


AI governance platform vendors are very good at one thing: making their software look indispensable during a sales demo. The dashboards are crisp. The risk scores update in real time. The compliance coverage looks comprehensive. The integrations slide shows every tool your team already uses. And then you sign a contract, try to deploy it against your actual systems, and discover that what you saw in the demo was a curated environment with clean data, pre-configured models, and none of the mess that characterizes real enterprise AI operations.
This is not a niche problem. According to recent analyses, 87% of AI projects fail to reach production, and fewer than 25% of AI governance pilots scale enterprise-wide. A significant portion of those failures trace back to inadequate evaluation during the pilot phase — organizations picking platforms based on feature lists and demo aesthetics rather than tested performance under genuine operating conditions.
Meanwhile, the pressure to move is real. Spending on AI governance platforms is projected to reach $492 million in 2026, driven by the EU AI Act’s August 2, 2026 enforcement deadline for high-risk systems, alongside the Colorado AI Act, NIST AI RMF adoption, and ISO 42001 certification demand. Organizations that don’t have functioning governance infrastructure in place are increasingly exposed — both to regulatory penalties that can reach EUR 35 million or 7% of global turnover, and to operational risk from unmanaged AI systems causing costly errors.
This guide is not about which platform to buy. It’s about how to run a pilot that actually tells you whether a platform is right for your organization — before you’re locked into a multi-year contract with software that looked better than it performs.
Why Most AI Governance Pilots Fail Before They Even Begin
The failure mode most organizations encounter isn’t technical. It happens in the weeks before a single line of configuration is written, in the decisions — and indecisions — that shape what the pilot is actually trying to prove.
The “Evaluate Everything” Trap
The most common pre-pilot mistake is scope inflation. A procurement committee identifies six candidate platforms. Someone suggests running all six in parallel “so we can compare them properly.” Three months later, the team has shallow data on six tools and no actionable decision. Pilots that try to evaluate everything simultaneously produce noise, not signal.
A disciplined pilot evaluates one or two platforms at a time, against a single defined workflow, with clear success criteria established before the trial begins. This is not how most enterprise technology evaluations work. But AI governance platforms require it, because the complexity of the domain means breadth of coverage destroys depth of insight.
Defining Success After the Pilot Ends
The second pre-pilot failure is arguably more damaging: entering a pilot without agreed-upon success criteria. This leaves the door open for confirmation bias to dominate the post-pilot analysis. Teams that wanted to buy a particular platform will find reasons the pilot succeeded. Teams resistant to adding compliance tooling will find reasons it failed. Without pre-registered metrics and thresholds, the pilot becomes a Rorschach test.
Before any pilot begins, the organization needs documented answers to three questions: What does success look like at Day 30, Day 60, and Day 90? What specific evidence would constitute a failure? And what is the minimum acceptable performance threshold that would justify moving to full deployment?
Underestimating Integration Complexity
Governance platform vendors consistently understate how much integration work a real deployment requires. The demo environment uses sanitized data pipelines and pre-built connectors. Your environment has legacy systems, custom-built models, undocumented data flows, and AI tools that were deployed by individual departments without IT oversight. Post-deployment governance costs 3–5x more than upfront integration when organizations skip proper pilot-phase integration testing. That cost multiplier is what happens when you discover integration problems after signing.
Building the Right Pilot Team: Who Needs to Be in the Room
AI governance is cross-functional by nature, which means governance platform pilots are almost always staffed incorrectly. The typical configuration — IT lead, a compliance analyst, and a vendor success manager — misses the people whose buy-in will determine whether the platform gets adopted or shelved.
The Core Pilot Team
An effective pilot team has five roles, and none of them are optional.
Executive Sponsor: Organizations with CEO or C-suite-level sponsorship are 5x more likely to achieve ROI from AI governance investments. The executive sponsor doesn’t attend daily standups, but they do attend phase-gate reviews and have the authority to make go/no-go decisions based on pilot results rather than sunk cost reasoning.
Day-to-Day Owner: This is the person who manages the pilot operationally — schedules the work, tracks milestones, escalates blockers, and writes the internal assessment at the end. They should have enough technical credibility to evaluate the platform’s capabilities and enough organizational standing to get time from busy stakeholders.
Legal and Compliance Representative: Not to rubber-stamp the evaluation — to actively test it. The compliance representative should be the one probing the platform’s regulatory coverage, testing whether audit trails actually satisfy the documentation requirements of the EU AI Act or NIST AI RMF, and identifying gaps between what the vendor claims and what the tool actually produces.
Engineering or Data Science Lead: Someone who works directly with the AI systems the platform is meant to govern. Their job is to stress-test integrations, push the platform against edge cases, and evaluate whether the monitoring capabilities would actually detect the failure modes your organization is most likely to encounter.
End-User Representative: The person who will use the platform day-to-day for model documentation, risk assessments, or policy enforcement. User adoption is one of the most predictive indicators of long-term governance platform success — targeting 70%+ adoption is a standard KPI for pilots that intend to scale. If the platform is unusable for the people doing the actual governance work, adoption will collapse regardless of how impressive the feature set looked in the demo.
The Stakeholder Alignment Meeting That Most Pilots Skip
Before the pilot begins, convene a structured stakeholder alignment session with all five roles. The agenda should cover: what problem the organization is actually trying to solve (be specific — “we need to comply with the EU AI Act” is not specific enough), what good looks like at the end of 90 days, who has authority to make the final purchase decision, and what happens if the pilot results are inconclusive. Getting these agreements documented in advance removes the most common causes of pilot dysfunction.
The AI Inventory Problem: You Can’t Govern What You Can’t See
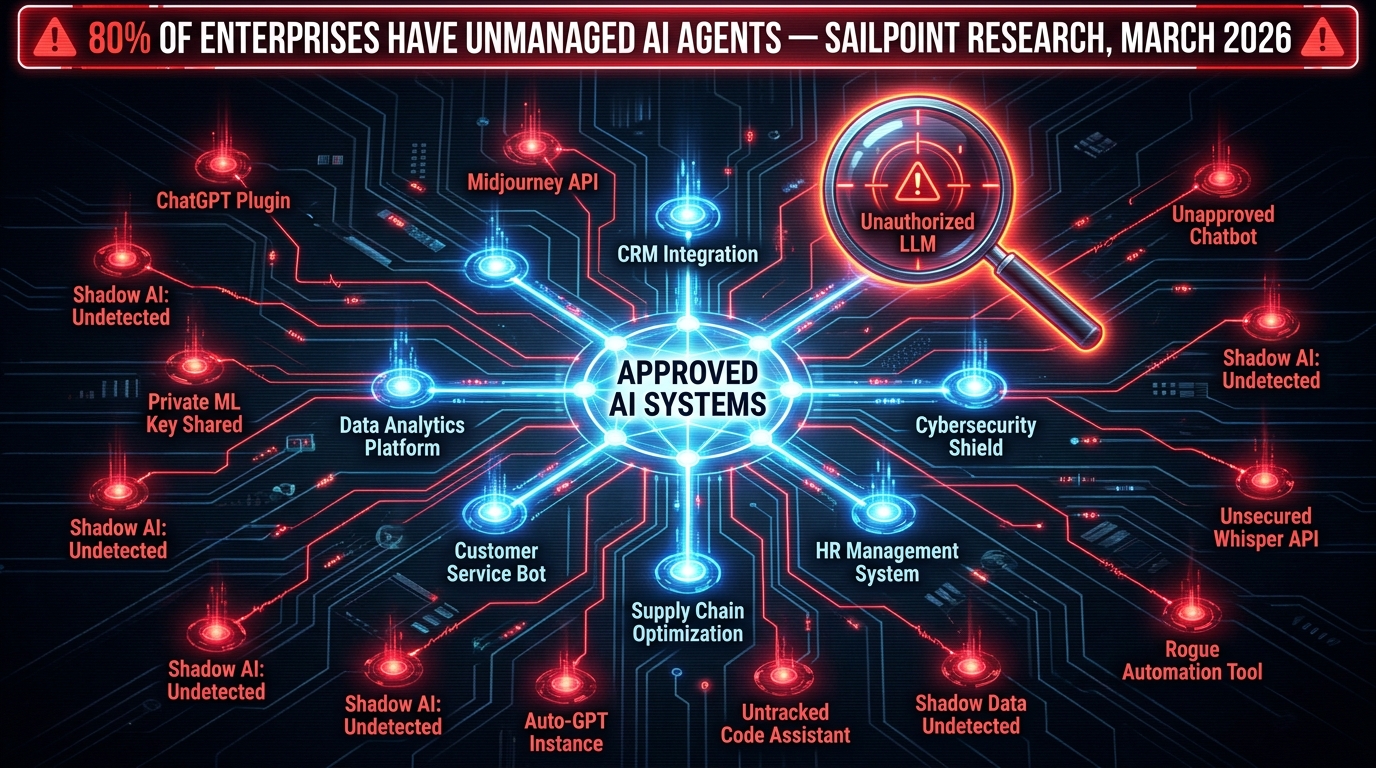
Before you can evaluate whether a governance platform works, you need to know what it’s governing. For most organizations, this turns out to be a deeply uncomfortable discovery process.
The Shadow AI Problem Is Larger Than IT Thinks
According to SailPoint research published in March 2026, 80% of organizations have encountered risks from unmanaged AI agents deployed without IT approval. Gartner projects that by the end of 2026, 40% of enterprise applications will embed AI agents — up from fewer than 5% in 2025. That growth rate means shadow AI is not a fringe problem. It is the default state of modern enterprise AI adoption.
Shadow AI takes several forms. Individual employees using consumer AI tools (ChatGPT, Claude, Gemini) through personal accounts and processing work data through them. Departments procuring AI-powered SaaS tools without IT review. Developers embedding third-party model APIs into internal applications without documentation. And increasingly, AI agents deployed by business units to automate workflows, with no oversight of what data they access or what decisions they make autonomously.
Nudge Security launched what it described as the first comprehensive AI agent discovery platform in March 2026, specifically to address this gap. The category of tooling exists precisely because the problem has become too large to ignore.
What the AI Inventory Step Actually Involves
Before piloting a governance platform — and as part of the pilot evaluation itself — organizations should conduct a structured AI inventory covering three layers:
- Sanctioned models and systems: Models deployed with IT knowledge and approval, including vendor-provided models embedded in approved software.
- Departmental AI tools: AI-powered applications procured at the department level, often under software budgets rather than AI budgets, frequently with minimal IT visibility.
- Individual and shadow usage: Employee use of consumer AI tools for work tasks, which may or may not involve organizational data.
The AI inventory step serves two purposes in a governance pilot. First, it gives you the actual scope of what the platform will need to govern — and you can test whether the platform’s discovery capabilities match what you already know exists. Second, it produces an asset that has governance value regardless of which platform you choose.
A governance platform that scores well in a vendor demo but fails to surface shadow AI systems during a pilot is not ready for production deployment. This is one of the most important tests your pilot can run.
Risk Classification in Practice: Categorize Before You Configure
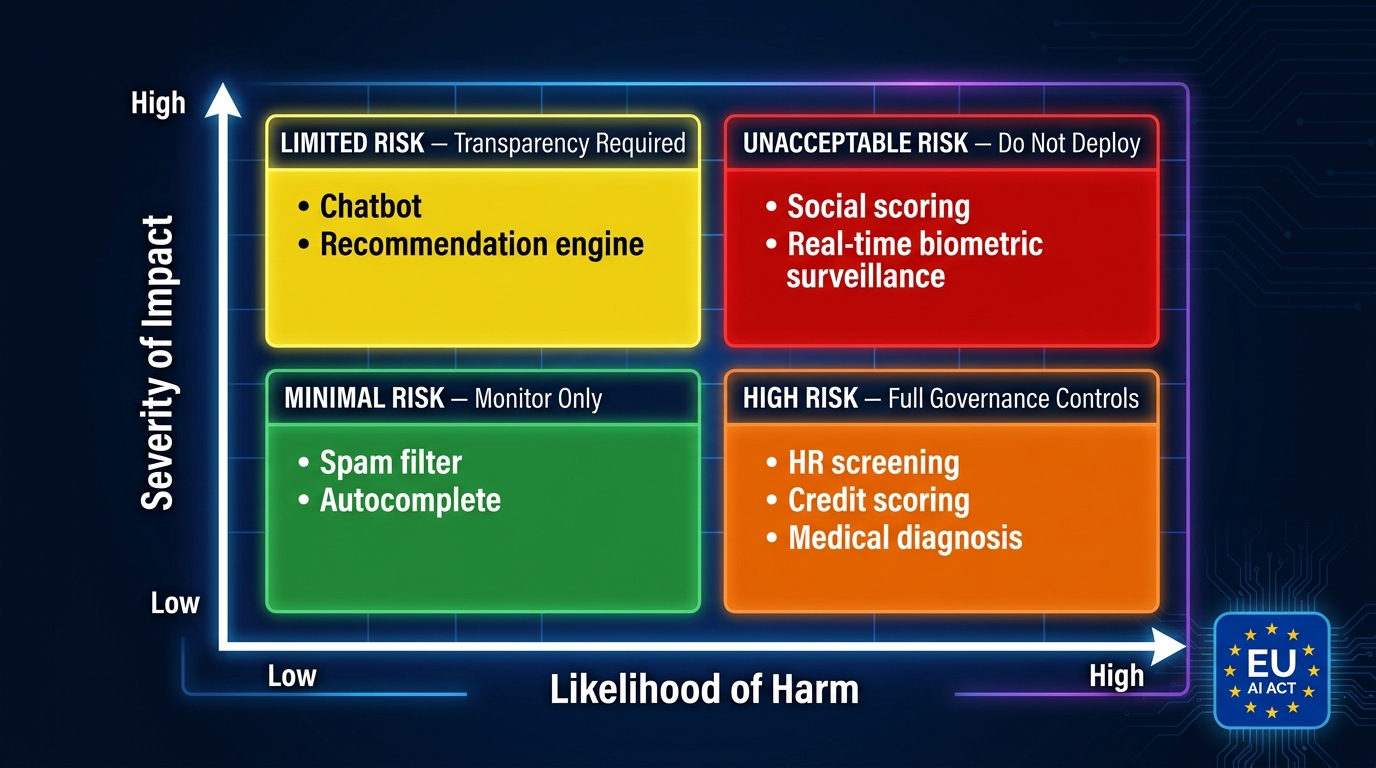
Not all AI systems require the same level of governance scrutiny. One of the core functions of a governance platform is to apply appropriate controls to each system based on its risk level — but before you can evaluate whether a platform does this well, you need to have done the risk classification work yourself.
The Four Risk Tiers Under the EU AI Act
The EU AI Act provides the most internationally consequential risk taxonomy for AI systems in 2026. Its four-tier structure has become a de facto reference point even for organizations outside the EU, because any organization processing EU residents’ data falls under its scope.
Unacceptable Risk: Prohibited outright. Includes social scoring systems, real-time biometric surveillance in public spaces, subliminal manipulation, and AI systems that exploit vulnerable groups. If your organization operates any of these, that’s a legal problem, not a governance platform problem.
High Risk: The most consequential category for enterprise governance platforms. High-risk AI includes systems used in hiring and HR decisions, credit scoring, medical diagnosis and triage, educational assessment, critical infrastructure management, and law enforcement. These systems require full documentation, human oversight mechanisms, bias and accuracy testing, data quality controls, and incident reporting. The EU AI Act’s August 2, 2026 enforcement deadline applies here.
Limited Risk: Includes AI systems that interact with users (chatbots, recommendation engines, deepfake generators). Transparency obligations apply — users must be informed they’re interacting with AI.
Minimal Risk: Spam filters, autocomplete, basic automation. Standard monitoring is sufficient; no special governance obligations.
Mapping Your Use Cases Before Choosing Your Pilot Scope
Before the pilot begins, map every AI system from your inventory against this risk taxonomy. This exercise accomplishes two things. First, it identifies which systems require the most urgent governance attention — your pilot should include at least one high-risk use case, because that’s where governance platform capabilities are most rigorously tested. Second, it gives you a basis for evaluating whether the platform’s built-in risk classification logic aligns with your own assessment. Significant disagreements between your classification and the platform’s are a yellow flag worth investigating.
NIST AI RMF and ISO 42001 both provide complementary risk assessment frameworks that overlap significantly with the EU AI Act — approximately 40–50% of controls are shared across all three frameworks. A governance platform that maps its controls to all three frameworks enables a “map once, satisfy many” approach that dramatically reduces compliance overhead.
Choosing Your Pilot Use Case: The Low-Risk, High-Signal Test
The pilot use case selection is where many organizations make a strategic error in one of two directions: they choose something so simple that the platform can’t possibly fail (producing a flattering but uninformative result), or they choose something so complex that the pilot becomes a deployment project rather than an evaluation (producing chaos instead of data).
What Makes a Good Pilot Use Case
The ideal pilot use case has four characteristics:
Real operational consequences: The AI system being governed actually matters to someone in the organization. This ensures the pilot generates genuine feedback about usability and workflow integration rather than an academic exercise.
Clear existing baseline: You know how the system is currently monitored (or not monitored), what documentation exists, and what a governance gap looks like for this specific system. This makes it possible to measure what the platform adds.
Moderate complexity: The use case is complex enough to stress-test meaningful platform capabilities — bias detection, model drift monitoring, audit trail generation, policy enforcement — without being so complex that integration work dominates the 90-day window.
Cross-functional visibility: Multiple stakeholders care about this system. A use case that only matters to one team limits the ability to evaluate cross-functional governance workflows and won’t generate the stakeholder feedback needed to assess whether the platform would achieve organization-wide adoption.
Use Cases by Industry Sector
The right use case varies significantly by sector. For financial services, credit risk scoring models or fraud detection systems are high-signal pilot candidates — they’re high-risk under EU AI Act, heavily scrutinized by regulators, and the governance requirements are well-understood. For healthcare organizations, clinical decision support tools or patient triage algorithms offer genuine complexity against which monitoring and human oversight capabilities can be meaningfully evaluated. For HR and talent management, any AI system that influences hiring, performance evaluation, or compensation decisions is both high-risk under the EU AI Act and an area where bias detection capabilities matter enormously. For retail and e-commerce, recommendation engines or dynamic pricing systems offer a lower-risk but still substantive test case, particularly for transparency and explainability features.
Platform Evaluation Framework: Testing What Vendors Won’t Show You

Leading platforms in 2026 include Credo AI, IBM watsonx.governance, OneTrust, Bifrost, and Ethyca — each with distinct architectural approaches and strengths. But comparing vendor feature tables tells you almost nothing about operational reality. The evaluation framework below focuses on what actually differentiates platforms under real conditions.
Discovery and Inventory Capabilities
Test whether the platform can find AI systems it wasn’t explicitly pointed at. Load the platform with your known AI inventory, but also give it access to your broader IT environment and see what it surfaces. Any platform worth deploying in a complex enterprise environment should surface at least some systems beyond what it was told to look for. If it only knows what you tell it, it’s a documentation tool, not a governance platform.
Policy Enforcement vs. Policy Alerting
This is one of the most consequential architectural differences between platforms, and vendors frequently obscure it in demos. Some platforms generate alerts when policies are violated — they observe and report. Others enforce policies in real time, blocking or modifying AI outputs that violate defined rules. Bifrost, for instance, operates at the infrastructure layer with a claimed latency of 11 microseconds for real-time enforcement. Policy alerting is appropriate for some governance workflows; policy enforcement is necessary for others. Your pilot should include test scenarios that distinguish between these modes and assess which your organization’s risk profile actually requires.
Bias and Drift Detection Under Realistic Conditions
Vendor demos typically demonstrate bias detection against clean, well-labeled datasets with obvious fairness issues. During your pilot, feed the platform with datasets that reflect the actual quality and structure of your production data — which means messy, partially labeled, with edge cases the model wasn’t trained on. Similarly, test drift detection by introducing controlled data distribution shifts and measuring how quickly the platform surfaces the alert and what information it provides to enable remediation. The time-to-alert and quality-of-alert are both important. A platform that flags “drift detected” without providing enough context to diagnose the cause is operationally useless.
Audit Trail Quality
This is a feature that sounds simple but varies dramatically in practice. Generate a scenario during the pilot that would require producing documentation for a regulatory audit — an EU AI Act compliance review, a NIST AI RMF assessment, or an ISO 42001 audit. Ask your compliance representative to review the audit trail output and assess whether it would actually satisfy the documentation requirements of the relevant framework. Many platforms produce audit logs that are technically comprehensive but practically useless — they capture everything but make it impossible to surface what auditors need without significant manual effort.
Integration Depth vs. Integration Breadth
Count integrations in a vendor’s marketing materials. Now ask the vendor which integrations were built natively versus which are achieved through generic API connectors. Then, during the pilot, actually configure two or three of your most critical integrations — the MLOps platform your data science team uses, the cloud environment your models run in, the GRC tool your compliance team already operates — and measure the effort and fidelity of each integration. Broad integration lists with shallow connections are a consistent source of post-purchase disappointment.
The 90-Day Pilot Roadmap: Phase Gates and Go/No-Go Decisions
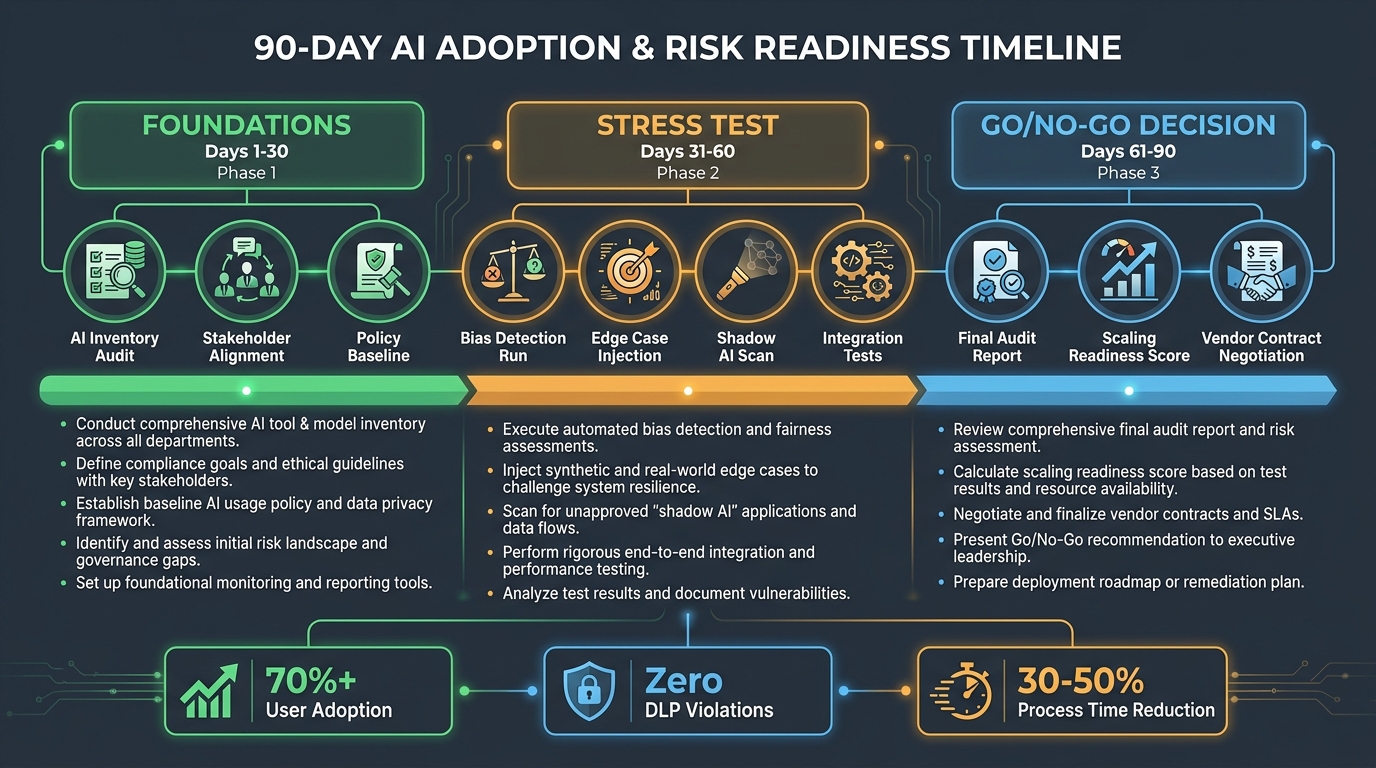
A well-structured 90-day pilot uses mandatory phase gates to force honest assessment at intervals, rather than allowing momentum and sunk cost to carry a failing pilot forward to an inevitable “buy” decision.
Days 1–30: Foundations
The first phase is about getting to a genuine baseline, not about demonstrating success. The work in this phase includes:
- Completing the AI system inventory across all three tiers (sanctioned, departmental, shadow)
- Finishing risk classification across all inventoried systems
- Configuring the platform against the selected pilot use case
- Establishing integrations with the two or three most critical existing tools
- Setting the initial policy baseline — what rules is the platform supposed to enforce or monitor?
- Documenting the pre-pilot governance state so there’s a measurable baseline to compare against
Day 30 Gate: Can the platform see what it’s supposed to govern? Are critical integrations functional? Has the team identified any show-stopping incompatibilities? If the answer to the first two questions is no, the pilot is already in trouble — surface this to the executive sponsor before proceeding.
Days 31–60: Stress Testing
This phase is where most pilots either prove their value or reveal their limitations. The evaluation team should deliberately create conditions the platform wasn’t designed to handle cleanly:
- Introduce edge cases: Feed inputs to monitored models that are likely to trigger edge cases in the model’s behavior, and observe whether the platform’s monitoring detects anomalies.
- Inject controlled data drift: Introduce a data distribution shift to the pilot use case and measure time-to-alert and alert quality.
- Shadow AI test: Add an unregistered AI tool to the environment (with appropriate authorization) and see whether the platform discovers it during routine scanning.
- Policy violation test: Deliberately trigger a policy violation — processing data without required consent logging, generating outputs that violate a defined content policy — and evaluate how the platform responds.
- Load testing: If the platform claims real-time enforcement, test it under the volume conditions your production environment would actually generate.
Day 60 Gate: Does the platform detect problems it wasn’t explicitly told to look for? How does it perform under stress conditions? Target metrics include 40%+ adoption among the pilot user group, zero undetected policy violations in test scenarios, and mean-time-to-alert under defined thresholds. If stress testing surfaces fundamental capability gaps, the executive sponsor needs to see those results before the pilot continues.
Days 61–90: Production Readiness Assessment
The final phase evaluates whether the platform can survive real-world deployment. This is not about running more tests — it’s about asking harder organizational questions:
- What would full deployment actually cost, including integration work, training, and ongoing management?
- What governance gaps remain after the pilot — are there AI systems that the platform cannot govern, and how significant are they?
- What would the platform’s ongoing operational overhead look like for the team responsible for managing it?
- What is the vendor’s roadmap for the capabilities the platform currently lacks?
Day 90 Gate: The final assessment should be structured as a formal go/no-go decision with the executive sponsor, presenting documented pilot results against pre-established success criteria. Target KPIs for a successful pilot include 70%+ user adoption among pilot participants, measurable reduction in governance process time (30–50% is a reasonable target), and zero data leakage incidents during the pilot period.
Regulatory Alignment During the Pilot: EU AI Act, NIST AI RMF, and ISO 42001
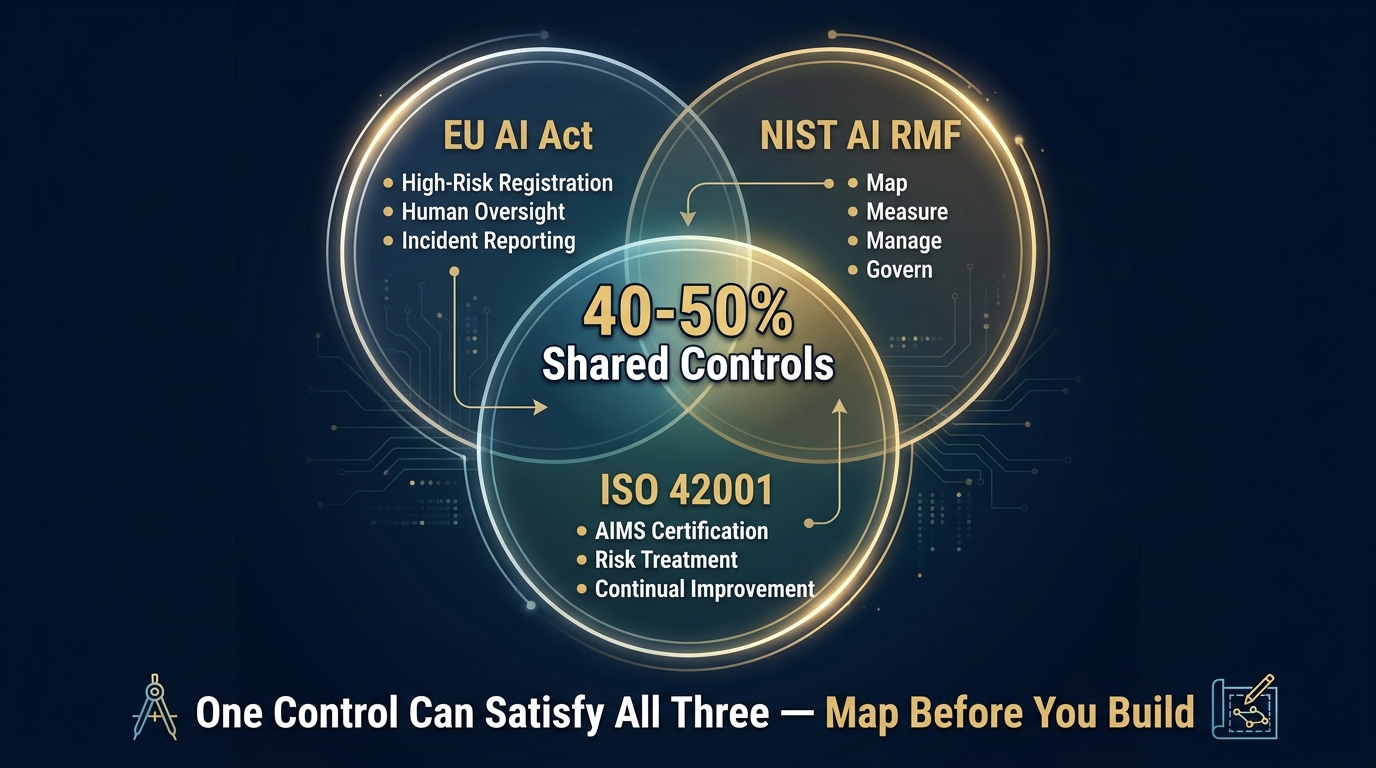
One of the most valuable things a governance platform pilot can do is surface the gap between where your organization currently stands on regulatory compliance and where it needs to be. But evaluating this gap requires understanding what each framework actually demands.
EU AI Act: The Binding Enforcement Deadline
The EU AI Act’s provisions for high-risk AI systems and general-purpose AI models become enforceable on August 2, 2026. For organizations operating high-risk AI systems — which, as noted above, includes HR, credit, healthcare, and critical infrastructure applications — full enforcement is not a future consideration. It is a current operational requirement.
The EU AI Act mandates, for high-risk systems: risk management documentation, data governance and data quality controls, technical documentation and logging, transparency to users, human oversight mechanisms, accuracy and robustness testing, and incident reporting obligations. During your pilot, test whether the governance platform’s documentation outputs would satisfy each of these requirements — and do it against a real audit scenario, not a theoretical checklist.
NIST AI RMF: The De Facto U.S. Standard
The NIST AI Risk Management Framework is voluntary in the United States but has become effectively mandatory in practice, through federal procurement requirements, contractual obligations with regulated counterparties, and investor due diligence processes. The NIST AI RMF’s four functions — Govern, Map, Measure, Manage — provide a structured methodology for AI risk management that complements the EU AI Act’s system-specific requirements with organization-wide governance practices.
When evaluating a governance platform against NIST AI RMF, focus on whether the platform supports the “Map” function effectively — helping organizations identify and classify AI risks across their portfolio — and whether the “Measure” function capabilities (monitoring, testing, evaluation) are operationally useful rather than just checkbox-satisfying.
ISO 42001: The Certifiable Standard
ISO 42001 defines requirements for an AI Management System (AIMS) — an organizational system for managing AI responsibly, similar to how ISO 27001 governs information security. Unlike the EU AI Act, ISO 42001 is not a legal requirement. But certification is increasingly demanded in enterprise procurement, particularly in sectors with high regulatory sensitivity. If your organization operates globally and pursues ISO 42001 certification, the governance platform you deploy will need to support the required documentation, audit evidence, and management review processes. Test these capabilities explicitly during the pilot.
The 40–50% Overlap Advantage
A critical insight for organizations managing multi-framework compliance: approximately 40–50% of controls are shared across the EU AI Act, NIST AI RMF, and ISO 42001. Risk assessment processes, AI inventory management, data governance, model transparency documentation, human oversight mechanisms, and incident reporting all appear in some form across all three frameworks. A governance platform that maps its controls to all three frameworks allows one control implementation to satisfy multiple requirements simultaneously, dramatically reducing compliance overhead. Test this explicitly: take a compliance requirement from each framework and trace how the platform’s control documentation addresses it. Gaps in cross-framework mapping will become expensive to fill after deployment.
Agentic AI and Shadow AI: The Governance Gap Every Pilot Must Address
The governance challenge that most current platform evaluations underestimate is not the management of known, documented AI systems. It’s the management of agentic AI — autonomous systems that take actions, access data, and make decisions with minimal human intervention — which is rapidly becoming the dominant form of enterprise AI deployment.
The Scale of the Agentic AI Shift
Gartner projects that 40% of enterprise applications will embed AI agents by the end of 2026, up from fewer than 5% in 2025. This is not a gradual shift — it’s a step change in the operational complexity that governance platforms need to handle. AI agents that autonomously execute multi-step workflows create governance challenges that are categorically different from static models that receive inputs and produce outputs.
An AI agent that can access email systems, query databases, initiate API calls, and produce documents requires governance oversight across its entire action surface — not just its outputs. The data it accesses, the systems it touches, the decisions it makes without human review, and the actions it takes on behalf of users all need to be observable, auditable, and controllable.
What Agentic Governance Oversight Actually Requires
During your pilot, assess whether the governance platform provides meaningful oversight of agentic AI systems through four specific capabilities:
Action logging: Does the platform record what actions an agent took, when, on whose behalf, and with what authorization? This is the audit trail requirement for agentic systems, and it’s substantially more complex than logging model outputs.
Data access visibility: Can the platform surface what data an agent accessed during a given workflow? This is essential for GDPR compliance, for EU AI Act documentation, and for incident investigation when an agent’s actions produce unexpected results.
Permission boundary enforcement: Can the platform enforce limits on what data an agent is allowed to access and what actions it’s permitted to take, in real time rather than through after-the-fact audit? This is where policy enforcement versus policy alerting becomes most consequential — for agentic systems, alerting after a boundary violation may already be too late.
Human escalation pathways: When an agent encounters a situation outside its defined parameters, does the platform provide a mechanism for escalating to human review before the agent acts? Human oversight isn’t just a compliance checkbox — for high-risk agentic applications, it’s an operational safety requirement.
The Shadow Agent Problem
SailPoint’s March 2026 research finding — that 80% of organizations have encountered risks from unmanaged AI agents — applies specifically to agents deployed without IT approval. These are not exotic edge cases. They include business units using AI workflow tools that autonomously process customer data, developers deploying AI coding assistants with access to proprietary codebases, and operations teams using AI scheduling tools that interface with production systems. Your governance platform pilot should include a test for shadow agent detection: deploy a simple agent in a controlled environment without registering it with the governance platform, and assess whether the platform discovers it. Platforms that can’t find what they don’t know about cannot be trusted to protect an organization from its most common real-world risk vector.
How to Read Pilot Results Honestly: Red Flags, Green Lights, and Gray Areas
At the end of 90 days, you have a body of evidence. Reading it accurately requires resisting the organizational pressures — toward buying, toward not buying, toward justifying time already spent — that make honest assessment difficult.
Clear Green Lights
A pilot result justifies moving toward full deployment when it demonstrates: user adoption above 70% among pilot participants without coercive mandates; all critical integrations functioning without significant manual workarounds; stress tests surfacing expected problem types (drift, bias, policy violations) within acceptable time windows; audit trail outputs that satisfy the requirements of relevant regulatory frameworks as assessed by the compliance team; and total cost of ownership for full deployment that is defensible relative to the risk reduction the platform provides.
Clear Red Flags
A pilot should trigger a hard stop or vendor reconsideration when it reveals: integration failures with two or more critical systems that require significant custom engineering to resolve; an inability to detect shadow AI systems in a controlled test environment; audit trail outputs that require substantial manual reconstruction before they could be used in a real audit; enforcement mechanisms that cannot operate at production load without significant performance degradation; or user adoption below 40% after 60 days despite adequate training and support.
Gray Areas That Require Honest Judgment
The genuinely difficult cases are the ones where the platform performs well in some areas and poorly in others. A platform with excellent regulatory documentation capabilities but weak agentic AI monitoring presents a real dilemma if your environment is rapidly moving toward agentic deployment. A platform that performs perfectly for the pilot use case but has demonstrably shallow integrations with several systems you’ll need to govern at scale is a risk that needs to be quantified, not dismissed.
Gray area results should prompt a structured conversation with the executive sponsor about which capability gaps are acceptable, which are acceptable with vendor commitment to a roadmap, and which are disqualifying regardless of other strengths. Do not let gray area results drift toward a default “buy” decision because the alternative is restarting the evaluation process.
From Pilot to Production: What the Transition Actually Requires
Organizations that run successful pilots and then struggle with production deployments typically underestimate one of three transition requirements. Understanding these in advance — and assessing them during the pilot — prevents the most common causes of post-purchase disappointment.
Governance Doesn’t Run Itself
A governance platform is not a set-and-forget compliance solution. It requires ongoing management: policy updates as regulations evolve, model registry maintenance as new AI systems are deployed, alert triage and investigation when the platform surfaces issues, and periodic audit evidence generation. During the pilot, track how much time the day-to-day owner and end-user representative actually spend managing the platform. This is your most accurate estimate of the ongoing operational overhead that full deployment will require — and it’s frequently two to three times higher than vendors suggest in their ROI models.
The Organizational Change Problem
The most common reason AI governance platforms fail after successful pilots is not technical — it’s organizational. Governance platforms impose new processes on people who already have jobs. Model developers are asked to complete documentation that wasn’t required before. Business units are asked to register AI tools that previously operated under the radar. Compliance teams are asked to learn new workflows for audit evidence collection. None of these changes are optional if the platform is to function as designed, and none of them happen automatically as a consequence of purchasing software.
During the pilot, identify every workflow change that the platform requires of non-pilot-team stakeholders and assess organizational appetite for each change. The ones that generate significant resistance during the pilot will generate significant resistance at scale.
Regulatory Change Is Ongoing
The regulatory environment for AI governance is not static. The EU AI Act’s high-risk provisions are enforceable from August 2026, but subsequent provisions, implementing regulations, and guidance from national supervisory authorities will continue to evolve. The Colorado AI Act takes effect in June 2026. Additional U.S. state laws are in various stages of development. International standards bodies are continuing to develop AI-specific guidance.
A governance platform that is well-configured for current regulatory requirements may require significant reconfiguration as requirements evolve. During vendor discussions, assess the platform’s track record of updating its regulatory coverage in response to new requirements, and build contractual commitments to regulatory update timelines into any enterprise agreement before signing.
The Vendor Relationship: What to Negotiate Before You Sign
The pilot is also a negotiating position. Organizations that run rigorous pilots with documented results are in a substantially stronger position when negotiating enterprise contracts than organizations that buy based on demo impressions. Use the pilot results to anchor specific contractual commitments.
Regulatory Coverage SLAs
Require the vendor to commit to updating the platform’s regulatory coverage within a defined timeframe — 60 or 90 days is reasonable — when new requirements become enforceable. Given that EU AI Act enforcement is ongoing and U.S. state laws are proliferating, this commitment has material value. Without it, you may find that the compliance coverage you evaluated during the pilot is no longer current six months into deployment.
Integration Support Commitments
Document which integrations were tested during the pilot and at what depth. For integrations that are critical to your governance operations, negotiate vendor support commitments — response times for integration failures, maintenance of connectors through upstream API changes, and a process for requesting new integrations when your technology stack evolves.
Exit Provisions
Governance data — AI system registries, risk assessments, audit trails, model documentation — has value beyond the platform that holds it. Before signing, negotiate data portability provisions that guarantee you can export all governance data in a usable format if you choose to change platforms. This is not a standard provision in vendor contracts, but it is a reasonable one, and vendors that resist it are signaling something about their confidence in long-term customer retention.
Conclusion: Pilot Rigorously or Regret Quickly
The AI governance platform market in 2026 is crowded with competent-looking software and sophisticated vendors who have refined their demos to be compelling. The pressure to move quickly — driven by August 2026 EU AI Act enforcement deadlines, board-level AI risk concerns, and the genuine operational chaos of managing AI at enterprise scale without governance tooling — makes it tempting to compress evaluation and buy fast.
That temptation is exactly the wrong response to an environment where post-deployment governance costs 3–5x more than upfront integration, where fewer than 25% of AI governance pilots successfully scale enterprise-wide, and where the penalty for a failed governance deployment isn’t just wasted software budget — it’s continued exposure to the regulatory, operational, and reputational risks the platform was supposed to address.
The organizations that will get the most from their AI governance platform investments in 2026 are the ones that treat the pilot as the most important 90 days of the purchase decision — not as a bureaucratic prerequisite before signing what’s already been decided. Run the pilot against real conditions. Stress test the capabilities that matter most. Surface the gaps honestly. And use the results to make a decision based on evidence rather than momentum.
Key Takeaways
- Start with an AI inventory — you cannot govern systems you haven’t identified, and the inventory itself is a governance asset regardless of platform choice.
- Classify risks before configuring anything — map your AI systems against EU AI Act tiers and NIST AI RMF before a vendor touches your environment.
- Assign all five pilot roles explicitly — executive sponsor, day-to-day owner, compliance rep, engineering lead, and end-user rep — before the pilot begins.
- Pre-register your success criteria — document what success, failure, and inconclusive results look like before Day 1.
- Use mandatory phase gates — Day 30, Day 60, and Day 90 check-ins with the executive sponsor create honest decision points rather than letting momentum carry a failing pilot to purchase.
- Test shadow AI discovery — deploy an unregistered system and see if the platform finds it. If it can’t, you know a critical limitation before you’re committed.
- Evaluate agentic AI oversight specifically — static model governance and agentic agent oversight are different capabilities; verify the platform handles both.
- Negotiate regulatory update SLAs — the compliance landscape is evolving; commit vendors contractually to keeping pace.
The right governance platform, selected through a rigorous pilot, is a genuine operational asset. The wrong one — selected through a hurried evaluation — creates more governance work than it eliminates and leaves organizations exposed to the exact risks they were trying to manage. Ninety days of disciplined evaluation is a small investment relative to the cost of getting it wrong.



