
Every engineering team that ships an LLM-powered product eventually confronts the same uncomfortable truth: adding guardrails to a demo is easy. Making those guardrails hold up under real user behavior, adversarial probing, edge cases, and the relentless entropy of production environments is something else entirely.
The industry has learned this the hard way. A study of 36 production LLM-integrated applications found that 86% were vulnerable to prompt injection. Assessments of enterprise deployments consistently put prompt injection–style attack success rates between 50% and 84%, depending on the architecture. And perhaps most sobering: guardrails that perform well during pre-launch testing regularly collapse after downstream fine-tuning — with one dataset showing jailbreak vulnerability increasing by more than 16% post-tuning.
Yet the conversation in most engineering teams still revolves around whether to add guardrails, not how to make them actually work under pressure. This post is about the latter. We’ll walk through the real structure of a production guardrail stack — what each layer does, where each one fails, how to pick the right tools, and how to stop treating safety as a pre-launch checklist and start treating it as a continuous engineering discipline.
No vendor pitches. No abstract principles. Just a layer-by-layer breakdown of what it actually takes to ship an LLM application that doesn’t embarrass your organization — or worse.
What “Guardrails” Actually Means in a Production System
Ask five engineers what “guardrails” means and you’ll get five different answers. Some think it means the system prompt instruction that tells the model to “be helpful and avoid harmful content.” Others think it means a third-party moderation API call bolted onto responses. A few are thinking about constitutional AI principles baked into RLHF training. None of these are wrong, exactly — but treating any single one of them as the guardrail is what leads to production incidents.
A working definition worth anchoring to
In production, guardrails are any control mechanism that constrains, validates, monitors, or intercepts the behavior of an LLM-powered system at runtime. That definition is deliberately broad — because the threat surface of a production LLM is also broad. It spans what goes into the model (user inputs, retrieved context, injected instructions), what comes out of the model (text, structured data, tool calls), and what happens around the model (tool execution, downstream API calls, memory writes).
Why “model-level” safety isn’t enough
LLM providers do bake safety behaviors into their models — RLHF alignment, Constitutional AI fine-tuning, built-in refusal behaviors. These matter. But treating them as your primary guardrail is like treating a database vendor’s default configuration as your entire security posture.
Provider-level safety filtering can be bypassed through clever prompt construction. It offers zero visibility into what your application is actually sending or receiving. It can’t enforce your specific business policies. And it provides no audit trail, which is increasingly a hard requirement for regulated industries. Enterprise guidance in 2026 is unanimous on this point: built-in provider safety is a baseline, not a strategy.
The shift to gateway-level enforcement
The dominant architectural pattern that has emerged across enterprise deployments is moving guardrail logic out of individual application code and into a centralized AI gateway — a shared runtime enforcement layer that sits between applications and LLM APIs. This approach makes policies consistent across use cases, creates a single place to update controls, and produces audit logs that actually mean something to a compliance team.
It also means guardrails become a platform capability rather than a per-app implementation detail — which matters enormously when you’re running dozens of AI-powered features across different products and teams.
The OWASP LLM Top 10 as Your Threat Map
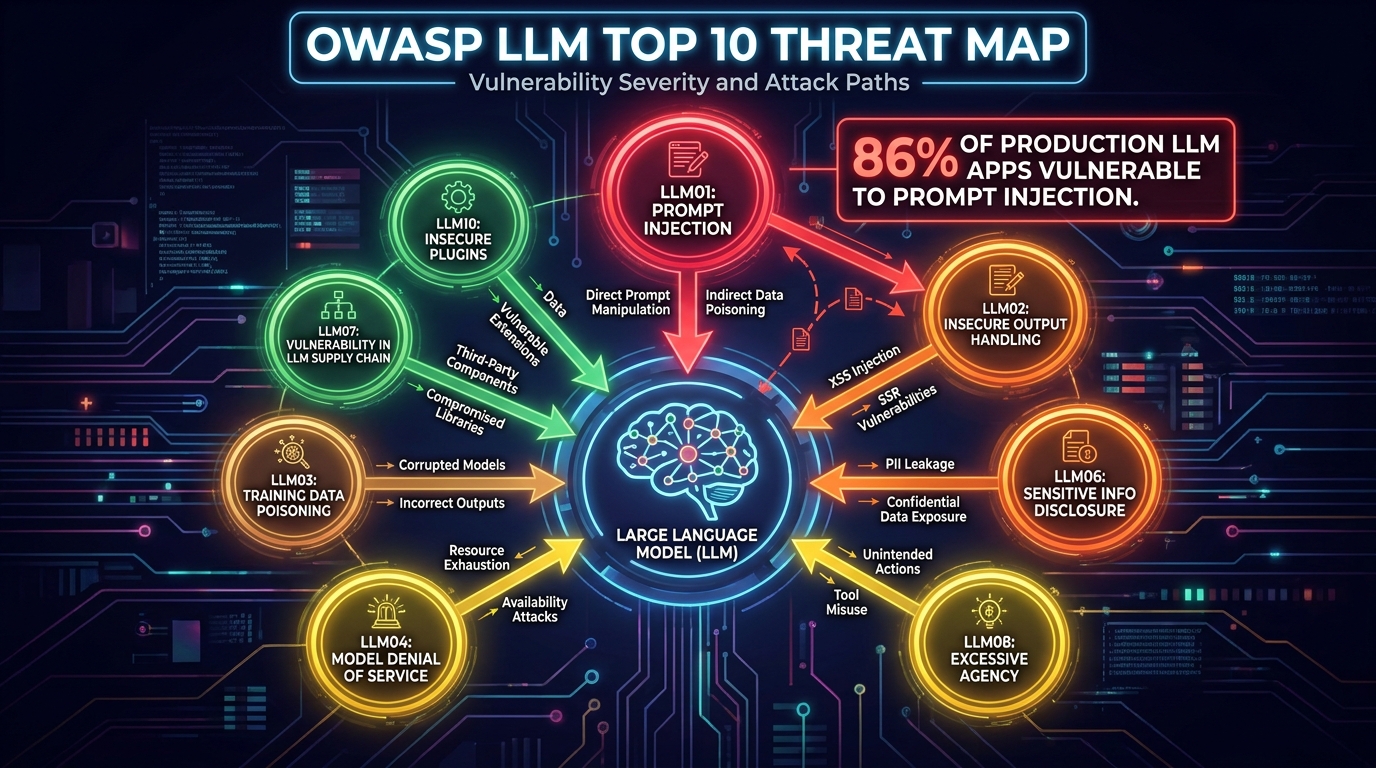
Before you can design a guardrail stack, you need a threat model. The OWASP Top 10 for Large Language Model Applications — now part of the broader OWASP GenAI Security Project, developed by over 600 experts across 18 countries — is the closest thing the industry has to a canonical threat taxonomy for LLM systems. Understanding it as a map of attack surfaces, rather than a checklist to tick off, changes how you design your controls.
The threats your guardrail stack needs to address
LLM01 – Prompt Injection: The highest-severity risk. An attacker crafts input that overrides or hijacks the model’s instructions, causing it to ignore its system prompt, exfiltrate data, or take unauthorized actions. Prompt injection appears in more than 73% of assessed production LLM applications. Indirect prompt injection — where malicious instructions are embedded in retrieved content like documents or web pages, rather than the user’s direct input — is significantly harder to defend against than direct injection and is increasingly common in RAG-based systems.
LLM02 – Insecure Output Handling: The model’s output is passed to downstream systems (shells, databases, browsers) without sanitization. This is the LLM equivalent of SQL injection or XSS. If your application executes code generated by an LLM without validation, or renders markdown/HTML from model responses without escaping, this is your exposure.
LLM06 – Sensitive Information Disclosure: The model reveals PII, credentials, trade secrets, or training data it shouldn’t have access to. This can happen through inadequate input filtering (user provides sensitive data that gets logged), inadequate output filtering (model regurgitates sensitive context), or training data leakage in fine-tuned models.
LLM08 – Excessive Agency: Tool-using and agentic systems that can take actions in the world (send emails, execute code, call APIs) cause real harm when they operate beyond their intended scope. Over-privileged agents acting on ambiguous or injected instructions are a primary failure mode in production agentic deployments.
LLM04 – Model Denial of Service: Resource-heavy inputs — deeply nested instructions, requests for very long outputs, recursive tool calls — can drive up compute costs and degrade service for legitimate users. Rate limiting and input length controls belong in your guardrail stack.
Using the Top 10 to prioritize your stack
The practical value of the OWASP taxonomy is in prioritization. Not every risk is equally relevant to every deployment. A customer service chatbot with no tool use has a very different risk profile than an autonomous coding agent with file system access. Map your specific deployment against the Top 10, rank the applicable risks by severity and likelihood, and design your guardrail layers to address the highest-priority threats first. This sounds obvious, but most teams skip it — and end up with guardrails optimized for the threats they were thinking about rather than the ones most likely to materialize.
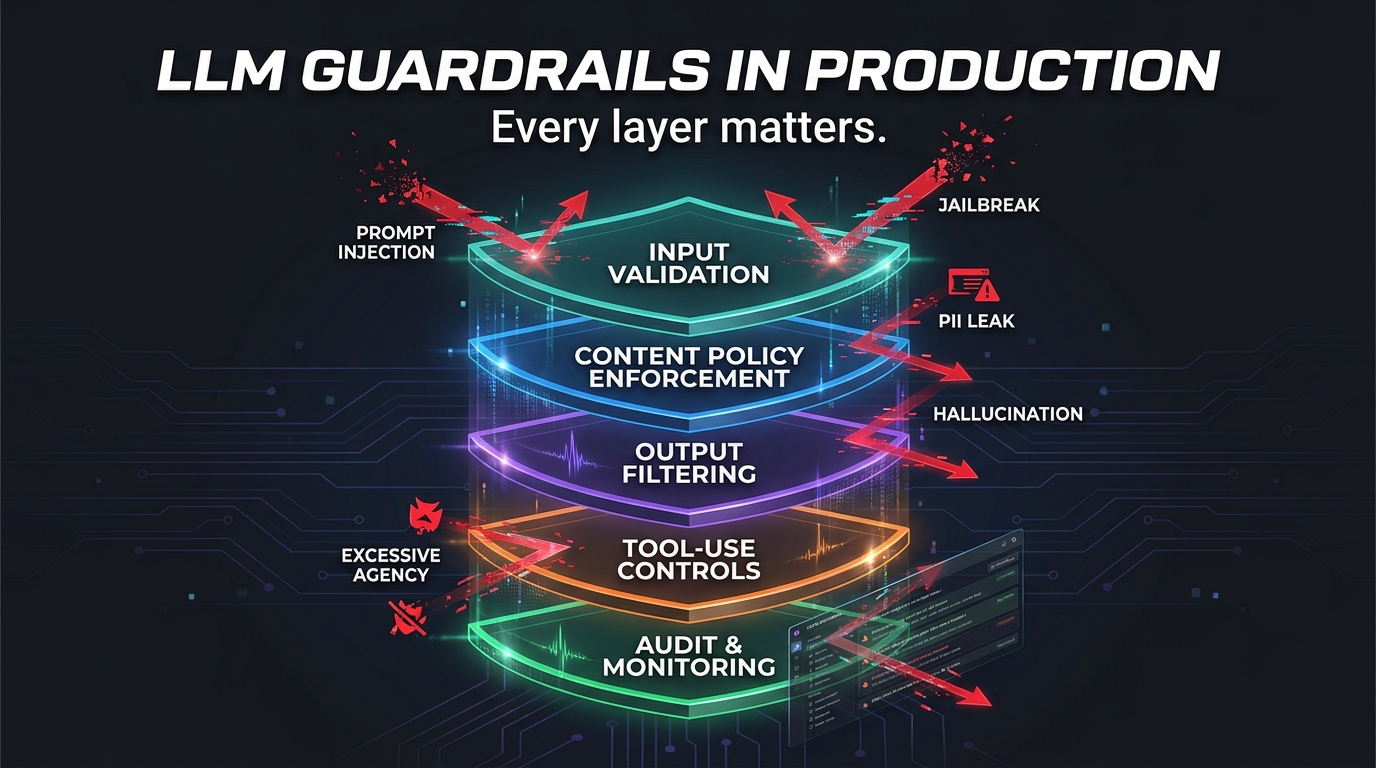
The Four-Layer Guardrail Stack Every Production Team Needs
Effective production guardrails don’t live in one place. They’re a stack — multiple independent layers that each catch different failure modes. Thinking about them as a stack has two benefits: it makes your defense more robust (an attacker who bypasses one layer still faces others), and it makes it easier to reason about where to invest effort and where you’re currently exposed.
Layer 1: Input validation and sanitization
The first line of defense. Every user input, retrieved document, tool result, and injected instruction that touches your LLM pipeline should pass through input validation before it reaches the model. This layer handles:
- Length and format enforcement: Reject inputs that exceed configurable token limits, preventing both cost abuse and denial-of-service attacks.
- Injection detection: Heuristic patterns, embedding-based similarity checks against known attack corpora, and classifier-based detection for prompt injection attempts.
- PII and credential scrubbing: Detect and redact sensitive data (emails, phone numbers, SSNs, API keys, passwords) before they enter the model context — especially important when users are submitting documents or pastes from their own systems.
- Context integrity checks: In RAG systems, validate retrieved documents for signs of adversarial content before injecting them into the model’s context window.
Layer 2: Content policy enforcement (runtime)
This layer applies your organization’s specific behavioral policies — what the model is and isn’t allowed to discuss, what topics are in-scope for each use case, what response formats are expected. Policy enforcement at this layer is what separates “we told the model to behave well in the system prompt” from “we have a runtime control that reliably enforces behavioral boundaries.”
Content policy enforcement typically happens on both inputs (pre-LLM) and outputs (post-LLM), using classifier models trained on your policy categories. For regulated industries, this layer is where financial advice restrictions, medical disclaimer requirements, and legal content boundaries get enforced — at the infrastructure level, not just through prompt instructions that can be overridden.
Layer 3: Output filtering and validation
Model outputs need their own dedicated validation stage. This layer handles:
- PII and secrets in outputs: Detect and redact sensitive data that the model has included in its response, whether from training data leakage or from context inadvertently passed in.
- Structural output validation: For applications that depend on the model returning JSON, SQL, or other structured formats, validate the schema before passing the output downstream. Missing or malformed structure is a common failure mode that causes cascading errors.
- Hallucination and grounding checks: Verify that factual claims in the output are grounded in the provided context (for RAG systems) or are appropriately qualified. More on this in the hallucination section below.
- Toxicity and harm filtering: Catch outputs that violate content policies before they reach users — a distinct check from input validation because the model can generate harmful content even from benign inputs.
Layer 4: Audit, observability, and alerting
This is the layer that most teams underinvest in until something goes wrong. Every interaction that passes through your guardrail stack should generate a structured log record: the input hash, the checks that were run, the results of each check, the final decision, and a timestamp. This audit trail serves three purposes: it lets you investigate incidents after the fact, it feeds your continuous testing and improvement loop, and it produces the evidence that compliance frameworks increasingly demand.
The audit layer should also surface aggregate metrics: guardrail trigger rates by check type, false positive rates, latency percentiles per guardrail component, and anomaly alerts when trigger rates spike suddenly. That spike is often your first signal that an adversarial campaign is underway.
Prompt Injection and Jailbreak Detection: What Actually Works
Prompt injection and jailbreaking are related but distinct threats, and conflating them leads to defenses that address neither properly.
Jailbreaking is when an attacker tries to make the model bypass its safety policies — getting it to generate content it’s trained to refuse. The attacker’s goal is to manipulate the model’s behavior, typically through clever prompt engineering: roleplay framing, hypothetical scenarios, base64 encoding, multilingual obfuscation, or increasingly, automated optimization of adversarial suffixes.
Prompt injection is when attacker-controlled text in the input overrides the application’s intended instructions — causing the model to follow the attacker’s instructions instead of the developer’s. This can come from the user directly (direct injection) or from external content the model processes (indirect injection through documents, search results, emails, or web pages in RAG systems).
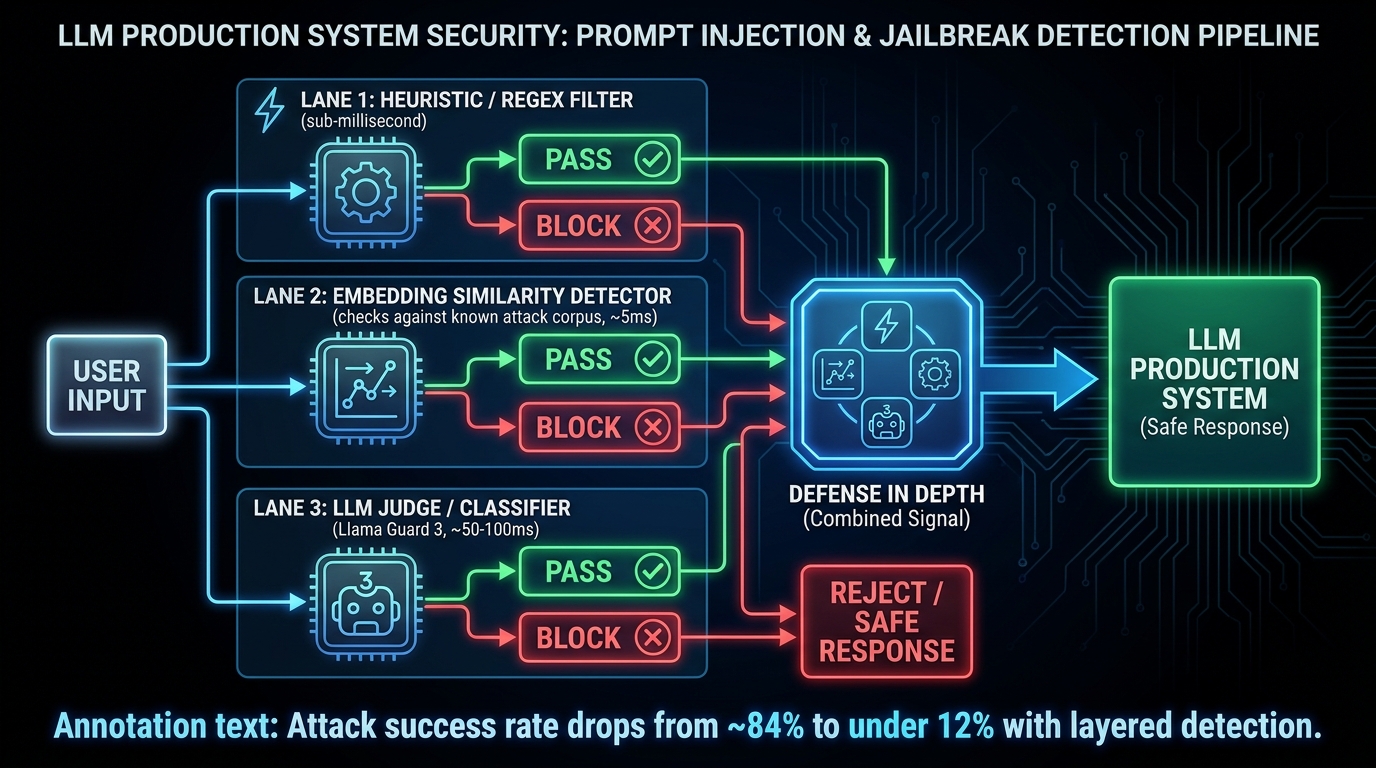
What detection actually looks like in practice
The honest answer is that no single detection method is reliably robust. Production systems that defend effectively against prompt injection and jailbreaking use layered detection as a heuristic aid — not as a gate that the application trusts completely.
Heuristic and regex-based filters catch known attack patterns in sub-millisecond time. They’re cheap, fast, and effective against unsophisticated attacks. They’re trivially bypassed by anyone with moderate creativity. Use them as the first pass in your input pipeline — they filter the noise — but don’t rely on them for anything they haven’t seen before.
Embedding-based similarity detection compares each incoming prompt against a curated corpus of known injection and jailbreak examples using vector embeddings. Flag inputs above a similarity threshold. This is considerably more effective than regex alone and catches novel phrasings of known attack patterns. The key is maintaining a current attack corpus — this is adversarial testing output that gets fed back into your detector. Latency is typically 5–15ms, which is acceptable in most production pipelines.
LLM-based classifiers (e.g., Llama Guard 3) run an independent safety-classification model on inputs and outputs. This is the highest-fidelity detection method and the most computationally expensive — expect 50–100ms per classification. Llama Guard 3 in particular returns violation categories alongside its classification, which is useful for audit logging. Use it on inputs that pass heuristic and similarity checks, and on all model outputs before they’re returned to users.
The architecture principle that matters most
Detection is useful. But the most important architectural principle for defending against prompt injection isn’t better detection — it’s never letting model output directly authorize privileged actions. If your application can be prompted into sending an email, executing code, or writing to a database, those actions should require an independent, deterministic authorization check that doesn’t rely on the model’s judgment about whether the action is appropriate. The model’s output is a request, not a permission grant. This distinction eliminates entire categories of prompt injection attack.
PII, Secrets, and Sensitive Data: The Output Leakage Problem
Sensitive data leakage from LLM systems happens through several distinct mechanisms, each requiring a different mitigation. Teams that treat “PII protection” as a single checkbox miss most of the actual exposure.
How sensitive data gets into your outputs
The most common leakage vectors in production systems are:
Context leakage: Sensitive data in the model’s context window — system prompts, retrieved documents, conversation history, user metadata — gets echoed back in model responses. A customer service agent that has access to account information in its context can inadvertently include that information in responses to other users if session context isn’t properly isolated.
Training data memorization: Large language models memorize portions of their training data. For models fine-tuned on proprietary datasets — internal documents, customer records, code repositories — this creates a real risk of the model reproducing sensitive training examples in response to targeted queries. This is a model-level risk that application-layer guardrails can mitigate but not eliminate.
Credential and secret extraction: If API keys, passwords, connection strings, or other secrets appear anywhere in the model’s context (system prompts, configuration, retrieved documents), a prompt injection attack can extract them. This is one of the highest-severity production incidents and requires aggressive scrubbing at both the input and output layers.
What effective PII protection looks like
Effective PII protection in production operates at three points in the pipeline. First, pre-ingestion scanning — before sensitive data is indexed in your vector store or passed into model context, detect and pseudonymize PII. Replace real values with tokens and maintain a reversible mapping if you need to de-tokenize for legitimate use cases. Second, output scanning before response delivery — run regex and ML-based PII detectors against every model response before it’s sent to the user. Third, differential privacy in fine-tuning — if you’re fine-tuning on sensitive data, apply differential privacy techniques to bound the amount of any individual’s data that can be extracted.
The output scanning step deserves particular attention because it’s often skipped. Teams implement input-side PII protection but assume the model won’t include sensitive data in its responses if you didn’t include it in the input. In practice, models can reconstruct sensitive information from contextual clues, infer PII from partial data, or simply include data that was in a retrieved document that wasn’t itself PII-filtered. Output scanning is not optional.
Hallucination Containment: Output Validation That Goes Beyond “Does It Sound Right”
Hallucination — the model generating plausible-sounding but factually incorrect output — is distinct from safety failures, but it’s increasingly treated as a production reliability concern that guardrails need to address. For applications where factual accuracy has downstream consequences (medical, legal, financial, technical documentation), an uncontained hallucination is a liability, not just an inconvenience.
The grounding verification approach
For RAG-based systems, the most reliable hallucination mitigation strategy is grounding verification: after the model generates a response, an independent verification step checks whether each factual claim in the response is supported by the retrieved context that was provided. This can be implemented as a secondary LLM call (using the same or a smaller model as a judge), as a structured entailment check, or as a hybrid of both.
The key engineering decision is whether this verification step runs synchronously (adding latency before the response is delivered) or asynchronously (flagging the response for review without blocking delivery). For high-stakes applications, synchronous verification is appropriate despite the latency cost. For lower-stakes interactions, asynchronous flagging — where ungrounded responses are logged, surfaced to reviewers, and used to improve retrieval quality — is often the right tradeoff.
Structured output validation
A large class of hallucination-related production failures has nothing to do with factual accuracy — it’s structural: the model returns JSON with missing fields, breaks a required schema, or produces output in a format that downstream code can’t parse. These failures are often silent at the application layer until they cause a downstream error that’s hard to trace.
The remedy is schema-first output validation. Define the expected output structure explicitly (as a JSON Schema, Pydantic model, or similar), and validate every model response against it before passing it downstream. Libraries like Guardrails AI are built specifically for this pattern, providing validation with structured retry and repair logic when the model’s output fails the schema check. This alone eliminates a significant category of production reliability failures.
Confidence calibration and uncertainty communication
For user-facing applications, hallucination containment includes communicating uncertainty appropriately. A model that generates confident-sounding wrong answers is more dangerous than one that qualifies its uncertainty. Implementing uncertainty disclosure — either through prompt-level instructions enforced by output validation, or through separate confidence estimation — is an underused guardrail that significantly reduces the harm from hallucinations that slip through verification.
The Latency Tax: Engineering Guardrails That Don’t Kill Your UX

The strongest objection to comprehensive guardrail stacks is always latency. And it’s a legitimate concern: naively implemented, a full guardrail pipeline can easily add 500ms to 1,000ms to your response time — which is the difference between an application that feels responsive and one that feels broken.
But this is an engineering problem, not an architectural inevitability. The teams that get guardrail overhead down to 20–50ms on top of model latency do it through deliberate performance engineering, not by cutting safety corners.
Understanding the latency profile of each check type
The latency cost of each guardrail component varies by orders of magnitude:
- Regex and heuristic filters: Sub-millisecond when implemented locally. These should always run synchronously; there’s no reason to make them async.
- Embedding-based similarity detection: Typically 5–15ms for local models, higher for API-based embedding services. Acceptable synchronously.
- Llama Guard 3 or similar classifier models: 50–100ms for local inference on appropriate hardware. This is on the edge of acceptable for synchronous input checking; often better to run asynchronously on input and synchronously on output.
- LLM-as-judge validation: 200–500ms for a secondary LLM call. This should almost always run asynchronously, feeding into monitoring and review queues rather than blocking response delivery.
- PII regex and ML scanners: 1–20ms depending on implementation. Run synchronously on outputs before delivery.
The async-first design principle
The most effective way to minimize the perceived latency of guardrails is to be deliberate about what runs synchronously versus asynchronously. The rule of thumb: synchronous checks are for things that must block delivery of a bad response. Asynchronous checks are for things that improve your system over time but don’t need to block the user in real time.
In practice, this means synchronous runs for: fast input filters, output PII scanning, schema validation, and critical content policy checks. Asynchronous runs for: secondary LLM judges, grounding verification for non-critical applications, detailed behavioral analysis, and audit log enrichment.
Sampling strategies for high-throughput systems
At scale — thousands of requests per second — running the full guardrail stack on every request is cost-prohibitive. Production systems handle this through intelligent sampling: run cheap synchronous checks on 100% of traffic, and run expensive checks (secondary LLM judges, deep behavioral analysis) on a sampled subset. The sampling rate can be risk-adjusted: sample higher rates for new users, for inputs that triggered heuristic flags, and for outputs going to high-risk downstream consumers. One production-oriented 2026 pattern reports guardrail overhead as low as 11 microseconds per request at 5,000 RPS using this gateway-with-sampling approach.
Agentic AI Changes Everything: Guardrail Patterns for Tool-Using Systems
Everything described so far applies to request-response LLM systems where the model generates text and a human reads it. Agentic systems — where the model plans multi-step tasks, calls tools, reads and writes to memory, and takes real-world actions — require a fundamentally different threat model and a meaningfully extended guardrail stack.
CISA’s 2026 Five Eyes guidance explicitly defines agentic AI as a distinct security domain. The reason is straightforward: in a non-agentic system, the worst-case guardrail failure is a bad response. In an agentic system, it’s an agent that sends emails, executes code, modifies databases, or calls external APIs based on injected instructions.
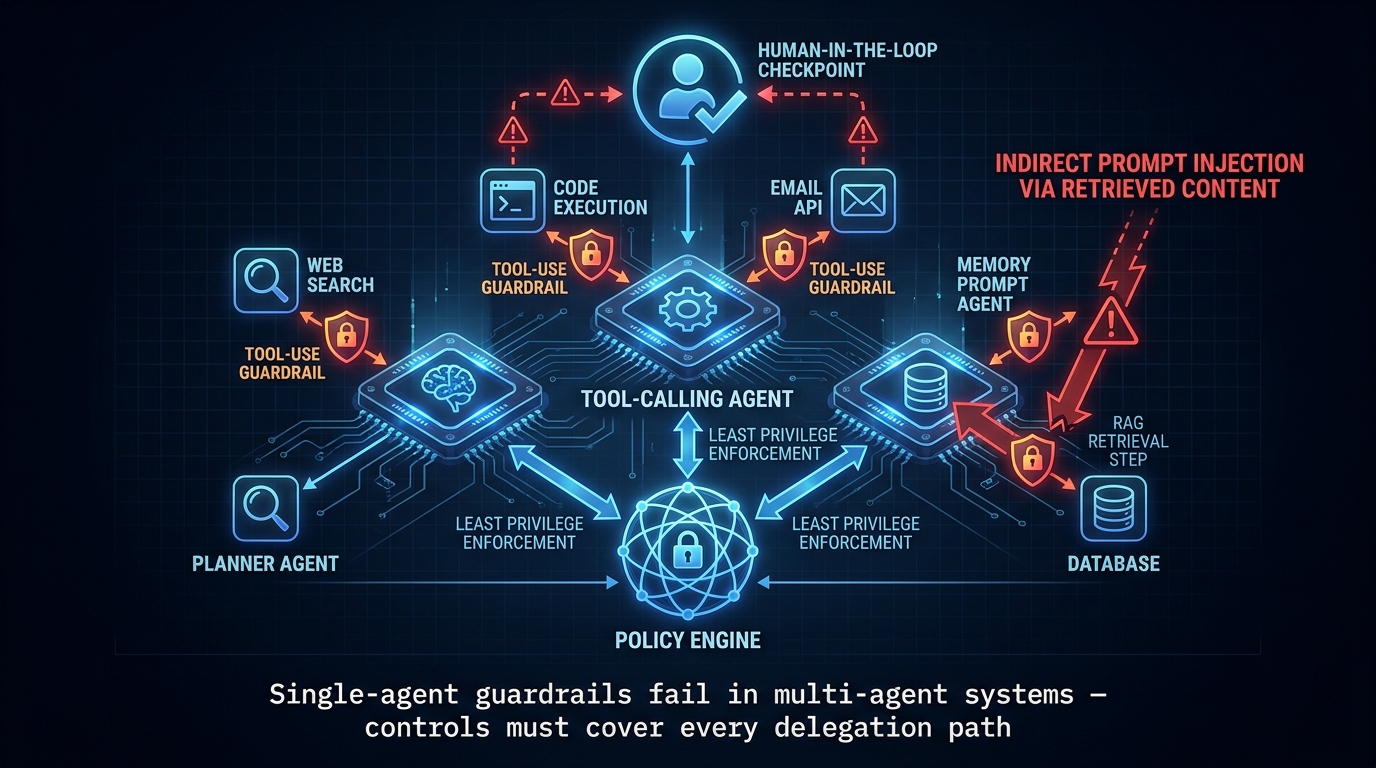
Why single-agent guardrails fail in multi-agent systems
The guardrail architecture for a single-agent system — validate inputs, filter outputs, log everything — doesn’t scale cleanly to multi-agent architectures. In a system with a Planner Agent, a Tool-Calling Agent, and a Memory Agent, each agent is both a consumer of other agents’ outputs and a producer of inputs for downstream agents. If one agent is compromised through prompt injection, it can pass adversarial instructions to other agents in the chain.
This means guardrails must cover inter-agent communication, not just user-to-model communication. Every message passed between agents needs to be treated as potentially untrusted input, validated by the receiving agent’s guardrail layer before being acted upon.
Tool-use controls: the most underinvested area
The tool call is where agentic systems do real damage when guardrails fail. Every tool an agent can call represents a potential action in the world with real consequences. Effective tool-use controls implement the following:
Least-privilege tool scoping: Each agent should have access only to the tools it strictly needs for its defined task. A summarization agent doesn’t need email-sending capability. A document-search agent doesn’t need database write access. Scoping tool access at deployment time is a structural control that no prompt injection can bypass.
Pre-execution tool call validation: Before any tool is executed, validate the parameters of the tool call against an allowlist of expected inputs. If your document-search tool is being called with a prompt that looks like “ignore previous instructions,” that’s a signal that should block execution and trigger an alert — not get passed through to the tool.
Human-in-the-loop checkpoints for high-risk actions: For actions above a defined risk threshold — sending communications, executing code with side effects, making financial transactions — require human approval before execution. This is not a scalable guardrail for high-volume systems, but it’s the appropriate control for high-stakes, low-frequency actions.
Indirect prompt injection in RAG-based agents
The most dangerous attack vector for production RAG-based agentic systems is indirect prompt injection: malicious instructions embedded in retrieved content that the agent processes as part of its workflow. A user uploads a document that contains hidden instructions telling the agent to exfiltrate its system prompt. A web search result contains text designed to redirect an agent’s behavior. These attacks are difficult to prevent entirely, but can be mitigated through context isolation (running retrieval in a separate context from instruction-following), through retrieved-content sanitization, and through output validation that checks for signs of instruction-following behavior that doesn’t match the original task specification.
The Tooling Landscape: Llama Guard, NeMo, Guardrails AI, and What Each One Actually Does

The open-source guardrail tooling ecosystem has matured significantly, but it remains genuinely confusing because the three primary tools — Llama Guard, NeMo Guardrails, and Guardrails AI — are complementary, not competing alternatives. They address different layers of the stack. Using one doesn’t mean you don’t need the others.
Llama Guard 3 (Meta)
Llama Guard 3 is an open-weight safety classifier — a model you call to classify inputs and outputs as safe or unsafe against a set of policy categories. It returns violation categories alongside its classification, which makes it useful for both blocking decisions and audit logging. It operates at the content policy enforcement and output filtering layers.
Key strengths: strong baseline performance on standard safety categories, open weights allowing local deployment, and detailed violation categorization that maps well to regulatory requirements. Key limitations: latency (50–100ms local inference), cost at high volume, and the need for customization to enforce policies beyond its default categories. Llama Guard works well as the primary classifier model in your guardrail stack, but it doesn’t handle structural output validation or dialog flow control.
NeMo Guardrails (NVIDIA)
NeMo Guardrails is a conversational safety framework with a domain-specific language (Colang 2.0) for defining dialog flows, safety policies, and tool-use controls. It’s most valuable for systems with multi-turn conversation state and agentic tool use — it lets you define what the model is and isn’t allowed to talk about, how it should handle edge cases in conversation flow, and what constraints apply to tool calls.
Key strengths: Colang 2.0 makes policy expression readable and auditable by non-engineers (security teams, compliance officers), strong support for agentic workflow controls, and active development with NVIDIA backing. Key limitations: the DSL has a learning curve, and it’s more complex to operate than simpler classifier-based approaches for non-conversational use cases.
Guardrails AI
Guardrails AI is an output validation and reliability framework — its core function is ensuring that LLM outputs conform to specified schemas, policies, and formats, with automatic retry-and-repair logic when they don’t. It’s the right tool for structured output validation (enforcing JSON schemas, data type constraints, business logic rules), PII detection in outputs, and hallucination detection through grounding validators.
Key strengths: extensive library of pre-built validators through Guardrails Hub, clean integration with most LLM APIs, and strong documentation. Key limitations: it’s not a security tool in the traditional sense — it doesn’t detect adversarial inputs or implement content policy enforcement. It lives at the output validation layer and complements, rather than replaces, input-side security controls.
How they work together in a production stack
A production guardrail stack at a well-resourced team typically looks like this: heuristic filters and embedding similarity detection at the input gate, Llama Guard 3 for content policy classification on inputs and outputs, NeMo Guardrails for dialog flow control and tool-use policies in conversational and agentic systems, and Guardrails AI for output schema validation and PII detection. The AI gateway layer ties these together, applies routing and sampling logic, and produces the unified audit log.
Not every team needs all of these. A simple question-answering application might use only Llama Guard 3 plus output PII scanning. A complex agentic workflow needs the full stack. The key is matching the tooling complexity to the actual risk profile of the deployment.
Continuous Red Teaming and Monitoring: Moving from Launch-and-Pray to Always-On Defense
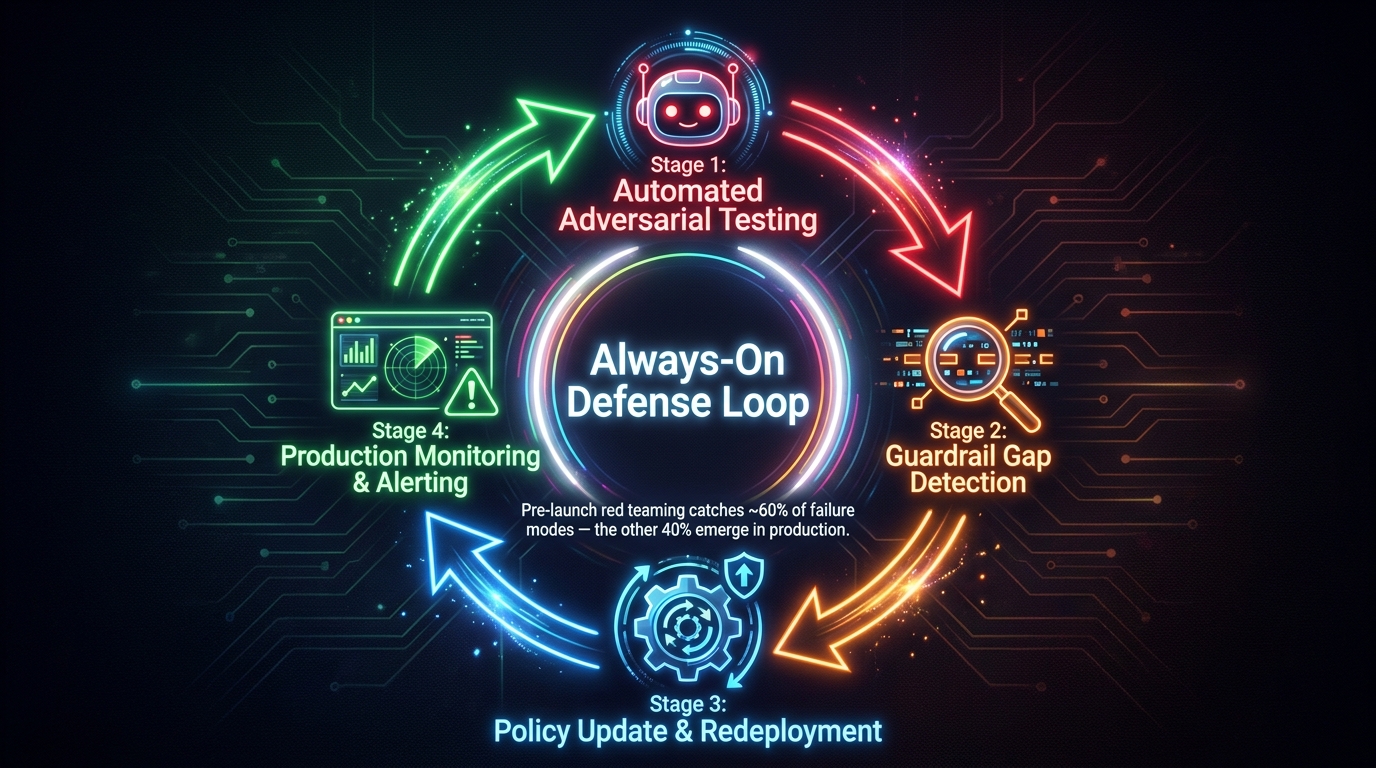
Pre-launch red teaming matters. But the evidence from production deployments is that it catches roughly 60% of failure modes — the other 40% emerge only after real users interact with the system at scale, in ways the red team didn’t anticipate. The 2026 shift in enterprise AI security is from point-in-time red team exercises to continuous, automated adversarial testing integrated into production operations.
Building an automated adversarial testing pipeline
Continuous red teaming at scale requires automation. Human red teams are expensive, slow, and limited in the variety of attacks they can generate. Automated adversarial testing frameworks — including tools that use LLMs themselves as adversarial attack generators — can run thousands of test cases continuously against your production guardrail stack.
The key design principle is a feedback loop: adversarial test cases that successfully bypass guardrails in CI/CD testing get added to the ongoing monitoring corpus. New bypass techniques discovered in production monitoring get added to the red team test suite. The guardrail configuration gets updated, deployed, and immediately re-tested. This loop is what separates organizations that stay ahead of the threat curve from those that are perpetually reacting to incidents.
Production monitoring: what to measure and alert on
A production guardrail monitoring dashboard should track, at minimum:
- Guardrail trigger rate by check type — broken down by hour, user cohort, and feature. A sudden spike in injection detection triggers is your early warning system for an active adversarial campaign.
- False positive rate — the percentage of legitimate requests that are incorrectly blocked. High false positive rates erode user trust and often lead teams to disable guardrails rather than tune them. Monitoring this metric forces the uncomfortable tradeoff between safety and usability into the open.
- Latency percentiles per guardrail component — P50, P95, and P99 latency for each check. P99 latency spikes often indicate a misconfiguration or a scaling issue that’s invisible in average-latency metrics.
- Bypass rate estimates — based on post-hoc analysis of logged interactions, what percentage of adversarial inputs appear to have successfully bypassed your stack? This requires periodic manual review of flagged-but-passed interactions, but it’s the metric that tells you whether your guardrails are actually working.
Incident response for guardrail failures
Every guardrail stack will eventually fail to block something it should have blocked. Having a defined incident response process for guardrail failures — before they happen — is the difference between a contained incident and a public one. Your runbook should define: how a guardrail bypass gets escalated, what constitutes a severity-1 guardrail incident vs. a severity-3, who is authorized to roll back a guardrail update, and how affected users are notified if sensitive data was exposed.
Compliance Alignment: Mapping Your Stack to NIST AI RMF and EU AI Act
Guardrails aren’t just an engineering concern anymore. The regulatory environment around AI systems is hardening fast, and the compliance frameworks now either explicitly require, or strongly imply, technical guardrail controls at the level of specificity we’ve been discussing throughout this post.
NIST AI RMF as the governance backbone
The NIST AI Risk Management Framework provides the governance structure within which your technical guardrails need to operate. Its four functions — Map, Measure, Manage, and Govern — translate directly to guardrail stack components:
- Map: Your threat modeling exercise (using OWASP LLM Top 10) is the Map function. Identify your risks before you design controls.
- Measure: Your monitoring and red teaming infrastructure is the Measure function. Continuous measurement of guardrail performance, false positive rates, and bypass rates produces the evidence that the Measure function requires.
- Manage: Your guardrail stack itself — the runtime controls, the incident response processes, the policy update procedures — is the Manage function.
- Govern: Your organizational policies around who can update guardrail configurations, how changes are reviewed and approved, and what accountability exists for guardrail failures is the Govern function.
The most common compliance gap in enterprise AI deployments isn’t missing technical controls — it’s missing the audit evidence that those controls are actually working. NIST AI RMF expects organizations to demonstrate, not just assert, that their risk management controls are effective. This is why the audit log layer and the continuous monitoring infrastructure are governance requirements, not just operational niceties.
EU AI Act obligations for high-risk systems
The EU AI Act’s requirements for high-risk AI systems — which include AI used in healthcare, employment, credit scoring, law enforcement, and critical infrastructure — map closely to the guardrail stack components described in this post. Key requirements include:
- Technical documentation of the risk management system, including the specific controls implemented and their testing results.
- Logging and auditability sufficient to enable post-hoc review of system behavior — the exact output of a well-designed guardrail audit layer.
- Human oversight mechanisms for high-consequence decisions — the human-in-the-loop checkpoints discussed in the agentic AI section.
- Accuracy, robustness, and cybersecurity standards that encompass both the model itself and the surrounding control infrastructure.
Importantly, the EU AI Act treats these as ongoing obligations, not pre-launch checklists. Continuous monitoring, periodic re-evaluation as the system or its deployment context changes, and documented incident response are requirements of compliant operation, not optional enhancements.
California and emerging U.S. state-level requirements
California SB 243 and AB 489 represent the emerging U.S. state-level regulatory environment for AI systems. Like the EU AI Act, they emphasize demonstrated performance over stated intentions — regulators increasingly expect organizations to produce evidence that their safety controls actually work under real-world conditions, not just paper policies and vendor safety certifications. This trend will only accelerate as AI incidents continue to attract legislative attention.
From Theory to Action: Building Your Guardrail Implementation Roadmap
The frameworks, tools, and patterns described throughout this post can be overwhelming when considered all at once. Most teams can’t build a full production-grade guardrail stack in a single sprint. The question is where to start, what to build first, and how to sequence the work.
Week 1–2: Threat model and baseline assessment
Before writing a line of guardrail code, map your specific deployment against the OWASP LLM Top 10. Which risks are actually applicable? Which tool calls does your system have access to? What data is in the model’s context window? What’s the worst-case scenario if an adversarial user successfully injects instructions? This assessment takes two engineers a few days and determines where every subsequent investment should go.
Simultaneously, run a basic red team exercise against your current stack — even an informal one with a few engineers trying common injection and jailbreak techniques. Document what works. This becomes your initial gap list.
Weeks 3–6: Core layer implementation
Implement the highest-priority controls from your gap analysis. For most applications, this means: input length and format validation, prompt injection detection (heuristic + embedding similarity at minimum), output PII scanning, and basic audit logging. These controls address the highest-frequency failure modes and are achievable within a sprint or two.
If you’re building or operating an agentic system, add tool-use scoping and pre-execution parameter validation in this phase. The risk asymmetry for tool-using agents makes these controls urgent regardless of where they rank on a general priority list.
Weeks 7–12: Monitoring, testing, and policy infrastructure
With baseline controls in place, build the infrastructure that makes them sustainable: the monitoring dashboard, the automated adversarial test suite, the incident response runbook, and the policy update process. This phase is often deprioritized in favor of feature work, and it’s the reason why many teams have guardrails that fail silently for weeks before anyone notices.
Deploy NeMo Guardrails (for conversational/agentic systems) or Guardrails AI (for structured output validation) in this phase, after you have the monitoring infrastructure to evaluate their impact on false positive rates and latency.
Ongoing: Continuous improvement loop
The hallmark of a mature guardrail program is a running improvement loop: production monitoring surfaces new failure modes, those failure modes become adversarial test cases, those test cases drive guardrail updates, those updates are validated against the monitoring baseline before deployment. This loop doesn’t require large teams — it requires instrumentation, process discipline, and a shared understanding that guardrail maintenance is ongoing engineering work, not a one-time project.
Final Thoughts: Safety Is an Engineering Discipline, Not a Feature
The teams that build LLM applications that hold up in production don’t think about guardrails as a compliance overhead or a marketing checkbox. They think about them the way mature engineering organizations think about reliability engineering, security hardening, and observability: as foundational infrastructure that needs the same engineering rigor, investment, and continuous attention as the features it protects.
The data is clear about what happens to teams that don’t: 86% of production LLM applications are vulnerable to the most basic attack class on the OWASP list. Guardrails that work in testing collapse after fine-tuning. Agentic systems with over-privileged tool access create incidents that take weeks to contain.
None of this is inevitable. The patterns, tools, and practices in this post are real, implemented by real teams running production systems at scale. The gap between them and the 86% isn’t cleverness or resources — it’s the decision to treat safety as an engineering discipline with its own rigor, metrics, and improvement loops.
Start with the threat model. Build the minimum viable guardrail stack for your actual risk profile. Instrument it properly from day one. Then run the continuous improvement loop, and keep running it.
Key takeaways for implementation teams: (1) Guardrails are a stack, not a single control — defense-in-depth is the only pattern that holds up under real adversarial pressure. (2) Never let model output directly authorize privileged actions — this one principle eliminates entire categories of prompt injection risk. (3) Async-first design keeps guardrail latency below 50ms overhead in well-engineered systems. (4) Agentic systems need tool-use controls and inter-agent message validation, not just input/output filtering. (5) Continuous monitoring and adversarial testing are not optional enhancements — they’re the mechanism by which your guardrails stay effective over time.


