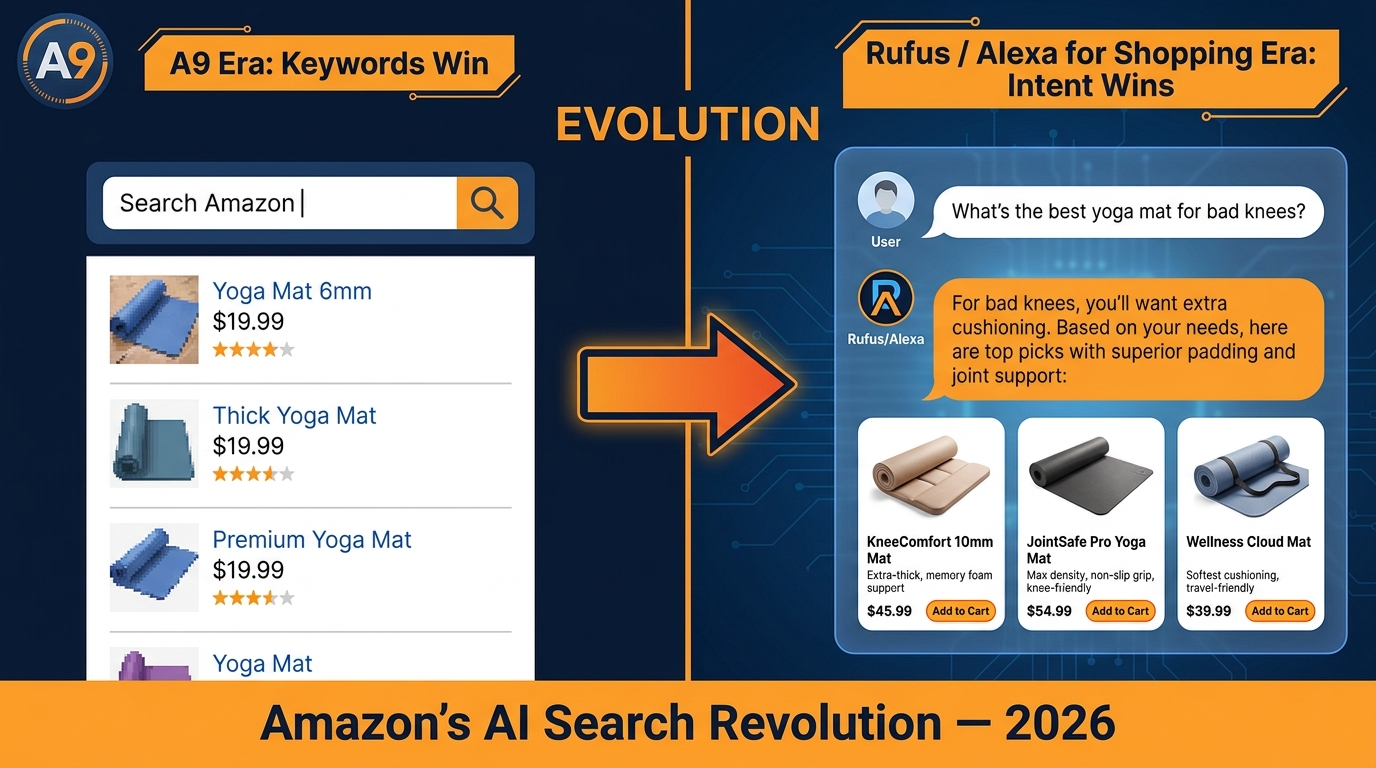

On May 13, 2026, Amazon quietly retired the Rufus brand and folded the technology into something called Alexa for Shopping. The announcement was low-key by Amazon’s standards — a product page update, a few lines in a developer note, and a brief mention in an earnings call. And that low-key delivery was deliberate. Because the name doesn’t matter. What matters is what the underlying architecture means for every brand, seller, and catalog manager trying to stay visible on the world’s largest shopping platform.
This guide is not about the rebrand. It’s about the operational reality underneath it — how the system reads your listings, what signals it uses to decide which products it recommends, why your current catalog hygiene is either an asset or a liability right now, and what you actually need to do differently at the team level starting this week.
Most of what’s been written about Rufus focuses on the consumer experience: the chat interface, the product comparisons, the conversational tone. That’s the shop window. This guide is about the supply chain behind it — specifically, how the machine reads your content, how it ranks and surfaces products, how the ad infrastructure plugs into it, and what an operational workflow actually looks like for a catalog team navigating this transition in 2026.
The sellers who are already winning in this environment didn’t get there by chasing a new trick. They got there by understanding the architecture and building operational processes around it. Here’s what they know.
What COSMO Actually Does — And Why It’s Not Just Semantic Search
Before you can optimize for Rufus (or Alexa for Shopping, or whatever it gets called next), you need to understand the system that actually does the product comprehension work underneath it. That system is COSMO — Amazon’s Common Sense Knowledge Generation and Serving System.
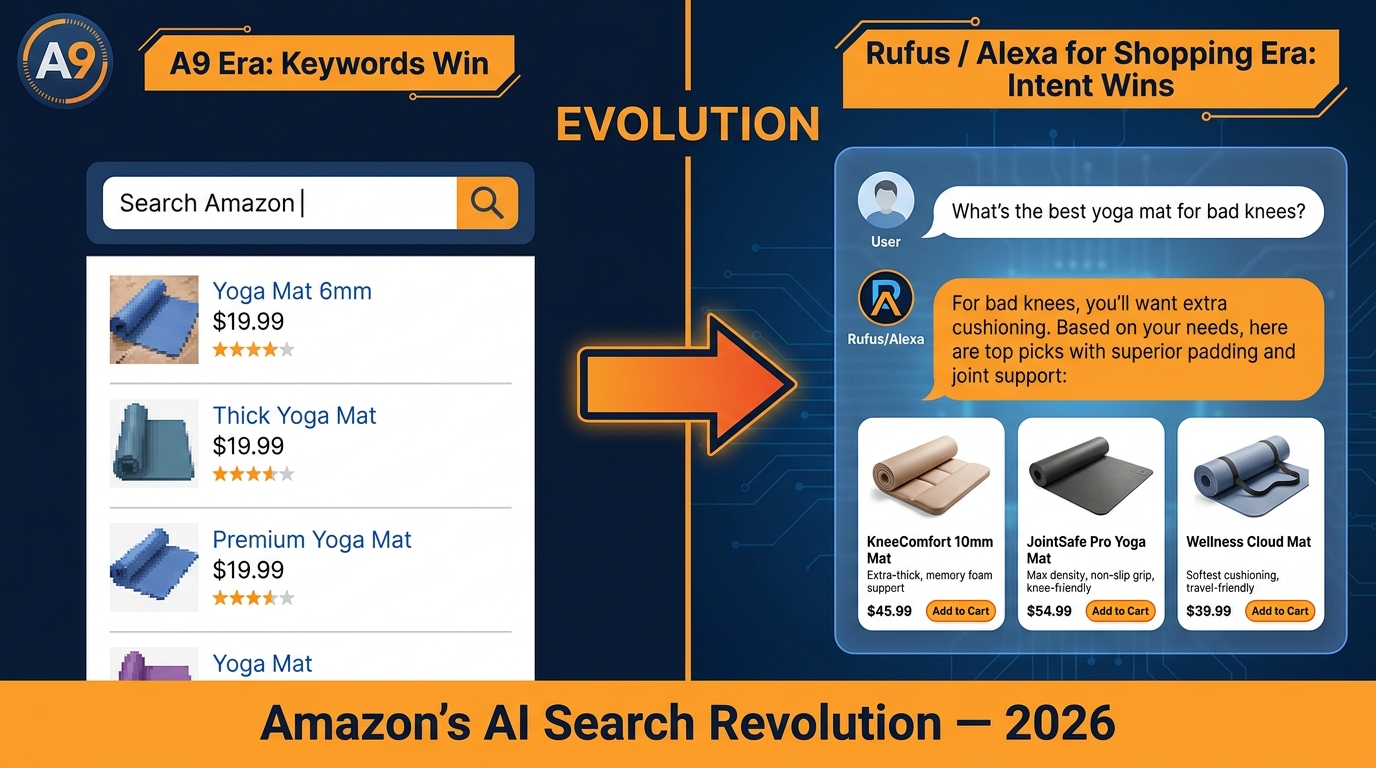
COSMO isn’t a search ranking algorithm in the traditional sense. It’s a knowledge graph builder. Where A9 and A10 are primarily concerned with matching query tokens to indexed content, COSMO’s job is to build a rich semantic representation of what each product is, what it does, who it’s for, and in what contexts it would be a good answer to a shopping question.
How COSMO Reads a Product Listing
Think of COSMO as constructing a “node” for each ASIN in a giant product knowledge graph. Every data input your listing provides feeds into that node. Your title contributes noun phrases and category signals. Your bullet points contribute use-case information and feature attributes. Your A+ content adds context, comparisons, and narrative framing. Your backend attributes (size, material, compatibility, certifications) populate structured fields in the graph. Your Q&A pairs contribute direct question-to-answer mappings that COSMO can retrieve verbatim. And your review text provides a high-volume source of real-world use-case language written by actual buyers.
Crucially, COSMO also incorporates behavioral signals — what shoppers who viewed or purchased your product also viewed or purchased, how they navigated the product detail page, and what queries led them there. This behavioral layer is what makes COSMO fundamentally different from a content-only system.
Where Rufus Fits In
When a shopper asks Rufus (now Alexa for Shopping) a conversational question like “what’s a good protein powder for someone with lactose intolerance who does endurance training,” Rufus doesn’t just run a keyword search. It queries the COSMO knowledge graph using retrieval-augmented generation (RAG) — pulling the richest, most intent-aligned product nodes and using a large language model to synthesize a recommendation from them.
This is the critical insight most sellers miss: Rufus doesn’t rank your listing. COSMO does. Rufus is the delivery mechanism. COSMO is the gatekeeper. And COSMO’s quality of representation for your ASIN is entirely determined by the quality and completeness of the data your listing provides it.
If your COSMO node is incomplete — thin attributes, sparse Q&A, keyword-stuffed bullets that don’t map cleanly to real use cases — you won’t surface in conversational results. It doesn’t matter how well you rank for “protein powder” in traditional search. In the Rufus layer, you simply won’t exist.
The Five Ranking Signals That Now Actually Matter
Amazon has not published an official ranking formula for the Rufus/Alexa for Shopping layer, and it likely never will. But third-party analytics providers, agency data, and the academic paper Amazon released on COSMO give us enough to construct a practical signal map. Here’s what operators are finding drives visibility in the conversational layer.

1. Intent Match Over Keyword Match
This is the foundational shift. Traditional Amazon SEO rewarded listings that contained the exact search terms a shopper typed. Rufus rewards listings that genuinely answer the shopper’s underlying intent — the need behind the query, not just the words of the query.
A shopper asking “what sleeping bag should I get for a trip to Patagonia in March” has a very specific intent: a sleeping bag rated for cold, wet conditions, likely packable for trekking, suitable for shoulder-season Patagonian weather. The listing that wins in Rufus is the one whose COSMO node most clearly maps to that multi-dimensional intent — not the one with the most raw keyword density for “sleeping bag.”
Operationally, this means you need to build use-case maps for your products: what scenarios, conditions, user profiles, and specific needs does each ASIN solve? That map needs to be reflected in your content, not buried in backend keywords.
2. Attribute Completeness
This is where most multi-SKU catalog teams are losing ground right now. Amazon’s attribute fields — material, dimensions, compatibility, certifications, target audience, style, color family, recommended use — are not optional decorators. They are COSMO’s structured input layer. An attribute field left blank is a question the knowledge graph cannot answer about your product. A question it cannot answer is a query it cannot match your product to.
The sellers reporting the strongest gains in Rufus visibility share one common operational practice: they treat attribute completeness as a technical requirement, not a content task. Every category has a maximum attribute set. Filling 60% of it is not passing. It’s leaving visibility on the table.
3. Review Signal Quality
Volume still matters — but the Rufus layer weights review content differently from A9. Specifically, COSMO mines review text for use-case language, attribute confirmation, and sentiment signals. A review that says “I bought this for cold-weather hiking in Iceland and it kept me warm down to -5°C — would recommend for anyone doing winter expeditions” is providing COSMO with rich, real-world use-case data that reinforces your listing’s relevance for that intent.
Quantity without quality is less valuable in this architecture than it was under pure A9 ranking. A listing with 200 reviews full of specific, contextual, use-case-rich language will often outperform a competing listing with 800 reviews full of “Great product! Fast shipping!”
4. Content Clarity and Structure
COSMO uses your content to build a product understanding model. Content that is ambiguous, inconsistent, or internally contradictory creates noise in that model. Keyword-stuffed bullets that string together product terms without forming coherent sentences are particularly problematic — they may index well under A9 but create a weak signal for COSMO’s semantic comprehension layer.
Conversational, clear, well-structured content — where each bullet point makes a coherent claim about a specific product feature or use case — provides a cleaner signal. This is counterintuitive for sellers who’ve spent years optimizing for keyword density, but it’s where the performance gap is now widening.
5. Behavioral Engagement Signals
Click-through rate from Rufus surfaces, time spent on product detail pages, add-to-cart rates, and purchase completion all feed back into the ranking system. This creates a compounding dynamic: listings that are better structured for the AI layer convert better in Rufus sessions, those better conversion signals boost the product’s weight in COSMO’s graph, which improves future recommendation frequency. The flywheel runs in both directions — poorly structured listings enter a visibility-decline spiral, while well-structured ones compound upward.
The Catalog Audit That Has to Happen Before Anything Else
Before you rewrite a single bullet point or seed a single Q&A pair, you need to know where your catalog actually stands relative to the signal set above. Without a baseline audit, you’re optimizing blind. Here is the four-part audit structure that experienced operators are running right now.
Part 1: Attribute Completeness Scoring
Pull your full catalog into a spreadsheet. For each category your ASINs sit in, identify the complete attribute set available in Amazon’s backend (Seller Central or Vendor Central). Map which attributes you’ve populated versus which are empty. Calculate a completeness percentage per ASIN and per category group.
Most catalog teams running this for the first time are finding completeness rates between 40% and 65% — even for listings that rank well in traditional search. That gap is your highest-leverage starting point. Attributes that are consistently empty across competitors represent whitespace in COSMO’s knowledge graph that you can own.
Part 2: Q&A Gap Analysis
Export every Q&A pair on your listings. Then map them against the actual shopper questions being asked in your category — you can surface these from search query reports, competitors’ Q&A sections, and customer service inquiry logs. Identify the questions that are being asked but not answered on your listings. Each one of those gaps is a missed COSMO input and a potential customer who didn’t get the answer they needed.
Pay particular attention to comparison questions (“is this better for X or Y?”), suitability questions (“is this appropriate for [specific use case]?”), and compatibility questions (“does this work with [complementary product]?”). These are exactly the types of conversational queries that Rufus fields most frequently.
Part 3: Keyword-to-Intent Mapping Audit
Review your current backend keyword strategy through the lens of intent rather than volume. High-volume, short-tail terms in your backend may be indexing your listing for queries that your product doesn’t actually serve well — which can generate irrelevant traffic that converts poorly and damages your behavioral signals. In the Rufus era, precise intent alignment matters more than raw impressions.
Use your Search Query Performance data in Brand Analytics to identify queries where your impression share is high but your click-through and conversion rates are below category average. These are your intent mismatch indicators. Pruning or deprioritizing these terms and replacing them with more specific, use-case-aligned phrases will often improve both Rufus visibility and overall conversion efficiency.
Part 4: Listing Content Coherence Check
Read each of your listings aloud as if you were a customer asking a conversational question. Does the content actually answer the questions a real buyer would have? Or does it read like a string of keywords that a human wouldn’t naturally produce? If you find yourself stumbling over awkward phrasing or realizing bullets don’t connect logically to buyer needs, that’s a COSMO signal problem, not just a readability problem.
Rewriting Listings for Conversational Queries
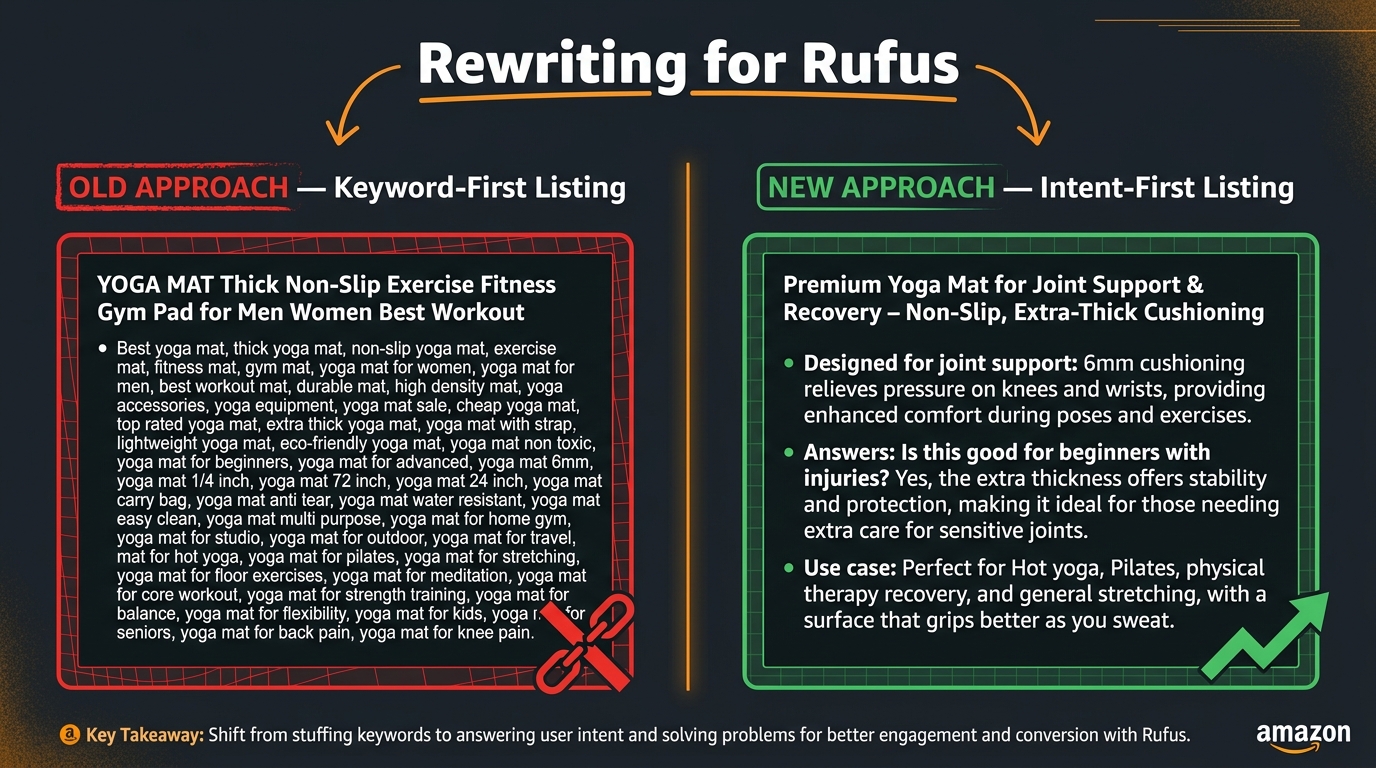
Once your audit is complete, the rewrite process begins. This is where most teams underestimate the scope of change required. Writing for Rufus isn’t about adding a few conversational phrases to existing keyword-dense copy. It’s a structural reframe of how you use every content field on your listing.
Title Strategy: From Feature String to Contextual Claim
Traditional Amazon title optimization stacks keyword terms: Brand + Product Type + Key Feature + Size/Color/Count. This still matters for A9 indexing and should not be abandoned entirely. But the best-performing titles in the Rufus era also embed a contextual use-case signal in the phrasing — something that helps COSMO understand when this product is the right answer, not just what it is.
For example, shifting from “Brand X Sleeping Bag 20°F Lightweight Camping Backpacking” to “Brand X Sleeping Bag — 20°F Rated, Ultralight Design for Multi-Day Backpacking & Alpine Trekking” preserves keyword signals while adding contextual use-case framing (“multi-day backpacking,” “alpine trekking”) that maps cleanly to the kinds of high-intent, specific questions Rufus handles.
Bullet Points: Question-Answer Architecture
Restructure your bullets so each one functions as an implicit answer to a common shopper question. Instead of leading with a feature claim (“Premium 600-fill power down insulation”), lead with the benefit context that answers the intent (“Warm in wet conditions: 600-fill water-resistant down retains 85% of its insulating capacity even when damp — engineered for shoulder-season and coastal trips”). The feature is still there. But it’s now framed as the answer to an implied question a real shopper would be asking.
This matters because Rufus frequently synthesizes bullet point language directly into its answers. If your bullet says “Great for outdoor use,” Rufus can’t do much with it. If your bullet says “Designed for three-season alpine climbing from 4,000–14,000 feet, rated to -10°C,” Rufus has a specific, usable answer for a very specific shopper question.
A+ Content: The Underused COSMO Input
Most brands treat A+ content as a branding exercise — pretty images, lifestyle shots, a comparison chart with competitors. In the COSMO era, A+ content is a major structured input that COSMO can mine for use-case context, comparison data, and product narrative.
Use your A+ modules to explicitly address the decision-making questions your category shoppers face. A “Who is this for?” section. A “When to choose X vs. Y” comparison that positions your product in context. A “Frequently asked questions” module that pre-answers the most common Rufus-style queries. These elements give COSMO additional graph nodes to connect your product to in its recommendation logic.
Product Description: Still Relevant for AI Comprehension
Many sellers have deprioritized the product description field since A+ content took over visually. Don’t make that mistake in the Rufus era. The description is still crawled and processed by COSMO, and for Vendor Central accounts especially, it’s an important secondary content field. Write it in full prose — not bullet points — and use it to tell the complete use-case story of the product in natural, conversational language. This is one of the places where COSMO finds the kind of coherent, context-rich narrative it uses to build a high-quality product node.
The Q&A and Review Strategy That Feeds the Knowledge Graph
If there’s one section of this guide that catalog teams consistently underinvest in, it’s this one. Q&A and reviews aren’t just trust signals for human shoppers — they are active data inputs to COSMO’s knowledge graph that directly influence Rufus recommendations.
Q&A as Structured Training Data
Amazon’s Q&A system is, from COSMO’s perspective, a pre-labeled dataset of intent-matched question-answer pairs. Every question submitted and answered on your listing teaches COSMO something about what shoppers want to know about your product. Rufus can retrieve these Q&A pairs directly and surface them as answers in conversational sessions.
This means your Q&A section is not a passive support tool. It’s an active SEO asset that most sellers are leaving largely unmanaged.
The strategic approach is to audit the questions being asked in your category (on your own listings, competitors’ listings, and in relevant forums and communities), identify the ten to fifteen highest-intent questions that aren’t yet answered on your listing, and systematically seed answers to them. Answers should be specific, complete, and written in natural language — not marketing copy. “Yes, this works with XYZ” is too thin. “Yes, this is compatible with XYZ model from 2022 onwards and requires the standard adapter, which is included in the box” is a COSMO-quality answer.
Managing Reviews for Signal Quality
You cannot write your reviews. You can influence their quality through operational practices upstream. The most effective lever is post-purchase follow-up communication that prompts buyers to describe their specific use case when leaving feedback — not in a way that violates Amazon’s review policies, but by framing your follow-up messages around the use context. “We’d love to know how the [product] performed on your [specific activity]” prompts more contextual reviews than “please leave us a 5-star review.”
Operationally, monitor your review text monthly for common use-case language. When you identify a use case being described frequently in reviews that isn’t reflected in your listing content, that’s a gap between your COSMO node and real buyer behavior. Fill it in your content.
Responding to Reviews: The Underrated Signal
Brand responses to reviews — particularly negative ones — are crawled by COSMO and contribute additional context about the product. A thoughtful, specific response that addresses a product concern while clarifying a use-case boundary (“This product is designed for X and may not be suitable for Y application”) does two things: it provides useful information for future shoppers, and it adds structured, coherent language about the product’s appropriate use cases to your COSMO node. Most sellers treat responses as customer service. They’re also content.
Sponsored Prompts: The New Ad Surface Most Sellers Are Flying Blind On
On March 25, 2026, Amazon moved its Rufus Sponsored Prompts from open beta to full CPC billing. This was not announced with fanfare — it was an automated transition. Eligible Sponsored Products and Sponsored Brands campaigns were auto-enrolled. If you didn’t notice the change in your ad spend, you’re either not yet eligible or you’re not watching your campaign pacing closely enough.
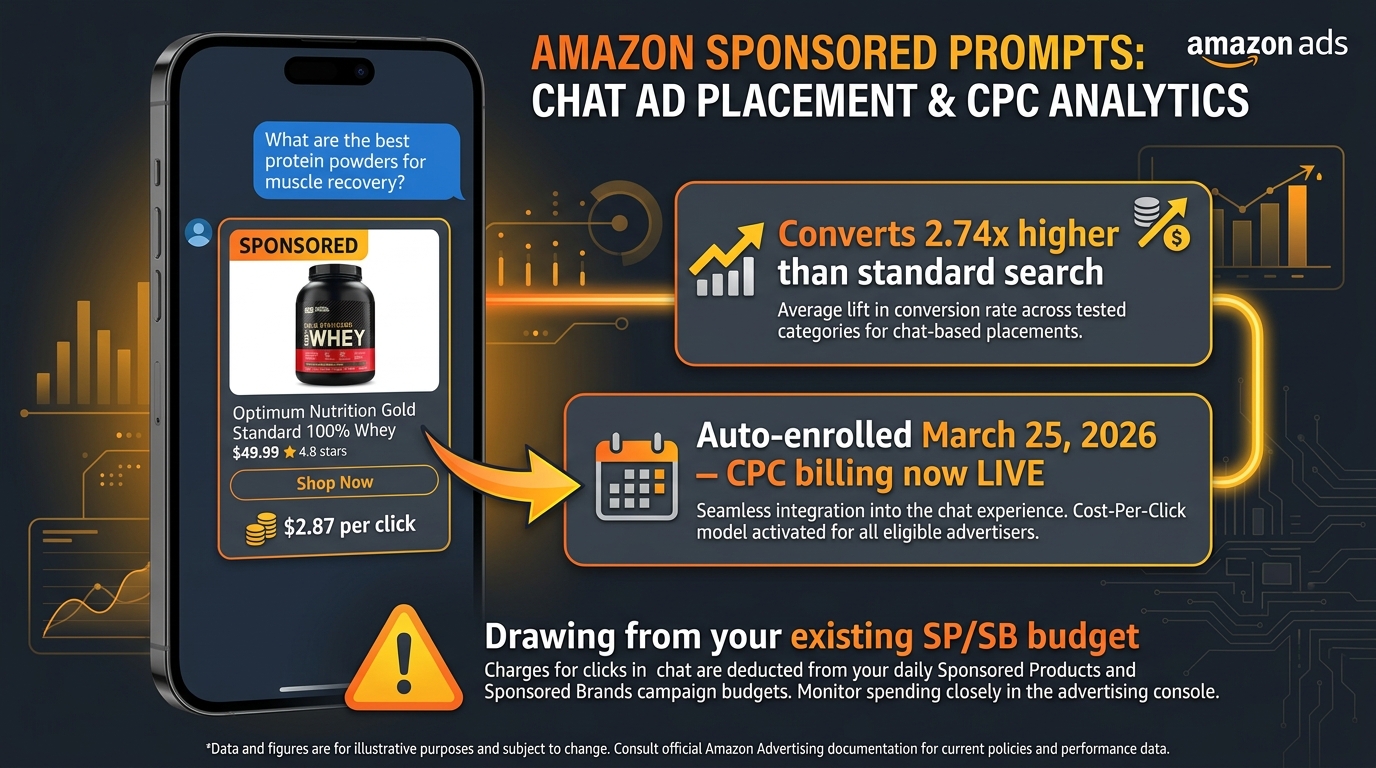
What Sponsored Prompts Actually Are
When a shopper interacts with Rufus / Alexa for Shopping and asks a product-related question, the AI doesn’t just surface organic results — it also surfaces sponsored placements within the conversational context. These are labeled as sponsored in the interface, but they appear as part of the AI’s answer framework rather than as separate ad units in a results list. The placement is conversational-native, which meaningfully changes how shoppers engage with them.
Critically, there is currently no separate bid control for Sponsored Prompts. Amazon draws from your existing Sponsored Products and Sponsored Brands campaign bids and budgets. This means your campaigns are now competing for a new type of impression that you may not have allocated budget for, and that traffic is drawing from the same daily budget as your traditional search placements.
The Traffic Quality Signal
The early performance data from Sponsored Prompts — both from Amazon’s own beta reports and from third-party agency analyses — is striking. Rufus-assisted shopping sessions convert at 2.5x to 3.5x the rate of standard search sessions. Shoppers who have already asked a specific conversational question and received an AI-synthesized recommendation are further along in their decision process by the time they arrive at your product detail page. CPCs on Sponsored Prompts are typically higher than equivalent traditional placements, but if the conversion rate differential holds, the profitability math often works — depending on your margin structure.
Managing Your Sponsored Prompts Exposure
Since there’s no separate bid line for Prompts, your operational lever is campaign-level architecture. Consider segmenting your highest-margin, highest-converting ASINs into dedicated campaigns where you can control daily budget independently of your lower-priority SKUs. This gives you cleaner data on where Prompt-attributed spend is flowing and the ability to adjust without impacting your broader keyword campaigns.
Also review your campaign-level placement bid modifiers. Amazon’s reporting now segments some Sponsored Prompts traffic separately — use this data to understand the CPC and conversion differential for your specific products, then adjust top-of-search and product page placement modifiers relative to the Prompt performance you’re observing.
Content Quality as an Ad Quality Score
Here’s the connection that most sellers miss: your listing content quality directly influences whether Amazon’s system selects your Sponsored Product for a Prompt placement in the first place. The AI isn’t going to surface a sponsored result that doesn’t semantically match the shopper’s question — even if you’re bidding competitively. The same content signals that drive organic Rufus visibility also gate your Sponsored Prompt eligibility. Organic and paid optimization for this channel are not separate workstreams. They’re the same workstream.
Measuring What You Can’t Yet Directly See
One of the most operationally frustrating aspects of the Rufus era is the analytics gap. Amazon does not provide direct attribution data for Rufus-driven sessions. You cannot currently see a “Rufus-sourced” traffic segment in your Seller Central dashboard. This creates a measurement blind spot that some teams are using as an excuse to deprioritize the work — which is exactly the wrong response.

Proxy Metrics That Signal Rufus Impact
Experienced operators have developed a set of proxy metrics that, taken together, give a reasonable signal of whether Rufus is working for or against specific ASINs. None of these are definitive. All of them are directional and actionable.
Conversion rate by ASIN over time. Run a month-over-month conversion rate trend for each ASIN against category average conversion rates. An ASIN whose conversion rate is trending up while your ad spend mix hasn’t changed materially is likely benefiting from higher-quality, AI-assisted traffic. An ASIN whose conversion rate is flat or declining despite strong keyword rankings may be missing out on Rufus-layer discovery.
Branded search volume in Brand Analytics. Rufus sessions frequently increase category-level awareness and consideration before shoppers search directly. An increase in branded search queries after a period of content optimization — even without a change in advertising — can indicate that Rufus is driving awareness that’s subsequently converting through branded search.
Detail page view rate vs. impression rate. If impressions are stable but detail page view rates are increasing, the quality of incoming traffic is improving — a pattern consistent with more intent-aligned, AI-mediated discovery sending better-qualified shoppers.
Q&A view counts and upvotes. Monitor Q&A engagement on your listings. When Rufus frequently references specific Q&A pairs in its answers, those pairs accumulate view signals faster. If you see specific Q&As gaining unusual traction, that’s a signal Rufus is actively serving those answers.
Sponsored Prompts CPC differential. As Sponsored Prompts reporting matures, track the CPC and conversion rate differential between Prompt placements and standard top-of-search placements for the same campaign. A higher CPC with a proportionally higher conversion rate confirms the traffic quality thesis. A higher CPC without a conversion lift suggests your content isn’t matching the conversational intent that’s generating the Prompt click.
Building a Measurement Framework Now
Amazon will likely add more granular Rufus attribution data over time — it’s in their interest to demonstrate the value of the conversational layer to advertisers. But waiting for perfect measurement before acting is a losing strategy. The brands that are building COSMO-quality catalogs now are accumulating knowledge graph depth, behavioral signal history, and content quality advantages that will compound regardless of when the reporting catches up.
Set up a simple monthly scorecard with the proxy metrics above segmented by ASIN group (recently optimized vs. control). Track direction of movement. Refine your content approach based on what the signal pattern tells you. This is not perfect attribution — but it’s operational intelligence in a system that doesn’t yet give you anything better.
The Weekly Operational Workflow: What Catalog Management Looks Like Now
Rufus-era catalog management isn’t a one-time content project. It’s an ongoing operational discipline. The brands building durable advantages in this environment have restructured their catalog management processes to treat COSMO signal maintenance as a standing weekly function alongside advertising management and inventory planning.

Monday: Attribute Completeness Review
Start each week with a scan of recently added or modified ASINs for attribute completeness. New product launches are particularly vulnerable — teams focus on getting the listing live and deprioritize attribute population. Any ASIN launched in the past 30 days with attribute completeness below your category benchmark should be flagged and resolved before the end of the week. For large catalogs, prioritize by revenue contribution: get your top 20% of ASINs by revenue to 100% attribute completeness first, then work down.
Wednesday: Q&A Gap Review and Seeding
Mid-week, pull the new Q&A questions that arrived on your listings in the past seven days. Respond to any unanswered questions within 48 hours. Then spend 30 minutes reviewing competitor Q&A sections in your category for new question patterns — questions being asked on competitor listings that aren’t yet covered on yours represent active COSMO input opportunities. Seed one to two new strategic Q&A pairs per ASIN per week based on what you’re finding.
Thursday: Sponsored Prompts Bid and Budget Audit
Run a campaign-level budget pacing check for any campaigns that include Sponsored Prompts-eligible ASINs. Look for campaigns that hit daily budget cap before end-of-day — this indicates Prompt traffic may be consuming budget faster than your baseline assumptions. Review the Sponsored Prompts segment in placement reporting for CPCs trending above 15% of your target. Adjust daily budgets or placement bid modifiers based on the conversion data you have. For high-performing Prompt placements, consider increasing daily budget ceiling rather than reducing bids — the traffic quality argument for Rufus sessions often holds even at elevated CPCs.
Friday: Review Signal Analysis
Pull the week’s new reviews across your priority ASINs. Flag any reviews that describe a use case not currently reflected in your listing content. Flag any negative reviews that point to a use-case misalignment (i.e., a shopper used the product in a context it wasn’t designed for — indicating your listing didn’t clearly communicate appropriate use cases to COSMO). Draft responses to negative reviews that clearly articulate the product’s intended use context. Add flagged use-case gaps to your content revision queue.
Ongoing: Competitive Intelligence Scanning
Set up a monthly competitive intelligence review focused specifically on how the AI comparison surfaces are framing your product category. Simulate Rufus queries for your main use cases and observe which products the system recommends, what language it uses to describe them, and whether your products appear. If competitors consistently appear in Rufus responses for queries you should own, reverse-engineer their listing content to understand what COSMO input they’re providing that you’re not.
Category-Level Competitive Intelligence in the Rufus Era
Competition on Amazon has always been category-level. In the Rufus era, competitive strategy gets more nuanced — because the battlefield is now the conversational query space in your category, not just the keyword ranking table.
Mapping the Conversational Query Space
For any given product category, there is a finite set of conversational questions that shoppers will ask Rufus. Some of these align with high-purchase-intent journeys: “what’s the best [product] for [specific use case]?” Others are comparison queries: “what’s the difference between [product type A] and [product type B]?” Others are suitability queries: “is [product] appropriate for [specific user profile or condition]?”
The brands that will dominate Rufus recommendations are those that map their product’s COSMO node most completely to the highest-traffic conversational queries in their category. You can reconstruct this query map by analyzing search query data, customer service inquiries, community forum questions (Reddit, Facebook groups, specialist forums), and review text for the language patterns real buyers use when evaluating your category.
Owning Use-Case Whitespace
Every category has conversational queries where no current listing provides a strong COSMO signal. These are your use-case whitespace opportunities — specific buyer scenarios where the knowledge graph has weak coverage and where a well-structured listing could become the definitive Rufus answer.
For a category like ergonomic office chairs, an example of whitespace might be “ergonomic chair for someone who does long video calls and needs head support.” If no listing in the category explicitly addresses this use case — with specific content about neck support, recline settings, and appropriate positioning for video calls — that’s a COSMO input gap that a first-mover can own. This is a fundamentally different competitive analysis than keyword gap analysis, but it follows the same logic: find where supply is thin relative to demand, and fill it.
Monitoring AI Comparison Cards
Rufus frequently generates comparison cards when shoppers ask “what’s the difference between” or “which is better for” questions. These comparison surfaces pull specific attribute data from competing products’ COSMO nodes. If you’re not appearing in comparative recommendations for your main competitors, it typically means one of two things: your attribute data is less complete than theirs, or your COSMO node doesn’t have enough contextual overlap with their node for the system to include you in the comparison.
Monitor these surfaces regularly by simulating comparison queries manually, and pay close attention to what attributes the comparison cards highlight. If a competitor’s attribute that you also have is being surfaced and yours isn’t, check whether you’ve populated that attribute correctly in your backend. Often the issue is as simple as a missing backend attribute that you technically have the data to provide but haven’t entered.
What the Alexa for Shopping Rebrand Actually Changes in Practice
Most of the Rufus-to-Alexa for Shopping rebrand is cosmetic from a catalog optimization standpoint. The underlying COSMO architecture, the RAG retrieval process, the signal set that drives recommendations — none of this changed on May 13, 2026. What did change is the surface area of where this AI layer operates and the depth of personalization it can draw on.
Deeper Personalization Signals
Rufus was personalized primarily based on Amazon browsing and purchase history. Alexa for Shopping integrates the much richer Alexa behavioral dataset — including voice search patterns, smart home device usage, routines, and household-level shopping patterns from Echo devices. For sellers, this means the AI is making progressively more personalized recommendations that take into account lifestyle and household context beyond what Amazon shopping history alone reveals.
The operational implication is nuanced. Your product’s COSMO node still needs to be rich enough to match to a diverse range of buyer intents. But Alexa for Shopping may increasingly match your product to very specific shopper profiles based on behavioral data you can’t directly observe. The only defense is COSMO node completeness — the richer your product’s knowledge graph representation, the more context the personalization layer has to work with when making intent matches.
Echo Device Integration
Alexa for Shopping means your product can now be recommended via voice — through Echo devices, Echo Show screens, and Alexa integrations in cars and other platforms. Voice-based product recommendations carry different content requirements than screen-based discovery. When Alexa reads a product recommendation aloud, it’s typically condensing your listing into a brief verbal description. The product attributes that translate well to a spoken format — clear product category, primary differentiator, key specification — matter more here than the full depth of your listing content.
For brands with strong Alexa for Shopping potential (consumables, frequently repurchased items, household staples), ensuring your product’s primary identification elements are clear and concise in your title and attributes is now important for discoverability in a surface that didn’t exist at meaningful scale under the Rufus-only era.
Search Integration Depth
Under Rufus, the AI was largely a sidebar experience — a chat panel you could open while browsing. Under Alexa for Shopping, the AI is progressively being integrated into the core Amazon search experience itself. Amazon has begun serving AI-generated “Research for your search” and product comparison surfaces directly in the main results page for a growing range of queries — not just when shoppers explicitly open a chat panel.
This means the Rufus-era optimization requirements are no longer niche. They’re becoming the default. A seller who treats AI-layer optimization as an optional enhancement is increasingly making a decision to opt out of a significant and growing share of product discovery, not just a supplementary channel.
What Operators Who Win in This Era Actually Do Differently
Zoom out from the tactical specifics for a moment and a pattern emerges. The brands seeing the strongest performance signals in the post-Rufus search environment share a common operating philosophy that’s distinct from how most Amazon-native teams have historically worked.
They Treat Catalog Data as Product Infrastructure
High-performing operators no longer treat their Amazon listings as marketing copy. They treat them as structured data infrastructure — inputs to a system whose output is product visibility and revenue. This mental model shift changes everything about how catalog work gets resourced, prioritized, and measured. Attribute completeness becomes an engineering-grade metric with an SLA, not a “let’s try to fill these in when we have time” task. Q&A management becomes a scheduled operational function, not an ad-hoc customer service activity.
They Run Continuous Content Experiments
The operators building durable competitive advantages in the Rufus era are running structured A/B tests on listing content — using Amazon’s Manage Your Experiments tool where eligible, and monitoring before-and-after proxy metrics where not. They’re testing different use-case framings in bullet points, different attribute emphases in titles, and different Q&A seeding strategies. They’re not optimizing once and moving on. They’re treating listing content as a continuously improving asset with a feedback loop.
They Connect Organic and Paid Strategy
As the Sponsored Prompts section above makes clear, your organic content quality and your paid performance in the Rufus layer are not separate systems. The teams winning in both channels have recognized this and unified their content and advertising strategy under a single framework: build the best possible COSMO node for each high-priority ASIN, then drive traffic to it through both organic Rufus recommendations and Sponsored Prompts placements. The content investment pays dividends in both channels simultaneously.
They Invest in Category Intelligence, Not Just ASIN Intelligence
Traditional Amazon analytics tends to be ASIN-centric: how is this listing performing? The Rufus era requires category-level intelligence: how is this category’s conversational query space structured, who owns which use cases in the knowledge graph, and where are the gaps we can fill? Operators who are winning are spending meaningful time on this category-level analysis — mapping conversational query space, running competitive Q&A analysis, and using their findings to inform both content strategy and product development decisions.
Building Your 90-Day Rufus Transition Roadmap
Knowing what needs to change is the easy part. Building a practical roadmap that a real team can execute is where most sellers get stuck. Here’s how to sequence the work across your first 90 days.
Days 1–30: Audit and Triage
Run the four-part catalog audit described earlier. Prioritize your ASIN set into three tiers: Tier 1 is your top 20% by revenue, Tier 2 is the next 30%, and Tier 3 is the long tail. Your first 30 days are about Tier 1 only. Get every Tier 1 ASIN to 100% attribute completeness. Audit and seed Q&A for the ten most common conversational queries in your category. Review your Sponsored Prompts enrollment status and set up monitoring dashboards for the proxy metrics above.
Days 31–60: Content Overhaul for Priority ASINs
Rewrite Tier 1 listing content using the intent-first framework: title contextual framing, question-answer bullet architecture, Q&A seeding at scale, A+ content restructure. Begin running Manage Your Experiments tests on title and bullet variations for eligible ASINs. Set up your weekly operational workflow cadence. Begin monthly competitive intelligence simulations for your top category queries.
Days 61–90: Measurement, Iteration, and Tier 2 Expansion
By day 60, you should have six to eight weeks of post-optimization data on your proxy metrics. Analyze conversion rate trends, branded search volume movement, and Sponsored Prompts performance for your Tier 1 ASINs. Use what you learn to refine your content approach, then apply the improved framework to Tier 2 ASINs. Continue the weekly operational cadence. At day 90, conduct a full competitive intelligence review for each major category you sell in and update your use-case whitespace map.
Conclusion: The AI Layer Is the New Category Page
For most of Amazon’s history, organic search ranking was the primary battleground. If your listing ranked at the top of the category page for your core keywords, you got traffic. The AI layer changes that in a fundamental way — not by replacing the category page, but by increasingly mediating access to it through an intent-filtering system that decides which products are worth showing before a shopper ever sees a results grid.
Rufus — whatever Amazon calls it next — is now that mediating layer. It’s the new category page for a growing share of product discovery journeys. And unlike keyword ranking, where optimization is primarily about matching tokens, the Rufus layer rewards something more fundamental: the quality and completeness of your product’s representation in a knowledge graph that Amazon has been building, quietly, for years.
The sellers who are winning in this environment aren’t treating it as a new SEO trick to learn. They’re treating it as a new operating reality to build infrastructure around. Attribute completeness, Q&A management, intent-aligned content, and integrated organic-plus-paid catalog strategy aren’t advanced optimizations in this environment — they’re the floor.
The operational complexity of the Rufus era is real. But so is the asymmetry it creates. Categories where most sellers are still operating on A9-era SEO logic are leaving Rufus-layer visibility largely unclaimed. For the operators who build the right workflows now, that unclaimed space is where the next wave of market share is sitting.
Key Takeaways for Operators:
- COSMO builds the product knowledge graph; Rufus/Alexa for Shopping retrieves from it. Optimize for COSMO, not just for search ranking.
- Attribute completeness is your highest-leverage, most under-invested signal. Audit your catalog against the full attribute set available in every category you sell in.
- Q&A is active SEO infrastructure, not passive customer support. Seed it strategically based on conversational query analysis.
- Sponsored Prompts are now CPC-billed and auto-enrolled — check your campaign pacing and build a dedicated monitoring workflow.
- You cannot directly measure Rufus attribution yet. Build a proxy metric framework and track direction of movement across five dimensions.
- Reframe your team’s relationship with listing content: it’s not marketing copy, it’s structured data infrastructure for an AI system that controls an increasing share of your visibility.
- The Alexa for Shopping rebrand expands the surface area of AI-mediated discovery — voice, search integration, deeper personalization. The optimization logic is the same. The stakes are higher.


