There is a peculiar problem spreading through enterprise AI deployments in 2026, and almost nobody is talking about it honestly. Organizations are successfully starting agentic AI workflows. They’re just not finishing them.
A loan application enters a multi-agent pipeline, clears document extraction, passes risk scoring — and then stalls at an edge case nobody anticipated. A procurement workflow routes a purchase order through three specialized agents, only to hit an ambiguous vendor policy and loop indefinitely. A customer service agent resolves 82% of tickets autonomously, but the remaining 18% fall into a void with no graceful handoff to a human.
The completion problem is the defining challenge of agentic AI in 2026. It’s not about whether agents are capable. The underlying models are powerful enough. The architectures are sophisticated enough. The issue is that most organizations build agentic workflows the way they once built RPA bots — step by step, optimizing each node in isolation — and then wonder why the end-to-end process doesn’t hold together.
This guide takes a different approach. Rather than cataloguing what agentic AI can do, it focuses on the architectural decisions, design patterns, and operational choices that determine whether a workflow actually reaches its intended outcome. We’ll cover the four-layer architecture that underpins every reliable production deployment, the communication protocols governing agent-to-agent handoffs, where human oversight should and shouldn’t sit, and the ROI measurement frameworks that tell you whether you’re generating real business value or just impressive task completion numbers.
The goal is a workflow that doesn’t just start confidently — it finishes reliably.
The Completion Problem: Why Most Agentic Workflows Stall Before the Finish Line
The statistics behind enterprise agentic AI adoption tell a surprisingly grim story. According to 2026 deployment data, 79% of enterprises have adopted AI agents in some form — but only 11% have those agents running in production at meaningful scale. That 68-point gap isn’t a technology problem. It’s a workflow architecture problem.
Gartner forecasts that more than 40% of agentic AI projects will be canceled before 2027. The reasons aren’t what most people assume. It’s not that the underlying models are too weak or too expensive. The leading causes are governance gaps (cited by 38% of failing projects), infrastructure bottlenecks (41%), and ROI misalignment (33%). In other words, the agents often work. The workflows around them don’t.
The Three Ways Workflows Break
Understanding where agentic workflows fail helps diagnose the architectural gaps before they become production incidents.
Cascading error propagation. In a multi-agent pipeline, an error in step three doesn’t just break step three — it can poison every downstream agent that inherits that context. Unlike traditional software where a bug fails loudly, a poorly reasoned intermediate output can propagate silently, producing a confident final result that’s built on flawed foundations. Without inter-agent validation gates, these errors compound invisibly.
Dead-end exception handling. Most agentic workflows are designed around the happy path. When an agent encounters something outside its training or configuration — an unusual document format, a policy edge case, a conflicting data signal — the system either loops indefinitely, throws an opaque error, or worst of all, makes an overconfident decision it shouldn’t. Real enterprise processes are full of exceptions. Workflows that don’t account for this stop being useful precisely when they’re needed most.
Context loss at handoff points. When one agent hands a task to another, critical context — the reasoning chain, the partial results, the constraints established upstream — is frequently truncated or lost. The receiving agent then makes decisions without the full picture, either duplicating work, contradicting earlier decisions, or missing edge cases that the first agent already identified. State management across handoffs is one of the most underinvested areas in most agentic deployments.
The Production Gap Is Closing — But Slowly
The organizations that do reach production are seeing significant returns. Survivors of the deployment gap — the 11% with agents in genuine production — report an average ROI of 171%, with a median payback period of 6.7 months (down 41% year-over-year from 11.4 months). The value is clearly there. The challenge is building workflows architecturally capable of claiming it.
What “End-to-End” Actually Means in an Agentic Context
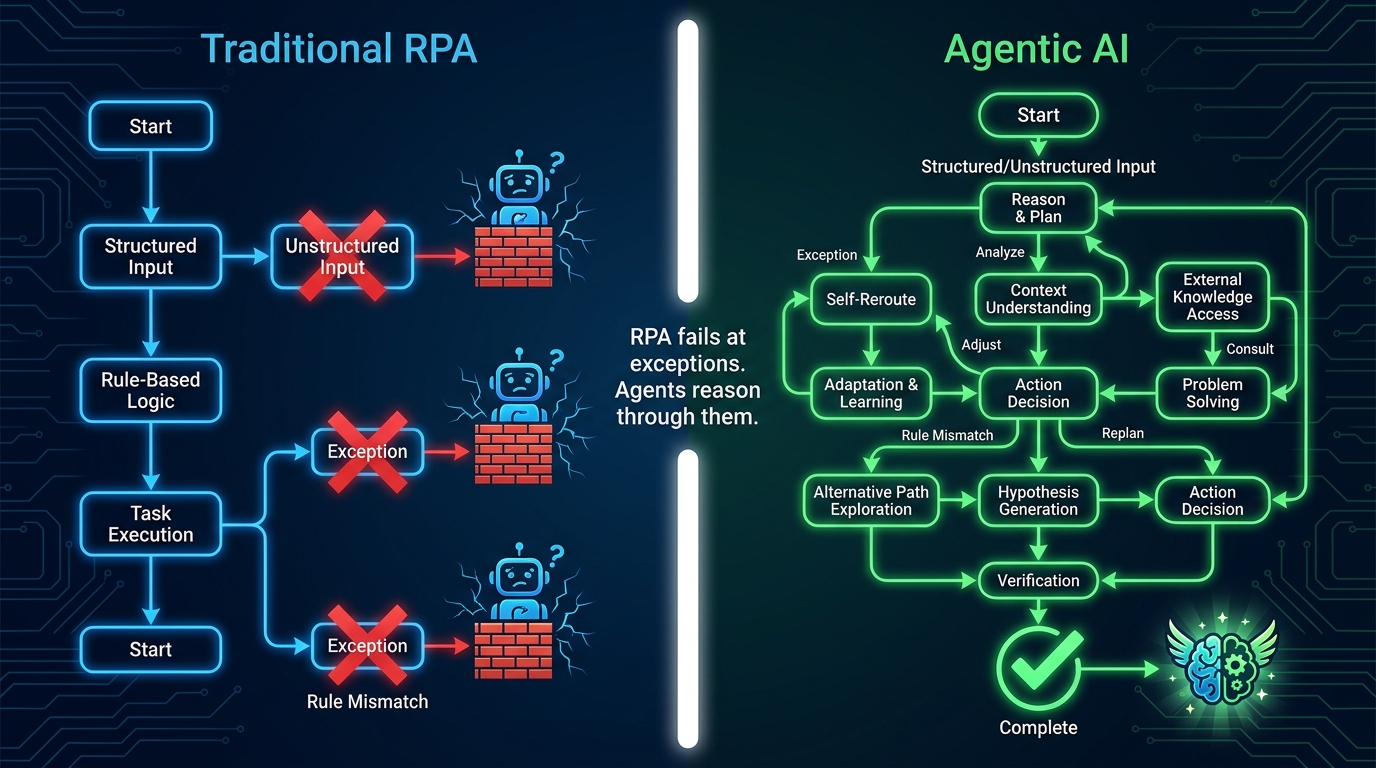
The phrase “end-to-end automation” has been overloaded to the point of meaninglessness. For years, vendors applied it to any multi-step process that touched more than one system. In the context of agentic AI, it means something far more specific — and far more demanding.
True end-to-end agentic execution has four defining characteristics that distinguish it from connected task automation:
Goal-Level Accountability
The workflow is given an outcome to achieve, not a sequence of tasks to execute. A traditional automation says: “Extract invoice data, validate against PO, approve if matched, flag if not.” An agentic workflow says: “Process this invoice.” The agent then determines what steps are needed, in what order, using what tools — and it holds itself accountable to the final outcome rather than procedural compliance. This distinction matters enormously for how workflows are designed, monitored, and measured.
Adaptive Path Execution
End-to-end agentic workflows don’t follow a fixed flowchart. They plan, act, observe results, and re-plan as needed. If the first approach encounters an obstacle, the system doesn’t stop — it reasons about alternatives. If a vendor portal is down, the agent routes through email. If a document is in an unexpected format, the agent attempts extraction with a different tool before escalating. This adaptability is what allows agentic workflows to handle the long tail of real-world variation that breaks rule-based systems.
Cross-System Integration by Default
An end-to-end workflow typically spans multiple systems — CRM, ERP, communication platforms, document stores, external APIs, regulatory databases. The workflow doesn’t just touch these systems as discrete stops; it coordinates information across them simultaneously, using outputs from one to inform decisions in another. This is the operational context in which multi-agent architectures become necessary rather than optional.
Outcome Verification
Perhaps the most underappreciated characteristic: a genuine end-to-end workflow verifies that the intended outcome was actually achieved. Not that the final task was executed — that the business goal was met. A customer case was resolved, not just closed. An order was delivered, not just processed. A compliance check passed, not just completed. This distinction drives the need for evaluation agents and feedback loops, which we’ll explore in depth in the architecture section.
By this definition, most current “agentic” deployments are actually partial-path automations dressed in agentic language. They automate the steps they can predict and hand off the rest — either to humans or to failure modes. Building genuinely end-to-end capability requires a different architectural foundation.
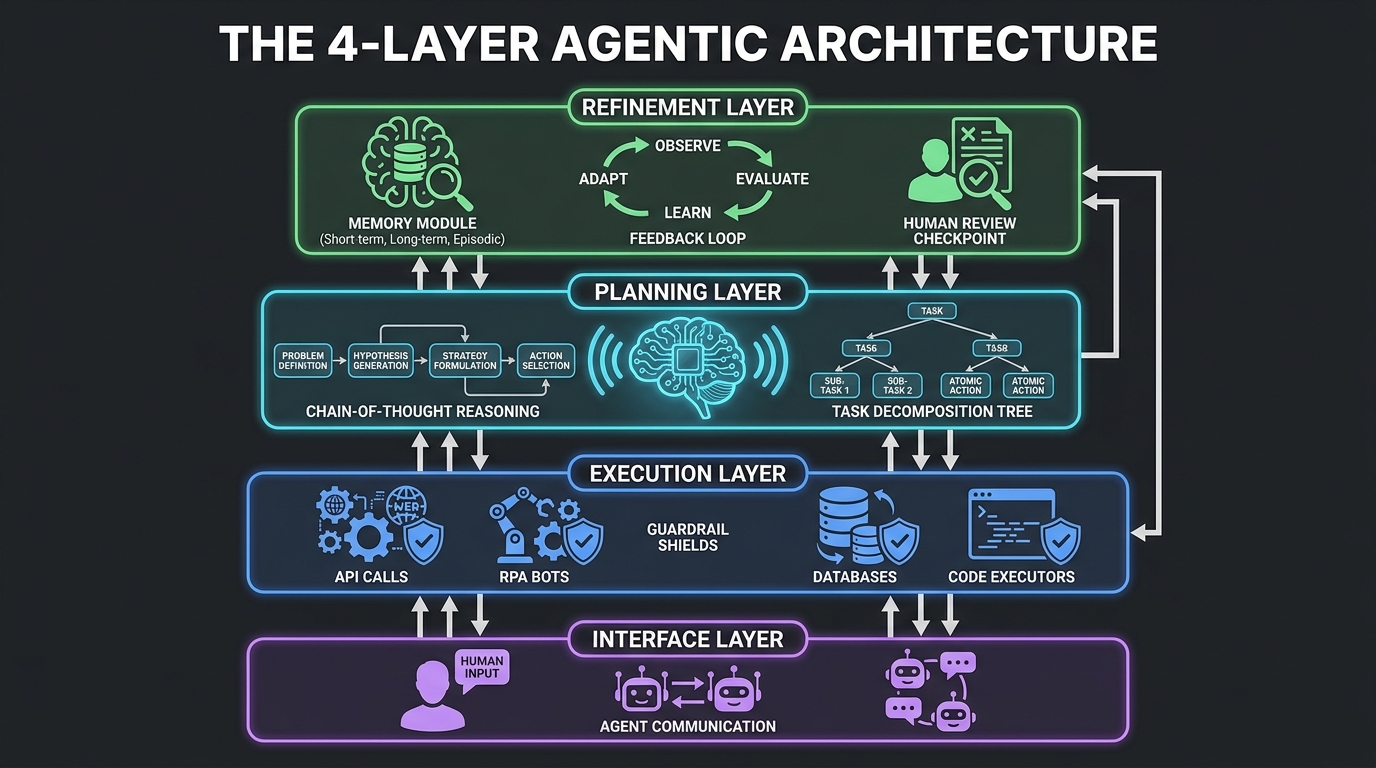
The Four-Layer Architecture Every Production Workflow Needs
Production-grade agentic workflows share a common architectural structure, even when implemented on different platforms or frameworks. This structure has four distinct layers, each with a specific responsibility. Collapsing or conflating these layers is one of the most common reasons deployments fail.
Layer 1: The Interface Layer
The interface layer handles all entry and exit points for the workflow — inbound goal inputs from humans, triggers from external systems, outputs to downstream applications, and escalation pathways back to human operators.
This layer is more complex than it sounds. A well-designed interface layer handles multiple input modalities (structured data, natural language, API calls, event triggers), normalizes them into a consistent internal goal representation, and manages authentication for both inbound requests and outbound actions. It also maintains the human communication channel — the interface through which operators can observe workflow status, approve escalations, and intervene when needed.
A common mistake is to design the interface layer purely around the happy path, omitting proper escalation architecture until problems emerge in production. By then, the cost of retrofitting a robust escalation pathway is significantly higher than designing it in from the start.
Layer 2: The Planning Layer
The planning layer receives a goal from the interface layer and produces a structured execution plan. This is where the majority of the reasoning work happens. The agent here uses techniques like Chain-of-Thought (CoT), ReAct (Reasoning + Acting), and task decomposition to break a complex objective into a sequence of achievable sub-tasks with explicit dependencies.
Critically, the planning layer also determines which agents or tools are best suited to each sub-task, estimates confidence levels, identifies potential failure points, and establishes contingency branches. A well-designed planning layer produces not just a primary path but explicit fallback paths for the most common failure modes.
In more sophisticated deployments, the planning layer operates iteratively — producing an initial plan, reviewing it with a separate critic or validator agent, and refining before handing off to execution. This “planner-critic-executor” pattern is particularly valuable for high-stakes workflows where plan quality directly impacts outcome quality.
Layer 3: The Execution Layer
The execution layer is where tasks actually happen. Specialized executor agents operate here, each with access to a constrained set of tools appropriate to their function. These might include API connectors, RPA bots for legacy system interaction, code execution environments, document processing engines, database query interfaces, or external service calls.
Guardrails at the execution layer are non-negotiable. Each executor agent should have explicit tool allowlists (it can only call the APIs it needs), time-bounded credentials, and action limits that prevent runaway execution. The execution layer also handles retry logic, timeout management, and intermediate result validation before passing outputs upstream.
Layer 4: The Refinement Layer
The refinement layer is frequently omitted in early agentic deployments and is almost always the root cause of the completion problem. This layer contains the memory management system, the evaluation components that verify outcome quality, the feedback loops that improve performance over time, and the human-in-the-loop checkpoints for cases requiring judgment calls.
Memory at this layer operates across multiple scopes: short-term working memory for the current task, session memory for the current workflow run, and long-term memory for patterns and preferences that persist across runs. The industry standard emerging in 2026 uses a four-scope model keyed on user, agent, run, and organization identifiers — allowing agents to carry context appropriately without conflating information from different workflow contexts.
The evaluation component in the refinement layer is what transforms a task-completing agent into an outcome-verifying one. Rather than treating the final executor’s completion as success, an evaluator agent independently assesses whether the intended business outcome was achieved. This is the architectural mechanism that closes the loop between “the process ran” and “the goal was met.”
Orchestrator Design: Who’s Actually Running the Show?
In any multi-agent workflow, the orchestrator is the central intelligence responsible for workflow lifecycle management — spawning agents, sequencing tasks, routing decisions, managing exceptions, and tracking state across the entire pipeline. How you design this component has outsized impact on the reliability, debuggability, and scalability of the entire system.
Centralized vs. Hierarchical Orchestration
Two orchestration patterns dominate enterprise production in 2026: centralized orchestration and hierarchical orchestration.
In a centralized orchestration model, a single orchestrator agent manages the entire workflow, maintaining a global view of state and directly coordinating all sub-agents. The advantage is simplicity — there’s a single point of accountability and a single state store to interrogate when debugging. The disadvantage is that a complex orchestrator becomes a bottleneck and a single point of failure as workflow complexity grows.
In a hierarchical orchestration model, a meta-orchestrator manages a set of lead agents, each of which orchestrates its own cluster of executor agents. This mirrors how complex human organizations structure work — a project manager coordinates team leads, who coordinate individual contributors. Fountain, the workforce technology company, implemented a hierarchical model for recruiting workflows and achieved 50% faster candidate screening, 40% faster onboarding, and cut staffing timelines from several weeks to under 72 hours.
The Orchestrator’s Core Responsibilities
Regardless of architecture choice, the orchestrator must handle five critical functions reliably:
Task routing and sequencing: Determining which agent handles which sub-task, in what order, and with what dependencies. This includes managing parallel execution where sub-tasks are independent and sequential execution where outputs feed inputs.
State synchronization: Maintaining a coherent view of the overall workflow state as individual agents complete tasks, encounter errors, or produce partial results. The orchestrator is the single source of truth for “where are we in this process.”
Exception handling and re-routing: When an agent fails, times out, or produces a low-confidence output, the orchestrator must decide: retry with the same agent, route to an alternative agent, fall back to a simpler approach, or escalate to a human. Having well-defined exception handling policies at the orchestrator level is what prevents cascading failures from stalling an entire workflow.
Context packaging for handoffs: When passing a task from one agent to another, the orchestrator should package not just the immediate task but the relevant context — what has been decided, what constraints apply, what alternatives have already been tried. Poor context packaging at handoffs is a leading cause of downstream agent errors.
Audit trail maintenance: The orchestrator should log every routing decision, every agent invocation, every output, and every state change. This audit trail is essential for debugging, for compliance requirements, and for the improvement cycles that make workflows better over time.
Choosing the Right Orchestration Framework
Open-source frameworks like LangGraph and CrewAI have emerged as popular choices for orchestration infrastructure. LangGraph is favored for its explicit state graph model, which makes workflow logic inspectable and debuggable. CrewAI provides strong role-based agent definition and is popular for hierarchical multi-agent setups. For enterprise deployments requiring tighter governance and integration with existing infrastructure, commercial platforms from vendors like Automation Anywhere and AutomationEdge provide managed orchestration with built-in observability.
The build-vs-buy decision here is real. Custom orchestrators give maximum flexibility but require significant engineering investment and ongoing maintenance. Managed platforms accelerate deployment and provide guardrails but may constrain architecture choices. The key consideration is whether your workflow complexity justifies the maintenance overhead of a custom orchestration layer — for most organizations, it doesn’t.
Agent-to-Agent Communication: A2A, MCP, and ACP Explained
One of the most consequential developments in agentic AI infrastructure in 2026 has been the emergence and adoption of standardized communication protocols. For the first time, there is meaningful convergence around how agents interact with tools, how agents communicate with each other, and how enterprise agent networks manage state. Understanding these protocols isn’t optional for serious workflow architects — they determine what’s possible at each layer of your system.
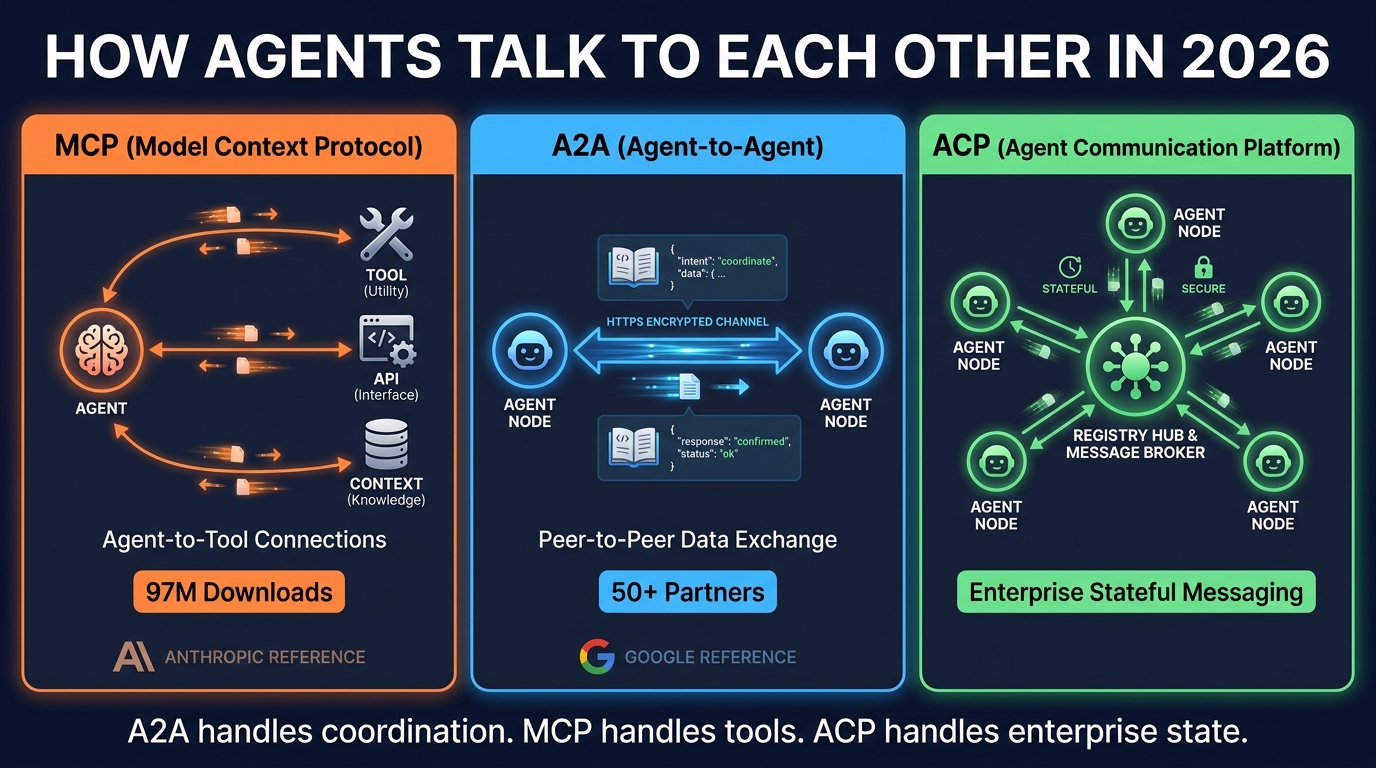
MCP: The Agent-to-Tool Standard
The Model Context Protocol (MCP), originally developed by Anthropic, has become the de facto standard for how agents interface with external tools, APIs, and data sources. With 97 million downloads and cross-vendor adoption from OpenAI, Google, Microsoft, and virtually every major AI platform, MCP functions as the API layer for the agentic world.
Think of MCP as the USB standard for AI agents — a consistent interface that allows any MCP-compatible agent to connect to any MCP-compatible tool without custom integration work. An agent running on one vendor’s platform can call a database tool, a web search service, or a legacy system integration built on another vendor’s infrastructure, all through the same protocol. For organizations managing complex multi-vendor tool ecosystems, MCP compatibility is now a baseline requirement when evaluating any agentic AI component.
A2A: The Agent-to-Agent Coordination Protocol
Where MCP handles tool access, the Agent-to-Agent Protocol (A2A), developed by Google with 50+ launch partners, handles peer-to-peer coordination between agents. A2A enables agents to discover each other’s capabilities (via Agent Cards — structured declarations of what an agent can do), delegate tasks, negotiate on approach, and stream real-time updates on task progress.
The protocol runs over HTTPS using JSON-RPC, with Server-Sent Events for real-time status updates. Security is handled through OAuth 2.0 authentication and mandatory audit trails. Critically, A2A supports task lifecycle management — not just “call this agent and get a result” but “assign this task with a contract, track its execution state, receive progress updates, and close the contract on completion.”
This lifecycle management capability is what makes A2A genuinely useful for enterprise workflows, as opposed to the simpler agent-calling patterns that characterized earlier multi-agent systems. When an orchestrator delegates a sub-task via A2A, it maintains a clear accountability chain and real-time visibility into execution state — solving one of the core context-loss problems that has historically plagued agent handoffs.
ACP: Enterprise State Management
The Agent Communication Platform (ACP) protocol fills the gap between A2A’s peer-to-peer coordination model and the stateful, registry-driven communication patterns that enterprise environments require. ACP is REST-based, registry-driven, and designed for scenarios where agents need to maintain persistent conversations, coordinate across organizational boundaries, and integrate with enterprise security and compliance infrastructure.
MCP, A2A, and ACP are complementary rather than competing. A well-designed enterprise workflow might use MCP for all tool access, A2A for cross-team agent delegation, and ACP for the stateful enterprise messaging layer that ties it together. Understanding which protocol belongs at which layer prevents the integration confusion that causes many agentic projects to bog down in infrastructure work before any meaningful workflow is built.
Human-in-the-Loop: Where to Place Checkpoints Without Killing Speed
Human oversight is not the enemy of agentic AI speed. Poorly designed human oversight is. The difference between a HITL (human-in-the-loop) architecture that enhances a workflow and one that negates the efficiency gains of automation comes down to where checkpoints are placed, how they’re triggered, and what the SLA is for human response.
The Graduated Autonomy Model
Industry consensus in 2026 has coalesced around a graduated autonomy model for HITL design. New deployments begin at 100% human review — every agent output is reviewed before the workflow proceeds. As the system accumulates reliability data, the review requirement decreases, and the orchestrator learns which categories of decisions can be trusted to proceed automatically and which require human eyes.
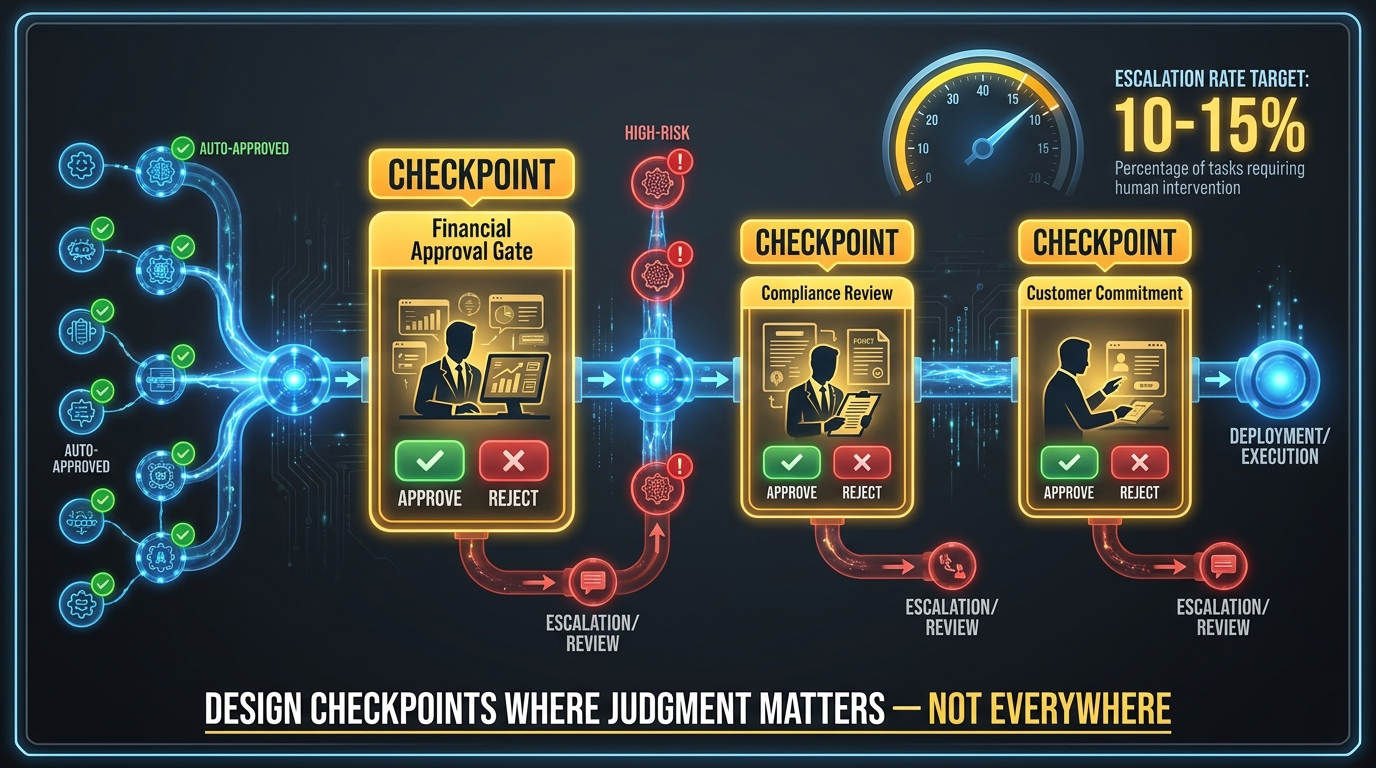
The target escalation rate in a mature deployment is 10–15% of cases. High enough to catch meaningful errors and edge cases. Low enough that the human review burden doesn’t recreate the bottlenecks that agentic AI was deployed to eliminate. AI agents in multi-step workflows fail approximately 70% of the time without any structured human oversight, so the goal isn’t to eliminate HITL — it’s to make it precise and efficient rather than broad and burdensome.
Risk-Stratified Checkpoint Design
Not all decisions carry the same risk, and checkpoint design should reflect this. A useful framework categorizes decisions into three tiers:
Tier 1 — Routine execution (auto-approve): High-confidence, low-stakes decisions where the agent’s accuracy exceeds the 95% threshold. Standard document processing, routine status updates, information retrieval, low-value transaction processing. These should flow without interruption.
Tier 2 — Monitored execution (human-on-the-loop): Moderate-confidence or moderate-stakes decisions where a human monitor is notified but doesn’t need to actively approve before the workflow proceeds. The human can intervene if they notice a problem, but the default is to let the agent proceed. Think: customer commitments within standard policy, moderately complex data synthesis, cross-system data writes.
Tier 3 — Mandatory approval gates (human-in-the-loop): High-stakes or low-confidence decisions that require explicit human authorization before proceeding. Financial transactions above defined thresholds, compliance determinations, PII handling, policy exceptions, anything with irreversible real-world consequences. These checkpoints should have defined SLAs — 15 seconds for low-risk approvals, up to 15 minutes for high-stakes decisions requiring review time.
Checkpoint Architecture Anti-Patterns
Several HITL design mistakes appear repeatedly in failing deployments. Checkpoint flooding — placing mandatory human review at every agent handoff point — effectively recreates the manual process the agentic workflow was supposed to replace, while adding complexity. Silent fallthrough — having no defined behavior when a human doesn’t respond to an approval request within the SLA — causes workflows to either stall indefinitely or proceed without the oversight that was supposed to occur. Context-stripped escalations — routing a decision to a human without the context needed to make an informed judgment — wastes human time and produces low-quality approvals that undermine the entire oversight model.
The regulatory environment is also tightening around HITL requirements. The EU AI Act and NIST’s CAISI framework (published February 2026) both mandate demonstrable, auditable human oversight for high-risk AI applications. This means checkpoint architecture isn’t just an operational efficiency question — it’s increasingly a compliance requirement with legal teeth.
Memory, State, and Context: The Hidden Engine of Multi-Step Workflows
If the orchestrator is the brain of an agentic workflow, memory is its working memory — and most agentic architectures in production today have surprisingly shallow short-term recall and almost no meaningful long-term learning. This is the hidden engine that separates workflows that improve over time from those that make the same mistakes indefinitely.
The Four Memory Scopes
The industry standard for agentic memory architecture in 2026 uses a four-scope model that organizes context by relevance and persistence:
Run scope captures everything relevant to the current workflow execution — the goal, the plan, intermediate results, decisions made, tools called, and their outputs. This is the working memory for a single workflow instance. It should be exhaustive within the current run but doesn’t need to persist after completion (though it should be archived for audit purposes).
Agent scope captures context specific to a particular agent’s operational history — what kinds of tasks it has handled, what patterns it has learned, what edge cases it has encountered. This scope allows an agent to improve its behavior on a specific task type over time without conflating lessons from different task types handled by different agents.
User scope captures context about the human or system that initiated the workflow — preferences, approval history, past interactions, escalation patterns. This is particularly valuable in customer-facing workflows where consistency across interactions builds trust and reduces repetition.
Organization scope captures institutional knowledge — company policies, standard operating procedures, historical workflow outcomes, compliance requirements. This is the long-term organizational memory that new agents can draw on without needing to rediscover institutional knowledge through trial and error.
Context Packaging at Handoffs
How context is packaged when one agent hands off to another is one of the most overlooked engineering decisions in agentic workflow design. A handoff that includes only the immediate task and its inputs leaves the receiving agent flying blind. A well-designed context package includes: the original goal, the progress made so far, the constraints established by upstream decisions, any edge cases or anomalies already noted, the confidence levels attached to intermediate results, and any specific considerations the next agent should be aware of.
Structuring handoff context as a first-class data artifact — rather than an afterthought appended to the task input — dramatically reduces the error rate at handoff points and is one of the highest-leverage improvements an organization can make to an existing multi-agent workflow.
Memory Poisoning: The Security Dimension
Memory architecture has an important security dimension that is frequently ignored until something goes wrong. Agentic AI systems are vulnerable to memory poisoning attacks — where adversarially crafted inputs are designed to contaminate the agent’s memory store with false information, modified preferences, or override instructions that persist across future workflow runs.
NIST’s CAISI framework addresses this through explicit memory provenance requirements — each piece of information in an agent’s memory store should have a traceable origin, and inputs from untrusted sources should be sandboxed rather than ingested directly into persistent memory. Organizations operating in regulated industries or handling sensitive data should treat memory security as a first-order design concern, not a retrofit.
Permission Scoping and Security Architecture
Agentic AI introduces a category of security risk that traditional software systems don’t face: the autonomous action risk. When an agent can call APIs, write to databases, send emails, execute code, and interact with external services on your behalf, the blast radius of a compromised or misbehaving agent is fundamentally different from a compromised static application.
The Least-Privilege Principle for AI Agents
Security teams that have successfully deployed agentic AI at scale in 2026 have converged on a consistent principle: agents should have exactly the permissions they need for their specific function and no more. This sounds obvious, but implementing it requires discipline against the natural tendency to give agents broad permissions to avoid integration friction.
In practice, least-privilege for agents means: dedicated service identities per agent role (not shared credentials), tool allowlists that explicitly enumerate what each agent can call, time-bounded tokens rather than persistent credentials (an agent executing a 30-minute workflow doesn’t need 30-day API credentials), and explicit consent requirements for any action with significant real-world consequences.
Prompt Injection and Agent Hijacking
Prompt injection — where malicious content in data processed by an agent contains instructions that override its intended behavior — is the most widely exploited vulnerability in deployed agentic systems. An agent tasked with processing incoming emails, for example, might receive an email whose body contains hidden instructions designed to exfiltrate data, modify workflow outputs, or trigger unintended actions.
Defense against prompt injection requires more than content filtering. It requires architectural separation between data being processed and instructions being followed, and it requires that the orchestrator maintain a privileged instruction channel that cannot be overridden by data-plane inputs. NIST’s OWASP Agentic Top 10 (published in 2026) addresses this as a primary vulnerability class, and treating it as a first-order design concern rather than a post-deployment patch is essential for enterprise production deployments.
Multi-Agent Trust Boundaries
In a multi-agent system, the security perimeter isn’t just between the system and the outside world — it’s between individual agents within the system. A compromised sub-agent can potentially propagate malicious instructions upward to the orchestrator or laterally to peer agents, particularly in systems with shared memory spaces or loose inter-agent trust models.
Production-grade multi-agent architectures treat inter-agent communication with the same skepticism as any external API call. Agent identity verification (A2A’s Agent Cards mechanism serves this purpose), signed message payloads, and isolated memory scopes per agent all contribute to a defense-in-depth model where a single compromised agent cannot compromise the entire workflow.
Measuring What Actually Matters: ROI Frameworks Beyond Completion Rate
One of the most persistent measurement mistakes in agentic AI deployment is conflating task completion with business value. A workflow that processes 95% of tasks to completion — but where 30% of those completions don’t achieve the intended business outcome — is delivering far less ROI than its completion metrics suggest. Worse, the misleading metric actively prevents the organization from understanding and fixing the real problem.
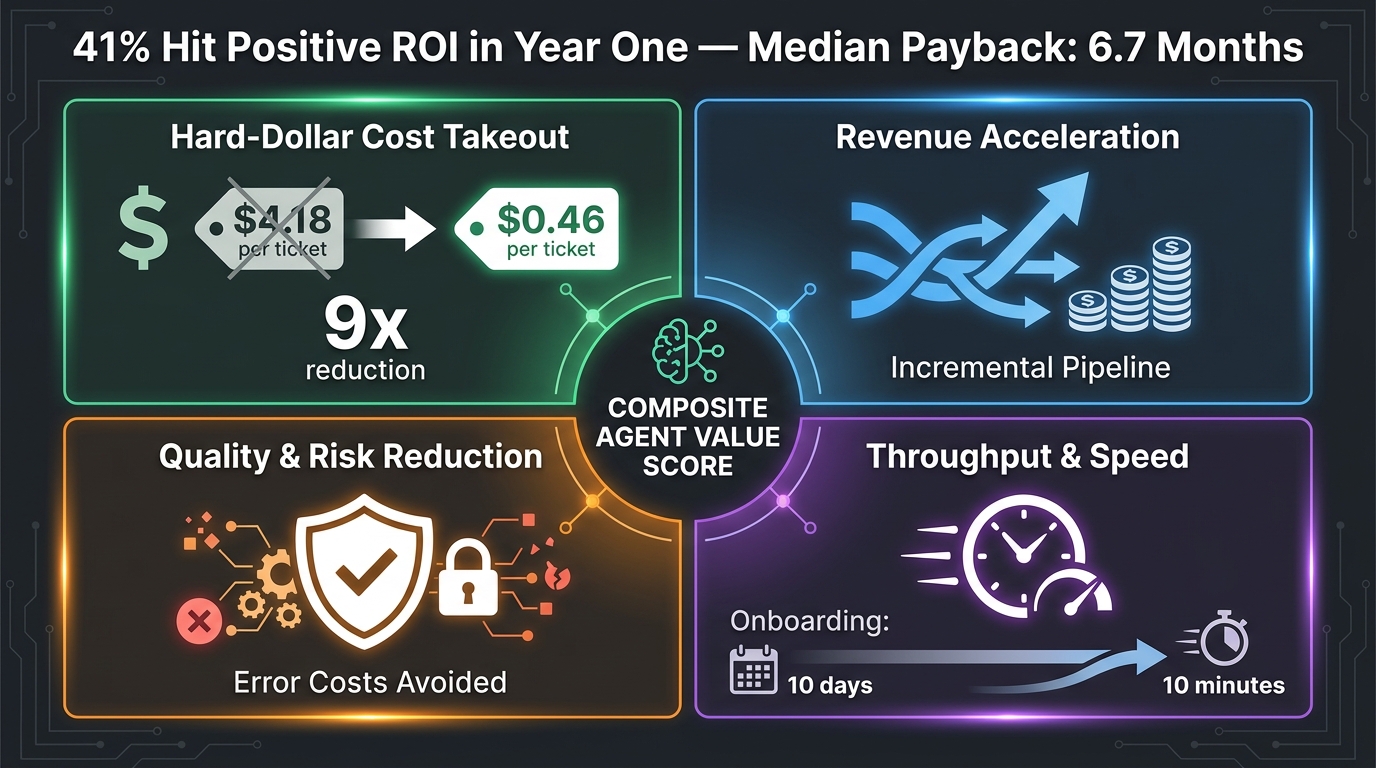
The Four-Pillar ROI Framework
Organizations with mature agentic AI measurement practices in 2026 have largely converged on a four-pillar ROI framework that captures the full value profile of a workflow deployment:
Pillar 1: Hard-dollar cost takeout. The most straightforward pillar — direct cost reduction per unit of work. The benchmark here is striking: AI agent deployments that reach production show cost-per-task reductions ranging from 9x to 66x depending on the use case, with specific examples like customer service ticket resolution dropping from $4.18 to $0.46 per ticket. This pillar requires pre-deployment baseline measurement to be meaningful. Without knowing what the process costs today, you can’t credibly claim cost savings tomorrow.
Pillar 2: Revenue acceleration. Harder to quantify but often larger in dollar terms than cost takeout. This captures incremental revenue that wouldn’t have been generated without the agentic workflow — faster sales cycle completion, better lead conversion from instant response times, upsell identification from comprehensive data synthesis, customer retention improvements from faster issue resolution. Measuring this requires pairing agentic workflow outputs with revenue outcome data, which demands coordination between AI implementation teams and revenue operations.
Pillar 3: Quality and risk reduction. This pillar captures the value of errors avoided, compliance incidents prevented, and decision quality improved. It’s measured via error rates, compliance audit results, and exception frequency — before and after deployment. For workflows operating in regulated industries, this pillar alone can justify deployment costs, as the cost of a single compliance failure often dwarfs the entire implementation budget.
Pillar 4: Throughput and speed. Cycle time reduction and throughput capacity increase. The example that has become a benchmark reference: employee onboarding workflows reduced from 10 days to 10 minutes through agentic orchestration. For operations teams, this pillar translates directly to capacity — the same team can handle significantly more volume without proportional headcount increase.
The Composite Agent Value Score
Leading practitioners are moving beyond pillar-by-pillar measurement toward a composite metric that weights these four pillars based on the strategic priorities of the specific workflow. A customer service deployment might weight Pillars 1 and 4 most heavily. A compliance workflow might weight Pillar 3 above all others. A sales automation workflow might make Pillar 2 the primary success metric.
The composite score also incorporates a critical modifier: the ratio of completion rate to outcome rate. An agent that completes tasks at 95% but achieves the intended business outcome only 70% of the time has an outcome-to-completion ratio of 0.74. This ratio should trend toward 1.0 as the workflow matures. A workflow where this ratio is declining — where more tasks are completing but a smaller proportion are achieving their intended goals — is a signal that something has gone wrong in the refinement layer, even if surface-level completion metrics look healthy.
Productivity Benchmarks for 2026
Beyond the process-level metrics, the broader productivity impact of agentic AI on knowledge workers is becoming measurable. BCG data from 2026 shows an average 2.7x agent multiplier — each knowledge worker operating with agentic AI support effectively operates with 2.7x their previous output capacity. The median hours saved per knowledge worker per week is 6.4 hours (up 64% year-over-year). JPMorgan has documented 360,000 manual hours saved annually across its agentic deployments. Coupa achieved 276% ROI in operations. These aren’t projections — they’re reported outcomes from production deployments.
Real-World Deployments: What Walmart, DHL, and Fountain Got Right
The architecture patterns described in this guide aren’t theoretical. They’re drawn from the actual deployment choices that have produced measurable results in 2026. Three deployments in particular illustrate the principles at work across different industries and use cases.
Walmart’s Agentic Supply Chain
Walmart’s end-to-end agentic supply chain is among the most sophisticated production deployments in retail. The system operates at the goal level — rather than automating specific steps in the supply chain, it manages the overall objective of ensuring product availability across thousands of stores and fulfillment centers. The orchestration layer continuously monitors demand signals, inventory levels, and logistics capacity, anticipating shortfalls before they occur rather than reacting after they’re visible.
When the system detects an emerging demand surge — a weather event increasing demand for certain product categories, for example — it autonomously initiates a coordinated response: adjusting reorder quantities, rerouting in-transit inventory, notifying suppliers, and updating fulfillment routing, all without a human initiating the process. The human oversight role has shifted from initiating and approving individual actions to monitoring system performance and setting the strategic parameters within which the agents operate.
The key architectural decision that makes this work is the clear separation between the orchestration layer (which holds the end-to-end goal and coordinates responses) and the specialized execution agents (which have narrow, well-defined responsibilities and constrained permissions). The orchestrator can trust executor agents to perform their specific functions reliably precisely because those functions are narrow and well-bounded.
DHL and HappyRobot: Logistics Coordination at Scale
DHL’s partnership with HappyRobot deployed agentic AI to handle the coordination-intensive work of warehouse logistics — scheduling truck appointments, handling inbound calls and emails from carriers, coordinating loading dock assignments, and managing the constant flow of exception cases that characterize high-throughput warehousing operations.
The architectural choice that defined this deployment’s success was its treatment of communication channels. Rather than automating only the structured, digital channels and leaving voice and unstructured email to humans, the system was built to handle all communication modalities. An agent answering a carrier’s phone call, extracting the appointment request, cross-referencing dock availability, confirming the booking, and logging the interaction in the warehouse management system represents a genuinely end-to-end workflow — not a partial automation that hands off to a human for the “hard parts.”
Fountain’s Hierarchical Recruiting Workflow
Fountain’s deployment of hierarchical multi-agent orchestration for high-volume recruiting demonstrates the value of matching architecture pattern to problem structure. Recruiting involves multiple parallel workflows (screening candidates across many open roles simultaneously) and multiple sequential workflows (moving individual candidates through stages from application to offer). A flat, single-orchestrator architecture would create bottlenecks in both dimensions.
By implementing a hierarchical model — a meta-orchestrator coordinating role-specific lead agents, each managing their own cluster of candidate-facing executor agents — Fountain achieved 50% faster candidate screening, 40% faster onboarding, and doubled candidate conversion rates. The staffing timeline for high-volume positions compressed from several weeks to under 72 hours. The architectural decision to match the orchestration hierarchy to the natural hierarchy of the recruiting process was the key insight that made these results possible.
The 40% Failure Problem: What’s Actually Going Wrong and How to Avoid It

Gartner’s forecast that more than 40% of agentic AI projects will be canceled by 2027 isn’t a condemnation of the technology. It’s a description of what happens when powerful technology is deployed without the architectural foundations that make it work. The failure patterns are consistent enough that they’re preventable — but only if you know what to look for before you’re in production.
Failure Mode 1: Hype-Driven Deployment Without Process Clarity
“Agent washing” — vendors applying the “agentic” label to products that are functionally advanced chatbots or glorified RPA workflows — has contributed to a wave of deployments that start with the technology and search for the problem afterward. Gartner estimates only around 130 vendors offer genuinely agentic capabilities, yet hundreds are marketing products as such.
The antidote is process-first design. Before evaluating any agentic AI platform, the organization should have documented answers to: What is the specific end-to-end process being targeted? Where are the current bottlenecks and exception points? What does “success” look like in concrete, measurable terms? Organizations that start with these questions, then evaluate technology against their requirements, have dramatically higher deployment success rates than those that start with a vendor demo and work backward.
Failure Mode 2: Governance Gaps That Surface in Production
The McKinsey 2026 AI Trust Survey of approximately 500 organizations found that while average responsible AI maturity has improved, only 30% of organizations reach maturity level 3 or above in strategy, governance, and agentic controls. This gap manifests in production as: agents taking actions outside their intended scope, no clear accountability chain when something goes wrong, audit trails that are insufficient for compliance review, and no defined process for handling the cases that fall outside the agent’s decision authority.
Governance architecture should be designed before the first line of workflow code is written. This means defining agent authority levels, establishing human oversight requirements for each decision tier, creating an audit trail architecture, and establishing clear accountability assignments — which human role is responsible for the outcomes of which agent cluster. McKinsey data indicates that organizations with explicit responsible AI accountability structures achieve significantly higher governance maturity than those treating governance as an implementation phase concern.
Failure Mode 3: Infrastructure Debt That Blocks Scale
Infrastructure issues are cited in 41% of failed deployments — the leading single cause. In most cases, this isn’t inadequate infrastructure per se. It’s infrastructure that wasn’t designed for the specific demands of agentic workflows: high-frequency API calls across many systems simultaneously, stateful sessions that need to persist across hours or days, observability requirements that exceed what was built for the pilot, and latency requirements that emerge only when the workflow is under real load.
The solution is to treat agentic workflow infrastructure requirements as a first-class deliverable, not an afterthought. Specifically: design your observability stack (logging, tracing, alerting) for agents before you need it; load-test not just individual agent components but the full orchestrated workflow under realistic concurrency; and establish your model and API cost monitoring before production, since unexpected inference costs are one of the most common reasons agentic projects lose business case support.
Failure Mode 4: Measuring the Wrong Things
Projects that measure completion rate as their primary success metric frequently look successful until someone asks about business outcomes. The 95% completion rate that drove the project approval is maintained throughout the deployment — but the revenue impact is negligible, the error rate in downstream processes is unchanged, and the business sponsors withdraw support because they can’t connect the metrics to value they care about.
As described in the ROI section above, the fix is establishing business outcome metrics at the same time as technical deployment metrics, with explicit linkage between the two. Completion rate is a useful leading indicator. It is not a measure of value delivered.
Building the Roadmap: From First Agent to Full Workflow in Three Phases
The distance between “we’re experimenting with AI agents” and “we have production agentic workflows delivering measurable ROI” is navigable — but it requires a structured approach that matches architecture complexity to organizational readiness at each stage.
Phase 1 (Months 1–3): Foundation and Validation
The objective in Phase 1 is not to automate at scale. It’s to validate the architecture foundations that everything else will be built on. This means: selecting a single high-value, well-understood process (ideally one with clean data, clear success metrics, and moderate exception complexity) and deploying a single-agent or simple orchestrator-plus-two-executors architecture against it. Run at 100% human review. Build your observability and audit trail infrastructure. Establish your baseline metrics. The goal is to prove that the architectural approach works and that the organization can operate it — not to demonstrate impressive automation numbers.
Phase 2 (Months 4–9): Scale the Architecture, Not Just the Volume
Phase 2 expands the workflow to handle a broader range of cases and begins the graduated autonomy progression — reducing human review requirements as reliability data accumulates. This is also where memory architecture matures: short-term run-scope memory is augmented with agent-scope learning and user-scope personalization. The exception handling architecture is stress-tested against real edge cases and refined. A second use case is introduced, allowing the organization to test whether the orchestration and infrastructure choices from Phase 1 generalize.
Phase 3 (Months 10+): Multi-Agent Orchestration and Continuous Improvement
Phase 3 introduces hierarchical multi-agent architectures for complex, cross-functional workflows, integrates the four-pillar ROI measurement framework with business reporting, and establishes the continuous improvement cycle — using the refinement layer’s evaluation outputs to systematically improve agent performance over time. Organizations that reach Phase 3 with solid foundational architecture begin compounding: each improvement to the workflow’s outcome-to-completion ratio generates returns that weren’t available in earlier phases.
Conclusion: Workflows That Don’t Just Start — They Finish
The most important reframe in agentic AI design is shifting the success criterion from “did the workflow execute?” to “did the workflow achieve its goal?” These sound similar. In practice, they drive entirely different architectural decisions.
A workflow designed around execution will optimize for throughput, minimize interruptions, and measure completion rate. A workflow designed around outcomes will invest in the refinement layer, design checkpoints that protect against consequence rather than procedural deviation, measure the gap between completion and outcome, and use that gap as the primary driver for continuous improvement.
The organizations seeing genuine returns from agentic AI in 2026 have made this reframe. JPMorgan didn’t save 360,000 manual hours by completing tasks faster — they restructured what the tasks were supposed to accomplish and built agents that held themselves accountable to those outcomes. Walmart’s supply chain agents aren’t impressive because they can route inventory. They’re impressive because they’ve reduced the gap between an emerging demand signal and a satisfied customer.
The four-layer architecture, the orchestration patterns, the communication protocols, the HITL checkpoint design, the memory management approach, and the ROI measurement framework described in this guide are not abstract principles. They’re the operational decisions that separate the 11% of organizations with agents in productive deployment from the 79% still struggling to bridge the gap from pilot to production.
The technology will keep improving. The models will get more capable. The protocols will mature. But the workflows that finish the job in 2026 — and in 2027, and beyond — will be the ones built on architectural foundations that were designed, from the first line of orchestration code, to care about outcomes rather than just execution.
Key Takeaways:
- The 68-point gap between AI agent adoption (79%) and production deployment (11%) is an architecture problem, not a technology problem.
- Genuine end-to-end agentic workflows are defined by goal-level accountability, adaptive path execution, cross-system integration, and outcome verification — not just multi-step task completion.
- The four-layer architecture (Interface, Planning, Execution, Refinement) is the structural foundation of every reliable production deployment. The refinement layer — memory, evaluation, feedback — is the one most commonly omitted.
- A2A handles agent-to-agent coordination; MCP handles agent-to-tool access; ACP handles enterprise stateful messaging. Understanding which protocol belongs at which layer prevents costly integration confusion.
- Target HITL escalation rates of 10–15% in mature deployments. Place checkpoints where stakes are high — not everywhere a handoff occurs.
- Measure with the four-pillar ROI framework: cost takeout, revenue acceleration, quality/risk reduction, and throughput. Completion rate alone is not a measure of value.
- The 40% failure rate is driven by governance gaps, infrastructure debt, and measurement misalignment — all preventable with a process-first, architecture-informed deployment approach.