alternatives — the action is automatically routed for human review even if it would ordinarily be in the low-risk tier.
This requires agents that can express calibrated uncertainty, which is a non-trivial prompt engineering and evaluation challenge. But it is worth the investment: a confidence-based escalation system catches the specific cases where autonomous action is most likely to go wrong, without requiring human review of every action.
State handoff and resumption
An often-overlooked dimension of HITL design is what happens to the workflow state during the human review period. If the workflow simply stops and holds all context in memory while waiting for approval, a server restart during the review window loses everything. If the review takes hours or days, the context may have become stale by the time the human approves. Effective HITL design requires durable state storage during pending review, clear presentation of context to the human reviewer (what did the agent do, what is it proposing to do, and why?), and a clean resumption mechanism that picks up where the workflow paused.
Durable Execution Engines and When to Reach for One
The decision of whether to use a durable execution engine — like Temporal, Restate, or AWS Step Functions — for an agent workflow is one of the most consequential architectural decisions a team makes. Used appropriately, these engines fundamentally change the reliability profile of long-running, stateful agent workflows. Used unnecessarily, they add operational overhead and complexity that a simpler approach wouldn’t require.
What durable execution engines actually provide
A durable execution engine provides a specific and powerful guarantee: that the workflow will complete, even if the processes running it crash and restart. It achieves this by automatically persisting the workflow’s execution history as an event log. When a worker process crashes and restarts, it replays the event log to reconstruct the workflow’s state exactly as it was, then continues execution from where it stopped. No checkpointing code is required from the developer. The durability guarantee is structural, not aspirational.
For AI agent workflows, this addresses the state management problem described earlier: long-running agents that make dozens of tool calls across minutes or hours no longer lose their progress to infrastructure failures. A worker restart is invisible to the workflow. Rate limit exhaustion that forces a multi-hour wait doesn’t require the workflow to restart from scratch. The execution engine handles the persistence; the developer handles the business logic.
Temporal’s positioning for agentic systems
Temporal has emerged as the primary durable execution engine for production agentic systems in 2026, partly because of its technical capabilities and partly because of its ecosystem development. At its Replay 2026 conference, Temporal announced integrations with Google’s Agent Development Kit (ADK) and OpenAI’s Agents SDK, as well as new capabilities including Standalone Activities (allowing individual tool calls to be durably executed without a full workflow) and Workflow Streams (enabling long-running streaming interactions between agents).
These integrations reflect a broader recognition: the infrastructure requirements of production agent workflows — durability, retry guarantees, state management, long-running execution — are exactly what workflow engines were designed to provide. The industry is converging on using them together rather than building bespoke state management inside agent frameworks.
When you don’t need a durable execution engine
It’s worth being equally clear about when you don’t need this level of infrastructure. Short-running agent tasks (under a few minutes, a handful of tool calls) that can tolerate restart from scratch don’t need durable execution. Workflows where all tool calls are idempotent and cheap to repeat don’t need it. Prototypes and internal tools don’t need it. The overhead of operating Temporal or a similar engine — the infrastructure, the learning curve, the operational complexity — is meaningful, and teams that reach for it before they need it are adding cost without commensurate benefit.
The practical heuristic: reach for a durable execution engine when your agent workflows run for more than a few minutes, involve more than ten tool calls, interact with external systems that can’t be safely re-invoked, or need to pause for extended periods waiting for human approval or external events. Below those thresholds, explicit checkpointing to a database is usually sufficient.
The Governance Layer Most Teams Skip Until It’s Too Late
Governance is the word that makes most engineers’ eyes glaze over. It sounds like a compliance concern, not an engineering concern. But in the context of agent workflows, governance is an engineering problem with concrete technical dimensions: access control, audit trails, policy enforcement, cost management, and version lifecycle management. Teams that skip it in the early stages of deployment consistently face painful retrofits — or worse, production incidents — that adequate governance would have prevented.
Access control and least-privilege tool authorization
Every tool in an agent workflow represents a capability — and a risk surface. An agent with write access to a customer database, send access to a marketing email system, and modify access to production pricing can do an enormous amount of damage if it reasons incorrectly or is manipulated by adversarial input. The principle of least privilege applies to agents as strictly as it applies to human users: each agent should have access to exactly the tools it needs for its defined task, and no more.
In practice, this requires explicit tool authorization per agent role, scoped API credentials that can be rotated and revoked, and regular reviews of what each agent is actually using versus what it has been granted access to. Teams that grant broad tool access early (“let’s figure out what it needs by watching it run”) and never narrow it down are accumulating risk with every deployment.
Cost governance and budget rails
Token costs for agentic workflows can escalate dramatically and unexpectedly. A workflow that loops unexpectedly, or that gets stuck in a retry cycle, or that calls an expensive model for a task that could use a cheaper one, can generate significant cost in a short time. Cost governance for agent workflows means: per-agent token budgets with hard limits, alerts when a workflow run exceeds expected cost, regular audits of model selection (is this agent using a $15/million-token model for tasks where a $0.15/million-token model would suffice?), and automatic circuit breakers that halt workflows whose cost exceeds defined thresholds.
Prompt and model versioning
An agent’s behavior is determined by three things: its prompt, its model, and its tools. When any of these change, the agent’s behavior can change — sometimes subtly, sometimes significantly. Governance requires treating all three as versioned artifacts with change management discipline: every change to a prompt or model version is logged, evaluated against the test suite before deployment, and attributable to a specific decision-maker. This isn’t bureaucracy for its own sake. It’s the infrastructure that allows a team to answer “what changed between last Tuesday when the agent was working and today when it’s producing wrong outputs?”
Key insight: The teams with the most reliable agent workflows in 2026 are not the ones using the most sophisticated models. They are the ones that treat agent systems with the same engineering discipline they apply to any other production software — versioned, tested, observed, and governed.
Regulatory documentation and audit trails
For organisations in regulated industries — financial services, healthcare, legal, government — the governance layer has a regulatory dimension that cannot be deferred. Decisions made by AI agents may need to be auditable: who authorised the workflow, what data did it access, what was its reasoning, what action did it take, and who approved high-risk decisions. Building audit trail infrastructure retroactively into a deployed agent system is a painful and often incomplete process. Building it from the start — as part of the initial architecture — is dramatically less expensive and produces better audit coverage.
A Reliability-First Framework for Agent Workflows: Conclusion and Actionable Takeaways
Reliable agent workflows don’t emerge from good luck, capable models, or careful prompting alone. They are engineered — deliberately, with the same discipline applied to any complex distributed system. The teams producing dependable results in production in 2026 share a common approach: they start narrow, design for failure from day one, instrument everything, test continuously, and govern explicitly.
The following is a distillation of the engineering discipline this article has covered, organised as actionable principles rather than aspirational goals:
Architecture principles
- Start with the simplest possible design. A single LLM call with good retrieval solves more problems than most teams acknowledge. Reach for multi-agent complexity only when simpler approaches demonstrably don’t meet requirements.
- Prefer workflows with agents inside them, not agents managing everything. Keep control flow deterministic where possible; use the LLM for the steps where intelligence is genuinely needed.
- Apply single-responsibility design to agents. One agent, one job, one clearly defined output schema. Modular systems fail in contained, attributable ways. Monolithic agents fail in opaque, expensive ways.
- Define handoff contracts explicitly. Every output passed between agents should have a schema. Validate at handoff points, not just at the final output.
State and resilience principles
- Design for failure before optimising for performance. For every step, define what happens when it fails. Silent propagation of errors is always worse than any explicit failure handling, however simple.
- Checkpoint state for workflows longer than a few minutes. Never design a workflow where a crash at step N means starting over from step 1. The cost of the lost compute is real; the cost of the repeated tool calls on external systems can be significant.
- Retry only transient errors, circuit break on sustained failures. Retrying a 400 response wastes tokens. Retrying a failing dependency without a circuit breaker cascades the failure across the workflow.
- Evaluate durable execution engines for complex, long-running workflows. If your workflow needs to survive infrastructure failures, pause for human review, or guarantee completion against external dependencies, Temporal or a similar engine pays for its complexity.
Observability and testing principles
- Instrument trace-level observability before shipping to production. If you can’t replay a workflow run step-by-step after the fact, you cannot reliably debug production failures. Basic logging is not enough.
- Build ground truth evaluation datasets as a first-class deliverable. The happy-path examples aren’t the ones that will cause production incidents. Edge cases, adversarial inputs, and realistic distributional variation are what matter.
- Make eval scores a CI/CD gate. Any change that decreases task completion rate or increases tool error rate below defined thresholds should not ship. Quality regression in agent systems is typically gradual and invisible until it isn’t.
Governance and oversight principles
- Design HITL escalation as a subsystem, not a safety net. Define risk tiers for every action. Define SLAs for every review tier. Test the handoff mechanism before you need it.
- Apply least privilege to agent tool access. Audit what each agent actually uses versus what it’s authorised for. Narrow access early, before it becomes a security or compliance issue.
- Version prompts and models like production code. If you can’t attribute a behavioral change to a specific prompt or model version change, you can’t debug it systematically.
- Build cost rails from day one. Token costs in agentic systems can escalate suddenly and significantly. Hard per-run limits and cost alerts are cheap to build and expensive to retrofit after an unexpected bill.
The deeper takeaway is this: the teams producing reliable agent workflows in 2026 are not primarily differentiated by their choice of model or framework. They are differentiated by the engineering rigour they apply to everything around the model. The LLM is one component in a distributed system. Getting that system to production reliability requires treating it like one.
The gap between a compelling agent demo and a trustworthy production system is real, it is wide, and it is almost entirely an engineering discipline gap. The good news is that the discipline is learnable, the patterns are established, and the tooling is maturing rapidly. The teams that close that gap — deliberately, systematically — are the ones building agent workflows that actually work when it matters.