
There is a question that comes up in almost every serious automation architecture meeting in 2026, and it is almost always asked too late: exactly where should the LLM agent stop, and the RPA bot take over?
Most teams skip this question entirely during the design phase. They assume the boundary will “emerge naturally” once they start building, or that the AI vendor’s demo architecture will translate cleanly into production. Neither assumption holds. The boundary problem — deciding what the language model should reason about versus what a deterministic bot should execute — is the single most reliable predictor of whether a combined LLM + RPA system survives contact with real enterprise workflows or collapses under them.
This is not a philosophical question. It is a design decision with direct consequences for reliability, auditability, cost, and security. Get it right, and you get a system that handles exceptions gracefully, produces an audit trail your compliance team can actually read, and scales without accumulating technical debt at every new process boundary. Get it wrong, and you get what most teams are currently experiencing: brittle pipelines that work beautifully in staging and fall apart the moment a vendor invoice arrives in an unexpected PDF format.
What follows is a practitioner’s guide to drawing that boundary correctly — and to building the orchestration architecture that enforces it in production. This covers the technical protocols now standardising handoffs, the specific failure modes that destroy production deployments, the tool contract pattern that makes LLM behaviour predictable, and three concrete deployment patterns drawn from real enterprise workflows in finance, insurance, and HR.
The framing here is deliberately different from vendor playbooks. It starts from the failure cases rather than the happy path, and it treats governance and observability as first-class design concerns, not afterthoughts.
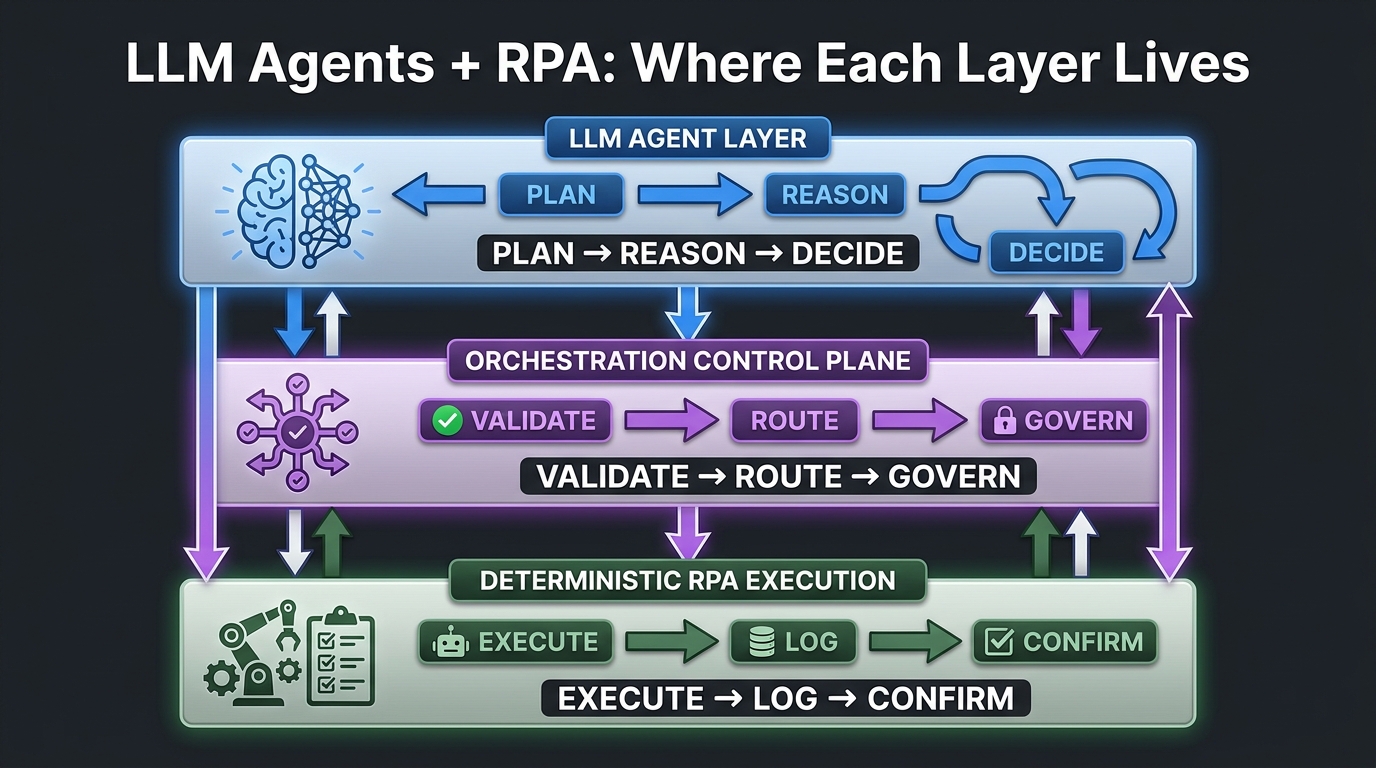
The Three-Layer Stack You Actually Need
Before drawing any boundaries, you need a clear mental model of the full stack. Most organisations collapse two or three of these layers together, which is where the confusion starts. In a well-designed LLM + RPA system, there are three distinct layers, and they should not bleed into each other.
Layer One: The LLM Agent Layer
This is the reasoning layer. It receives goals, not instructions. When a procurement workflow routes an invoice for exception handling, the LLM agent layer is responsible for understanding what kind of exception it is, what the policy says about it, what additional information might be needed, and which tool or downstream process should be triggered. It reasons over context — structured data, documents, conversation history, retrieved knowledge — and produces a decision and a structured action proposal.
Critically, the LLM agent layer does not execute anything directly. It does not log into SAP. It does not submit forms. It does not write to a database. It proposes a tool call — a structured JSON payload — that says, in effect: “Run the approve_invoice tool with these parameters.” What happens next is handled by the layer below it.
Layer Two: The Orchestration Control Plane
This is the layer most teams underinvest in. The orchestration control plane sits between the LLM agent and the RPA execution layer. Its job is to receive the agent’s proposed action, validate it against schema and policy, authenticate the request, route it to the correct bot or API, manage retries and timeouts, collect results, and pass them back to the agent.
The control plane is also where governance lives. Budget guardrails, PII scrubbing, approval gates for high-value actions, and human escalation routing all happen here. If a proposed tool call would trigger a payment over a defined threshold, the control plane intercepts it and routes it to a human queue before execution. The LLM never sees or manages this logic — that is the point.
Layer Three: Deterministic RPA Execution
This layer executes exactly what it is told, precisely, every time, with a complete audit log. RPA bots interact with legacy systems, UIs, APIs, and databases. They do not make decisions. They receive validated, structured task payloads from the control plane and execute them to completion, returning structured results: success, failure, partial completion, or an error code for the control plane to interpret.
The key design principle across all three layers is this: the further down the stack you go, the more deterministic the behaviour must be. Non-determinism is acceptable and useful at Layer One. It is dangerous at Layer Three.
The Handoff Protocol: How Tool Calls Actually Reach RPA Bots
The mechanics of how an LLM agent instructs an RPA bot to act have become significantly more standardised in 2026, converging on two complementary protocols that enterprise teams should understand before designing any integration.
MCP: The Agent-to-Tool Standard
The Model Context Protocol (MCP), originally developed by Anthropic and now under the Linux Foundation umbrella, has emerged as the dominant standard for how agents discover and invoke tools. In an LLM + RPA context, this means your RPA bots — or more precisely, the tasks your bots can perform — are exposed to agents as typed, schema-described tools.
When an agent starts a session, it receives a capability catalog: a list of available tools, each described with a name, a description in natural language, a JSON schema for inputs, and a JSON schema for expected outputs. The agent uses this catalog to decide which tool to call and to formulate a valid call. The MCP layer handles authentication, transport, and basic schema validation before passing the call to the RPA execution layer.
The practical implication: every RPA task that an agent might invoke needs to be wrapped as an MCP-compatible tool. This is not a small amount of work, especially for legacy bot libraries, but it pays back immediately in reliability. Agents can only call tools that exist in the catalog, with parameters that match the schema. The class of errors where an agent tries to invoke a process that does not exist, or passes a string where an integer is expected, is eliminated at the protocol level.
A2A: The Agent-to-Agent Standard
Where MCP governs how a single agent talks to tools and resources, the Agent-to-Agent (A2A) protocol — now seeing broad vendor adoption across UiPath, Microsoft, Salesforce, and Google — governs how agents talk to each other. This matters because real enterprise workflows are rarely single-agent problems.
In a claims processing workflow, for instance, an intake agent might receive an initial claim document, extract structured data, and then delegate to a validation agent that checks coverage eligibility against a policy database, which in turn delegates to an execution agent that triggers the appropriate RPA bot to update the claims management system. A2A defines how these delegation messages are structured, how agents report status back up the chain, how timeouts and failures propagate, and how a human escalation can be injected at any point in the chain.
The Practical Handoff Loop
Put together, a typical production handoff looks like this six-step loop:
- Goal receipt: The LLM agent receives a task (e.g., “process this invoice for payment”) along with relevant context documents and a session with an available tool catalog.
- Reasoning: The agent decomposes the goal, retrieves any needed context from memory or RAG, and selects the appropriate tool from its catalog.
- Tool call emission: The agent emits a structured JSON tool call payload — function name, typed arguments, idempotency key.
- Control plane validation: The orchestration layer validates the schema, checks policy constraints, authenticates, and either routes to execution or intercepts for human approval.
- RPA execution: The bot executes the task in the target system and returns a structured result.
- Result feedback: The control plane passes the result back to the agent, which uses it to decide whether the goal is complete, whether a follow-up action is needed, or whether to escalate.
This loop runs in seconds for simple tasks and in minutes for multi-step workflows requiring human approval. The important thing is that every step is logged with the same structured schema, making the entire chain replayable and auditable.
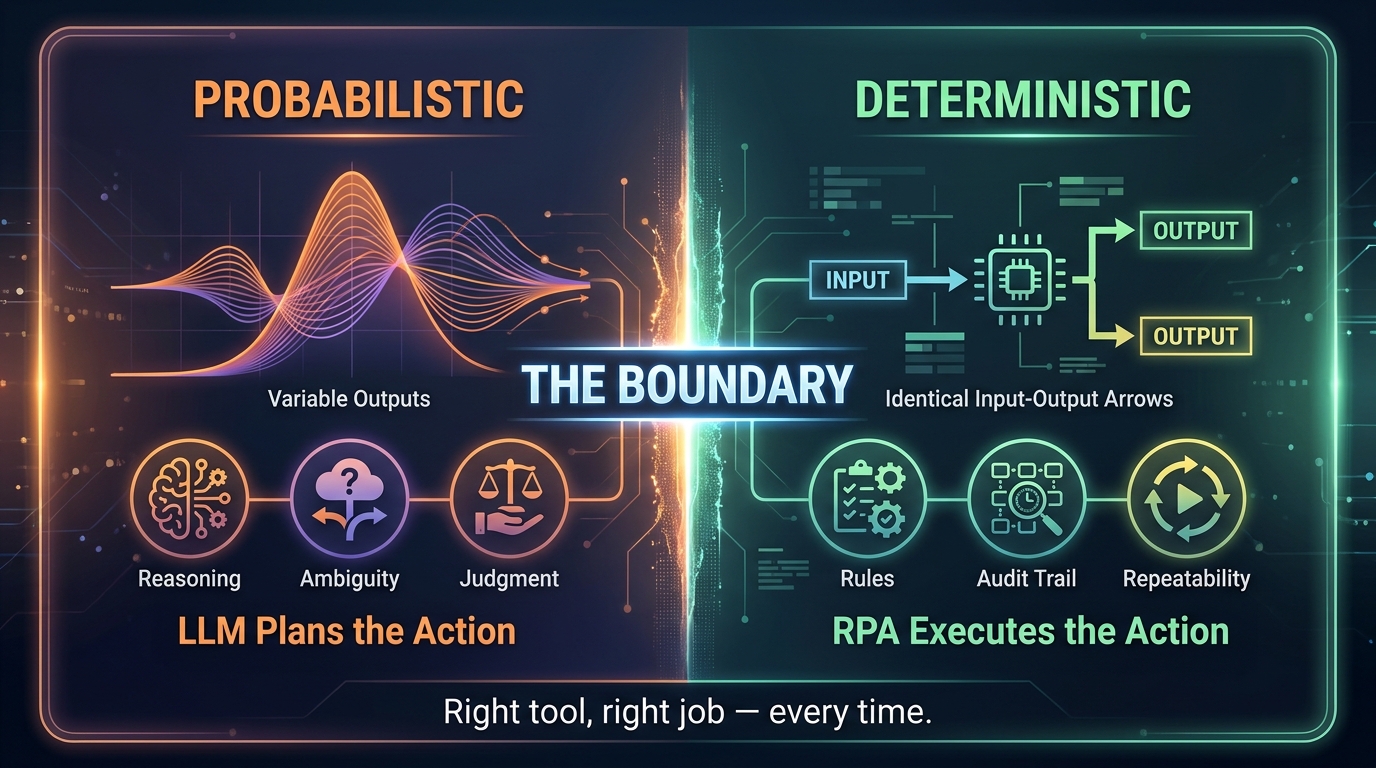
Where Determinism Belongs — and Where It Absolutely Does Not
One of the most consistent findings from enterprises that have moved LLM + RPA systems from pilot to production is that the failures are rarely caused by the LLM making a bad decision. They are caused by teams putting LLM reasoning in the wrong place, or expecting RPA bots to handle decision-making they were never designed for.
Understanding the precise conditions that call for deterministic versus probabilistic behaviour is the foundational design skill for this kind of architecture.
Where Determinism Is Non-Negotiable
Financial transactions and state changes. Any action that changes data in a system of record — creating a payment, updating an account balance, writing to a database — must be deterministic. The same inputs must always produce the same outputs. There is no acceptable variance. If you have an LLM deciding in real time whether a payment should be for $4,750 or $4,800 based on its interpretation of a contract, you have a compliance and financial controls problem.
Audit-trail steps. Any step that generates a record for regulatory, legal, or compliance purposes must be deterministic and must produce the same output on replay. LLMs cannot guarantee this. RPA bots, executing against a validated payload, can.
System interactions requiring authentication. Logging into a legacy ERP, navigating a vendor portal, submitting a form — these are all deterministic steps. The RPA bot follows a defined path. If you let an LLM improvise the navigation path, you introduce unpredictability into a system that treats unexpected actions as errors.
Where Probabilistic Reasoning Has Genuine Value
Exception classification. When an invoice arrives with a missing PO number, a vendor name that does not match the master file, or a line item that falls outside normal patterns, an LLM can classify the exception type and determine which resolution path to invoke far more flexibly than any rules engine. Rules engines require you to enumerate every exception type in advance. LLMs handle the unknown cases.
Document understanding under variance. Vendor invoices, insurance claims, contracts, and HR documents arrive in formats that vary unpredictably. An LLM extracting structured data from an unstructured document introduces some variance but handles that format diversity far better than regex patterns or fixed-template OCR.
Policy interpretation in context. When a procurement request is unusual but not explicitly covered by policy, an LLM agent grounded in the relevant policy documents can assess whether approval is likely appropriate and what additional information would help — something a rules engine cannot do without explicit programming for every edge case.
The Five Production Failure Modes — and the Fix for Each
Practitioner reports and post-mortem analyses from 2026 deployments reveal that LLM + RPA system failures cluster around five identifiable patterns. Only about 10% of AI agent pilots that show strong results at the pilot stage successfully scale to production — and most of the failures are traceable to one or more of these modes.

Failure Mode 1: Context Overflow at the LLM Boundary
What happens: The agent receives too much context — a full 200-page contract, the entire transaction history for an account, a raw database dump — and either fails to process it within the context window, loses relevant details in the middle of a long context, or incurs token costs that make the workflow economically unviable at scale.
The fix: Context must be pre-processed before it reaches the LLM. The orchestration control plane should handle document chunking, retrieval-augmented generation (RAG) to surface only the relevant passages, and structured summarisation of long records. The LLM should receive a curated, bounded context — not the raw source material. Treat context window as a constrained resource to be managed, not an elastic buffer.
Failure Mode 2: Brittle Connector Between Agent and Bot
What happens: The integration between the LLM agent and the RPA bot is built as a point-to-point custom connector — often a hardcoded REST call or a scripted webhook. When the bot is updated, the RPA platform is upgraded, or a new version of the workflow is deployed, the connector breaks silently. The agent emits a tool call, receives a timeout or a malformed response, and either retries indefinitely or fails without a meaningful error.
The fix: All connectors should be schema-validated and version-pinned through the MCP tool contract layer. When a bot is updated, the tool contract version is incremented, the schema is re-published to the capability catalog, and any agents using the old version are either automatically updated or explicitly notified of a breaking change. Treat your RPA tools like versioned APIs, because that is exactly what they are.
Failure Mode 3: Exception Loop With No Exit
What happens: The agent encounters an exception — a document it cannot parse, a validation step that fails, an RPA bot returning an unexpected error code — and lacks a clear policy for what to do next. It retries, hits the same error, retries again, and burns through token budget and bot execution credits in a loop that a human operator eventually notices hours later, after significant cost has accumulated.
The fix: Every agent workflow needs explicit exception handling paths, not just happy-path logic. Define maximum retry counts at the control plane level. Define a structured escalation signal — a specific return code that the control plane interprets as “route to human queue” — and ensure the agent can emit it cleanly. Never let the agent decide whether to keep retrying; that decision belongs to the deterministic control plane.
Failure Mode 4: Schema Drift Between Layers
What happens: The output schema of the LLM agent’s tool call gradually diverges from the input schema expected by the RPA bot. This happens because the agent’s prompt is updated (changing the format of tool call arguments), the RPA bot is modified (changing expected field names or types), or a new LLM version handles tool call formatting differently. The result is validation failures that are hard to diagnose because the symptom (RPA bot failure) is spatially far from the cause (prompt change upstream).
The fix: Schema validation must be enforced at the control plane boundary on every request, not just during initial integration testing. When a tool call arrives with a schema mismatch, it should fail fast with a structured error that identifies the specific field discrepancy. Include schema version numbers in all tool call payloads, and run schema compatibility tests as part of your CI/CD pipeline for any change to agent prompts, bot workflows, or tool contract definitions.
Failure Mode 5: Ghost Execution Without Audit Trail
What happens: An RPA bot executes successfully, performs a state change in a downstream system, and returns a confirmation — but the execution record in the orchestration layer is incomplete or missing. This happens when logging is implemented at the bot level but not at the control plane level, when trace IDs are not propagated through the full call chain, or when an agent retries a failed call and both the failed attempt and the retry succeed (double execution).
The fix: Every tool call must carry an idempotency key — a unique identifier generated by the agent and propagated through every layer. The control plane checks for duplicate idempotency keys before routing any execution. Every execution is logged at the control plane level, not just the bot level, with a structured trace entry that includes the initiating agent ID, the tool contract version, the input payload hash, and the result. Idempotency and trace propagation are not optional features — they are safety requirements.
Tool Contracts: The Interface That Keeps Agents Honest
The tool contract pattern deserves extended treatment because it is the single design decision that has the largest positive impact on LLM + RPA system reliability. A tool contract is a machine-readable specification that defines everything an agent needs to know about a capability — and everything the execution layer needs to enforce about how that capability can be invoked.

What a Well-Written Tool Contract Contains
A complete tool contract has six elements. Each one eliminates a specific class of failure:
1. Identity and description. A unique, versioned tool name (e.g., process_invoice_approval_v2) and a natural-language description written for the LLM, not the developer. The description should tell the agent when to use this tool, not just what it does. Poor example: “Approves invoice.” Better example: “Use when an invoice has been validated against the PO and is ready for finance approval. Do not use for invoices with missing vendor IDs or amounts exceeding $50,000.”
2. Typed input schema. Every input field with its data type, format constraints, whether it is required or optional, and a description of what the field represents. This schema is what the control plane validates against before routing any execution.
3. Typed output schema. The structured response the agent will receive on success, including all possible status values, reference IDs, and any data it needs to proceed to the next step. Agents that do not know what a successful response looks like cannot reason about whether they have achieved their goal.
4. Constraints and guardrails. Explicit rules that the control plane enforces regardless of what the agent requests. Common examples include: maximum transaction amounts, PII fields that must be stripped from logs, rate limits, prohibited system environments (e.g., never call this tool against the production database during a batch window), and approval requirements above specific thresholds.
5. Error taxonomy. A defined set of error codes and their meanings, mapped to specific handling instructions. An error code of VENDOR_NOT_FOUND should map to a specific escalation path. An error code of SYSTEM_UNAVAILABLE should map to a retry with exponential backoff. The agent should know what these codes mean and what to do about each one.
6. Observability hooks. Which fields from this tool call should be emitted to the observability layer, at which log level, and with which trace tags. This is defined in the contract rather than implemented ad hoc, ensuring consistent trace data across all tools in the catalog.
Versioning Tool Contracts Without Breaking Agents
One of the more subtle operational challenges of the tool contract pattern is managing contract evolution. RPA bots get updated. Business rules change. New fields become required. The naive approach — update the contract and redeploy — risks breaking agents that have the old contract in their context window or that have been fine-tuned on tool call examples from a previous version.
A more robust approach treats breaking changes and non-breaking changes differently. Additive changes (new optional fields, new error codes, new output fields) increment the minor version and are backwards-compatible. Breaking changes (new required fields, changed field types, removed fields) increment the major version, and the old version remains in the capability catalog for a defined deprecation window — typically 30 to 60 days — during which agents are progressively migrated.
Multi-Agent Coordination: When One Agent Is Not Enough
Most real enterprise workflows are too complex for a single agent. The naive response to this is to give one agent access to a very large tool catalog and a very long system prompt. In practice, this approach produces agents that are expensive to run, hard to debug, and prone to tool selection errors as the catalog size grows.
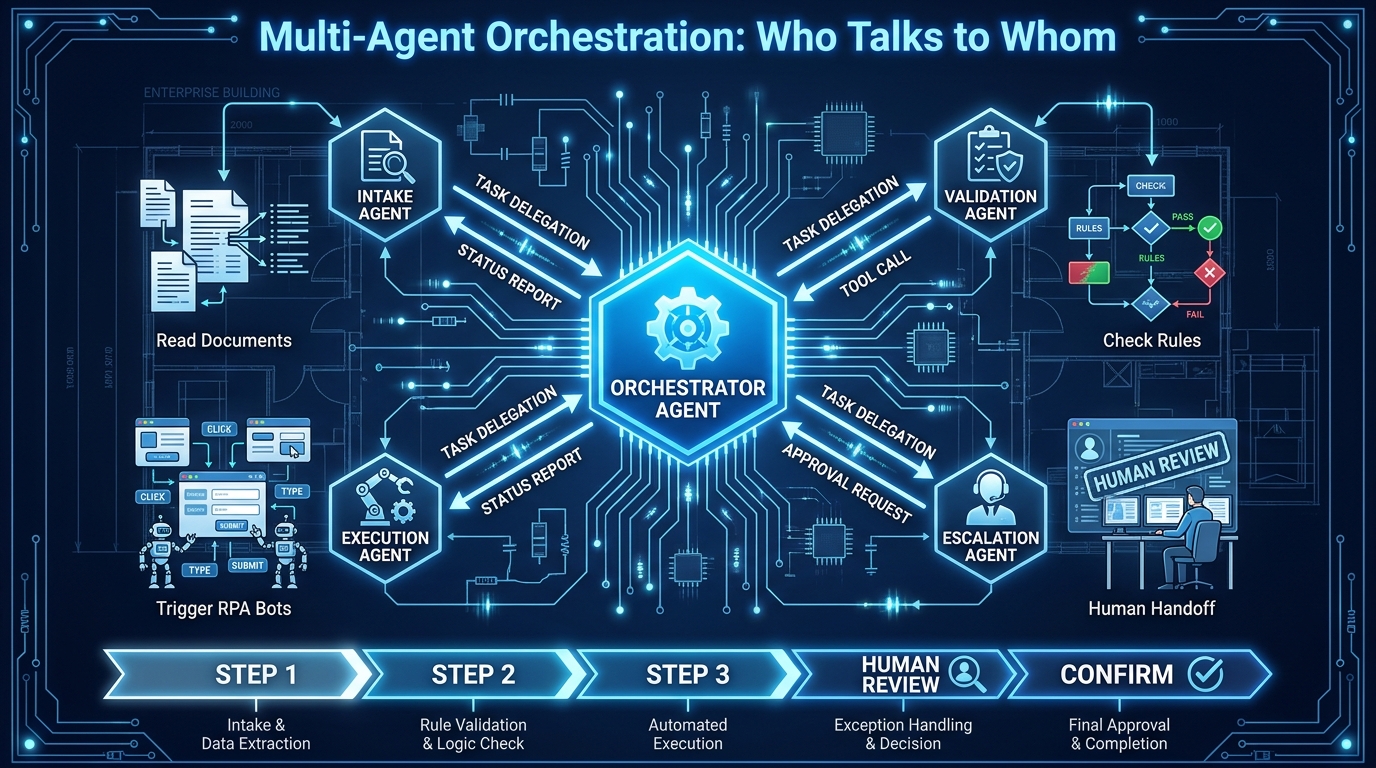
The Orchestrator-Specialist Pattern
The pattern that consistently performs better in production is the orchestrator-specialist model. An orchestrator agent receives the high-level goal and is responsible for decomposing it into sub-tasks and delegating those sub-tasks to specialist agents. Each specialist agent has a narrow, well-defined scope — a smaller tool catalog, a focused system prompt, a specific domain of knowledge — and reports back to the orchestrator with structured results.
In a claims processing workflow, this might look like:
- Orchestrator agent: Receives the claim, identifies its type and complexity, and assigns sub-tasks to specialists.
- Document extraction agent: Extracts structured data from the claim documents using a set of document-processing tools.
- Coverage validation agent: Checks the extracted data against the policy database using a different set of retrieval and lookup tools.
- Adjudication agent: Applies coverage rules to recommend an approval, denial, or further review routing.
- Execution agent: Triggers the RPA bots that update the claims management system based on the adjudication decision.
Each specialist has a smaller context window requirement, a more accurate tool selection (fewer tools to choose from), and a clearer success criterion. When something goes wrong, the failure is localised — you know it happened in the coverage validation step, not somewhere in a monolithic agent with 40 tools available.
A2A Delegation Patterns in Practice
With A2A communication in place, delegation between agents follows a structured message pattern. The orchestrator sends a task message to a specialist that includes: the task type, a unique task ID, the input payload, any relevant context documents or memory references, a deadline, and escalation instructions. The specialist returns a result message with: the task ID (for correlation), a status code, the output payload, and any errors encountered.
The critical governance point here is that delegation chains should have a defined maximum depth. Orchestrators can delegate to specialists, but specialists should generally not delegate to further sub-specialists without orchestrator approval. Unbounded delegation depth creates situations where a human operator cannot reconstruct the chain of decisions that led to an action — which is a compliance failure in any regulated industry.
In 2026, the most mature deployments cap delegation depth at three levels and require all delegation chains to be logged as a structured trace that can be replayed and audited on demand.
Observability You Actually Need in Production
Observability for LLM + RPA systems is qualitatively different from standard application monitoring. You are not just tracking request latency and error rates — you are tracking reasoning quality, decision consistency, cost per workflow, exception rates by exception type, and the distribution of human escalation triggers over time.
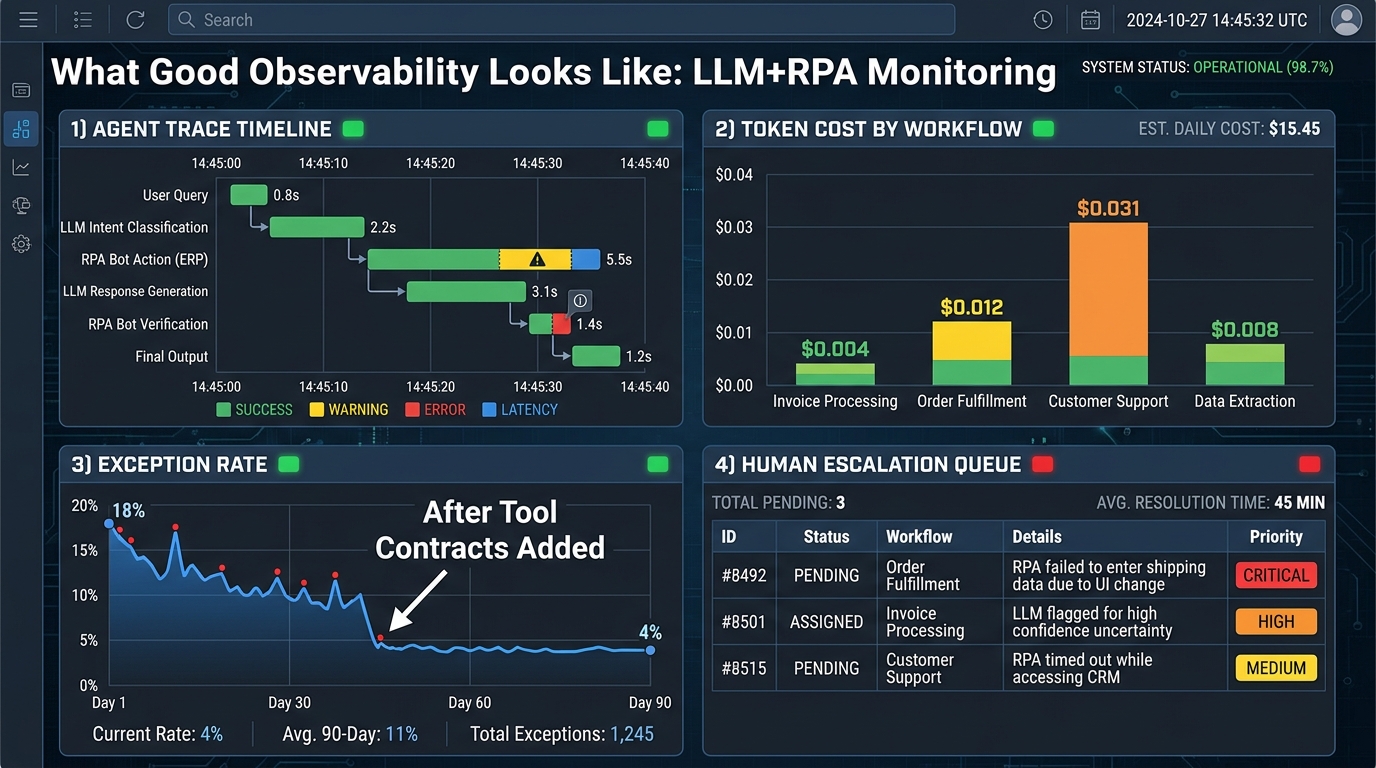
The Four Observability Layers
Layer 1 — Execution tracing. Every agent invocation, tool call, control plane validation, and RPA execution gets a trace entry with a shared correlation ID. This trace should be queryable by workflow instance, by tool name, by agent ID, and by time range. When something goes wrong in production, the first question is always “what actually happened, in what order” — and you need to answer it in under five minutes, not five hours.
Layer 2 — Token and cost telemetry. LLM API costs in production scale with token consumption per workflow run. Without cost telemetry at the workflow level, you cannot identify which processes are uneconomical, which prompts are generating unnecessarily long context, or which exception paths are burning disproportionate token budget. Track cost-per-workflow-instance as a first-class metric, not an afterthought.
Layer 3 — Decision quality monitoring. This is the layer most teams skip, and it creates the most invisible risk. Agent decisions that look correct in isolation can drift over time — as the underlying model is updated, as the prompt evolves, as the distribution of input documents shifts. Implement a sampling-based evaluation loop where a representative set of agent decisions is reviewed against ground-truth outcomes, and track the deviation rate as a metric over time.
Layer 4 — Human escalation analytics. Track every human-in-the-loop intervention: what triggered it, which agent and tool were involved, how long the human took to resolve it, and what the resolution was. This data is your primary signal for identifying which parts of your workflow are over-relying on human judgment and which exception types could be resolved automatically with additional agent capability or rule refinement.
The Metric That Predicts System Health
Across multiple production deployments, one metric has proven to be the most predictive indicator of overall system health: the straight-through processing rate — the percentage of workflow instances that complete end-to-end without human intervention. Early-stage deployments typically achieve 60–75% straight-through rates. Mature deployments, with well-tuned tool contracts and exception paths, commonly reach 85–92%.
If your straight-through rate is declining over time despite stable input volume, you likely have a schema drift problem, a model behaviour shift, or a downstream system change that is producing new exception types your agents have not been trained to handle. The metric surfaces the problem; the trace logs tell you where to look.
Governance Patterns That Don’t Slow the Business Down
The most common objection to comprehensive governance in LLM + RPA systems is that it creates friction and slows down the business value that automation was supposed to deliver. This objection usually reflects a governance design that was bolted on after the fact, rather than designed into the architecture from the start.
Effective governance in this context is not a committee reviewing every automation decision. It is a set of policy-as-code rules that run at the control plane level, a risk-tiered approval model that only surfaces high-risk actions to humans, and a clear ownership model for each component in the stack.
Risk-Tiered Action Governance
Not all automated actions carry the same risk. A risk tiering model assigns each tool in your capability catalog to one of three tiers based on the potential business impact of an error:
Tier 1 — Fully autonomous. Low-impact, reversible actions. Examples: reading data from a system, generating a document draft, sending an internal notification. These run without any human approval gate. The control plane logs them and enforces schema validation, but no human is in the loop.
Tier 2 — Confirm on exception. Medium-impact actions that run autonomously within defined parameters but route to a human queue if any parameter falls outside the normal range. Examples: invoice approvals under a defined threshold with a known vendor, standard benefits enrolments, routine data updates. Most of the business volume runs through this tier autonomously; exceptions are rare but handled.
Tier 3 — Pre-authorised. High-impact or irreversible actions. Examples: large payments, contract commitments, employee status changes. These always require explicit human authorisation before the RPA bot executes. The agent can prepare all the context, propose the action, and route it to the right approver — but it cannot execute without the approval signal.
This tiering model means that 80–90% of workflow volume runs with no human intervention and minimal latency, while the 10–20% of cases that genuinely need human judgment get routed correctly and consistently.
The AI Agent Governance Council
The most mature organisations in 2026 have evolved their traditional RPA Centre of Excellence into an AI Agent Governance Council. The scope change is significant. A traditional RPA CoE owned bot development standards, deployment pipelines, and runtime monitoring. An AI Agent Governance Council owns all of that, plus: LLM model selection and versioning policies, tool contract standards and approval processes, agent behaviour evaluation frameworks, EU AI Act compliance mapping (for relevant jurisdictions), and the risk tiering model for the entire capability catalog.
This governance body does not need to be large. In most organisations, a council of five to eight people — drawn from IT architecture, legal/compliance, the business units most active in automation, and operations — can govern a portfolio of dozens of agent workflows, provided the policy-as-code infrastructure is in place to enforce their decisions automatically rather than through manual review.
Three Real-World Deployment Patterns
Abstract architecture is useful; concrete patterns are better. Here are three deployment patterns that represent the most common high-value applications of LLM + RPA orchestration in enterprise environments in 2026, with the specific orchestration decisions that make each one work.
Pattern 1: Intelligent Invoice Processing
Invoice processing is the entry point for most LLM + RPA deployments because the problem is well-understood, the ROI is measurable, and the workflow has a clearly defined exception structure. A mature implementation handles approximately 140,000 invoices per year at an enterprise scale with over 85% straight-through processing.
Where the LLM agent layer adds value: Extraction of line items from variable-format PDFs (including vendor-specific layouts that legacy OCR misses), classification of invoice exceptions by type (missing PO, amount discrepancy, unregistered vendor, duplicate submission), and routing decisions for each exception type.
Where RPA executes deterministically: Lookup of PO numbers against the ERP, validation of vendor registration in the master data system, submission of approved invoices to the payment queue, writing of exception records to the workflow management system, and all audit trail entries.
The critical boundary decision: The LLM agent classifies the exception and proposes a resolution path. It does not decide whether to approve payment. All payment actions are Tier 3 tools — they require explicit human authorisation or a deterministic rule-based approval for invoices that pass all validation checks below the automated approval threshold.
Documented outcomes: Deployments in this category typically report 70–85% reduction in invoice processing cycle time, 60–70% reduction in manual handling cost, and a payback period of six to twelve months for the full implementation.
Pattern 2: Claims Intake and Triage
Insurance and benefits claims processing involves high document variance, complex coverage rules, and significant downstream cost if exceptions are misclassified. The orchestration challenge is more complex than invoice processing because the rules are more nuanced and the stakes of a wrong decision are higher.
Where the LLM agent layer adds value: Extraction of claim details from multi-format documents (FNOL forms, medical reports, police reports, supporting photographs), initial triage of claim type and complexity, cross-referencing against policy terms to identify coverage questions, and generation of structured summaries for adjudicators.
Where RPA executes deterministically: Policy lookup in the claims management system, coverage eligibility validation, assignment of claim to the correct adjudicator queue based on value and type, status updates at each workflow milestone, and all communications triggered by status changes.
The critical boundary decision: Claims adjudication — the actual coverage decision — remains a Tier 3 human action for all claims above the organisation’s auto-approval threshold. The agent’s role is to eliminate the manual data entry and document review work that currently consumes 40–60% of adjudicators’ time, so they can focus on the judgment-intensive decisions that require human expertise.
Documented outcomes: Claims intake and triage automation with LLM orchestration delivers 40–60% reductions in intake processing time and measurable improvements in adjudicator capacity — the same headcount handles 30–50% higher claim volume in mature deployments.
Pattern 3: Employee Onboarding Orchestration
Employee onboarding spans multiple systems (HRIS, identity management, payroll, benefits administration, facilities) and involves high process variance driven by employee type, location, department, and role. It is historically one of the most error-prone and compliance-sensitive processes in HR operations.
Where the LLM agent layer adds value: Interpretation of offer letter and role details to determine which onboarding path applies, identification of jurisdiction-specific compliance requirements, generation of the correct task sequence for each specific hire, and handling of unusual cases (international transfers, rehires, role changes) that do not fit standard templates.
Where RPA executes deterministically: Creation of accounts in each target system, provisioning of access rights based on role templates, enrollment in benefits plans, generation of required compliance documentation, and all integration calls between HR systems that the new employee profile needs to propagate through.
The critical boundary decision: Access provisioning follows a deterministic rule: roles map to access templates in the identity management system, and the agent cannot propose custom access that deviates from the approved template library. If a hiring manager requests non-standard access for a new hire, this is routed as a Tier 3 action to IT security — the agent surfaces the request but does not fulfil it autonomously.
Documented outcomes: Onboarding automation with LLM orchestration reduces end-to-end onboarding time from an average of five to seven days to under 24 hours for standard cases, with a 90%+ reduction in manual data entry errors across connected systems.
Building Your Phased Rollout Without Burning Trust
One of the most consistent failure modes in enterprise LLM + RPA programmes — and one that does not show up in technical post-mortems — is loss of stakeholder trust. This happens when a system is deployed with overstated capability claims, encounters an unexpected failure in front of a business stakeholder, and loses the organisational confidence needed to continue investing in the programme.
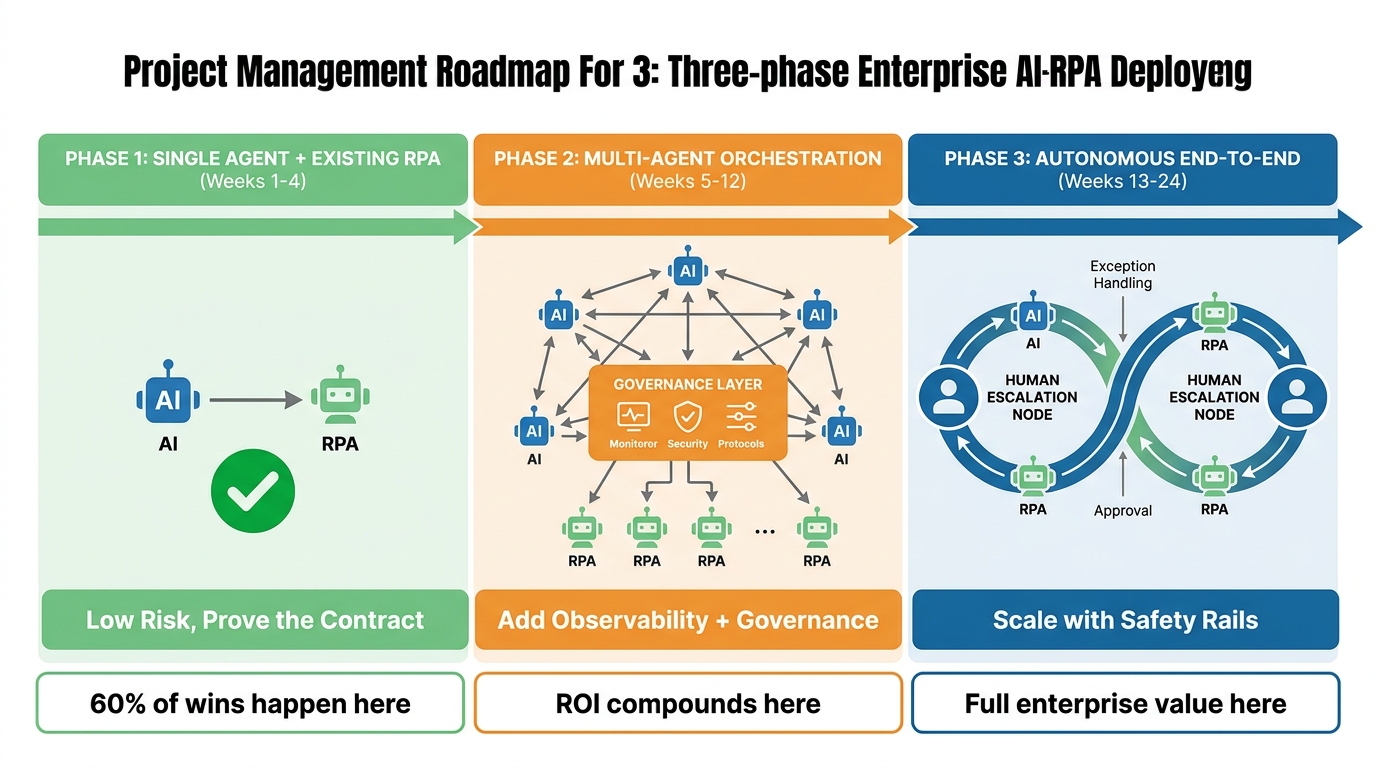
A phased rollout designed to build and protect trust looks like this:
Phase 1: Single Agent, Existing RPA (Weeks 1–4)
Pick one high-volume, well-understood process where you already have RPA bots running. Add a single LLM agent that handles the exception path — the cases that currently go to human review because they do not fit the existing rules. The agent’s job is not to replace the existing automation; it is to reduce the manual handling queue.
This phase proves the tool contract pattern in a low-risk environment, establishes your observability baseline, and delivers a measurable early win (reduction in manual exception handling volume) that business stakeholders can see. Do not add scope or complexity until you have a clean audit trail from at least four weeks of production operation.
Phase 2: Multi-Agent Orchestration (Weeks 5–12)
Introduce the orchestrator-specialist pattern on a second process, using the governance and observability infrastructure built in Phase 1. Extend the capability catalog to cover the new process’s RPA tools. Implement the risk tiering model explicitly across all tools in both processes.
This phase is where most of the compounding ROI begins. Two processes with shared governance infrastructure cost significantly less to operate than two independently managed automations. The straight-through processing improvements in Phase 2 typically deliver stronger absolute ROI than Phase 1, because you are applying the same architecture to a larger process scope.
Phase 3: Autonomous End-to-End (Weeks 13–24)
Connect the exception handling agents from Phase 1 and Phase 2 into end-to-end orchestrated workflows. Extend to additional processes using the established patterns. Begin operating the AI Agent Governance Council formally, with quarterly reviews of decision quality metrics, escalation analytics, and the risk tiering assignments across the full capability catalog.
Phase 3 is also when you should conduct your first systematic review of which Tier 2 exceptions could be promoted to Tier 1 (fully autonomous) based on six months of tracked performance data. This review — using real outcome data rather than theoretical capability assessments — is how you expand autonomous scope responsibly and with stakeholder confidence intact.
The Boundary Is the System
The temptation in LLM + RPA architecture is to focus on the capabilities — what can the agent reason about, what can the bot execute, how sophisticated can the multi-agent coordination become. These are interesting questions, but they are not the questions that determine production success.
Production success is determined by the boundaries: how precisely you have drawn them, how consistently you enforce them, and how quickly you can detect when something on either side of a boundary has changed in a way that threatens the system’s reliability or compliance posture.
The organisations consistently reporting strong results from LLM + RPA deployments in 2026 — 70–85% cycle time reductions, six-to-twelve-month paybacks, straight-through processing rates above 85% — share a common design philosophy. They treat the orchestration control plane as the critical investment, not an afterthought. They write tool contracts before they write agent prompts. They implement observability before they expand scope. And they build governance in as a structural property of the architecture, not as a review process that runs on top of it.
The LLM is not the system. The RPA bot is not the system. The boundary between them, and the control plane that governs it, is the system.
Actionable Takeaways
- Map every action in your target workflow to a tier before you build. Know which actions are fully autonomous, which escalate on exception, and which always require human pre-authorisation. This decision shapes your entire architecture.
- Write tool contracts before you write prompts. The contract defines the interface. The prompt teaches the agent to use it. Build in that order.
- Instrument cost-per-workflow-instance from day one. Token costs at scale are a genuine business risk. You cannot manage what you are not measuring.
- Treat schema validation as a safety control, not a nice-to-have. Every tool call that reaches an RPA bot without schema validation is an untested assumption about the boundary.
- Start with exception handling, not end-to-end replacement. The fastest path to measurable ROI is reducing the manual handling queue in a process where you already have working RPA. Add LLM intelligence at the edges before you redesign the core.
- Cap delegation depth at three levels. Beyond three levels of agent-to-agent delegation, auditability degrades and failure localisation becomes practically impossible.
- Track straight-through processing rate as your primary health metric. If it is declining, the boundary has shifted somewhere. The trace logs will show you where.


