


There is a peculiar blind spot in how most sellers and brands approach AI listing optimization. They treat it as a search problem — a race to outrank competitors on keyword relevance scores, a challenge of feeding the right phrases into the right title fields and backend attributes. The tools are sophisticated, the dashboards are impressive, and the ranking metrics look great. Then the shoppers arrive. And they leave without buying.
This is the conversion gap. It exists because nearly every AI listing tool on the market today is engineered to solve one specific problem: getting your product discovered. That’s a worthy goal, but discovery is only the first micro-conversion in a chain of five or six that leads to a completed purchase. Optimizing only for impressions and clicks is the equivalent of filling a leaking bucket — you can keep pouring more traffic in, but the underlying content structure keeps bleeding potential buyers out.
The data bears this out. The global average e-commerce conversion rate sits around 2.86%. AI-assisted shopping experiences, by contrast, are converting at 12.3% — more than four times higher — with shoppers completing purchases 47% faster when AI helps remove decision friction at the listing level. The gap between those numbers isn’t a keyword gap. It’s a full-funnel optimization gap.
This article isn’t about basic keyword research or how to stuff a title field. It’s about the five conversion stages that happen after a search engine surfaces your listing, the specific ways AI can intervene at each one, and why the sellers pulling ahead in 2026 have stopped thinking about listing optimization as an SEO task and started treating it as a behavioral science problem.
Why Listing Optimization Has Always Stopped at Discovery
To understand where the gap comes from, it helps to trace the history of what listing optimization tools were actually built to do. The first generation of Amazon SEO tools — Helium 10, Jungle Scout, and their contemporaries — emerged as keyword research engines. Their core value proposition was data arbitrage: surface the exact phrases that shoppers type into the search bar, and stuff your listing with those phrases in the right density and positions. It worked extraordinarily well for a long time because the algorithm rewarded relevance signals that were essentially keyword-presence signals.
The second generation added reverse-ASIN competitive intelligence, allowing sellers to identify what keywords their highest-converting competitors were indexing for. Again, the optimization target was the same: search placement. Get to page one, and you win.
AI entered the picture and, rather than rethinking the problem, largely turbocharged the same workflow. LLMs were applied to generate keyword-stuffed copy faster. Machine learning was used to prioritize which keywords to include, based on search volume and competitor density. The output quality improved. The fundamental question being asked stayed identical: how do we get this listing in front of more searchers?
This is a legitimate question. But it is not the only question that matters. And in 2026, it may not even be the most important one.
The Metric Mismatch Problem
Most AI listing tools are optimized for metrics that their vendors can demonstrate in a dashboard: keyword rank, search visibility score, index coverage. These are impressions-layer metrics. They measure your ability to appear in front of shoppers, not your ability to persuade them. The trouble is that the tools that measure what happens after the impression — conversion rate, add-to-cart rate, session-to-order percentage — are siloed in a different system entirely, often a different department, and almost never feed back into the listing optimization workflow in real time.
The result is a systematic optimization mismatch. You end up with listings that are exceptionally good at earning impressions from shoppers who won’t buy them. High-volume keywords that don’t match buyer intent. Titles that front-load phrases that rank well but read awkwardly to a human who’s actually trying to make a decision. Bullet points that list features rather than answer the questions that drive purchase hesitation.
Fixing this requires a different mental model — one that treats the listing not as a search document to be indexed, but as a conversion asset to be experienced.
The Three AI Layers Every Listing Must Now Satisfy

Before diving into the conversion funnel, it’s worth establishing the current technical landscape of what a modern listing must actually accomplish. On Amazon — the world’s largest product search engine — listings in 2026 are evaluated by three distinct AI systems simultaneously, each with a different definition of what makes a “good” listing.
Layer 1: A10 — The Performance Ranker
A10 is Amazon’s core search ranking algorithm, and it operates much as its predecessors did: matching keyword signals to search queries, then sorting by a combination of relevance and performance. Performance here means click-through rate, conversion rate, and sales velocity. Critically, this last point is where keyword optimization meets conversion: a listing that ranks well but converts poorly will see its A10 ranking degrade over time. The algorithm learns that shoppers who click your listing don’t buy, and it surfaces you less often as a result.
This creates a direct, measurable financial incentive to optimize for conversion alongside keywords. Poor conversion doesn’t just cost you the immediate sale — it compounds into reduced organic visibility, which reduces future traffic, which further compounds into even lower conversion opportunities. The ranking and conversion problems are inseparable.
Layer 2: COSMO — The Semantic Knowledge Graph
COSMO is Amazon’s semantic understanding layer. Unlike A10, it doesn’t primarily match phrases — it builds a relational map of what products are, what they’re used for, who uses them, in what contexts, and alongside what other products. A listing that simply contains the keyword “camping tent” will rank for that phrase under A10. A listing that explains the tent’s wind resistance for exposed ridgeline camping, its weight relative to ultralight backpackers’ typical base weight limits, and its compatibility with specific sleeping bag temperature ratings will be understood by COSMO as more than just a camping tent — it will be understood as the right product for a specific buyer in a specific situation.
This semantic depth is what creates the “knowledge document” approach to listing writing. COSMO rewards completeness of context, not completeness of keyword coverage.
Layer 3: Rufus — The Conversational Layer
Rufus is Amazon’s generative AI shopping assistant, and it represents the most direct conversion tool in the stack. It reads your listing’s title, bullets, description, A+ content, and critically, your reviews and Q&A, then answers natural-language shopper questions using that data. Shoppers who interact with Rufus convert at a rate 60% higher than those who don’t, and Rufus has driven over $10 billion in incremental annualized sales since its wider rollout, with 250 million users and triple-digit growth in interactions year over year.
The implication is significant: if your listing doesn’t contain the content that answers the questions Rufus’s users are asking, Rufus will either redirect them to a competitor who does answer those questions, or it will hallucinate an answer — which, if inaccurate, creates a mismatched buyer who is far more likely to return or leave a negative review. In either case, your conversion suffers.
Optimizing for all three layers at once requires a fundamentally different content strategy than traditional keyword stuffing. It requires writing for intent, context, and conversation — not just for phrase matching.
Mapping the Conversion Funnel Inside a Single Listing
Most sellers think of the conversion funnel as a macro-level construct: awareness → consideration → decision. But inside a single product listing, there is a micro-funnel that mirrors this structure exactly, and each stage can be optimized or broken by specific content decisions.
Stage 1: The Impression — Earning the Click
The impression stage is where keyword optimization legitimately matters. Your title and primary image are the only elements visible in search results, and both must simultaneously satisfy A10 relevance scoring and human click psychology. This is the first place where AI keyword tools earn their keep — but it’s also where the most common mistake occurs.
AI-generated titles frequently front-load brand name or product category terms to maximize keyword density in the first 80 characters. This satisfies the algorithm. It often fails the human, who is making a split-second decision about whether this product is worth investigating. The highest-converting titles at the impression stage tend to lead with the core use-case benefit, not the product category. “Waterproof Hiking Boot — Zero-Break-In, Women’s Wide Fit, All Terrain” performs differently in human psychology than “Women’s Waterproof Hiking Boots Wide Width All Terrain Non-Slip” — even when both contain the same keywords.
The AI that earns clicks isn’t just matching keywords. It’s constructing a value proposition that fits in 80 characters.
Stage 2: The Click to Consideration — The First Three Seconds
When a shopper lands on your listing, research consistently shows that the first interaction is visual — the primary image and the pricing block. Within the first three seconds, the shopper has formed a preliminary judgment about whether this is a serious candidate. Only then do they read anything.
AI listing optimization almost universally focuses on text. This is a mistake at Stage 2. The content that governs the click-to-consideration transition is primarily visual: image quality, image storytelling, lifestyle context, and the presence of trust signals like review count and star rating visible on the page. A listing with perfectly optimized keyword copy and low-quality images will hemorrhage shoppers at this stage regardless of how well it ranks.
Stage 3: Consideration to Conviction — Where the Bullet Points Live
If a shopper is reading your bullet points, you have already achieved something meaningful: they’re considering you seriously. This stage is where AI copywriting makes the biggest direct impact on conversion — and where the difference between keyword-optimized and conversion-optimized copy is most visible.
Keyword-optimized bullets look like this: “PREMIUM QUALITY MATERIALS: Made from high-grade stainless steel, this product is durable and long-lasting.” Conversion-optimized bullets address the actual decision friction a buyer experiences: “Won’t rust after the dishwasher — the 18/10 grade steel resists corrosion even after 500+ wash cycles, so you’ll stop replacing utensils every two years.”
The second version contains the same keywords. It also answers the question that was actually blocking the purchase decision.
Stage 4: Conviction to Cart — The Hesitation Zone
This is the stage that most listing optimization completely ignores. A shopper who has read your bullets, looked at your images, and is impressed by the product still has unresolved anxieties that block the add-to-cart action. These are almost always questions about risk: Will it fit? Will it arrive in time? What if I don’t like it? Is this the right size/quantity/version for my specific situation?
A+ content, Q&A sections, and review management exist specifically to address Stage 4 friction. AI tools that analyze review sentiment to identify the most common hesitation questions — and then build that content into A+ modules — are directly attacking the most expensive part of the funnel drop-off.
Stage 5: Cart to Purchase — The Final Micro-Conversion
Cart abandonment is a significant problem in e-commerce: roughly 70% of items added to cart globally are never purchased. Many of the drivers of cart abandonment (complex checkout, unexpected shipping costs) are outside a seller’s listing control. But pricing presentation, urgency signals, and bundle offers at the listing level can meaningfully reduce the gap between “add to cart” and “complete purchase.”
Voice of Customer Mining: AI’s Most Underrated Conversion Tool
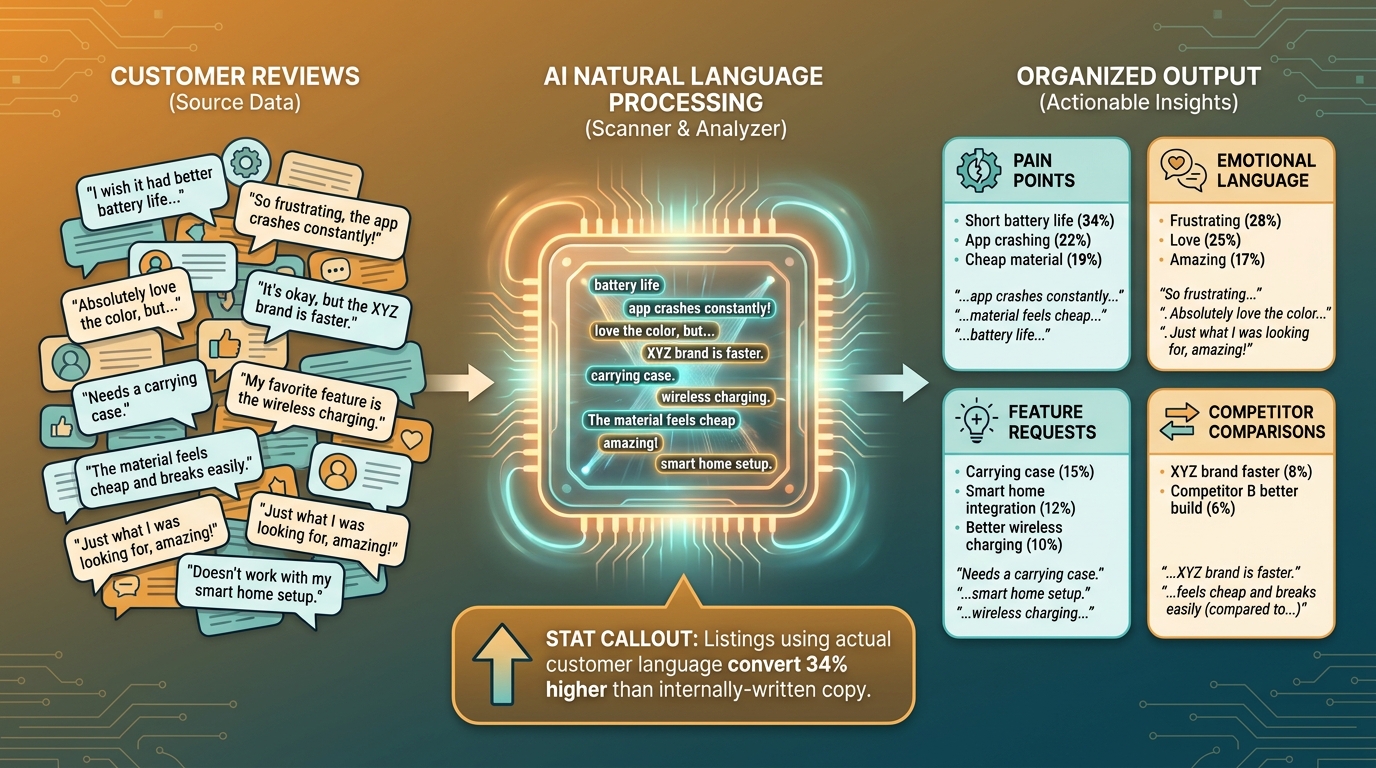
The most valuable conversion copy in the world already exists. It was written by your customers, in their own words, in your product reviews. They described exactly why they bought, what hesitation they overcame, what surprised them, what disappointed them, and what phrase they use to recommend it to friends. Almost no one systematically mines this data for listing copy — and the AI tools to do it well are now genuinely sophisticated.
How Review Mining Actually Works
Modern AI-powered review mining goes substantially beyond simple sentiment scoring. The process works in several layers:
Entity extraction identifies the specific product features and attributes that customers mention, categorized by sentiment polarity. You learn not just that customers are happy or unhappy, but which specific features drive each emotion, and how frequently.
Language pattern matching identifies the exact phrases customers use to describe the product’s value. This is enormously useful for listing copy because it replaces internal product jargon with language that mirrors how your buyers already think about the product. If 340 customers describe your blender as “powerful enough to crush frozen fruit without burning out the motor,” that specific phrase — or a close variant — belongs in your bullet points. It will resonate with exactly the buyer who needs that reassurance because it was written by someone who had that same concern before they bought.
Hesitation mapping identifies recurring questions in reviews that indicate pre-purchase uncertainty. “I was worried it wouldn’t fit in a standard cabinet, but…” tells you that cabinet clearance is a real purchase hesitation for your buyer segment. If you’re not addressing that in your listing, you’re leaving conversions on the table for every shopper who had that concern and didn’t see an answer.
Competitive gap analysis applies the same review mining process to your competitors’ listings. Their negative reviews are a map of unmet needs in the category — needs your listing can address proactively and explicitly.
The Language Mirror Effect
There is a well-documented psychological phenomenon in persuasion research called the “language mirror effect”: people are measurably more likely to trust and act on copy that uses the same vocabulary they use internally when thinking about a problem. AI review mining creates a systematic method for identifying that vocabulary at scale. Listings written using customer-derived language consistently outperform those written from the seller’s internal perspective, even when the underlying information is identical. The reason is that internally-written copy sounds like a brochure. Customer-language copy sounds like a recommendation from a peer who solved the same problem.
For sellers managing large catalogs, AI review mining tools can process thousands of reviews across dozens of ASINs and produce structured copy briefs — essentially, a set of prioritized bullet point frameworks for each product, ranked by the frequency and sentiment strength of the underlying customer mentions. This compresses what was once weeks of manual research into hours of structured output.
Semantic Content Architecture: Writing for AI Discovery and Human Decision-Making at Once
The emergence of semantic search engines — both Amazon’s COSMO and Google’s AI Mode, which triggers shopping-focused AI Overviews on 61.7% of e-commerce queries — has created a content challenge that pure keyword optimization can’t solve. You need listings that are structurally complete enough for an AI to understand the full context of your product, while still being readable enough for a human to scan and decide in under two minutes.
These two requirements are not actually in tension. They just require a different organizational logic than keyword-density thinking.
The Topical Completeness Framework
Semantic AI systems evaluate listings for what information experts call “topical completeness” — the degree to which a product description covers all the conceptually relevant dimensions of that product type. For a pair of running shoes, topical completeness means covering: fit characteristics, surface type suitability, cushioning technology, durability indicators, sizing notes (does it run large/small?), care instructions, and intended use case (road running vs. trail vs. track).
A listing that covers six of these nine dimensions will be ranked as semantically less complete than one that covers all nine — even if both listings contain the same primary keywords. This creates a checklist-style optimization challenge: for any given product category, what are the full set of dimensions that a semantically complete listing should cover? AI category analysis tools can generate this checklist by analyzing the structural attributes of top-ranking, high-converting listings in the category.
Intent Signals vs. Keyword Signals
Keyword signals answer the question: “What words does this listing contain?” Intent signals answer the question: “What buyer problem does this listing solve, and for which buyer?” The semantic layer is built around intent signals, and they are structured differently from keywords.
An intent signal is a complete thought, not a phrase: “This product is appropriate for beginning woodworkers who need accurate cuts but don’t have a workshop with permanent tool mounts” is an intent signal. “beginner woodworking saw” is a keyword. The intent signal contains the keyword, plus the context that allows an AI system to match this product to the right buyer query — even if that query is “what saw should I buy for home projects without a dedicated workspace?”
Writing listings with intent signals rather than keyword phrases is harder and takes more time. It also produces substantially better results at both the semantic discovery layer and the human conversion layer, because an intent-signal listing answers questions instead of listing attributes.
Structured Data as a Conversion Signal
Beyond the visible listing content, structured data — properly completed product attributes in every available category field — plays an increasingly significant role in semantic relevance. Amazon’s attribute fields for material, size, color family, compatibility, country of origin, intended use, and dozens of other dimensions are inputs into the COSMO knowledge graph. A listing with 60% attribute completion and a competitor with 95% attribute completion are not equally visible to the semantic layer, even if their visible text is comparable in quality.
AI-powered attribute enrichment tools can automate this completion process, pulling attribute values from product images, manufacturer specifications, and competitor listings to fill in the gaps. For catalog-scale sellers with hundreds or thousands of ASINs, this is an area where AI delivers a disproportionate return relative to the effort of manual completion.
Split Testing at Scale: How AI Changes the Experiment
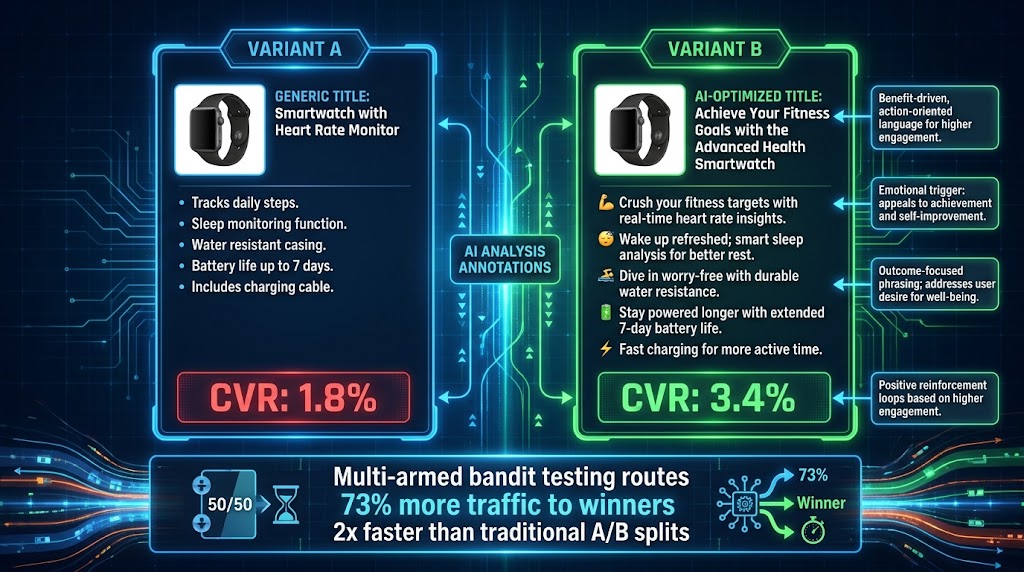
Traditional A/B testing for listing optimization has a fundamental statistical problem: most product listings don’t receive enough traffic to reach statistical significance within a reasonable testing window. Amazon Experiments, the built-in A/B testing tool available to Brand Registered sellers, typically requires three to four weeks of runtime for meaningful results — and even then, lower-traffic ASINs often produce inconclusive data.
AI-native testing approaches resolve this in two ways: by using Bayesian rather than frequentist statistical methods, and by implementing multi-armed bandit allocation rather than traditional 50/50 splits.
Bayesian Testing: Decisions Before You Have Enough Data
Traditional A/B testing waits until a statistically predetermined threshold of confidence is reached before declaring a winner. Bayesian testing approaches the same question differently: it continuously updates a probability distribution of which variant is more likely to be better, based on accumulating data. This means you can make a pragmatic decision — “Variant B is 87% likely to outperform Variant A” — well before you’d reach traditional statistical significance, at substantially lower traffic cost.
For listing optimization, this is particularly valuable for elements like title phrasing and hero image selection, where the stakes of running an inferior variant for weeks are high (you’re losing conversions in real time) and the traffic needed for traditional significance is often not available.
Multi-Armed Bandits: Testing While You Earn
Multi-armed bandit algorithms go a step further: they don’t hold traffic at a fixed 50/50 split throughout the test. Instead, they dynamically allocate more traffic to whichever variant is currently performing better, while maintaining a smaller allocation to the “challenger” variant to continue gathering information. The practical result is that you earn more conversions during the test period itself — you’re not sacrificing as much revenue to the testing process — while still generating the data needed to reach a confident decision.
Leading CRO platforms now apply multi-armed bandit approaches to product listing tests, reducing the effective traffic cost of reaching a confident decision by 40-60% compared to traditional equal-split testing. For high-stakes decisions like seasonal main image updates or major copy revisions, this makes real-time testing practical where it previously wasn’t.
What to Test (And in What Order)
AI listing testing reveals a consistent priority order based on conversion impact per element tested:
- Primary image: Consistently the highest-impact single variable, with typical CVR differences of 0.5–1.5 percentage points between high and low performers
- Title value proposition: The core promise stated in the first 80 characters has significant impact on both CTR (impression to click) and immediate bounce rate (click to continued engagement)
- First bullet point: The first bullet reads disproportionately more than subsequent bullets — it is often treated as the listing’s “sub-headline” by scanners
- Pricing architecture: Where subscriptions, bundles, or tiered quantities are available, how these are presented affects both conversion rate and AOV
- A+ content layout: Module sequence, image-text balance, and comparison chart inclusion affect time on page and add-to-cart rate for shoppers who reach A+ content
Testing elements in this order maximizes the conversion impact of each testing cycle, because you’re always addressing the highest-leverage variable first.
The Dynamic Pricing Dimension: Where Most Optimization Stops Short
Conversion rate doesn’t exist in a vacuum — it is intimately connected to price positioning, and price positioning in competitive e-commerce categories now changes in near-real time as AI repricing tools adjust competitor prices continuously. A listing optimized for conversion at a $34.99 price point may perform very differently when a competitor drops to $28.99, or when your own dynamic repricing tool adjusts you up to $39.99 during a low-stock period.
Price Anchoring and Its Impact on Perceived Value
The listing content itself creates price anchoring effects that either support or undermine the conversion rate at any given price point. A listing whose copy, images, and social proof signal premium quality creates room for higher price points without conversion penalty. A listing whose visual presentation looks indistinguishable from a generic commodity will see conversion crater at any price point above the category floor.
This is why premium brands invest in lifestyle imagery, premium unboxing content, and A+ modules that contextualize the product within an aspirational use case: not because they need to explain the product, but because they need the presentation to justify the price. AI tools that analyze the relationship between visual and copy quality signals and price-relative conversion rates can identify the specific presentation gaps that are causing conversion to underperform at your current price point.
AI-Generated Price Sensitivity Analysis
More sophisticated platforms now offer AI-driven price sensitivity analysis at the listing level — identifying the price elasticity of demand for your specific ASIN based on historical conversion data at different price points. This allows you to understand not just “what price converts best” but “at what price point does a $1 increase cause a disproportionate conversion drop?” — a distinction that has significant margin implications. Selling at $36.99 when $34.99 converts 18% better may produce less gross profit per week than selling at $34.99 with the higher conversion volume, depending on margin structure.
The Post-Purchase Feedback Loop: Building the Self-Improving Listing

The most sophisticated AI listing optimization programs treat the post-purchase experience not as the end of the customer journey, but as the beginning of the next iteration of the listing. Every review, every return reason, every Q&A submitted, and every customer service interaction contains signal about where the listing is creating mismatched expectations — and mismatched expectations are the single most controllable driver of both negative reviews and return rates.
Return Rate as a Listing Quality Signal
Return rates are one of the most underutilized data signals in listing optimization. A high return rate almost always indicates a gap between what the listing promised and what the product delivered — either an accurate product that was poorly described, or a description that was accurate but selected customers who weren’t the right fit. Both problems are listing problems, not product problems.
AI tools that correlate return reason codes with specific listing claims can identify which specific representations in your copy are generating the most mismatched expectations. If “returns: too small” spikes after you added a size claim to your title, the size claim is creating a conversion-attracting-but-return-generating effect that looks positive in short-term CVR data but is deeply destructive to rank over time (Amazon factors return rates into seller metrics and, indirectly, into product ranking signals).
Review Velocity as a Content Update Trigger
Negative review spikes — particularly around specific topics — are real-time signals that something in the listing is creating misaligned expectations. An AI monitoring system that detects a spike in reviews mentioning “battery life” when your listing doesn’t explicitly manage expectations about battery performance is identifying a content gap that will continue to cost you conversion rate and seller metrics for every day it remains unfixed.
The most effective operators have built automated workflows where review sentiment monitoring triggers a listing content review task whenever sentiment around a specific attribute drops below a threshold. This converts what was previously a reactive process (noticing bad reviews after they’ve accumulated) into a proactive one (updating listing content before the negative pattern compounds).
Q&A Population as a Conversion Asset
The Q&A section of a listing is, for most sellers, an afterthought at best and a liability at worst (unanswered questions signal product neglect to shoppers). For AI-aware sellers, it is a structured database of the exact hesitation questions that the listing’s current content is failing to answer. Each question that receives high upvotes is, by definition, a question that multiple shoppers had and that the listing didn’t resolve before they felt compelled to ask.
AI tools can automatically monitor Q&A patterns, identify clusters of questions around similar topics, and generate suggested A+ content modules or bullet point additions that would address those questions preemptively. This is a direct, measurable path from post-purchase data to pre-purchase conversion improvement.
Building the Full-Funnel AI Optimization Stack
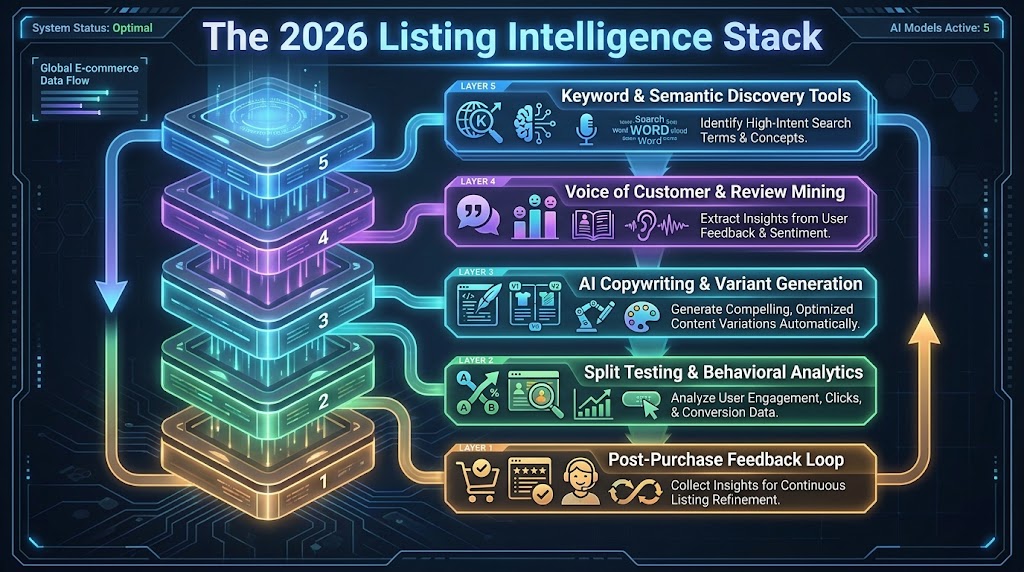
A mature full-funnel listing optimization program in 2026 integrates five distinct capability layers, each addressing a different phase of the conversion micro-funnel. Understanding what belongs in each layer — and crucially, how data flows between them — is what separates sellers who see compound improvement over time from those who plateau after initial keyword gains.
Layer 1: Semantic Discovery Infrastructure
This is the foundation layer, and it’s the one most sellers already have. It includes keyword research tools, reverse-ASIN competitive analysis, backend search term management, and attribute completeness tracking. The key evolution for 2026 is integrating semantic keyword clustering — grouping keywords not by shared root word but by shared buyer intent — alongside traditional volume-based prioritization.
Semantic clusters identify the full network of concepts associated with your product type in COSMO’s knowledge graph: what products it’s frequently bought alongside, what problems it solves, what contexts it appears in. This expands your visibility to shoppers who don’t use your primary keywords but are searching for adjacent problems your product solves.
Layer 2: Voice of Customer Intelligence
The second layer systematically mines review data, Q&A content, and competitor review data to build a structured understanding of buyer language, hesitation points, emotional triggers, and unmet needs. This layer should produce output that directly informs the copywriting layer: a prioritized set of claims to make, questions to answer, and language patterns to mirror — all grounded in what actual buyers said, not what the brand’s marketing team thinks they care about.
Layer 3: AI Copywriting and Variant Generation
With semantic and VoC intelligence as inputs, the copywriting layer uses LLM-powered tools to generate title variants, bullet structures, description drafts, and A+ module copy. The key discipline here is providing structured briefs rather than open-ended prompts — an AI generating copy from a structured brief containing “top hesitation: will the battery last a full workday; primary emotional driver: reliability for professionals; competitor gap: competitors’ returns cite battery as issue” will produce conversion-focused copy that keyword-focused AI generation without those inputs simply cannot match.
Layer 4: Testing and Behavioral Analytics
The testing layer converts copy and visual hypotheses into statistically grounded decisions. This includes Amazon Experiments for Brand Registered sellers, third-party testing platforms, and consumer panel tools for pre-launch testing of images and value propositions before they go live on a listing. Testing should be continuous, not episodic — the competitive landscape changes fast enough that a listing tested thoroughly twelve months ago may be significantly sub-optimal today.
Layer 5: Post-Purchase Feedback Integration
The capstone layer closes the loop between what the listing promised and what the post-purchase experience delivered. Automated monitoring of return reasons, review sentiment, and Q&A patterns feeds back into Layer 2 (VoC intelligence), triggering content update cycles when specific signals breach defined thresholds. This layer is what separates a listing optimization program that generates a one-time improvement from one that generates compounding improvements over time.
Measuring What Actually Matters: Funnel-Stage Metrics for Serious Sellers
The metrics that most sellers track — keyword rank, organic sales velocity, sponsored ad ACoS — are useful but incomplete. A full-funnel optimization program requires visibility into the specific conversion rate at each stage of the micro-funnel, because a problem at Stage 2 (visual first impression) is invisible to a metric system that only tracks total conversions.
The Metrics Matrix
Here is the complete metric set for full-funnel listing optimization, mapped to funnel stage:
- Stage 1 (Impression to Click): Click-through rate by keyword group, impression share by search placement type, organic CTR vs. paid CTR comparison
- Stage 2 (Click to Consideration): Bounce rate (page views resulting in immediate exit), time on page for first-time visitors, image engagement metrics (if accessible via heatmap tools)
- Stage 3 (Consideration to Conviction): Scrolling depth correlation with add-to-cart rate, A+ content engagement, return visitor rate (shoppers who viewed without buying and came back)
- Stage 4 (Conviction to Cart): Add-to-cart rate (session-level), Q&A interaction rate, review sort behavior (are shoppers digging into specific review categories before converting?)
- Stage 5 (Cart to Purchase): Cart abandonment rate, subscription opt-in rate where available, bundle attachment rate
- Post-Purchase: Return rate by reason code, review sentiment trend by attribute, Q&A question frequency by topic
Not all of these metrics are directly accessible through Amazon’s seller tools, and some require third-party behavioral analytics platforms. But even a partial view — tracking add-to-cart rate and return rate alongside total conversion rate — provides dramatically more optimization signal than most sellers currently have.
The Benchmark Context Problem
Category conversion rate benchmarks vary widely: a consumable product in a replenishment category (protein powder, printer paper) has a fundamentally different conversion rate profile than a high-consideration, high-price item (DSLR camera, standing desk). The industry benchmark of 2.86% is a blended average that is nearly useless for diagnostic purposes. What matters is your conversion rate relative to your category’s top performers — and relative to your own historical baseline across specific funnel stages.
An improvement in overall conversion rate that is entirely driven by better click-through rate (Stage 1) requires a different response than one driven by better add-to-cart rate (Stage 4). The intervention needed at Stage 1 is different from the intervention needed at Stage 4. Without stage-level metrics, you can’t tell which problem you’re actually solving.
The Competitive Intelligence Dimension: What Your Competitors’ Listings Tell You
One of the most powerful and underused applications of AI listing analysis is competitive intelligence — not for keyword stealing, but for identifying conversion architecture patterns that work in your specific category.
Reverse-Engineering High-Converting Competitor Listings
When a competitor consistently outranks you and, more importantly, consistently outconverts you at similar price points, the performance gap is almost always traceable to specific content decisions. AI competitive analysis tools can identify patterns across the highest-converting listings in a category: are they leading with a specific type of claim (durability, ease of use, compatibility)? Are they using a specific image sequence (hero product, lifestyle, size comparison, feature callout, social proof)? Do their bullet point structures follow a benefit-first or feature-first pattern?
These patterns are not accidental. They emerge through the same market selection process that eliminates ineffective content over time: listings that convert well survive and scale, listings that don’t get revised or shut down. Reading these patterns as a body of evidence about what your category’s buyers respond to is substantially more reliable than building your listing content strategy from internal assumptions.
Gap Analysis: What Your Category’s Top Listings Are Saying That You’re Not
A structured AI gap analysis compares your listing’s content coverage — the full set of claims, attributes, use cases, and hesitation answers it contains — against the content coverage of top-performing competitors. The output is a prioritized list of content gaps: things that the market’s best-performing listings address that yours doesn’t. Each gap is a potential conversion improvement opportunity, weighted by how frequently it appears among top performers.
This approach is more actionable than simply “write better copy” because it provides specific, evidence-grounded direction: your listing doesn’t mention compatibility with X mounting system, and seven of the ten top performers do. That’s a testable hypothesis, not a vague aspiration.
From Listing Optimization to Listing Intelligence: The 2026 Mindset Shift
The sellers and brands who are pulling ahead in 2026 have made a fundamental cognitive shift in how they think about their listing content. They no longer treat a listing as a static document that gets created once and updated occasionally when rank drops. They treat it as a living, data-responsive asset — something closer to a software product than a marketing brochure.
This shift has practical implications for how teams are structured, how tools are selected, and how work is prioritized. Listing intelligence teams in sophisticated operations look more like data analytics teams than content teams. They maintain dashboards tracking funnel-stage metrics. They run continuous, rolling tests. They have automated triggers that surface content update tasks when behavioral data signals a problem. They treat a spike in return rates with the same urgency they’d treat a rank drop, because they understand that both are symptoms of the same underlying problem: a listing that isn’t serving its buyers well.
The AI Flywheel Effect
When all five layers of the listing intelligence stack are connected and data flows between them, something valuable happens: the system improves itself. Better copy attracts better-fit buyers, who convert more consistently, who leave reviews with more specific language, which feeds back into VoC intelligence, which produces better copy briefs, which generates better variants to test, which generates better performance data. Each iteration of the cycle produces incremental improvement, and those increments compound over time into a competitive moat that is very difficult for competitors to replicate quickly.
This is the real promise of AI in listing optimization — not that it makes any single listing dramatically better in a single revision cycle, but that it enables a continuous improvement discipline that was previously impossible to sustain at scale without proportional increases in human effort. The AI doesn’t just write the copy. It learns what works, updates the inputs, generates better copy, and measures the result. Humans remain in the loop for judgment and strategy. The machine handles the iteration speed and scale that no human team can match.
What This Means for Sellers Who Are Just Starting
Not every seller has the resources to build a full five-layer optimization stack immediately. The practical starting point for sellers earlier in the journey is identifying which single stage of the conversion funnel is losing the most buyers relative to category benchmarks, and investing AI resources there first. In most cases, the highest-return first investment is either:
- Review mining for VoC copy if you have strong traffic but weak conversion rate — your discovery is working but your persuasion isn’t
- Semantic attribute completion if you have weak traffic relative to price competitiveness — your discovery is the problem, not your persuasion
- Post-purchase sentiment monitoring if you have reasonable conversion but high return rates or declining review scores — your listing is attracting the wrong buyers
In each case, AI provides the analysis scale that makes these diagnostics actionable. The diagnosis is the hard part. The fix is almost always specific, targeted, and testable.
Conclusion: The Listing Is the Product Experience Before the Product Experience
There is a moment in every e-commerce purchase where a shopper has never touched, smelled, heard, or experienced your physical product — and yet they are deciding whether to buy it. Everything they know about it comes from the listing. Everything they believe about whether it will work for them, whether it’s worth the price, whether the brand behind it is trustworthy, whether it will arrive as described — all of it is a function of what the listing communicated and how well it communicated it.
That framing makes listing optimization one of the most consequential investments an e-commerce seller can make. Not because it affects search rank — though it does — but because it is the primary driver of whether the shopper experience before the purchase creates a customer who is likely to be satisfied, or a customer who is likely to be disappointed.
AI is not making this challenge easier in the sense of requiring less judgment or less strategic thinking. It is making it more tractable — by processing more data, running more tests, and surfacing more specific insights than any human team could generate at the same scale and speed. The sellers winning the conversion game in 2026 are not those with the best AI tools. They’re the ones who asked the right questions first, built the right measurement systems, and then let AI accelerate the answers.
The keyword is still the front door. But the conversion is built room by room — and most sellers have only ever decorated the entrance.
Key Takeaways
- Listing optimization is a multi-stage funnel problem, not a single keyword placement problem. Each stage — impression, click, consideration, conviction, cart, purchase — has distinct optimization levers and distinct failure modes.
- The three AI layers now governing marketplace discovery (A10, COSMO, Rufus) reward different content qualities: keyword presence, semantic completeness, and conversational answerability respectively. All three must be addressed simultaneously.
- Voice of customer review mining produces conversion copy that outperforms internally-written copy because it mirrors actual buyer language, addresses real hesitation points, and builds trust through linguistic familiarity.
- Multi-armed bandit testing approaches reduce the traffic cost of confident optimization decisions by 40-60% compared to traditional A/B splits, making continuous testing practical at all traffic levels.
- The post-purchase data loop — return rates, review sentiment, Q&A patterns — is the most underutilized signal in listing optimization and the key to building listings that improve continuously rather than plateau.
- Stage-level funnel metrics, not just total conversion rate, are required to diagnose which specific intervention will produce the most improvement for your specific listing’s current performance profile.

