


There is a specific kind of disappointment that has become routine in enterprise AI teams. A Retrieval-Augmented Generation prototype gets built in a few weeks — polished, accurate, genuinely impressive in a controlled demo. The business sponsors are excited. Budget is approved. Then the team tries to scale it.
Within months, the cracks appear. Answers start missing context. The system confidently produces responses that contradict the source documents it supposedly retrieved. Latency climbs. IT flags a compliance exposure. The pilot that impressed everyone quietly gets shelved, reclassified as a “learning exercise.”
This pattern is not a technology failure. It is an architecture and strategy failure — one that repeats because most RAG guidance focuses on getting it running rather than keeping it trustworthy. The global RAG market reached $1.94 billion in 2026 with a projected 38.4% compound annual growth rate through 2030. Yet only 30% of RAG pilots ever reach production, and just 10–20% show measurable ROI. That gap between investment and outcome is not random. It has identifiable causes and fixable solutions.
This guide is not about what RAG is. It is about what goes wrong, what the research actually says about each component decision, and how to build a system that works when real users with real stakes depend on it. Whether you are a technical lead making architecture choices or a business decision-maker trying to evaluate what you are actually buying, this is the perspective the polished vendor presentations will not give you.
The State of RAG in 2026: A Market Built on Unfinished Work
Retrieval-Augmented Generation has moved from research curiosity to production infrastructure faster than most enterprise technology categories in recent memory. The concept — connecting a large language model to an external knowledge base at inference time so it can retrieve relevant context before generating an answer — is straightforward enough. Its appeal is obvious: you get AI outputs grounded in your data, not just the model’s training knowledge, without needing to retrain the model every time your information changes.
Where the Market Stands
The numbers reflect genuine enterprise demand. The $1.94 billion RAG market in 2026 is being driven primarily by organizations deploying knowledge management systems, internal search tools, customer service automation, and compliance document analysis. Every major cloud provider now offers RAG-adjacent tooling. Every major enterprise software vendor has announced “AI search” features that lean heavily on retrieval architectures.
But the same research that surfaces those growth figures also reveals the production gap problem. A consistent finding across implementation analyses: while pilot deployments are common, the majority stall before reaching the reliability threshold that business operations actually require. The reasons are almost never about the underlying LLM being inadequate. They are about what happens before the model sees a single word of context.
The Shift That Matters Most
The most important shift in RAG thinking in 2026 is the move from treating RAG as a feature to treating it as infrastructure. When RAG is a feature, you optimize for demos. When it is infrastructure, you optimize for correctness under load, data freshness, governance, and observability. Most failed implementations are feature-thinking projects that hit infrastructure-level problems they were never designed to handle.
Enterprises that are succeeding — and there are specific, measurable cases worth examining — made that mental shift early. They designed separate indexing and query pipelines. They built evaluation frameworks before they built user interfaces. They treated chunking strategy as an engineering decision, not a default setting. The rest of this guide walks through exactly what that looks like in practice.
Why RAG Breaks: The Five Root Causes
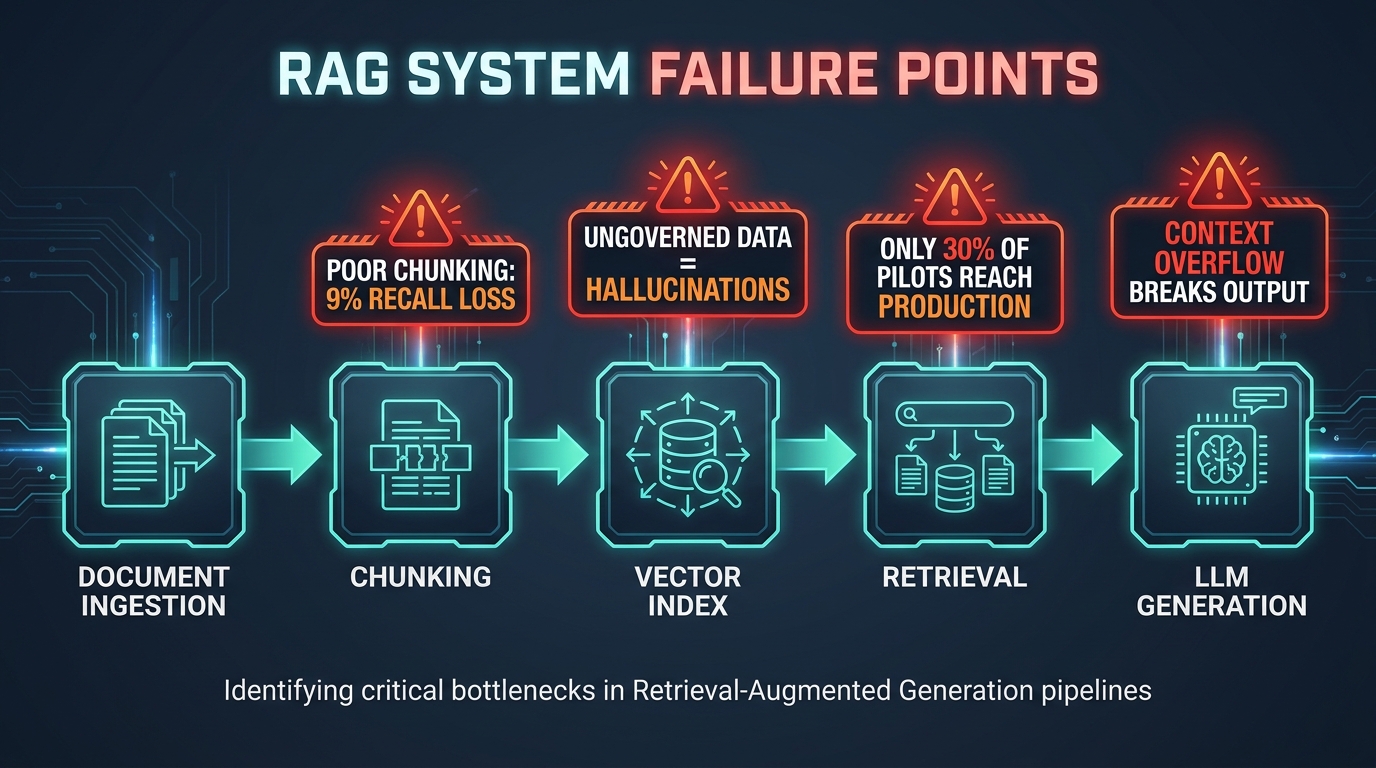
Post-mortems on failed RAG deployments reveal a consistent set of failure modes. They cluster around five root causes, and critically, most of them are invisible during a demo using clean, curated test data.
1. Chunking Done Without Intent
Chunking is the process of splitting source documents into retrievable segments before indexing them. Most developers start with whatever default a library offers — fixed-size token splits, often around 512 tokens — and never revisit the decision. NVIDIA’s benchmarking data shows that chunking strategy alone can create up to a 9% recall gap between the best and worst approaches across standard datasets. That is not a minor optimization. That is the difference between a system that finds the right answer and one that doesn’t.
The problem is compounded by treating all documents the same. A compliance policy document, a chat log, a technical manual, and a customer contract have fundamentally different structures. Fixed-size chunking on a contract can split a conditional clause across two chunks — rendering both chunks misleading when retrieved in isolation.
2. Context Collapse Post-Retrieval
Retrieval succeeds. The right chunks are pulled. Then the model fails anyway. This is the context control problem, and it is more common than any other failure mode in production. As conversations accumulate history, as retrieved documents overlap, as token limits approach — the model’s ability to synthesize coherently degrades. Systems that work perfectly on single-turn queries fail on the multi-turn exchanges that real users actually have.
3. Ungoverned Knowledge Bases
Organizations index everything they have access to. Outdated policy documents, superseded product specs, draft content that never got published, information from departments with different access permissions. Without governance, the knowledge base becomes a mix of accurate, stale, and contradictory content. Research on hallucination rates in RAG systems shows that a 52% fabrication rate in ungoverned deployments drops to near-zero with structured governance frameworks. That statistic alone should reframe how seriously organizations treat content curation before indexing.
4. No Evaluation Framework
Most RAG systems are deployed without a systematic way to measure how well they are working. Teams rely on manual spot-checking and user complaints as proxies for system quality. By the time the complaints accumulate, trust is already eroded and often irreparable. Without baseline metrics established before launch, there is no way to catch regression when document updates, model changes, or query pattern shifts degrade performance.
5. Security and Permissions as an Afterthought
A retrieval system that can surface any document to any user is a compliance liability. In organizations with tiered information access — which is effectively every organization — a RAG system that does not enforce the same permissions as the underlying document management system creates exposure. This is not a hypothetical risk. It is a deployment blocker in regulated industries, and retrofitting permission enforcement onto a system that was not designed for it is significantly more costly than building it in from the start.
The Data Foundation: Chunking Strategy Is Your Most Consequential Decision
Before you choose a vector database, an LLM provider, or a retrieval algorithm, you need a chunking strategy. Chunking decisions have a larger impact on RAG accuracy than almost any other architectural choice — and yet most implementations treat it as a default parameter.
What the Research Actually Shows
Page-level chunking delivers the highest average RAG accuracy (0.648) across datasets in current benchmarks, outperforming token-based approaches (0.603–0.645) and section-level strategies. The reason: page boundaries tend to respect natural content organization in ways that arbitrary token counts do not. Content that belongs together stays together. Retrieval coherence improves.
That said, page-level is not universally optimal. Financial data often performs best with token-based chunks around 1,024 tokens. Entity-heavy data benefits from smaller chunks in the 64-token range, which can boost fact-based recall by 10–15% compared to larger chunks — though this gain disappears for narrative queries where context continuity matters more.
Domain-Aware Chunking in Practice
The practical guidance is to match your chunking strategy to your document type. Here is a working framework:
- Legal and compliance documents: Rule-based chunking at the clause or section level (roughly 1,000–1,500 tokens), with explicit overlap on conditional statements. Never split a conditional structure across chunks.
- Technical manuals and documentation: Hierarchical chunking that preserves the parent-section relationship, so retrieval returns both the specific paragraph and its parent heading for context.
- Chat logs and conversation records: Smaller semantic chunks (200–400 tokens) that capture individual exchanges rather than arbitrary token counts.
- Product catalogs and structured data: Entity-level chunking aligned to product records, with metadata fields (category, SKU, date) preserved as filterable attributes.
- General knowledge documents: Page-level chunking as the default, with 50–100 token overlap at page boundaries to avoid losing context across page breaks.
Metadata as a First-Class Citizen
Chunking strategy and metadata enrichment are inseparable. Every chunk should carry metadata that enables filtering: document type, author, date, department, access classification, version number. This metadata serves two purposes: it enables more precise retrieval (you can filter by date range or department before vector search), and it is the foundation for permission enforcement at the retrieval layer.
Teams that skip metadata enrichment at ingestion time almost always regret it. Retrofitting metadata onto an existing index is technically possible but operationally painful — requiring full re-ingestion, re-chunking, and re-indexing of every document in the knowledge base.
Choosing Your Retrieval Architecture: Vector, Hybrid, or Graph
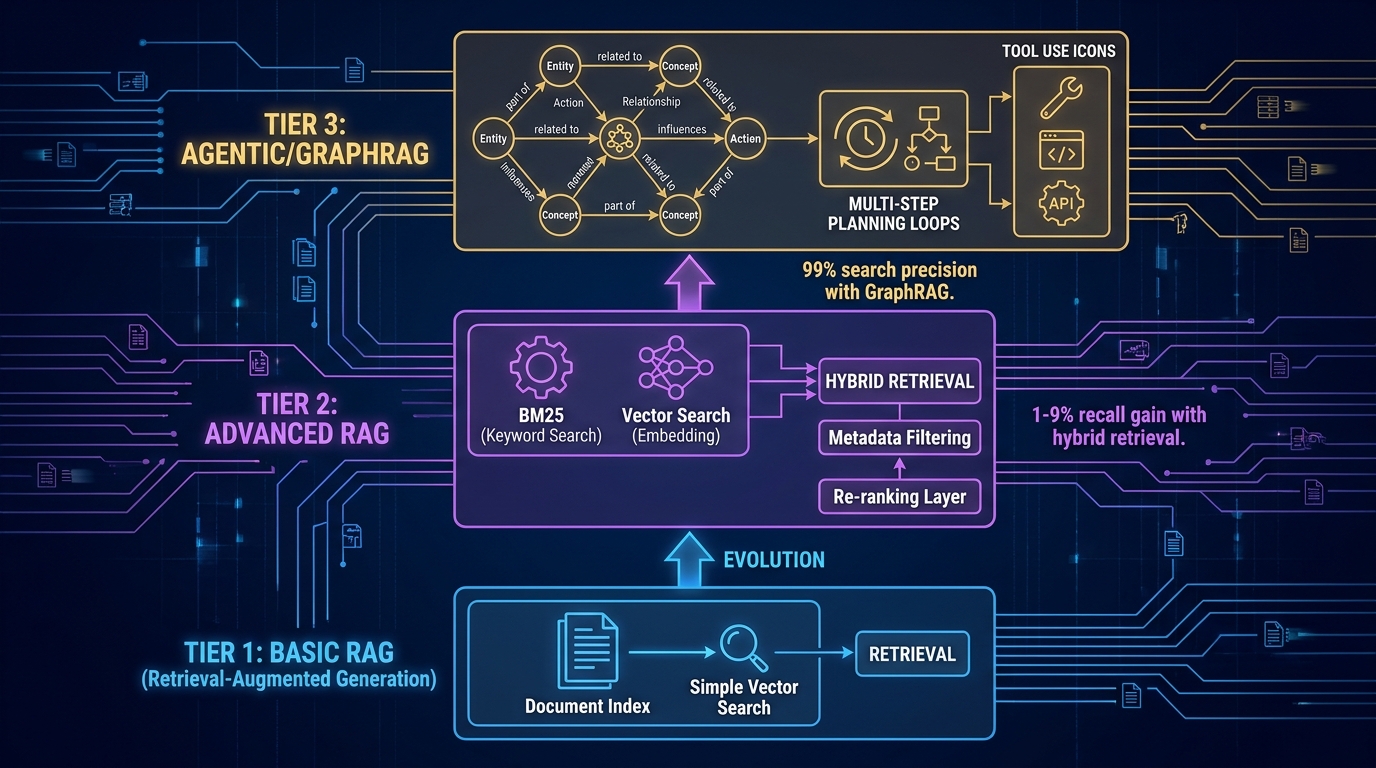
Once your data foundation is solid, the next architectural decision is retrieval method. There are three primary options, each with distinct performance characteristics and appropriate use cases.
Pure Vector Search: The Starting Point, Not the Destination
Vector search converts text into numerical embeddings and retrieves the most semantically similar chunks to a query. It handles synonym variation and natural language well. It is also the baseline that most RAG tutorials cover, which is why most proof-of-concept systems use it exclusively.
The limitation: vector search struggles with exact keyword matching, specific entity retrieval (product codes, names, identifiers), and queries where the precise wording of the source document matters. For a general knowledge assistant, this is often acceptable. For legal, financial, or technical applications where exact terminology is significant, pure vector search underperforms.
Hybrid Retrieval: The Production Default
Hybrid retrieval combines vector search (semantic similarity) with BM25 (lexical keyword matching) using a technique called Reciprocal Rank Fusion to merge the result sets. The research finding is consistent: hybrid retrieval improves recall by 1–9% over pure vector search. That range might sound modest, but at enterprise query volumes it represents thousands of correct answers per day that would otherwise be missed.
Hybrid retrieval should be the default choice for any production RAG system handling diverse query types. The additional infrastructure cost is minimal. The reliability improvement is measurable. Sub-millisecond vector search implementations (such as Redis-based vector stores) keep latency competitive even with the added lexical pass.
Pairing hybrid retrieval with a re-ranking layer — a secondary model that reorders retrieved chunks by relevance before passing them to the LLM — provides another performance layer. Re-ranking adds latency (typically 100–200ms), but for high-stakes applications where answer quality outweighs response speed, it is often worth the trade-off.
GraphRAG and Knowledge Graphs: When Relationships Matter
GraphRAG extends retrieval by incorporating a knowledge graph — a structured representation of entities and the relationships between them — alongside the vector index. Instead of retrieving isolated text chunks, it retrieves contextually connected information: not just the document mentioning a regulation, but the entities governed by that regulation, the departments responsible for compliance, and the related policies that intersect.
The precision improvement is significant. GraphRAG implementations report search precision as high as 99% for entity-relationship queries, compared to vector search which can struggle with multi-entity disambiguation. For ESG reporting, financial relationship analysis, regulatory compliance tracking, and any use case where entity relationships are central to the query, GraphRAG delivers accuracy that simpler approaches cannot match.
The cost: GraphRAG requires building and maintaining a structured ontology alongside your document index. This is not trivial. It requires domain expertise to define the entity types and relationship structures that matter for your use case, and ongoing maintenance as those structures evolve. The investment is justified when complex multi-entity reasoning is core to the application. It is not justified for a general-purpose document search tool.
RAG vs. Fine-Tuning: Making the Actual Business Decision

One of the most common sources of wasted AI investment is choosing between RAG and model fine-tuning based on perception rather than use-case fit. Fine-tuning gets treated as the “more serious” option — something enterprises do when they really mean business. This is the wrong mental model entirely.
The Cost Reality
The financial comparison is clearer than most vendors make it seem. RAG setup costs run $4,000–$10,000 for a properly configured implementation. Fine-tuning costs $15,000–$50,000 upfront, plus $500–$5,000 per knowledge update that requires retraining. Over a full year, typical analysis shows RAG year-one costs around $18,000 versus $31,000 for fine-tuning for equivalent capability. The gap widens every time the knowledge base changes.
The Decision Framework
The decision between RAG and fine-tuning hinges on three questions: How often does your knowledge change? What is your query volume? How much does latency matter?
Choose RAG when:
- Your knowledge base updates weekly, monthly, or even daily — product catalogs, policy documents, regulatory guidance, pricing
- Query volumes are below roughly 50,000–100,000 per day
- You need source attribution and explainability (RAG can cite the specific document chunk it retrieved)
- The use case spans multiple knowledge domains
- You need to be able to update or remove content from the AI’s knowledge for compliance reasons
Choose fine-tuning when:
- Query volume exceeds 100,000 per day and per-query cost at that scale makes RAG prohibitive
- The task requires consistent behavioral customization (specific tone, format, or reasoning style) rather than just access to current information
- Latency requirements are under 200ms and a retrieval step makes that impossible to achieve
- The knowledge domain is highly stable and does not require frequent updates
Use both when: Your application has a stable behavioral core that benefits from fine-tuning, plus a dynamic knowledge layer that requires retrieval. A customer service model fine-tuned on your brand’s communication style, augmented with RAG to pull current product specifications, is a well-designed hybrid. The key is being intentional about which component handles which function.
The Hidden Cost of Fine-Tuning
Fine-tuning’s real cost is often not the upfront model training expense — it is the operational cost of keeping a fine-tuned model current. Every time regulatory guidance changes, a product line updates, or a policy gets revised, a fine-tuned model needs to be retrained or it becomes a liability. RAG’s architecture makes knowledge updates operationally trivial: add, update, or remove documents from the index, and the system immediately reflects the change without any model modification. For organizations in regulated industries where information accuracy is a compliance matter, that operational advantage is often decisive.
Agentic RAG and GraphRAG: Knowing When to Upgrade Your Architecture
Standard single-pass RAG — query in, retrieve context, generate response — handles a wide range of use cases well. But there is a class of business query that it handles poorly: questions that require synthesizing information from multiple documents, reasoning across several retrieval steps, or taking action based on what is retrieved. This is where agentic architectures become relevant.
What Agentic RAG Actually Means
Agentic RAG replaces the single retrieval step with a multi-step planning loop. The system decides what to retrieve, retrieves it, evaluates whether the retrieved context is sufficient, and either generates an answer or decides to retrieve more before responding. This adaptive behavior enables handling of complex queries that would defeat a single retrieval pass.
A regulatory compliance query is a useful example. “Which of our operations are subject to the updated emissions reporting requirements?” is not answerable from a single document chunk. An agentic RAG system might retrieve the regulation, identify the covered industry categories, retrieve the company’s operational records, cross-reference them against the categories, and synthesize a structured answer. A standard RAG system would retrieve one or two chunks and generate an incomplete — potentially dangerous — response.
The Trade-Offs of Agentic Architectures
Agentic RAG is not free. Multi-step retrieval loops introduce latency, increase LLM API costs, and create new failure modes around loop termination and tool selection. Production agentic systems require careful guardrails to prevent runaway retrieval chains and careful monitoring to catch cases where the planning loop makes incorrect decisions about what to retrieve.
The operational requirement: agentic RAG needs robust observability. You need to be able to trace exactly which retrieval steps occurred, what was retrieved at each step, and how the final response was assembled. Without that traceability, debugging errors and satisfying compliance audits becomes intractable.
GraphRAG for Entity-Heavy Domains
Knowledge graphs shine in domains where entities and their relationships are the primary subject of queries. Financial services firms using GraphRAG for client relationship analysis, healthcare organizations tracking treatment protocol relationships across conditions and medications, and ESG reporting tools connecting regulatory requirements to operational data — all of these represent cases where the structured relationships in a knowledge graph provide precision that document retrieval alone cannot.
The 99% search precision figure cited in GraphRAG research comes specifically from entity disambiguation: cases where the same term refers to different things in different contexts, and the knowledge graph’s ontological structure resolves the ambiguity correctly. For knowledge domains with high terminological complexity, this is a meaningful capability improvement. For straightforward document Q&A, it is architectural overkill.
Measuring What Actually Matters: RAG Evaluation in Practice
The failure to establish evaluation frameworks before deployment is one of the most consistent patterns in failed RAG projects. Teams that build evaluation into the development process catch degradation before users do. Teams that skip it discover problems through escalating complaints and eroded trust.
The RAGAS Framework for Business Teams
RAGAS (Retrieval-Augmented Generation Assessment) provides a structured evaluation framework with metrics that map to business-relevant quality dimensions. The core metrics worth tracking:
- Faithfulness (0–1 scale): The fraction of claims in the generated answer that are supported by the retrieved context. This is your primary hallucination indicator. A faithfulness score below 0.85 in production is a red flag requiring investigation. RAGAS achieves 95% agreement with human judgment on this metric, making it a reliable automated proxy for manual review.
- Answer Relevancy: How semantically aligned the answer is with the original query. High faithfulness with low relevancy indicates a system that is accurate but not answering what was actually asked — a different failure mode but equally problematic in practice.
- Context Precision and Recall: Whether the retrieval step is pulling the right documents (precision) and not missing relevant ones (recall). These metrics help distinguish retrieval failures from generation failures — a distinction that is critical for directing improvement work.
- Mean Reciprocal Rank (MRR): How highly the most relevant retrieved document is ranked. Useful for evaluating the re-ranking layer if you have one.
Business-Level KPIs That Matter
Technical metrics need to connect to business outcomes or they will not sustain organizational attention. The business KPIs that have proven most useful for RAG program management:
- Escalation rate: The percentage of AI-generated responses that require human review or correction. This is the clearest business-level signal that faithfulness metrics are declining.
- Task completion time: For productivity-focused deployments (legal research, support resolution, policy lookup), the time users spend to complete tasks with versus without the RAG system.
- Token cost per productive query: Total LLM token spend divided by queries that resulted in a successful outcome (not just any query). As systems are optimized, this metric improves — semantic caching of common queries, for example, has been shown to reduce LLM costs by up to 68.8%.
- Knowledge base staleness rate: The percentage of indexed documents that are more than a defined threshold old (often 90 days for policy content). This is a leading indicator of accuracy degradation before it shows up in faithfulness scores.
Building an Evaluation Cadence
Evaluation should not be a one-time pre-launch activity. Establish a baseline before deployment, run automated RAGAS evaluation on a random sample of production queries weekly, and trigger manual review when any metric drops more than 10% from baseline. When model providers update their models (which happens without announcement and can change generation behavior significantly), run a full evaluation cycle before relying on results for high-stakes decisions.
Governance, Security, and Compliance: Building Trust Into the Architecture

Governance failures kill RAG projects in regulated industries faster than any technical problem. A system that produces excellent answers but exposes HR data to sales teams, or surfaces draft compliance documents to external auditors, creates organizational risk that no accuracy metric can offset. Security and governance need to be designed in from day one — not bolted on after a compliance review raises concerns.
The Architecture-Enforced Governance Principle
The single most important governance principle: access controls must be enforced at the retrieval layer, not at the application layer. An application-layer gate (the UI only shows certain results to certain users) is easily bypassed through API access, prompt injection, or simple misconfiguration. Retrieval-layer enforcement — where the vector search itself only considers documents the querying user has permission to access — is architecturally robust.
Implementation: embed user identity and role in every retrieval request. Use metadata filters on chunks to restrict retrieval to documents within the user’s permission scope. Enforce row-level security at the vector database level where the database supports it. Test permission enforcement explicitly, including testing that privilege escalation through prompt manipulation is not possible.
Data Protection in the Pipeline
RAG pipelines handle sensitive organizational data at multiple stages: during ingestion (where documents are parsed and chunked), during indexing (where embeddings are stored), and during generation (where retrieved content is included in LLM prompts). Each stage represents a potential exposure point.
Core data protection requirements for regulated industries:
- Storage encryption: AES-256 encryption for vector stores and document repositories at rest. TLS for all data in transit between pipeline components.
- PHI and PII handling: Anonymize or tokenize personally identifiable information before ingestion where the use case does not require it. For healthcare deployments, HIPAA-compliant handling must be documented at each pipeline stage.
- Data minimization: Index only the data the RAG system actually needs to answer the queries it is designed for. Broad indexing of all organizational data creates risk without proportionate benefit.
- Audit trails: Log every retrieval operation with user identity, timestamp, query, and retrieved document references. These logs are essential for compliance audits and for diagnosing incidents after the fact.
Governance as Organizational Infrastructure
Beyond technical controls, RAG governance requires organizational structure. Assign clear ownership of the knowledge base with defined responsibilities for content freshness, accuracy review, and access classification. Establish a change management process for knowledge base updates — particularly for content that informs high-stakes decisions. Define SLAs for the RAG system and treat violations as incidents requiring root cause analysis.
Organizations that treat their RAG knowledge base as seriously as they treat a database schema — with versioning, change approval processes, and clear data ownership — consistently produce more reliable systems than those that treat it as a shared file repository. The content is infrastructure. It deserves infrastructure-grade management.
The Business Case: ROI Framework for RAG Investments
Making the internal case for RAG investment requires connecting architectural decisions to financial outcomes. The data on RAG ROI in 2026 is detailed enough to build credible business cases, with real deployment numbers available for several use case categories.
Benchmarks From Real Deployments
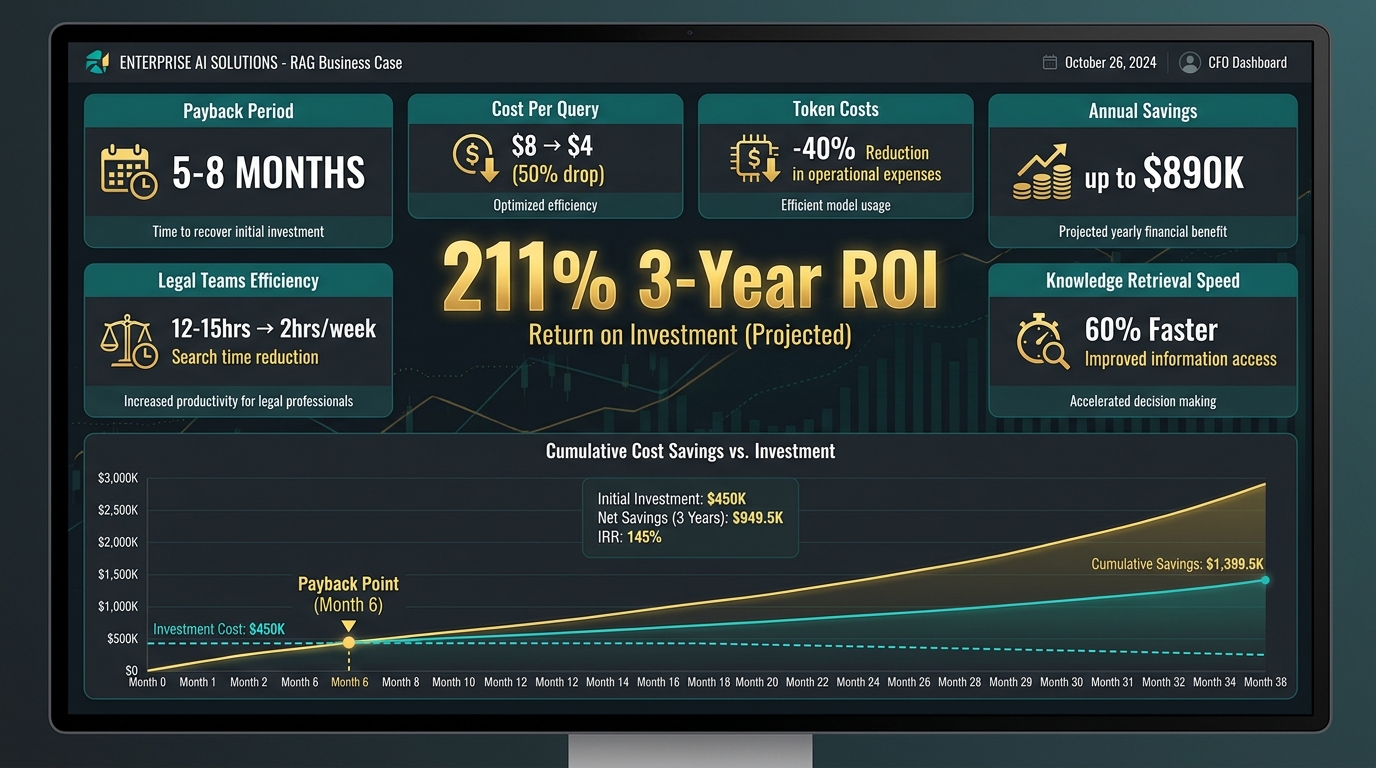
A mid-sized financial services firm with 200,000 annual knowledge queries implemented a production RAG system for their internal knowledge management function. The results after one year: cost per interaction dropped from $8.00 to $4.00 through reduced verification requirements and faster response times. Annual net benefit: $890,000. Payback period: approximately 8 months. The ROI improvement came primarily from reduced analyst time spent searching documents and from fewer escalations requiring senior review.
A legal team deployment shows a different profile but comparable returns. Pre-RAG: 12–15 hours per week spent searching document repositories for relevant case materials, regulatory precedents, and contract clauses. Post-RAG: under 2 hours per week for the same scope of search. For a team of 6 attorneys at fully-loaded hourly costs, the time savings alone justified the investment within 4–5 months.
A smaller-scale pilot ($22,000 implementation cost) in a professional services context generated year-one savings of $39,740 through productivity gains and reduced error rates, delivering a 3-year ROI of 211%. The payback period was 5.2 months.
Where the Financial Return Actually Comes From
Across these cases, RAG ROI concentrates in five measurable categories:
- Labor time displacement: Knowledge workers spending less time searching and more time on judgment-intensive work. This is typically the largest ROI driver and the most straightforward to quantify.
- Error and escalation reduction: Fewer downstream corrections, rework cycles, and senior escalations when frontline staff have access to accurate, sourced answers.
- Token cost efficiency: Semantic caching of common queries reduces LLM API costs by up to 40% in mature deployments. At scale, this compounds significantly.
- Avoided compliance costs: Quantifying this requires estimating incident probability, but for regulated industries the cost of a single material compliance failure often exceeds the entire cost of a RAG governance implementation.
- Reduced IT maintenance: Well-designed RAG systems require significantly less ongoing maintenance than fine-tuned models. Maintenance costs dropping from $120,000 to $30,000 annually has been documented in enterprise deployments.
Building a Credible Internal Business Case
The most credible business cases for RAG investment start with a specific, measurable use case rather than a general “AI knowledge management” initiative. Quantify the current cost of the problem the RAG system will solve: how many hours per week, at what fully-loaded cost, do knowledge workers spend searching for information? What is the error rate on decisions made with inadequate information access, and what does each error cost to correct?
Use conservative assumptions for the improvement estimate — targeting 50% time savings rather than 80%, for example — and model the implementation cost with realistic scope. A pilot with well-defined scope, clear success metrics, and a measurement plan is far more likely to get funding, deliver on expectations, and convert to a scaled deployment than a broad initiative with aspirational ROI projections.
A Phased Implementation Roadmap That Actually Works
The difference between RAG implementations that reach production and those that don’t is often not technical capability — it is scope discipline and sequencing. The teams that succeed do less in phase one, measure more, and earn the right to expand.
Phase 1: Scoped Pilot (Weeks 1–8)
Choose a single, well-defined use case with a bounded knowledge domain. “Internal HR policy Q&A” is better than “all company knowledge.” “Technical support for product line X” is better than “all products.” The narrower the scope, the more control you have over data quality, evaluation, and iteration speed.
Key phase 1 deliverables:
- Chunking strategy documented and justified for your specific document types
- Metadata schema defined for all ingested documents
- Baseline evaluation metrics established (faithfulness, answer relevancy) before any users access the system
- Permission model implemented and tested
- Semantic caching configured for predictable query patterns
Do not build a user interface in phase 1. Build the retrieval pipeline, test it with synthetic queries, measure it against your baseline, iterate on chunking and retrieval configuration, and only then build the interface. Teams that build the UI first spend phase 1 managing user expectations instead of improving the system.
Phase 2: Production Hardening (Weeks 9–16)
Introduce real users with a defined beta group. Monitor evaluation metrics daily. Establish the knowledge base governance process with clear ownership and update schedules. Implement observability: every query, retrieval, and generation should be logged with enough detail to reconstruct what happened for any given response.
Phase 2 is where architecture decisions get stress-tested. Query patterns you did not anticipate in phase 1 will emerge. Chunking strategies that worked for your test queries will fail on some real-world questions. Evaluate whether hybrid retrieval should be added, whether re-ranking improves the highest-priority query types, and whether any content in the knowledge base is causing accuracy problems.
Phase 3: Scale and Expand (Month 5 Onward)
Expansion to additional use cases or knowledge domains should only happen after phase 2 delivers stable metrics. Each expansion is effectively a new phase 1 — bounded scope, documented chunking strategy, established evaluation baseline — applied to the new domain. The infrastructure scales; the discipline stays the same.
At scale, evaluate whether agentic retrieval improves outcomes for complex multi-document queries. If query patterns show consistent multi-hop reasoning requirements, architect the agentic layer carefully — with loop termination controls, full trace logging, and dedicated latency monitoring for the expanded retrieval cycles.
Continuous Improvement as Steady State
A mature RAG system is not a deployed artifact — it is an active system requiring ongoing attention. Model provider updates, knowledge base changes, shifting query patterns, and evolving business requirements all affect system performance over time. Establish a quarterly review cadence that examines evaluation metrics trends, knowledge base coverage gaps, and cost efficiency metrics. Budget for this ongoing work as part of the initial business case. Teams that present RAG as a one-time deployment cost consistently underdeliver on long-term ROI.
The Infrastructure Decisions That Will Make or Break You at Scale
Several technical decisions that seem minor in a pilot environment become critical constraints at production scale. Getting these right before you have hundreds of concurrent users is substantially easier than retrofitting them afterward.
Separate Your Indexing and Query Pipelines
Single-pipeline architectures — where document ingestion and query serving share the same process — create resource contention that degrades query latency during indexing operations. Production-grade RAG systems use separate pipelines: an asynchronous indexing pipeline that handles document ingestion, chunking, embedding generation, and index updates in the background; and a synchronous query pipeline optimized for sub-2 second time-to-first-token at the p90 latency percentile.
This separation enables incremental index updates via change data capture (CDC) — detecting and indexing only changed documents rather than full re-indexing — which can deliver sub-minute knowledge freshness without the cost of full re-indexing. For organizations with continuously updating knowledge bases (policy documents, pricing data, operational records), this architecture is the difference between near-real-time and hours-delayed information.
Semantic Caching at Scale
In any production RAG deployment, a significant fraction of queries are semantically similar to previous queries. A support tool fielding hundreds of daily questions about the same product features will retrieve very similar context for very similar questions. Semantic caching — storing the results of recent retrievals and serving them for semantically equivalent new queries without hitting the vector database or LLM — can reduce LLM costs by up to 68.8% in mature deployments.
Implementation requires a cache validity strategy: how long should a cached retrieval result be considered fresh? For stable knowledge bases, cache TTLs of hours to days may be appropriate. For dynamic content with frequent updates, much shorter TTLs or event-driven cache invalidation tied to knowledge base changes are necessary.
Vector Database Selection Is More Nuanced Than Benchmarks Suggest
The vector database market has matured significantly, with capable options including Pinecone, Weaviate, Qdrant, pgvector (PostgreSQL extension), Redis, and Chroma, among others. Benchmarks comparing query latency and recall tend to produce similar results across leading options at typical enterprise scale. The more differentiating factors are operational: Does it integrate with your existing infrastructure? Does it support the metadata filtering your permission model requires? Does it offer row-level security? What is the operational overhead of managing the deployment?
For teams already running PostgreSQL, pgvector with proper indexing (HNSW indexes) delivers competitive performance with dramatically lower operational overhead than deploying a dedicated vector database service. For high-scale deployments where vector search is the primary bottleneck, a purpose-built vector database’s performance optimizations become more relevant. Match the tool to the constraint, not to the benchmark leaderboard.
Conclusion: Building RAG That Earns Long-Term Trust
The common thread running through every successful RAG implementation is a refusal to separate technical quality from organizational trust. Systems that users trust — that they rely on for decisions that matter — are not just technically accurate. They are accurate consistently, under diverse query conditions, as knowledge changes, and across the full population of users rather than just the ones whose queries resemble the test set.
Building that kind of trust requires treating the knowledge base as infrastructure, not content. It requires measuring faithfulness and relevancy continuously, not just at launch. It requires governance that enforces document ownership and access controls as rigorously as any other enterprise data system. It requires an architecture that separates the responsibilities of ingestion, retrieval, and generation so that failures in one component can be isolated, diagnosed, and fixed without rebuilding the whole system.
None of this is especially exotic. The techniques exist, the measurement frameworks exist, the governance patterns exist. What is consistently missing in failed implementations is not capability but discipline — the decision to invest in the unglamorous foundations before the impressive user interface, to measure before you optimize, and to earn trust in a bounded scope before expanding to the full organization.
Key Takeaways
- Chunking strategy outweighs most other architectural decisions — invest time in domain-appropriate chunking before choosing a vector database or LLM provider.
- Hybrid retrieval (vector + BM25) should be the production default — the 1–9% recall improvement over pure vector search is consistent and the implementation cost is minimal.
- RAG beats fine-tuning economically for dynamic knowledge bases — $18K year-one cost versus $31K, with zero retraining cost for knowledge updates.
- Governance must be enforced at the retrieval layer, not the application layer — application-layer gates are architecturally fragile and compliance-inadequate.
- Establish evaluation baselines before launch — RAGAS faithfulness scores and business KPIs tracked from day one enable proactive detection of degradation.
- Payback periods of 5–8 months are achievable, but only when the use case is specific, the success metrics are defined in advance, and the knowledge base is actively governed.
- Separate indexing and query pipelines before you go to production, not after latency problems surface.
- Scope the pilot deliberately small — the teams that succeed at scale are almost universally the ones that resisted the pressure to boil the ocean in phase one.
The RAG market will continue growing as organizations find genuine, measurable value in grounded AI systems. The ones that find that value are not the ones with the most sophisticated models or the largest budgets. They are the ones that respect the unglamorous work of data quality, evaluation rigor, and governance discipline that makes the difference between a demo that impresses and a system that performs.


