
AI agents are no longer sitting in sandbox demos or proof-of-concept slides. In 2026, they’re scheduling meetings, updating CRMs, drafting contracts, managing support queues, and — in some deployments — triggering financial transactions. The shift from “AI that suggests things” to “AI that does things” is the defining infrastructure change of this decade.
But here’s where most organizations are quietly stalling: deployment has sprinted ahead of governance. According to Gravitee’s 2026 AI Agent Security Report, 88% of organizations reported confirmed or suspected AI agent security or privacy incidents in the past year. And yet only a fraction have deployed formal, documented guardrail architectures for the workflows those agents are running inside.
The most common response — adding a human-approval step and calling it “human-in-the-loop” — turns out to be insufficient, and in some cases actively counterproductive. Approval fatigue is real. Alert volume scales faster than human attention. Governance that exists on paper but degrades in practice is worse than no governance at all, because it creates false confidence.
This piece is about what actually works. Not the theory of guardrails, but the architecture of them — how to design a layered control stack that holds in real client workflows, how to tier your controls by risk, how to build for reversibility, and how to use observability as active safety infrastructure rather than passive logging. We’re also going to tackle the harder organizational question: when does protecting a workflow start to look like throttling it?
The organizations getting this right in 2026 are treating guardrails not as a compliance checkbox but as a design discipline. The ones getting it wrong are discovering that autonomous agents operating without proper containment have a very short distance between “impressive demo” and “expensive incident.”
Why “Prompt Safety” Was Never Enough
The first generation of AI safety work inside organizations focused almost entirely on the model layer. Teams invested heavily in system prompt engineering — adding instructions like “do not discuss competitors” or “always recommend consulting a professional” — and content filters that blocked offensive or inappropriate outputs. For a chatbot that answered questions, this was broadly adequate.
Agents are fundamentally different. An agent doesn’t just respond to a prompt — it plans, selects tools, executes actions, observes outcomes, and loops back to plan again. A system prompt cannot govern a multi-step execution chain the way it can govern a single response. The attack surface isn’t just the input; it’s every tool call, every API invocation, every piece of retrieved context, and every decision point in the loop.
The Model Layer vs. the System Layer
This distinction — model-level safety vs. system-level safety — is the key conceptual shift that governance frameworks in 2026 are built around. Model-level safety asks: “Can this model be made to say harmful things?” System-level safety asks: “What can this agent actually do, and what’s the blast radius if something goes wrong?”
The shift matters because a perfectly aligned model embedded inside a poorly designed agentic workflow can still cause real damage. It can read data it shouldn’t have access to. It can send communications that shouldn’t be sent. It can make changes to systems that are difficult or impossible to reverse. The model’s behavior might be entirely “correct” by its training — but the workflow architecture gave it tools it shouldn’t have had, and permissions that weren’t scoped appropriately.
From Content Moderation to Runtime Control
The expert consensus in early 2026 is clear: the frontier of AI safety has moved from content moderation to runtime control. This means the conversation has shifted from filtering what an agent says to governing what it does — which tools it can call, which systems it can reach, which actions require human review, and which actions are categorically off-limits.
This is not a small update. It requires organizations to think about their AI governance architecture the same way they think about their network security architecture: in layers, with defense-in-depth, enforced at the system level rather than relying on any single point of control.
Runtime guardrails that organizations are deploying in production in 2026 include: policy-as-code enforcement on agent action types, sandboxed execution environments that limit what external systems an agent can reach, pre-action authorization gates on high-impact operations, and real-time anomaly detection on agent behavior patterns. None of these are prompt-level interventions. All of them operate below and around the model.
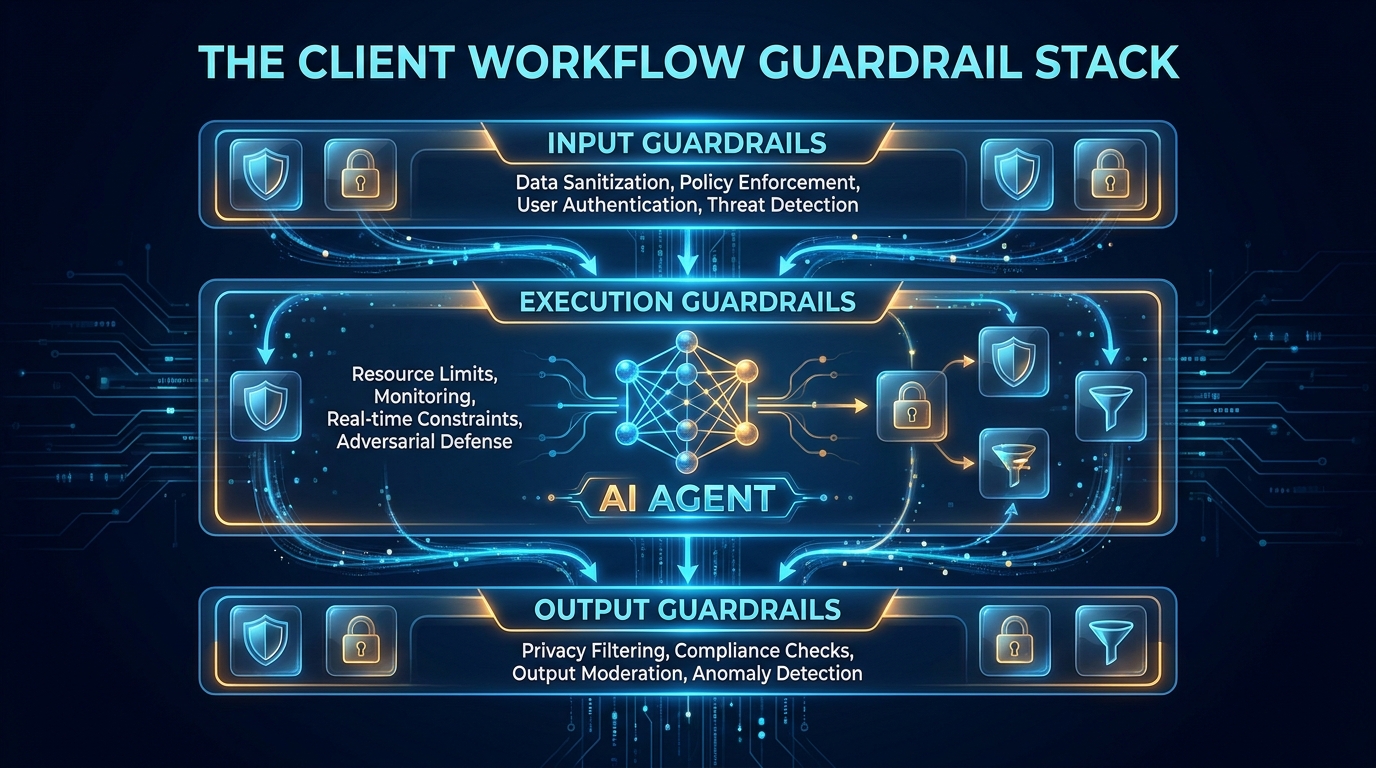
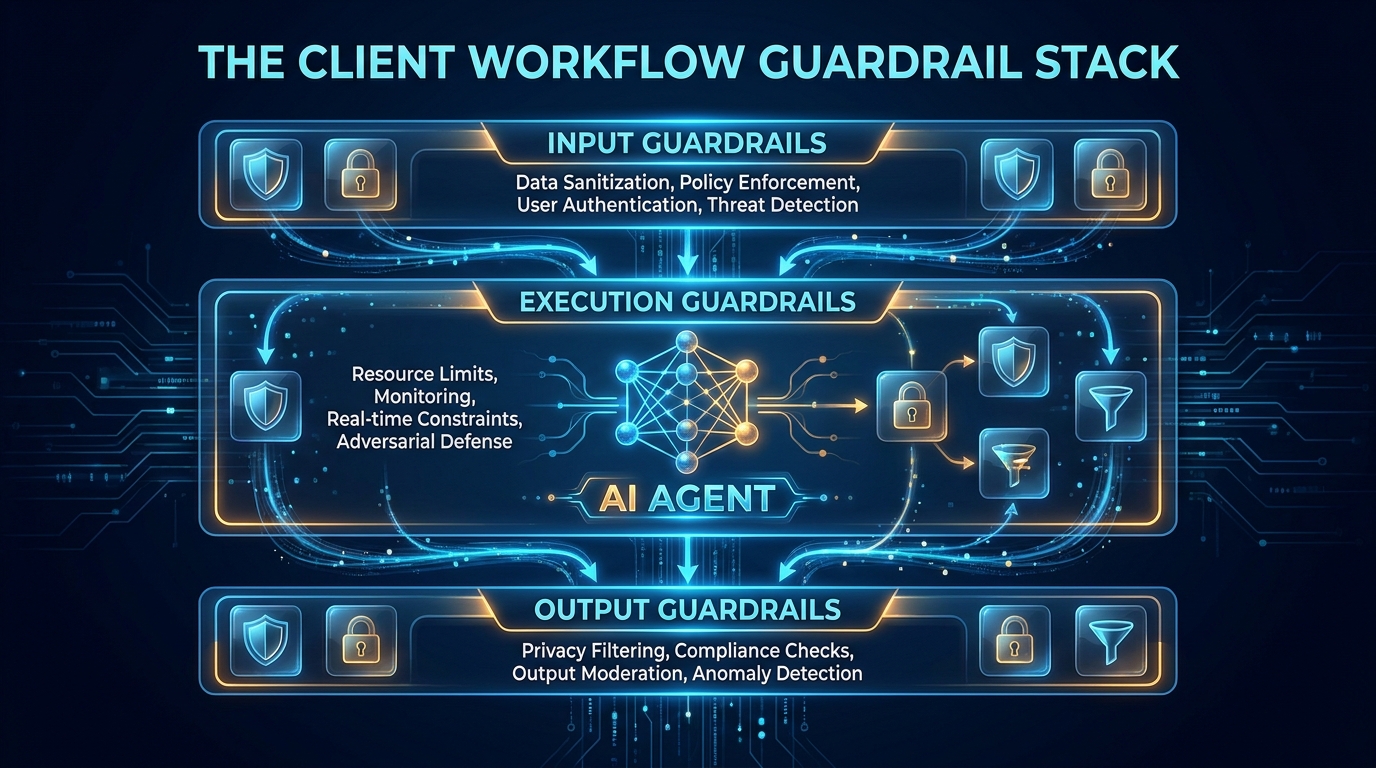
The Three-Layer Guardrail Stack
The most durable guardrail architectures in production share a common structural pattern: three distinct layers, each responsible for a different phase of the agent’s operation. These aren’t stages — they run concurrently and enforce against each other. Understanding each layer’s role is the starting point for any serious guardrail design.
Layer 1: Input Guardrails
Input guardrails operate before the model or planning loop sees a prompt or context. Their job is to protect the agent system from adversarial or policy-violating inputs — most critically, prompt injection attacks, where malicious instructions are embedded in data the agent retrieves and processes as part of its workflow.
In a client workflow, input guardrails typically include: prompt classification (does this input request fall within the agent’s defined scope?), PII and sensitive data detection (does the input contain data that shouldn’t be processed by this agent?), rate limiting and cost controls (is this request volume consistent with expected usage?), and source validation (is the retrieved context coming from trusted, permissioned data sources?).
OWASP’s Agentic Applications Top 10 classifies Agent Goal Hijack (ASI01) as the most critical risk — the scenario where indirect prompt injection through retrieved data, external content, or tool outputs redirects what the agent is actually trying to accomplish. Input-layer guardrails are the first line of defense against ASI01, but they’re not sufficient on their own, which is why the stack has three layers.
Layer 2: Execution Guardrails
Execution guardrails are the most operationally complex layer — and the one most organizations underinvest in. They operate during the agent’s planning and action loop, governing which tools can be called, what parameters those tools can accept, which external systems can be reached, and what sequence of actions is permissible.
The primary controls at this layer are: tool-level permissions (scoped, minimal-privilege access to each tool the agent can use), action-type restrictions (read operations vs. write operations vs. delete or send operations may have entirely different authorization requirements), pre-action authorization gates (a step that confirms human or policy approval before high-impact actions execute), and sandbox boundaries (hard limits on which APIs, databases, or external services the agent’s execution environment can reach).
Execution guardrails are where “blast radius” is actually controlled. If an input-layer guardrail fails — if a prompt injection succeeds and the agent is misdirected — the execution layer is what determines how much damage the misdirected agent can do before it’s stopped.
Layer 3: Output Guardrails
Output guardrails validate what the agent produces before it reaches users, clients, or downstream systems. In a simple chatbot, this means checking the response for policy violations, hallucinations, or sensitive content. In an agentic workflow, it means checking not just text output but the results of completed action sequences — did the CRM update happen correctly, does the drafted document conform to templates, does the API response confirm that the intended action was executed and not something else?
Output-layer controls also include: response sanitization (stripping data that shouldn’t leave the agent’s context), output evaluation (automated checks for factual accuracy, format compliance, and policy adherence), action receipt logging (a confirmed record of what was actually done, not just what was planned), and escalation triggers (conditions under which the output prompts a human review queue rather than direct delivery).
The important point is that these three layers must be designed together. An organization that has strong input filters but weak execution controls has a system that catches adversarial prompts but can still be made to do too much by confused, ambiguous, or edge-case instructions. A system that has strong input and output controls but no execution sandboxing has an agent that can reach systems it shouldn’t — and the output validation is just checking the damage after it’s done.
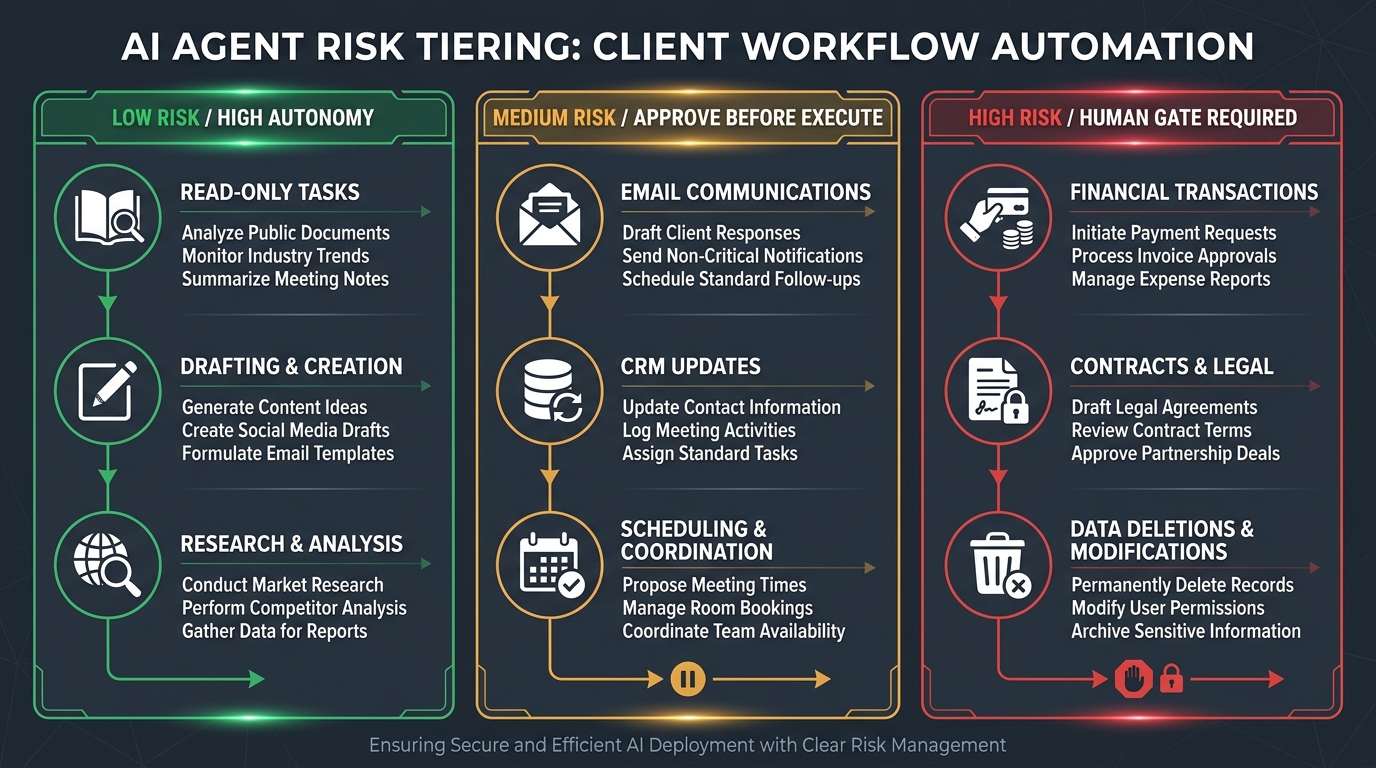
Risk Tiering: Matching Autonomy to Workflow Impact
One of the most operationally useful frameworks to emerge from 2026 enterprise deployments is risk-tiered guardrails: the idea that not all agent actions are equally dangerous, and not all of them need the same level of oversight. Designing a single uniform guardrail policy for all agent actions is a path to either under-protecting high-risk actions or over-constraining low-risk ones.
The practical approach is to classify each workflow action — or each category of action — into a risk tier, and then design oversight requirements appropriate to that tier. Most production architectures in 2026 are using a three-tier model.
Tier 1: Low Risk — Full Automation
Tier 1 covers actions that are read-only, reversible, or limited in their external impact. Examples in client workflows include: summarizing meeting notes, drafting a document for human review, retrieving data from an internal database, generating a report, classifying an incoming request, or searching a knowledge base. The key characteristic is that the agent’s action doesn’t change the state of any external system, doesn’t communicate outside the workflow, and doesn’t commit the organization or client to anything.
These actions can be fully automated. Guardrails at Tier 1 focus primarily on access control (ensuring the agent only reads data it’s permitted to), cost control (preventing runaway loops that generate excessive tokens or API calls), and output validation (checking that the result is accurate and format-compliant before it’s surfaced to a user).
Tier 2: Medium Risk — Approve Before Execute
Tier 2 covers actions that write to systems, communicate externally, or make changes that are difficult but not impossible to reverse. Examples include: sending a draft email (queued for review before sending), updating a CRM record, creating a calendar event, submitting a form, publishing content to an internal wiki, or making a moderate API write request. These actions have real-world consequences, but the consequences are manageable if caught before or shortly after execution.
Tier 2 actions typically require a human approval step or a policy-based auto-approval conditioned on specific criteria. The design challenge at this tier is keeping the approval step lightweight enough that it doesn’t become a bottleneck — which is exactly where approval fatigue starts. Well-designed Tier 2 governance shows the reviewer only the most relevant information (what the action is, why the agent chose it, what it will change) and makes approval or rejection a two-click decision, not a deep review.
Tier 3: High Risk — Hard Gate
Tier 3 covers actions that are irreversible, high-impact, or have significant external consequences. Examples include: executing a payment or financial transaction, sending a client-facing communication, deleting or overwriting records, executing code in a production environment, signing a document, or modifying access credentials. These are actions where an error — whether caused by model hallucination, prompt injection, or workflow misconfiguration — can cause damage that is difficult or impossible to undo.
Tier 3 actions require a hard gate: explicit human authorization that is documented, logged, and cannot be bypassed by the agent or by approval fatigue mechanics. Some organizations implement dual-authorization for the highest-risk Tier 3 actions — requiring two independent reviewers to approve before execution. The principle is that autonomy stops at the boundary of irreversibility.
Blast Radius Design: Building for Failures You Haven’t Anticipated

No guardrail architecture is perfect. Prompt injections will occasionally succeed. Edge cases will confuse the planning loop. Tool calls will return unexpected results that the agent misinterprets. The question isn’t whether failures will happen — it’s how much damage a failure can cause before it’s caught and contained.
This is the concept of blast radius, borrowed from security architecture: the maximum scope of damage that a single failure can produce. Designing for minimal blast radius is what separates deployments that recover from failures versus those that generate incidents from them.
The Reversibility Principle
The single most powerful blast-radius reduction technique in agentic workflow design is what practitioners are calling the reversibility principle: default to reversible actions, and treat every irreversible action as an exception that requires explicit justification.
In practice, this means auditing every tool in an agent’s toolkit for reversibility. Sending an email: irreversible. Drafting an email in a queue: reversible. Deleting a database record: irreversible (without backup). Moving a database record to an archive table: reversible. Executing a payment: irreversible. Staging a payment for review: reversible. In almost every case, there’s a reversible version of the same action — it just requires a slightly different workflow design.
Organizations applying the reversibility principle are finding that a large fraction of what looked like “high-risk” actions can be converted into “medium-risk” staged actions with minimal workflow overhead. The agent drafts; a human approves and sends. The agent stages; a human reviews and executes. This doesn’t eliminate automation — it inserts a human confirmation at the irreversibility boundary, which is exactly where human judgment adds the most value.
Scope Containment and Tool Minimalism
The second major blast-radius reduction technique is scope containment: ensuring that the agent’s tool access is the minimum required to accomplish its defined task, with hard limits on what external systems it can reach. This is the application of the least-privilege principle to agent architecture.
In most early agent deployments, tool access was permissive. Agents were given access to everything that might be useful, on the theory that restrictive access would limit usefulness. What this actually creates is an agent with an enormous blast radius — one whose worst-case failure mode is “access to every system in the stack” rather than “access to the three systems needed for this workflow.”
Scoped tool access, combined with sandboxed execution environments that enforce network and API boundaries at the infrastructure level, creates hard limits on what a misdirected or compromised agent can actually reach. This is the equivalent of network segmentation for agent deployments.
Circuit Breakers and Automatic Halts
Production deployments in 2026 are also implementing circuit breakers at the workflow level — conditions under which the agent automatically halts and escalates to human review rather than continuing. Common circuit-breaker triggers include: repeated failed tool calls (indicating the agent may be stuck in a loop), unexpected tool outputs that don’t match expected schemas, exceeding defined cost or token-count thresholds, attempting to access a system that isn’t in the approved tool list, or detecting output patterns consistent with prompt injection success.
Circuit breakers don’t require the guardrail to anticipate every possible failure mode — they require it to detect anomalies that suggest the agent is operating outside its expected behavioral envelope. The agent doesn’t need to explain why it halted; it just needs to stop, log the state, and route to human review.
The Approval Fatigue Problem: When Human-in-the-Loop Breaks Down

Ask most teams what their AI agent guardrails look like, and the answer will include “human-in-the-loop.” It’s become the default governance answer, the phrase that ends the concern about autonomous AI. But in early 2026 production deployments, human-in-the-loop is increasingly revealing itself to be a governance illusion when it’s applied uniformly to everything.
The failure mode has a name: approval fatigue. When human reviewers are asked to approve every agent action — or even a high volume of low-stakes actions — the cognitive load of reviewing becomes unsustainable. What starts as careful review degrades into rubber-stamping. Reviewers begin clicking “approve” reflexively, just to clear the queue. In some deployments, teams have enabled “auto-approve mode” or “YOLO mode” — effectively bypassing the human review entirely under the cover of a nominal human-in-the-loop architecture.
Why Uniform Review Policies Fail
The root cause of approval fatigue is almost always a uniform review policy applied to a heterogeneous set of actions. If an agent completes 200 actions per day and all of them require human review, the reviewer is processing 200 approvals — most of which are routine, obvious, and low-stakes. The signal-to-noise ratio in the review queue drops to the point where it can’t surface the actual high-risk actions that require genuine human judgment.
This is a system design problem, not a human attention problem. You cannot solve it by asking reviewers to try harder. You solve it by redesigning the review queue to contain only actions that actually require human judgment — which means risk tiering, as described above, and routing only Tier 2 and Tier 3 actions to human review.
Risk-Tiered Oversight in Practice
Organizations that have moved past approval fatigue in 2026 are applying a pattern called risk-tiered oversight: automated handling of Tier 1 actions with post-hoc sampling review, lightweight structured approval for Tier 2 actions, and mandatory full review with documented authorization for Tier 3 actions.
The “sampling review” element for Tier 1 is particularly important. Rather than reviewing every Tier 1 action, reviewers periodically audit a random sample — say, 5% of completed actions — to verify that the agent is behaving as expected. This maintains meaningful oversight without creating volume-driven cognitive overload. If the sample review reveals anomalies, the sampling rate increases, and potentially the actions get reclassified to Tier 2.
Making Approval Decisions Faster Without Making Them Worse
For the Tier 2 actions that do go to human review, the design of the approval interface matters enormously. A reviewer who has to navigate to a separate system, read a long agent trace, understand the full context, and then decide whether to approve is going to be slow and is likely to cut corners. A reviewer who sees a single screen showing: “The agent drafted this email to client X — here’s the draft, here’s why it triggered review, here’s what approving will do” can make a quality decision in seconds.
The best approval interfaces in 2026 deployments are designed around the principle that the reviewer’s job is to verify intent and check for obvious errors — not to reconstruct the agent’s entire reasoning chain. Structured approval cards, pre-populated context summaries, and one-click approve/reject with a required rejection reason are the design patterns that keep Tier 2 review both fast and meaningful.
Identity, Access, and the Least-Privilege Agent
One of the most underappreciated dimensions of AI agent guardrails is identity. In most early deployments, agents operated under service accounts with broad access — often the same permissions as the human engineer who set them up. This is the IAM equivalent of giving a new employee the same access as the CISO because it was easier than thinking through what they actually need.
The OWASP Agentic Applications Top 10 includes Identity and Access Mismanagement as a top-tier risk precisely because permissive agent identities are one of the most common and most damaging failure modes in real deployments. An over-privileged agent that gets compromised via prompt injection can do what its identity allows — and if that identity has broad access, the blast radius is enormous.
Agents as First-Class Identities
The architectural shift that’s happening in 2026 is treating agents as first-class identities with their own IAM profile — not as service accounts or human-adjacent credentials. This means each agent gets its own identity, its own scoped permissions, its own audit trail, and its own credential rotation schedule. The permissions for that identity are defined based on the minimum access required for the specific workflow the agent is running — nothing more.
Role-based access control (RBAC) for agents means defining roles that map to specific workflow capabilities. An agent handling customer support ticket triage gets read access to the ticket system and write access to ticket status fields — not read access to the billing system, not write access to user account settings, not API keys for external communication services. Every permission is a decision, and the default is deny.
Credential Scoping and Expiry
Credential management for agents in production deployments includes: short-lived credentials that expire and rotate automatically (preventing compromised credentials from enabling sustained access), scope-limited API keys that restrict what endpoints each credential can reach, context-bound tokens that are issued per workflow instance rather than per agent (so a credential issued for one workflow instance can’t be used by another), and regular access reviews that verify permissions haven’t drifted beyond what’s needed as workflows evolve.
Privilege creep — where agent permissions gradually accumulate over time as workflows are extended — is one of the most common governance failures in longer-running deployments. Automated access review tooling that flags agents whose permissions exceed their recent usage pattern is becoming standard in mature guardrail architectures.
Multi-Agent Trust Boundaries
As more organizations move from single-agent workflows to multi-agent architectures — where one orchestrating agent delegates tasks to specialized sub-agents — the question of inter-agent trust becomes critical. Should a sub-agent automatically trust instructions from an orchestrating agent? The answer in secure architectures is: no, not unconditionally.
The principle of inter-agent skepticism means that each agent in a multi-agent system maintains its own guardrail stack — it doesn’t bypass its input or execution guardrails just because the instruction came from another agent rather than a human. An orchestrating agent that has been compromised via prompt injection should not be able to cause downstream sub-agents to take actions they wouldn’t otherwise be permitted to take.
The OWASP Agentic Top 10: A Practical Risk Map for Workflow Design
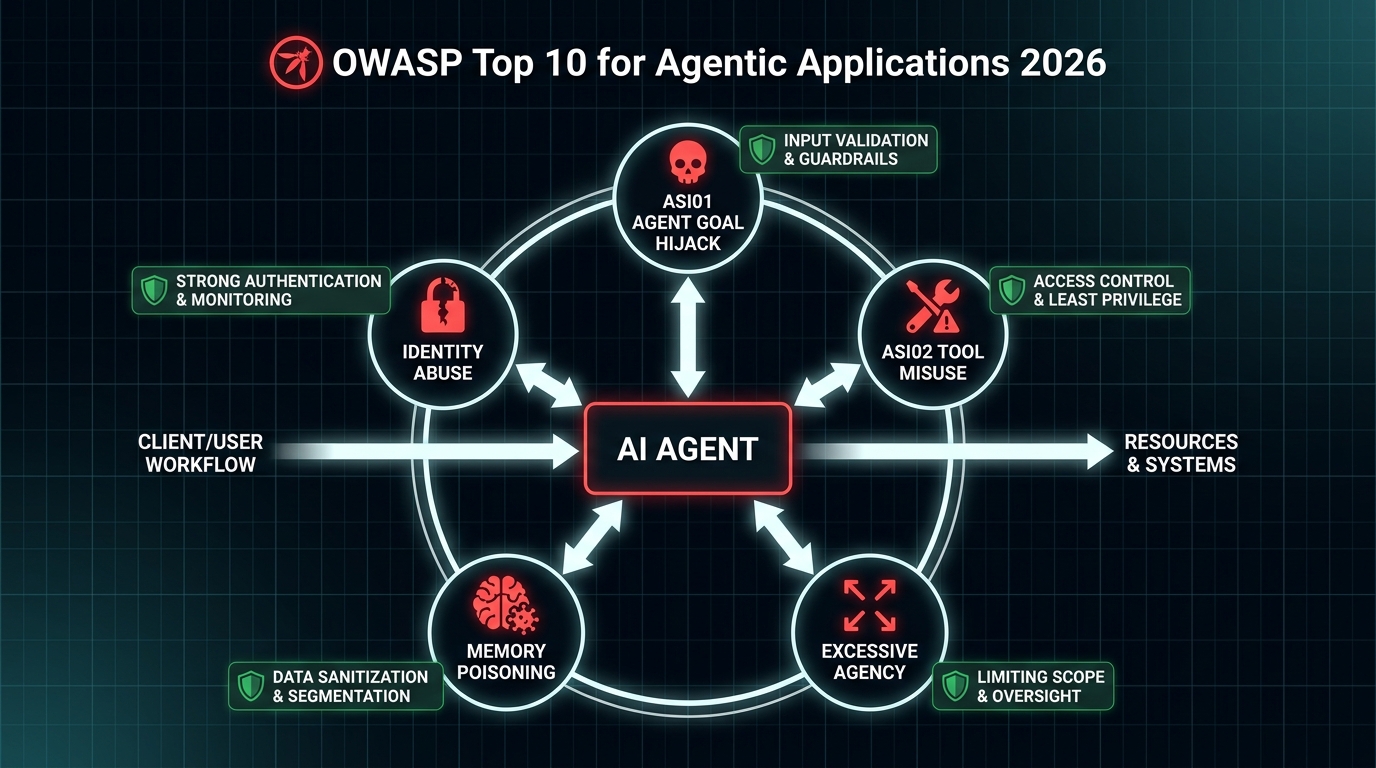
The OWASP Top 10 for Agentic Applications, finalized in December 2025 and now widely adopted as the primary security taxonomy for autonomous agent systems, provides the clearest structured view of what can go wrong. Understanding these risks in terms of client workflow design — not just as abstract categories — is how you use the framework productively.
ASI01: Agent Goal Hijack
The most critical risk in the OWASP agentic taxonomy. Goal hijack happens when malicious content embedded in the agent’s context — retrieved documents, web pages, API responses, user inputs — successfully redirects the agent’s objectives. The agent behaves correctly relative to its (now hijacked) goal, but the goal is no longer what the deploying organization intended.
In a client workflow context, this is the scenario where an agent processing a client’s submitted document encounters embedded instructions designed to redirect it — to exfiltrate data, to take a prohibited action, to generate misleading outputs. The mitigation architecture combines input-layer validation of retrieved content, constrained tool scopes that limit what a redirected agent can do even if the injection succeeds, and output validation that checks whether the agent’s output is consistent with its defined purpose.
ASI02: Tool Misuse and Exploitation
Tool misuse covers scenarios where the agent calls a legitimate tool in an unexpected, unauthorized, or harmful way. This includes calling tools with parameters outside their intended range, chaining tool calls in sequences that weren’t anticipated during design, or using a tool’s functionality for a purpose the tool’s permissions weren’t designed to support.
The mitigation is parameter validation at the tool-call level — not just “is this tool permitted?” but “are these parameters within the acceptable range for this tool in this workflow context?” Tool-call auditing that checks parameter patterns against expected usage profiles can catch misuse that permission-level controls miss.
Excessive Agency (LLM08 / ASI Crossover)
Excessive agency — granting agents more capability, permission, or autonomy than they need for their defined task — appears in both the original OWASP LLM Top 10 (as LLM08) and carries forward into the agentic taxonomy. It’s the root cause of unnecessarily large blast radii. The mitigation is simple in principle and requires discipline in practice: every capability, permission, and degree of autonomy must be explicitly justified by the workflow requirement. The question isn’t “could this be useful?” but “is this specifically needed?”
Memory and Context Poisoning
Agents with persistent memory — those that maintain context across sessions or store information in shared memory stores — face a specific risk: poisoned memories. If an agent stores information from a compromised session, that information can influence future sessions with different users or contexts. In a client workflow context, this means an attacker who can influence one session might be able to affect subsequent sessions via the agent’s persistent memory.
Mitigations include: memory isolation between client contexts, validation of stored memories against expected schemas, expiration policies for persisted context, and monitoring for anomalous patterns in stored memory content.
Using the OWASP Framework as a Design Checklist
The practical use of the OWASP Agentic Top 10 in workflow design is to run through each category before deployment and answer: “What is our specific mitigation for this risk in this workflow?” If the answer is “we don’t have one,” that’s the guardrail gap that needs to be addressed. The framework is most valuable not as a compliance document but as a structured prompt for design review conversations.
Observability and Audit Logging as Active Guardrail Infrastructure
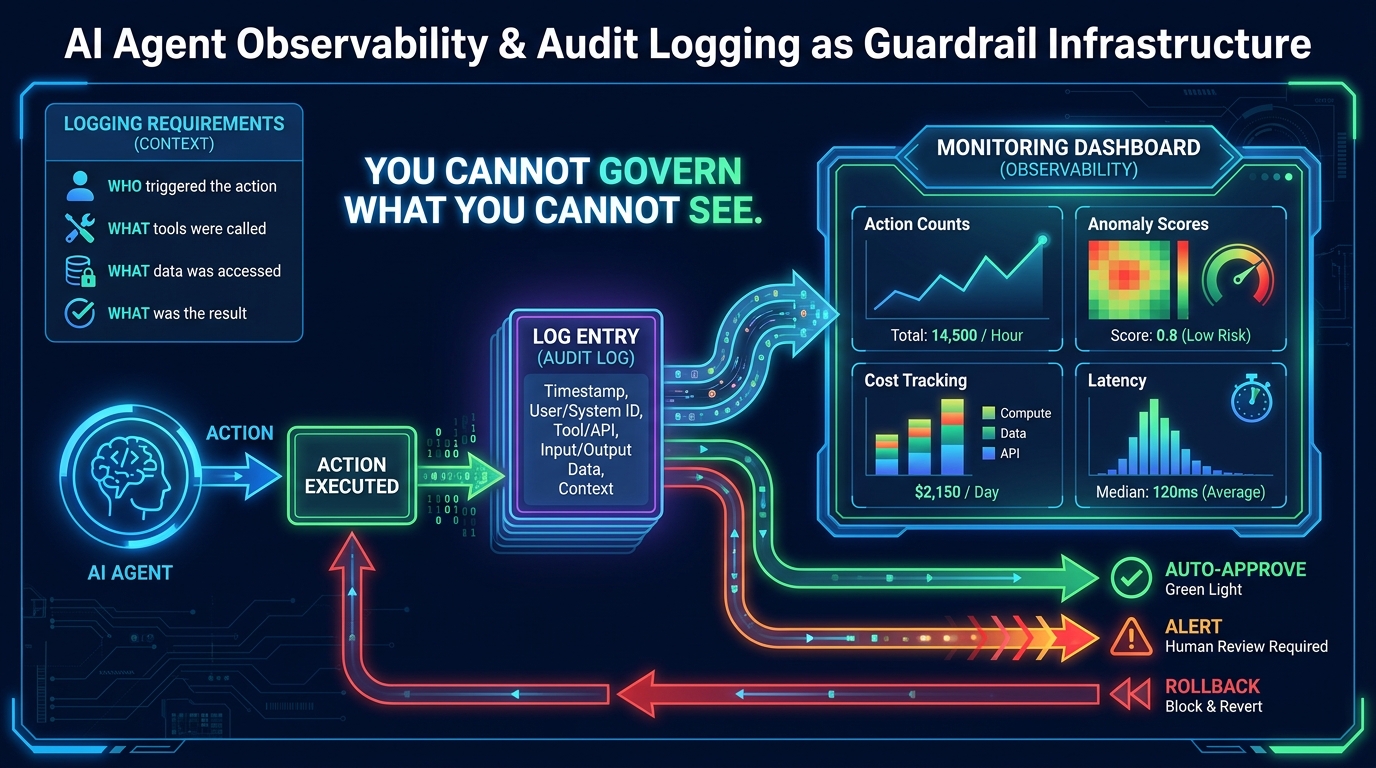
A guardrail architecture that can’t be inspected can’t be improved. More immediately: a guardrail architecture that can’t be inspected in real time can’t detect failures before they propagate. Observability — the ability to understand what an agent is doing, has done, and why — is not a nice-to-have add-on. It’s a foundational requirement for production-grade guardrails.
The most common mistake in early agent deployments was treating logging as a post-hoc record-keeping requirement: store the logs, comply with retention policies, retrieve them if there’s an incident. This is passive logging, and it’s insufficient. Active observability means using the log stream in real time to drive monitoring, alerting, and automatic intervention.
What Agent Logs Must Capture
For an agent audit trail to be useful for both governance and incident response, it needs to capture four categories of information for every action in the execution loop:
- Identity and context: Who or what triggered this agent run? Which workflow, which user, which client context?
- Tool calls and parameters: Which tools were called, with what exact parameters, in what order?
- Data access: Which data sources were queried or read? What was retrieved?
- Action outcomes: What did each action produce? Was the result within expected ranges?
Without all four categories, incident reconstruction is guesswork. With all four, you can replay any agent run step-by-step and understand exactly what happened and why — which is also exactly the data you need to improve guardrail design over time.
Real-Time Anomaly Detection
The transition from passive logging to active observability happens when you build anomaly detection on top of the log stream. Anomaly detection for agents isn’t primarily about security threats — it’s about catching behavioral drift, unexpected action sequences, cost overruns, and edge-case failures before they become incidents.
Common anomaly detection signals for client workflow agents in 2026 include: token or cost rate spikes (indicating runaway loops or unexpectedly expensive operations), unusual tool call frequencies (calling a tool more often than the workflow design anticipated), unexpected external network connections (an agent contacting systems outside its sandbox), output format violations (structured outputs that don’t conform to expected schemas), and latency outliers (execution times significantly longer than the workflow baseline).
Anomaly alerts should have defined response playbooks: what happens when this anomaly fires? Does the agent pause? Does it escalate to human review? Does it continue while a reviewer is notified? Undefined response protocols for observability alerts are almost as bad as no observability at all — because the alert fires and no one is sure what to do with it.
Observability as a Feedback Loop for Guardrail Improvement
The most mature guardrail architectures in 2026 use observability data not just for monitoring but for continuous improvement. The pattern looks like this: production logs are periodically sampled and reviewed, not just for incidents but for near-misses — cases where the agent did something unexpected but not harmful. Near-misses are analyzed to understand whether the guardrail design could have caught them, and if not, what additional control would have.
This creates a feedback loop where the guardrail architecture improves based on real production behavior rather than only pre-deployment testing. Pre-deployment testing is essential but insufficient — it can only test against anticipated scenarios. Production observation catches the scenarios you didn’t anticipate, which is where most actual incidents originate.
Guardrails Across the Full Deployment Arc: From Pilot to Production
The guardrail requirements for an AI agent in a pilot context are categorically different from the requirements for the same agent in a production client workflow. One of the most common failure patterns in 2026 deployments is applying pilot-level governance to production deployments — moving fast through the safety architecture because the early version worked well in a controlled setting.
Pilot Phase: Controlled Scope, Manual Review
In the pilot phase, guardrails can lean heavily on manual review because volume is low and the goal is learning, not throughput. Pilots should deliberately run in environments with restricted access to production systems — using read-only data copies where possible, stubbed tool endpoints that log but don’t execute externally, and small user groups whose outputs can be reviewed comprehensively.
The primary deliverable of the pilot phase isn’t a working agent — it’s a documented understanding of how the agent actually behaves across a diverse sample of inputs. This behavioral map is the foundation for designing production guardrails. If you skip this step and deploy directly to production based on cherry-picked pilot results, you’re deploying a guardrail architecture designed for a best-case scenario rather than the full input distribution.
Staging Phase: Automated Controls with Shadow Monitoring
The staging phase introduces the automated guardrail stack — input classifiers, execution policy enforcement, output validators — alongside shadow monitoring where the agent’s automated decisions are compared against what a human reviewer would have decided. This is the calibration phase: you’re validating that your automated guardrails have the right thresholds and that your risk tiering correctly reflects actual risk levels.
Shadow monitoring in staging is more work than simply deploying and observing, but it’s the only reliable way to validate guardrail accuracy before you’re relying on it in production. It answers the question: “Of the actions the automation passed, what percentage would a human reviewer have flagged?” If that number is high, your Tier 1/Tier 2 boundary is miscalibrated and needs adjustment before production deployment.
Production Phase: Layered Automation with Continuous Audit
Production deployment activates the full guardrail stack: automated handling of Tier 1 actions, structured human review for Tier 2, hard gates for Tier 3, real-time anomaly monitoring, and ongoing sampling review. The important addition at production phase is the formal governance process: who owns the guardrail configuration, how are changes to the stack approved, what’s the incident response protocol if a guardrail failure is detected?
Ownership is a critical governance detail that many organizations overlook. Guardrail architectures that have a clear owner — a specific team or person responsible for their maintenance, review, and improvement — evolve and improve over time. Guardrail architectures that are “owned by everyone” degrade as the system changes around them, because no one has the specific accountability to keep them current.
An Implementation Checklist: Designing the Guardrail Stack for a New Client Workflow
Putting all of this together into a practical starting point: here’s the structured checklist for designing guardrails before deploying an AI agent into any new client workflow. This isn’t a compliance checklist — it’s a design checklist. The goal is to make every guardrail decision explicit before the system goes live.
Scope and Access Design
- What is the specific, bounded task this agent is being deployed to accomplish?
- What data sources does it need read access to? Write access? Are these the minimum required?
- What external systems (APIs, communication services, databases) does it need to reach?
- What IAM identity will the agent operate under, and what are its exact permissions?
- What is the sandbox boundary — what external systems are explicitly off-limits?
Action Classification and Risk Tiering
- What is the complete list of actions this agent can take in this workflow?
- For each action: is it reversible or irreversible?
- For each action: what is the blast radius if it’s executed incorrectly?
- Which tier does each action belong to (Tier 1 / Tier 2 / Tier 3)?
- Are there irreversible actions that can be redesigned as reversible staged actions?
Input, Execution, and Output Controls
- What input classification or validation runs before the agent processes a prompt?
- What tool-call parameter validation is in place at the execution layer?
- What are the circuit-breaker conditions that cause the agent to halt and escalate?
- What output validation checks run before responses reach users or downstream systems?
Human Review Design
- What is the approval interface for Tier 2 actions — what does a reviewer see, and what can they do?
- What is the maximum expected volume of Tier 2 review requests per reviewer per day?
- Is that volume sustainable without causing approval fatigue?
- What is the authorization protocol for Tier 3 actions — who can approve, and how is it logged?
- What is the sampling review cadence for Tier 1 actions?
Observability and Incident Response
- What is being logged for every agent action, and where?
- What anomaly detection signals are configured, and what are the response protocols for each?
- Who owns the guardrail configuration, and how is it updated?
- What is the incident response protocol if a guardrail failure is detected?
- What is the rollback procedure if the agent needs to be taken offline?
Guardrails as Differentiation: The Business Case for Getting This Right
There’s a tempting narrative in the AI deployment space that guardrails are friction — that they slow agents down, reduce their capability, and add cost and complexity to deployment. This narrative is seductive, but it’s backwards in the context of client-facing workflows.
For internal tooling where failures only affect internal users, weak guardrails have limited reputational and legal consequences. For client-facing workflows — where an agent is acting on behalf of an organization in interactions that affect clients — the consequences of a guardrail failure extend far beyond the immediate technical incident. A misdirected client communication, an unauthorized data access, a financial transaction executed in error: these are compliance events, liability events, and trust events simultaneously.
Trust as the Currency of Agentic Deployment
The organizations that are successfully expanding their AI agent deployments in 2026 share a common characteristic: they built client trust early by demonstrating governance discipline before expanding autonomy. They deployed agents first in tightly scoped, well-governed workflows. They showed clients what the guardrail architecture looked like. They provided audit access to logs. They demonstrated the human review process.
That transparency — “here is how we’ve designed this to be safe, here is what we’re monitoring, here is who reviews high-stakes actions” — turns the guardrail stack from an internal technical requirement into an external trust signal. Clients who understand how an agent workflow is governed are significantly more willing to extend its scope than clients who are asked to simply trust that it’s safe.
The Compounding Cost of Skipped Governance
On the other side of this equation, the cost of skipped governance compounds. An agent that runs without proper access controls will eventually acquire permissions it doesn’t need. An agent without circuit breakers will eventually get stuck in a loop that generates significant cost before anyone notices. An agent without risk-tiered oversight will eventually have an approval fatigue failure that lets a high-risk action through without genuine review.
Any one of these outcomes is recoverable. All of them happening in the same client workflow — because governance was treated as a post-deployment consideration — is the kind of scenario that ends programs, damages relationships, and creates the incident case studies that get presented at industry conferences as cautionary tales.
The math is straightforward: the cost of designing guardrails correctly before deployment is substantially lower than the cost of redesigning an already-deployed agent workflow after a governance failure. That’s not a theoretical claim — it’s a lesson that enough early-mover organizations have learned expensively that the industry has largely converged on it as a design principle.
Conclusion: The Guardrail Stack Is the Product
AI agents are going to keep getting more capable, more autonomous, and more deeply embedded in client workflows. That trajectory is not stopping. The question isn’t whether to deploy agents — it’s whether to deploy them with governance architectures that are fit for the autonomy level they’re operating at.
The key principles from 2026’s production deployments are consistent enough to serve as design axioms. Treat guardrails as system design, not as a safety layer bolted on afterward. Match autonomy to risk using explicit tiering. Default to reversibility and treat irreversibility as an exception. Design for blast-radius minimization by scoping access to the minimum required. Replace uniform human review with risk-tiered oversight that puts human attention where it actually adds value. Build observability as active safety infrastructure, not passive logging. And treat the guardrail architecture as a live system that requires ownership, maintenance, and continuous improvement.
The organizations that will extend the most autonomy to their agents in 2026 and beyond won’t be the ones who are most comfortable with risk — they’ll be the ones whose governance architecture has earned that autonomy by demonstrating that the controls hold in production. The guardrail stack isn’t the overhead that slows agents down. It’s the foundation that makes more ambitious deployments possible.
Key Takeaways for Implementation Teams
- Classify every agent action into a risk tier before deployment — don’t apply uniform oversight to heterogeneous risk levels
- Apply the reversibility principle: design staged, reversible versions of actions wherever possible, and treat irreversibility as an exception requiring explicit justification
- Assign agents dedicated IAM identities with scoped, minimal-privilege access — no shared service accounts with broad permissions
- Treat approval fatigue as a design failure: if reviewers are overwhelmed, the tier classification or review interface needs redesign
- Build observability as active infrastructure with real-time anomaly detection and defined response protocols, not just passive logging
- Assign explicit ownership of the guardrail configuration — systems without accountable owners degrade silently over time

