


There is a specific window of time — usually between six and eighteen months — where an AI trend has enough real-world traction to act on, but hasn’t yet become so mainstream that your competitors are already building around it. That window is where careers accelerate, products get built with lasting moats, and businesses quietly pull away from the pack. Miss it, and you’re spending twice as much competing for the same ground.
The challenge isn’t that AI moves too fast. It’s that most people are looking at the wrong signals. They’re reading the same TechCrunch headlines, watching the same LinkedIn thought leaders, and showing up at the same conferences — sources that, by the time they publish, are already broadcasting information that the informed minority absorbed months ago.
This article isn’t about the trends themselves. It’s about the intelligence practice behind finding them early. Specifically, how to build a personal or organizational system that consistently picks up on AI developments while they’re still in the research phase, early enterprise pilots, or niche community adoption — long before they explode into mainstream coverage and competitive crowding.
We’ll cover the five-layer signal framework, how to read research papers without a technical background, what VC funding patterns actually tell you and when they don’t, the community-based intelligence that most operators ignore, and how to build a 90-day evaluation process that turns raw signals into strategic decisions. This is a practitioner’s guide — built for people who want to act, not just observe.
Why Most People Spot AI Trends Too Late
The fundamental problem is where most people get their information. General-purpose tech media, LinkedIn posts from influencers, and industry newsletters all share one thing in common: they publish after something has already reached critical mass. By the time a trend earns enough readership to justify a feature article, the early movers are already nine months into execution.
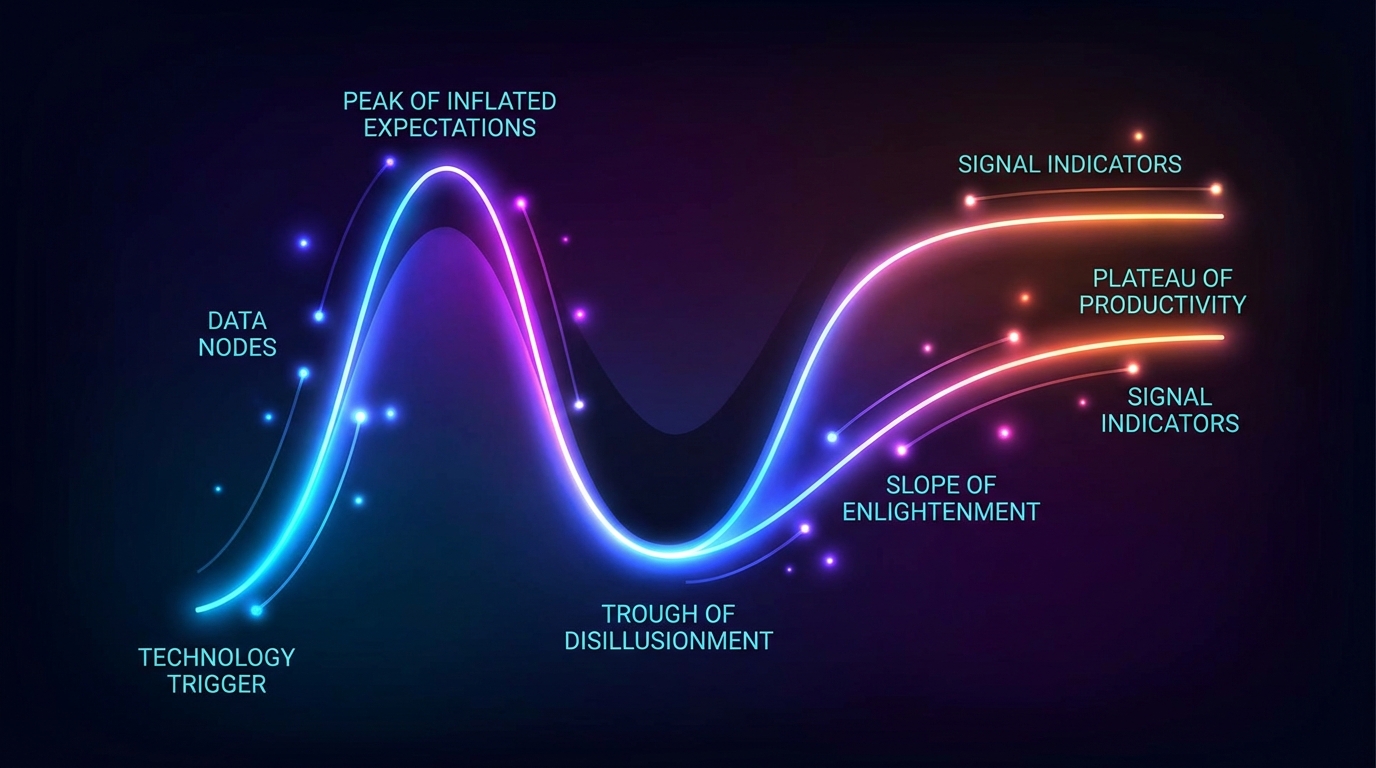
The Hype Cycle as a Positioning Tool
Gartner’s Hype Cycle is often cited but rarely used properly. Most people treat it as a curiosity — a diagram that explains why things went wrong in retrospect. Used proactively, it’s a positioning map. Each phase of the cycle has a different risk/reward profile, and understanding where a specific AI capability sits on that curve tells you what kind of move to make.
As of the 2025 cycle (the most recent published as of early 2026), Generative AI has entered the Trough of Disillusionment. This sounds alarming, but it’s actually instructive. The Trough signals that the early hype has burned off, the failed experiments have been catalogued, and the real use cases are beginning to separate from the wishful thinking. It’s often the best time to build — not because it’s exciting, but because the crowd has thinned out.
The data supports this paradox. Despite widespread disillusionment, worldwide AI spending is projected to reach $2.5 trillion in 2026 — a 44% increase year-over-year. Companies that invested an average of $1.9 million in GenAI during 2024 saw fewer than 30% of their CEOs report satisfaction with the returns. That gap between investment and satisfaction is where the Trough lives. But it’s also where the practitioners who know what actually works gain ground on those who followed the hype.
The “Mainstream Lag” Problem
Here’s the mechanics of the timing problem. A research paper describing a new capability is published on arXiv. A handful of ML engineers read it within the first two weeks. Three months later, a startup raises a seed round to commercialize it. Six months later, a blog post explaining the concept in plain English appears. Twelve months later, it’s a LinkedIn carousel. Eighteen months later, it’s a keynote at a major conference.
Most business operators enter the awareness cycle at the blog post or LinkedIn carousel stage. By then, they’re not ahead — they’re behind everyone who reads research, follows early-stage funding, and participates in technical communities. The goal of this guide is to move your entry point from the blog post stage back to the research paper and seed funding stage — without requiring you to become a machine learning researcher.
The Cost of Lateness
Late trend adoption isn’t just a missed opportunity. It carries real costs. You’re competing against companies that have already learned what doesn’t work, have iterated on their approach, and often have distribution advantages they built when the space was less crowded. The SEO landscape for a trend-adjacent keyword is already dominated. The niche creator community has already developed loyalty to established voices. The hiring market for relevant skills is more competitive and more expensive.
Moving six months earlier doesn’t just mean arriving first. It means arriving when the rules of the game haven’t yet been written — which is when you have the most ability to shape them in your favor.
The Five Signal Layers That Precede a Trend’s Peak

No single data source tells the whole story. The most reliable early detection comes from triangulating across multiple layers — each of which has different lead times and different reliability characteristics. Think of these layers as a signal stack, where the bottom layers are the earliest and most technical, and the upper layers are more accessible but also more lagged.
Layer 1: Academic Research Velocity
The earliest reliable signal for AI trends comes from academic and applied research output. Platforms like arXiv, Semantic Scholar, and Papers With Code are where ideas surface before anyone has built a product around them. The key metric isn’t just whether a paper exists — it’s how fast related papers are being published on the same topic, and how quickly those papers are accumulating citations.
A sudden spike in arXiv submissions across a narrow category (for example, cs.LG for machine learning, cs.CL for language models, or cs.RO for robotics) often precedes commercial interest by six to twelve months. This is because research publication is the first formal record of an idea getting serious attention. When five teams publish independently on the same technique in the same quarter, that convergence is a signal that something is being validated across institutions.
You don’t need to read every paper. The abstract, the conclusion, and the benchmark comparisons table will tell you the essential story in most cases. More on the non-technical reading strategy in the next section.
Layer 2: Open-Source Repository Activity
When researchers or engineers release code to accompany a paper or experiment, that release on GitHub becomes a trackable signal. The metrics that matter are: stars (interest), forks (intent to build), pull request velocity (active development), and the number of derivative repositories that appear in the weeks following a release.
A repository that accumulates 1,000 GitHub stars within its first two weeks of existence is behaving differently from one that accumulates 1,000 stars over a year. The velocity matters as much as the volume. Rapid early adoption of an open-source release indicates that a large latent community was already watching for exactly this kind of tool or capability.
GitHub’s own trending page is a rough indicator, but it’s too surface-level for serious signal work. The more useful approach is to monitor specific organizations — university labs, major AI research institutions like DeepMind, Meta FAIR, and MIT CSAIL, plus key individual researchers — and track when they release new repositories outside of their normal output cadence.
Layer 3: Venture Capital Funding Patterns
VC funding functions as a signal, but the signal quality depends heavily on which stage you’re watching. Seed and pre-seed rounds — typically under $5 million — are the most forward-looking. They represent investor bets on something that doesn’t yet have commercial validation. When multiple seed rounds cluster around a similar technical theme within the same two-quarter window, it suggests that professional investors who track research closely are seeing the same signal you should be looking for.
By contrast, mega-rounds — the $100 million-plus raises that dominate headlines — are confirmation signals, not leading signals. When you read that a company has raised $200 million in a Series C for an AI capability, the trend has already been validated. You’re not early anymore. In Q1 2026, AI captured more than 80% of all global VC activity, with total AI funding reaching approximately $242 billion. That’s not an early signal. That’s mainstream capital deployment.
The useful question to ask is: what seed rounds are happening this quarter that nobody is writing about yet?
Layer 4: Job Posting Language Shifts
Enterprise job postings are an underused but highly reliable trend signal. When a new technical capability or methodology starts appearing in job descriptions — especially at companies with large engineering organizations — it means that organization has already decided to build or integrate that capability and is now resourcing it. That decision typically comes after an internal evaluation period of three to six months.
Tracking LinkedIn job posts, Indeed, and specialized boards like Greenhouse or Lever for new or unusual skill requirements gives you a real-time picture of what enterprises are committing budget and headcount to. A surge in postings for a specific skill that didn’t exist in those job descriptions twelve months ago is one of the most actionable trend signals available.
Layer 5: Niche Community Conversation Density
The fifth and perhaps most undervalued layer is the density and quality of conversation in communities that are ahead of mainstream awareness. This includes specific subreddits (r/MachineLearning, r/LocalLLaMA, r/ArtificialIntelligence), Discord servers for AI tools and developer communities, Slack groups for specific engineering disciplines, and the comments sections under key technical blog posts from institutions like Anthropic, DeepMind, and OpenAI.
The signal here isn’t just that a topic is being discussed. It’s about the quality of the discussion. When highly technical practitioners are asking implementation questions — “how do I integrate this into a production environment?” rather than “what is this?” — you’ve moved from curiosity to adoption. That shift in question type is a meaningful indicator that the trend has crossed from theoretical interest to practical use.
Reading Research Papers Without a PhD

The most common reason business operators skip the research layer is an assumption that they need a technical background to extract value from academic papers. In reality, you can get 80% of the commercially relevant information from any AI paper without reading a single equation — if you know where to look.
The Three-Pass Reading Method
Popularized by machine learning practitioners including Andrew Ng, the multi-pass reading approach is worth adapting for trend intelligence work. For business purposes, three targeted passes are sufficient.
Pass 1 — The Five-Minute Overview: Read the title, abstract, and conclusion only. The abstract tells you what problem the paper is solving and what the authors claim to have achieved. The conclusion tells you what worked, what limitations exist, and what the authors think should come next. In five minutes, you know whether this paper represents an incremental improvement or a potentially significant capability shift.
Pass 2 — The Benchmark Scan: Jump to the results tables and figures. Benchmark comparisons tell you how this approach performs against prior state-of-the-art methods. If the new approach shows significant performance gains (not just marginal ones) on well-recognized benchmarks, that’s a signal worth flagging. You don’t need to understand the technical mechanism to understand that a 40% improvement on a standard measure is meaningful.
Pass 3 — The Future Work Check: Look at the “limitations” and “future work” sections near the end. These tell you what problems the authors themselves see as unsolved — which is often the roadmap for the next wave of papers and startups. Knowing what open problems exist in a space tells you where the next six months of research energy will concentrate.
The arXiv Categories That Matter for Business
arXiv is organized by category, and not all of them are equally relevant for business-oriented trend spotting. The highest-signal categories for AI business applications are:
- cs.LG (Machine Learning): Core learning algorithms, training methods, efficiency improvements. This is where foundation model innovations surface.
- cs.CL (Computation and Language): Language models, NLP, reasoning systems, agents. If you’re watching the trajectory of language AI, this is the primary source.
- cs.AI (Artificial Intelligence): Broader AI systems, planning, reasoning, autonomous agents.
- cs.RO (Robotics): Embodied AI, physical AI systems, human-robot interaction. Given the emerging physical AI trend, this category is increasingly relevant for non-robotics businesses.
- cs.CV (Computer Vision): Image and video understanding, multimodal systems, generative visual models.
Tools like Semantic Scholar, Papers With Code, and several GitHub repositories built specifically for arXiv monitoring allow you to set up email digests or dashboards that surface papers matching specific topic queries — without requiring you to manually browse thousands of daily submissions.
What Signals a Breakthrough (vs. an Incremental Step)
Not every paper represents a meaningful trend signal. The indicators that distinguish potentially significant papers from routine incremental work include: performance gains of 15% or more over existing benchmarks, methods that remove a previously fundamental limitation (like requiring massive compute for training), results that replicate across multiple datasets or domains, papers that appear with corresponding open-source implementations, and papers that come from multiple independent labs simultaneously rather than a single team.
Convergent discovery — where several groups independently arrive at similar results — is one of the strongest signals that a capability is real, reproducible, and on the verge of commercialization.
The VC Funding Ladder: Reading Investment Signals Correctly
Not all investment activity tells the same story. The most useful framework for using VC data as a trend intelligence tool is understanding the information content at each stage of the funding ladder — and being clear-eyed about which stage actually signals “early.”
Pre-Seed and Seed: The Forward-Looking Stage
Pre-seed and seed funding — typically ranging from $500,000 to $5 million — is where professional investors make bets on unproven ideas backed by strong research signals and early founder capability. These rounds often happen before a product has been built, sometimes before a company has even been incorporated in its final form. They are the earliest commercial validation of a technical idea.
When you see three or four seed rounds cluster around a similar technical theme within a single quarter, that clustering is meaningful. Professional investors at this stage are typically tracking arXiv, monitoring specific research labs, and meeting with PhD candidates before they’ve graduated. They’re operating from the same signal layers described earlier — just with more access and full-time focus. Their investment decisions are effectively a curated signal service, available for free to anyone who monitors public funding announcements.
Sources like Crunchbase, PitchBook (with subscription), TechCrunch’s Startups section, and dedicated newsletters like The Information and The Generalist track early-stage rounds. Set up alerts for companies tagged with specific AI categories and monitor the descriptions of what they’re building.
Series A and B: The Validation Stage
By the time a company reaches Series A — typically $10 million to $50 million — the concept has been validated with real customers. This is still a relatively early signal for trend purposes, but you’re now looking at something that has crossed from “possible” to “working.” The trend is real. The question is whether it’s large enough to be worth acting on strategically.
Series B rounds are useful for a different reason: they indicate that a capability is being productized and sold at scale. The company is now spending heavily on go-to-market, which means awareness will increase rapidly over the next twelve to eighteen months. If you’re not already positioned at Series B stage, you’re entering a space that’s about to get crowded.
Mega-Rounds: The Confirmation Lag Signal
In 2026, AI mega-rounds have become so routine that they function primarily as market temperature gauges rather than trend signals. When a leading AI company raises $110 billion or a frontier lab raises $30 billion, these aren’t indicators of where the next interesting AI development is coming from — they’re confirmation that large language models and AI infrastructure are fully mainstream. The early window on those trends closed years ago.
The practical takeaway: use mega-rounds to understand the market context, but never use them as your primary trend signal. By the time the headline appears, you’re twelve to twenty-four months late on the strategic window.
Geography as a Signal
One dimension of VC data that’s often overlooked is the geography of early-stage activity. Seed rounds in non-traditional AI hubs — cities that aren’t San Francisco, New York, or London — often indicate that a capability has matured enough to be commercialized by non-specialized talent. This geographic diffusion is itself a signal of trend maturation and mainstream accessibility.
Turning Online Communities Into Trend Intelligence
The internet’s most valuable trend intelligence doesn’t live in paywalled reports or curated newsletters. It lives in the unfiltered, real-time conversations happening in communities where practitioners share work-in-progress thinking, tool discoveries, frustrations, and early wins. Learning to read these communities systematically is one of the highest-return intelligence activities available to business operators.
Reddit as a Leading Indicator
Several subreddits function as early-warning systems for AI development trajectories. The quality of signal varies by community, and understanding the composition of each is important for interpreting what you’re seeing.
r/MachineLearning skews heavily toward researchers and advanced practitioners. Posts discussing new papers, open-source releases, and experimental findings here are strong early signals. The comment quality is high — disagreements are technical and substantive. A paper post that generates hundreds of high-quality comments is worth reading carefully.
r/LocalLLaMA has become an invaluable signal source for the trajectory of on-device and locally-run AI models. This community’s discussion reflects what practitioners can actually do with open-weight models today — which is often 12 to 18 months ahead of what mainstream enterprise coverage acknowledges as possible.
r/singularity and r/artificial skew more consumer and general interest, which means they lag behind the technical communities. They’re better indicators of when a trend is crossing into broader public awareness — useful for timing content and marketing, less useful for strategic early detection.
Discord and Slack: The Highest-Signal Layer
Discord servers for specific AI tool communities — particularly those attached to fast-moving open-source projects — contain some of the richest early-signal content available. When practitioners are sharing bugs they’ve encountered while building production systems, posting early benchmarks from their own testing, or asking integration questions, that activity indicates a level of real-world engagement that public platforms often lag by months.
The challenge with Discord as a signal source is discoverability and scale. There’s no public index of what’s being discussed across thousands of private servers. The practical approach is to join the Discord communities attached to ten to fifteen specific tools or research projects you’re tracking, and establish a weekly review habit for each. The investment is two to three hours per week, but the signal quality is significantly higher than what’s available through public media.
LinkedIn Job Titles as Leading Indicators
A less obvious but highly reliable community signal comes from LinkedIn job title patterns. When a new role type begins appearing frequently — especially at mid-size companies rather than just the largest tech firms — it indicates that a function or capability has reached broad enterprise adoption. New job titles are often created to describe work that existing job descriptions don’t cover, which means they’re created at the adoption frontier.
In 2023, “Prompt Engineer” titles began appearing. By 2024, companies were hiring “AI Integration Leads.” In 2025, “AI Governance Officer” and “AI Infrastructure Engineer” became common at companies outside the core AI sector. Each of those title shifts was a signal that the underlying capability had moved from experimentation to operational deployment.
Twitter/X Technical Communities
Despite general uncertainty about the platform’s long-term direction, Twitter/X remains highly active for specific technical communities. The subset of ML researchers, AI engineers, and startup founders who share working notes, paper summaries, and tool discoveries on the platform are operating at the same early-signal layer as arXiv and GitHub. Following the right 100 accounts on this platform gives you a real-time feed of early thinking that no newsletter can replicate.
The key is curation. A raw Twitter/X feed is noise. A carefully curated list of researchers, lab accounts, open-source contributors, and serious practitioners is a signal channel. Building that list takes time, but it’s a durable intelligence asset once established.
The Tools Stack for Systematic Trend Spotting
You don’t need an enterprise intelligence budget to build a functional trend-spotting system. A thoughtfully assembled stack of free and low-cost tools, used consistently, produces better results than expensive platforms used sporadically.
Search and Discovery Tools
Exploding Topics scans millions of unstructured data points across Google, Reddit, TikTok, Spotify, YouTube, and e-commerce platforms, using machine learning to classify trends as “Regular,” “Exploding,” or “Peaked.” The platform claims to surface trends up to twelve months before mainstream awareness. Their own retrospective data supports this — their system flagged “AI writing” as an emerging trend in July 2021, more than a year before ChatGPT brought it into mainstream consciousness. The free tier provides limited access; the Pro subscription unlocks the full database and trend history.
Google Trends remains the most accessible validation tool for a suspected trend. Its value isn’t in discovery — it’s in confirmation and timing. When you’ve identified a signal through a more specialized source, Google Trends tells you how far that signal has already diffused into general search behavior. A trend with strong signals in the research layer but still-flat Google Trends data is in the early adoption window. A trend that already shows steep growth in Google Trends is approaching mainstream.
Glimpse extends Google Trends with predictive scoring and monitors early adoption signals specifically from Reddit, TikTok, and Discord — the communities that precede mainstream search behavior. It’s particularly useful for consumer-facing AI applications where community adoption precedes search volume by months.
Research and Repository Monitoring
Semantic Scholar (free) provides citation tracking and topic-level analytics for academic papers. Setting up alerts for specific topics or authors ensures that relevant research surfaces in your inbox without manual browsing. Their API allows more sophisticated monitoring for those willing to do basic scripting.
Papers With Code (free) links research papers directly to their corresponding GitHub implementations, benchmarks, and datasets. This is the fastest way to find papers that have moved from theory to working code — a key signal of near-term commercial applicability.
GitHub Trending (free) shows the fastest-growing repositories by day, week, and month. While the page-level view is surface-level, using GitHub’s search and topic filter functions to track specific areas (for example, searching for repositories tagged “llm,” “agents,” “multimodal,” or “robotics” and sorting by recent stars) gives a more directed signal.
Funding Intelligence Tools
Crunchbase (free tier + paid) allows you to set up alerts for funding rounds in specific categories or geographic regions. The free tier is sufficient for basic seed and early-stage monitoring. Filtering for “Artificial Intelligence” companies with rounds under $10 million, sorted by date, gives you a running list of early-stage bets happening in real time.
Y Combinator’s portfolio directory is underused as a trend signal. Each YC batch contains companies that are six to twelve months ahead of the market in identifying viable AI applications. The batch descriptions and company one-liners from Demo Day are a free, curated signal source that’s published twice yearly.
Community Aggregation
Hacker News remains one of the most reliable aggregators of technical community sentiment. Its Ask HN and Show HN threads are particularly useful — they represent practitioners sharing real work and asking genuine questions about implementation challenges, which is a strong signal of active adoption rather than passive interest.
Substack and similar newsletter platforms have become home to some of the highest-quality AI analysis available. The challenge is that subscribing to too many creates its own noise problem. The discipline here is to curate ruthlessly — maintain a list of five to eight newsletters that consistently contain first-hand insights rather than aggregated summaries of mainstream coverage.
From Signal to Strategy: The 90-Day Trend Evaluation Framework
Identifying a signal is the beginning, not the end. The mistake most operators make is moving too quickly from “I’ve seen this mentioned three times” to “we should build something.” Conversely, the opposite mistake is spending so long in evaluation mode that the window closes before any decision is made. The 90-day framework creates a structured process that balances speed with rigor.
Days 1–14: Signal Collection and Classification
When a new potential trend signal surfaces — whether from a research paper, a GitHub repository spike, a cluster of seed rounds, or a community discussion pattern — the first two weeks are for collection, not action. Your job in this phase is to gather every adjacent piece of evidence you can find without trying to form a conclusion.
During this phase, document: the source of the original signal, what layer it came from (research, code, funding, jobs, community), any contradicting signals you encounter, the approximate timeline of the earliest mentions you can verify, and the names of the practitioners or organizations most actively involved.
Classify the signal according to two dimensions: signal strength (how many independent sources have confirmed this independently?) and business relevance (how directly does this connect to a market you operate in or could plausibly enter?). Keep both dimensions separate at this stage — a high-strength signal in a low-relevance domain is not a priority, and a high-relevance signal with weak confirmation deserves more investigation before action.
Days 15–42: Cross-Layer Validation
The validation phase is where you attempt to confirm the signal across multiple independent layers. A trend that appears simultaneously in research velocity, GitHub activity, seed funding, and niche community discussion is far more reliable than one that only appears in one layer. The presence of cross-layer confirmation significantly reduces the probability that you’re looking at a momentary spike or a coordinated marketing push rather than genuine adoption momentum.
Specific validation tasks during this phase: search arXiv for related papers published in the last three months; check Crunchbase for seed rounds in the same technical category during the last six months; search LinkedIn for job postings requiring the relevant skill or describing the relevant workflow; find and join the most active Discord or Slack community where practitioners discuss this area; and locate at least three first-hand accounts from people actually using or building the technology.
At the end of this phase, you should be able to answer: Is this trend at the research stage, early adoption stage, or early mainstream stage? That positioning determines the urgency and type of strategic response required.
Days 43–90: Strategic Options Mapping
With a validated signal and a clear positioning on the adoption curve, the final phase maps available strategic responses. For most business operators, four options exist: build (invest in creating internal capability or a new product); buy/partner (work with companies already operating in this space); prepare (invest in learning and monitoring without committing resources to production); or wait (document the trend, set a review date, and revisit when more validation data is available).
The decision between these options should be driven primarily by two factors: the distance between the current adoption stage and mainstream adoption (which determines how much time you have before the window closes), and the cost of the minimum viable move in your context (which determines whether acting now versus later materially changes your competitive position).
The 90-day framework isn’t a rigid process. Some trends require a faster decision because the adoption curve is steep. Others warrant a longer evaluation because the technology is still in research and commercial applications are twelve or more months away. The framework is a starting structure, not a fixed prescription.
Signal vs. Noise: Why AI Trends That Look Real Often Aren’t
The same system that helps you find real trends early also exposes you to a high volume of false positives. AI is an unusually noisy domain because it attracts enormous media attention, significant financial speculation, and a large population of people with incentives to amplify certain narratives. Learning to filter aggressively is as important as learning to detect early.
The Fad Signature
Fads share several detectable characteristics that distinguish them from durable trends. The first is a sharp, symmetric search volume spike — rapid growth followed by equally rapid decline, without an established base. Real trends grow, plateau at a higher level than their starting point, and then continue to grow from that plateau. Fads return to baseline.
The second characteristic is a concentration of activity in commentary rather than construction. When most of the discussion around a technology is about what it might do, will do, or should do — rather than what practitioners are actually doing with it today — that is a signal that adoption is still aspirational rather than real. Actionable trends generate implementation questions. Fads generate philosophical discussions.
The third characteristic is a single-source origination. When a narrative about an AI capability originates primarily from one organization (often the one that created or is selling the capability) and then propagates through media, that origination pattern is a warning sign. Real trend signals emerge from multiple independent sources without coordinated announcement.
Disillusionment as a Filter
Gartner’s Trough of Disillusionment is a useful filter for separating lasting capabilities from oversold ones. The statistical reality, as of 2026, is instructive: despite billions invested in GenAI tools, a significant proportion of deployments have generated limited measurable ROI. That doesn’t mean the technology is worthless — it means the use cases that actually deliver value are narrower and more specific than the hype suggested. And identifying those specific use cases is itself a form of early trend detection.
The practical discipline is to maintain a “skepticism queue” — a list of trends you’ve noted but deliberately chosen not to act on, alongside your reasoning for waiting. Reviewing that queue quarterly and tracking which trends in it proved real versus which ones faded is an important calibration exercise. Over time, this review process builds pattern recognition for the specific characteristics that distinguish real signals from coordinated noise.
When Multiple Signals Don’t Converge
One of the most reliable noise filters is looking for the absence of convergence. If a trend appears strongly in VC funding and media coverage, but you can find no corresponding activity in research papers, GitHub repositories, or niche practitioner communities — that asymmetry is a red flag. It suggests that the narrative is ahead of the actual technical development, which is a classic pattern for a hype-driven spike without substance.
The inverse is also useful. A trend that shows strong convergent signals across research, code, and community — but very little VC funding or mainstream coverage yet — is a strong candidate for early positioning. The lack of media attention is a feature, not a bug. It means the window is still open.
Case Studies in Early Detection: What Getting It Right Looks Like
The most useful way to internalize the signal framework is through concrete examples of organizations and individuals who used it effectively — and what their early detection actually enabled.
Google’s 2016 AI-First Declaration
When Google CEO Sundar Pichai announced in 2016 that the company was pivoting from a “mobile-first” to an “AI-first” strategy, the decision wasn’t based on mainstream trends. Machine learning had been advancing in research since the early 2010s, but public awareness was minimal. Google’s research teams had been tracking the signal layer — particularly deep learning benchmark results in image recognition and language tasks — for several years before the announcement.
By 2023, Pichai was able to describe Google as “seven years into our journey as an AI-first company.” Those seven years of compounding investment in infrastructure, talent, and product integration created a depth of capability that competitors couldn’t replicate quickly. The competitive moat wasn’t the technology itself — it was the time advantage created by acting at the research signal stage rather than the mainstream awareness stage.
Amazon’s Recommendation Engine
Amazon’s item-to-item collaborative filtering system, which generates approximately 35% of the company’s total revenue, was developed in the early 2000s when personalization algorithms were a research-level concept rather than an established commercial practice. The team didn’t wait for the market to validate the idea — they read the research signal and built. Today, that investment makes it effectively impossible for new entrants to replicate the benefit without both the technology and two decades of behavioral data.
Early Agentic AI Adopters
Enterprises that began piloting agentic AI workflows in late 2023 — when the concept was still primarily discussed in research papers and ML Discord servers — entered 2026 with operational systems that had already undergone twelve to eighteen months of real-world debugging and refinement. By the time agentic AI became a mainstream enterprise topic in 2025, these early movers had already built internal expertise, identified the use cases that actually worked, and discarded the ones that didn’t. The result is a capability gap that late movers are now struggling to close.
The Pattern That Repeats
Across these examples and others, the same pattern emerges. Early movers weren’t luckier or better resourced. They were reading from different sources at a different stage of the adoption curve. Google’s AI-first call came from internal research teams, not from industry analysts. Amazon’s recommendation work came from academic collaboration on collaborative filtering algorithms, not from competitive intelligence on what retailers were doing. The edge was informational, not financial.
That informational edge is accessible to anyone willing to build the system to observe it. The tools are largely free. The communities are largely open. The research is publicly available. The barrier isn’t access — it’s consistency and the discipline to act before the window closes.
Building Your Personal Trend Intelligence System
The frameworks described in this article only generate value if they’re applied consistently. An intelligence system that runs for two weeks and then gets abandoned produces no compounding benefit. What follows is a practical operating cadence designed to be sustainable for a single person alongside a full professional workload.
The Weekly Cadence (90 Minutes)
Reserve 90 minutes per week — split into two 45-minute sessions — for active signal monitoring. The first session covers the research and code layer: scan your Semantic Scholar alerts, check Papers With Code for new entries in your tracked categories, and review GitHub trending repositories for the past seven days. The second session covers the community layer: read the weekly digest from your curated Discord/Slack channels, check your tracked subreddits for high-engagement technical posts, and scan your Twitter/X list for shared papers or tool releases.
The output of each week’s monitoring should be a single note — a brief log entry that captures: the strongest signal you saw, which layer it came from, whether it aligns with or contradicts existing trends you’re tracking, and any action items for follow-up. Over time, this log becomes a searchable record of your trend observations and, more valuably, a retrospective dataset you can use to calibrate your signal detection accuracy.
The Monthly Review (2 Hours)
Once per month, conduct a structured review of the trends you’re actively tracking. For each, update the signal strength assessment based on new evidence, note any changes in adoption stage, and decide whether to escalate to the 90-day evaluation framework, maintain current monitoring, or deprioritize.
This monthly review is also the right time to prune. Most intelligence systems fail not from under-collection but from over-collection — maintaining too many active trend threads makes the whole system feel unmanageable. A practical cap is fifteen to twenty active trend threads at any given time, with clear criteria for when one gets replaced by another.
The Quarterly Strategy Session (Half Day)
Four times per year, take half a day to assess the strategic implications of your current trend intelligence across three time horizons. The near-term question (zero to six months): which currently tracked trends are approaching mainstream adoption and require an active response? The medium-term question (six to eighteen months): which early-stage trends are developing in directions relevant to your business? The long-term question (eighteen months-plus): which research-stage signals suggest fundamental shifts in your industry’s competitive landscape?
This quarterly session is also where you compare notes with peers. Intelligence gathered independently is valuable; intelligence cross-referenced with two or three trusted colleagues who are tracking the same space from different vantage points is significantly more valuable. The goal isn’t agreement — it’s triangulation. Where your independent observations converge, the signal is stronger. Where they diverge, the discrepancy is worth investigating.
The Three-Source Rule
A practical discipline for avoiding both false positives and confirmation bias: before escalating any trend signal into active evaluation, require that you’ve seen independent evidence from at least three sources that occupy different layers of the signal stack. One research paper plus two community discussions from the same Discord server isn’t three sources — it’s one source amplified. A research paper, plus a seed funding announcement, plus practitioner implementation questions in a niche community — that is three genuinely independent sources, and it’s a signal worth taking seriously.
This rule slows down your reaction time slightly. It also dramatically reduces the number of false positives you act on — which is a worthwhile tradeoff for any organization making real resource commitments based on trend intelligence.
The Compounding Advantage of Consistent Signal Watching
The case for building a sustained trend intelligence practice doesn’t rest on any single observation or any single decision made early. It rests on compounding. Every accurate early identification builds your pattern recognition. Every false positive you catch improves your filtering. Every 90-day evaluation you complete — whether it results in action or a deliberate pass — adds to a personal library of how AI trends actually develop versus how they appear to develop from the outside.
After twelve months of consistent practice, you’ll find that you’re not just spotting individual trends earlier. You’re developing an intuition for the shape of adoption curves in your specific domain, the lead times between different signal layers in your industry, and the characteristics that distinguish durable capabilities from oversold moments. That intuition is difficult to transfer and difficult to replicate quickly — which means it becomes, over time, a genuine and durable advantage.
The window before an AI trend peaks is real. It’s measurable. And it’s accessible to anyone willing to build the system to observe it. The operators who treat trend intelligence as a practice — not a coincidence — are the ones who consistently find themselves in position to act when others are still reading about what they’ve already built.
The difference between early movers and late followers isn’t access to better information. It’s access to earlier information — and the discipline to act on it before it becomes common knowledge.
Key Takeaways
- The real signal lag is your information source. Mainstream media reports trends 12–18 months after the earliest detectable signals. Moving your sources upstream is the highest-leverage change you can make.
- Use five signal layers, not one. Research velocity, open-source activity, seed funding, job postings, and community discussion density each provide different information with different lead times. Cross-layer convergence is the strongest signal.
- VC mega-rounds confirm, not predict. Seed rounds are early signals. $100M+ raises are lagging indicators. Adjust how you use funding news accordingly.
- The 90-day evaluation framework prevents both premature action and missed windows. Structure the time between signal detection and strategic decision, and track your decisions retrospectively to build calibration.
- Require three independent sources before escalation. Cross-layer confirmation eliminates most false positives. One source amplified across media channels is still one source.
- Consistency compounds. A weekly 90-minute intelligence practice, maintained over twelve months, produces calibration and pattern recognition that periodic trend reports cannot replicate.
- The Trough of Disillusionment is often the best time to build. When mainstream coverage turns negative and the crowd thins out, the practitioners who know what actually works have the least competition.