Imagine an AI agent that looks perfectly healthy. Its error rate is near zero. Its latency is stable. Your monitoring dashboard is a wall of green. And yet, over the past six weeks, it has been quietly making decisions that diverge from what you actually intended — routing edge cases the wrong way, consulting a stale knowledge base, applying a deprecated approval policy, and calling a tool whose behavior changed in a recent API update.
Nobody noticed. The agent didn’t crash. It didn’t hallucinate in any obvious way. It just drifted — and it took a downstream compliance review, a customer complaint, or a financial reconciliation error to surface what the dashboards never caught.
This is the defining operational challenge of agentic AI in 2026. As organizations move from single-step LLM calls to multi-agent, multi-tool autonomous workflows that touch real systems and real decisions, the concept of “is it working?” becomes dangerously inadequate. The question that actually matters is is it still doing what it was designed to do, the way it was designed to do it? That requires an audit — not a performance review, not a red-team exercise, but a structured, repeatable examination of workflow-level drift.
This post lays out exactly how to conduct one. We’ll cover what drift actually means in the context of agentic systems (it’s much more specific than model drift), the six distinct drift types that accumulate silently in production, the warning signals that appear before a full-blown failure, and a five-phase audit framework you can start using today. We’ll also cover the toolchain that makes continuous auditing practical and the architectural choices that make agents more auditable by design.
Why “Model Drift” Is the Wrong Frame for Agentic Systems
The machine learning community has spent years refining the concept of model drift — the statistical divergence between the distribution of data a model was trained on and the distribution it encounters in production. Techniques like Population Stability Index (PSI), Kullback–Leibler divergence, and feature drift monitoring are well-established. For a classification model or a regression pipeline, these techniques are genuinely useful.
But AI agents are not classifiers. They are orchestrators — systems that combine an LLM reasoning core with external tools, retrieval systems, memory stores, policy rules, and API integrations to complete multi-step tasks. When an agent drifts, the failure often has nothing to do with the underlying model at all. The model weights haven’t changed. The training data distribution is irrelevant. What changed was the world around the model.
The Fundamental Difference
A traditional ML model is a function: input goes in, prediction comes out. Monitoring means watching whether the function’s inputs and outputs stay statistically consistent over time. An AI agent is a process: the agent reads context, forms a plan, calls tools, interprets results, updates its reasoning, and takes action — potentially across dozens of steps, with branching logic and environmental side effects at each one.
Model drift monitoring watches the function. Agent workflow auditing watches the process. These are not the same thing, and conflating them is precisely why so many enterprise teams have production agents they believe are healthy but that are actually operating in a degraded state.
Why Existing Monitoring Misses It
Most enterprise observability stacks are built around infrastructure metrics: latency, error rates, token usage, API call volume. These tell you whether an agent is running, not whether it is reasoning correctly. An agent can be fast, cheap, and error-free while systematically using outdated context, skipping validation steps it was designed to perform, or escalating decisions it should be resolving autonomously — and vice versa.
Research published in early 2026 quantifies the gap: approximately 91% of deployed ML models degrade in performance over time in production without active behavioral monitoring. For agentic systems, the figure is likely higher, because they have more surfaces through which divergence can enter. Yet the monitoring practices in most organizations haven’t caught up to the architecture they’re actually deploying.
“The hardest failure mode to detect is the one where the agent is completing its task but completing the wrong version of it. Everything looks fine until someone asks whether ‘fine’ was actually what we wanted.”
The Six Drift Types That Accumulate Silently
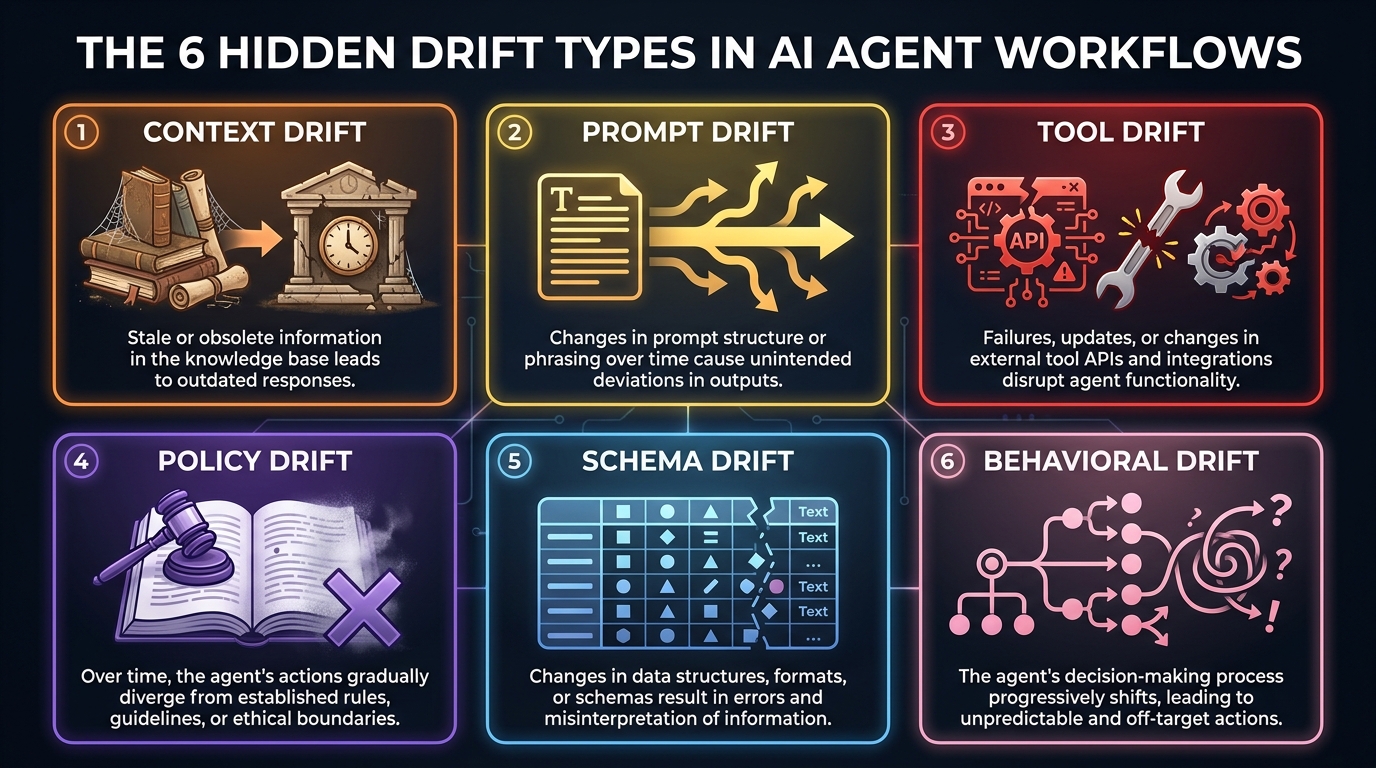
Workflow drift in agentic systems is not a single phenomenon. It is a family of related failure modes, each with a distinct origin, a distinct signature in your traces, and a distinct remediation path. Understanding which type you’re dealing with is the difference between a surgical fix and a week of guesswork.
1. Context Drift
Context drift occurs when the information layer an agent reads from becomes stale, incomplete, or misaligned with current reality. This is arguably the most common drift type in RAG-powered agents. The vector store or knowledge base was indexed at a point in time. Products changed. Policies were updated. Org charts shifted. But the retrieval system still returns the old documents — confidently, at high similarity scores — and the agent reasons from them as though they were current.
Context drift is particularly dangerous because it creates authoritative-sounding outputs based on incorrect premises. The agent doesn’t know the context is stale. It has no mechanism to detect that the document it’s citing was superseded two months ago. The errors it produces look like correct reasoning applied to a world that no longer exists.
2. Prompt Drift
Prompt drift is what happens when system prompts, few-shot examples, or template logic change incrementally over time — through hotfixes, feature additions, A/B test remnants, or simple accumulated editing — until the active prompt no longer matches the original specification. This is a software versioning problem masquerading as an AI problem.
In fast-moving engineering teams, prompts are often treated as informal configuration rather than code. They get modified in production without formal review. A guardrail clause gets softened to “fix” a user complaint. A formatting instruction gets added that subtly changes how the agent structures its outputs. An example gets updated without considering its effect on the agent’s inference behavior. None of these changes individually seem significant. Collectively, they can shift the agent’s effective behavior profile substantially.
3. Tool Drift
Agentic systems don’t operate in isolation — they call external tools, APIs, databases, and services. Tool drift occurs when those integrations change their behavior without the agent being updated to account for it. An API changes its response schema. A search tool’s ranking algorithm is updated. An internal database gains a new mandatory field. A third-party service starts returning results in a different format.
The agent doesn’t know the tool has changed. It parses the new response through the logic it learned for the old one, and the results can range from silently incorrect to visibly broken. Because tool errors often look like data errors, they’re frequently misattributed to model quality problems rather than integration drift.
4. Policy Drift
Policy drift is the divergence between the rules an agent is supposed to follow and the rules it actually follows in practice. This emerges when organizational policies, compliance requirements, or business rules change but the corresponding agent guardrails, escalation thresholds, or decision boundaries aren’t updated in sync. It’s a particularly high-stakes drift type in regulated industries.
An agent in a financial services workflow that was calibrated to escalate decisions above a certain risk threshold may continue operating with the old threshold after risk appetite changes. An agent handling customer data may continue applying a consent logic from a previous version of the privacy policy. These aren’t model failures — they’re governance failures, and they require governance-level audits to catch.
5. Schema Drift
Schema drift occurs when the data structures an agent reads from or writes to change shape — new fields appear, types change, field names are renamed, required fields become optional — and the agent’s parsing, validation, or output logic doesn’t adapt. This is a classic data engineering problem that becomes more complex when the consumer of the data is an autonomous reasoning system rather than a deterministic parser.
Unlike tool drift, which affects external integrations, schema drift typically affects internal data sources: databases, event streams, data warehouses. An agent that reads customer records to inform recommendations may start receiving records with a new segmentation field that it ignores, missing a signal that would change its outputs. The agent remains functional; it just operates on an impoverished version of the available information.
6. Behavioral Drift
Behavioral drift is the most abstract and the most difficult to detect. It refers to gradual changes in how an agent reasons and decides — its effective “character” — that emerge from the interaction of all the other drift types plus subtle changes in the model’s own behavior due to model updates, fine-tuning adjustments, or inference parameter changes. An agent that was calibrated to be conservative in uncertain situations may become progressively more confident. An agent designed to prefer shorter responses may gradually produce longer, more elaborate outputs.
Behavioral drift is best detected not through metrics but through evaluation: regularly running the agent against a fixed set of reference scenarios and comparing outputs over time. This is a practice that most teams currently neglect.
The Silence Problem: Why Drift Is So Hard to Catch Without an Audit
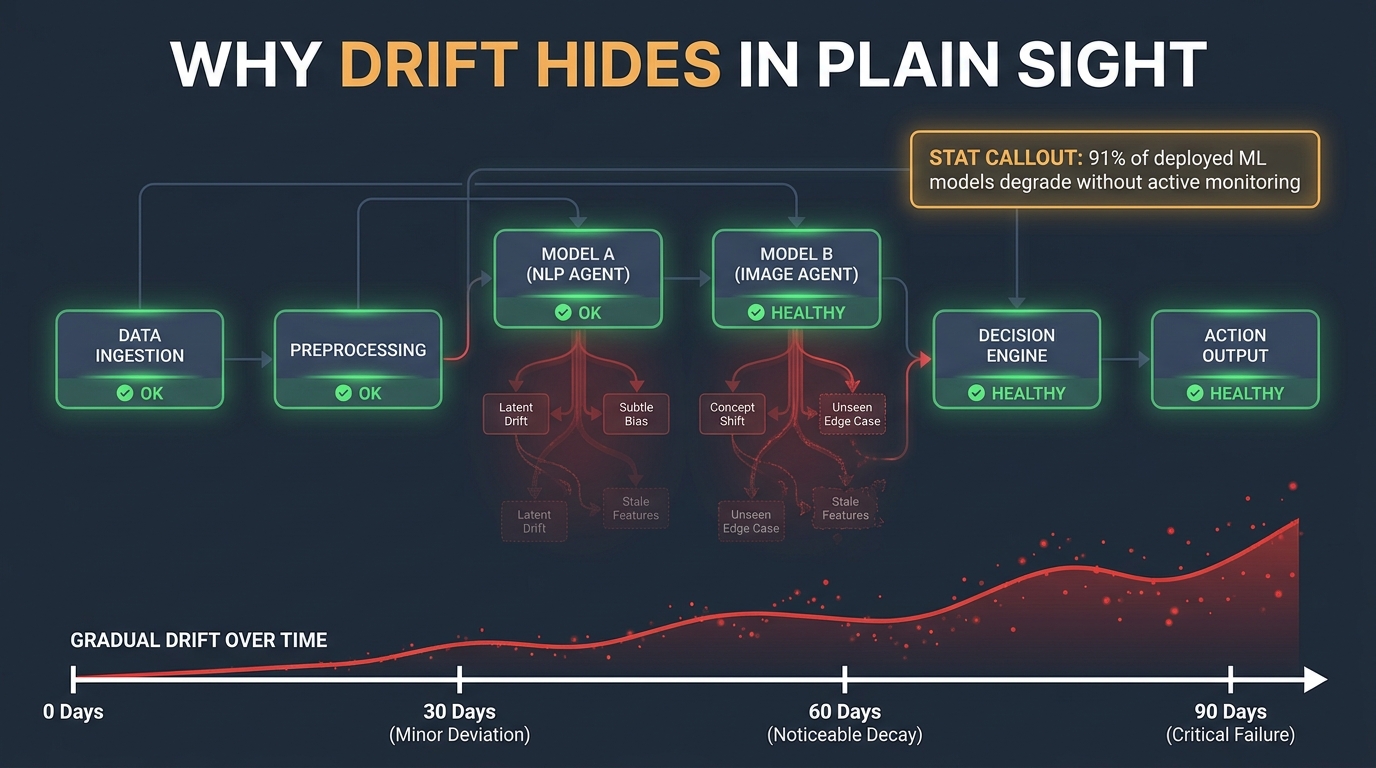
One of the most striking findings from research into agentic AI failures in 2025 and 2026 is how frequently failing agents produce no observable error signals. A March 2026 paper formally defines what researchers call “silent hallucinations” in agentic workflows — internal false beliefs, assumptions, or intermediate representations that never surface in the agent’s output but still drive its actions toward unintended outcomes. The agent produces a coherent, grammatically correct, contextually plausible response. It just happens to be wrong.
The Green Dashboard Problem
Standard infrastructure monitoring was built to detect crashes, timeouts, and exceptions — discrete, detectable failure events. Drift is not a discrete event. It is a continuous, slow divergence. A crashing agent gives you an alert. A drifting agent gives you nothing. Your dashboards stay green. Your SLAs stay met. The only signal is in the quality and intent-alignment of the decisions the agent is making, and that signal requires deliberate measurement to surface.
This creates what practitioners sometimes call the “green dashboard problem”: teams that believe their agents are healthy because their observability stack shows no failures, when in fact what their observability stack is measuring has no bearing on whether the agent is behaving as intended. Error rate and latency are necessary but not sufficient conditions for a healthy agent.
Cascading Failures and Delayed Consequences
In multi-agent architectures, drift in one agent compounds through downstream agents. A classification agent that develops context drift starts feeding subtly wrong categorizations to a routing agent, which passes them to an action agent. No individual agent in the chain fails. But the end-to-end outcome is wrong in ways that can be very difficult to trace back to a root cause without full workflow-level tracing.
The delay between the onset of drift and its business consequences makes the problem worse. An agent handling customer service triage may drift toward misclassifying a certain type of complaint for weeks before the pattern becomes visible in escalation data. By that point, dozens or hundreds of customers have had degraded experiences, and diagnosing the cause requires retrospective trace analysis — expensive, time-consuming, and often incomplete.
The “It Was Always Like That” Trap
One particularly insidious consequence of slow drift is that teams gradually normalize the drifted behavior. New team members join and onboard to the current behavior of the agent, not to its original specification. Documentation becomes outdated. The original design intent exists only in the memory of whoever built the system initially. Over time, the team loses its ability to recognize drift because it has lost its reference point for what “correct” looks like.
Regular audits are, in part, a mechanism for preserving institutional memory. The audit process forces teams to revisit the original design intent, compare it to current behavior, and formally document the gap. Without that forcing function, specification creep becomes the new normal.
Reading the Pre-Failure Signals
Workflow drift does leave traces — they’re just not in the places most teams are looking. Before a full-blown failure surfaces in business outcomes, there are typically several earlier warning signals that a structured audit or continuous monitoring practice can detect. Knowing what to look for changes the economics of the problem significantly: catching drift at the signal stage costs a fraction of what it costs to investigate and remediate it after it has caused damage.
Changes in Tool-Call Patterns
One of the most reliable early drift indicators is a change in the distribution of tool calls an agent makes. If an agent that normally uses Tool A for 60% of a given workflow category starts using Tool B at 40% with no corresponding change in task inputs, something has shifted. Either the agent’s decision logic has changed, or one of the tools has changed its behavior in a way that’s affecting the agent’s tool selection.
Tracking tool-call frequency distributions over time — broken down by workflow category, input type, and time window — gives you a quantitative baseline against which deviation becomes detectable. This doesn’t require sophisticated ML; it requires that you’re logging structured tool-call data in the first place.
Escalation Rate Changes
Agents in production are typically designed with escalation logic: conditions under which the agent defers to a human rather than acting autonomously. Changes in the escalation rate — either spiking (the agent is becoming more uncertain or encountering more edge cases) or declining (the agent is becoming overconfident and not escalating when it should) — are strong signals that something in the agent’s decision landscape has shifted.
A declining escalation rate that isn’t accompanied by a corresponding improvement in autonomous resolution quality is a particularly concerning pattern. It suggests the agent is bypassing safeguards without improving its capability, which is exactly the signature of policy drift or behavioral drift.
Output Quality Degradation
If you’re running any form of human evaluation or automated evaluation scoring on agent outputs, consistency checks across time windows are essential. A drop of even a few percentage points in output quality scores — below what sampling noise would explain — deserves investigation. The same applies to format compliance: if an agent that was reliably producing structured JSON outputs starts occasionally producing prose responses, that’s a prompt drift signal.
Anomalous Permission and Log Patterns
Agents that call APIs or interact with databases leave permission and access logs. If an agent starts accessing resources it doesn’t typically access, or starts making API calls in an order that differs from its normal pattern, that’s worth examining. This is particularly important for detecting tool drift (the agent adapting its behavior in response to changed tool outputs) and for security-relevant cases where unexpected resource access could indicate a compromised or manipulated agent.
The Five-Phase Audit Framework
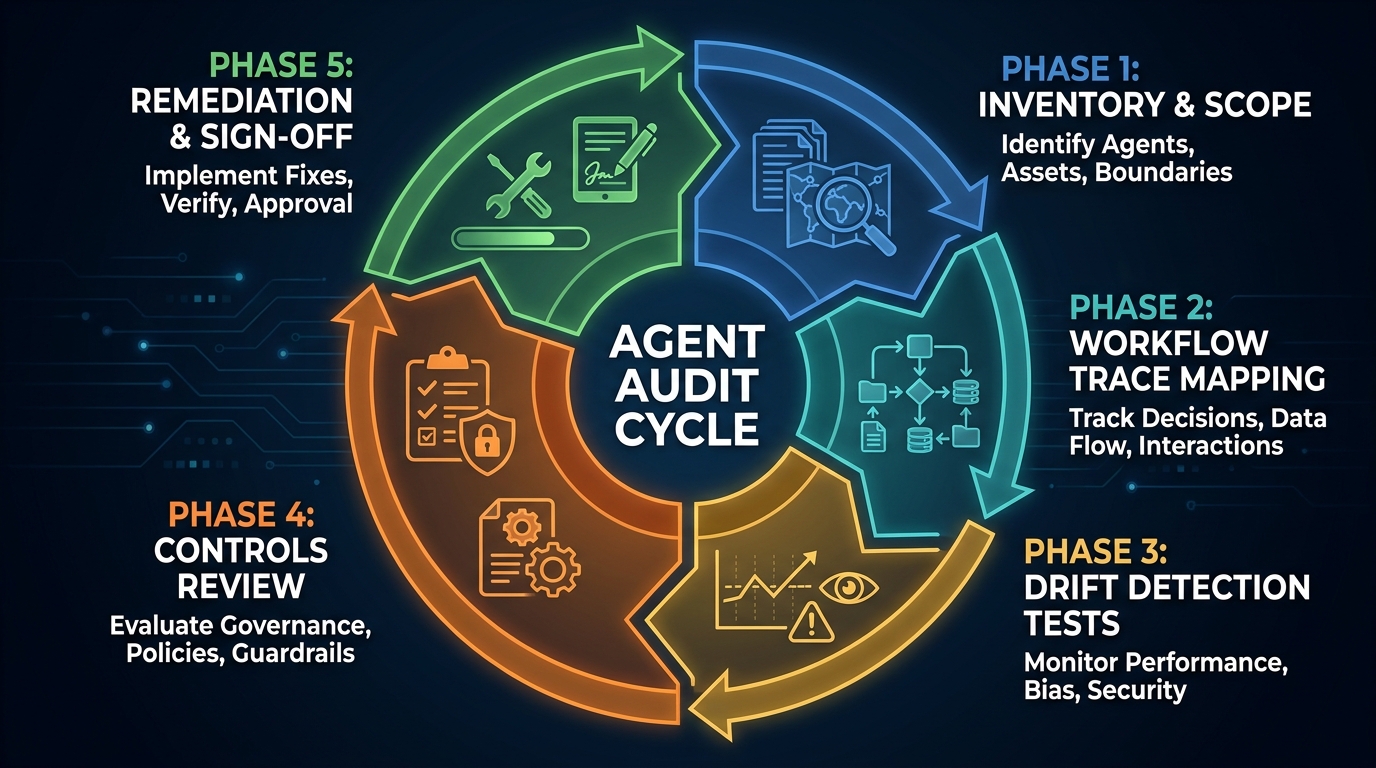
A rigorous agent workflow audit has five phases. Each builds on the previous one, and each is necessary — skipping phases tends to produce audits that either miss the real failure modes or generate so much noise that remediation becomes unmanageable. The full cycle, for a moderately complex agent workflow, should take one to three weeks the first time and become faster on subsequent runs as baselines and tooling are established.
Phase 1: Inventory and Scope
Before you can audit anything, you need a precise, up-to-date inventory of what you’re auditing. For AI agents, this means documenting every agent in scope along with: its original design specification and intended behavior; the model version(s) it uses; every tool, API, and data source it calls; its current prompt and configuration; its deployment date and last significant modification; and its business function and risk classification.
Many teams discover their first serious drift problem during this phase, simply because maintaining this inventory forces them to compare documentation to reality. Prompts that were “temporarily” modified six months ago and never reverted. Tool integrations pointing at deprecated API versions. Agents running on model versions that have since been superseded. The inventory is not a formality — it is the first diagnostic step.
Risk classification is also established in this phase. Not all agents warrant the same audit depth. An agent that generates first-draft emails is lower risk than one that processes financial approvals or makes clinical routing decisions. Tiering the agents by risk determines how deep the subsequent phases go and how frequently the full audit cycle should repeat.
Phase 2: Workflow Trace Mapping
Trace mapping is the process of walking an agent workflow end-to-end and constructing a detailed map of what it actually does — not what the documentation says it does, but what the production traces show. This requires pulling a representative sample of recent execution traces (typically 50–200 runs, depending on workflow complexity and volume) and analyzing them for the actual sequence of steps, tool calls, decision branches, and outputs the agent produced.
Compare the trace map to the design specification. Where do they diverge? Are there execution paths that don’t appear in the spec? Are there specified paths that never appear in production traces? Are tool calls happening in a different order than intended? Are escalation triggers firing in the right conditions?
Trace mapping is where tool drift and schema drift most commonly surface. If the agent is making tool calls that weren’t in the original design, or if tool call responses are being parsed in ways that produce warnings or silent failures, those will appear in the traces. Automated trace analysis tools (covered in the toolchain section) can accelerate this, but a manual review of a sample of traces by someone who knows the original design intent is irreplaceable.
Phase 3: Drift Detection Testing
Having mapped what the agent is doing, the third phase actively tests for each drift type using a defined test suite. The gold standard is a set of reference scenarios — representative inputs with known-correct expected outputs — that were established at deployment time and have been preserved. Running these scenarios against the current agent and comparing outputs to the baseline directly measures behavioral drift.
For context drift, test the retrieval layer independently: given a set of queries that have known correct source documents, is the retrieval system returning those documents, or has index staleness caused it to return outdated alternatives? For prompt drift, compare the current production prompt to the versioned baseline and run a structured diff — both at the text level and at the behavioral level (do reference inputs produce the same outputs with old vs. new prompt?). For policy drift, construct edge cases designed to trigger escalation or constraint logic and verify that they still fire correctly.
Tool drift testing requires testing each tool integration against its current interface specification and confirming the agent’s parsing logic handles current response formats correctly. This is often treated as a software testing problem (because it largely is one) but requires AI-specific considerations around how the agent’s LLM core handles unexpected or changed tool responses.
Phase 4: Controls Review
Phase 4 examines the governance and safety controls around the agent: what guardrails are in place, whether they’re functioning correctly, and whether they’re still appropriate for the current operational context. This is where policy drift and permission scope issues most commonly surface.
The controls review should cover: all hard constraints and soft guardrails in the agent’s configuration; the escalation policy and whether thresholds are still calibrated correctly; the agent’s permission scope (is it accessing only what it needs to access, with least-privilege principles applied?); and the human oversight mechanisms — are the right people receiving escalations, reviewing flagged decisions, and acting on them in a timely way?
For agents in regulated environments, the controls review also includes compliance alignment: does the current agent behavior comply with the relevant regulatory framework as it stands today, not as it stood at deployment time? Regulatory environments evolve, and agents that were compliant at launch may have drifted out of compliance through no fault of their own — simply because the rules changed and nobody updated the agent.
Phase 5: Remediation and Sign-Off
Phase 5 translates audit findings into a prioritized remediation plan and formally closes the audit. Findings are categorized by severity: critical (the agent is producing wrong outputs in ways that have or could cause material harm), major (the agent is operating with meaningful divergence from specification that requires prompt remediation), minor (small drifts that should be addressed in the next development cycle), and informational (documented deviations that are understood and accepted).
Each finding maps to a specific remediation action: prompt update, knowledge base reindex, tool integration patch, policy threshold recalibration, permission scope adjustment, or architectural change. Remediation actions have assigned owners, deadlines, and verification criteria. Sign-off requires that all critical and major findings have been addressed and that the baseline for the next audit cycle has been updated to reflect the current validated state.
The Audit Toolchain: What to Actually Use
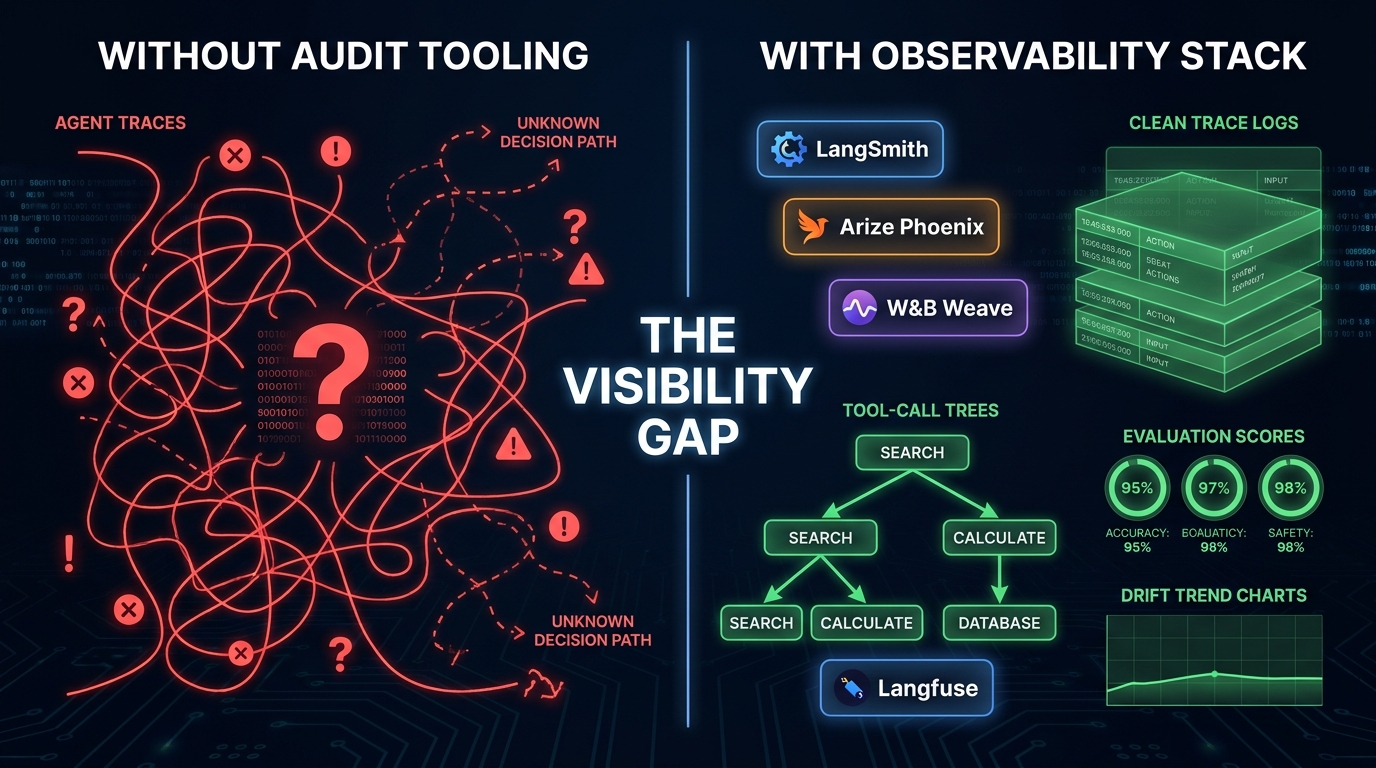
The manual audit framework above works. But it works much better — and becomes sustainable at scale — when it’s supported by the right tooling. The 2026 agent observability landscape has matured enough to provide genuinely useful infrastructure for each phase of the audit. The key is understanding what each tool does well and where it leaves gaps.
Trace Collection and Structured Logging
The foundation of any audit toolchain is comprehensive, structured trace collection. Every agent run should produce a case-level trace ID, a structured event stream capturing each step in the execution, and decision evidence — which model version was used, which prompt version fired, which tool was called with what parameters, which documents were retrieved from which index version.
OpenTelemetry has become the de facto standard for agent trace collection in 2026, with most major agent frameworks providing native or near-native instrumentation. If your agents aren’t producing structured, searchable traces, that is the first infrastructure gap to close before any meaningful audit is possible.
LangSmith
LangSmith, part of the LangChain ecosystem, is purpose-built for tracing and evaluation of LLM applications and agents. Its core strength is the combination of run tracing (full input/output logs for every step in an agent chain), evaluation datasets (you can create and maintain reference scenario sets and run them on demand or on a schedule), and prompt version management. For teams whose agents are built on LangChain or LangGraph, LangSmith provides the tightest integration and the most immediately actionable data.
For audit purposes, LangSmith’s evaluation dataset functionality is particularly relevant to Phase 3. The ability to run a fixed reference dataset against the current agent version and compare results to a historical baseline provides a direct, quantitative measurement of behavioral drift over time.
Arize Phoenix
Arize Phoenix takes a broader approach: it’s an open-source observability platform that integrates with multiple agent frameworks (LangChain, LlamaIndex, custom implementations) and provides both real-time production monitoring and retrospective analysis. Its strength lies in LLM evaluation metrics — response quality, groundedness (is the answer supported by retrieved documents?), and retrieval relevance — which map directly to detecting context drift and output quality degradation.
Phoenix’s combination of embedding-based drift detection and LLM-evaluated quality scoring gives it an advantage for production monitoring between formal audit cycles. Rather than waiting for a quarterly audit to detect that your knowledge base has become stale, Phoenix can surface context drift signals continuously.
Weights & Biases Weave
W&B Weave is the most experiment-oriented of the major options, reflecting W&B’s heritage in ML experiment tracking. Its strength is version control and comparison: tracking exactly which prompt version, model version, and configuration produced which outputs across a large number of runs. For teams that iterate frequently on agent configurations and need to understand the causal impact of each change on agent behavior, Weave provides a level of version-controlled traceability that is difficult to replicate with more general observability tools.
In the context of a workflow audit, Weave is particularly useful for prompt drift investigation: it can show you the exact diff between prompt versions and the corresponding behavioral change in outputs, making it possible to trace behavioral drift back to the specific configuration change that caused it.
Langfuse
Langfuse is an open-source, self-hostable alternative that has gained significant traction in enterprises where data sovereignty and cost control are priorities. It provides trace logging, evaluation, and user feedback collection in a package that can be run entirely within a private cloud environment. For regulated industries — banking, healthcare, defense — where sending trace data to a third-party SaaS platform creates compliance concerns, Langfuse provides a way to maintain audit-grade observability without the data residency risks.
What No Single Tool Covers
One important reality of the current tooling landscape: no single tool covers the full audit surface. Trace collection, evaluation, policy monitoring, and access log analysis typically require at least two to three tools working in combination. The most common pattern in mature teams is a primary observability tool (LangSmith, Phoenix, or Langfuse) for trace collection and evaluation, combined with a broader APM layer for infrastructure-level metrics, plus an access management system for permission and security-relevant log analysis.
The integration between these layers matters as much as the individual tools. An audit that can correlate a behavioral anomaly in the trace layer with a permission scope change in the access log layer in a single investigation workflow is dramatically more efficient than one where these data sources sit in isolated silos.
Building Drift-Resilient Agents: Architecture First
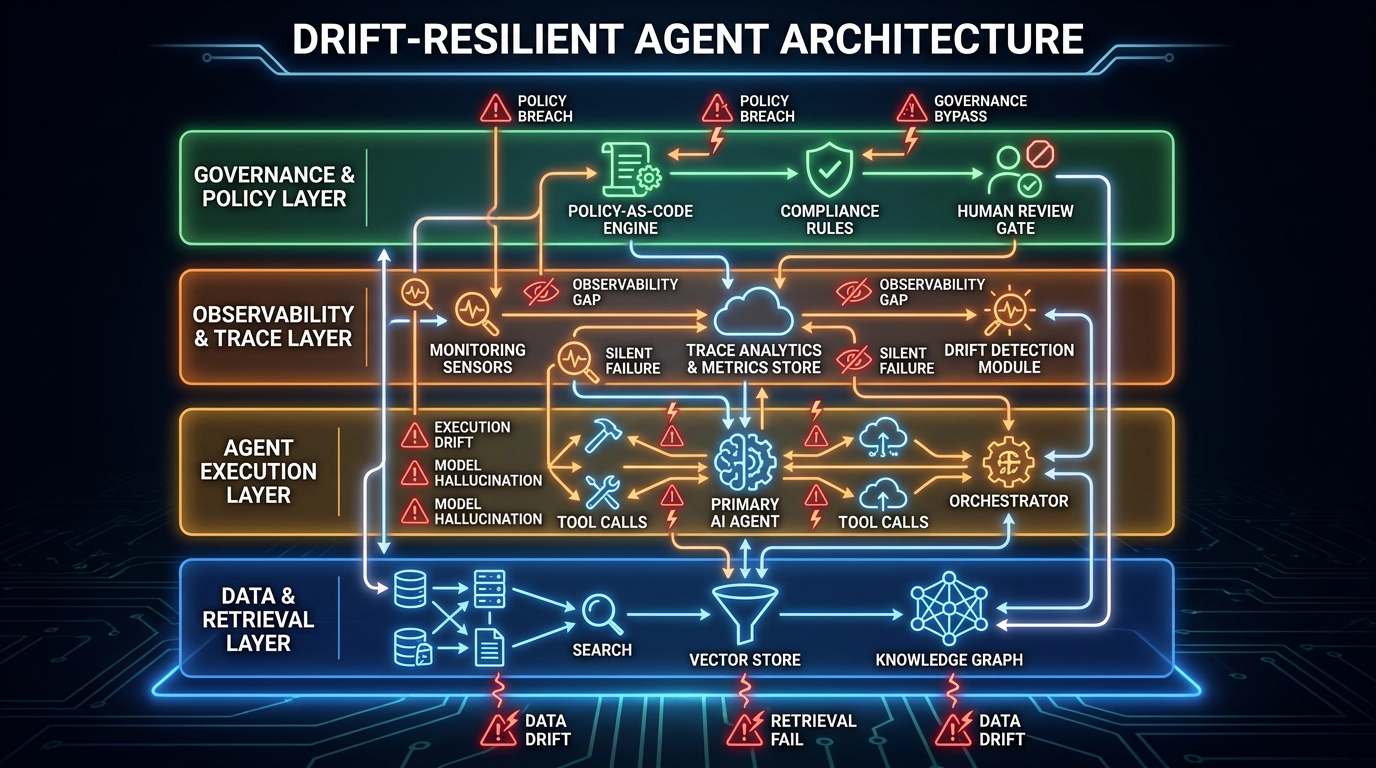
The most efficient place to address workflow drift is in the architecture — before the agent is deployed. Well-designed agents are dramatically easier to audit and dramatically more resistant to certain drift types than poorly designed ones. This doesn’t mean over-engineering; it means making deliberate choices that favor auditability.
Treat Prompts as Code
The single highest-leverage architectural decision for preventing prompt drift is to treat prompts as first-class code artifacts: version-controlled in a repository, reviewed through a pull request process, deployed through a CI/CD pipeline, and rolled back through the same mechanism used to roll back software. This is not how most teams currently manage prompts, but the gap between “prompts in a database” and “prompts in version control with review gates” is the difference between controllable and uncontrollable prompt drift.
Prompt versioning should include the full prompt template, any few-shot examples, the model parameters (temperature, top-p, etc.), and the expected behavioral specification. When a prompt is changed, the change should be accompanied by a regression test against the reference evaluation set before deployment to production.
Version and Validate Your Context Sources
Every knowledge base, document store, or retrieval index that an agent reads from should be versioned and monitored for staleness. Practically, this means maintaining a metadata layer that tracks when each document in your index was last validated as current, and building processes for refreshing the index on a defined schedule or in response to source document changes.
For high-stakes agents, consider adding an explicit context validation step: before the agent uses retrieved documents in its reasoning, a lightweight verification process checks whether the documents are above a freshness threshold and whether they come from authoritative sources. Documents that fail validation can be flagged or excluded rather than silently passed to the agent as reliable context.
Define Explicit Schema Contracts
Every tool integration and data source that an agent interacts with should have an explicit, documented schema contract. When the underlying tool or data source changes its schema, that change should be caught by a contract test before it reaches the production agent. This is a standard data engineering practice (contract testing frameworks like Pact are well-established) that is frequently neglected in the context of AI agent development.
Schema contracts also make tool drift audits dramatically faster. Instead of inferring what the tool’s expected behavior is from historical traces, you have a formal specification to test against.
Design for Safe Pause
Every production AI agent should have a well-defined, tested “safe pause” mechanism — a way to stop the agent’s autonomous operation and route it to human review when drift detection signals or safety thresholds are exceeded. The design of this mechanism should be a first-class engineering concern, not an afterthought.
Safe pause mechanisms work best when they are granular: pausing a specific workflow category rather than all agent activity, notifying the right people with enough context to make an informed decision, and providing a clear path back to autonomous operation once the issue is resolved. Agents that can only be stopped by killing the process are not safe-pause-ready, no matter how good their monitoring is.
Policy as Code
For agents operating in compliance-sensitive environments, policy-as-code frameworks (such as Open Policy Agent, or custom policy engines) provide a way to encode business rules, regulatory constraints, and escalation thresholds as versioned, testable artifacts rather than as ad hoc instructions buried in system prompts. When the policy changes, the policy code changes — in version control, with review, with automated tests. This directly addresses policy drift by making policy changes explicit, deliberate, and auditable rather than implicit and gradual.
When to Audit: Cadence, Triggers, and the Continuous Monitoring Bridge
One of the most common questions teams ask when they adopt a formal audit practice is: how often? The honest answer is that the right cadence depends on the risk profile of the agent, the rate of change in its environment, and the maturity of your continuous monitoring infrastructure.
Risk-Tiered Cadence
A practical starting framework ties audit frequency to the risk tier established in Phase 1 of the audit framework. High-risk agents — those making decisions with direct financial, clinical, legal, or compliance consequences — should undergo a full audit cycle every four to eight weeks. Medium-risk agents, handling significant but reversible business processes, warrant quarterly audits. Lower-risk agents operating in well-bounded, low-consequence workflows can be audited semi-annually, with continuous monitoring providing coverage between cycles.
These aren’t absolute rules — they’re starting points. An agent that operates in a rapidly changing environment (volatile data sources, frequent tool updates, evolving regulatory requirements) should be audited more frequently regardless of its base risk tier. An agent with strong continuous monitoring in place that surfaces no anomaly signals can extend its cycle modestly.
Event-Triggered Audits
Beyond scheduled cadence, certain events should trigger an immediate out-of-cycle audit regardless of when the last scheduled audit occurred. These include: significant model version updates by the underlying LLM provider; major changes to any tool or API integration the agent depends on; relevant regulatory or policy changes in the agent’s operational domain; discovery of a material error or incident attributable to agent behavior; and any substantial change to the agent’s system prompt, configuration, or tool set.
Having a documented list of trigger events and a clear process for initiating an expedited audit is as important as having a scheduled cadence. Most organizations that catch drift early do so through triggered audits, not scheduled ones — because drift rarely waits for the next quarterly review.
Continuous Monitoring as the Bridge
Formal audit cycles, however well-designed, have gaps. Between a quarterly audit in January and the next one in April, an agent can drift significantly if the only detection mechanism is the next scheduled audit. Continuous monitoring bridges those gaps by watching the drift-signal indicators described earlier — tool-call distribution changes, escalation rate anomalies, output quality shifts — in real time and alerting when signals exceed defined thresholds.
Think of continuous monitoring and periodic audits as complementary, not competing. Monitoring surfaces the signals that trigger investigations. Audits provide the deep, structured investigation capability to diagnose, understand, and remediate what monitoring surfaces. Organizations that have monitoring without audits have good detection but weak diagnosis. Organizations that have audits without monitoring have excellent periodic snapshots with blind spots between them. Both are necessary for a genuinely robust operational posture.
The Governance Layer: Making Audits Stick Organizationally
Technical frameworks and tooling are necessary but not sufficient. Workflow drift audits become durable organizational practices only when they have the governance structures to back them up — ownership, accountability, process integration, and escalation paths that work in practice, not just on paper.
Defining Ownership
The most common reason audit practices fail to take root is ambiguous ownership. In many organizations, AI agents are built by engineering teams, overseen by product managers, and governed by compliance and risk teams — and none of these groups fully owns the operational health of the agent in production. Drift audits require someone who owns the question: is this agent doing what it was designed to do?
In practice, this usually means establishing the role of an AI agent owner or agent steward for each production agent above a defined risk threshold. This person is responsible for maintaining the design specification, scheduling and owning the audit cycle, reviewing audit findings, and signing off on remediation. They don’t need to be the one running the technical phases — that work can be distributed — but the responsibility needs to be clearly assigned.
Integrating Audits into Change Management
Many of the drift types described in this post originate from changes that happen outside the AI agent’s immediate codebase: tool API updates, data source schema changes, model version releases, policy changes. Catching these before they cause drift requires that the audit process is integrated with the change management processes in adjacent systems.
Concretely, this means: adding an AI impact assessment to the change request process for any tool, API, or data source that agent-critical systems depend on; requiring that model version updates trigger an agent regression test before the update propagates to production; and building in a notification workflow so that the agent owner is alerted when any of the agent’s dependencies changes.
Audit Records as Institutional Memory
Each audit cycle should produce a formal audit record: the scope, the methodology used, the findings, the remediations, and the updated baseline. These records serve a function beyond compliance documentation — they are the institutional memory that prevents teams from losing their reference point for intended agent behavior over time.
Audit records also provide the longitudinal data needed to identify patterns. If the same agent produces a context drift finding in three consecutive audits despite remediation, that’s a signal that the remediation isn’t addressing the root cause — perhaps the knowledge base indexing cadence is fundamentally too slow for the rate of change in the underlying sources. The pattern only becomes visible if the records are maintained and reviewed.
Escalation That Actually Works
Governance structures live or die by their escalation paths. When an audit surfaces a critical finding — an agent that is systematically producing incorrect outputs in a high-risk domain — there needs to be a clear, practiced escalation process that results in the agent being paused, corrected, and restored to operation in a defined time frame, with appropriate stakeholder communication at each step.
In organizations where this process hasn’t been tested before a real incident, it almost always fails under pressure. The right time to discover that your agent escalation process doesn’t actually work is not during a live compliance event or a customer-impacting incident. Running tabletop exercises against hypothetical critical findings — before you actually have a critical finding — is a simple practice that most organizations skip and most organizations eventually regret skipping.
Building the Audit Habit: Where to Start
If your organization has deployed AI agents in production and hasn’t yet established a formal audit practice, the gap between where you are and where this post describes can feel large. It doesn’t have to be closed all at once. The most effective approach is to start with the highest-risk agent in your production environment and run the five-phase audit against it manually, even if the tooling isn’t yet in place. The findings from that first audit will teach you more about your specific drift exposure than any amount of theoretical preparation.
From that first audit, you’ll know which drift types are most prevalent in your environment, which phases of the audit framework require the most work, and which tooling investments would have the highest leverage. That knowledge shapes your roadmap more accurately than building a complete audit infrastructure before you’ve seen what you’re actually dealing with.
The goal, ultimately, is not to run audits — it’s to build agents you can trust over time. Audits are the mechanism for that trust. They’re the practice of looking clearly at what your agents are actually doing, comparing it honestly to what you intended them to do, and closing the gap with discipline and rigor. In a world where AI agents are taking on consequential work in real organizations, that practice isn’t optional. It’s the baseline of responsible operation.
Conclusion: The Operational Maturity AI Agents Actually Require
The conversation about AI agents in 2026 has largely moved past “can these systems work?” to “how do we keep them working the way we intend?” That’s a meaningful shift — it reflects a growing organizational understanding that deploying an agent is not a one-time event but an ongoing operational commitment.
Workflow drift is the mechanism by which that commitment gets eroded. It happens slowly, silently, and across multiple dimensions simultaneously: stale context, changed tools, evolved policies, accumulated prompt modifications, schema mismatches, and gradual behavioral shifts that compound into meaningful divergence from design intent. None of these individually look like a crisis. Together, they represent the difference between an AI agent that does what you built it to do and one that used to.
The good news is that workflow drift is detectable, preventable, and remediable — but only with the right practices in place. The five-phase audit framework, supported by the right tooling and backed by genuine organizational governance, gives you a systematic way to maintain control of agentic systems that are otherwise inherently prone to silent divergence.
Key Takeaways
- Reframe your mental model: Audit agent workflows, not just model performance. The divergence that matters most often has nothing to do with the underlying model.
- Know your six drift types: Context, prompt, tool, policy, schema, and behavioral drift each require different detection methods and different remediations.
- Watch the pre-failure signals: Tool-call distribution changes, escalation rate anomalies, and output quality shifts are early drift indicators that appear before business-level failures.
- Run the five phases in order: Inventory and scope, trace mapping, drift detection testing, controls review, and remediation and sign-off. Don’t skip the controls review — it’s where the governance-level failures live.
- Match your toolchain to your needs: LangSmith, Arize Phoenix, W&B Weave, and Langfuse each have distinct strengths. The right choice depends on your framework, your data residency requirements, and whether your primary need is evaluation or real-time monitoring.
- Build auditability in from the start: Prompts as code, versioned context sources, schema contracts, safe-pause mechanisms, and policy-as-code are architectural choices that make agents dramatically easier to audit and maintain.
- Pair continuous monitoring with periodic audits: Neither alone is sufficient. Monitoring catches the signals; audits provide the diagnosis. Both are necessary.
- Assign clear ownership: The AI agent owner role is the single most important governance investment you can make. Ambiguous ownership is where audit practices go to die.
The organizations that will get the most durable value from agentic AI are not necessarily the ones that deploy the most agents. They’re the ones that build the operational discipline to understand what their agents are actually doing — and maintain that understanding over time.