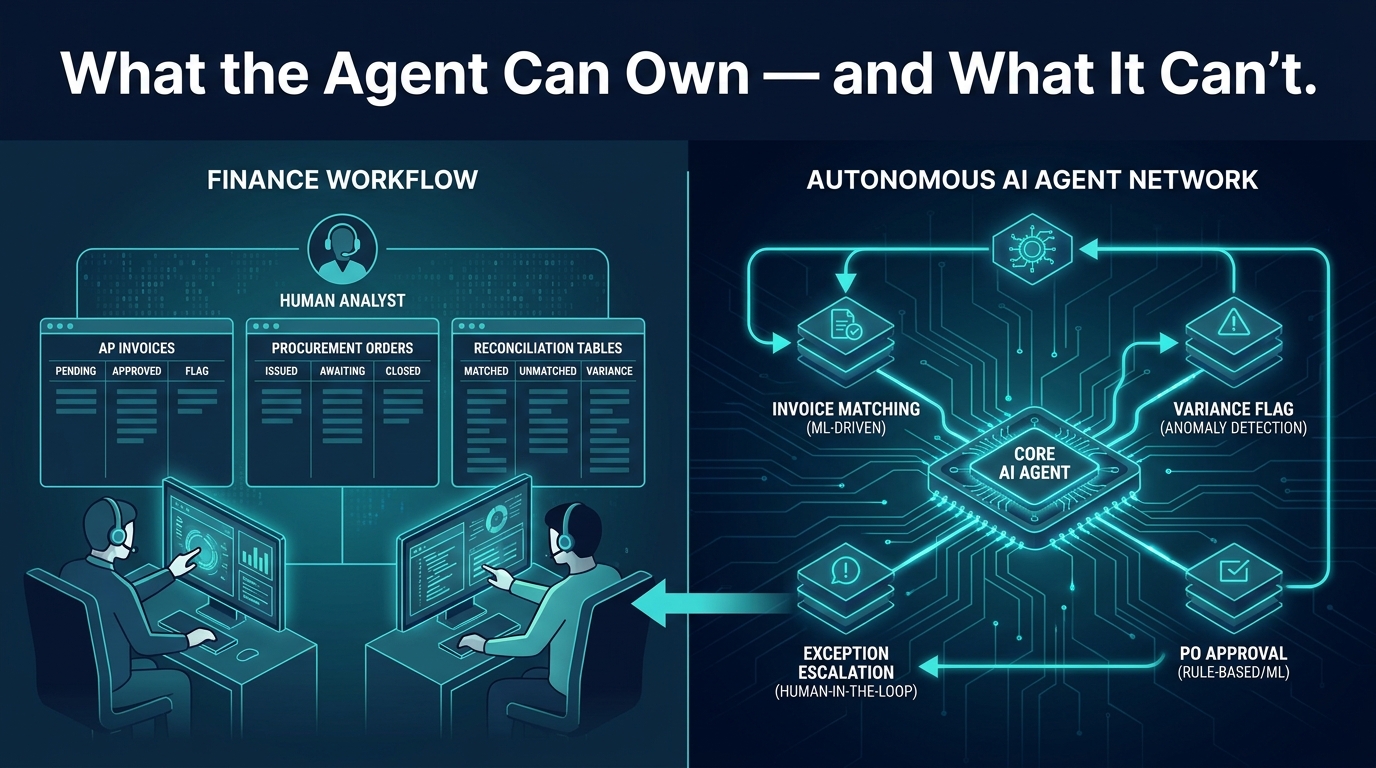

Most conversations about agentic AI in finance start with the wrong question. They ask: “How much can we automate?” The question that actually separates teams who deploy successfully from teams who spend twelve months in pilot purgatory is different: “Where exactly does this agent’s judgment end and ours begin?”
That boundary — the judgment line — is the only thing that matters when you are moving an autonomous AI agent into a process that touches cash, compliance, or contractual obligation. Get it right, and you compress your month-end close from twelve days to three. You cut AP processing labor by 70–80%. You run continuous vendor risk monitoring without adding headcount. Get it wrong, and you create a system that posts journal entries no auditor can attribute, flags fraud it cannot explain, and routes payments your controller never approved.
This post is a practitioner’s map of that judgment line. It is not a general overview of agentic AI, a definition piece, or a vendor comparison. It is a process-level playbook: which finance and ops workflows are genuinely ready for agent autonomy in 2026, which are not, how to design the escalation architecture that sits between them, and — critically — in what order to wire everything up so that each phase proves value before you move to the next.
The data here comes from across the field: KPMG’s 2026 finance agent benchmarks, Forrester’s AP automation guidance, McKinsey supply chain findings, Berkeley CMR’s Agentic Operating Model framework, and PCAOB’s amended standards on AI-touched internal controls — effective for fiscal years beginning on or after December 15, 2026. Where specific company deployments are referenced, they are named. Where aggregate statistics are cited, their source is noted.
If you are a CFO, COO, VP of Finance, or a finance ops lead trying to move from proof-of-concept to something your controller and your auditors can actually live with, this is the map you need.
The Judgment Boundary Problem: Why “Just Automate It” Keeps Failing
There is a persistent misconception embedded in how most finance automation projects get scoped: the idea that intelligence and execution are the same thing, and that if an AI can understand an invoice, it can process it without restriction. This conflation is responsible for most of the failures that keep finance AI pilots from reaching production.
Traditional automation — RPA, rule-based workflow tools, BPM platforms — was bounded by explicit rules. You could audit exactly which logic triggered which action. Agentic AI is categorically different. These systems reason across multiple data sources, plan multi-step sequences, and take actions in live enterprise systems — ERPs, payment rails, vendor portals — without a human initiating each step. That capability is genuinely powerful. It is also what makes the judgment boundary so critical to define upfront.
What “Agentic” Actually Means in a Finance Context
An agentic AI system in finance is not a better chatbot. It is a goal-directed execution layer. Given an objective — “process all invoices under $5,000 with valid POs” — it will autonomously ingest, validate, match, code, and route those invoices to payment without a human touching each one. It will handle exceptions it recognizes, flag exceptions it does not, and log every step with structured reasoning traces.
The key distinction from traditional AI is the action loop. A standard AI model reads an invoice and tells you its category. An agentic system reads the invoice, queries the ERP to confirm the PO exists, checks the contract database for price tolerance, confirms the three-way match, and either posts the entry or routes it to a reviewer — all in one automated sequence. That loop is where the ROI comes from. It is also where the risk accumulates if the judgment boundary is not set correctly.
The Three Failure Patterns That Keep Finance AI in Pilot Mode
FP&A Trends’ April 2026 analysis identified three recurring failure patterns that keep finance AI stuck in pilots rather than reaching production at scale:
- Fragmented data and system silos. Agents need a coherent “data spine” — a reliable, governed connection between ERP, GL, banking feeds, contract repositories, and procurement systems. Most enterprise finance stacks are not there yet. An agent operating on incomplete or siloed data does not just underperform; it makes confident errors, which is worse than making no decision at all.
- Change-management resistance and unclear ownership. Finance teams that have spent years building expertise in reconciliation, coding, and close processes do not naturally hand those workflows to an autonomous system. If the CFO has not explicitly defined who owns the agent’s outputs — and who is accountable when it makes a mistake — adoption stalls at the manager level.
- An undefined AI-human handshake. This is the judgment boundary problem made operational. If no one has specified exactly which conditions trigger a human review and what that human is expected to do in response, the agent either escalates everything (negating the automation value) or escalates nothing (creating control gaps your auditors will find).
The teams that avoid these failure patterns share one common trait: they design the human handshake before they deploy the agent, not after. The rest of this playbook is built around that principle.
The Four-Layer Anatomy of a Finance and Ops AI Agent
Before mapping specific workflows, it helps to have a precise structural model of what a finance agent actually consists of. Berkeley CMR’s March 2026 framework proposes a four-layer Agentic Operating Model that translates well to finance and ops contexts.
Layer 1: The Cognitive Layer
This is the reasoning engine — typically a large language model or specialized domain model that interprets documents, understands context, and plans action sequences. In finance, this layer handles document intelligence (reading invoices, POs, contracts, remittance advices), natural language understanding (parsing vendor emails, interpreting policy language), and reasoning (deciding whether a $12,000 invoice with a $10,000 PO ceiling constitutes a policy exception or a price-increase clause activation).
The cognitive layer is where most organizations over-invest their attention. Model capability matters, but it is rarely the binding constraint in finance deployments. Data quality and governance are almost always the binding constraints.
Layer 2: The Coordination Layer
This layer manages multi-agent orchestration — the sequencing of specialized sub-agents that work in parallel or in series. A purchase-to-pay workflow might involve a document-ingestion agent, a three-way-match agent, a policy-compliance agent, and a payment-scheduling agent running in coordinated sequence. The coordination layer ensures they share state, pass context correctly, and do not double-process or miss handoffs.
For finance ops specifically, the coordination layer is also where you define the agent’s system access: which ERP modules it can read, which it can write to, and under what conditions. These access boundaries are not just a security consideration — they are a materiality control. An agent that can read the GL but cannot post to it without a human approval step is structurally different from one that can post entries autonomously.
Layer 3: The Control Layer
The control layer is your escalation architecture — the set of rules, thresholds, and routing logic that determines when the agent acts autonomously and when it routes to a human. This is the judgment boundary made operational. It includes confidence thresholds (if the match score is below 85%, escalate), materiality thresholds (if the variance exceeds $10,000, escalate), and exception-type rules (if a new vendor has been active fewer than 90 days, require human approval for first payment).
In well-designed finance agents, the control layer is transparent and auditable. Every escalation decision has a logged reason code. Every autonomous action has a structured reasoning trace. This is not optional hygiene — it is what makes the system legible to your external auditors.
Layer 4: The Governance Layer
The governance layer sits above the agent itself and defines the organizational accountability structure: who owns the agent’s outputs, who reviews its performance, who can modify its decision thresholds, and who is responsible when it makes an error. This layer is where most organizations are underbuilt in 2026. The governance layer does not ship with the agent. It has to be constructed deliberately by finance leadership.
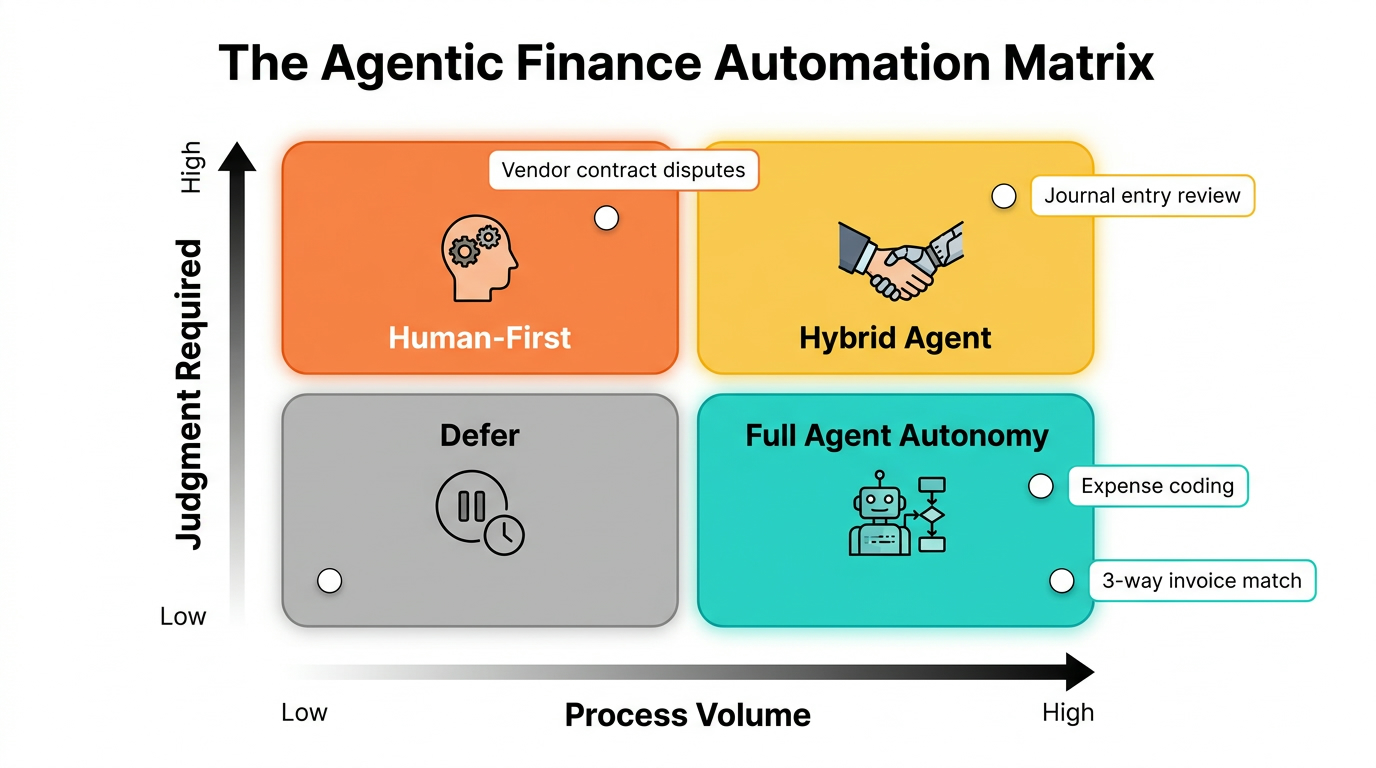
The Automation Matrix: Mapping Finance Workflows to Agent Autonomy Levels
Not every finance workflow is equally suited to agent autonomy. The most practical way to think about this is a two-axis framework. The first axis is process volume — how many instances of this workflow occur per period. The second axis is judgment required — how much context-dependent reasoning, stakeholder negotiation, or organizational discretion the workflow typically demands.
Plotting your workflows across these two axes gives you four zones:
Zone 1: Full Agent Autonomy (High Volume, Low Judgment)
These are your immediate targets. High-volume, rules-heavy, data-rich workflows where the correct action can be determined algorithmically with high confidence. The key characteristic: if you gave the workflow to three different experienced analysts, they would all produce the same output 95%+ of the time.
Finance examples in this zone include:
- Three-way invoice matching against existing POs and goods receipts
- Expense report coding against pre-defined category rules
- Remittance advice matching and cash application
- Bank statement reconciliation to GL entries
- Vendor master data validation (duplicate detection, format standardization)
- Standard journal entry preparation from source documents
- Payment term calculation and early-payment discount identification
Zone 2: Hybrid Agent (High Volume, High Judgment)
These workflows have the volume to justify automation investment but involve enough contextual complexity that full autonomy creates unacceptable risk. The agent handles the structured portions — data gathering, initial scoring, option generation — while a human reviewer makes the final call. The human’s job shifts from doing the work to reviewing a structured recommendation and approving or overriding it.
Finance examples include:
- FP&A variance analysis — agent drafts the narrative, human reviews and adds organizational context
- AR collections prioritization — agent scores accounts and recommends outreach cadence, human adjusts for relationship dynamics
- Loan or credit application pre-screening — agent aggregates and scores, human makes final credit decision
- Month-end journal entry review — agent prepares and flags anomalies, controller approves
- Spend category analysis and budget variance reporting
Zone 3: Human-First (Low Volume, High Judgment)
These workflows are not automation candidates, at least not in 2026. The volume does not justify the engineering overhead, and the judgment requirements are too context-specific to encode reliably. Agent assistance is still valuable here — for research, drafting, or information aggregation — but the agent should never be in the execution loop.
Finance examples include:
- Vendor contract disputes and negotiations
- M&A financial due diligence
- Covenant breach response and lender communication
- CFO board narrative construction (though draft support is fine)
- Strategic capital allocation decisions
Zone 4: Defer (Low Volume, Low Judgment)
These are workflows where the volume is low enough that manual processing is perfectly manageable, and automation investment would not meaningfully change team capacity. There is no urgency to wire these up; focus your agent budget elsewhere.
Accounts Payable and Procure-to-Pay: The Highest-ROI Starting Point
Every serious agentic AI playbook for finance begins here, and for good reason. AP and P2P workflows are the ideal proving ground for finance agents: they are high-volume, highly structured, data-rich, and the ROI is both measurable and fast.
The numbers from early enterprise deployments are striking. Finance operations teams implementing agentic AP agents report 70–80% reductions in AP processing labor. Touchless invoice processing rates — invoices handled from ingestion to payment posting without a human touch — climb to 80% or more in mature deployments. Forrester’s 2026 AP guidance notes that agentic systems can now handle complex exceptions like multi-level PO matching and service contract invoices that traditional rules-based automation could not.
What the AP Agent Actually Does
A well-configured AP agent runs a continuous, end-to-end process that looks roughly like this:
- Ingestion and extraction: The agent ingests invoices from all channels — email, vendor portals, EDI feeds, PDF uploads — and uses document intelligence to extract structured data: vendor ID, invoice number, line items, amounts, tax, PO references, and payment terms. OCR accuracy for structured invoices now routinely exceeds 97% in production systems.
- Three-way match: The agent queries the ERP for the referenced PO and goods receipt. It validates quantities, unit prices, and totals against the match. If all three match within configured tolerance bands (typically 0.5–2% for pricing, exact for quantities), it proceeds. If not, it classifies the exception type — price variance, quantity discrepancy, missing goods receipt, or duplicate — and routes accordingly.
- Policy and compliance checks: The agent checks the invoice against vendor standing (is this vendor on a watchlist? is their payment bank account consistent with the master record?), payment terms (early-pay discount available?), and coding rules (which GL account, cost center, and project code applies?).
- Autonomous processing or escalation: Invoices that pass all checks within the agent’s configured authority level are queued for payment. Exceptions are routed to the appropriate human reviewer with a structured summary: what the exception is, what data the agent used to classify it, and what resolution options are available.
- Audit logging: Every step — every query, every match result, every routing decision — is logged with timestamps, data sources, and reasoning traces. This is the audit trail that makes the process defensible to your external auditors.
Setting Your AP Agent’s Authority Thresholds
The most important configuration decision in AP automation is not which model to use or which ERP connector to buy. It is how you set the agent’s authority thresholds. A practical starting framework for most mid-market organizations:
- Full autonomous processing: Invoices under $10,000 with a valid, open PO, within price tolerance, from a vendor active more than 90 days, with no watchlist flags.
- Automated processing with manager notification: Invoices between $10,000 and $50,000 meeting the same criteria — the agent processes but sends a same-day summary to the AP manager.
- Human approval required: Invoices above $50,000, invoices from vendors active fewer than 90 days, invoices with price or quantity variances outside tolerance, invoices referencing contracts with unusual terms.
- Controller escalation: Duplicate invoice flags, bank account change requests from vendors, invoices referencing expired POs, and any transaction the agent’s confidence score rates below a defined threshold.
These thresholds are not universal — they should be calibrated to your organization’s risk appetite, average transaction size, and audit history. But the principle is consistent: define the boundaries explicitly before you deploy, and review them quarterly as the agent’s performance data accumulates.
Month-End Close and Reconciliation: From 12 Days to 3
The month-end close is, in many ways, the defining operational challenge of a finance team. It is a time-bounded, high-stakes, multi-system coordination problem that consumes enormous analyst capacity every period — and produces outputs that directly feed board reporting, regulatory filings, and management decisions. The average close for a mid-sized enterprise runs 8–12 days. Early enterprise adopters of agentic close acceleration report compressing that to 3 days, a roughly 75% improvement.
That compression is not magic. It comes from removing the waiting and the manual coordination that dominates the close calendar, not from shortcuts in the underlying accounting.
Where Close Time Actually Goes
Before configuring an agent for close acceleration, it is worth analyzing where close time actually goes in a typical organization. The breakdown usually looks something like this:
- Bank and sub-ledger reconciliation: Matching GL balances to bank statements, AR sub-ledger, AP sub-ledger, fixed asset registers, and intercompany accounts. This is often the single largest time sink — 30–40% of close days — and is almost entirely algorithmic in nature.
- Journal entry preparation: Accruals, deferrals, reclassifications, and period-end adjustments. A significant portion of these are recurring, formulaic entries that follow identical logic every period.
- Variance analysis: Comparing actuals to budget and prior period, identifying drivers of significant variances, and drafting explanatory narratives for management review.
- Exception resolution: Chasing down the unmatched items, the out-of-balance sub-ledgers, and the missing approvals that block the close from proceeding. This is where close time is least predictable and most frustrating.
- Reporting package assembly: Compiling the P&L, balance sheet, cash flow statement, and supporting schedules into the format required for management, board, and regulatory reporting.
What Agents Handle vs. What Stays Human
Reconciliation is the clearest close-acceleration win: agents run continuously, matching entries as they occur throughout the period rather than scrambling at month-end. By the time the close date arrives, 80–90% of reconciliation items are already matched and logged. The human team focuses only on the genuine exceptions — the items where the matching logic surfaced a real discrepancy requiring judgment.
Recurring journal entries are the second big win. An agent can prepare all standard accruals — prepaid amortization, depreciation, payroll accruals, revenue deferrals — from source data, flag any anomalies (an accrual that is 30% higher than prior period average, for example), and queue them for controller review and posting. The controller’s job shifts from preparing entries to reviewing a pre-populated, already-reconciled package.
Variance analysis narrative drafting is the area with the most nuance. Agents are now genuinely useful at generating first-draft variance commentary — “Revenue is $2.3M unfavorable to budget, driven primarily by $1.8M shortfall in the enterprise segment, consistent with the pipeline timing shift flagged in the Q3 sales forecast.” That draft saves an analyst 2–3 hours. But it requires a senior finance professional to validate the context before it goes to the board. The agent drafts; the human approves and contextualizes.
The “Continuous Close” Model
The most forward-thinking finance teams are not just accelerating their close — they are using agentic systems to shift toward a continuous close model, where reconciliation and sub-ledger maintenance happen in real time rather than in a periodic sprint. This does not eliminate the month-end close, but it dramatically changes what the close consists of: reviewing and approving a continuously maintained ledger rather than building one from scratch over 12 days.
Reaching a continuous close requires two things beyond the agent technology: a clean, real-time data integration between all source systems and the GL, and a redefined organizational model where finance team members are allocated to continuous monitoring and exception review rather than periodic crunch work. Both are cultural changes as much as technical ones.
FP&A Augmentation: Scenario Modeling Without the Spreadsheet Stampede
Financial planning and analysis is one of the most time-consuming and talent-intensive functions in a finance organization — and one of the most misunderstood targets for agentic automation. The mistake most teams make is trying to automate the decisions in FP&A (which scenarios to model, which assumptions to use, what the results mean for strategy) rather than the mechanics (data gathering, model population, variance calculation, narrative drafting).
The distinction matters enormously in practice. Agentic AI in FP&A is an augmentation play, not a replacement play. The goal is to eliminate the hours of mechanical work that consume analyst time so that those analysts can spend more time on the higher-order judgment that actually makes FP&A valuable to the business.
The Four FP&A Tasks Where Agents Deliver the Most Value
1. Data aggregation and model population. In most organizations, the first 40–60% of any FP&A project involves pulling data from multiple systems — ERP actuals, CRM pipeline data, HR headcount files, operational KPIs — cleaning it, and loading it into the planning model. This is pure mechanics. An agent running on a clean data integration layer can do this continuously, so that the planning model is always populated with current actuals rather than data that is three days old when the analyst starts their analysis.
2. Variance analysis and anomaly detection. Agents are excellent at the first pass of variance analysis: identifying which line items are out of tolerance, calculating the magnitude and direction of variance, and flagging items that deviate significantly from forecast or prior period. A well-configured agent can surface the ten most significant variance items in a 500-line P&L in seconds, with the underlying data trail attached. The analyst then investigates the drivers — a task that genuinely requires business judgment.
3. Scenario model generation. When the business asks “what happens to our Q4 forecast if enterprise deal close rate drops by 15%?”, the agent can recompute the revenue model, cascade the impact through gross margin and opex, and produce a revised output within minutes. This is not strategic judgment — it is arithmetic applied at speed. Analysts who previously spent half a day rebuilding a model for a scenario run can now review a machine-generated output and focus on the strategic implications.
4. Board narrative and management commentary first drafts. Language models are now sufficiently capable that their first-draft variance commentary for management reporting is often more consistent and less error-prone than analyst-written commentary produced under close-week time pressure. The agent produces a structured first draft; the VP of Finance edits it for organizational context, nuance, and tone. This is not “AI writes the board pack” — it is “AI eliminates the blank-page problem on the 47th line of the management discussion section.”
What Not to Automate in FP&A
Just as important as knowing what to automate is knowing what to leave alone. In FP&A, the following belong firmly in the human domain:
- Assumption selection. Which growth rate to use for the base case, which cost inflation assumption to apply, which market scenario to weight most heavily — these are judgment calls that reflect the organization’s strategic posture. An agent can present options and model their implications; it should not select among them.
- Strategic narrative construction. The CFO’s read of why Q3 underperformed and what it signals about the business is not a variance calculation — it is an organizational interpretation that requires political, strategic, and relational context the agent does not have.
- Annual planning process facilitation. The negotiation between business units and the finance function over budget targets is a deeply human process. Agents can support it with data, but they should not be in the loop on the conversations.
Operations: Procurement, Vendor Management, and Inventory

The ops side of this equation has its own distinct profile. Where finance workflows are primarily about processing and compliance, ops workflows are primarily about coordination and response — managing the flow of goods, suppliers, and commitments in real time. Agentic AI in ops is not about replacing the supply chain team; it is about giving them continuous visibility and decision support that was previously only achievable with significant manual monitoring labor.
McKinsey’s research on AI-enabled supply chains puts the stakes clearly: early adopters have achieved approximately 15% lower logistics costs and 35% lower inventory levels compared to industry averages. Those are not marginal improvements — they are structural competitive advantages that compound over time.
Procurement: From Reactive to Continuous
Traditional procurement is fundamentally reactive. A requisition appears, a buyer reviews it, vendor quotes are solicited, a PO is issued. Agentic procurement is continuous. Agents monitor spend patterns, contract utilization, vendor performance, and market price signals in real time, surfacing opportunities and risks before a human would typically notice them.
Vendor qualification and scoring is one of the clearest wins. Manually evaluating and scoring 500 potential vendors across financial stability, compliance certifications, geographic risk, and category experience takes weeks. An agent can process that same evaluation in hours, producing structured scorecards that the procurement team reviews and acts on. The human effort shifts from data gathering to decision-making.
Contract renewal and compliance monitoring is another high-value ops agent application. Agents can continuously monitor the full contract portfolio — tracking renewal dates, automatically alerting procurement 60–90 days before key dates, flagging contracts where the vendor’s performance data suggests renegotiation leverage, and identifying contracts that have gone beyond their stated term without renewal action.
Supplier risk monitoring moves from periodic reviews to continuous, always-on surveillance. An agent configured for supplier risk can monitor financial filings, news feeds, sanctions lists, and operational performance data for every significant vendor in the supply base, surfacing risk signals in real time rather than waiting for the annual supplier review cycle.
Inventory and Replenishment
Walmart’s deployment of autonomous inventory agents — monitoring stock levels, forecasting regional demand, and automatically adjusting procurement orders across thousands of SKUs — is the most-cited example of agentic AI in ops at scale. The principle transfers to organizations of any size: agents can monitor inventory positions against demand signals continuously and trigger replenishment actions within configured authority levels, escalating only when demand signals are ambiguous or when order sizes exceed the agent’s authority threshold.
The critical configuration element here is the autonomy boundary: what order sizes can the agent execute independently, under what demand signal confidence levels, and which SKU categories require human sign-off regardless of signal strength? High-volume, commodity SKUs with stable demand patterns are ideal candidates for full agent autonomy. New SKUs, promotional items with volatile demand, and long-lead-time components require tighter human oversight.
Operations Agents and the ERP Integration Problem
The persistent bottleneck for ops agent deployments is ERP and system integration. Agents need real-time access to inventory data, purchase order history, vendor master records, and demand signals that often sit in multiple, loosely connected systems. Organizations with clean, well-governed data environments — SAP S/4HANA with live ERP data, or Workday Supply Chain with consistent master data — can deploy ops agents meaningfully faster than those running fragmented legacy stacks with manual data exports.
This is not a reason to wait. It is a reason to treat data integration as Phase 0 of your ops agent roadmap, not an afterthought. The cost of connecting your ERP and procurement systems cleanly is typically recouped within the first quarter of agent operation — but only if you do it before the agent goes live, not after it starts making decisions on stale data.
Compliance, SOX, and the Audit Trail Your Controller Will Actually Sign Off On
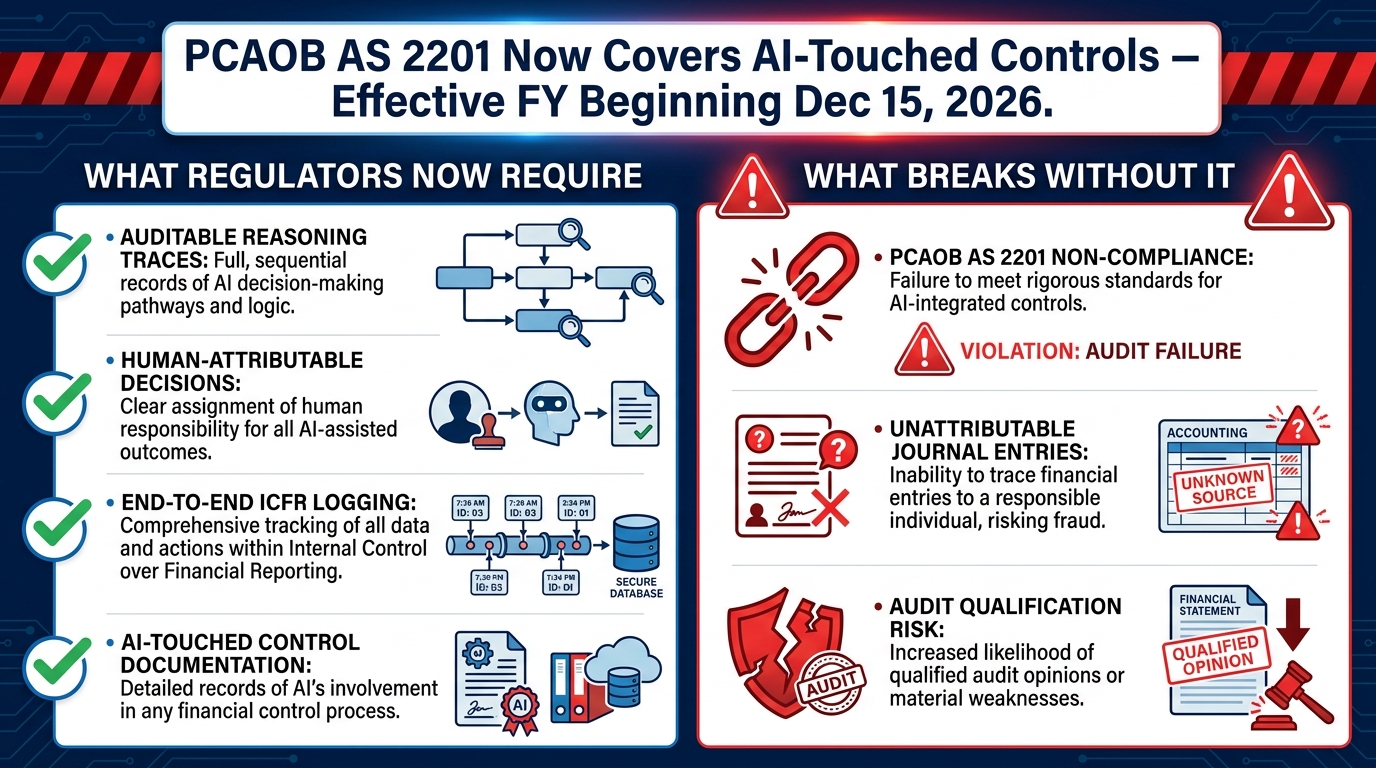
Of all the topics in this playbook, compliance is the one that most finance teams handle least well in their initial agent deployments. Not because they ignore it — but because they address it too late. Compliance architecture for an agentic finance system is not something you retrofit after the agent is live. It must be designed into the system from the first line of configuration.
The regulatory environment in 2026 is sharpening in ways that make this urgency concrete. PCAOB’s amended standards AS 2201 and AS 2101, effective for fiscal years beginning on or after December 15, 2026, extend the scope of internal control over financial reporting (ICFR) audits to explicitly cover AI-touched controls. This is a material change. Under the new standards, if an AI agent influences ICFR — including through autonomous journal entries, payment authorization, or financial data processing — auditors will expect the same documentation and evidence standards as for any other control.
What Auditors Are Now Looking For in AI-Touched Controls
The practical implication of PCAOB’s amended standards breaks down into four requirements that your agent architecture must satisfy:
1. Auditable reasoning traces. Auditors will not accept “the agent did it” as a description of a control. For every material financial transaction or journal entry that an agent processes, there must be a structured, human-readable log of what data the agent used, what logic it applied, and why it reached the conclusion it did. This is not an optional feature — it is a fundamental requirement for any AI-touched ICFR control.
2. Human-attributable decisions. SOC 2 and SOX frameworks expect privileged financial actions to be attributable to a specific, accountable person. Where an agent takes action autonomously, the governance framework must specify which human role is accountable for that agent’s actions — not as a rubber stamp, but as a genuine review-and-approval checkpoint at a frequency appropriate to the materiality of the transactions. The controller who owns the AP agent’s configuration is accountable for its autonomous decisions in the same way they would be accountable for a staff accountant’s work.
3. End-to-end ICFR logging. The agent’s audit log must cover the full transaction lifecycle, not just the matching or coding step. If an agent is involved in the process from document ingestion to payment posting, the log must span that entire chain with no gaps. Auditors are specifically looking for evidence that AI-automated steps were subject to the same control documentation as manual steps.
4. Exception and override documentation. When an agent’s recommendation is overridden by a human reviewer, the override must be logged with a reason code and reviewer identification. When an agent routes an exception to a human, the human’s resolution must be documented in a way that is traceable back to the original transaction. This documentation chain is what makes the control testable — and therefore auditable.
The “Agent Did It” Problem and How to Solve It
The most common compliance failure mode in early finance agent deployments is what auditors are calling the “agent did it” problem: transactions where the agent took action autonomously but no human has clear accountability for the outcome, and the reasoning trace is either absent or unintelligible to a non-technical reviewer.
The solution is architectural, not documentary. Rather than trying to document a poorly designed agent’s decisions after the fact, design the agent to produce clean, human-readable decision logs natively. Practically, this means configuring your agent platform to generate structured exception reports, decision reason codes, and transaction-level logs in a format that integrates with your existing GL audit trail — not as a separate system that your auditors have to interpret independently.
It also means designing your governance layer before deployment, not after. The question “who is accountable for this agent’s actions?” needs to be answered in your RACI matrix and your job descriptions before the agent processes its first invoice — not when your Big Four auditor asks the question during fieldwork.
Escalation Architecture: Designing the Human Handshake
The escalation architecture is the operational heart of an agentic finance system. It is also the most underspecified element in most initial deployments. Teams that define it rigorously before go-live have dramatically better outcomes than teams that try to tune it reactively after the agent starts generating exceptions that nobody knows how to handle.
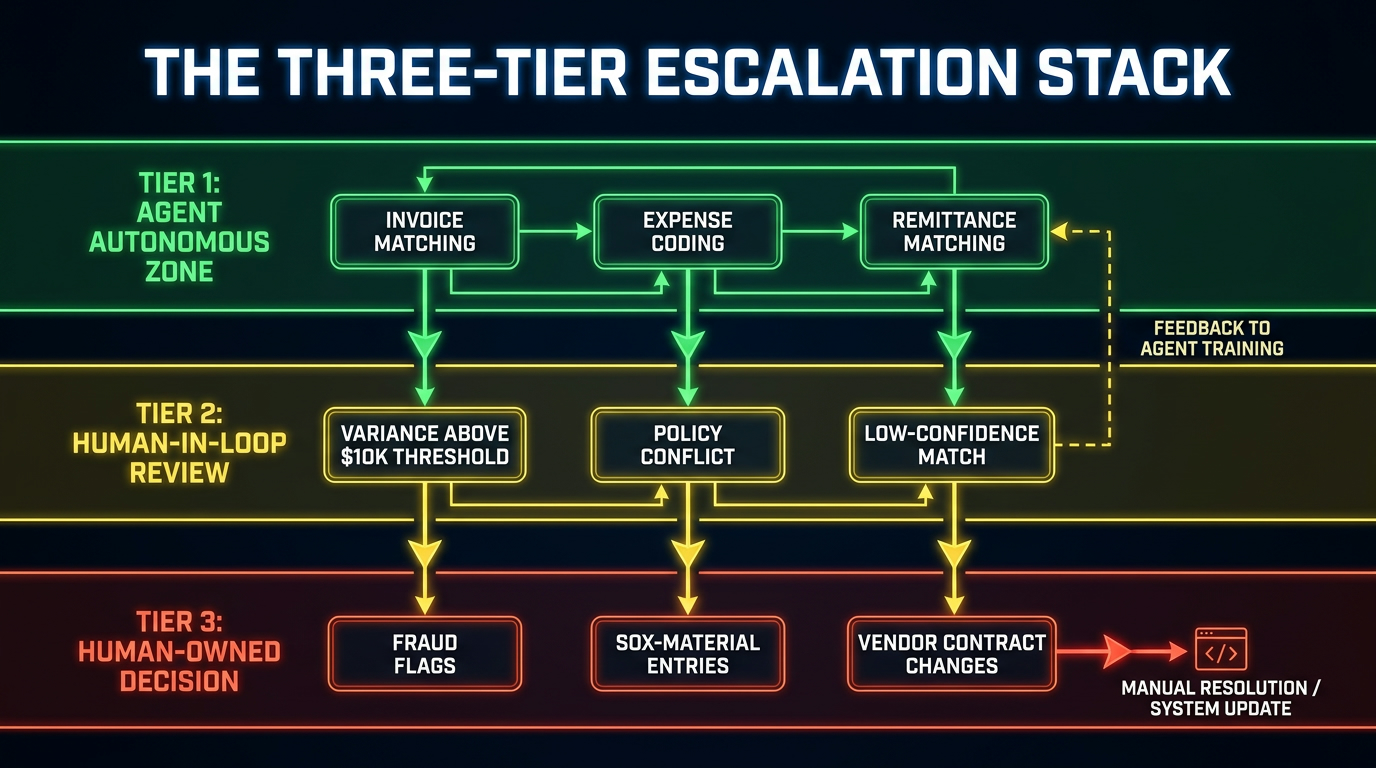
The Three-Tier Escalation Model
A practical escalation architecture for finance agents has three tiers, each with a defined set of conditions and a defined human response requirement:
Tier 1 — Agent Autonomous Zone: The agent acts independently, logs the action, and does not require human intervention. Triggered when all of the following are true: the confidence score exceeds the configured threshold, the transaction is within the agent’s dollar authority, the vendor and account are verified and active, and no exception flags are raised. The human team reviews a daily summary report of all Tier 1 actions; they do not review individual transactions.
Tier 2 — Agent Recommendation, Human Approval: The agent prepares a structured recommendation with supporting data and routes it to a named human reviewer. The reviewer approves, modifies, or rejects the recommendation, with the decision logged. Triggered by: confidence score below threshold, transaction above dollar authority, new vendor with fewer than 90 days of history, variance outside tolerance, or any transaction type specifically designated for hybrid review in the governance framework. The human reviewer has a defined response SLA — typically 4–8 business hours for payment decisions, 24 hours for non-payment decisions.
Tier 3 — Human-Owned Decision, Agent Support Only: The agent provides information and analysis but takes no action. The human makes the decision, executes it, and logs the rationale. Triggered by: fraud flags, watchlist matches, bank account change requests from vendors, SOX-material entries above a materiality threshold, policy conflicts requiring legal or compliance review, and any situation where the agent’s confidence score falls below a minimum floor. Tier 3 cases are assigned to a specific named individual, not a queue.
Designing Your Escalation Triggers
The specific triggers for each tier should be calibrated to your organization’s transaction profile, risk appetite, and audit history. A useful starting-point exercise is to pull 90 days of historical transaction data and ask: “For each transaction, what would the correct tier assignment have been?” This retrospective calibration helps you set thresholds that reflect your actual transaction population rather than theoretical norms.
Common escalation trigger categories:
- Dollar thresholds: Different for payments, journal entries, and vendor master changes. Generally more conservative for new vendors and new account codes.
- Confidence thresholds: Model-specific, typically expressed as a percentage. Needs regular review as the model’s performance data accumulates.
- Anomaly flags: Unusual timing (invoice date significantly before or after period), unusual amounts (significantly above or below vendor average), unusual destinations (payment to new bank account, payment to country not in vendor’s profile).
- Regulatory triggers: OFAC/sanctions checks, PEP (Politically Exposed Person) matches, duplicate payment indicators.
- Business-rule exceptions: Invoices referencing expired POs, invoices where the vendor contract has a price increase clause, invoices coded to capital accounts above a defined threshold.
The Sequencing Framework: What to Wire Up First
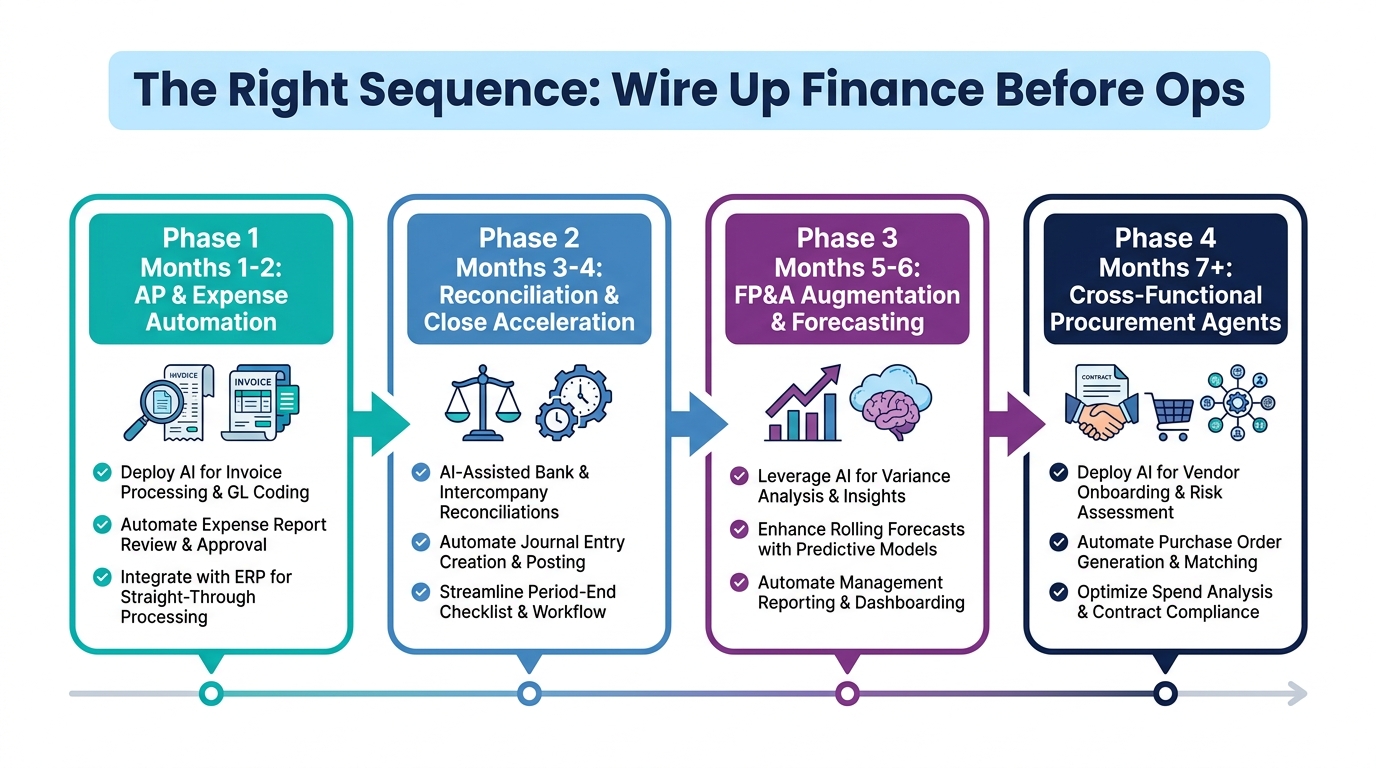
The question of where to start is as important as the question of what to automate. The most common sequencing mistake is trying to deploy across too many workflows simultaneously, resulting in governance gaps, integration problems, and team overwhelm that collectively push the project back into pilot status.
A sequencing framework built on four phases, each designed to deliver standalone value while creating the infrastructure foundation for the next phase, is the most reliable path from first deployment to enterprise-scale agent operations.
Phase 1 (Months 1–2): AP and Expense Automation
Start here. AP automation is the cleanest first deployment: high-volume, structured data, measurable ROI, and a well-defined human review layer. It also creates the technical foundation — ERP integration, agent logging infrastructure, escalation workflow tooling — that subsequent phases build on.
Deliverables: An agent processing at least 60% of invoices touchlessly within 60 days of go-live. A three-tier escalation architecture configured and documented. A daily summary report format approved by the controller. An initial governance framework with clear accountability assignments.
Success metric: Reduction in manual AP processing hours. Target a 50% reduction in Phase 1, growing toward 70–80% as the system matures.
Phase 2 (Months 3–4): Reconciliation and Close Acceleration
With the AP agent running and the data integration layer established, extend the agent’s scope to month-end reconciliation. This phase leverages the bank feed and ERP connections built in Phase 1 and adds continuous matching logic that begins compressing close timelines immediately.
Deliverables: Automated bank and sub-ledger reconciliation running continuously. Agent-prepared recurring journal entry packages queued for controller review. A close checklist integrated with the agent’s output pipeline. Measurable reduction in close-day count.
Success metric: Close timeline reduced by at least 30% from Phase 1 baseline, with a roadmap to 50%+ reduction over the following two quarters.
Phase 3 (Months 5–6): FP&A Augmentation and Forecasting Support
With clean, continuously maintained actuals flowing from Phase 2, the FP&A augmentation layer has the reliable data foundation it needs. This phase deploys variance analysis agents, forecast model population automation, and narrative drafting support.
Deliverables: Automated variance flagging against budget and prior period with structured exception reports. Rolling forecast model populated from live actuals within 24 hours of period close. First-draft management commentary for standard reporting packages.
Success metric: Reduction in analyst hours spent on data gathering and model population. Target at least 40% reduction in mechanics-type FP&A work, freeing capacity for higher-value analysis.
Phase 4 (Month 7 Onward): Cross-Functional Procurement and Ops Agents
The ops extension is the most complex phase because it crosses organizational boundaries — finance and procurement must align on governance, data ownership, and escalation authority. Phases 1–3 build the organizational trust and technical infrastructure that makes this cross-functional coordination feasible.
Deliverables: Vendor qualification agents integrated with the procurement workflow. Continuous supplier risk monitoring across the top 50–100 vendors. Contract renewal and compliance monitoring across the full contract portfolio. Inventory reorder agents configured for high-volume commodity SKUs.
Success metric: Reduction in procurement cycle time, measurable improvement in supplier risk response time, reduction in inventory carrying costs.
The Governance Stack: Decision Rights, Accountability, and What Breaks Without It
Governance is the least glamorous element of an agentic AI deployment and the most determinative of long-term success. Lumenova AI’s 2026 enterprise survey found that the primary bottleneck in finance AI scaling is not model capability — it is operating-model and governance readiness. Teams with clear governance structures scale; teams without them plateau.
The Four Governance Questions That Must Be Answered Before Go-Live
1. Who owns the agent’s outputs? Every transaction the agent processes autonomously must have a named human who is accountable for it — not as someone who reviews every transaction, but as someone who owns the configuration, monitors the performance, and is responsible for escalations the agent generates. In practice, this is typically the AP Manager for AP agents, the Controller for close agents, and the FP&A Director for planning agents.
2. Who can modify the agent’s decision thresholds? Threshold changes — raising the dollar authority, relaxing a confidence floor, adding or removing exception triggers — must go through a formal change-management process. Informal threshold adjustments are how control gaps develop. Define a change governance process: who can propose changes, who reviews them (controller + IT security + internal audit), and what documentation is required.
3. What happens when the agent makes a mistake? This question reveals gaps in the accountability structure faster than any other. Define error-response procedures before go-live: how errors are detected (monitoring, exception reports, periodic audits), how they are investigated, how affected transactions are corrected, and how the agent’s configuration is updated to prevent recurrence.
4. How is the agent’s performance measured and reported? Set a cadence and a scorecard. Touchless rate, exception rate, escalation response time, error rate, and cost per transaction processed are all standard metrics. Review them monthly with the agent owner, quarterly with the Controller and CFO. An agent whose performance is not monitored is an agent whose drift from expected behavior goes undetected.
The Internal Audit Function in an Agentic Finance Environment
Internal audit’s role does not shrink in an agentic finance environment — it shifts. Instead of testing individual transactions, internal audit tests the agent’s control configuration: are the thresholds appropriate? Is the audit log complete and legible? Are escalations being resolved within SLA? Is the human review process functioning as designed, or are reviewers rubber-stamping agent recommendations without genuine scrutiny?
The most effective internal audit approach for agentic finance systems is a combination of continuous controls monitoring — automated alerts when agent error rates spike or escalation volumes shift unusually — and periodic deep-dive reviews of the governance documentation, threshold history, and a sample of Tier 2 and Tier 3 escalation resolutions.
Building the Finance AI Center of Excellence
PwC’s 2026 financial services playbook recommends establishing a Finance AI Center of Excellence (CoE) as a prerequisite for scaling agent deployments beyond Phase 2. The CoE does not need to be large — in a mid-market organization, it might be two or three people — but it needs to bring together finance operations knowledge, data engineering capability, and governance expertise in a single coordinated function.
The CoE’s responsibilities: maintaining the agent configuration registry, running the change-governance process for threshold modifications, coordinating with external auditors on AI-touched control documentation, monitoring regulatory developments (PCAOB, EU AI Act, relevant industry guidance), and building the internal knowledge base so that the organization’s agent expertise does not depend on any individual.
What the Numbers Say: Benchmarks Worth Holding Your Program Against
One of the most common obstacles to securing internal investment for agentic finance programs is the absence of credible, specific benchmarks. Leadership teams are skeptical of vendor-provided ROI estimates, which are almost always optimistic. Here is a consolidated view of benchmarks from identifiable, non-vendor sources that you can cite in internal business cases:
AP and Procure-to-Pay
- 70–80% reduction in AP processing labor in mature agentic AP deployments (BeanCount.io field guide, 2026)
- 80%+ touchless invoice processing rate in well-configured deployments (Forrester, 2026)
- Agentic systems now handle complex exception types — multi-level PO matching, service contract invoices — that previous-generation automation could not (Forrester, 2026)
Month-End Close
- 55% faster monthly close in early enterprise adopter cohort (BeanCount.io, 2026)
- 12-day close to 3-day close in leading-edge deployments (multiple sources, 2026)
Supply Chain and Procurement
- ~15% lower logistics costs among AI-enabled supply chain early adopters (McKinsey, cited in Redwood Software 2026)
- ~35% lower inventory levels for the same early adopter cohort (McKinsey, cited in Redwood Software 2026)
Adoption Context
- Only 24% of executives say AI agents currently take independent action in their organization; 67% expect this by 2027 (IBM IBV, 2026)
- Finance AI adoption is still substantially in pilot mode in mid-2026, primarily due to governance gaps and data quality issues — not model limitations (FP&A Trends, April 2026)
- Gartner projects that approximately 40% of agentic AI projects will be cancelled by 2027 due to cost, unclear value, or inadequate risk controls
These benchmarks matter not because your organization will exactly replicate them, but because they establish a plausible range and identify the drivers of performance variation — governance, data quality, threshold configuration — that your program design should address directly.
Conclusion: Building the Judgment-Aware Finance Machine
The organizations that are winning with agentic AI in finance and ops in 2026 are not the ones that deployed the most sophisticated models or moved the fastest. They are the ones that took the time to map the judgment boundary precisely — to distinguish between the workflows an agent can own completely, the workflows where agents and humans share the work, and the workflows that belong to people because they require the kind of contextual, relational, and organizational intelligence that no current AI system reliably provides.
That distinction — more than model selection, more than vendor choice, more than integration architecture — is what determines whether an agentic finance program delivers the 70–80% labor reductions and 55% close-time compressions that the leading deployments are demonstrating, or ends up as the 40% of projects Gartner expects to be cancelled by 2027.
The playbook is not complicated. Start with AP. Establish your escalation architecture before the agent goes live. Build your governance layer with the same rigor you would apply to any other financial control. Extend to close acceleration once the AP infrastructure is stable. Add FP&A augmentation once you have clean, continuously maintained actuals. Move to procurement and ops only after finance has demonstrated the organizational model that makes cross-functional agent governance feasible.
And throughout every phase, keep returning to the same central question: where exactly does this agent’s judgment end and ours begin? The teams that answer that question with precision and document it with rigor are the ones building finance operations that are genuinely more capable — not just faster, but better at surfacing the information and executing the transactions that the business depends on every day.
Key Takeaways for Finance and Ops Leaders
- Map every workflow to the automation matrix before deployment. High volume + low judgment = full agent autonomy. High volume + high judgment = hybrid agent with human approval.
- Design your three-tier escalation architecture before the agent goes live. Define the conditions for each tier explicitly, with dollar thresholds, confidence floors, and exception categories specified.
- AP automation is your Phase 1. It is the highest-ROI starting point, the cleanest data environment, and the foundation on which all subsequent phases depend.
- PCAOB’s amended AS 2201 and AS 2101 cover AI-touched ICFR controls for fiscal years beginning December 15, 2026 onward. Build audit-ready logging and human-attributable accountability into your agent architecture from day one.
- Governance is not a compliance afterthought. Answer the four governance questions — who owns the outputs, who controls the thresholds, what happens on errors, how is performance measured — before you approve deployment.
- The sequencing matters: Finance first, then cross-functional ops. Building organizational trust and technical infrastructure in Phases 1–3 is what makes the Phase 4 expansion viable rather than chaotic.



