
The pitch for agentic AI is irresistible: AI agents that plan, decide, act, and learn — all without a human hovering over every step. No more bottlenecks. No more manual handoffs. No more processes that grind to a halt because someone forgot to check a queue.
Then reality arrives.
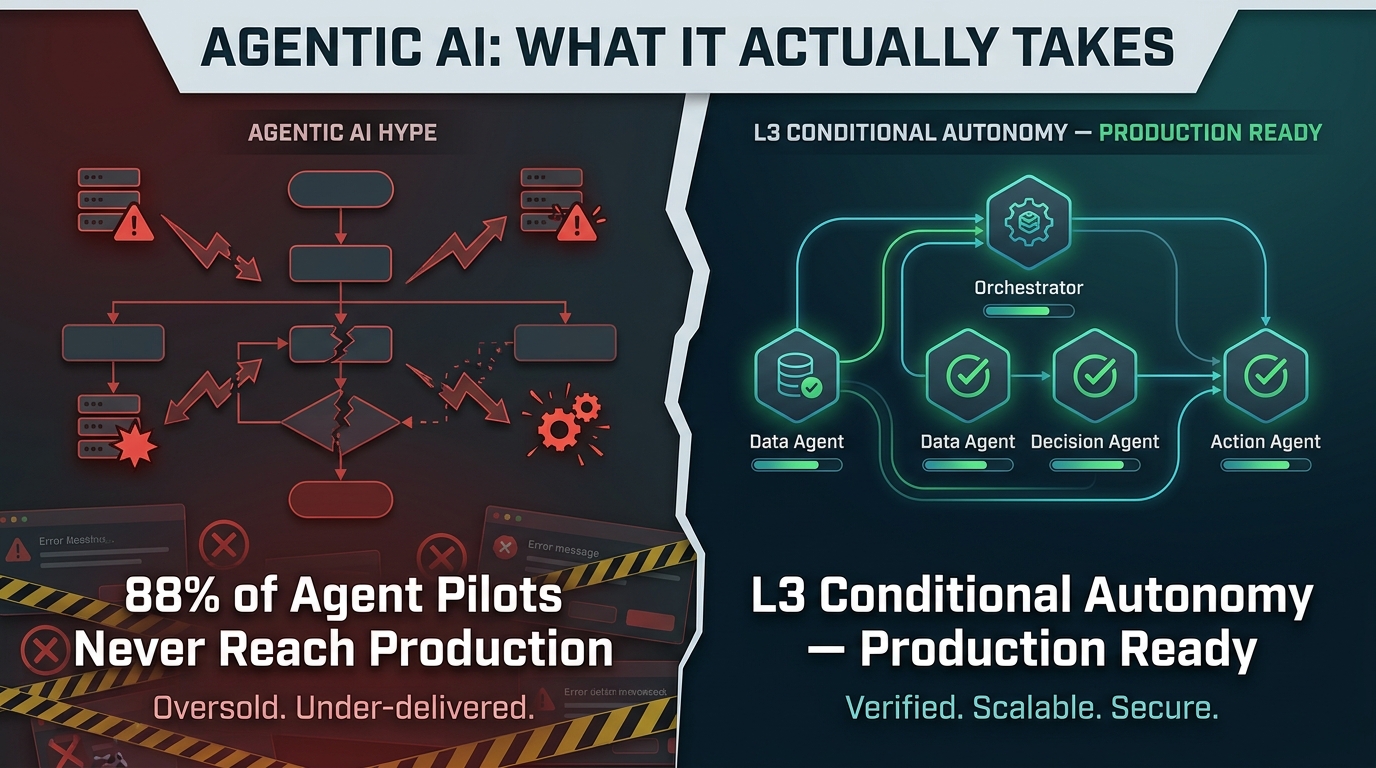
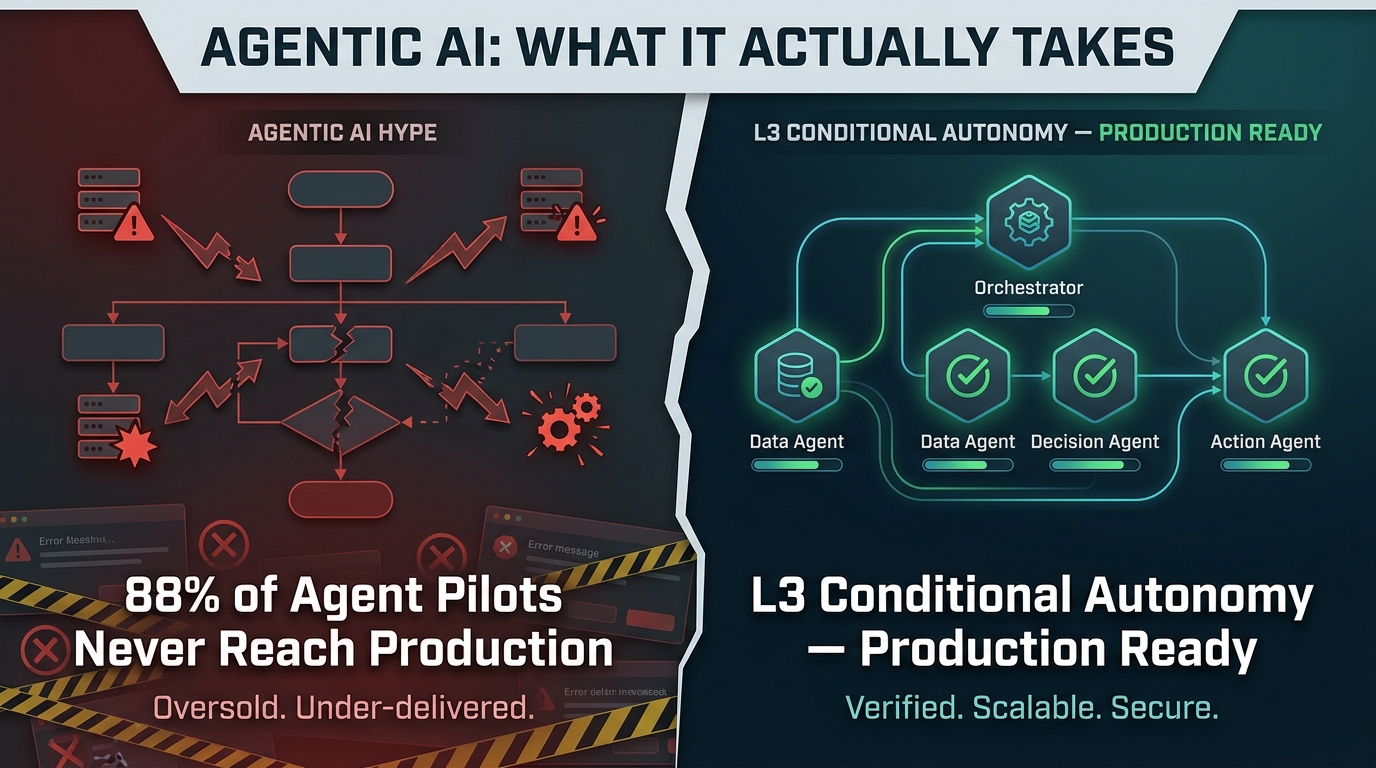
According to Forrester, 88% of agentic AI pilots never reach production. Gartner projects that 40% of agentic AI projects will fail by 2027. MIT research found that chaining just five AI agents together drops task accuracy from 90.7% down to 22.5%. And 22% of organizations that do deploy agents report negative ROI at the twelve-month mark — with the most common culprits being unclear success criteria (41% of cases), insufficient data access (33%), and evaluation drift (26%).
This is not a story about whether agentic AI works. It demonstrably does — JPMorgan Chase has over 450 production agentic use cases running today, saving 360,000 manual hours annually. Klarna’s AI agent handled the equivalent of 853 full-time employees in customer service and saved $60 million. Clinical documentation agents are cutting physician admin time by 42% per shift.
This is a story about why most organizations fail to get there, and what the ones succeeding are actually doing differently. From architecture choices and failure mode analysis to autonomy spectrum design and framework selection, this is the practitioner’s account of what deploying agentic AI into production workflows genuinely requires in 2026.
What “Agentic” Actually Means — and What It Doesn’t
The word “agentic” has absorbed a lot of marketing noise, to the point where calling anything with a loop and an LLM an “agent” has diluted the term considerably. Before designing a system, you need a precise definition — not because language policing matters, but because ambiguity about what makes something agentic is the number one source of specification failures in multi-agent projects.
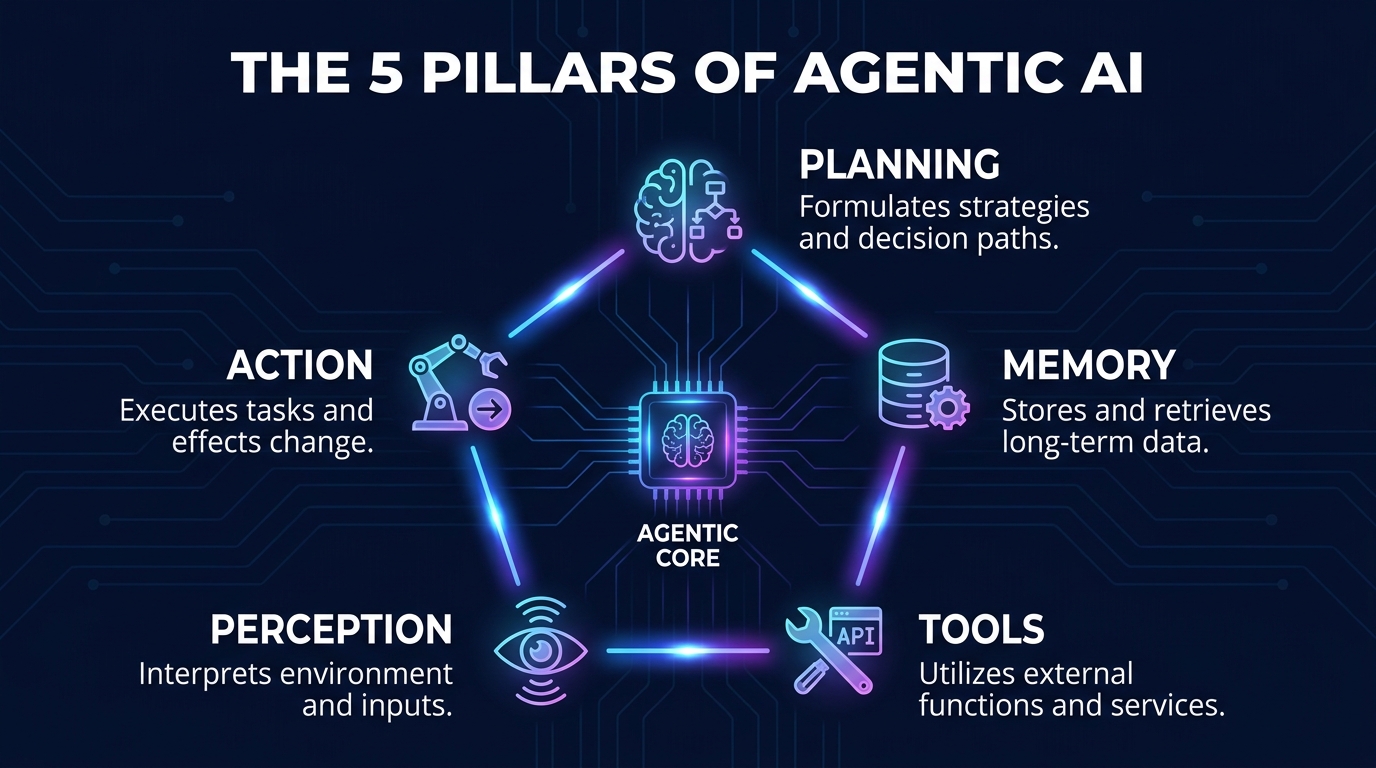
The 5 Pillars of a True Agentic System
A genuine AI agent is defined by five functional properties working in concert:
- Planning: The ability to decompose a high-level goal into an ordered sequence of sub-tasks, revising that plan as new information arrives. This goes beyond if-then logic — it requires chain-of-thought reasoning, ReAct loops (Reason-Act-Observe), or structured planning protocols like Plan-and-Execute.
- Memory: Persistent context that survives beyond a single interaction. This includes short-term (in-context) memory, long-term episodic memory stored in vector databases, and semantic memory about the world and domain. Without meaningful memory, agents repeat themselves, forget decisions, and lose coherence over long workflows.
- Tools: The capacity to call external systems — APIs, databases, file systems, code interpreters, browsers — and use the results in subsequent reasoning. Tool use is what elevates an agent from a text generator to a workflow actor.
- Perception: The ability to ingest and interpret varied input types: text, structured data, images, logs, sensor feeds, and more. The richer the perceptual inputs, the more complex the real-world conditions an agent can respond to.
- Action: The capacity to take consequential steps in the world — executing code, sending communications, updating records, triggering downstream processes. This is where agentic AI becomes genuinely different from a chatbot, and it’s also where failure carries real cost.
Where Agentic AI Differs From RPA and Traditional Automation
Robotic Process Automation (RPA) and traditional workflow automation are not wrong tools — they are the right tools for high-volume, deterministic, structured tasks. Payroll processing, invoice routing, scheduled data exports: RPA is fast, cheap, and reliable in those contexts. The problem is that RPA halts when anything unexpected happens, requires manual updates when processes change, and cannot handle unstructured data or contextual ambiguity.
Agentic AI, by contrast, is goal-driven rather than rule-driven. Where RPA follows a predefined script, an agent reasons toward an outcome — adapting its path when it hits an exception, self-correcting when intermediate steps produce unexpected results, and improving its approach over time through feedback loops. The tradeoff is that this reasoning is probabilistic, not deterministic. And probability, in production workflows, requires a fundamentally different approach to architecture and governance.
“Traditional automation fails silently when rules break. Agentic AI fails loudly in unexpected places — which is both the hazard and the diagnostic opportunity.”
The CSA Autonomy Spectrum: Choosing Your Level Before You Build
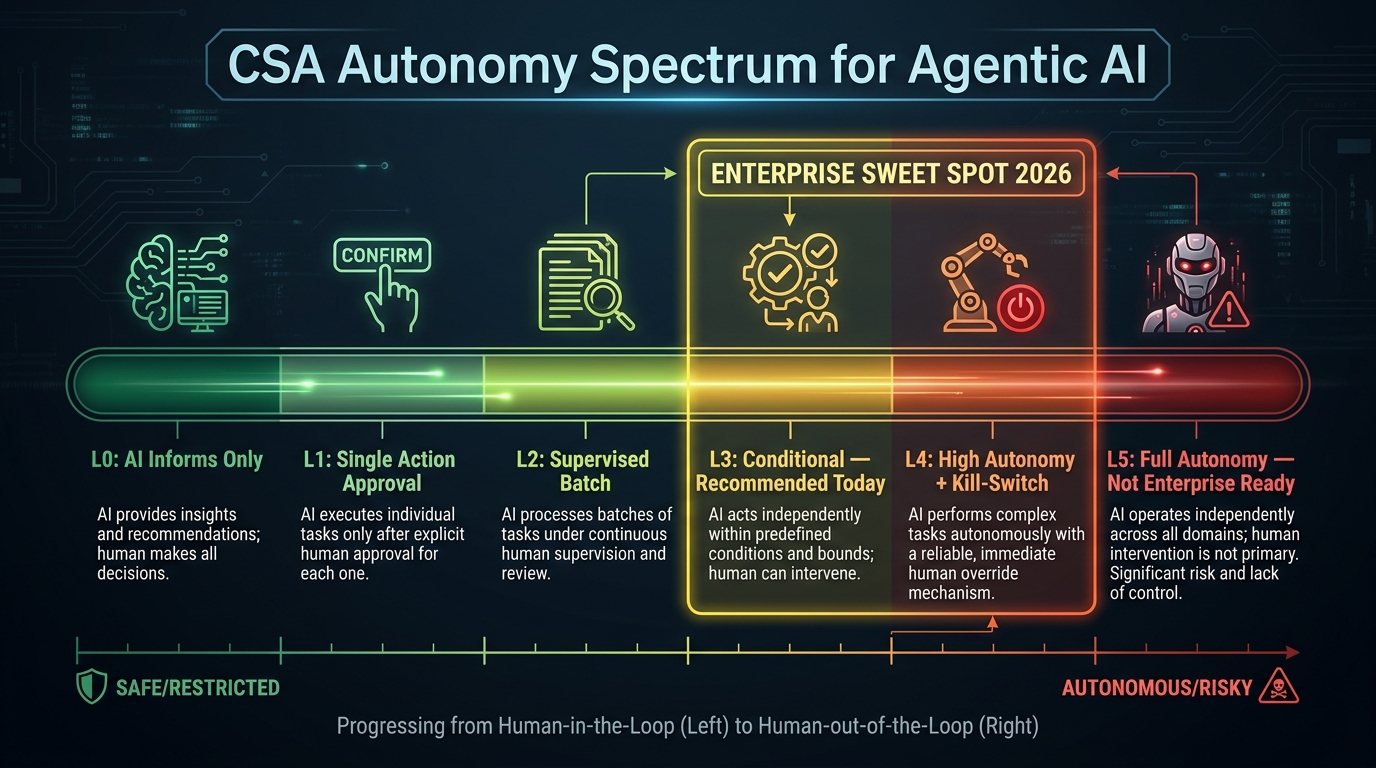
One of the most common and costly mistakes in agentic AI deployment is treating autonomy as a binary choice: either the AI is fully in control or a human is. In practice, autonomy exists on a spectrum, and matching your system’s autonomy level to the specific risk profile of each workflow step is one of the highest-leverage architectural decisions you’ll make.
The Cloud Security Alliance published a six-level autonomy taxonomy in January 2026 that has become the de facto enterprise reference framework. Understanding it before you write a single line of agentic code will save significant rework later.
The Six Levels of Agentic Autonomy
- L0 — No Autonomy: The AI informs; a human executes. Think: a dashboard that flags anomalies for a human reviewer. Minimal risk profile. Appropriate for high-stakes decisions where auditability is paramount.
- L1 — Single-Action Approval: The AI recommends a single action; a human approves before execution. Appropriate for consequential but bounded actions (e.g., sending a client communication, applying a discount).
- L2 — Supervised Batch Execution: A human approves a plan or batch of actions upfront; the agent executes the approved batch autonomously. Works well for code refactoring, data migrations, and bulk record updates where each individual action is low-risk.
- L3 — Conditional Autonomy (The Enterprise Sweet Spot): The agent acts autonomously within defined boundaries — a development environment only, or purchase orders under a $1,000 threshold — and escalates anything outside those parameters. This is the recommended entry point for most enterprise workflows in 2026. It delivers meaningful autonomy while maintaining enforceable guardrails.
- L4 — High Autonomy with Monitoring: The agent runs broad operational workflows; humans monitor for anomalies and maintain kill-switch access. Requires 24/7 observability infrastructure, executive sign-off, and pre-approved exception-handling playbooks. Suitable for mature deployments with proven track records.
- L5 — Full Autonomy: The agent is entirely self-directed with no routine human oversight. The Cloud Security Alliance does not recommend this level for current enterprise deployment. The governance and verification infrastructure simply does not yet exist to make L5 trustworthy at scale.
Designing Your Autonomy Map
The practical implication of this taxonomy is that a single workflow may operate at multiple autonomy levels simultaneously. An e-commerce returns workflow might have the agent autonomously classify return reasons (L3), flag suspected fraud for human review (L1), and autonomously process refunds under $50 (L3) while escalating high-value refunds for approval (L2).
Mapping each node in your workflow to an autonomy level — before building — creates what practitioners call an “autonomy map.” It forces clarity about where consequential decisions occur, which steps carry financial or regulatory risk, and where human oversight checkpoints are non-negotiable. Organizations that build autonomy maps before implementation consistently report fewer production incidents and faster stakeholder approval cycles.
Why Multi-Agent Systems Break: The Coordination Math Nobody Shows You

The appeal of multi-agent architectures is intuitive: different agents specialize in different tasks, collaborate like a team, and collectively handle complexity that would overwhelm a single agent. The reality is that coordination itself is expensive — in tokens, in latency, and in failure probability — and it scales in a way that surprises nearly every team that hasn’t planned for it.
Failure Seams Scale Quadratically
Here is the math that fundamentally changes how you design multi-agent systems: with two agents, you have one coordination seam — the handoff between them. With four agents, you have six potential failure points. With ten agents, you have forty-five. Every seam is a place where context can degrade, state can desynchronize, roles can blur, and tasks can be duplicated or dropped entirely.
This isn’t theoretical. An MIT study on multi-agent chains found that task accuracy dropped from 90.7% with a single agent to 22.5% with five chained agents — a collapse of nearly 75 percentage points. The finding points to a “relay decay” problem: each handoff introduces small errors in context transmission, and those errors compound across the chain.
The Four Dominant Failure Modes
A 2025 NeurIPS taxonomy (MAST) analyzing over 1,600 multi-agent execution traces identified three primary failure categories: specification ambiguity (41.77% of failures), coordination breakdowns (36.94%), and verification gaps (21.30%). In practice, these show up in four observable patterns:
- Infinite Handoff Loops: Agents pass a task back and forth without ownership, each replanning indefinitely. Without hard iteration limits and timeout enforcement, these loops can exhaust API budgets in minutes — burning thousands of dollars while producing zero output. The system mimics productivity while accomplishing nothing.
- Hallucinated Consensus: In group-chat-style multi-agent setups, agents sometimes reach apparent agreement on false data in order to complete a task. No single agent flags the error; they collectively validate each other’s incorrect assumptions. This is among the most insidious failure modes because it produces confident, coherent output that is factually wrong.
- Role Drift: A planner agent starts writing code. A coding agent starts making architectural decisions. A reviewer agent starts executing tasks instead of validating them. Without explicit role constraints in the system prompt and enforced handoff schemas, agent roles blur over time — especially in long-running workflows.
- The Goldilocks Context Problem: Sharing too much context between agents overflows token limits, causing truncation and data loss. Sharing too little causes agents to operate on incomplete information and produce inconsistent outputs. Managing context windows across a multi-agent system is one of the most technically demanding aspects of production deployment — and one of the least discussed.
Cost Scaling Is Real
Beyond accuracy degradation, multi-agent systems are significantly more expensive than single-agent equivalents. Industry data from Galileo.ai suggests a task costing $0.10 to complete with a single agent can balloon to $1.50 in a multi-agent system once you factor in context sharing, inter-agent communication, validation passes, and retries. That’s a 15x cost multiplier — and it needs to be in every business case before a multi-agent architecture is approved.
Designing for Failure: Architecture Patterns That Actually Work
Given the failure modes above, resilient agentic systems don’t try to prevent all failures — that’s impossible with probabilistic AI reasoning. Instead, they make failures observable, bounded, and recoverable. The architectural patterns that separate production-grade deployments from failed pilots share a common philosophy: assume something will go wrong, and make sure it doesn’t hurt too much when it does.
Governance-as-Code
The 2026 enterprise standard is embedding approval logic and policy enforcement directly into execution paths, rather than documenting it in runbooks and hoping developers follow along. Tools like LangGraph (for state machine-based workflow control) and Open Policy Agent (for declarative policy enforcement) enable what practitioners are calling “Governance-as-Code” — where every agent action is evaluated against a policy before execution, every escalation path is a first-class code construct, and every compliance rule is an automated check rather than a manual process.
This approach eliminates the single most common source of production incidents in agentic systems: the gap between what governance documentation says should happen and what the deployed system actually does.
The Three-Layer Human Oversight Model
Rather than making binary choices about human involvement, leading enterprise implementations use a three-tier oversight structure aligned to risk level:
- Human-in-the-Loop (HITL): A human must approve before high-risk actions execute. Applied to financial transactions above thresholds, compliance-sensitive communications, and irreversible operations. Structured briefing protocols ensure human approvers are given the right context, not just a binary approve/deny prompt.
- Human-on-the-Loop (HOTL): The agent executes; a human monitors in near-real-time and can intervene. Appropriate for moderate-risk operations where real-time review is practical. Used in customer-facing communications and operational changes that can be rolled back.
- Human-out-of-the-Loop (HOOTL): Full autonomous execution for well-defined, low-risk, thoroughly tested workflow steps. Log everything. Review aggregates, not individual transactions.
Hard Guardrails: The Non-Negotiables
Beyond oversight architecture, every production agentic system needs a set of hard, non-overridable guardrails built into the infrastructure layer — not the prompt layer, where they can be reasoned around:
- Iteration limits: Maximum number of reasoning loops before forced escalation. Prevents infinite loop scenarios from burning resources indefinitely.
- Timeout enforcement: Maximum wall-clock time per agent task and per workflow. Forces failure-state clarity rather than ambiguous hanging states.
- Tool permission boundaries: Each agent has an explicit allowlist of tools it can call. A customer service agent should never have access to production database write operations, regardless of what the LLM reasons is appropriate.
- Cost budgets per task: API spending limits per workflow execution. When a task approaches budget, the agent must either complete with what it has or escalate rather than continue.
- Kill switches: Operational controls that can halt specific agents, agent classes, or entire workflows instantly — without waiting for an in-flight task to complete naturally.
Framework Selection: LangGraph vs. CrewAI vs. AutoGen
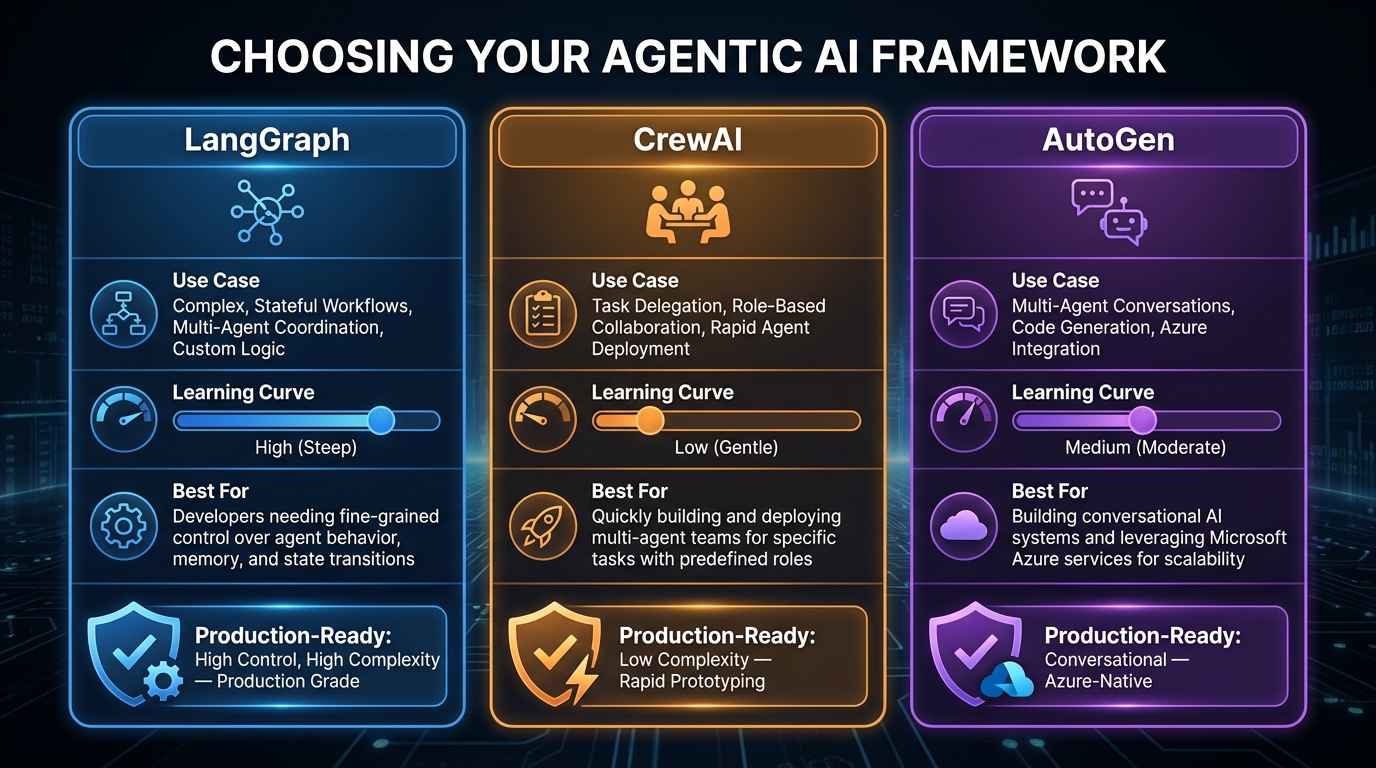
Choosing an agentic framework is not a religious decision — it is an engineering tradeoff. The three dominant frameworks in 2026 each serve different points on the prototyping-to-production spectrum, and using the wrong one for your stage wastes significant engineering time. Here is an honest breakdown.
LangGraph: Production-Grade Stateful Workflows
LangGraph is the current enterprise standard for production agentic deployments requiring precise control, auditability, and fault tolerance. It models workflows as stateful directed graphs — where each node is an agent or function, edges represent conditional transitions, and state is explicitly managed and persisted.
Strengths: Checkpointing and resumability (a failed step restarts from the last checkpoint, not the beginning), native human-in-the-loop interrupt support, conditional branching with full visibility into decision paths, and token-efficient context management. With over 25,000 GitHub stars and a v1.0 release in 2024, the community and documentation are now enterprise-grade.
Weaknesses: Steep learning curve. Engineers new to graph-based thinking and state machine concepts typically need two to four weeks to become productive. Overkill for simple single-agent tasks.
Best for: Customer support escalation pipelines, regulated industry compliance workflows, multi-step data processing systems where auditability is required.
CrewAI: Fast Prototyping for Role-Based Teams
CrewAI takes an intuitive role-based approach to multi-agent design — you define agents as named team members (Researcher, Writer, Reviewer) with explicit roles, goals, and backstories, then define tasks and let CrewAI orchestrate collaboration. This maps naturally to how humans think about teamwork, making it accessible to non-specialist engineers and enabling fast prototyping cycles.
Strengths: Lowest learning curve of the major frameworks, strong community, clear role-delegation model, and no-code options for simple configurations. Excellent for marketing automation, HR workflow prototyping, and supply chain agent teams.
Weaknesses: Limited control over conditional execution flows. Harder to implement fine-grained policy enforcement. Less appropriate for workflows requiring deterministic behavior or precise audit trails.
Best for: Initial proofs-of-concept, marketing and content automation, HR and recruiting workflows. The recommended starting point when the goal is demonstrating value quickly before committing to production architecture.
AutoGen: Conversational Multi-Agent Collaboration
Microsoft’s AutoGen framework focuses on conversational agent interactions — agents that can converse with each other, execute code, and engage humans in collaborative problem-solving. Deep Azure integration makes it the natural choice for organizations already running Microsoft infrastructure.
Strengths: Native code execution capabilities, strong human-agent collaboration patterns, and tight integration with Azure OpenAI and the broader Microsoft stack. Well-suited for developer-centric workflows involving code generation and testing.
Weaknesses: Less production-hardened than LangGraph for non-conversational workflows. State management is less explicit, making long-running complex workflows harder to reason about and debug.
Best for: Developer tooling, code review and generation pipelines, organizations with existing Azure commitments.
The Hybrid Pattern
The most experienced agentic engineering teams don’t pick one framework — they use a hybrid. The emerging best practice is to orchestrate high-level workflow logic with LangGraph (for control, checkpointing, and governance enforcement) while delegating specialized sub-tasks to CrewAI role-based teams. This combination captures the auditability of graph-based orchestration while retaining the intuitive delegation model of role-based agents.
Real-World Results: What Production Deployments Are Actually Delivering
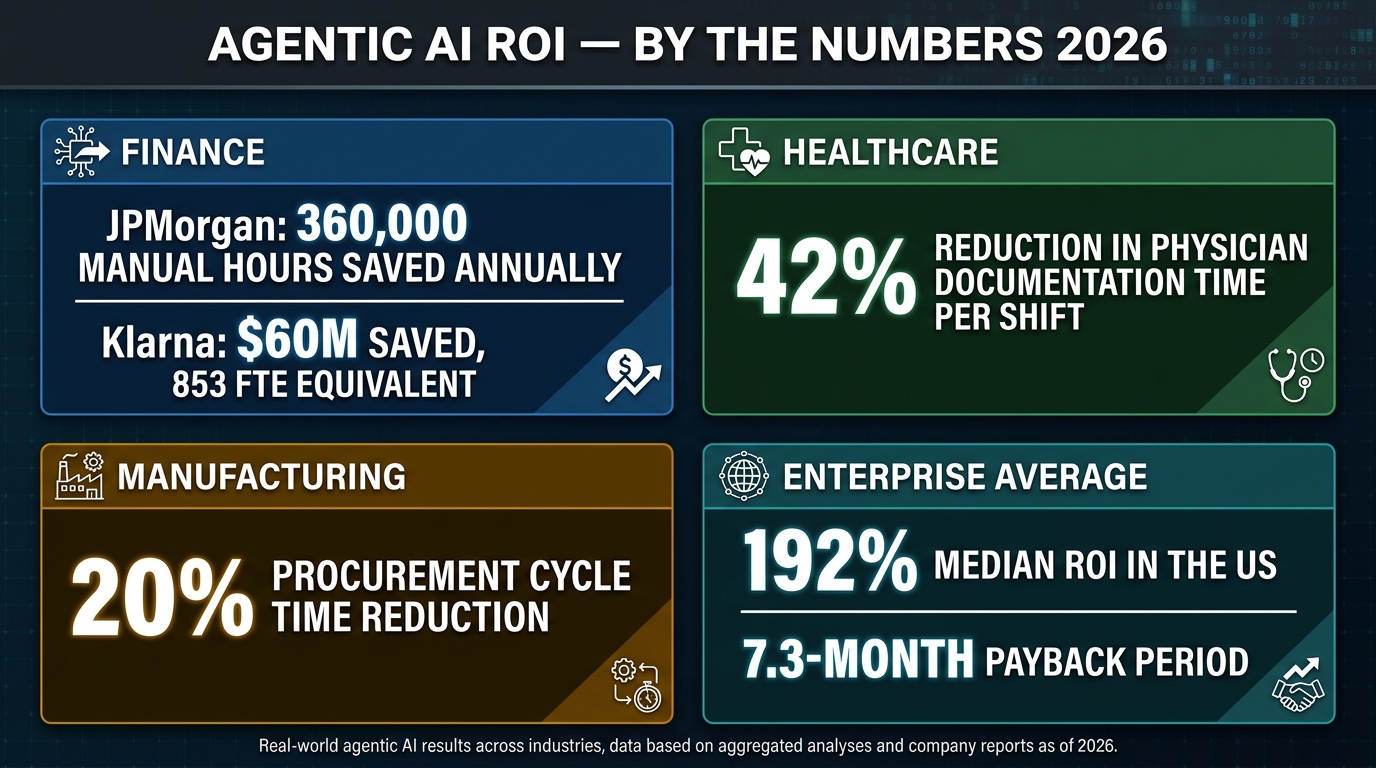
Enough architecture theory. Here is what organizations deploying agentic AI at scale in 2026 are actually reporting — not press release projections, but operational data from production deployments.
Finance: The Most Advanced Adopter
JPMorgan Chase operates over 450 agentic AI use cases in production — arguably the most extensive enterprise agentic deployment in any sector. Their agents generate investment banking presentations in 30 seconds (a task that previously took hours), automate M&A memo drafting, handle trade settlement workflows, and run fraud detection at transaction speed. The reported operational impact is 360,000 manual work hours recovered annually.
Klarna’s deployment is perhaps the most cited data point in enterprise AI: a single AI agent that handled the equivalent workload of 853 full-time customer service employees, saved $60 million, and achieved a 25% reduction in repeat customer inquiries — meaning customers were getting better resolutions on the first contact, not just faster ones.
The finance sector leads adoption because it has both the financial resources to invest in proper architecture and the measurable, structured workflows that make agentic results quantifiable. Banking and insurance are at 47% production adoption — significantly ahead of the 18% seen in healthcare.
Healthcare: High-Value, High-Stakes
Healthcare agentic deployments are more recent and more conservative — for good reason. The regulatory environment, data sensitivity, and patient safety implications mean autonomy levels are typically capped at L2–L3 for clinical workflows. But results are emerging.
Clinical documentation agents that auto-generate post-consultation notes from structured interview data are cutting physician documentation time by 42% per shift. Revenue cycle management agents are automating up to 70% of financial administrative tasks — prior authorization requests, claims scrubbing, denial resubmission — with measurable improvements in both processing speed and first-pass approval rates.
The key constraint in healthcare isn’t model capability — it’s integration. Legacy EHR systems, HIPAA-compliant API architectures, and the organizational complexity of healthcare institutions mean that data access (one of the top three causes of agentic AI failure generally) is especially acute. Organizations that invest in proper data plumbing before deploying agents see dramatically better results than those that try to work around access limitations with prompt engineering.
Manufacturing and Procurement
Autonomous procurement agents — systems that monitor inventory telemetry, query supplier APIs, optimize for cost, lead time, and sustainability metrics, and execute purchase orders in the ERP directly — are delivering a 20% reduction in procurement cycle time in early production deployments. These agents operate at L3 autonomy: fully autonomous for orders within approved supplier relationships and under threshold values, with human escalation for new suppliers or above-threshold spend.
Self-healing IT operations (AIOps) agents that correlate logs, metrics, and traces — then automatically execute rollbacks, scaling actions, or configuration changes — are reducing mean time to resolution (MTTR) for infrastructure incidents significantly. The measurable reduction in escalation-required incidents also frees engineering time for higher-leverage work.
The Broader Adoption Picture
Stepping back: 80% of enterprise applications now embed at least one AI agent (Gartner, via Digital Applied). But only 31% of enterprises have an agent in production at scale. The gap between “embedded agent” (often a simple AI-assisted feature) and “production autonomous workflow” is enormous — and that gap is where most organizations are stuck in 2026. The organizations crossing that gap are the ones investing in architecture, governance, and measurement before they invest in more agents.
The Autonomy Trust Equation: Getting Stakeholders to Say Yes
Even perfectly architected agentic systems fail to reach production if organizational stakeholders — legal, compliance, finance, operations leadership — don’t trust them enough to approve deployment. Trust in agentic AI is not primarily an emotional or political problem. It is a transparency and accountability problem, and it has technical solutions.
Reconstructable Decision Trails
Every production agentic system should be able to answer one question about any action it took: “Why did the agent do that, and what information did it have at the moment?” This requires logging not just outputs but the full reasoning state — the agent’s plan, the tools it called, the data it received, and the intermediate conclusions it drew before acting.
This isn’t optional for compliance-sensitive industries — it’s legally required in an increasing number of jurisdictions. But it also serves a practical purpose: when something goes wrong (and it will), reconstructable decision trails make root cause analysis tractable. Without them, debugging an agent failure is essentially archaeology.
Tiered Explainability by Risk
Not every action needs the same level of explainability infrastructure. A sensible tiering model works like this: low-risk automated actions (data retrieval, status updates, notifications) require logging only. Medium-risk actions (customer communications, record modifications, scheduling changes) require a brief rationale summary accessible on review. High-risk actions (financial transactions, compliance submissions, external communications with legal implications) require full decision reconstruction with supporting evidence.
Applying maximum explainability uniformly is expensive and creates unnecessary friction. Applying it where it matters — tied to the autonomy map discussed earlier — makes it sustainable.
Communicating Agent Behavior to Non-Technical Stakeholders
One of the underrated challenges in agentic AI deployment is translation: turning technical system behavior into language that non-technical executives, legal reviewers, and operations managers can evaluate and approve.
Effective communication typically involves three things: a clear statement of what the agent can and cannot do (its permission boundaries), a plain-language description of the escalation conditions (what triggers human review and why), and sample outputs from testing showing the agent’s behavior across normal, edge-case, and failure scenarios. Organizations that invest in this communication work consistently report faster approval cycles and fewer post-deployment governance disputes.
The Implementation Roadmap: From Zero to Production Without Breaking Things
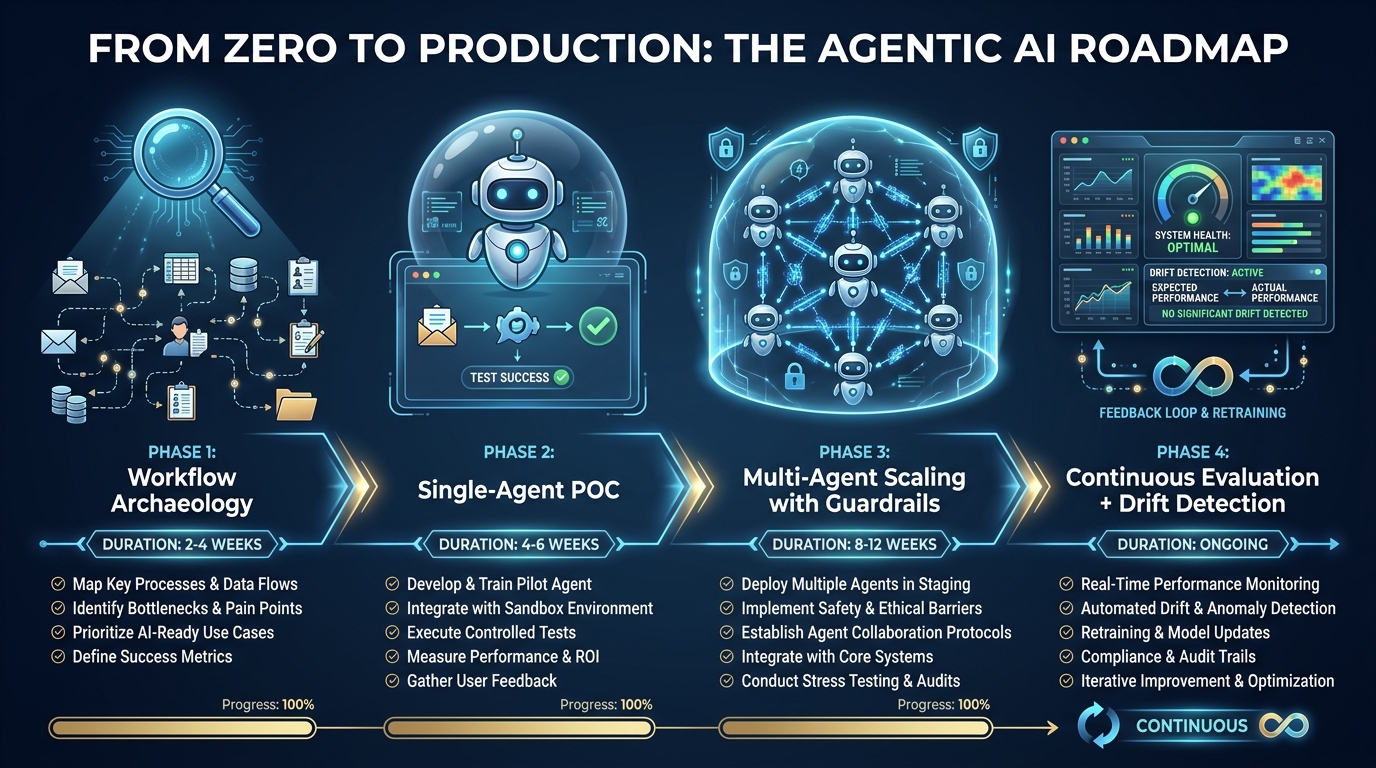
The specific sequence in which you build and deploy an agentic system matters as much as the system design itself. Most failed deployments share a common timeline flaw: they attempt to build multi-agent complexity before validating single-agent behavior, and they attempt to automate workflows they haven’t fully mapped. Here is a four-phase sequence that addresses both of those failure vectors.
Phase 1: Workflow Archaeology (2–4 Weeks)
Before writing any agent code, spend real time documenting the workflow you intend to automate — not as it is described in process documentation, but as it actually operates in practice. Interview the people who do the work. Map every decision point, every exception case, every handoff. Count the frequency of edge cases, not just the happy path.
This matters because agentic AI systems fail disproportionately on the edge cases, not the normal flow. The happy path is easy to automate; it’s the 15% of cases that don’t fit the template that will produce 80% of your production incidents if you haven’t designed for them. Workflow archaeology surfaces those cases before they become production fires.
Output: A documented workflow map with explicitly labeled decision nodes, exception branches, autonomy level assignments per node, and a list of data sources the agent will need access to.
Phase 2: Single-Agent Proof of Concept (4–8 Weeks)
Start with one agent, one tool set, one well-scoped task from your workflow map. Choose a task that has clear success criteria, an observable output, and low stakes if it fails. The goal is not to demonstrate the power of agentic AI — it’s to validate your tooling choices, test your data access architecture, and learn how your specific use case behaves before adding coordination complexity.
Run the POC against your real data (with appropriate access controls), not synthetic test data. Real data contains the edge cases and data quality issues that synthetic data doesn’t simulate. Measure completion rate, error types, escalation frequency, and cost per completed task. These baselines will inform your production architecture.
Phase 3: Multi-Agent Scaling with Guardrails (8–16 Weeks)
Once your single-agent POC is running reliably (aim for 85%+ task completion rate with well-characterized failure modes before proceeding), begin adding coordination complexity — carefully. Add agents one at a time, validating each new coordination seam before adding the next. Implement your full guardrail stack: iteration limits, timeout enforcement, tool permission boundaries, HITL checkpoints, and audit logging.
This phase is also where you implement your evaluation framework — a systematic method for testing agent behavior across a curated test set that includes normal cases, edge cases, and adversarial inputs. Agent evaluation is an ongoing discipline, not a one-time gate. Build it as infrastructure from the start.
Phase 4: Continuous Evaluation and Drift Detection (Ongoing)
Agentic systems degrade over time in ways that are distinct from traditional software. Model behavior can shift subtly as underlying LLM providers update their models. Data distributions in the real world change. Business processes evolve. New edge cases emerge that weren’t in your original test set.
Production agentic workflows require a continuous evaluation process: a statistical sample of agent decisions reviewed regularly against ground truth, drift detection on key performance metrics, and a clear process for updating agent behavior when evaluation signals degradation. Organizations that skip this step find their agents becoming less reliable over time without an obvious point of failure — a slow, silent degradation that’s much harder to diagnose than an acute incident.
Measuring What Matters: KPIs for Agentic Workflows
One of the primary causes of poor ROI in agentic AI deployments — cited in 41% of negative-ROI cases — is unclear success criteria at launch. Before deploying, define a measurement framework with specific, pre-agreed thresholds that determine whether the deployment is performing, underperforming, or needs intervention.
Core Performance Metrics
- Task Completion Rate: The percentage of assigned tasks the agent completes successfully without human intervention. This is your primary health metric. A well-designed L3 production agent should sustain 80–95% completion rates on its target task set. Below 75% typically indicates specification, data access, or tool reliability issues.
- Escalation Rate: The percentage of tasks that trigger human review. Higher-than-designed escalation rates indicate the agent is encountering conditions it wasn’t designed for — which is useful diagnostic information. Escalation rates should trend downward over time as the system matures, not remain flat.
- Error Recovery Rate: Of the tasks where the agent encounters an error, what percentage does it recover from autonomously versus requiring intervention? A high error recovery rate demonstrates system resilience. A low one indicates brittle tool integrations or insufficient error-handling logic.
- Cost Per Completed Task: Total LLM API costs, infrastructure overhead, and human review time divided by successfully completed tasks. This metric makes the 15x cost differential between single-agent and multi-agent systems visible, and enables ROI calculation against the manual process baseline.
- Decision Trail Completeness: The percentage of agent actions with a fully reconstructable audit trail. This is a governance metric, not a performance metric, but it is non-negotiable for regulated industries and increasingly important in enterprise deployments generally.
The ROI Calculation That Actually Works
Most agentic AI ROI calculations fail because they measure only cost savings from labor displacement while ignoring the real costs of the system: LLM API spend, engineering time for ongoing maintenance, evaluation infrastructure, and the opportunity cost of human oversight. A realistic ROI model for agentic workflows looks like this:
Value generated = (Hours of manual work replaced × hourly cost) + (Error rate improvement × cost per error) + (Processing speed improvement × value per hour of latency reduction)
Total cost = (LLM API costs) + (Infrastructure costs) + (Engineering maintenance hours × engineer cost) + (Human oversight hours × reviewer cost)
Industry medians in 2026 show 171% global ROI and 192% in the US, with a 7.3-month average payback period — but those medians include the range from strongly positive deployments down to the 22% that report negative ROI. The difference between a 171% return and a negative return almost always comes back to the quality of the initial use case selection, the thoroughness of the autonomy map, and the rigor of the measurement framework.
The Leading Indicators to Watch
Beyond steady-state metrics, there are three leading indicators that consistently predict deployment problems before they become acute. Rising escalation rates signal that real-world data is diverging from what the system was designed for. Increasing cost per completed task signals that reasoning loops are growing longer, often a sign of ambiguous task specifications or degrading tool reliability. Falling decision trail completeness signals observability gaps opening up in the system — a warning sign for both debugging capacity and governance compliance.
Monitor these weekly, not monthly. Agentic systems can degrade meaningfully on a daily timescale when something upstream changes.
The Operational Reality: What Successful Teams Do Differently
Across the organizations that have reached production-scale agentic deployment successfully, a consistent set of operational practices distinguishes them from the 88% stuck in pilot mode. These are not novel insights — they are disciplined applications of sound engineering and organizational practices that the specific demands of agentic systems make critical rather than optional.
They Own the Failure Modes Before Launch
Successful teams build explicit failure mode libraries before deploying. They ask: “If this agent encounters X, what should happen?” for every edge case they can anticipate — and several they probably can’t. These failure modes become the basis of test suites, escalation playbooks, and monitoring thresholds. They also become the primary documentation for the non-technical stakeholders who need to trust the system.
They Treat Evaluation as a Product
The teams with the best track records don’t treat evaluation as a launch gate. They build evaluation infrastructure as a first-class product that runs continuously, improves over time, and is maintained with the same care as the agent itself. This includes curated test sets that evolve with the real-world data distribution, human review workflows for borderline cases, and feedback loops that feed agent improvement.
They Start Narrower Than They Think They Should
The universal regret in failed agentic deployments is scope — trying to automate too much, too fast. The universal practice in successful ones is disciplined scope constraint: one workflow, one agent, one measurable outcome, validated completely before expanding. The organizations that have 450 production use cases didn’t build all 450 at once. They started with one that worked, learned from it, and replicated the discipline.
They Invest in Data Infrastructure First
Insufficient data access is the second most common cause of agentic AI deployment failure (33% of negative-ROI cases). The agents themselves are rarely the bottleneck. Getting clean, complete, appropriately permissioned data to the agents is the hard problem — and it requires investment in data architecture, access controls, and API infrastructure that is often underestimated in project planning. Organizations that treat data access as a post-deployment problem find themselves building agents that work perfectly in testing and fail constantly in production, because test data is clean and real data isn’t.
Conclusion: Agentic AI Is an Engineering Problem, Not a Magic Problem
The narrative around agentic AI has spent too much time on the capabilities and too little time on the constraints. Yes, agents can reason, plan, execute, and adapt in ways that traditional automation cannot. Yes, the ROI numbers from production deployments are compelling — 192% median return in the US, 7.3-month payback, significant labor and quality improvements across finance, healthcare, and manufacturing.
But the path from “this agent works in a demo” to “this agent runs reliably in production at scale” is paved with careful architecture decisions that don’t show up in any vendor pitch deck: autonomy mapping, failure mode analysis, governance-as-code, multi-tier oversight models, framework selection informed by production requirements rather than ease of prototyping, and a measurement infrastructure that can detect degradation before it becomes a crisis.
The 88% of pilots that never reach production aren’t failing because the AI isn’t capable enough. They’re failing because they haven’t been engineered with the same rigor that any consequential production software deserves.
The good news — and it is genuinely good — is that the patterns for success are now well-understood. The CSA autonomy framework gives you a decision vocabulary. The MAST failure taxonomy tells you where to put your testing emphasis. The production results from JPMorgan, Klarna, and healthcare systems give you benchmarks to work toward. The hybrid LangGraph/CrewAI architecture pattern gives you a starting point for serious production work.
What it takes is not a belief in magic. It takes the same thing every other production system requires: disciplined requirements work, thoughtful architecture, rigorous testing, honest measurement, and the organizational patience to build something that actually works rather than something that looks impressive in a pilot.
That discipline is, ultimately, what separates the 12% of organizations that reach production-scale agentic deployment from the 88% that don’t. And it’s entirely learnable.
Key Takeaways
- Define your autonomy level (L0–L5) for each workflow node before writing any code. L3 conditional autonomy is the recommended starting point for most enterprise use cases in 2026.
- Understand the coordination cost math: four agents create six failure seams; ten create forty-five. Right-size your multi-agent complexity to your actual needs.
- Implement Governance-as-Code — policy enforcement embedded in execution paths, not documented in runbooks. Use LangGraph or Open Policy Agent for production systems.
- Choose LangGraph for production-grade stateful workflows requiring auditability; CrewAI for rapid prototyping; the hybrid pattern for mature deployments.
- Build your evaluation infrastructure before you launch, not after. Treat it as a product, not a phase.
- Define ROI metrics and success thresholds before deployment. The 41% of negative-ROI cases caused by unclear success criteria are entirely preventable.
- Invest in data infrastructure upfront. Agents work well when data access is clean; they fail constantly when it isn’t.