


In 2026, 87% of organizations will tell you they have a clear AI governance framework. Ask them to show you the evidence trail from last Tuesday’s model output, and the conversation changes fast.
That gap — between claiming governance and operating it — is where most enterprise AI programs quietly fail. Not in a dramatic, headline-making way, but in the slow accumulation of unmonitored drift, unowned incidents, undocumented approvals, and audit requests that nobody can answer cleanly. According to recent cross-industry research, fewer than 25% of organizations have fully implemented the controls their own governance frameworks require. The rest have documents, committees, and slide decks that stop short of the thing that actually matters: operational enforcement.
This post is not about why governance matters. That argument has been made. It is about the specific, concrete difference between governance that looks serious and governance that actually holds up — under regulatory scrutiny, under a production incident, under the pressure of an audit from a customer, a regulator, or your own legal team. The focus is on what breaks in real deployments, how to fix the structural problems that cause those breaks, and what the organizations getting this right are doing differently at the workflow level — not just at the policy level.
The EU AI Act’s high-risk system controls become enforceable from 2 August 2026. The window for building governance infrastructure that meets that bar — and the broader bar of running trustworthy AI at enterprise scale — is closing. Here is what you need to build, why it breaks the way it does, and how to make it stick.
The Gap Between Having a Policy and Having Governance
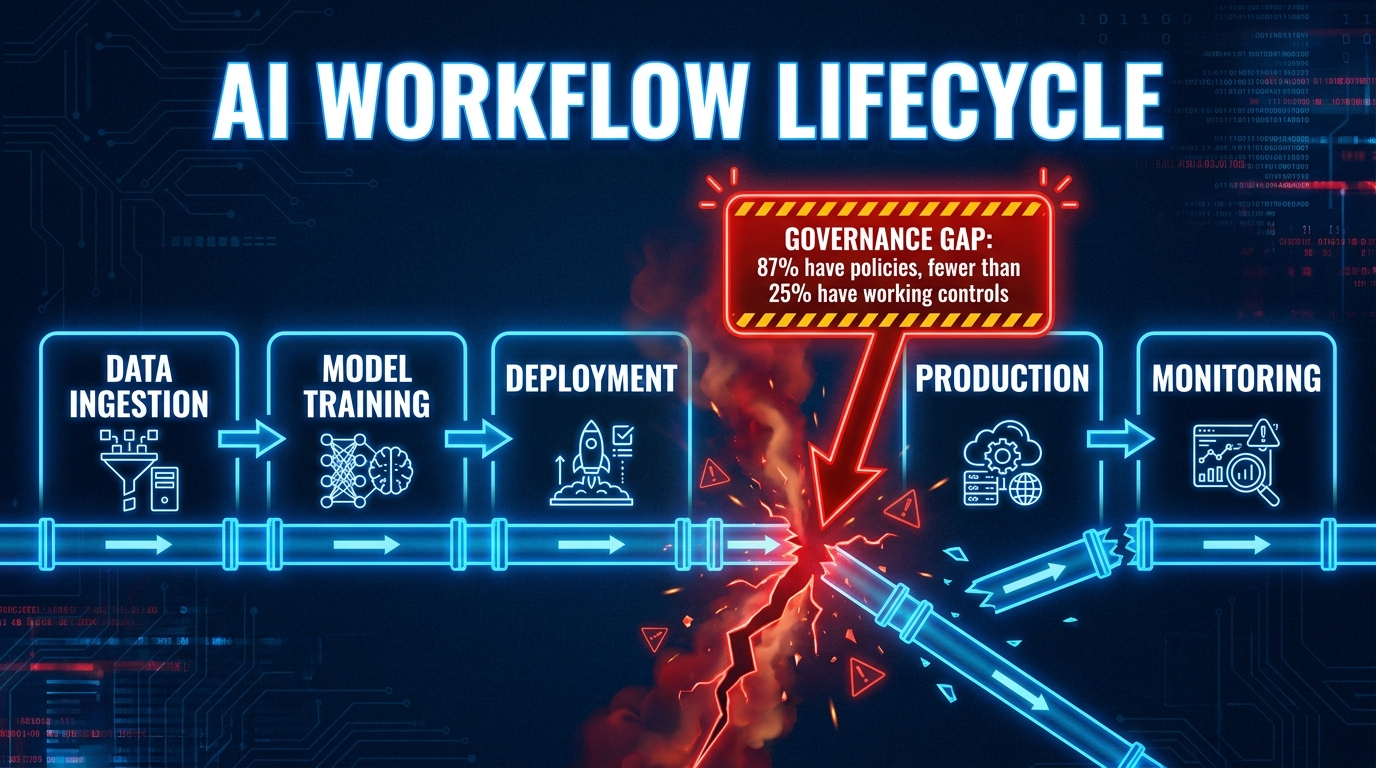
The most dangerous place in AI governance is the space between an approved policy document and a deployed production system. Organizations fill that space with assumptions. The assumptions compound, and eventually something fails that the governance documentation says couldn’t happen — because nobody ever connected the policy to the process.
What “Having a Framework” Usually Means in Practice
When organizations say they have AI governance in place, they typically mean one or more of the following: a written policy reviewed by legal, a principles statement signed off by the board, an AI ethics committee that meets quarterly, or a checklist embedded in the procurement process for new AI vendor relationships. These are not useless. They represent genuine organizational intent, and they provide the scaffolding that real governance can eventually hang from.
What they are not is operational governance. None of those things tell you whether a model running in production today is still performing within the parameters it was approved for six months ago. None of them document who reviewed the model’s outputs last week and what they found. None of them create an evidence trail that a regulator can follow from a specific decision back through the model, the data it used, and the human being accountable for approving its deployment.
This distinction — between governance as declaration and governance as operation — is the central fault line in enterprise AI in 2026. The organizations on the wrong side of that fault line are not reckless or indifferent. They genuinely believe they are governed. That belief is the problem, because it prevents them from building the infrastructure they actually need.
Why “Policy Theater” Persists
The term “policy theater” — governance programs with policies but no enforcement evidence — has become pointed shorthand in enterprise AI circles for exactly this dynamic. It persists for understandable reasons. Building operational governance is harder, slower, and more expensive than writing policies. It requires cross-functional alignment, technical infrastructure, ongoing resource commitment, and organizational processes that outlast the people who built them. Writing a policy requires a few weeks and a document editor.
The incentive structure also works against operational depth. A board can be satisfied with the existence of a governance policy. A regulatory check before the EU AI Act enforcement deadline can be met with documentation. A risk audit can be passed with a framework reference and a committee structure on an org chart. None of these external checkpoints, historically, have required organizations to demonstrate that their governance actually runs in production — that it catches things, that it routes things to named owners, that it creates records that survive the people involved.
That is changing. Regulators in the EU and increasingly in the US are moving toward evidence-based enforcement: they want to see logs, they want to see incident records, they want to trace decisions through the system. Customers in enterprise procurement processes are starting to ask the same questions. The theater phase of AI governance is ending, and the organizations that invested only in the performance of governance are discovering the gap between what they documented and what they built.
The Cost of the Gap
The costs are not always immediate or visible. A 2026 analysis of enterprise AI deployment patterns found that 42% of companies abandoned most of their AI initiatives, up sharply from 17% in 2024. Many of those abandonments were not failures of model performance — they were failures of the surrounding control infrastructure. Models that couldn’t be audited couldn’t be defended to procurement. Models that couldn’t be monitored couldn’t be maintained. Models whose outputs couldn’t be traced couldn’t be corrected when they drifted. Weak governance doesn’t always announce itself with a dramatic incident. It usually shows up as slow-moving inability to scale.
Why Workflows — Not Models — Are Where Governance Breaks Down
There is a common misdirection in how organizations approach AI governance: they focus it on the model. They build governance around model approvals, model cards, model risk assessments. Those things matter. But the model is not where governance breaks down most of the time. The workflow is.
The Model vs. the Workflow
A model, in isolation, is a relatively bounded object. It has a version, a training dataset, an evaluation report, a set of documented performance characteristics. Governing a model — approving it, documenting it, assigning it a risk classification — is difficult but tractable. The model itself is static in any given deployment. What changes constantly is the workflow around it: the data being fed into it, the downstream processes consuming its outputs, the human checkpoints that are supposed to catch errors, the integrations with other systems that may have changed since the model was approved.
This is why workflow-level governance failures are so common and so consequential. An organization approves a loan-underwriting model and documents it thoroughly. Six months later, an upstream data pipeline starts delivering different input distributions because a product change altered what data gets collected. The model’s outputs shift accordingly — not because the model changed, but because the workflow did. If governance is focused on the model, that shift goes undetected. If governance covers the workflow, it gets caught.
Where Workflow Governance Actually Fails
The failure patterns that show up repeatedly in real-world AI incidents fall into a few consistent categories:
- Ungoverned integrations: Third-party data feeds, API connections, and upstream system changes that affect model inputs without triggering any governance review, because the integration layer sits outside the model governance scope.
- Last-mile process breakdown: Human-in-the-loop checkpoints that exist on paper but have become rubber stamps in practice — either because the volume of decisions outpaces the reviewer’s capacity, or because the reviewer lacks the context to meaningfully evaluate the model’s output.
- Output consumption without feedback: Downstream processes that consume model outputs but don’t route feedback about outcomes back to anyone monitoring model performance. The model keeps running, the outputs keep being used, and nobody sees the drift.
- Approval without re-approval: Models approved under one set of workflow conditions continue operating after those conditions change — new users, new data sources, new decision stakes — without triggering a re-review.
- Incident handling gaps: When something goes wrong, there is no clear escalation path, no documented procedure, and no owner who knows what steps to take. The governance framework that was built for the approval phase has nothing to say about what happens during a live production failure.
Governance Needs to Follow the Output, Not Just the Model
The practical implication is that AI governance architecture needs to be designed around the full output journey — from the moment a model receives its input through every downstream system, human checkpoint, and business decision that consumes its output. That is a fundamentally different scope than model governance, and it requires different tools, different ownership structures, and different monitoring approaches. Most organizations have not made that design shift yet, and that is the specific gap that produces the incidents that make headlines and the slow-motion failures that don’t.
The Accountability Architecture: Who Actually Owns What
The single most common cause of AI governance failures — more common than technical shortcomings, more common than data quality issues, more common than model errors — is unclear accountability. When something goes wrong with a production AI system and the question is “who owns this?”, the answer in most organizations involves a pause, a meeting, and a negotiation. That pause is the governance failure.
The Diffuse Ownership Problem
AI systems touch many functions: data engineering, machine learning, product, legal, compliance, risk, and business operations all have legitimate interests and relevant expertise. The natural response is to create shared ownership — a committee, a council, a cross-functional working group. The consequence is that nobody is accountable. Committees cannot be held accountable the way people can. When a model drifts and causes a compliance incident, “the AI governance committee” cannot be fined, escalated, or disciplined in any meaningful organizational sense.
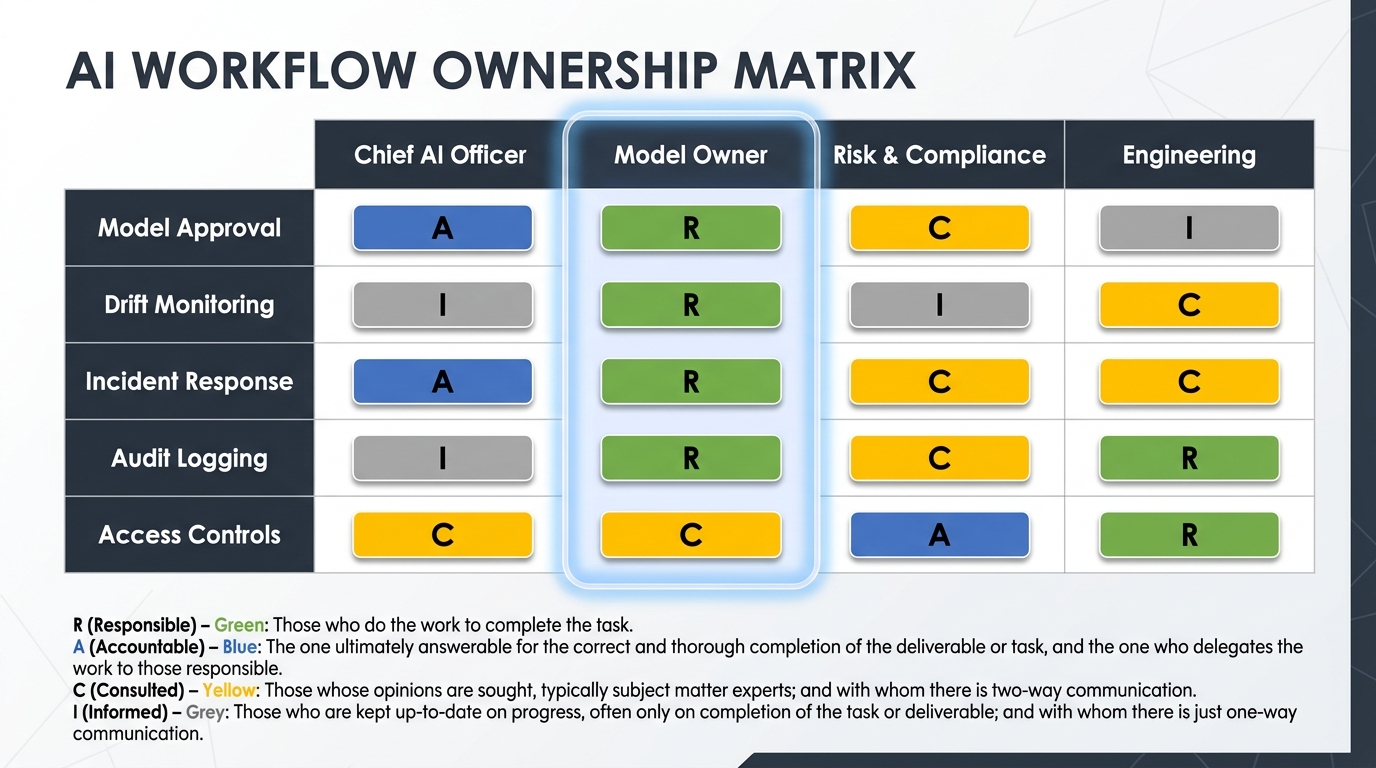
Effective governance requires named individuals — not roles, not committees, but specific people — who are accountable for specific AI systems and specific control functions. Research into organizations that have built governance that actually holds up consistently identifies single-threaded accountability as the structural difference between programs that work and programs that don’t.
Building the Accountability Stack
The accountability architecture that works in practice has several distinct layers, and each layer needs to be designed explicitly rather than assumed:
The Model Owner is a named individual — typically in a business or product function — who is accountable for a specific AI system across its full lifecycle. Not responsible for building it. Accountable for it. That means accountable for its performance in production, for its compliance with applicable policies, for escalating incidents, and for the decision to retire it when it is no longer operating as intended. The Model Owner role is not a technical role; it is a business accountability role.
The Chief AI Officer or equivalent executive sponsor holds the governance function at the portfolio level: maintaining the AI system inventory, setting the governance standards that Model Owners operate within, escalating cross-cutting risks to the board, and owning the relationship with regulators. In organizations that have formalized this role, the CAIO sits alongside the CRO, CTO, and CDO in the enterprise risk structure — not below them.
Risk and compliance functions perform independent validation and monitoring — they are not in the approval chain for model deployment (that creates capture), but they audit that the governance controls are being followed and that the evidence trail meets regulatory requirements. In financial services, this maps directly to the three-lines-of-defense model that regulators already understand.
Engineering and data science teams build and operate the technical governance infrastructure — the logging, the drift monitors, the access controls — under specifications set by governance and compliance. They are responsible for the controls working; they are not accountable for the governance decisions those controls support.
Making RACI Work in Practice
RACI frameworks for AI governance have a reputation for being over-engineered and under-used, mostly because organizations apply RACI to every task rather than to the decision rights and accountability relationships that actually matter. The version that works is leaner: define RACI at the level of governance decisions (who approves deployment, who approves changes, who can authorize remediation, who must be notified of incidents) rather than at the level of every activity. Keep the matrix small enough to be actionable, and review it when organizational structure changes — because the most common way governance accountability breaks down is that the named person changes roles and the governance documentation doesn’t get updated.
Technical Controls That Enforce Themselves
Good governance is not purely organizational. The organizational layer — the owners, the committees, the policies — sets the rules. Technical controls are how those rules are enforced when people are not paying attention. And in production AI systems running at scale, people are not paying attention most of the time. That is not a criticism; it is a design constraint. Technical controls need to be designed to enforce governance without requiring constant human intervention.
Access Controls and Least Privilege
The first category of technical controls is access management. AI systems — particularly those handling sensitive data or making high-stakes decisions — need to operate under the principle of least privilege: every component of the system should have access only to the data, tools, and capabilities it explicitly needs to perform its function. In practice, this means access controls baked into the AI pipeline itself, not just in the surrounding infrastructure.
In organizations running agentic AI workflows — where AI systems take autonomous actions rather than just generating outputs for human review — this becomes even more critical. An agentic AI that can access customer records, draft and send emails, modify database entries, and call external APIs needs those capabilities scoped and audited individually. The failure mode that produces the most significant incidents in agentic AI is not model error; it is a model with broader tool access than it needs, performing an action outside its intended scope because nobody constrained the action space explicitly.
Approval Gates and Change Controls
Technical governance controls need to include hard gates at critical lifecycle transitions. Deployment without an approved model card, a signed-off risk assessment, and a documented test report should not be mechanically possible in a governed system — not just organizationally prohibited, but technically blocked. The same applies to significant changes: a model retrain, an input schema change, a threshold adjustment. Each of these should require a documented approval before it propagates to production.
This is where many organizations have the conceptual governance right but the implementation wrong. They have an approval process that runs in email chains and shared documents, parallel to the technical deployment process. Those two processes frequently fall out of sync — a model gets updated in production because the fix was urgent, and the governance approval follows retroactively or not at all. The fix is to make the approval a prerequisite in the deployment pipeline itself, so governance and deployment are the same system rather than parallel systems that need to be kept aligned manually.
Kill Switches and Rollback Capability
A governance control that gets underweighted in most frameworks is the kill switch: the ability to halt, suspend, or roll back an AI system quickly when something goes wrong. This sounds obvious, but it requires explicit engineering investment — model versioning that supports clean rollback, circuit breakers that can halt inference when error rates exceed thresholds, and a documented procedure for who can invoke these controls and how fast they can act.
The organizations that recover fastest from AI production incidents are not the ones with the most sophisticated monitoring. They are the ones that can make the problem stop quickly and then investigate. Recovery speed is a governance design choice, not a technical accident.
Runtime Policy Enforcement
For AI systems that generate outputs subject to content, legal, or regulatory constraints — a growing category as AI is applied to customer communications, medical information, and financial advice — runtime policy enforcement is a governance layer that operates at inference time. This includes output filtering, confidence thresholding (suppressing low-confidence outputs from appearing in high-stakes contexts), and input validation that rejects out-of-distribution or policy-violating inputs before they reach the model. These are not model improvements; they are governance controls that sit around the model and enforce boundaries the model itself cannot reliably enforce.
Audit Trails: Building the Evidence Chain Regulators Can Actually Use
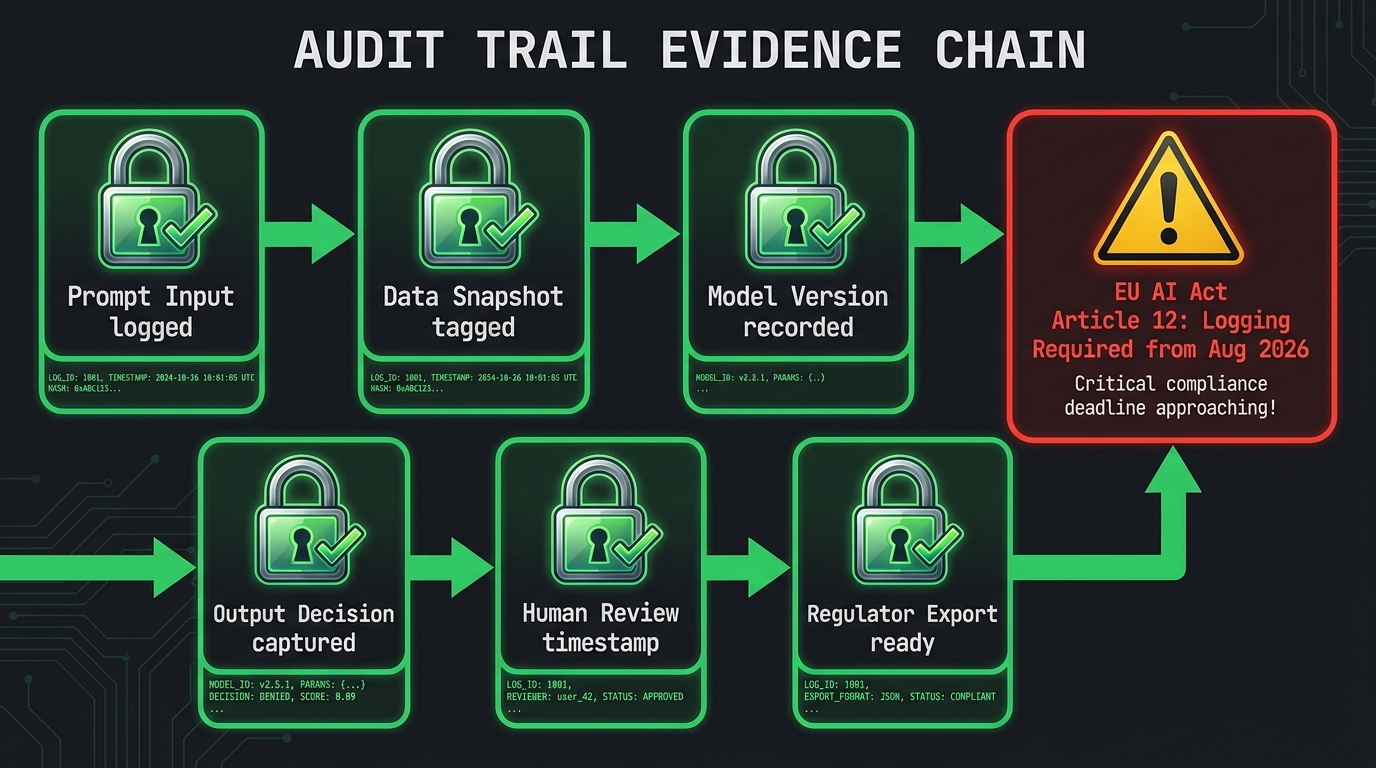
An audit trail is not a log file. That distinction matters more than it might seem. A log file records what happened. An audit trail records what happened, establishes that the record is complete and tamper-evident, links each event to its context and the person or system responsible, and makes the whole chain navigable by someone who wasn’t there when the events occurred. Building audit trails rather than log files is an engineering and governance discipline that most organizations have not fully developed for AI systems.
What the EU AI Act Actually Requires
The EU AI Act’s Article 12, enforceable from August 2026 for high-risk AI systems, mandates logging capabilities that enable post-market monitoring and facilitate the investigation of incidents. The language is deliberately operational: it is not enough to have a policy that logging should occur. The technical capability must exist, the logs must be retained for defined periods, and they must be in a format and structure that supports the investigation it is designed to enable.
Practically, the EU AI Act logging requirements for high-risk systems create the following obligations: logging of inputs or input categories (not necessarily every raw input, but enough to reconstruct the conditions under which a decision was made); logging of decisions and outputs; recording of human oversight activities and who performed them; and retention of records that map each high-risk AI decision to the model version, training data version, and configuration state that produced it.
These are not light requirements. Many organizations’ current logging practices capture some of this incidentally, but not in a structured, recoverable way. The difference between a log that could theoretically support an audit and an audit trail that actually does support an audit is significant engineering and governance work.
The Five Elements of a Governance-Grade Audit Trail
Based on current regulatory guidance and the operational requirements of organizations that have been through external AI audits, a governance-grade audit trail for a production AI system needs to capture five things:
- Input provenance: What data was used, from which sources, processed through which transformations, at what point in time. This is not just the raw input to the model — it includes the lineage of that input through the data pipeline.
- Model identity: Which specific model version, with which configuration parameters and threshold settings, produced the output. Not the model family — the exact version, pinned to a hash or equivalent identifier that makes it reproducible and auditable.
- Decision record: What the model output was, what decision or action it drove, and what confidence or probability was associated with that output. For high-risk decisions, this needs to be stored in a way that is linked to the specific individual or account affected.
- Human oversight record: If a human was required to review or approve the model’s output before it drove an action, the audit trail needs to document that review — who performed it, when, and what judgment they applied. A rubber-stamp review is not meaningful oversight, but the record of what review occurred is still required.
- Tamper-evidence: The audit trail needs to be stored in a way that makes unauthorized modification detectable. This is a data integrity requirement, not just a storage one — and it matters both for regulatory purposes and for internal incident investigation where the integrity of the record may be contested.
Making Audit Trails Operational, Not Just Available
The audit trail architecture fails operationally when it is complete but unusable. This is a common problem: organizations build logging infrastructure that technically captures everything required but stores it in formats, locations, or volumes that make it practically unusable for investigation. A governance-grade audit trail needs to be queryable: you need to be able to ask “show me every decision this model made for customers in this category between these dates” and get a clean answer in minutes, not days of data engineering work.
Organizations that pass external audits cleanly are not those with the most logging. They are those whose audit infrastructure was designed for retrieval, not just storage, and whose governance team knows how to use it before they need it.
Model Drift Is a Governance Problem, Not a Data Science Problem
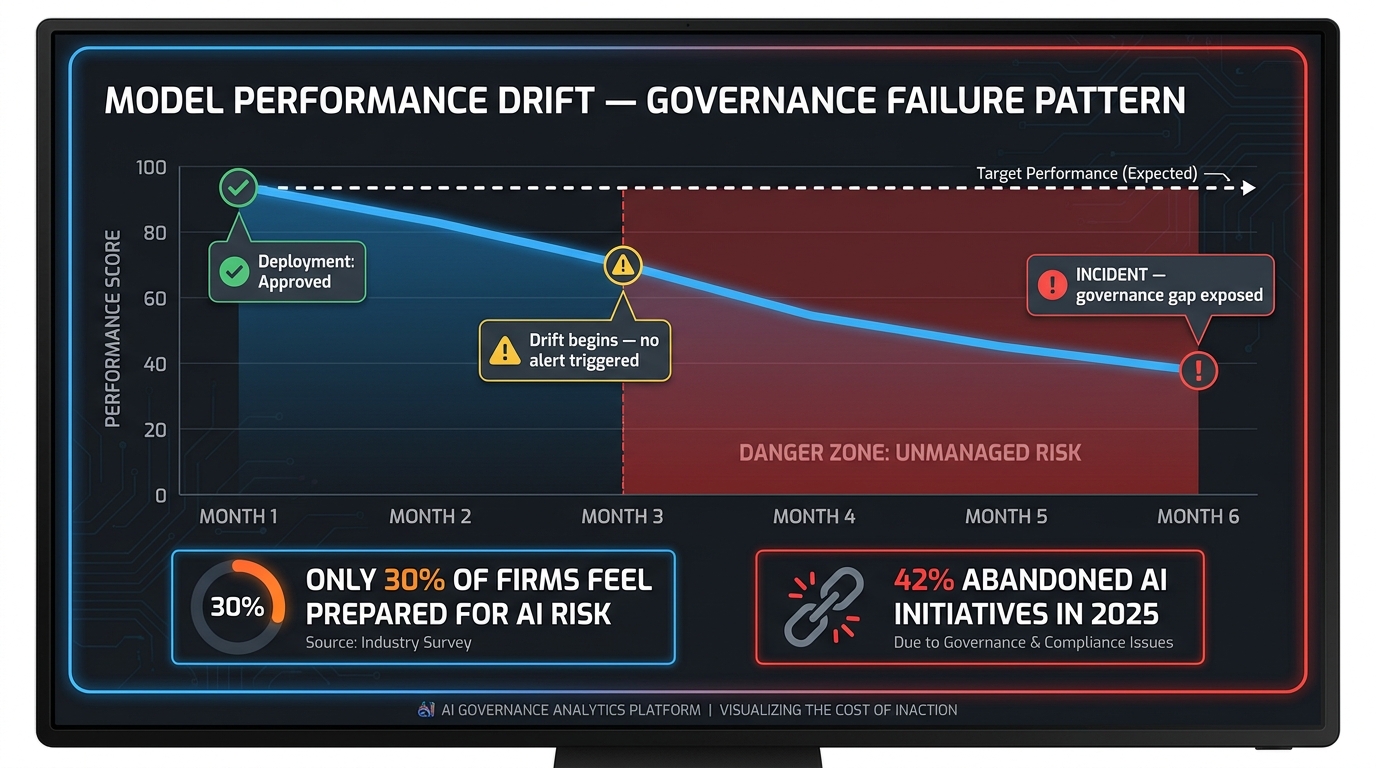
Model drift — the gradual degradation of a model’s performance as the world it operates in changes — is usually discussed as a machine learning problem. It is framed around data distributions, feature statistics, concept drift, and retraining schedules. All of that is real and relevant. But the reason model drift causes governance incidents is not that data scientists don’t know about it. It is that organizational governance systems don’t have clear ownership of the response to drift, and they don’t have the institutional structures to act on drift signals when they appear.
Why Drift Escapes Governance
Consider what actually happens when a model starts to drift. The data science team may notice a statistical signal — input distributions shifting, output distributions changing, evaluation metrics declining on periodic checks. They log it, they track it, they might file a ticket or send an email. But who owns the governance decision of whether the drift is significant enough to warrant a deployment freeze, a remediation, or a risk escalation? In most organizations, that is unclear. The data science team doesn’t own the business risk. The business team doesn’t understand the technical signal. Risk and compliance may not even know drift is occurring.
Only 30% of firms report feeling prepared for AI risk management in 2026. The gap is largely structural: the technical capability to detect drift exists in many organizations, but the governance pathway from drift detection to governance response — escalation, investigation, remediation, or decommission — is undefined. A drift alert that doesn’t have a clear owner, a clear response protocol, and a clear escalation path is not governance. It is observation without accountability.
Connecting Drift Detection to Governance Response
The governance infrastructure for model drift needs to define, in advance, the following:
- Drift thresholds that trigger governance actions: Not just statistical alerts, but explicit thresholds tied to business and risk outcomes — at what level of performance degradation does a governance review become mandatory? At what level does operation require explicit re-approval? At what level does the system get suspended pending investigation?
- Named governance responders: Who receives a drift alert? Who is responsible for convening a review? Who has the authority to order a model suspension? These names need to be documented, current, and tested in drills rather than discovered for the first time during an incident.
- Response timelines: How fast must the governance response occur? For high-risk systems in regulated sectors, regulators are beginning to expect defined response timelines — not best-effort investigations, but committed timeframes from detection to remediation or shutdown.
- Re-approval criteria: If a model is remediated and redeployed after a drift incident, what does re-approval require? The answer should be more than “the data science team says it’s fixed.” It should include independent validation, updated model documentation, and a governance sign-off that the root cause has been addressed.
Continuous Monitoring as a Governance Obligation
The framing that resolves the ownership ambiguity around drift is treating continuous monitoring as a governance obligation rather than a data science practice. This is the shift that regulators are making, and organizations that have worked through serious AI governance programs are making it too. The Model Owner is accountable for continuous monitoring being in place and for the governance response to monitoring signals. The data science team builds and operates the technical monitoring. Risk and compliance audits that the monitoring is occurring and the governance response is being triggered appropriately. When monitoring reveals a problem, the governance pathway is already defined — because it was designed as a governance system, not just a technical one.
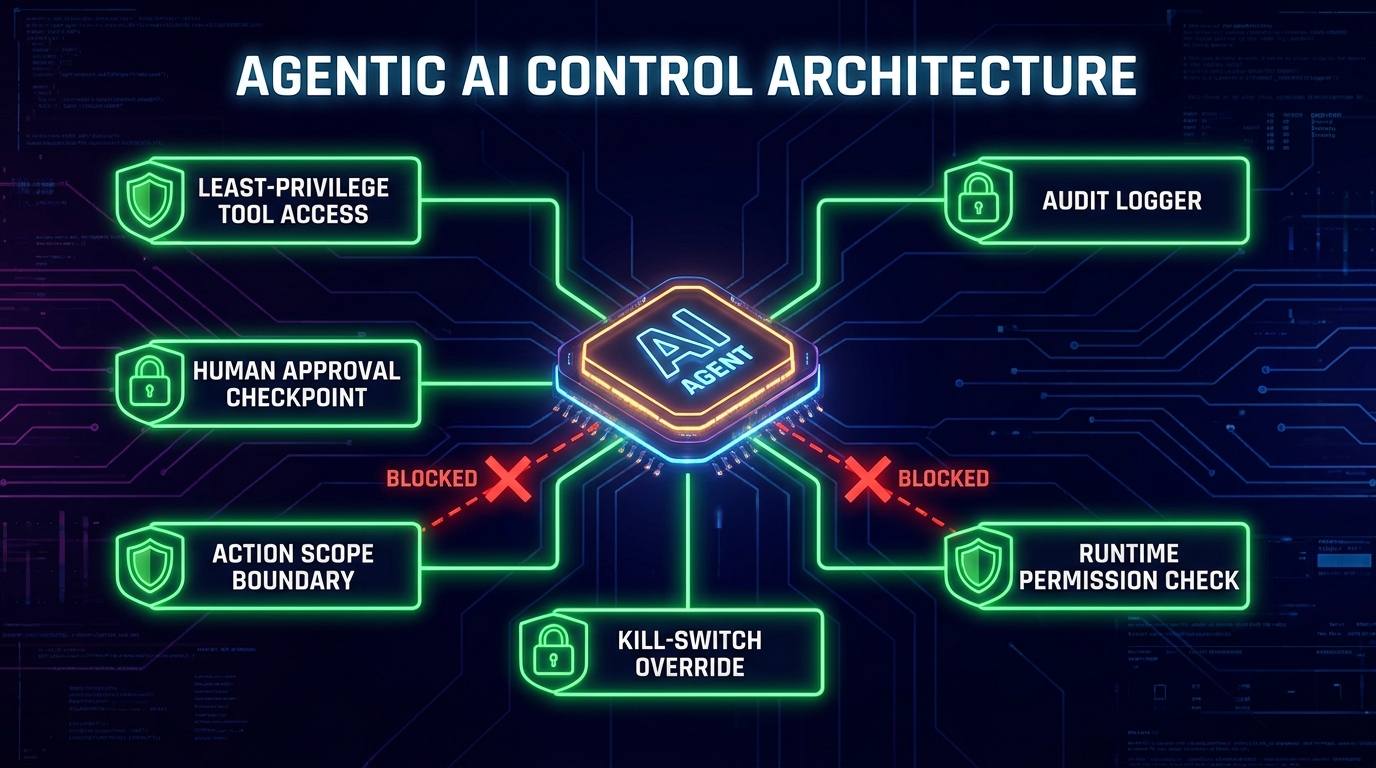
Agentic AI: Why Autonomous Workflows Need Harder Guardrails
Agentic AI systems — those that take sequential actions, use tools, and operate with a degree of autonomy rather than simply generating outputs for human review — represent the frontier of both AI capability and AI governance difficulty. The governance frameworks that work for inference-only models do not map cleanly onto agents, and organizations deploying agentic workflows in production in 2026 are discovering that the hard way.
What Makes Agentic Governance Different
In a standard AI deployment, the governance control points are relatively clear: control what goes in (data governance, input validation), control the model itself (approvals, versioning, documentation), and control how outputs are used (human review, downstream process controls). The model doesn’t take actions. Humans or downstream systems do.
In an agentic deployment, the AI system itself takes actions: it sends emails, calls APIs, modifies records, triggers purchases, and chains multiple steps together without human review at each step. This changes the governance problem fundamentally. The consequences of a governance failure are no longer limited to a bad output that gets acted on by a human who might catch the error. They extend to the direct actions the agent takes autonomously, including actions that may be difficult or impossible to reverse.
The governance failures that show up most in agentic deployments are access-related: agents with tool access broader than their intended scope, performing actions outside that scope when edge cases in their prompts or inputs lead them to unexpected decision paths. The fix is not better models. It is tighter technical governance of the action space.
Defense-in-Depth for Agentic Systems
The governance architecture that organizations are converging on for agentic AI in production applies a defense-in-depth approach across four layers:
Layer 1 — Least-privilege tool access: Each agent is scoped to the specific tools and data it needs for its defined task, with access enforced technically rather than assumed from the model’s instructions. If an agent’s task is scheduling, it has calendar access and nothing else. If its task is drafting customer responses, it has read access to relevant customer records and send access to a review queue — not direct send access to customers. This scoping is designed and reviewed as a governance artifact before deployment, not configured ad hoc by the engineering team.
Layer 2 — Human approval checkpoints at high-stakes actions: Actions that are difficult to reverse, have significant external consequences, or fall above a defined risk threshold require human approval before execution, regardless of how confident the agent is in its decision. This is not a default to human-in-the-loop for all actions — that defeats the purpose of agentic automation — but a calibrated checkpoint structure that reserves human judgment for the decisions where its absence is most consequential.
Layer 3 — Runtime policy enforcement: Policies governing what the agent can and cannot do are enforced at runtime, not just at design time. This means the agent’s operating environment actively checks each action against the defined policy before allowing it to execute — not relying on the model to have internalized the policy correctly, but enforcing it as a technical constraint regardless of what the model decides.
Layer 4 — Full observability and kill-switch capability: Every action the agent takes is logged with enough context to reconstruct its reasoning, the tool calls it made, and the outcomes of those calls. A kill switch is available and tested: the ability to halt agent operation immediately, with a defined procedure for who can invoke it and under what conditions. Recovery from an agent incident should not require an emergency engineering intervention. It should be a documented governance procedure.
The Agentic Governance Gap in 2026
The honest assessment of where the industry is in 2026 is that most organizations deploying agentic AI do not yet have all four layers in place. Most have some logging. Fewer have scoped tool access by design. Fewer still have runtime policy enforcement separate from model instructions. And the organizations that have tested their kill switch before needing it are a distinct minority. This is the governance frontier, and the consequences of failing on it are more immediate and more reversible-harm-generating than the failures that occur in inference-only systems.
The EU AI Act Deadline and What It Forces You to Build
The EU AI Act’s enforcement timeline provides a useful external forcing function for governance infrastructure that many organizations need but haven’t prioritized. From 2 August 2026, high-risk AI systems operating in the EU — a category that includes AI used in employment decisions, credit assessments, essential services, and several other domains — must comply with a set of mandatory operational requirements. Understanding what those requirements actually demand in practice is more useful than understanding them as an abstract compliance checklist.
High-Risk vs. General-Purpose: Getting the Classification Right
The first governance task is classification. Organizations need to determine which of their AI systems fall into the EU AI Act’s high-risk categories, because the compliance obligations differ significantly. This is not always straightforward — the classification depends on both what the system does and how it is used in context, and organizations that have relied on their AI systems being “general-purpose” need to examine carefully how those systems are actually deployed in business processes that may make them high-risk in application if not in design.
Getting the classification wrong — assuming a system is not high-risk when it is — is not a safe error. It means the governance infrastructure for that system won’t meet the legal requirements, and the liability for that gap sits with the deployer, not the model developer. In enterprise AI governance, the deployer is responsible for ensuring that the compliance posture of the system as deployed meets the applicable regulatory standard.
What Articles 9 Through 17 Actually Require
The substantive requirements for high-risk AI systems under the EU AI Act cluster around a few core operational obligations:
Risk management system (Article 9): A continuous, iterative risk management process that covers the full lifecycle of the system — not a one-time assessment, but an ongoing process that updates as the system’s operating environment changes. This maps closely to what effective governance organizations were already doing; for everyone else, it requires building a risk management operating rhythm around each high-risk system.
Data governance (Article 10): Training, validation, and testing data must meet defined quality standards, with documented processes for data management, examination of biases, and practices for data security. This creates a direct link between data governance programs and AI governance programs that many organizations have not yet formalized.
Technical documentation (Article 11): Comprehensive, maintained documentation that covers design choices, training methodologies, validation results, and the intended purpose of the system. This documentation must be kept current — it cannot be written at deployment and left unchanged as the system evolves.
Logging and record-keeping (Article 12): The automatic logging of events relevant to monitoring, incident investigation, and regulatory review, as discussed above. For high-risk systems, this is mandatory and must be designed as a capability, not retrofitted after the fact.
Human oversight (Article 14): High-risk AI systems must be designed and deployed such that natural persons can effectively oversee the system — understand its outputs, detect failures, intervene, and override or halt operation. The human oversight requirement is operational, not nominal: having a human sign off on a process that is too fast or too opaque for meaningful review does not satisfy Article 14.
Building for August 2026 and Beyond
The practical governance build required by the EU AI Act is not a compliance exercise done once and filed. It is an operating infrastructure — the risk management process, the documentation maintenance, the logging architecture, the human oversight design — that runs continuously as long as the system is deployed. Organizations that treat it as a one-time project will find themselves out of compliance as soon as their systems or operating environments change, which they will. Organizations that build it as an operating system will find that the investment compounds: the infrastructure that supports EU AI Act compliance also supports internal governance, audit readiness, and the organizational ability to catch and respond to problems before they become incidents.
Cross-Functional Governance Without the Coordination Overhead
One of the most common failure modes in enterprise AI governance design is over-engineering the coordination structure. Organizations recognize that AI governance requires input from multiple functions and respond by creating large governance committees, elaborate review processes, and multi-stage approval chains that are technically comprehensive and operationally paralytic. The governance system becomes the bottleneck, and the pressure to move fast leads teams to route around it. Governance that takes too long gets bypassed, which means it governs nothing.
The Coordination Problem in AI Governance
The functions that need to be involved in AI governance are genuinely different from each other. Legal and compliance care about regulatory exposure. Risk management cares about operational and financial risk. Data engineering cares about data lineage and quality. Machine learning cares about model performance. Product cares about user experience and business outcomes. Information security cares about access controls and data protection. Each function has relevant expertise, legitimate authority, and real accountability for some part of the governance picture. The challenge is creating structures that capture that expertise without requiring everyone to be involved in every decision.
Design Governance for the Decision, Not the Function
The governance design that minimizes coordination overhead maps approval authority to decision type rather than requiring all functions to review all decisions. Not every governance decision requires legal, risk, data engineering, ML, product, and security to have a seat at the table. A model retrain that doesn’t change architecture, scope, or training data may only require the Model Owner and an ML lead. A new system deployment with significant personal data processing and regulatory implications requires a broader review. A production threshold adjustment within pre-approved bounds may require only a logged record.
This tiered approach — sometimes called a governance traffic light, where green-lane decisions are pre-authorized within defined parameters, yellow-lane decisions require lightweight review, and red-lane decisions require full committee process — dramatically reduces coordination overhead without reducing governance coverage. It requires upfront design work to define the lanes clearly, but that work pays for itself quickly by removing the friction that drives teams to bypass governance entirely.
Standing Committees vs. Embedded Governance
The governance structures that work best in 2026 are not primarily committee-based. They are embedded into the development and operations workflow, with governance decisions surfaced and tracked in the same tools teams already use — CI/CD pipelines, issue trackers, risk registers, and deployment systems. The committee structure exists for escalations, policy decisions, and periodic portfolio reviews — not for routine decisions that should be handled at the Model Owner level with documented evidence rather than convened meetings.
Moving governance from a meeting-based model to a workflow-embedded model is a cultural and tooling change, not just a process redesign. It requires governance teams to invest in the developer experience of the governance process itself — making it fast to document, fast to route for approval, and fast to retrieve the evidence when needed. Governance that is burdensome to participate in will be avoided. Governance that is frictionless to follow will be followed.
What Good Looks Like: Patterns From Organizations Getting It Right
Across the organizations that have built AI governance that demonstrably holds up — that passes external audits, that catches and contains production incidents, that scales without collapsing under coordination overhead — a consistent set of patterns emerges. None of these are exotic or theoretically complex. What makes them rare is that they require sustained organizational will to implement and maintain, not just technical sophistication.
Pattern 1: The AI System Registry as the Governance Anchor
Organizations with effective governance maintain a current, comprehensive inventory of every AI system in production, including third-party AI tools embedded in vendor products. This registry is not a static document — it is a live system that tracks the system’s current status, the Model Owner’s name, the applicable risk classification, the last governance review date, the compliance status, and links to current documentation and monitoring dashboards.
The registry serves as the governance anchor: it is how the CAIO knows what needs to be governed, how compliance knows what needs to be audited, and how incident responders know what they are dealing with when something breaks. Organizations without a maintained registry cannot govern what they don’t know they have — and in most large organizations, the number of AI systems in production significantly exceeds what the central governance function is aware of.
Pattern 2: Governance Triggers Built into the Development Workflow
Rather than treating governance as a separate phase that happens before or after development, organizations that succeed embed governance triggers into the development process itself. Deploying a new model requires completing a model card in the same ticket where deployment is tracked. Changing an input schema requires a risk review that is linked to the change request, not filed separately. Passing monitoring thresholds triggers governance alerts in the same channels where engineering incidents are tracked.
This integration means governance evidence is generated as a natural byproduct of development work rather than as a separate documentation burden. The quality and completeness of the evidence trail improves because it is captured in context rather than reconstructed from memory at audit time.
Pattern 3: Red-Team Testing Before Deployment
Organizations with mature governance don’t rely solely on standard performance evaluations before deployment. They conduct adversarial testing — red-teaming — designed to find failure modes that standard evaluation doesn’t surface: edge cases where the model behaves in policy-violating ways, prompt injection attacks in agentic systems, data inputs that cause the model to make protected-class-correlated errors, and scenarios that test the human oversight mechanisms rather than just the model.
Red-teaming is increasingly expected by regulators and major enterprise customers as evidence of due diligence before deployment of high-risk systems. Organizations that have built it into their pre-deployment checklist have better evidence of diligence and better-performing systems in production — both because the testing catches real issues and because the discipline of conducting it forces more careful pre-deployment thinking.
Pattern 4: Governance Reviews That Are Forward-Looking, Not Just Backward
Periodic governance reviews in effective programs don’t only look backward at what happened in the past cycle. They look forward at what is likely to change in the next cycle: planned model updates, anticipated changes to input data distributions, planned expansions of the system’s use scope, upcoming regulatory milestones. Governance that is entirely retrospective is always playing catch-up. Governance that anticipates change can prepare for it — updating documentation, re-running risk assessments, and adjusting monitoring thresholds before the change occurs rather than after it causes a problem.
Governance Debt: The Hidden Cost of Skipping Controls Early
There is a concept in software engineering called technical debt: the accumulated cost of shortcuts and deferred maintenance that builds up over time, making future changes more expensive and more risky than they would have been if the work had been done properly earlier. Governance debt in AI systems works the same way, and it compounds in ways that technical debt does not always match.
How Governance Debt Accumulates
Governance debt accumulates through predictable decisions that each seem reasonable at the time: deploying a model without full documentation because the deadline is tight; skipping the red-team test because the use case seems low-risk; assigning the Model Owner role to a team rather than a person because nobody wants to take individual accountability; building monitoring that captures events but not in a retrievable, structured format because the data engineering work to do it properly got deprioritized.
Each of these decisions creates a future cost. The undocumented model needs to be reverse-engineered for documentation when the audit request arrives. The un-red-teamed system produces an incident that requires a post-hoc investigation that would have been faster as pre-deployment testing. The team-owned model has nobody to call when the incident response clock is running. The unstructured monitoring data requires weeks of data engineering to produce the evidence the regulator needs.
The challenge is that each individual governance shortcut looks like a reasonable near-term trade-off when it is made. The cumulative cost only becomes visible when it is time to pay it down — which is usually under pressure, during an audit, a regulatory inquiry, or a production incident.
The Cost of Governance Debt at Scale
In organizations that have allowed governance debt to accumulate across many AI systems, the remediation cost can be significant. Re-documenting deployed models requires the original developers to reconstruct decisions they made months or years ago. Re-running evaluations requires reproducing training data and model versions that may not have been carefully versioned. Re-assigning ownership to individuals requires organizational negotiations that governance documentation created at deployment would have resolved upfront. And the window in which all of this can be done before a regulatory enforcement action or a significant incident is shorter than most organizations expect.
The practical advice here is consistent across governance practitioners: govern the first model as carefully as you intend to govern the hundredth. The habits and infrastructure built around the first deployment become the template for every subsequent deployment. Organizations that shortcut governance on early, “low-risk” systems find that those shortcuts become the default, and that reversing them at scale requires more effort than building them correctly the first time.
Paying Down Governance Debt Systematically
For organizations that already have a governance debt problem — a portfolio of AI systems that were deployed without adequate governance infrastructure — the remediation approach that works is prioritized and systematic rather than comprehensive and simultaneous. Start with the systems with the highest risk classification, the most sensitive data, or the most significant regulatory exposure. Document them properly, assign individual ownership, build their monitoring, and integrate them into the governance registry. Then work down the risk priority order. The goal is not to reach zero governance debt instantaneously — it is to stop accumulating new debt while systematically paying down the existing balance, starting where the exposure is greatest.
Making Governance Durable: The Organizational Conditions That Keep It Working
Governance infrastructure that works on the day it is built but erodes over time is not operational governance. The final challenge — and it is primarily an organizational challenge rather than a technical one — is making governance durable. This means building the organizational conditions that keep governance working as people change roles, as the AI portfolio grows, as regulatory requirements evolve, and as the pressure to move fast competes with the discipline of moving carefully.
Governance as a Product, Not a Project
The mental model shift that distinguishes organizations with durable governance from those with governance programs that peak and then decay is treating governance as a product with ongoing ownership rather than a project with a completion date. A project ends. A product is maintained, iterated, and improved in response to what users need and what the operating environment requires.
This means the governance function has ongoing engineering resources, not just one-time build resources. It means the governance tooling — the registry, the audit trail infrastructure, the monitoring dashboards — is maintained and updated as the AI portfolio evolves. It means governance policy is reviewed and updated when the regulatory environment changes, not when someone notices that the policy no longer reflects current requirements. These commitments are organizational rather than technical, which makes them harder to sustain — and more consequential when they lapse.
Governance Literacy Across the Organization
Durable governance requires that the people who build and operate AI systems understand what governance requires of them — not at a compliance-training level, but at a working knowledge level. Model Owners who don’t understand what a model card should contain, data engineers who don’t know that input schema changes require governance review, product managers who don’t know that expanding a model’s use scope requires a re-assessment: these knowledge gaps are governance vulnerabilities.
The organizations investing in governance literacy are not just training compliance. They are creating the conditions under which governance requirements get caught and handled by the people closest to the work, rather than requiring a governance specialist to supervise every decision. That shift — from governance as specialist oversight to governance as distributed organizational competency — is the operating model that scales.
The Board and Executive Layer
Durable governance requires executive ownership and board visibility. In 2026, this is increasingly not optional: regulators are beginning to expect that boards of organizations deploying high-risk AI can demonstrate informed oversight of their AI governance programs. That means boards need access to meaningful AI risk reporting — not vanity metrics about the number of models deployed, but risk-oriented reporting about governance coverage, incident trends, compliance status, and significant emerging risks.
Organizations that have built this board-level visibility find that it creates useful organizational pressure in the right direction: governance programs that have board attention tend to receive the resources and organizational priority they need to remain effective. Governance that is invisible to leadership is vulnerable to being deprioritized when other pressures mount — which they always do.
Conclusion: Governance That Holds Up Under Pressure
The test of AI governance is not whether it passes inspection on a calm day when everything is working. It is whether it holds up under pressure — under a regulatory audit, under a production incident, under the organizational pressure to ship faster than the governance process allows, under the stress of a personnel change that puts the named Model Owner in a new role six months after they were assigned.
The organizations that have built governance that actually holds up share a common understanding: governance is not a wrapper around AI work. It is part of AI work. The audit trail is not generated retrospectively for compliance purposes — it is built as a byproduct of properly structured development. The drift monitoring is not a data science project separate from the business process — it is a governance obligation with a named owner and a defined response procedure. The human oversight checkpoints are not nominal review steps at the end of a process — they are designed to provide meaningful judgment at the points where meaningful judgment is most consequential.
The structural investments required to reach this state are real: dedicated governance infrastructure, individual accountability, workflow-embedded controls, audit trails built for retrieval not just storage, and the organizational discipline to maintain all of this as the AI portfolio grows. None of it is free. But the cost of not building it is increasingly visible, increasingly measured, and increasingly borne by the organizations that chose performance over governance on the assumption that the governance debt could be paid down later.
August 2026 is not the deadline for building AI governance. It is a milestone on a longer journey toward AI operations that can be trusted — by regulators, by customers, by the people inside organizations who need to know that the systems they build and run will behave as designed, report when they don’t, and stop when they must.
Key Takeaways: Build governance as operating infrastructure, not policy documentation. Assign individual accountability for every AI system. Embed governance controls in the deployment pipeline so approval and deployment are the same process. Design audit trails for retrieval, not just storage. Treat model drift as a governance trigger, not just a data science signal. Apply defense-in-depth to agentic AI action spaces. Prioritize governance debt remediation by risk level. Make governance durable by treating it as a product with ongoing ownership.


