
Every AI team has a drawer full of these: the agent that nailed a vendor onboarding run in a Tuesday afternoon test, the automated triage tool that cleared a backlog in three hours, the invoice reconciliation bot that saved a finance analyst an entire week of work — once. The demo was brilliant. The Slack messages were celebratory. And then, somewhere between the screenshot and the production ticket, the whole thing quietly stopped working.
This pattern has a name in serious AI operations circles: the demo graveyard. And in 2026, with the global agentic AI market valued at roughly $7.6 billion and accelerating toward $236 billion by 2034, the gap between a promising proof-of-concept and a genuinely repeatable system has become one of the most expensive problems in enterprise technology. Fiddler’s production data puts the failure rate for AI agents in live environments at between 70 and 95 percent. That is not a minor implementation gap. That is a structural crisis of documentation.
The problem is almost never the model. It is almost never the tooling. It is the absence of a Standard Operating Procedure — a rigorous, versioned, executable description of exactly what the agent is supposed to do, under what conditions, within what constraints, and with what human oversight. This post is about building those procedures. Not as Word documents, not as Confluence pages that nobody reads, but as living infrastructure that turns your one-off automation victories into systems that run reliably, improve over time, and compound in value across your entire operation.
The Demo Graveyard: Why One-Off Agent Wins Almost Never Survive Contact With Reality

Before you can fix the problem, you need to understand why it happens with such brutal consistency. The anatomy of a failed agent pilot follows a remarkably predictable pattern, regardless of industry, team size, or technology stack.
The “Magic Prompt” Trap
Most successful agent demos are built on what practitioners call the “magic prompt” — a carefully crafted natural language instruction that happens to work brilliantly for the specific scenario the team tested. The problem is that the real business process is hidden inside that prompt. The logic, the edge cases, the decision rules, the fallback paths — all of it is encoded in natural language that the agent interprets differently depending on the model version, the input phrasing, and a hundred contextual variables the team never thought to test.
When the demo runs again three weeks later with slightly different data, or when a different team member adds a minor modifier to the prompt, or when the underlying LLM is updated, the “magic” evaporates. There was no explicit procedure — just an instruction that worked once and was never decomposed into its constituent parts.
The Hidden Human Glue Problem
The second failure mode is subtler and arguably more damaging. During a successful pilot, there is almost always a human “shepherd” — the engineer who built the tool, or the domain expert who seeded it with the right context — quietly fixing things behind the scenes. They re-run failed steps. They supply missing context. They interpret ambiguous outputs and nudge the agent back on track.
None of this gets documented. When the shepherd moves on to another project, or when the agent needs to run at 2am without anyone watching, the invisible scaffolding disappears. What looked like an autonomous system was actually a human-agent collaboration with the human’s role never written down.
The Clean Data Illusion
Successful demos almost always run on clean, curated data. Production environments do not have clean data. They have inconsistently formatted fields, missing values, schema changes that were pushed without warning, and edge cases that your test suite never considered. An agent SOP that doesn’t account for data quality variance — that doesn’t specify what the agent should do when an expected input is absent or malformed — will fail silently in production while appearing to run correctly from the outside.
This is one of the core reasons why the jump from 70% task completion in testing to under 30% in live deployment is so common. The agent isn’t broken. The procedure was never specified completely enough to handle the world as it actually is.
What Makes an Agent Win Actually “Repeatable” (Most Teams Get This Wrong)
The word “repeatable” gets thrown around a lot in automation discussions, but it means something very specific in the context of AI agents. A repeatable agent win is not just a win that can be run again. It is a win that can be run again by anyone, on any compatible data, without the original builder present, and produce an outcome within a defined variance of the original success.
That definition immediately surfaces why most teams’ instinct — to capture the prompt and the tool configuration and call it documented — falls short.
Repeatability Requires Explicit Success Criteria
The first thing most one-off wins lack is a written definition of what “winning” actually means. Was the vendor onboarding run successful because it completed in under ten minutes? Because it produced a correctly formatted output file? Because zero human corrections were required afterward? Because it hit a specific accuracy threshold on the extracted fields?
If your team can’t answer that question from the documentation alone, you don’t have a repeatable process — you have a memory. And memories are not infrastructure.
Defining success criteria forces several useful conversations that pilots typically skip: What is the acceptable error rate? What happens at the boundary — when results are 80% confident rather than 99%? Who signs off on outputs before they trigger downstream actions? These conversations feel like overhead when you’re in demo mode. They are non-negotiable when you’re building for production.
Repeatability Requires Scoped Failure Handling
A repeatable system must know what to do when it doesn’t know what to do. This sounds circular, but it isn’t. An explicit fallback path — “if the agent cannot classify an invoice line with greater than 85% confidence, flag it for human review and continue with the remaining lines” — turns an unpredictable failure into a predictable exception. The agent doesn’t stall. The process doesn’t break. The human gets a clean exception queue rather than a confusing mess of partial outputs.
Most one-off wins have no fallback paths because they were never needed during the demo. Encoding those paths is perhaps the single most important step in converting a successful experiment into a production system.
Repeatability Requires Minimal Human Dependency
This does not mean removing humans from the loop. It means making human involvement explicit and scheduled rather than implicit and reactive. A repeatable system has defined checkpoints where a human reviews, approves, or escalates — and defined criteria for when those checkpoints trigger. What it doesn’t have is a reliance on a specific individual noticing something looks wrong and fixing it informally.
The Anatomy of an Agent SOP: Beyond Prompts and Into Procedures
In November 2025, AWS open-sourced Agent SOPs through its Strands Agents project — a standardized markdown-based format for defining multi-step AI agent workflows using structured natural language and RFC 2119 constraint keywords (MUST, SHOULD, MAY). The project has since been adopted across multiple agent frameworks including Kiro, Cursor, and Claude-based tools. It represents the field’s growing consensus that prompts are not procedures.
Understanding what a complete agent SOP contains — and why each element earns its place — is the foundation of everything else in this post.
Element 1: Purpose and Business Context
Every agent SOP must begin with a clear, jargon-free statement of the business objective the agent serves. Not “automate the AP process” — but “verify that every vendor invoice contains a matching purchase order number, a correct line-item total, and a valid payment terms code, and route verified invoices to the approval queue while flagging exceptions.” The more specific the objective, the more constrained the agent’s behavior, and the easier it is to detect when that behavior drifts.
Element 2: Trigger and Entry Criteria
What event starts the SOP? A new email in a specific inbox? A webhook from an upstream system? A scheduled cron job? A manual initiation by an authorized user? The entry criteria also define what a valid input looks like — so the agent can immediately flag runs that begin with corrupted or insufficient data rather than proceeding and producing garbage output.
Element 3: Sequential Step Definitions
Each step in the procedure should contain exactly one action. Not “retrieve the invoice and check its fields” — but step one: retrieve the invoice document from the specified source. Step two: extract the vendor ID field. Step three: validate the vendor ID against the approved vendor registry. One action per step is not pedantry. It is the difference between an agent that can be debugged and one that fails in ways you can never trace.
Element 4: Decision Branches and Constraint Keywords
Each decision point in the workflow needs a documented branch: if condition A, do X; if condition B, do Y; if condition is ambiguous or unknown, do Z. The RFC 2119 keyword system (borrowed from internet standards documents) adds legal-grade precision to agent instructions: MUST means the agent has no discretion, SHOULD means preferred behavior with documented exceptions, MAY means optional behavior within defined parameters.
Element 5: Tool Access and Authorization Scope
An SOP must explicitly list which tools the agent is authorized to use, with what parameters, and with what rate or volume limits. An agent that can send emails, write to databases, and call external APIs without explicit scope constraints is a liability waiting to materialize. The SOP’s tool section is effectively an agent permission manifest.
Element 6: Exit Criteria and Output Specification
What does a successfully completed run produce? In what format? Delivered where? What confirms that the output has been accepted by the downstream system? Exit criteria close the loop on success definition and make it possible to measure completion rates in a way that actually means something.
Knowledge Extraction: How to Pull the Tacit Logic Out of a Successful Run
Writing a rigorous SOP is only possible if you’ve successfully extracted the tacit knowledge embedded in your successful agent runs. This is harder than it sounds because most of that knowledge lives in three places: the heads of the people who built and ran the pilot, the implicit logic in the prompts that happened to work, and the informal interventions that happened during testing without being recorded.
The Run Autopsy Method
The most reliable knowledge extraction technique is what experienced AI operations teams call a run autopsy. Immediately after a successful agent run — while the context is fresh — you systematically walk backwards through the execution log and answer a specific set of questions for each step:
- What was the exact input to this step?
- What decision did the agent make, and why (to the extent the trace reveals)?
- What would have caused this step to fail?
- Was any human intervention involved, even minor?
- What assumption does this step rely on that might not always hold?
The answers to these questions are your SOP draft. They represent the real procedure, not the idealized one — which is exactly what you need for a production system.
SME Interview Protocols
For processes that were designed by domain experts rather than engineers, knowledge extraction requires structured interviews with those experts. The key is to ask about exceptions before you ask about the standard case. Ask the subject matter expert: “When does this process break? What are the cases you handle differently? What would a new hire get wrong?” The edge cases and exceptions are where the real procedural logic lives.
An increasingly common 2026 practice is to use an AI agent to facilitate these interviews — generating structured questions from an initial process description, then synthesizing the SME responses into a draft SOP that the expert reviews and corrects. This turns a two-week documentation project into a two-day one.
Prompt Archaeology
If your successful agent run was built on a long, complex prompt, that prompt needs to be decomposed before it can be turned into a procedure. Break the prompt into its constituent instructions. Map each instruction to a specific step in the business process. Identify which instructions are essential constraints (MUST-style) and which are stylistic preferences (SHOULD-style). What you’re left with is the skeleton of your SOP, extracted from what was previously a monolithic instruction block that would have been impossible to debug, update, or hand off.
The 5-Layer SOP Stack: From Intent to Execution
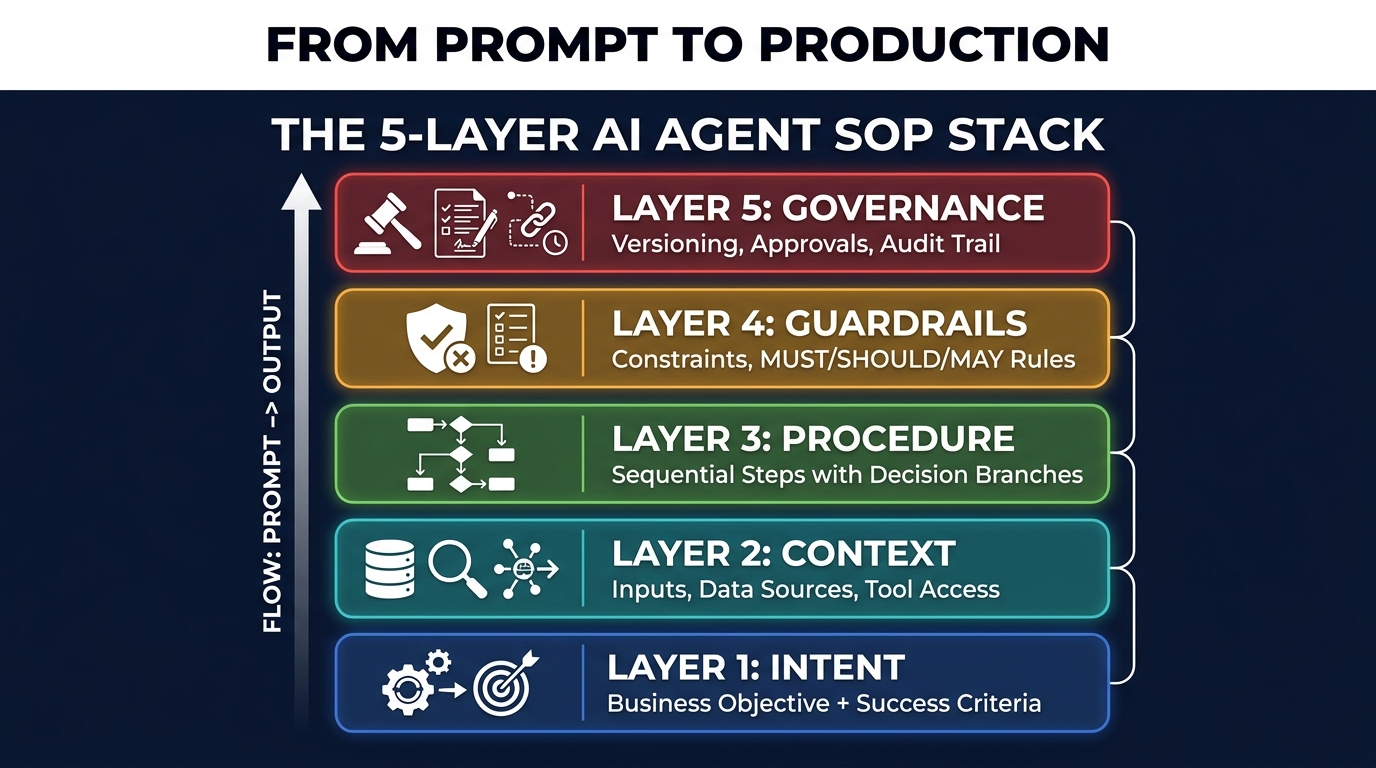
A useful mental model for SOP construction is to think in five distinct layers, each building on the one below it. This structure mirrors how software architects think about system design — and that parallel is intentional. Agent SOPs are software artifacts, not documentation artifacts.
Layer 1: Intent
The bottom layer defines the business objective, the success criteria, the key performance indicators, and the accountable owner. This layer answers the question: why does this agent exist? It should be written in language that a non-technical business stakeholder can read and verify. If the intent layer is vague, every layer above it will be unstable — because there is no fixed point of reference for evaluating whether the system is working correctly.
Layer 2: Context
The context layer defines the environment the agent operates in: the data sources it reads from, the systems it integrates with, the upstream dependencies it relies on, and the expected state of the world at the time the SOP triggers. This layer is where you document assumptions about data quality, input formats, and system availability. It is also where you document what changes in the environment should trigger an SOP review.
Layer 3: Procedure
The procedure layer is the step-by-step execution specification: every action, every decision branch, every exception path. Each step is atomic (one action), explicit (no ambiguous verbs), and traceable (its execution can be confirmed or denied from a log). This is the layer that most teams attempt to write first and the layer that requires everything above it to already exist.
Layer 4: Guardrails
The guardrails layer encodes the constraints on agent behavior using explicit priority-ranked rules. MUST constraints are inviolable — the agent cannot proceed if they cannot be satisfied. SHOULD constraints represent strong preferences with documented exception paths. MAY constraints define optional behaviors the agent can exercise within defined parameters. Guardrails also include rate limits, data access restrictions, and hard stops that prevent runaway execution.
Layer 5: Governance
The governance layer addresses the SOP itself as a managed artifact: version history, change approval process, review schedule, rollback procedure, and audit trail requirements. This layer is what separates a document from infrastructure. Without it, the SOP itself can drift — becoming increasingly misaligned with reality without anyone formally responsible for noticing.
Human-in-the-Loop Checkpoints That Don’t Kill Your Automation ROI
One of the most persistent objections to rigorous agent SOPs is that adding human checkpoints negates the efficiency gains that motivated the automation in the first place. This objection is based on a flawed model of what human-in-the-loop (HITL) oversight actually means in a well-designed system.
The Checkpoint Design Principle
Effective HITL checkpoints are not approval gates on routine operations. They are exception handlers for high-stakes decisions, confidence thresholds, and risk boundaries. The goal is not to have a human review everything — it is to have a human review exactly the things the agent cannot reliably handle, and nothing else.
A well-designed SOP specifies the precise trigger conditions for human review: a confidence score below a defined threshold, an action that exceeds a financial limit, a data pattern that matches a known exception category, a tool call that would modify a record marked as sensitive. When these conditions don’t occur — which should be the vast majority of runs — the agent completes without interruption. When they do occur, the human gets a clean, contextualized exception rather than a stalled workflow.
Four Checkpoint Types Worth Knowing
Confidence-gated checkpoints pause execution when the agent’s output confidence falls below a defined threshold. The human reviews the specific low-confidence item, provides a decision, and the agent continues. This is the most common pattern for document processing and classification tasks.
Risk-threshold checkpoints trigger when an agent action would have consequences above a defined risk level — modifying a financial record above a dollar threshold, sending an external communication, or updating a master data record. The human approves or rejects the specific action.
Ambiguity-resolution checkpoints engage when the agent’s procedure branches cannot resolve a decision without additional information. Rather than choosing arbitrarily or stalling indefinitely, the agent packages the ambiguous context and routes it to the appropriate human for a decision, then continues from that point.
Scheduled audit checkpoints are periodic human reviews of a sample of completed agent runs — not because any specific run triggered a problem, but because statistical sampling is the only reliable way to catch systematic drift in agent behavior before it becomes a crisis.
Calculating the Real Overhead
If a process previously required 100% human handling and your agent handles 92% of cases autonomously with 8% routed to human review, the effective overhead of human involvement has dropped by roughly 90% — even with checkpoint infrastructure in place. The framing of checkpoints as “killing ROI” almost always comes from comparing a fully automated ideal against reality, rather than comparing the automated-with-oversight system against the status quo.
Versioning Agent SOPs Like Code (Because They Are Code)
Gartner’s Q1 2026 enterprise survey found that 80% of enterprise applications shipped or updated that quarter embedded at least one AI agent. As agents proliferate across organizations, the management of their underlying procedures becomes a software engineering problem — and should be treated as one.
Why Version Control Matters for SOPs
An agent operating from an outdated SOP is not just less effective — it is actively dangerous. If the procedure referenced a data schema that was updated, a tool API that was modified, or a compliance rule that changed, the agent will continue executing against the old specification while the world around it has moved on. Without version control and change tracking, you cannot know when a SOP diverged from reality, who authorized the change, or what the agent was actually doing during the gap.
The principles of software version control — commit history, branching, code review, tagged releases — apply directly to SOP management. Each SOP should have a version number, a changelog, a defined owner, and an approval workflow for changes. Rollback capability is not optional: when a SOP update produces degraded performance, you need to be able to revert to the previous version immediately.
The SOP Change Management Workflow
A practical change management process for agent SOPs follows four stages. First, a change proposal is submitted describing what is changing, why, and what impact is expected on agent behavior. Second, the proposed change is tested in a staging environment against a representative sample of production-equivalent inputs, with performance metrics compared against the current version baseline. Third, the change undergoes a review and approval step by the SOP owner and any relevant stakeholders — compliance, operations, legal where applicable. Fourth, the new version is promoted to production with monitoring alerts configured to detect performance regressions within the first 48 hours.
This process feels like overhead the first time you implement it. By the tenth SOP update, it feels like basic competence — and the time it saves in incident response vastly exceeds the time it costs in process.
Semantic Versioning for SOPs
Borrowing semantic versioning conventions from software (MAJOR.MINOR.PATCH) works well for SOPs. A patch version increment (1.0.0 → 1.0.1) indicates a minor clarification that doesn’t change behavior. A minor version increment (1.0.0 → 1.1.0) indicates new optional behaviors or added edge case handling. A major version increment (1.0.0 → 2.0.0) indicates a change to core procedure logic that may produce different outputs from identical inputs — and therefore requires re-evaluation of all downstream systems that depend on this SOP.
Observability as SOP Enforcement: How to Know When Your Procedure Breaks

Traditional application performance monitoring — latency, uptime, error rates — is necessary but not sufficient for AI agent systems. An agent can have 100% uptime and 0% error logs while producing confidently wrong outputs that silently corrupt downstream processes. Agent-native observability means monitoring what the agent is actually doing, not just whether it is running.
The Four Observability Pillars for Agent SOPs
Step-level tracing records the execution of each individual step in the SOP, including inputs, outputs, decision branches taken, tool calls made, and latency. This is the foundation of debugging: when a run produces a wrong output, step-level traces let you identify exactly which step diverged from expected behavior and what input triggered the divergence.
Semantic quality evaluation assesses whether agent outputs are correct in meaning, not just syntactically valid. A document extraction agent might produce well-formatted JSON with plausible-looking values — and still have the wrong vendor ID, a transposed invoice amount, or a payment term that contradicts the source document. Semantic quality checks compare outputs against known-good references, use secondary validation agents, or trigger statistical sampling for human review.
Behavioral drift detection tracks changes in agent behavior over time — specifically, whether the distribution of decisions, tool call patterns, or output characteristics is shifting in ways that aren’t explained by changes in input data. Drift that isn’t explained by input changes is almost always caused by a change in the model, the tool environment, or the data infrastructure that the SOP didn’t account for.
Cost and rate monitoring tracks token consumption, tool call volumes, and execution time at the step level. Sudden increases in any of these metrics are often the first observable signal of a feedback loop, a runaway retry pattern, or an edge case the agent is handling inefficiently — before the problem becomes a failed run or a surprise invoice.
Building SOP Compliance Metrics
The most underused observability metric for agent SOPs is procedure adherence rate: the percentage of runs in which the agent followed the defined SOP steps in the correct order without unauthorized deviations. In a well-functioning system, this should be very close to 100%. When it drops, you have found either a SOP that doesn’t adequately cover a real scenario, or an agent that is circumventing its own procedure — both of which demand immediate investigation.
Process Drift: The Silent Killer of Production Agent Systems
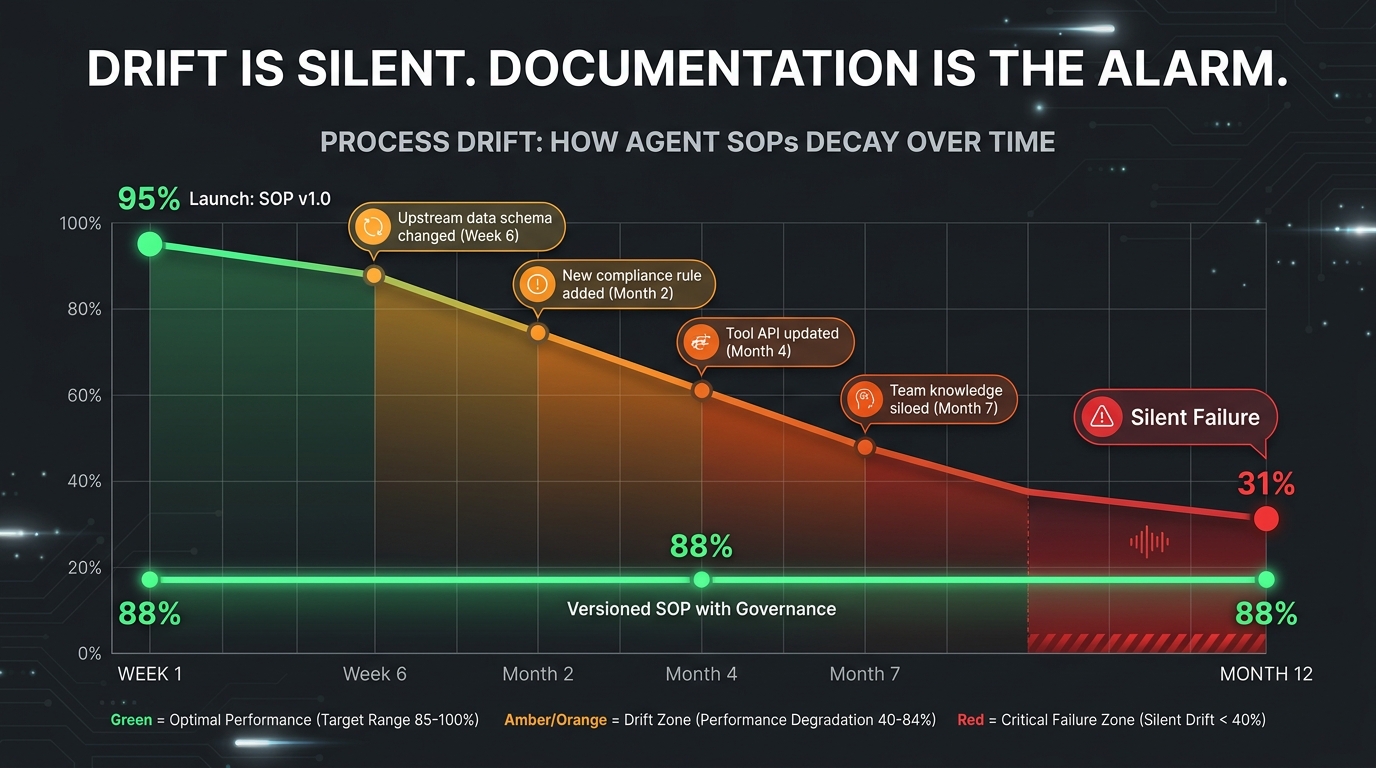
Process drift is what happens when the world changes and the SOP doesn’t. It is insidious precisely because it doesn’t announce itself. The agent continues to run. The logs show no errors. The business continues to believe the system is working. Meanwhile, the gap between what the SOP specifies and what the agent should be doing in the current environment grows wider every week.
The Four Sources of Drift
Data schema drift occurs when upstream data sources change their structure — new field names, changed value formats, deprecated fields — without notifying the agent team. An agent checking for a field called vendor_id will silently fail if that field has been renamed supplier_code in a schema migration. This type of drift is responsible for a disproportionate share of silent agent failures because it produces no error — just wrong or missing outputs.
Policy and compliance drift occurs when regulatory requirements, internal policies, or contractual obligations change after the SOP was written. An agent that was correctly handling invoice approvals under one approval threshold framework will be operating incorrectly if that framework changes — even though the agent itself has not changed at all. Without a defined SOP review schedule that is triggered by policy updates, this drift can persist for months.
Tool and API drift occurs when the external services the agent uses change their interfaces, response formats, rate limits, or availability characteristics. This is particularly acute in 2026 as the ecosystem of AI tools and APIs is evolving rapidly. An SOP that specifies a particular API endpoint or response schema becomes incorrect the moment that service issues an update.
Organizational knowledge drift occurs when the team members who understood the nuances of the original SOP move on, and their institutional knowledge is not captured in the documentation. This is perhaps the most insidious form of drift because it doesn’t affect the agent’s behavior directly — it affects the humans’ ability to evaluate, debug, and update the agent correctly. The SOP becomes a document that everyone treats as authoritative but no one fully understands.
Building Drift Detection Into Your SOP Infrastructure
The practical counter to drift is a SOP review trigger system. Every SOP should have a defined set of events that automatically initiate a review: scheduled calendar reviews (quarterly for most SOPs, monthly for high-risk ones), upstream system change notifications (any schema or API change in a dependency triggers a review of all SOPs that reference it), performance threshold alerts (a drop below a defined success rate metric triggers a review within 48 hours), and compliance update notifications (any relevant regulatory change triggers a review of all SOPs in that domain).
Reviews are not necessarily rewrites. A review might confirm that the SOP is still accurate and close with no changes. But the act of conducting the review — verifying that the current procedure matches current reality — is what prevents the silent accumulation of drift that eventually produces a catastrophic failure.
Building a SOP Culture: Making Procedure Documentation a Team Reflex
All of the technical infrastructure described above is worthless if the team that builds agents doesn’t treat SOP creation as a first-class engineering responsibility. In most organizations, documentation is what happens after the interesting work is done — which means it rarely happens at all. Changing this requires addressing both the incentive structure and the practical friction of documentation work.
The “Definition of Done” Approach
The most effective structural intervention is to add SOP documentation to the definition of done for any agent deployment. An agent is not “done” when it passes testing. It is done when the SOP is written, reviewed, versioned in the repository, observability alerts are configured, and the HITL checkpoints are live and tested. This is not bureaucracy for its own sake. It is the same discipline that software engineering applied to testing and code review — and it produces the same long-term quality improvements.
Teams that implement this standard report initial resistance followed by a significant reduction in production incidents. The investment at the front end of each deployment pays back in reduced firefighting, easier onboarding for new team members, and a growing library of reusable SOP components that accelerates future development.
Reducing Documentation Friction With AI Assistance
One of the most promising developments in this space is using AI agents to assist in writing SOPs for other AI agents. An agent that observes a successful pilot run, analyzes the execution trace, and generates a draft SOP (including step definitions, decision branches, and suggested guardrails) can reduce the documentation overhead from hours to minutes. The engineer’s role shifts from authoring the SOP to reviewing and refining it — a dramatically lower-friction workflow.
This meta-automation — using agents to document agents — is already in use at several forward-thinking engineering teams and represents a sustainable path to making SOP creation genuinely practical at scale.
The SOP Review Ritual
Beyond initial creation, the most important cultural practice is the regular SOP review ritual: a brief, scheduled session where the team reviews recently deployed SOPs, discusses any production observations, and makes any necessary updates. Fifteen minutes per sprint, attached to an existing engineering ceremony, is sufficient for most teams. The discipline of regular review is what turns documentation from a one-time artifact into a living system.
From SOP to System: The Compounding Returns of a Documented Agent Library

The most compelling argument for rigorous agent SOPs is not the prevention of failure — though that alone justifies the investment. It is the compounding returns that accumulate when your SOPs become a library of reusable, battle-tested process assets.
The SOP as Organizational Asset
A well-written agent SOP captures something more valuable than how to run a particular automation. It captures the organization’s understanding of a business process in executable form. The vendor onboarding SOP is not just an agent instruction set — it is a codified version of your procurement team’s institutional knowledge about what correct vendor onboarding looks like, including all the edge cases and exceptions that took years of experience to identify.
This captured knowledge does not retire when the agent is updated. The SOP becomes a reference point for training new staff, auditing compliance, evaluating process improvements, and onboarding new tools or models. Organizations that have built libraries of 20 or 30 documented agent SOPs report that new agent deployments in related domains can be prototyped in days rather than weeks, because they are composing from known-good process logic rather than starting from scratch.
Composability and the SOP Primitive
Once your team has documented enough SOPs, patterns emerge. Certain step sequences appear across multiple procedures. Certain guardrail configurations are applicable to entire categories of business process. Certain HITL checkpoint designs work well for specific risk profiles. These patterns can be extracted into SOP primitives — reusable components that can be composed into new procedures without being rebuilt from scratch.
A team that has built SOP primitives for data extraction, entity validation, exception routing, and compliance checking can assemble a new SOP for a related process in hours, with a high degree of confidence in the reliability of each component — because those components have already been proven in production. This is the point at which agent documentation stops being overhead and starts being a genuine competitive advantage.
Cross-Team Knowledge Transfer
Perhaps the most underappreciated benefit of a documented SOP library is what it enables across teams and organizational boundaries. When the finance team’s AP automation is documented in a rigorous SOP, the procurement team can understand exactly what the agent does and design their own processes to interface with it cleanly. When the legal team’s contract review SOP is documented, the compliance team can assess it against regulatory requirements without needing to interrogate the engineers who built it.
This cross-team transparency — made possible only by rigorous documentation — is what allows AI agent adoption to spread through an organization coherently rather than as a collection of isolated, incompatible experiments. It is the difference between an AI program and an AI capability.
The Practical Implementation Sequence: Where to Start
If you are starting from a position where your team has no formal SOP practice for AI agents, the path forward is not to immediately document everything. It is to choose one successful agent that is already in production, write the SOP retrospectively using the run autopsy method, publish it in a repository, configure basic observability, and use that experience as the template for every future deployment.
The First SOP Sprint
Allocate one focused sprint to the retrospective SOP for your most mature running agent. The sprint has four phases: knowledge extraction (run autopsies and SME interviews, 2–3 days), SOP drafting in the 5-layer structure described above (2 days), internal review and revision (1 day), and observability configuration to match the new SOP (1 day). By the end of the sprint, you have your first properly documented agent system and, more importantly, a team that has been through the process once and knows how it works.
The Onboarding Gate
After the first SOP sprint, implement the definition-of-done gate for all new agent deployments. No agent reaches production without a documented SOP. For the first few months, this will slow initial deployment slightly. Within two quarters, it will accelerate it — because the growing SOP library means new agents are being built from composed primitives rather than blank pages.
The Review Cadence
Set up quarterly reviews for all active SOPs and monthly reviews for any SOP covering a high-risk or compliance-sensitive process. Assign a named owner to each SOP. Put the review dates in the team calendar as recurring events. These 30 minutes per SOP per quarter are the most leverage-efficient time investment in your entire AI operations practice.
Conclusion: The Ops Mindset Shift That Separates Durable Systems From One-Hit Wonders
The gap between an AI team that accumulates one-off wins and an AI team that builds durable, compounding capability is fundamentally a documentation gap. It is the difference between treating agents as experiments and treating them as systems. It is the difference between knowing that something worked once and knowing exactly why it worked and how to make it work again.
The production failure rates for AI agents — 70 to 95 percent in unstructured deployments — are not a verdict on the technology. They are a verdict on the operational maturity of teams that deploy the technology without the procedural infrastructure to support it. The 5 to 30 percent of agents that do work reliably in production are not running on better models or more sophisticated tooling. They are running on better documentation.
Building that documentation discipline is not glamorous work. It does not make for exciting demo presentations. It will not generate headlines. But it is, without question, the work that determines whether your AI program produces a collection of impressive pilots or a library of productive, compounding systems that deliver value every day — with or without the original builders watching.
The agents that last are the ones someone took the time to describe precisely. Everything else is a memory, and memories are not infrastructure.
Key Takeaways
- Define repeatability explicitly. A successful agent run is not a repeatable system until it has written success criteria, documented fallback paths, and no dependency on informal human intervention.
- Use the 5-layer SOP stack. Intent → Context → Procedure → Guardrails → Governance. Each layer must exist before the one above it can be built correctly.
- Extract knowledge from successful runs immediately. Run autopsies within 24 hours of a successful pilot capture tacit logic before it fades from institutional memory.
- Version your SOPs like code. Every change needs a version number, a changelog entry, a review process, and a rollback path.
- Monitor for procedure adherence, not just uptime. An agent can be running while silently violating its own SOP. Behavioral observability is the only way to know the difference.
- Treat drift as a known risk with a defined response. Build review triggers into your SOP infrastructure and review schedules into your team calendar.
- Build a library, not a collection. Extract SOP primitives from mature procedures and use them to accelerate future deployments. The compounding value of documented agent systems is real and measurable.


