
There is a version of hyperautomation that every vendor pitch deck describes. A single, harmonious enterprise where every process flows seamlessly from one department to the next, governed by AI, orchestrated in real time, and endlessly self-improving. Costs drop. Headcount redeploys. The CFO smiles.
Then there is the version that most companies actually live. A finance team running three disconnected RPA bots that break every time the ERP gets an update. An HR department that automated interview scheduling but still processes onboarding paperwork by hand. An IT service desk that added a chatbot but didn’t wire it to the ticketing system. Isolated wins. No connective tissue. A collection of automation islands rather than an automated organisation.
The gap between those two versions is not a technology problem. Every component organisations need — RPA, AI, process mining, low-code platforms, agentic workflows — either exists today or is maturing fast. The gap is a sequencing and architecture problem. Companies deploy automation tools before they understand which processes actually need automating. They let individual departments run independent initiatives without establishing shared infrastructure. They measure outputs instead of outcomes. And they forget that automation, however intelligent, still operates inside an organisation made of people.
This article is about closing that gap — department by department, decision by decision. Not a vendor landscape review, and not another argument for why hyperautomation matters. By 2026, the market is projected to reach $65.2 billion, with 90% of large enterprises already treating it as a strategic priority. The maturity question has been answered. What hasn’t been answered for most organisations is the operational question: in what order do you build this, how do you govern it, and what does good actually look like inside each function?
That is what follows.
What Hyperautomation Actually Means in 2026 — Beyond the RPA Origin Story
Hyperautomation was coined by Gartner as a top strategic technology trend, and in the early years the conversation was dominated by RPA — robotic process automation, the technology that uses software bots to mimic human interaction with digital interfaces. Record keystrokes, replay them at scale, done. It was valuable, it was fast to deploy, and it created enormous enthusiasm. It also created a lot of disappointment when organisations discovered that rule-based bots are brittle, expensive to maintain, and limited to structured processes.
By 2026, the definition has expanded significantly. Hyperautomation now describes the disciplined combination of multiple complementary technologies to automate increasingly complex, judgment-dependent processes across an entire organisation. The core technology stack includes:
- Robotic Process Automation (RPA): Still the execution layer for UI-based, repetitive tasks — but no longer the centrepiece.
- Artificial Intelligence and Machine Learning: Enabling classification, prediction, natural language understanding, and decision-making in unstructured environments.
- Process Mining and Task Mining: Using event log data from ERP and CRM systems to objectively map how processes actually run — not how documentation says they run.
- Low-Code and No-Code Platforms: Allowing non-technical staff to build, modify, and maintain automation without developer dependency.
- Agentic AI: Autonomous AI agents that can decompose goals, select tools, and handle exceptions dynamically — the layer that makes hyperautomation genuinely adaptive rather than merely fast.
- Digital Process Twins: Virtual replicas of business processes used to simulate automation impacts before deployment and detect drift in live systems.
- Integration Platforms (iPaaS): The connective tissue that enables data to move across ERP, CRM, HRIS, and legacy systems without custom code for every connection.
What makes hyperautomation distinct from “we have some bots” is the integration of these layers into a coherent architecture, governed centrally and scaled across functions. Gartner’s most recent survey showed that over 56% of organisations already have four or more concurrent hyperautomation initiatives running simultaneously — which is simultaneously impressive and dangerous. More on that in the governance section.
The Agentic Shift: Why 2026 Is Different
The development that has changed the strategic calculus more than any other in the past 18 months is agentic AI. Gartner projects that 40% of large enterprises will deploy autonomous AI agents for business process management by the end of 2026. This is not incremental. Traditional automation executes a fixed sequence; agentic systems reason about what sequence makes sense given the current state of the world.
Walmart is using agentic AI for autonomous supply chain adjustments. DHL has deployed agents for warehouse scheduling. Danfoss reports that 80% of order queries are now handled by AI agents without human intervention. Suzano cut customer query resolution time by 95% using Google’s Gemini-based agent infrastructure. These are not hypothetical futures — they are operating deployments in 2026, and they represent the upper end of what hyperautomation looks like when the technology stack and organisational architecture are both functioning.
The point isn’t to achieve what Walmart or DHL have achieved immediately. The point is that the path to that level of capability is paved with the same foundational decisions every organisation must make: which processes to automate first, how to build the orchestration layer, and how to govern it all without letting complexity become an unmanageable liability.
The Sequencing Problem: Why the Order in Which You Automate Matters
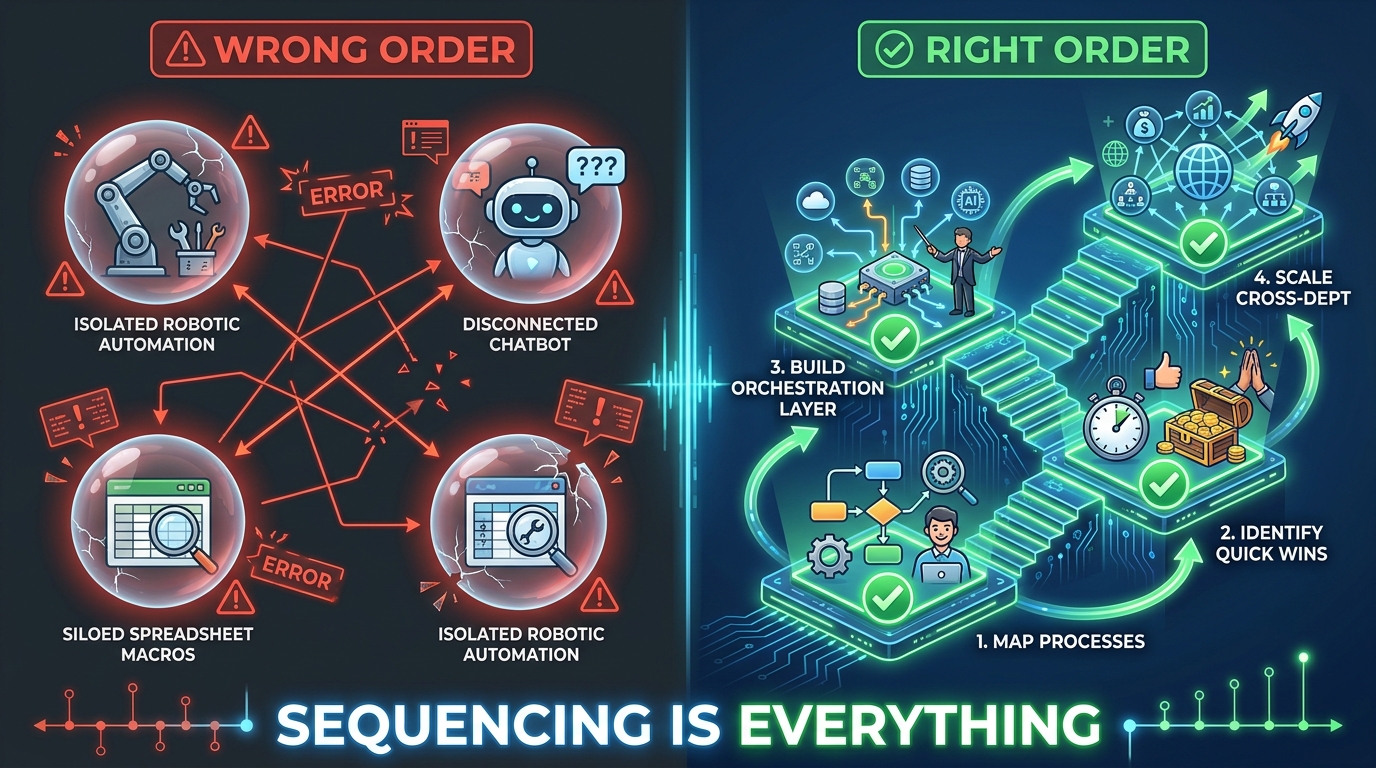
Enterprise-wide scaling of hyperautomation succeeds in only 16–25% of initiatives. That figure, drawn from multiple 2026 implementation studies, is the most important number in this entire article. It does not mean that automation itself fails — individual initiatives frequently succeed. It means that most organisations cannot move from “some automation” to “systemic automation.” The reason, in the vast majority of cases, is sequencing.
The Tool-First Trap
The most common failure pattern looks like this: a department head — usually in finance or IT — attends a vendor demonstration, sees a compelling ROI case, and secures budget approval. A platform gets licensed. A few processes get automated. Results are good, but modest. A second department hears about it and wants the same. They choose a different platform because the first one doesn’t fit their needs. By year two, the organisation has three automation platforms, no shared data model, no centralised governance, and an ongoing argument about which platform to standardise on.
The root cause is that the technology decision preceded the process and architecture decision. The right sequence runs in the opposite direction.
The Four-Stage Sequencing Model
Before any department touches an automation tool, organisations that succeed at scale have typically worked through four foundational stages:
- Process Intelligence First: Deploy process mining across your highest-volume functions to generate an objective map of how work actually flows. This typically reveals that the processes people believe are candidates for automation are not actually the bottlenecks — and that the real delays are elsewhere. A frequently cited example: an order fulfilment process that appeared slow at the fulfilment stage was revealed by process mining to be bottlenecked at the data entry stage three steps earlier. Automating fulfilment would have done nothing.
- Quick Wins in High-Volume, Low-Complexity Processes: Use initial automation deployments to validate your platform choices and build organisational confidence. Finance’s accounts payable and HR’s onboarding paperwork are the canonical starting points for good reason — the volume is high, the variance is low, and the ROI is fast. These wins fund the next phase and create internal advocates.
- Build the Orchestration Layer: Before scaling to complex, cross-departmental processes, establish the integration middleware, API management, and data governance infrastructure that allows automation in one department to connect to data and systems in another. Skipping this stage is why supply chain automation that needs live finance data and HR headcount data fails in production.
- Scale to Complex, Cross-Functional Workflows: Once the foundation is in place, expand to the processes that create the most value but require coordination across functions — order-to-cash, employee lifecycle management, procurement-to-pay, customer onboarding. These are where hyperautomation delivers its most significant strategic impact.
Organisations that follow this sequence consistently report better outcomes, faster time-to-value at scale, and fewer platform consolidation problems than those who let departments proceed independently. The sequencing is not bureaucracy — it is architecture.
Finance and Accounts: Where Hyperautomation Pays the Fastest
Finance is consistently the department where hyperautomation initiatives start, and for rational reasons. The processes are high-volume and highly repetitive. The data is relatively structured. The outcomes are directly measurable in dollars and hours. And the cost of errors — duplicate payments, missed compliance obligations, fraud — is quantifiable and painful enough that finance leadership tends to be genuinely motivated.
Accounts Payable and Invoice Processing
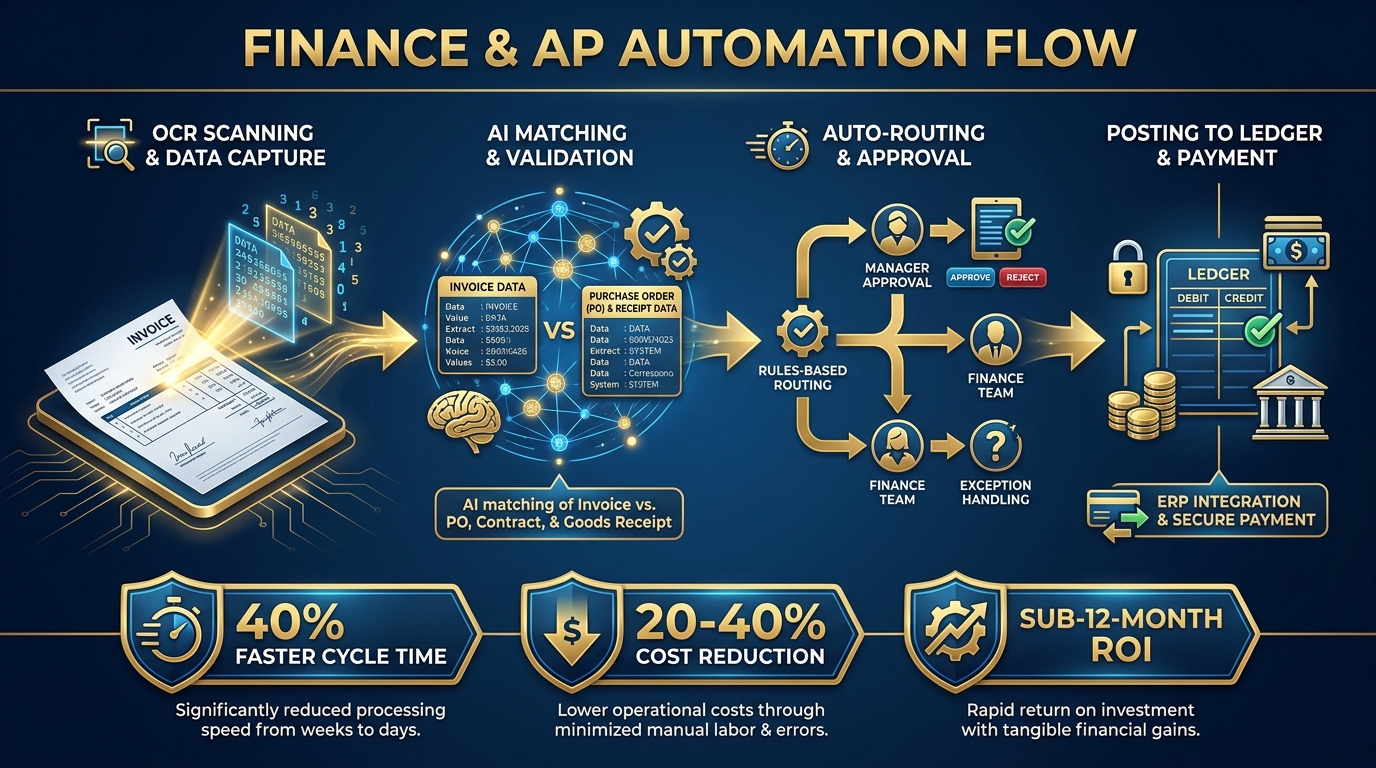
Invoice processing is the canonical hyperautomation use case in finance, and it is still the one where companies find the fastest payback. The automated pipeline typically works as follows: AI-powered optical character recognition (OCR) extracts data from incoming invoices regardless of format — PDFs, scanned paper, EDI, email attachments. An AI matching layer compares extracted data against purchase orders and goods receipts in the ERP. Duplicate detection flags anomalies. Clean invoices route to automatic posting; exceptions route to human reviewers with all relevant context pre-surfaced.
Benchmarks from 2026 implementations show 20–40% reductions in accounts payable processing costs, cycle times accelerating by over 40%, and return on investment achieved within 12 months for most deployments. Banking and financial services firms report revenue uplifts of 27–28% when combining AP automation with broader financial workflow transformation.
Financial Reporting and Month-End Close
Month-end close is a different challenge. The volume is lower but the complexity is higher — journal entries, intercompany reconciliations, variance analysis, regulatory reporting. Hyperautomation here works at three levels: automated data extraction and consolidation from multiple source systems, AI-driven anomaly detection that flags unusual entries before they reach reviewers, and report generation bots that compile standard packages without manual assembly.
Progressive finance organisations are now deploying process mining to understand their month-end close processes with precision — measuring not just how long close takes, but where in the sequence time is lost, which step has the most variation, and which individuals are becoming bottlenecks. The resulting automation targets are far more precise than intuition-based decisions.
Tax, Compliance, and Audit Readiness
Regulatory compliance automation is the third major finance frontier. Tax data aggregation, VAT return preparation, audit trail maintenance, and regulatory filing can all be substantially automated. The EU AI Act, fully applicable from August 2026, adds a new layer of governance obligation for organisations deploying AI in financial decision-making — making audit-ready, explainable automation not just operationally useful but legally necessary in European markets.
What Finance Automation Unlocks Downstream
The strategic value of finance automation extends beyond the finance department. When the AP process is automated, procurement gets real-time visibility into committed spend. When reporting is automated, the executive team gets data faster and with more confidence. The finance function transitions from a backward-looking recording department to a forward-looking intelligence function — and that change in role is only possible when the operational burden of data entry and reconciliation has been substantially removed.
HR and People Operations: The Overlooked Automation Goldmine
HR is systematically underestimated as an automation priority. IT and finance dominate early hyperautomation budgets, while HR teams continue processing onboarding paperwork manually, answering the same policy questions via email, and running payroll corrections through spreadsheets. The opportunity cost is enormous.
A 2026 industry survey found that 74% of HR leaders report substantial time savings from automation initiatives — yet adoption across the full HR function remains uneven, with most organisations automating only the most visible processes while leaving substantial workflow complexity untouched.
Employee Onboarding and Offboarding
Onboarding is the HR process with the most immediate automation ROI. A new hire joining an organisation triggers a cascade of tasks: system access provisioning across IT, payroll setup, benefits enrollment, equipment ordering, compliance training assignment, and manager notification. In the typical manual organisation, these tasks are coordinated by email, completed at different speeds by different people, and frequently incomplete by the employee’s start date — a genuinely damaging first impression.
In an automated onboarding workflow, a single trigger — the HRIS record being set to active — initiates a multi-system orchestration sequence. IT receives an automatic provisioning request. Payroll is updated. Benefits enrollment links are dispatched on a timed schedule. Equipment orders are placed automatically. The entire sequence runs in hours rather than days, with exception alerts surfaced to the HR team only when something genuinely needs human judgment.
Offboarding automation mirrors this but adds compliance criticality: immediate access revocation, exit interview scheduling, final payroll calculation, and documentation of equipment return. Organisations that automate offboarding reduce the risk of orphaned access permissions — a significant security and compliance vulnerability.
HR Helpdesk and Policy Queries
An estimated 40–60% of HR helpdesk interactions in large organisations involve repetitive questions: leave balances, holiday entitlements, payslip requests, expense policy queries, benefit eligibility. These are not questions that require human judgment — they require accurate data retrieval and clear communication. AI-driven conversational interfaces connected to the HRIS can resolve these queries instantly, 24 hours a day, and redirect HR staff to the genuinely complex situations that require them.
Recruitment and Talent Operations
Recruitment automation spans the full funnel: AI-powered resume screening that matches applications to role requirements without manual review, automated interview scheduling that eliminates the email back-and-forth that wastes recruiter time, candidate communication sequences that maintain engagement without manual touchpoints, and predictive analytics that identify the sourcing channels generating the highest-quality applicants.
The risk in recruitment automation — and it is a genuine one — is bias. AI trained on historical hiring data can encode the preferences of the past rather than the needs of the future. Responsible implementation requires regular bias audits, diverse training data, and human oversight on final hiring decisions. This is not an argument against automation in recruitment; it is an argument for thoughtful implementation with appropriate governance.
Workforce Analytics and Predictive Retention
The most strategically valuable HR automation in 2026 is not process automation at all — it is predictive analytics. By combining HRIS data, performance review data, engagement survey data, and external market salary benchmarks, AI models can identify employees who are statistically likely to leave before they signal any intention of doing so. Proactive intervention — a salary review, a development conversation, a project rotation — is far less costly than replacement hiring. Organisations deploying this capability report measurable reductions in voluntary attrition in high-value employee segments.
Supply Chain and Operations: Where Complexity Demands Orchestration
Supply chain is where hyperautomation arguments are won or lost at scale. The processes are complex, the data volumes are enormous, the number of external dependencies (suppliers, logistics partners, customs authorities, weather) is high, and the consequences of getting it wrong — stockouts, excess inventory, delayed fulfilment — are immediately visible to customers and directly measurable in lost revenue.
Demand Sensing and Inventory Optimisation
Traditional demand forecasting relies on historical sales data and static seasonal patterns. AI-driven demand sensing incorporates real-time signals — point-of-sale data, social media sentiment, competitor pricing changes, weather forecasts, economic indicators — and updates inventory recommendations continuously rather than on a weekly or monthly planning cycle.
The operational result is a significant reduction in both stockouts and overstock events. Automated reorder triggers fire when inventory levels cross dynamically calculated thresholds rather than fixed reorder points. Safety stock levels adjust based on supplier lead time variability rather than static buffers. The entire inventory optimisation process becomes a continuous, data-driven operation rather than a periodic manual exercise.
Supplier Management and Procurement Automation
Procurement automation covers a wide range of use cases: automated request-for-quotation processes, AI-assisted supplier evaluation, automated purchase order generation for pre-approved suppliers, and invoice-matching-to-receipt for three-way validation. Beyond efficiency, procurement automation creates compliance documentation automatically — a critical capability in regulated industries and public sector procurement.
Organisations with mature procurement automation are beginning to deploy AI agents that monitor supplier financial health indicators and flag early warning signals before a supplier failure becomes a supply chain disruption. This is not prediction; it is ongoing intelligence gathering at a scale no human team can match.
Logistics and Fulfilment Coordination
The logistics layer of supply chain automation involves route optimisation, carrier selection, exception management, and customer communication. When an outbound shipment is delayed, an automated system can simultaneously trigger a carrier escalation, update the customer portal, notify the account manager, and flag the order for expediting review — all in the time it would take a human coordinator to read the delay notification email.
DHL’s deployment of AI agents for warehouse scheduling is instructive. The system does not simply follow a fixed algorithm — it balances incoming workload, available staff, equipment capacity, and real-time exceptions to produce an optimal schedule. When a large unexpected inbound shipment arrives, the agent recalculates warehouse assignments and task priorities without waiting for a human scheduler to intervene.
Manufacturing: Predictive Maintenance and Quality
In manufacturing environments, hyperautomation extends to the physical layer through IoT integration. Sensors on production equipment generate continuous performance data that AI models use to predict maintenance requirements before failure occurs. Industry benchmarks show up to 50% reductions in unplanned downtime from predictive maintenance deployments, with a 35% ROI boost in manufacturing efficiency overall.
Quality control automation — AI vision systems that inspect products at machine speed — replaces sampling-based quality checks with 100% inspection, catching defects that would previously have reached customers. The data from these systems also feeds back into process improvement, identifying the upstream production conditions that correlate with downstream quality problems.
IT and the Service Desk: Automating the Automators
The IT function has a dual role in hyperautomation. It is both a consumer of automation (its own processes are highly automatable) and an enabler of automation across the rest of the organisation (it owns the infrastructure that other departments’ automation runs on). The risk is that IT becomes a bottleneck to enterprise-wide automation if it focuses only on its own function and fails to build the shared platforms that others need.
Service Desk and Ticket Resolution
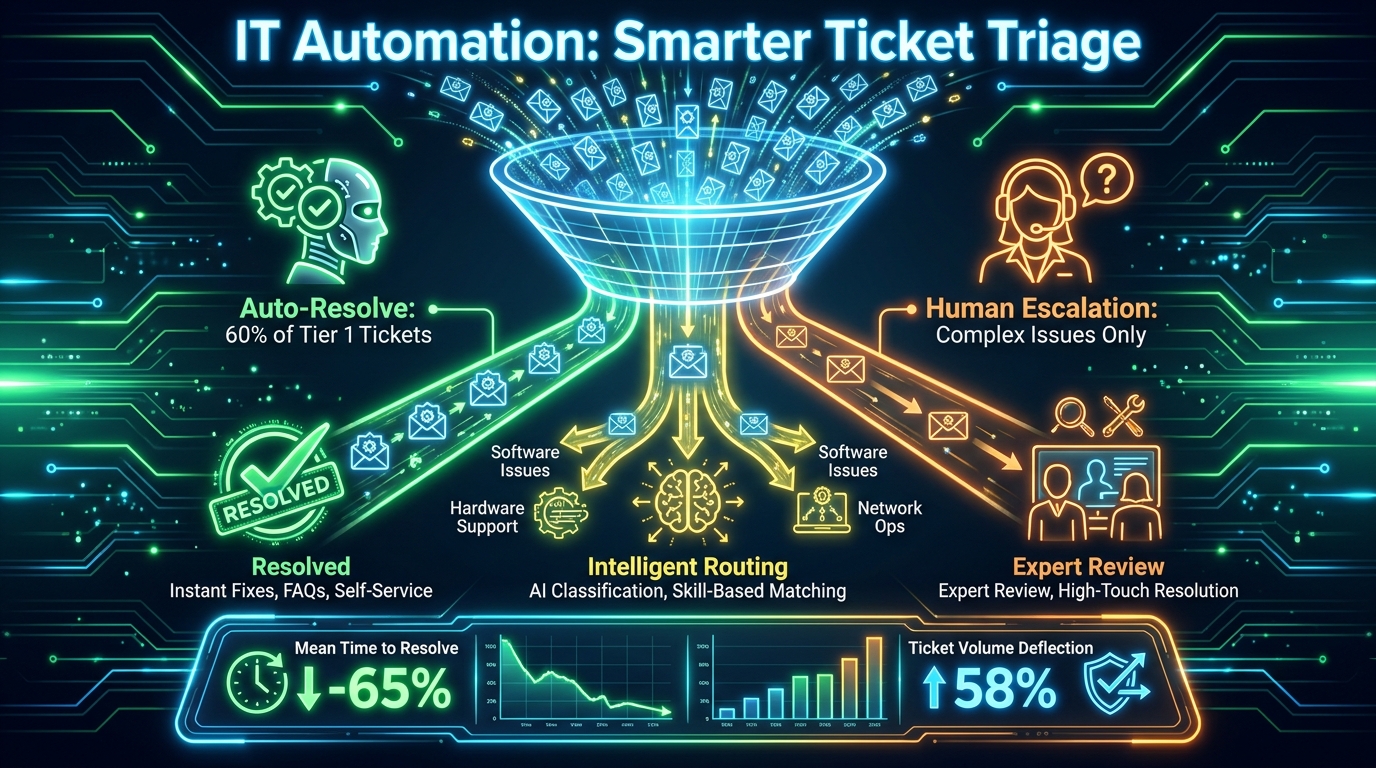
The IT service desk is the most immediate automation opportunity in most organisations. Ticket volumes are high, a significant proportion of issues are repetitive, and resolution is constrained by the availability of human agents rather than by complexity. Studies from 2026 deployments show that automated systems can handle 30–60% of Tier 1 tickets without human intervention — password resets, access requests, software installation approvals, connectivity troubleshooting with standard remediation steps.
Intelligent ticket routing adds a second layer: tickets that cannot be auto-resolved are classified, prioritised, and assigned to the right team automatically, with all relevant context (system, user, previous incidents, knowledge base articles) pre-assembled. The result is a significant reduction in mean time to resolve (MTTR), higher first-call resolution rates, and a measurable improvement in end-user satisfaction scores.
Infrastructure and Cloud Operations
AIOps — AI-driven IT operations — represents the mature form of IT automation. In an AIOps environment, infrastructure monitoring generates predictive alerts before systems degrade, runbook automation executes standard remediation procedures automatically, and capacity management adjusts cloud resource allocation in response to real-time demand rather than static provisioning rules.
The business case for AIOps is straightforward. Every minute of unplanned downtime has a quantifiable cost. Automated detection and remediation reduces mean time to recovery (MTTR) dramatically compared to alert-based, human-driven incident response. For organisations running customer-facing digital services, the difference between a two-minute automated recovery and a 45-minute human-driven one is not only financial — it is reputational.
Software Development and DevOps Pipelines
Hyperautomation in software development concentrates on the non-creative tasks that consume developer time: automated code review, security scanning, testing pipeline execution, deployment orchestration, and environment provisioning. The goal is not to automate software design — that remains a human intellectual endeavour — but to remove the operational friction that prevents developers from focusing on it.
CI/CD pipeline automation, infrastructure-as-code, and automated test generation each reduce the cycle time from code commit to production deployment. For organisations that compete on software velocity, this is not a nice-to-have — it is a core competitive capability.
Customer-Facing Functions: High Visibility, High Stakes
Automation in customer-facing functions operates under a different constraint than back-office automation. When an automated AP process produces an error, a human catches it before it affects anyone outside the organisation. When an automated customer interaction produces a poor experience, the customer feels it directly — and the consequence is relationship damage rather than internal inefficiency.
This does not mean customer-facing automation should be avoided. It means it should be designed with the customer experience as the primary design criterion, not cost reduction.
Customer Service and Conversational AI
AI-powered customer service agents have advanced dramatically from the rigid chatbots of five years ago. Modern conversational AI systems can handle complex, multi-turn conversations, access real-time customer data, execute transactions, and hand off to human agents with full context when situations exceed their capability. The key metric is containment rate — the percentage of customer interactions fully resolved without human intervention.
Klarna’s deployment is one of the most cited benchmarks in this space: the company reported 3.6x revenue per employee and a $40 million profit uplift attributable substantially to AI-driven customer service automation. Their AI agent handles the work equivalent of 700 full-time employees, resolving queries with equivalent customer satisfaction scores while operating across 23 markets and 35 languages simultaneously.
Achieving those results requires more than deploying an AI platform. It requires deep integration with the CRM, the order management system, the payments platform, and the returns system. The AI can only resolve queries that require data it can access — which is why the integration infrastructure built in earlier automation phases directly enables customer service AI capability.
Sales and Revenue Operations
In sales, hyperautomation targets the non-selling activities that consume a disproportionate share of salespeople’s time: CRM data entry, quote generation, contract routing, activity logging, and pipeline reporting. Studies consistently show that sales professionals spend less than 30% of their time in active selling activities — automation attacks the remaining 70%.
AI sales intelligence tools add a predictive layer: identifying the accounts most likely to convert, the timing and channel for outreach most likely to generate responses, and the pricing strategies most likely to close deals at acceptable margins. These capabilities don’t replace salespeople — they make the time salespeople do spend with customers significantly more valuable.
Marketing Operations
Marketing automation has existed for over a decade, but hyperautomation extends its scope significantly. AI content personalisation, predictive lead scoring, automated campaign optimisation that adjusts creative and bidding in real time based on performance data, and multi-channel attribution modelling all represent the current frontier. Benchmarks cite a $5.44 return for every dollar invested in marketing automation when implemented with proper audience segmentation and content strategy.
Process Mining and Digital Twins: Building Your Automation Map
Every automation initiative should begin with an objective understanding of the process being automated. The instinct to skip this step — to rely on process documentation, stakeholder interviews, or intuition — is one of the leading causes of automation projects that automate the wrong thing or automate it in the wrong way.
What Process Mining Actually Reveals
Process mining works by extracting event log data from enterprise systems — the timestamps and transaction records that accumulate in every ERP, CRM, and workflow platform — and reconstructing the actual paths that transactions take through a process. The output is typically startling to organisations that believe they understand their own processes.
What process mining typically reveals: processes that have 10–20 times more distinct execution paths than anyone expected. Steps that documentation says are done in a fixed sequence but that are regularly done in different orders. Tasks that are supposed to take hours but routinely wait days because of upstream dependencies. Individuals or teams who are de facto bottlenecks because of how work is routed to them.
Knowing this before designing an automation solution is the difference between automating the constraint and automating around it. One improves the process. The other creates an expensive bottleneck with more throughput arriving at it.
Digital Process Twins: Testing Before Deploying
A digital process twin is a virtual model of a business process that reflects its real behaviour — including all its variants, exceptions, and dependencies. Once built, it can be used to simulate the impact of proposed automation changes before any code is deployed in production.
The simulation capability is particularly valuable for complex, cross-departmental processes where automating one step can create unexpected effects downstream. A simulation that shows an automated AP matching process will increase exception volumes by 15% because of invoice format inconsistencies is far less expensive than discovering the same thing in production.
Digital twins also enable ongoing process monitoring — comparing the live process’s behaviour against the modelled optimum in real time, and alerting when drift occurs. As automation scales and business conditions change, process drift is inevitable. Digital twins make it visible and measurable rather than gradual and hidden.
Building the Governance Layer: The Center of Excellence Model
Less than 20% of enterprises have established mature governance over their hyperautomation portfolio, despite over 90% identifying it as a priority. This governance gap is not a minor operational inconvenience — it is the primary reason enterprise-wide scaling fails. Without centralised governance, automation efforts fragment. Standards diverge. Platforms multiply. Shadow automation proliferates — departments building automation outside any approved framework because the approved process is too slow.
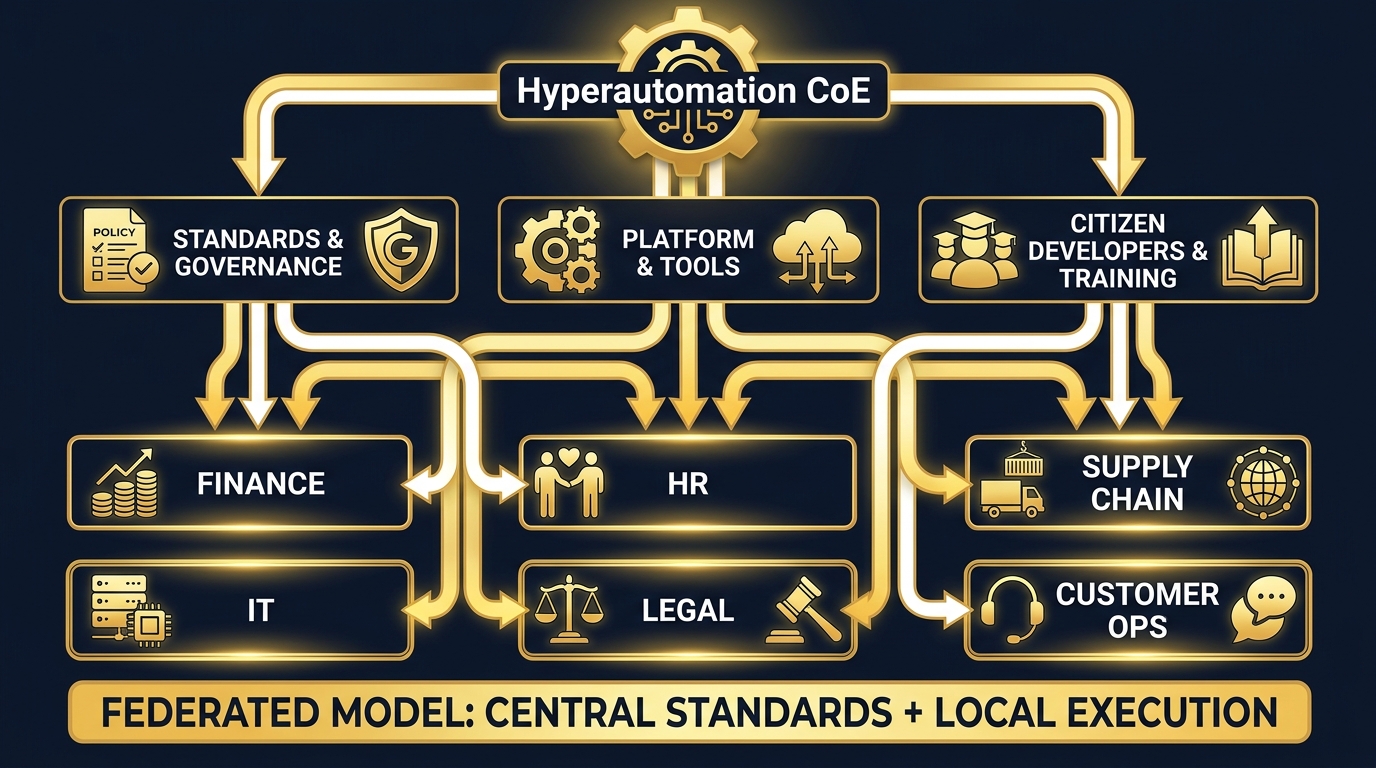
The Federated CoE Structure
The governance structure that works best at scale is the federated Center of Excellence (CoE) model. It consists of two elements in deliberate tension:
Central governance functions define the standards, platforms, security requirements, data governance policies, and performance measurement frameworks that apply to all automation across the organisation. They own the architecture decisions, the vendor relationships, and the compliance posture. They also provide shared services — process mining tools, testing environments, a library of reusable automation components — that departments can draw on rather than build themselves.
Distributed execution capability sits inside business units. Trained citizen developers — non-technical staff who have been equipped with low-code tools and the skills to use them — build and maintain automations within their own functions, subject to the governance standards set centrally. This model scales far more effectively than centralised IT delivery because it matches automation capacity to process knowledge: the people who know the HR process best are in HR, and they can build the automation if they have the tools and guardrails to do it safely.
Governance-as-Code for Agentic Systems
The rise of agentic AI in 2026 has added a new dimension to governance. Rules-based RPA operates predictably; agentic systems adapt their behaviour to new situations. Governing adaptive systems requires governance-as-code — policy enforcement mechanisms embedded in the automation platform itself rather than applied as external controls. This includes role-based access constraints on what agents can do, audit trail requirements that log the reasoning behind automated decisions, human-in-the-loop gates for decisions above defined risk thresholds, and automatic escalation when agent confidence falls below acceptable levels.
The EU AI Act, fully applicable from August 2026, codifies many of these requirements for high-risk AI applications. Organisations in European markets — and global organisations operating there — need explainability, human oversight, and documented risk management for AI systems involved in employment, credit, and certain operational decisions. Building governance infrastructure now, ahead of enforcement, is significantly cheaper than retrofitting it.
Shadow Automation: The Hidden Risk
One of the most underappreciated governance risks is shadow automation — automation built outside any approved framework, typically using consumer-grade tools, without security review, without documentation, and without ownership. It exists in almost every large organisation. An operations manager has built a macro that reformats data before it goes into the ERP. A finance analyst has a Python script running on their laptop that pulls data from three systems and compiles a report. These are automations. They are also risks: security vulnerabilities, single points of failure that leave with the person who built them, compliance gaps in regulated environments.
Effective CoEs don’t eliminate shadow automation through prohibition — they eliminate the need for it by making approved automation faster and easier than unofficial workarounds. When the governed path is genuinely more convenient than the ungoverned one, compliance follows.
The Workforce Dimension: Skills, Change, and the Human Layer
Hyperautomation is not primarily a technology story. It is an organisational change story in which technology plays the lead role. Every automation initiative displaces some existing human activity and requires new human capability in its place. Organisations that ignore this dimension discover it the hard way — technically successful automation implementations that fail in production because the people who were supposed to work alongside them were never prepared to do so.
The Skills Reality
87% of organisations face automation-related skill gaps. 90% are expected to encounter IT skills shortages by the end of 2026. These gaps are not primarily in advanced AI engineering — they are in the practical skills required to design, deploy, maintain, and govern automation in operational contexts: process analysis, data quality management, low-code development, and the management of human-AI workflows.
The most pragmatic response is a tiered upskilling programme that does not attempt to turn everyone into a developer but does give everyone a working vocabulary for automation and a subset of staff the capability to build automations independently. Tier one: universal AI and automation literacy across the organisation. Tier two: low-code citizen developer skills for a defined cohort in each department. Tier three: deep technical skills in the CoE team and IT function for the complex integration and governance work that requires engineering.
Redeployment vs. Displacement
The workforce question that every organisation must answer honestly is what happens to the people whose work is automated. The optimistic framing — that automation creates higher-value work for displaced staff — is sometimes true and sometimes not. Finance staff freed from invoice processing genuinely can shift to financial analysis if the organisation provides the training and creates the roles. In other cases, the honest answer is that the workload reduction is real and headcount reduction is the intended outcome.
Neither outcome is inherently wrong, but both require honest communication. Automation initiatives that proceed without clear workforce planning create anxiety, resistance, and — most damagingly — the strategic withholding of process knowledge by staff who fear that sharing how their job works will accelerate their own redundancy. This is the most insidious form of automation failure: organisations technically capable of automating processes that never get automated because the people who know those processes won’t cooperate.
Change Management as an Investment, Not an Overhead
Mature hyperautomation programmes treat change management as a parallel workstream with its own budget, leadership, and milestones — not as a communication activity bolted on to a technology project. This means executive sponsorship that is visible and credible, not ceremonial. It means departmental champions who understand both the technology and the human dynamics of their function. It means feedback loops that allow staff to report automation problems and improvement ideas without penalty. And it means measurement of adoption and utilisation, not just of deployment.
An automation that has been deployed but is routinely bypassed by staff who prefer the manual process is not a successful automation, regardless of what the deployment dashboard says. Measuring actual utilisation — and diagnosing low utilisation before writing it off as resistance — is a governance responsibility.
What to Measure: ROI Frameworks That Actually Work
Most hyperautomation ROI calculations are wrong — not because the math is incorrect, but because the measurement framework is incomplete. Organisations that measure only cost reduction systematically undervalue their automation portfolio, because the most significant impacts are often speed, quality, and strategic capability — none of which appear directly in a cost line.
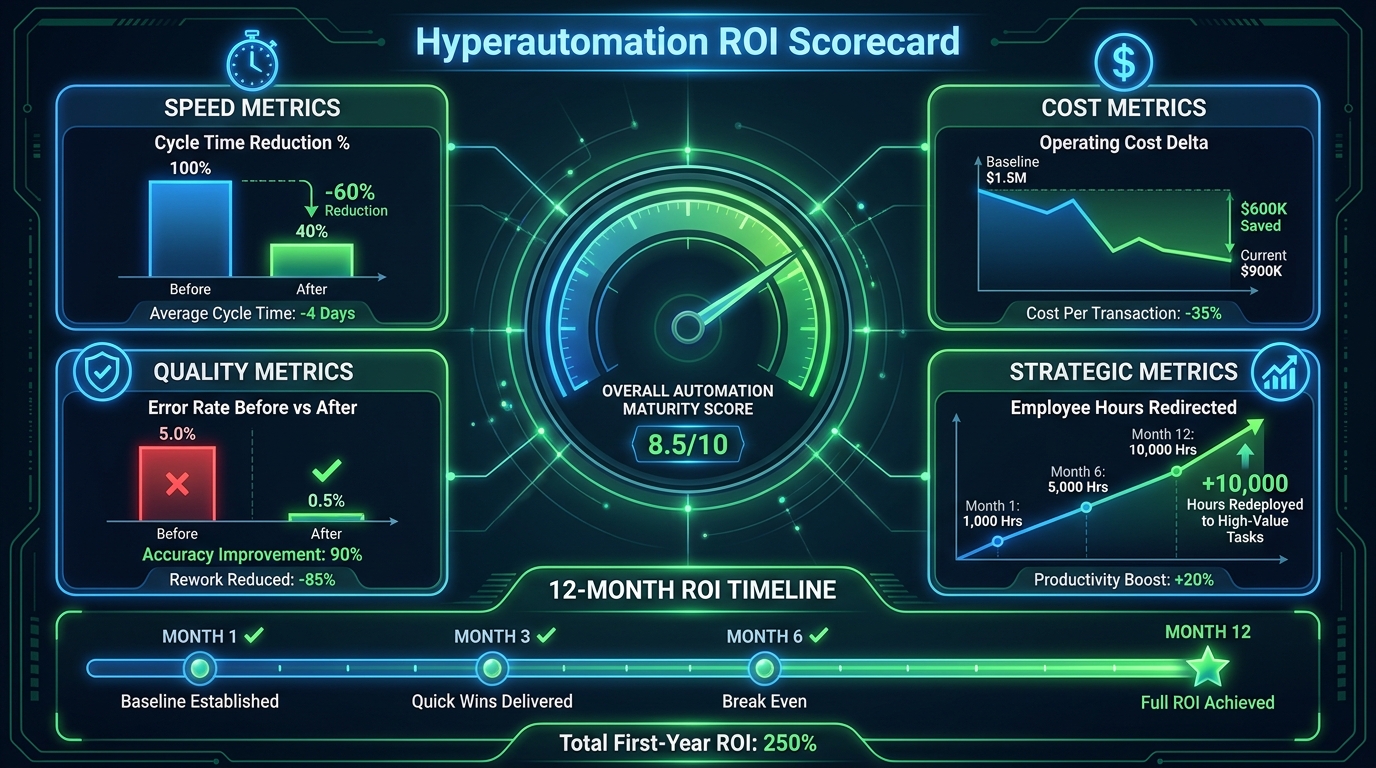
The Four Measurement Domains
A complete hyperautomation measurement framework covers four domains:
Speed Metrics: Cycle time reduction is the most immediate indicator of automation impact. How long does the process take now compared to before? Measure this at the process level, not the task level — automating one step in a five-step process may speed up that step while leaving total cycle time unchanged if the bottleneck was elsewhere. End-to-end process duration, measured from the same entry point as before, is the relevant number.
Cost Metrics: Operating cost delta accounts for both the cost savings from automation and the ongoing cost of the automation itself — platform licences, maintenance, integration support, and the governance overhead of the CoE. Both sides of the ledger must be measured. A process that saves 10 FTEs but requires 8 FTEs to maintain the automation is a 2 FTE net saving, not a 10 FTE saving.
Quality Metrics: Error rate before and after automation is a frequently overlooked metric that often reveals more value than cost reduction. An automated invoice matching process that reduces exception rates from 8% to 0.5% has created value not just in processing speed but in the downstream time saved by finance staff who no longer handle exceptions — and in the risk reduction from fewer payment errors. Customer-facing quality metrics — satisfaction scores, complaint rates, first-contact resolution rates — apply in customer operations contexts.
Strategic Metrics: The hardest to measure but often the most important. How many employee hours are being redirected to higher-value work? What new capabilities does the organisation have that it didn’t before? How has data quality improved, and what decisions are now being made with better information? What is the organisation’s automation maturity score, and how is it trending relative to competitors?
Benchmarks and Realistic Expectations
2026 implementation data provides the following benchmark ranges for well-executed hyperautomation across business functions:
- Finance/AP processing: 20–40% cost reduction, 40%+ cycle time improvement, payback in 6–12 months.
- Customer service: 15% productivity gain, 30–60% Tier 1 ticket auto-resolution, 200–1,000% first-year ROI for high-volume deployments.
- HR operations: 26–55% productivity improvement, significant reduction in onboarding errors, measurable improvement in employee experience scores.
- Manufacturing/supply chain: Up to 50% reduction in unplanned downtime, 35% efficiency ROI improvement, 20% reduction in inventory carrying costs.
- Overall enterprise: 20–40% operating cost reduction for mature deployments, average 171–330% ROI across implementations.
These figures represent achievable outcomes, not guaranteed ones. The variance between top and bottom quartile performers is enormous — and that variance is almost entirely explained by the quality of process intelligence, governance, and change management, not by the technology choices made.
The Measurement Cadence
Automation ROI should be measured at three horizons: 30-day post-deployment to validate that the automation is functioning as designed, 90-day to confirm that adoption is genuine and the process is stable, and 12-month to capture the fully loaded ROI including maintenance costs and the value of redirected employee time. Organisations that only measure at deployment typically overstate ROI by missing the maintenance cost and understate it by not capturing the strategic value that only becomes visible over time.
The Honest Reality of Scaling Hyperautomation Across the Enterprise
Enterprise-scale hyperautomation is a multi-year programme, not a series of projects. The organisations that have reached mature, cross-functional automation — where finance, HR, supply chain, IT, and customer operations are operating on connected automated infrastructure — did not get there in a single initiative. They got there through sustained commitment, consistent governance, and a willingness to invest in the enabling infrastructure that doesn’t produce immediate ROI but makes everything else possible.
The following realities are worth absorbing before committing to an enterprise hyperautomation journey:
Integration Is Where Projects Die
The leading technical cause of hyperautomation project failure is integration. Systems that don’t share data models. APIs that aren’t available. Legacy platforms that predate any integration standards. The automation that works perfectly in the vendor’s demo environment fails in production because the production environment is a 20-year-old ERP with a proprietary data structure.
The investment in integration infrastructure — API management, iPaaS, master data management — is unglamorous and expensive. It generates no obvious ROI on its own. It is also the foundation without which every other automation investment underperforms. Organisations that treat integration infrastructure as overhead rather than foundational investment consistently struggle to scale beyond isolated departmental wins.
Data Quality Is Not an IT Problem
60% of AI-driven automation projects that fail cite poor data quality as the primary cause. This is not surprising — AI systems trained on or operating with low-quality data produce low-quality outputs, and automated processes that ingest bad data propagate errors at machine speed rather than human speed. What is surprising is how often this is treated as an IT problem to be solved rather than an organisational quality management commitment to be sustained.
Data quality is owned by the business, not by IT. The finance team owns the quality of its financial data. The HR team owns the quality of its employee records. Supply chain owns the quality of its supplier and inventory data. Automation projects that begin without a data quality assessment and remediation plan will encounter their poor data in production at the worst possible time.
The Automation Debt Accumulation Problem
Every automation built today is tomorrow’s maintenance obligation. Rule-based RPA bots require updates every time the underlying system changes its interface. AI models require retraining as data distributions shift. Integrations break when vendors update APIs. The cumulative maintenance burden of a large automation portfolio — without proper documentation, governance, and lifecycle management — can become significant enough to consume the capacity of the team responsible for it, leaving no bandwidth for new development.
Organisations that manage this effectively treat automation like software: with version control, documentation standards, owner assignment, and scheduled review cycles. Those that don’t find themselves maintaining a portfolio of brittle, undocumented automations that no one fully understands — the automation equivalent of technical debt.
Where to Begin: A Practical Starting Framework for 2026
The question every organisation asks after understanding the scope of enterprise hyperautomation is: where do we start? The answer depends on the organisation’s current state, but several principles apply broadly.
Start With Process Intelligence, Not Tools
Before deploying any automation technology, invest in understanding your processes. Deploy process mining on your highest-volume, most critical workflows. The data will reveal automation opportunities you didn’t know existed and prevent investment in automating the wrong things. This phase typically takes 4–8 weeks and generates insights that anchor all subsequent automation decisions.
Choose Your First Automation Domain Strategically
For most organisations, finance is the strongest first domain — high volume, measurable outcomes, relatively structured data, and payback timelines that fund subsequent phases. IT service desk is often a close second, for similar reasons. HR onboarding is an excellent early choice for organisations where the talent experience is a strategic priority. The criterion for selection should be: where is the combination of high volume, high data structure, measurable outcome, and internal champion strongest?
Build the Governance Architecture Early
The CoE structure should be established before the second department launches its automation programme, not after the fifth. The governance overhead of establishing standards, choosing platforms, and building a citizen developer programme feels disproportionate when only one department is active. By the time five departments are running independent initiatives, it is too late to standardise without painful consolidation work.
Invest in the Integration Foundation
The investment in iPaaS, API management, and master data management should begin in parallel with the first automation domain rather than waiting until integration problems force the investment. Every dollar spent on integration infrastructure before it is needed is worth significantly more than the same dollar spent in crisis mode when production automations are breaking because systems can’t communicate.
Design for Humans, Not for Efficiency Targets
Every automation design decision should be evaluated not only for its technical soundness and efficiency impact, but for how it affects the humans who work alongside it — the staff whose roles change, the customers who interact with it, the managers whose decisions it informs. Automation that achieves its efficiency target while producing staff disengagement, customer frustration, or management information that is misunderstood is a partial failure, regardless of what the ROI dashboard shows.
Conclusion: The Enterprise That Automates Well Wins Differently
The organisations winning with hyperautomation in 2026 are not necessarily those with the most sophisticated technology or the largest automation portfolios. They are the organisations that have done the unglamorous foundational work — mapping their processes honestly, building governance before it was urgently needed, integrating their systems before automation demanded it, and preparing their people before automation changed their roles.
Hyperautomation done well is not about removing humans from work. It is about removing humans from the work that machines do better — the high-volume, high-repetition, high-error-risk work that drains human capability without utilising human judgment — so that human effort concentrates on the work that genuinely requires it: complex problem-solving, relationship management, creative decision-making, and the continuous improvement of the automated systems themselves.
The department-by-department expansion of automation is not a technical roadmap. It is an organisational maturity journey. Finance learns to automate, then teaches the organisation what automation looks like when it works. HR follows and discovers different challenges. Supply chain adds complexity. IT becomes the enabler. Customer operations adds the human stakes that sharpen discipline. The CoE evolves from a project team to an institutional function. And at some point — not at once, but gradually — the organisation has become genuinely different in its capabilities: faster, more consistent, more data-driven, and more capable of deploying human intelligence where it matters most.
That is not a technology story. It is a strategy story in which technology is the instrument. And strategy, unlike technology, cannot be purchased. It has to be built.
Immediate Actionable Takeaways
- Run a process mining assessment on your top three highest-volume processes before investing in any new automation tooling. Let the data tell you where to build.
- Establish your CoE governance structure now, even if it is currently a small team. Define your platform standards and data governance policies before they become contested.
- Identify your first cross-departmental automation use case — an end-to-end process that touches at least two functions. Build it as a proof-of-concept for the orchestration layer.
- Audit your current automation portfolio for shadow automation, orphaned bots, and undocumented processes. Understand what you have before you build more.
- Conduct a workforce readiness assessment alongside your process assessment. The human change management timeline is at least as long as the technology timeline, and it needs to start at the same time.
- Build your measurement framework before deployment, not after. Define your baseline metrics now so you can claim the ROI later with data rather than estimates.