Something quietly changed about the way millions of Amazon shoppers find products. It did not come with a press release or a seller notification. It showed up as a small chat icon in the Amazon app, a box asking “What are you shopping for today?” — and behind it, a system that does not care about your keyword density at all.
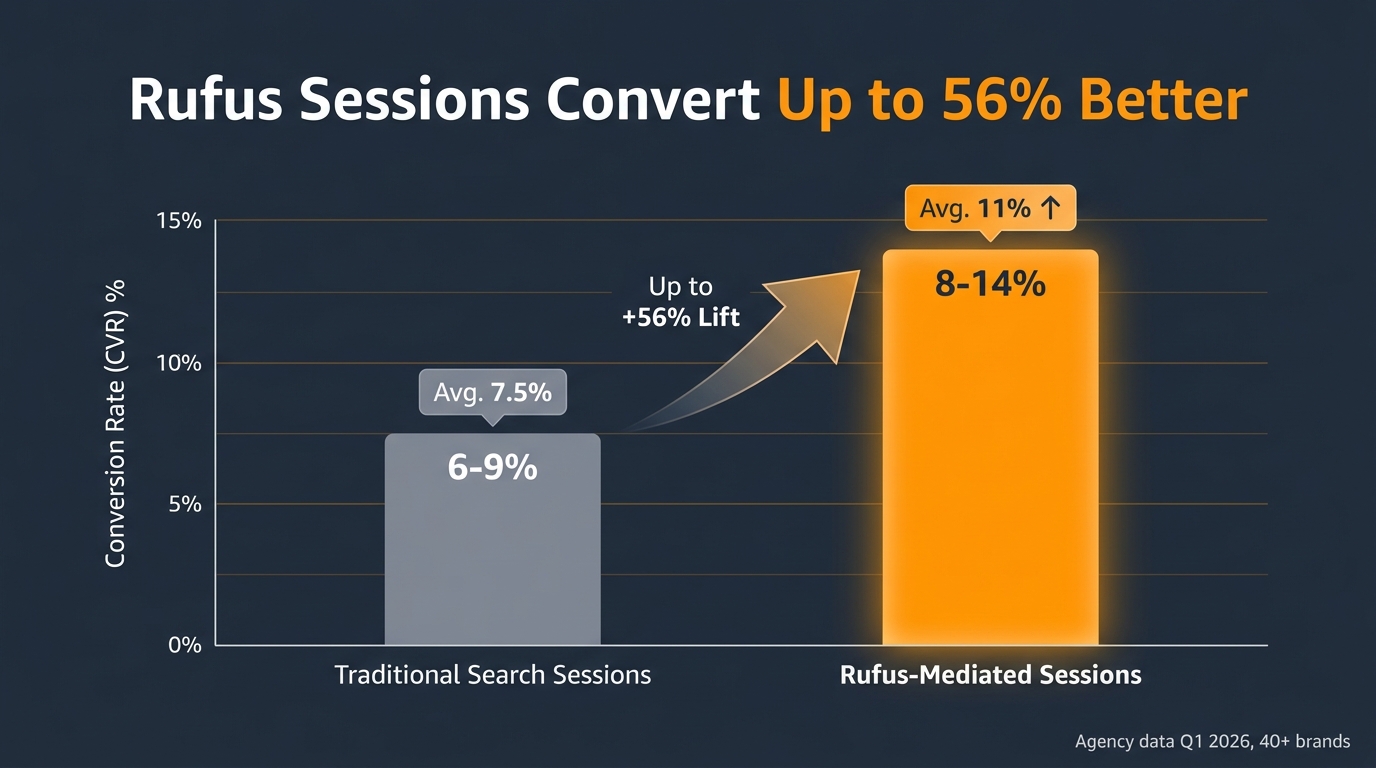
That system is Rufus, Amazon’s generative AI shopping assistant. By early 2026, Rufus is estimated to mediate somewhere between 15 and 20 percent of mobile shopping sessions on the platform, and Amazon CEO Andy Jassy has publicly stated that customers who use Rufus are 60 percent more likely to complete a purchase than those who do not. Third-party agency data from Q1 2026, covering more than 40 brands, shows Rufus-attributed sessions converting at 8–14% CVR compared to 6–9% for traditional search sessions on the same ASINs.
The implication is uncomfortable if you have spent years mastering Amazon SEO. The skills that built your current listings — exact-match keyword research, backend search term stuffing, tactical title construction — are largely invisible to Rufus. The assistant does not crawl your keyword density. It asks a much harder question: Can I confidently recommend this product to a shopper who just described exactly what they need?
This piece is about how to answer that question with a yes. Not through hacks or workarounds, but by understanding what Rufus actually reads, how it makes decisions, and where most seller listings currently leave it with nothing useful to say.
The Architecture Behind Rufus: RAG, COSMO, and a Different Kind of Search
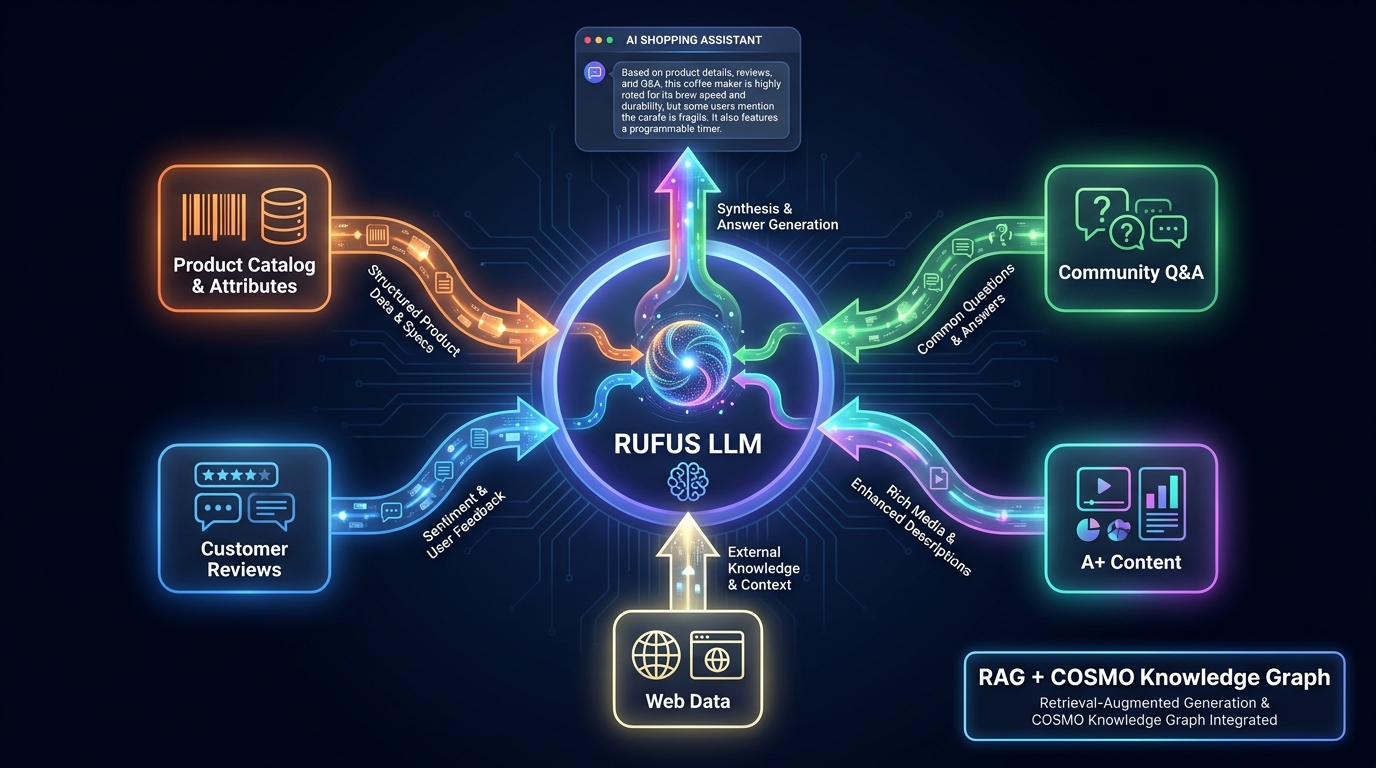
Before you can optimize for Rufus, you need an accurate mental model of what it actually is. Most sellers still think of it as a smarter search bar. It is not. Rufus is a retrieval-augmented generation (RAG) system layered on top of a custom large language model, which itself queries Amazon’s proprietary knowledge infrastructure at inference time.
The RAG Layer: Why Rufus Is Not Just an LLM
A pure LLM answers questions from what it learned during training. Rufus does not operate that way. When a shopper asks “What’s the best hiking boot for plantar fasciitis?”, Rufus does not simply generate an answer from pre-trained weights. Instead, it:
- Interprets the intent of the query (activity type, medical constraint, footwear category)
- Retrieves live data from Amazon’s product catalog, recent reviews, community Q&As, and other structured sources
- Synthesizes that retrieved information into a ranked, conversational response
- Grounds its answer in citable product data to reduce the risk of generating false information
The RAG architecture matters for sellers because it means Rufus’s answer quality is directly constrained by the quality of the data it retrieves. If your listing provides unclear, sparse, or contradictory data, Rufus is forced to either skip your product or fill in gaps with assumptions — both outcomes hurt your visibility.
COSMO: The Knowledge Graph Running Beneath the Surface
Underlying the entire Rufus system is COSMO, Amazon’s large-scale common-sense knowledge generation and serving system. COSMO mines behavioral data from Amazon’s massive transaction and browsing logs to build an industry-scale knowledge graph connecting products, shopper intents, use cases, and purchase contexts.
When Rufus evaluates whether to recommend your ASIN, it is partly checking how well your product maps to nodes in that knowledge graph. A product that has a rich, consistent, semantically clear representation in COSMO’s graph is far more likely to be surfaced confidently. A product with sparse attributes and inconsistent copy creates a thin, unreliable node — and Rufus will pass over it in favor of something it can speak about with confidence.
What This Means for Traditional Amazon SEO
Traditional Amazon A10 algorithm optimization prioritized exact-match keyword indexing, click-through velocity, and conversion signals. Those signals still matter for organic placement in standard search results. But Rufus adds an entirely new ranking dimension: semantic confidence. The question is no longer just whether your listing is indexed for a keyword. It is whether Rufus can construct a defensible, accurate, helpful answer about your product in response to a natural-language question.
Sellers who understand this distinction early will capture a disproportionate share of Rufus-mediated traffic — which, given the significantly higher conversion rates of those sessions, represents a meaningful revenue opportunity.
The Five Data Sources Rufus Actually Feeds From
Amazon has been relatively transparent about the data Rufus uses to generate product answers, and this transparency gives sellers a clear map of where to invest their optimization energy. Here is what Rufus actually reads — and what it can do with each source.
1. Product Catalog Data (Titles, Bullets, Attributes, Identifiers)
This is the primary structural input. Rufus reads your title, bullet points, product description, backend item attributes, category taxonomy, and product identifiers. These fields are the foundation of its understanding of what your product is, who it is for, and what problem it solves.
Critically, Rufus does not weight this data the way A10 does. It is not looking for keywords — it is looking for facts. Structured, labeled, specific facts. “Material: 100% Merino Wool” is far more useful to Rufus than “premium soft warm comfortable fabric.” The first statement can be cited in an answer. The second cannot.
2. Customer Reviews (Text, Ratings, Extracted Themes)
Rufus actively mines review text to understand real-world product performance. It extracts themes — things customers frequently praise, criticize, or mention in specific use contexts — and uses these themes to answer questions like “Is this good for sensitive skin?” or “Do these run true to size?”
This means your review profile is not just a social proof signal anymore. It is a content source that shapes how Rufus characterizes your product. Reviews that contain specific, use-case-anchored language — “I wore these on a 12-mile wet trail and my feet stayed completely dry” — give Rufus citable evidence. Reviews that say “great product, love it” give it nothing actionable.
3. Community Q&A
The community Q&A section is perhaps the most underutilized asset on any Amazon listing, and in the context of Rufus it is uniquely powerful. When a shopper asks Rufus a product-specific question, Rufus will often pull directly from existing Q&A answers if they match the query semantically. A well-stocked Q&A section can essentially pre-answer the questions Rufus will be asked about your product.
4. A+ Content and Brand Story
Brand-registered sellers have access to A+ Content and Brand Story modules that Rufus also reads. These assets are increasingly important as AI recommendation surfaces expand. A+ content that explains product use cases, compatibility context, comparison frameworks, and lifestyle applications gives Rufus richer semantic material to work with — especially for “best for” and comparison-style queries.
5. Web Data and External Signals
For category-level and comparison-type questions, Rufus also retrieves information from the broader web — particularly brand websites, editorial reviews, and authoritative product guides. This creates an external SEO dimension to Rufus readiness: brands with strong off-Amazon content ecosystems (brand site, product pages, press coverage) have an additional signal pathway into Rufus recommendations that private-label sellers without external web presence lack.
Why Hallucination Risk Is Now the Most Dangerous Threat to Your Visibility

Most sellers are familiar with the concept of listing suppression — Amazon removing or demoting an ASIN because it fails to meet content or compliance standards. Rufus introduces a new variant of that problem that operates invisibly and leaves no notification in Seller Central.
What Hallucination Risk Actually Means
Hallucination, in AI terminology, refers to the tendency of generative models to produce confident-sounding but factually incorrect outputs when they lack sufficient grounding data. Amazon has built Rufus with safety guardrails specifically designed to avoid recommending products about which it cannot make accurate, defensible statements.
When Rufus evaluates your listing and finds ambiguous, missing, or contradictory information, it faces a choice: attempt an answer and risk hallucinating incorrect product claims, or deprioritize the product in favor of one it can describe accurately. Given Amazon’s liability exposure around inaccurate product recommendations — particularly in categories like health, safety, and children’s products — the system consistently chooses the latter.
In practice, this means your ASIN can be technically indexed and ranking in traditional search while simultaneously being passed over by Rufus because the AI cannot confidently characterize it. You would see no suppression notice. Your organic rank would be unaffected. But the 15–20% of sessions Rufus mediates would never see your product.
The Most Common Hallucination Risk Triggers
Field audits from agencies working on Rufus optimization in early 2026 have identified consistent patterns in listings that trigger this risk:
- Empty or minimally filled attribute fields. Any attribute that Amazon provides as a structured input field and that you have left blank is a gap in Rufus’s data map. For physical products, this often includes material composition, dimensions, compatibility information, age/audience targeting, certifications, and care instructions.
- Contradictions between frontend copy and backend attributes. If your bullet says “fits up to 250 lbs” but your backend weight capacity field says “200 lbs,” Rufus encounters conflicting signals it cannot resolve. The safest resolution for the AI is to skip the product.
- Generic, non-citable language in bullets and titles. Phrases like “high quality,” “premium materials,” or “long-lasting” cannot be quoted as facts. They do not help Rufus answer a specific question and can even raise confidence flags in the model about whether the listing contains substantive product data at all.
- Thin review and Q&A profiles. ASINs with fewer than 20–30 reviews and minimal community Q&A content give Rufus almost no real-world usage evidence to draw from. This matters more as Rufus handles complex use-case questions that require experiential data.
The Compounding Effect on New Listings
New ASINs face a particular vulnerability here. Traditional Amazon SEO allows new listings to gain traction through sponsored ads while building organic rank over time. But a new listing with thin content and no review profile may be effectively invisible to Rufus from day one — meaning it misses the high-converting session pool that experienced sellers are increasingly trying to capture. Getting the listing architecture right before launch is no longer optional; it is the baseline requirement for participating in AI-mediated discovery.
Backend Attributes: The Invisible Architecture Rufus Relies On
If there is one tactical area where sellers can make the most immediate impact on their Rufus visibility, it is backend attributes. These fields — the ones filled in through Seller Central’s product listing interface, not the customer-facing copy — form the structural skeleton that both COSMO and Rufus use to model what your product actually is.
Think of Attributes as API Parameters, Not SEO Fields
The mental model shift most sellers need here is significant. Under keyword-based SEO thinking, backend attributes were a secondary concern — places to stuff additional keywords that might help with long-tail indexing. Under Rufus, attributes are primary. They are the structured, machine-readable data layer that the AI treats as ground truth about your product.
An LLM reading your listing treats a properly formatted attribute field the way a database query treats a labeled column. Material: Stainless Steel 304 Grade is a clean, structured fact. The same information buried in a bullet point as “made from premium restaurant-grade stainless steel” is prose — harder to extract, easier to misinterpret, and less likely to be cited accurately.
The Completeness Imperative
Best practice in 2026 is unambiguous: fill every single available attribute field that applies to your product. This means going beyond the required fields (which most sellers complete) to fill every optional field Amazon offers for your category.
In apparel, this includes size type, fit type, closure type, fabric weight, fabric care instructions, and occasion. In electronics, it includes compatibility, connector types, frequency specifications, and certifications. In home goods, it includes assembly required status, material composition by percentage, and finish type. Every filled field is another data point Rufus can use to match your product to a shopper query.
Consistency Between Frontend and Backend
Run a consistency audit on your top ASINs. Compare every claim in your visible copy against the corresponding backend attribute. Any mismatch — in dimensions, weight capacities, material claims, compatibility statements — is a hallucination risk factor. Fix these systematically, and fix the backend first, since Rufus treats structured attribute data as higher-confidence than unstructured prose.
Category-Specific Attribute Priorities
Not all attribute fields carry equal weight. For any given category, the attributes most directly tied to purchase decision factors tend to be the most critically read by Rufus. In sporting goods, that means activity type, fit, and performance rating. In consumables, it means ingredients, dietary certifications, and serving size. In baby products, it means age range, safety certifications, and material safety. Identify the decision-critical attributes for your category and ensure those fields are not just filled, but filled with specific, accurate values rather than generic placeholders.
Rewriting Your Bullets for AI Intent Matching
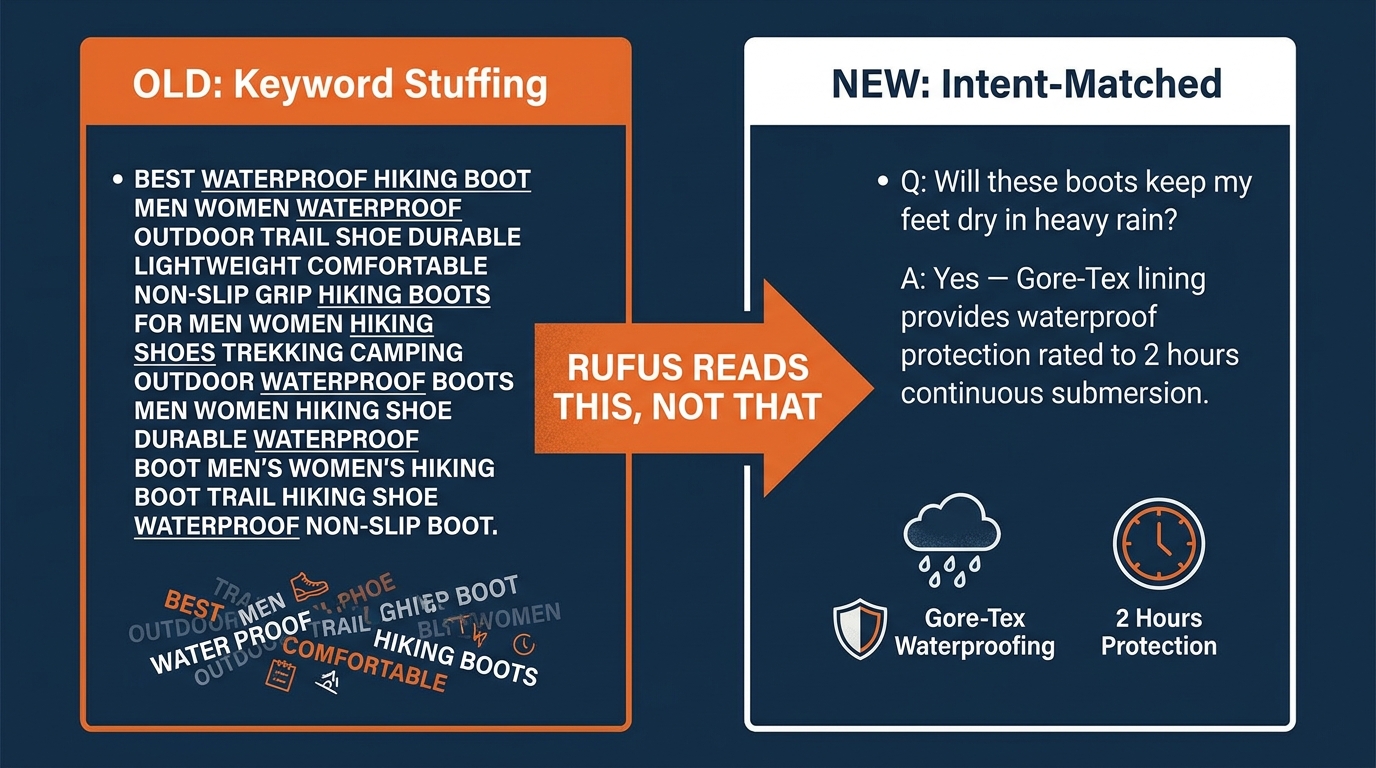
The Amazon bullet point has been treated as a keyword delivery mechanism for most of the platform’s seller history. Pack in the search terms, front-load the most important keywords, and cram as much information as technically possible into the character limit. That approach was rational under A9 and A10. Under Rufus, it is counterproductive.
The Problem with Keyword-First Bullets
Consider a bullet that reads: “Waterproof hiking boots men women outdoor trail running shoe non-slip grip all-terrain durable lightweight breathable.”
From a keyword indexing perspective, this is doing work. It contains multiple search terms and covers a range of query patterns. From Rufus’s perspective, it is nearly useless. The AI cannot extract a specific, citable fact from this string. It cannot use it to answer “Are these boots breathable enough for summer hiking?” because the word “breathable” appears but no substantive claim supports it. It cannot use it to answer “Will these fit women with narrow feet?” because no sizing context exists.
The Intent-First Rewrite Framework
Rufus-optimized bullets start with a question. Not a literal question mark in the text (Amazon’s style guidelines would flag that), but a question implicit in the structure: What does a shopper need to know to feel confident buying this product?
Each bullet should function as an answer to a specific, likely pre-purchase question. Structure them as: [Context claim] + [Specific evidence] + [Use-case application].
Example rewrite for a hiking boot bullet:
- Before: “Waterproof hiking boots men women outdoor trail running shoe non-slip grip all-terrain durable lightweight breathable.”
- After: “Gore-Tex membrane keeps feet dry for up to 3 hours of continuous rain exposure — purpose-built for Pacific Northwest trail conditions and shoulder-season alpine hikes where weather turns fast.”
The rewritten version contains a specific, citable claim (Gore-Tex membrane), a quantified performance threshold (3 hours), and explicit use-case context (Pacific Northwest trails, shoulder season). Rufus can quote this. It can use it to answer “Are these waterproof?” with specificity rather than just flagging that the word “waterproof” appears somewhere in the listing.
Distributing Your Bullets Across Intent Categories
A common mistake is writing all five bullets about product features. For Rufus optimization, your bullets should map to different intent categories that shoppers will approach from:
- Performance claim bullet: What does this product do, and how well? (Specific specs, certifications, measurable outcomes)
- Compatibility/fit bullet: Who is this for, and how does it fit into their life? (Audience, context, sizing, compatibility)
- Comparison signal bullet: How is this different from similar products? (Material differentiators, unique construction, what it replaces)
- Use-case scenario bullet: In what specific situations does this product perform at its best? (Named activities, environments, conditions)
- Trust/proof bullet: What third-party validation exists? (Certifications, testing standards, warranty, brand heritage)
This distribution ensures that when Rufus processes a comparison query, a “best for” query, or a specific use-case question, it has relevant, substantive material to draw from regardless of the angle the shopper approaches from.
Engineering Your Q&A Section for Rufus Answers
The Community Q&A section sits on every Amazon product page and is actively read by Rufus during inference. Yet the overwhelming majority of sellers treat it as a passive channel — monitoring it for customer questions, maybe answering a few, but never approaching it as a content strategy asset. That oversight is becoming increasingly expensive.
How Rufus Uses Q&A in Responses
When a Rufus query closely matches an existing Q&A question, the system can essentially retrieve and surface the existing answer as part of its response. This is one of the clearest direct-feed mechanisms between your listing content and Rufus outputs that sellers can influence.
A product page with 15 substantive Q&A entries covering compatibility, sizing, care, use-case scenarios, and comparison context is providing Rufus with 15 pre-formed answer units. A product page with three sparse Q&As and several unanswered questions is providing almost nothing.
A Systematic Q&A Seeding Strategy
The practical approach is to treat Q&A seeding as a structured content task, not a reactive customer service function. Here is how the process works:
First, identify your most common pre-purchase objections and questions. Pull data from your existing reviews (particularly the 3-star and 4-star reviews, which tend to contain qualified praise alongside specific concerns), from competitor Q&A sections in your category, and from any customer service communications your brand receives. These represent the actual questions shoppers are asking before — and instead of — buying.
Second, submit questions through buyer accounts and answer them comprehensively through your seller account. This is a standard practice within Amazon’s policies. The questions should be phrased in natural language, exactly as a shopper would ask them. The answers should be specific, factual, and structured — not marketing copy.
Third, target a minimum threshold of 15 substantive Q&A entries across the categories that matter most in your product vertical. For most categories, the highest-value question types include: sizing/compatibility, care/maintenance, safety (if relevant), use-case scenarios, and direct comparison questions (“Is this better than [competitor product]?”).
Answer Quality Standards for Rufus Readiness
The quality of the answer matters as much as the presence of the question. A good Rufus-ready Q&A answer:
- Opens with a direct, unambiguous yes/no or specification value before elaborating
- Includes specific data (dimensions, weight, material, compatibility model numbers) rather than vague assurances
- Addresses the implicit concern behind the question, not just the surface question
- Avoids marketing language, superlatives, and unverifiable claims
- Stays under approximately 150 words so it can be directly quoted without truncation
A+ Content and Brand Story: The Long Game Signals
A+ Content and Brand Story are available to brand-registered sellers, and they represent one of the more underutilized Rufus optimization surfaces currently available. While industry data suggests that titles, bullets, and attributes carry heavier weights in Rufus’s current retrieval logic, A+ and Brand Story are increasingly important as the system matures — and they carry a compounding advantage that justifies early investment.
How Rufus Reads A+ Content
A+ Content modules provide rich semantic material that sits between structured attribute data and narrative review content. Well-constructed A+ content — comparison tables, use-case scenario modules, feature callout sections — gives Rufus additional context for answering comparison and “best for” queries that require more than a simple fact lookup.
The most effective A+ content for Rufus visibility uses structured comparison language explicitly. Rather than using A+ modules purely for brand-building visuals, include text-heavy modules that directly compare your product to alternatives in the category, articulate the specific use cases for which your product is the optimal choice, and explain the technical differentiators that justify a purchase.
Brand Story as Credibility Infrastructure
The Brand Story module serves a different function in Rufus’s evaluation: it contributes to what AI researchers call the “source credibility” signal. A brand with a coherent, substantive brand story that explains its expertise, heritage, and product philosophy gives Rufus more confidence in the accuracy of the product claims elsewhere in the listing. Think of it as establishing author authority in a publishing context — it does not directly answer product questions, but it raises the confidence weight of the answers that do.
Module Priorities for Rufus Optimization
If you are building or rebuilding A+ content with Rufus in mind, prioritize these module types:
- Comparison charts that position your product against category alternatives on the dimensions shoppers care about (not just dimensions where you win)
- Use-case scenario modules with specific, named scenarios and why your product fits each one
- Technical specification deep-dives that go beyond what appears in your bullets — material provenance, manufacturing standards, testing methodology
- FAQ modules that use natural-language question format (Amazon recently relaxed formatting restrictions that previously made this awkward)
Review Signals: How Sentiment Mining Shapes What Rufus Says About You
Customer reviews have always been a ranking signal in Amazon’s algorithm. Under Rufus, they take on a qualitatively different role: they become the experiential evidence layer that Rufus uses to characterize your product in real-world use.
Theme Extraction: What Rufus Mines From Reviews
Rufus does not simply look at your star rating average. It performs a form of theme extraction from review text — identifying patterns in what customers mention, praise, criticize, or compare against alternatives. These extracted themes directly inform how Rufus describes your product in response to natural-language queries.
If 40 reviews mention that your hiking boots “run half a size small,” Rufus will likely include that signal when answering questions about sizing. If 60 reviews mention excellent arch support, that theme enters Rufus’s characterization of your product for shoppers who ask about foot comfort or plantar fasciitis accommodation. The review corpus is essentially crowdsourcing your product’s real-world characterization.
The Quality Threshold Problem
ASINs with fewer than 25–30 reviews face a compound disadvantage with Rufus. Not only is the theme extraction data thin (too few reviews to establish reliable patterns), but the low volume also signals to the AI that it cannot generate a high-confidence characterization of the product. Rufus may still surface the ASIN in standard search results but will deprioritize it in conversational recommendations where confidence in product characterization is more critical.
Influencing Review Quality Without Violating Policy
Amazon’s review policies are strict and well-enforced, so this section is about legitimate strategies only. The goal is not to manufacture positive reviews — it is to create conditions where customers who do review your product naturally provide the kind of specific, use-case-anchored language that is most useful for Rufus theme extraction.
Post-purchase follow-up messaging through the “Request a Review” feature should be timed to when customers have had sufficient time to actually use the product in context — typically 14 to 21 days after delivery for most physical goods. Packaging inserts (within Amazon’s guidelines) that encourage customers to share their specific experience — how they used the product, what worked — tend to produce more substantive review content than generic “rate us” prompts.
When you respond to critical reviews, do so with specific information that addresses the concern — these responses also feed into the listing content layer that Rufus reads. A response that clarifies “our sizing guide on the product page has updated information for this” adds a content signal while also demonstrating seller engagement quality.
Winning the Comparison and “Best For” Shortlist

Some of the highest-value queries Rufus handles are comparison and “best for” queries. “What’s the best protein powder for women over 40?” “What’s the difference between the X and Y versions of this product?” “Which yoga mat is easiest to clean?” These queries have high purchase intent and, because they require the AI to construct an evaluative recommendation rather than a simple search result, they heavily favor listings that have rich, structured, use-case-specific content.
How Rufus Constructs a Shortlist
For “best for” queries, Rufus does not simply return the top-ranked ASINs for a broad keyword. It parses the query into an intent bundle — extracting the activity type, constraint, preference, or context embedded in the question — and then filters the catalog for products whose structured data demonstrates a high confidence match for that intent bundle.
A shopper asking “best protein powder for women over 40 who don’t want artificial sweeteners” has given Rufus four distinct filters: demographic (women), age range (40+), dietary constraint (no artificial sweeteners), and product category (protein powder). For an ASIN to make the shortlist, Rufus needs to find evidence of match for all four dimensions — in attributes, bullets, Q&A, or reviews.
Building Use-Case Specificity Into Your Listing
The practical implication is that use-case specificity is now a competitive moat. A listing that explicitly targets “women over 40,” names the specific sweeteners it does and does not contain, and has review content from customers in that demographic is almost certain to outperform a listing that makes broader, less targeted claims — even if the broader listing has better traditional SEO metrics.
This is counterintuitive to sellers who have historically tried to cast as wide a net as possible. The Rufus optimization instinct runs the opposite direction: be specific, be narrow, be defensibly accurate about exactly who this product is for and in what context it performs best. You will lose visibility for queries where your product is a marginal fit. You will win the shortlist for queries where it is the right answer — and those are the sessions with the highest purchase probability.
Comparison Query Optimization: Help Rufus Make the Case
For comparison queries between your product and alternatives, the goal is to give Rufus specific differentiating data it can use to articulate why your product is the better choice for a particular shopper context. This means:
- Your bullets should include at least one explicit comparison signal — a specific way your product differs from category alternatives, framed in factual rather than superlative language
- Your Q&A should include comparison questions (“How does this compare to [category benchmark product]?”) with answers that are honest, specific, and use-case-qualified
- Your A+ comparison tables should include dimensions where competitors have an edge as well as areas where you lead — this honesty signals to the AI that the comparison data is reliable rather than promotional
Measuring Rufus Visibility: What the Data Actually Tells You
One of the genuine challenges of Rufus optimization in 2026 is attribution. Amazon has not yet surfaced Rufus-specific traffic segments in Seller Central analytics, which means sellers cannot directly observe how much of their traffic flows through Rufus-mediated sessions versus traditional search. This data gap will narrow over time as Amazon builds out attribution reporting, but in the meantime there are indirect signals worth monitoring.
Brand Analytics: Search Query Performance as a Proxy
Brand Analytics’ Search Query Performance report can serve as an indirect Rufus signal. Rufus-mediated queries tend to be longer, more conversational, and more specific than traditional search queries. If you are seeing impression growth in long-tail, conversational-format queries within Brand Analytics, that growth is likely at least partially attributable to Rufus-mediated exposure rather than traditional keyword search.
Monitor month-over-month changes in queries containing three or more words, question-format language (“how to,” “best for,” “what is”), and use-case-specific phrases. These query types are disproportionately handled by Rufus rather than standard search, so growth in impressions from these query forms suggests your optimization work is gaining traction.
Session-Level Conversion as a Quality Signal
Because Rufus-attributed sessions convert at materially higher rates than average sessions, an increase in your overall conversion rate — without a corresponding increase in traffic volume — can indicate growing Rufus share. If your CVR is climbing while unit session volume stays flat or grows modestly, the most likely explanation is that a higher proportion of your traffic is coming through high-intent, AI-mediated channels.
The Q&A Activity Monitor
An indirect but underappreciated signal of Rufus engagement is Q&A activity volume on your listing. When Rufus surfaces your product in response to a question and the shopper then visits your product page, they are more likely to interact with the Q&A section (to verify the AI’s characterization) than a shopper arriving through traditional search. Sustained increases in Q&A impressions and clicks, which are visible in Brand Analytics, can signal that Rufus is routing traffic to your listing.
Competitive Intelligence: Audit Your Rivals’ Rufus Readiness
One of the most useful exercises any seller can do right now is to identify the two or three competitors they lose to most often in traditional search — and then evaluate those competitors’ listings through a Rufus readiness lens. Are their attributes fully filled? Are their bullets factual and use-case specific? Is their Q&A section substantive? Sellers whose main competitors have not yet made this transition are sitting on a meaningful optimization window before those competitors catch up.
The New Content Contract: What Rufus Demands From Sellers
It is worth stepping back from the tactical detail to consider the strategic shift that Rufus represents in the Amazon seller-platform relationship. Traditional Amazon SEO was fundamentally a gaming exercise: understand the algorithm’s ranking factors, optimize against them, and outrank competitors. The quality of the underlying product information was somewhat secondary to the effectiveness of the keyword strategy.
Rufus changes the terms of that deal in a fundamental way. The AI does not reward clever keyword placement. It rewards accurate, complete, well-structured product information. A listing that is genuinely the best answer to a shopper’s specific question — and that has the content infrastructure to make that clear to the AI — will win. A listing that has been optimized for a keyword match algorithm but contains sparse, generic, or internally inconsistent content will lose.
The Sellers Who Will Win the Rufus Era
The early winners in Rufus optimization share a few consistent characteristics. They are treating their listing content as a knowledge management asset rather than a marketing copy exercise. They are investing in completeness — filling every attribute, maintaining every Q&A, monitoring and responding to review themes — rather than focusing exclusively on a handful of high-traffic keyword optimizations. And they are accepting a degree of specificity in their positioning that would have felt commercially risky under the old SEO paradigm: explicitly targeting specific use cases, specific demographics, and specific contexts rather than trying to rank for the broadest possible keyword set.
The Ongoing Optimization Cadence
Rufus optimization is not a one-time listing refresh — it is an ongoing content management practice. Review themes shift as your customer base evolves. Q&A questions accumulate and require substantive answers. Category attributes expand as Amazon adds new structured fields. A+ content should be updated to reflect product evolution and emerging competitive context.
Sellers who build a quarterly Rufus audit into their operations calendar — checking attribute completeness against new category requirements, reviewing new Q&A questions, monitoring review theme shifts, and updating comparison content in A+ — will maintain a compounding advantage over competitors who treat the listing as a static asset.
Looking Ahead: Where Rufus Goes From Here
Amazon’s investment in Rufus is not slowing down. The company is actively expanding the assistant’s capabilities to handle more complex agentic tasks — reordering, cart management, purchase completion without leaving the chat interface — and integrating it more deeply into advertising and sponsored placement logic. Sellers who have built Rufus-ready listings now are positioning for the next phase of that expansion, where AI-mediated commerce is not a supplement to traditional search but increasingly the primary discovery mechanism.
The window for early-mover advantage is finite. As Rufus optimization becomes standard practice — as it inevitably will — the relative gain from doing it well will compress. The sellers who act on this architecture shift in 2026, before it is table stakes, will be the ones with the compounding review profiles, the established Q&A libraries, and the fully structured attribute architectures when the rest of the market finally catches up.
Actionable Takeaways: Your Rufus Readiness Checklist
To close with something concrete, here is a prioritized checklist for auditing your current listings against Rufus readiness criteria. Work through these in order of impact.
High Impact — Do First
- Attribute completeness audit: Open your top 10 ASINs in Seller Central. For each, identify every available attribute field in your category. Fill every applicable field with specific, accurate values. Start with the ASINs in your highest-revenue categories.
- Frontend/backend consistency check: Cross-reference every specific claim in your bullets and title against the corresponding backend attribute. Resolve all contradictions — always defaulting to the more specific and accurate value.
- Q&A seeding: For each top ASIN, identify the 10 most common pre-purchase questions in your category. Ensure each one has a specific, factual, Rufus-citable answer in your Q&A section.
Medium Impact — Do Next
- Bullet rewrite for intent mapping: Rewrite bullets using the five intent categories (performance, compatibility, comparison, use-case, trust) as your structural framework. Eliminate keyword strings and replace them with citable facts.
- Review theme audit: Read your 50 most recent reviews and identify the top five recurring themes — positive and negative. Ensure your listing copy proactively addresses the top negative themes with accurate information, and that the top positive themes are reinforced in your attributes and bullets.
- A+ comparison content: Build or rebuild A+ comparison tables that include honest, use-case-qualified comparisons with category alternatives. Include scenarios where a competitor might be the better choice — and scenarios where your product clearly wins.
Ongoing — Sustain and Compound
- Monitor Brand Analytics Search Query Performance monthly for shifts in conversational query traffic
- Review and respond to new Q&A questions within 48 hours with substantive, specific answers
- Update A+ content quarterly to reflect new product variants, competitive landscape changes, and evolving use-case contexts
- Check for new category attribute fields in Seller Central each quarter — Amazon regularly adds structured fields as categories mature
Rufus is not a future consideration. It is already shaping how a significant and growing share of Amazon’s highest-converting shoppers discover products. The listings optimized to speak its language — structured, specific, complete, and consistent — are quietly outperforming the keyword-optimized catalog that most sellers are still maintaining. The gap between those two groups is widening. The time to switch sides is now.