Ask most engineering teams where their multi-agent AI system breaks, and you’ll hear a familiar answer: “We think it’s the model.” A prompt that degrades over long conversations. A tool call that returns unexpected output. A reasoning step that goes sideways. The blame lands squarely on the LLM.
It’s almost always the wrong diagnosis.
Production data from 2026 is unambiguous: multi-agent AI systems fail at rates exceeding 50% across real workloads, and the dominant failure pattern is not model capability. It’s the handoff — the transition point where one agent’s work ends and another’s begins, where task state crosses a boundary, where responsibility implicitly transfers across teams. Those moments are where the system quietly falls apart.
What makes this particularly costly is that handoff failures compound. When Agent A passes malformed context to Agent B, Agent B doesn’t necessarily throw an error. It reasons confidently over bad inputs, produces plausible-looking outputs, and passes those downstream. By the time a human notices something is wrong, the error has propagated three or four layers deep. Recovery requires unwinding the entire chain. The productivity loss is rarely captured in any dashboard.
The AI industry spent most of 2024 and 2025 obsessing over model benchmarks and context window sizes. In 2026, the engineers actually running these systems in production are discovering that the model is rarely the bottleneck. The bottleneck is coordination — specifically, what happens at the seams between agents and between the teams that own them. This article examines exactly that: what breaks at handoffs, why it breaks with such regularity, and what the teams building stable multi-agent systems are doing differently.

Why Agent Handoffs Fail at Such High Rates
The >50% failure rate in production multi-agent systems is not a fringe finding. It appears consistently across different frameworks, different model families, and different enterprise contexts. Understanding why requires dissecting what actually happens at a handoff.
When one agent completes its portion of a workflow and passes control to another, three things need to transfer successfully: the task state (what has been accomplished), the context (what information is relevant to the next step), and the intent (what the overall goal is and what constraints apply). In theory, all three travel together. In practice, they frequently don’t — and not because anyone designed it that way.
Root Cause 1: Unstructured Context Transfer
The most prevalent failure mode is raw text handoffs. One agent completes its work, wraps up a natural-language summary, and passes that to the next agent as its input. This seems reasonable — LLMs are good at reading natural language, after all. But natural language is deeply ambiguous in ways that matter for downstream reasoning.
When an agent receives “the customer has expressed some concerns about delivery timelines and the order value appears to be significant,” it has to make interpretive decisions: How concerned? How significant? What constraints apply? What has already been tried? It fills in those gaps with inference — and inference at handoffs is where hallucination enters multi-agent pipelines. The downstream agent isn’t hallucinating from nothing; it’s interpolating over underspecified inputs. The difference matters because the failure is invisible unless you’re specifically looking for it.
Structured context transfer — typed schemas, JSON payloads with defined fields, tool output objects — eliminates this ambiguity. If the handoff payload includes order_value: 4280.00, delivery_concern: true, previous_resolutions_attempted: [], and escalation_threshold_met: false, the next agent has no interpretive work to do. It operates on facts, not inference.
Root Cause 2: Unclear Ownership at the Boundary
The second major failure pattern is organizational rather than technical: nobody owns the handoff itself. Agent A is owned by the sales automation team. Agent B is owned by the fulfillment engineering team. The handoff between them — the schema, the error handling, the fallback logic — exists in neither team’s mandate. When it breaks, both teams point at each other.
Healthcare executives at HIMSS26 reported this exact pattern in their agentic architecture deployments: most failures occurred between agents rather than inside them. The agents themselves performed adequately within their defined scope. The coordination layer between teams’ systems was where things collapsed. This is a systems design problem disguised as a technology problem, and treating it with more model fine-tuning accomplishes nothing.
Root Cause 3: Brittle Routing Logic
The third root cause is routing logic that assumes the happy path. Most agent orchestration systems handle the cases their designers anticipated. They break when encountering edge cases: ambiguous task state that doesn’t map cleanly to a single next agent, partial failures that require reprocessing, or loops where two agents pass the same unresolved problem back and forth. Without explicit handling for these scenarios — timeout logic, dead letter queues for stuck tasks, circuit breakers for agents that are producing degraded outputs — the system’s behavior in production becomes unpredictable.
Context Rot: The Silent Killer of Multi-Agent Pipelines
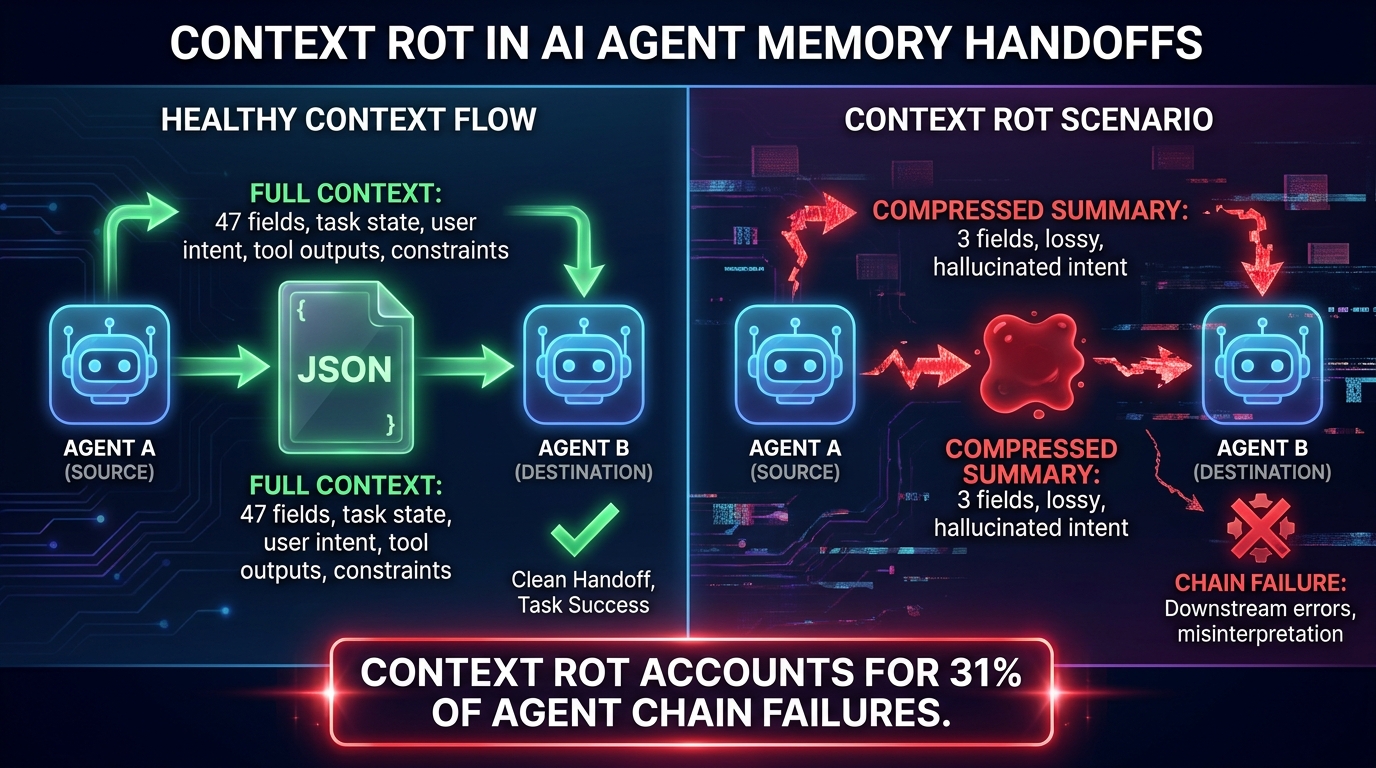
“Context rot” is the term practitioners are increasingly using to describe what happens to task information as it travels through a multi-agent chain. It’s worth spending time on this concept because it’s the most misunderstood aspect of multi-agent failure — and because it’s fixable if you understand the mechanism.
How Context Degrades Across Agent Steps
Each agent in a chain typically receives a context window with some combination of: the original user request, the outputs of previous agents (often summarized), and its own system prompt. When that context window gets long — which it does quickly in complex workflows — something has to give. The most common solution is lossy compression: the orchestration layer summarizes previous steps into a paragraph or two and passes that forward.
The problem is that summarization is itself a model call, and model-generated summaries privilege information that seemed relevant when the summary was created — not necessarily what the next agent actually needs. Crucial constraints get dropped. Specific numeric values get rounded or paraphrased. Edge cases encountered in earlier steps get smoothed over in the narrative. The downstream agent receives a version of reality that has been simplified and filtered by a prior model’s judgment about relevance.
This is compounded across longer chains. An agent at position six in a pipeline is potentially working from context that has been summarized five times. Each compression step is a lossy transformation. The cumulative effect is a context that bears a family resemblance to the original task but no longer accurately represents it. The term “context rot” is apt: the degradation is gradual, invisible from any single step, and only apparent when you compare what the final agent is reasoning over against what the user actually asked for.
What Queryable Memory Actually Solves
The architectural response to context rot is queryable memory: instead of compressing task history into a rolling summary and passing it forward, the system persists key artifacts — structured outputs, tool results, intermediate decisions — in a retrievable store. Each agent queries this store at runtime for the specific pieces of context it needs, rather than receiving a pre-filtered summary decided by a prior step.
This approach solves several problems simultaneously. It decouples context size from chain length (the memory store grows, but each agent’s active context window stays bounded). It preserves specificity — numeric values, boolean states, structured tool outputs remain queryable exactly as they were generated. And it creates an audit trail: you can inspect what any agent retrieved and when, which is essential for debugging failures and for compliance in regulated industries.
The practical implementation varies. Some teams use vector databases for semantic retrieval. Others maintain structured key-value stores for deterministic lookups of task state. The most robust approaches combine both: a structured store for task state and tool outputs, and a semantic layer for retrieving relevant prior context from longer-running workflows. The shared principle is that context is managed rather than simply passed.
The Compounding Error Problem
Context rot leads directly to the compounding error problem, which deserves its own mention. In a well-designed pipeline, errors are caught early and don’t propagate. In a multi-agent system with degraded context, they don’t just propagate — they amplify. An agent that reasons from a flawed premise doesn’t produce a slightly wrong answer; it produces a confidently wrong answer that looks correct, which then becomes the premise for the next agent’s reasoning.
Engineering teams tracking this in production describe finding errors at step six of a pipeline that originated at step two — but weren’t detectable at step two because the output of step two looked plausible in isolation. This is why step-level evaluation, not just end-task evaluation, is emerging as a non-negotiable requirement for production multi-agent systems.
The Handoff Contract: What It Is and Why You Need One

A handoff contract is the specification for what one agent must produce for the next agent to succeed. It’s not a new concept — software engineering has used interface contracts for decades — but applying it rigorously to AI agent transitions is a relatively recent and underutilized practice.
The framing matters: a handoff contract shifts the design question from “what should Agent A output?” to “what does Agent B need as input?” Those are not the same question, and the difference in framing produces better systems. Designing from the receiver’s requirements backward forces you to specify the exact information, format, and completeness conditions that make the downstream step reliable.
The Core Fields of a Handoff Contract
A minimal handoff contract for production systems typically includes the following elements:
- Source and destination agents: Explicitly identified, with version tags. This matters for debugging — knowing which version of Agent A produced the payload that Agent B is reasoning over is essential when behavior changes after a model update.
- Task state: The current status of the workflow — what has been completed, what is in progress, what has been explicitly skipped or deferred. This should be a typed enum, not a prose description.
- User intent: The original goal, preserved verbatim or as a structured representation, not summarized by an intermediate agent. Intent degradation — where the original user objective gets reinterpreted by agents along the chain — is a documented failure mode that explicit intent preservation prevents.
- Tool outputs: Structured results from any tools called during the prior step, passed as typed objects rather than prose summaries. If Agent A called an inventory API and received a JSON response, that response should travel to Agent B intact.
- Active constraints: What the next agent is and isn’t permitted to do. Compliance boundaries, budget limits, time constraints — anything that restricts the solution space. These are among the most commonly dropped fields in unstructured handoffs.
- Fallback owner: The named human or team responsible if the handoff fails or if the receiving agent cannot proceed. Not optional in regulated environments.
- Correlation ID and timestamp: For tracing and audit purposes. These allow you to reconstruct the full workflow history for any given task, across any number of agent steps.
Versioning Handoff Contracts
One of the most practically important aspects of handoff contracts — and one that gets overlooked until it causes a production incident — is versioning. When Agent A’s team updates their output schema, Agent B needs to know. Without version tracking on handoff contracts, a schema change by one team can silently break downstream agents maintained by a different team. The failure mode is exactly what you’d expect: Agent B receives fields it doesn’t recognize (or doesn’t receive fields it expects), fills in gaps with inference, and produces wrong outputs without throwing an error.
The solution borrows from API design: treat handoff contracts as versioned interfaces. Breaking changes require a version bump. Receiving agents declare which versions they accept. Deprecation notices go out before old versions are retired. This sounds bureaucratic until you’ve debugged a cross-team handoff failure at 2am and wished you had it.
Contract Validation at Runtime
The most robust implementations validate handoff payloads at runtime against the contract schema before the receiving agent begins processing. If the payload fails validation — missing required fields, wrong types, constraint violations — the system routes to a defined error handler rather than letting the receiving agent reason over malformed input. This shifts the failure mode from a silent, compounding error to an explicit, recoverable fault. The distinction is enormous from an operational perspective.
Protocols in 2026: A2A, MCP, and What They Actually Do for Handoffs
The AI agent protocol landscape in 2026 has crystallized around a small set of specifications that define how agents communicate, share context, and transfer task ownership. Understanding these protocols helps clarify what infrastructure problems they solve — and what they don’t.
Model Context Protocol (MCP)
MCP, originally developed by Anthropic and now widely adopted, defines a standard interface for how agents connect to external tools, data sources, and APIs. It’s primarily an agent-to-tool protocol: it specifies how an agent requests a capability (a search, a database query, an action) and how the tool returns structured results.
For handoffs, MCP matters because it standardizes the format of tool outputs — the structured results that should travel through handoff payloads. When agents across different teams use MCP-compatible tools, their tool outputs share a common schema. This reduces the friction of passing structured tool results through handoffs: a downstream agent can reason over the output of a prior agent’s tool call without needing custom parsing logic.
Agent-to-Agent Protocol (A2A)
A2A is the more directly relevant protocol for handoffs: it defines how agents communicate with each other. The 2026 version of A2A specifies a typed message schema with defined message types — TASK, RESULT, STATE_UPDATE, INTENT — and mandatory metadata including agent identifiers, correlation IDs, and capability tags.
The capability tags are worth specific attention. They allow a receiving agent to declare what kinds of tasks it can process, which enables intelligent routing — an orchestrator can inspect a receiving agent’s declared capabilities before routing a task to it, rather than discovering at runtime that the agent can’t handle the work. This addresses a common failure mode where handoffs fail not because of context problems but because of capability mismatches: the work gets routed to an agent that isn’t equipped to do it.
What These Protocols Don’t Solve
It’s important to be clear about the limits of protocol adoption. A2A and MCP provide the transport layer and message format for agent communication. They don’t define what goes in the messages — that’s the handoff contract layer. They don’t enforce that context is complete or accurate. They don’t handle the organizational question of who owns the interface. Protocols are necessary infrastructure, but they are not a substitute for thoughtful handoff design.
Teams that adopt A2A and MCP but don’t invest in handoff contract design will reduce schema incompatibility errors while still experiencing context rot, ownership gaps, and routing brittleness. The protocols solve the plumbing. They don’t architect the building.
Supervisor vs. Swarm: Choosing the Right Topology for Your Handoffs
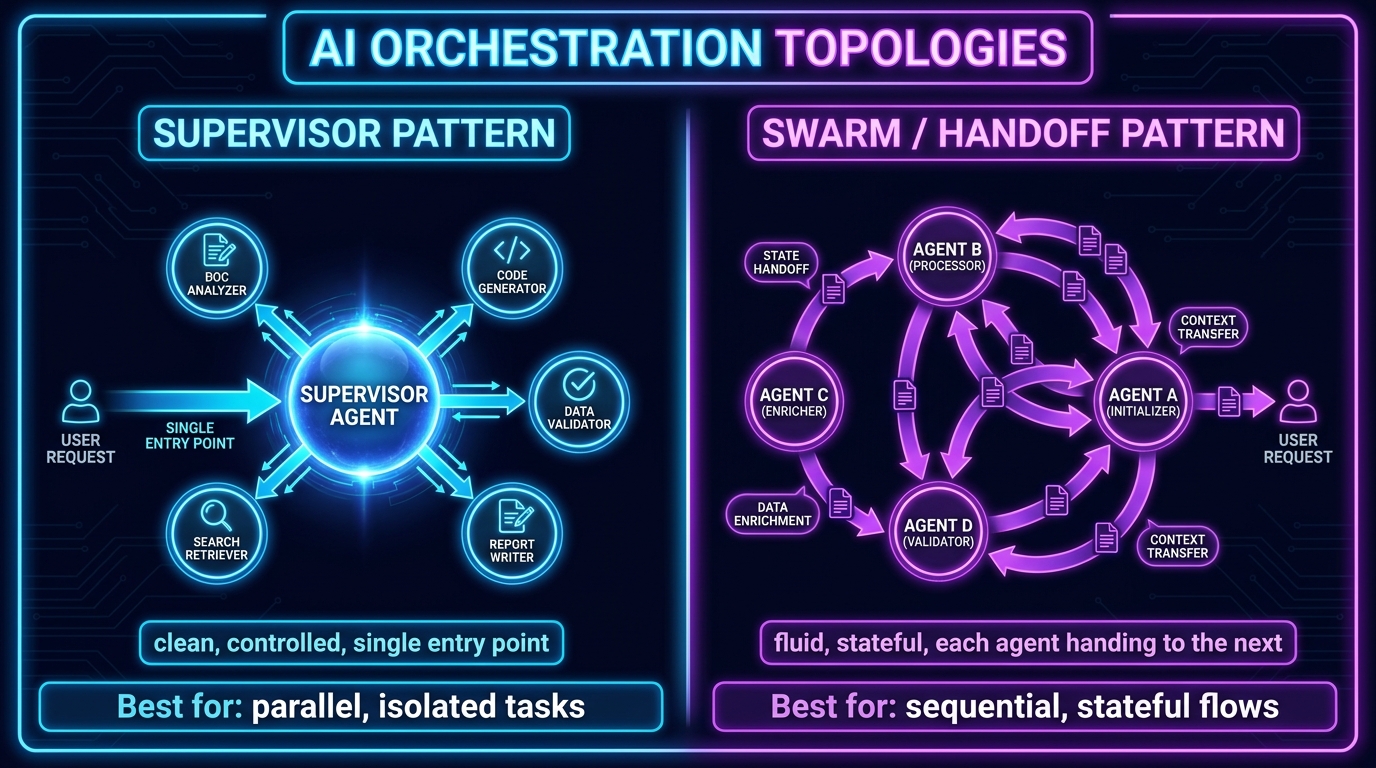
One of the most consequential architectural decisions in multi-agent system design is the choice between two fundamentally different orchestration topologies: the supervisor pattern and the swarm (or handoff chain) pattern. The wrong choice for a given workflow creates structural handoff problems that are expensive to fix after the fact.
The Supervisor Pattern
In the supervisor pattern, a central orchestrating agent manages a set of specialized sub-agents. The supervisor receives the user’s request, decomposes it into subtasks, delegates those subtasks to appropriate sub-agents (typically by calling them as tools), receives their outputs, and synthesizes a response. Sub-agents are stateless from the workflow’s perspective — they receive a scoped task, complete it, and return a result. They don’t communicate with each other directly.
This topology’s strength is exactly what makes it legible: the supervisor owns the full state of the workflow at all times. There is one place to look when something goes wrong. The handoff problem is partially contained because sub-agents receive well-scoped tasks and return structured results, both defined by the supervisor’s orchestration logic.
The limitations appear when workflows are genuinely sequential and stateful — when Agent B’s work depends not just on Agent A’s output but on the ongoing state of a task that evolves across multiple steps. In those cases, funneling everything through a supervisor adds latency and token cost while creating a bottleneck. The supervisor itself can become a point of failure if its context window grows too large or if its orchestration logic doesn’t handle edge cases well.
The Swarm / Handoff Chain Pattern
In the swarm or handoff chain pattern, agents pass control directly to each other. Agent A completes its work and hands off to Agent B, which completes its work and hands off to Agent C, and so on. The active agent at any given moment is stored in a shared state variable, and each agent can trigger the transition to the next. There’s no central orchestrator — the workflow topology is embedded in the handoff logic itself.
This pattern maps naturally to sequential, stateful workflows: support triage systems where each step gates the next, order management processes that move through defined stages, or research pipelines where each agent builds on the prior agent’s work. The handoffs are explicit and auditable — you can see exactly when and why control transferred.
The risk is that the handoff logic becomes the system’s most complex and fragile component. When workflows have many branches or edge cases, the state machine that governs handoffs can become difficult to reason about. Teams that adopt the swarm pattern without investing in robust handoff contract design and step-level observability tend to discover edge cases the hard way, in production.
The Decision Criteria
The practical decision rule most production teams have converged on is fairly clear: use the supervisor pattern for workflows where sub-tasks are largely independent and can be executed in parallel or in any order; use the handoff chain pattern for workflows that are inherently sequential and where earlier steps produce state that directly shapes what later steps can do. Many real systems use both: a supervisor at the top level for task decomposition and routing, with handoff chains within specific workflow legs where sequencing matters.
The anti-pattern to avoid is choosing topology based on familiarity or convenience rather than workflow requirements. A supervisor applied to an inherently sequential workflow creates artificial indirection and single points of failure. A swarm pattern applied to a parallel task set creates unnecessary state management complexity and handoff overhead. Start with the workflow’s natural structure and choose the topology that matches it.
Observability at the Seams: Tracing Agent Handoffs in Production
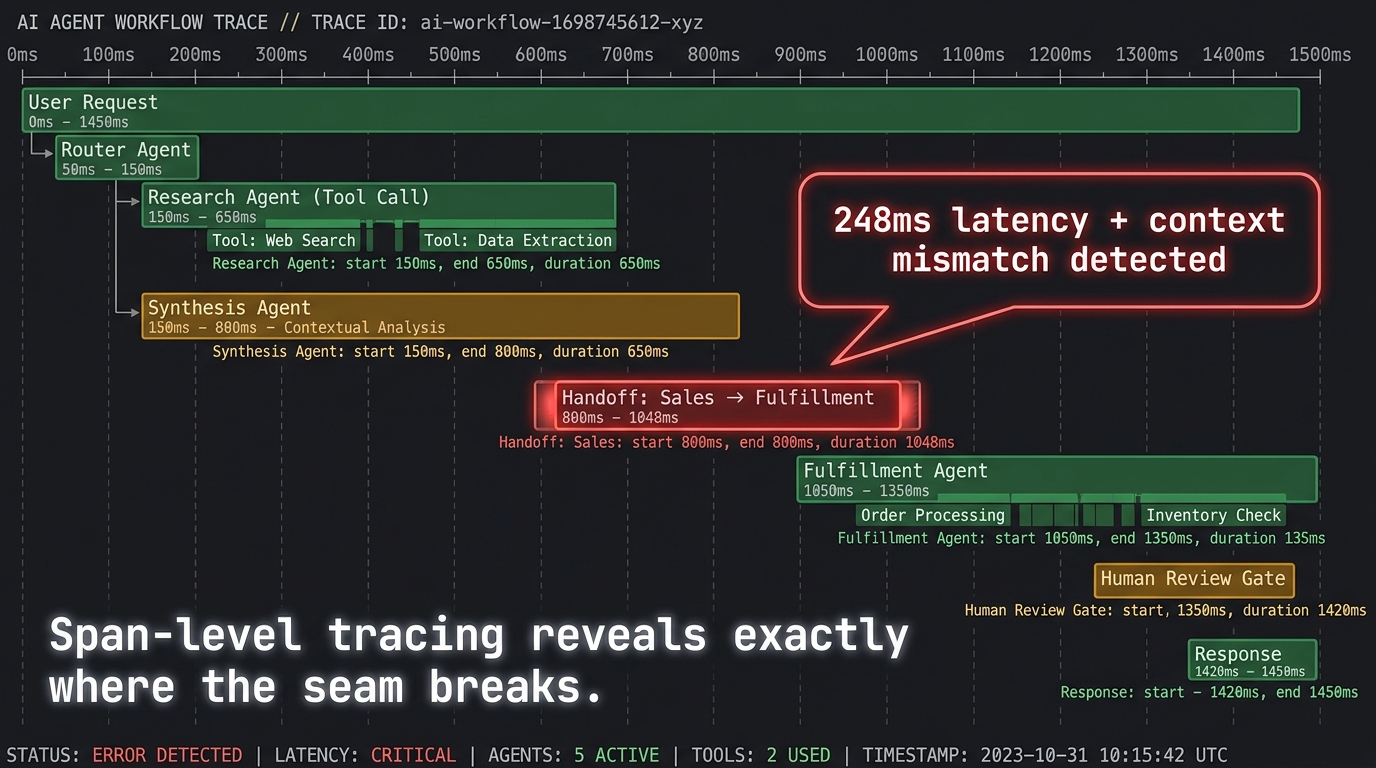
Building good handoffs is necessary but not sufficient. Production multi-agent systems require the ability to see, in real time, what is happening at each handoff — not just whether the system produced an output, but whether each transition transferred context correctly, completed within acceptable latency, and passed control to the right downstream agent.
The observability paradigm that has emerged for this is span-level distributed tracing, borrowed from microservices architecture and adapted for AI workflows. A single user request becomes a root trace, with child spans for each agent step, tool call, retrieval operation, and handoff. Each span captures timing, inputs, outputs, and metadata. The handoff spans specifically capture the payload transferred, the source and destination agents, and any validation failures.
Why Single-Call Logging Is Not Enough
Many engineering teams start with simple LLM call logging: each model invocation is recorded with its prompt and completion. This is better than nothing, but it’s insufficient for multi-agent workflows for a specific reason: it captures what each agent did in isolation, but not what passed between them. The failure modes at handoffs — context truncation, schema mismatches, dropped constraints — don’t appear in per-agent logs. They only appear when you instrument the handoff transitions themselves as observable events.
The shift to span-level tracing creates a fundamentally different debugging experience. When a multi-agent pipeline produces a wrong output, the trace shows exactly which handoff carried the error into the pipeline. You can inspect the handoff payload at each step, compare what was sent against what was received, and identify the precise point where context diverged from ground truth. This kind of root cause identification — which previously required hours of log archaeology — becomes a matter of minutes.
What to Instrument at Handoff Points
Effective handoff observability instruments at minimum: the full payload being transferred (with sensitive fields masked for compliance), the schema validation result, the latency of the handoff operation, the version of both the source and destination agent, and any fallback or retry events triggered. In regulated environments, this trace data also serves as the audit log for compliance reporting — demonstrating that specific constraints were applied and maintained throughout a workflow.
OpenTelemetry has emerged as the standard instrumentation framework for this work. Several purpose-built AI observability platforms — Langfuse, LangSmith, Arize Phoenix, and others — provide the UI layer for navigating these traces, with support for session replay, step-level evaluation, and cross-agent comparison. The infrastructure investment is real, but teams that have made it consistently report that it changes their relationship with production failures: problems become diagnosable rather than mysterious.
Evaluation at the Step Level, Not Just the Task Level
One of the more significant shifts in production AI operations in 2026 is the move from end-task evaluation to step-level evaluation. Evaluating whether the final output of a multi-agent pipeline is correct tells you whether the system worked, but not where it went wrong or why. Step-level evaluation — assessing the quality of each agent’s output and each handoff payload against defined criteria — enables the kind of targeted debugging and improvement that end-task metrics alone can’t support.
In practice, this means defining what “correct” looks like for each step: what fields the handoff payload must contain, what ranges or types are acceptable for key values, what invariants should hold across the transition. Automated evaluators can then check these criteria for every handoff in production, flagging deviations in real time rather than waiting for end-task failures to surface them.
Human-in-the-Loop Gates: The Most Underrated Handoff Pattern
In the current discourse around autonomous AI agents, human-in-the-loop (HITL) gates are sometimes framed as a limitation — a concession to distrust of AI, a temporary measure until systems are good enough to operate fully autonomously. This framing is backwards, and it leads teams to remove human gates prematurely, often with poor results.
HITL gates are not a workaround for insufficient AI capability. They are a structural component of robust multi-agent design, specifically at handoff points where the risk of compounding errors is highest or where the stakes of an error are unacceptable.
Identifying Where Human Gates Add Value
The useful heuristic for HITL gate placement is to identify the handoffs where a wrong context transfer would lead to consequential, hard-to-reverse actions. In a customer service pipeline, the handoff from a classification agent to a resolution agent that can issue refunds or cancel orders is a candidate. In a procurement workflow, the handoff from a vendor assessment agent to an agent that can send contract offers warrants a human review step. In a content pipeline, the handoff from a drafting agent to a publication agent might need compliance sign-off before the content goes live.
The key is precision: not every handoff needs a human gate, and adding gates everywhere defeats the purpose of automation. The goal is identifying the specific transitions where human review adds information that the system doesn’t reliably have — judgment about business context, approval authority, regulatory compliance — and placing gates there specifically.
Designing Gates That Don’t Break Flow
Poorly designed human gates create their own problems. If a gate requires a human to review a complex technical payload that they can’t meaningfully evaluate in under two minutes, the gate becomes a rubber stamp — it adds latency without adding judgment. Good gate design presents the reviewing human with exactly the information they need to make the relevant decision, in language they understand, with a clear description of what happens in each branch.
This means the handoff contract for a human-gated step includes a human-readable summary of the current state, the proposed next action, and the specific decision being requested — in addition to the machine-readable payload for the downstream agent. Designing both representations is more work upfront, but it’s what separates gates that function as genuine quality controls from gates that are security theater.
Cross-Team Governance: Who Actually Owns the Handoff?
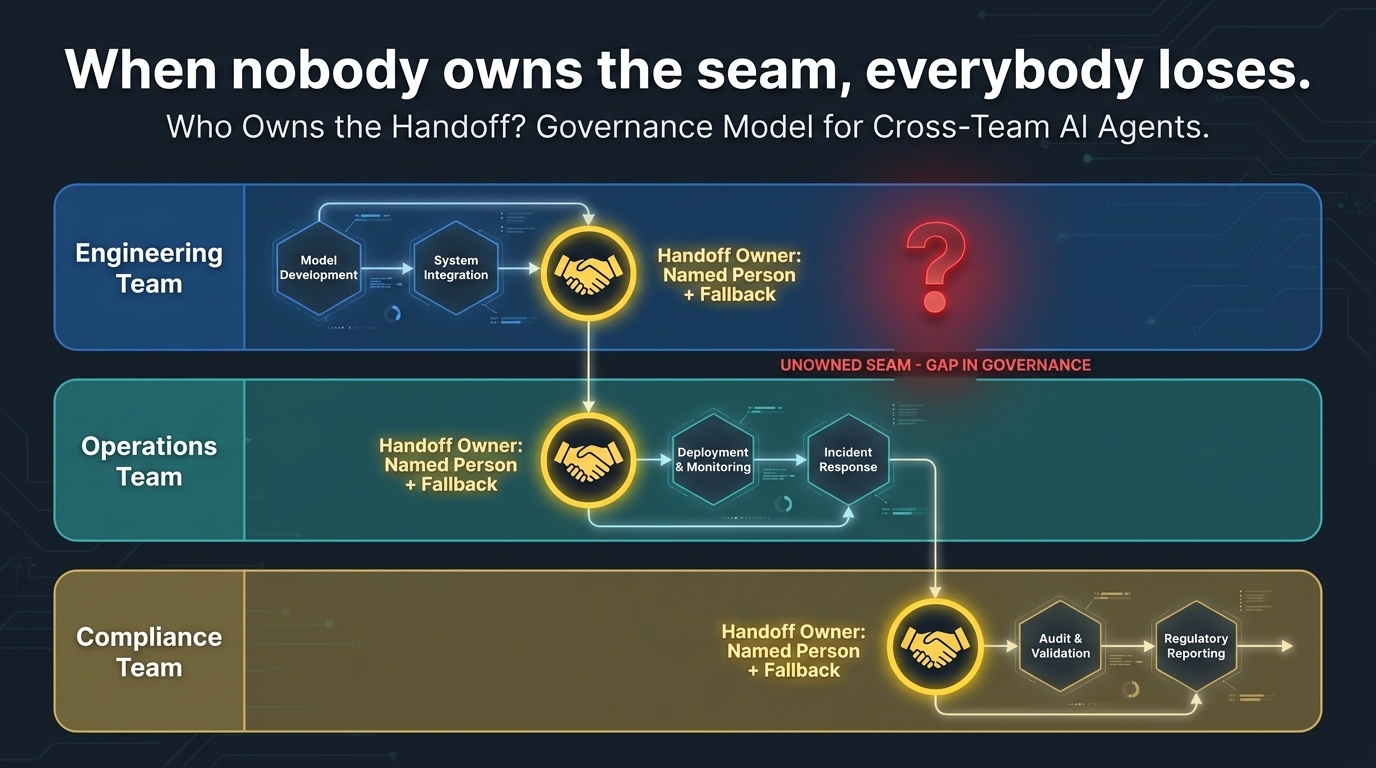
The most technically sophisticated handoff infrastructure fails if the organizational question isn’t answered: who is responsible for this handoff when it breaks?
In most enterprises, AI agents are built and maintained by separate teams with separate backlogs, separate on-call rotations, and separate definitions of done. The agent that serves the sales team was built by one engineering group. The fulfillment agent was built by another. The handoff between them crosses an organizational boundary — and in most organizations, nobody has explicit ownership of that boundary.
The “No Man’s Land” Problem
When a handoff fails at 2am and the automated alerting fires, who pages? The team that owns Agent A will look at their logs, see that Agent A produced what it was supposed to produce, and reasonably conclude the problem is downstream. The team that owns Agent B will look at their logs, see that they received a malformed payload, and reasonably conclude the problem is upstream. Both are correct. Neither team has the mandate or the context to fix the interface between them. The incident sits unresolved while each team files a ticket pointing at the other.
This is not a hypothetical — it’s the modal experience of cross-team AI agent failure in enterprise environments, according to practitioners building and operating these systems. The organizational gap is as consequential as any technical gap, and it requires an organizational solution.
Handoff Ownership Models That Work
Three governance models have emerged in practice, each with different tradeoffs:
Downstream ownership: The team that receives the handoff owns the contract definition. They specify what they need, and the upstream team is responsible for producing it. This model works well when the receiving team has clear requirements and the upstream team has the capacity to adapt their outputs. It breaks down when the upstream team is constrained by what their underlying system can produce.
Platform team ownership: A dedicated orchestration or platform team owns all handoff interfaces as part of owning the overall workflow infrastructure. Individual agent teams implement to the platform’s specifications. This model scales well and provides consistent governance, but requires investment in a platform team with sufficient scope and authority to set and enforce standards.
Joint ownership with defined escalation: Both teams co-own the handoff contract, with documented escalation procedures when there’s a disagreement or failure. This is the most common model in practice and the hardest to make work well — it requires genuine cross-team collaboration and a shared definition of the handoff’s success criteria. When it works, it tends to produce the best handoff designs because both teams’ knowledge of their respective systems informs the contract.
Regardless of the model chosen, the key requirement is that ownership is named and documented, not assumed. Every handoff in a production multi-agent system should have an entry in a runbook that identifies the owning team(s), the escalation path for failures, the monitoring alerts that cover it, and the version history of its contract.
Agent Sprawl and Governance Debt
A related organizational problem is agent sprawl: as individual teams experiment with and deploy AI agents, the number of agents in a given enterprise can grow faster than the organization’s ability to govern them. Each new agent creates new potential handoff points, and without a catalog of what agents exist, what they do, and how they connect, it becomes impossible to reason about the system as a whole.
Teams that are ahead of this problem maintain an agent registry: a living document or system that catalogs every agent in production, its owning team, its capabilities (ideally in a format compatible with A2A capability tags), its handoff interfaces, and its current health status. This registry becomes essential for impact analysis when a change is proposed to any component — you can assess which downstream agents might be affected before making the change, rather than discovering after deployment.
Patterns That Hold in Production: Engineering for Handoff Resilience
Synthesizing what works across production deployments, several concrete patterns emerge that reliably improve handoff resilience. These are not theoretical recommendations — they are drawn from the operational experience of engineering teams that have iterated through failures and converged on what holds.
Pattern 1: Schema-First Design
Define handoff schemas before writing agent code, not after. Start with the question “what does the receiving agent need?” and work backwards to define the producing agent’s output requirements. This inversion — designing the interface before the implementation — is a habit from API design that translates directly to agent handoff engineering. It tends to surface requirement gaps and capability mismatches early, when they’re cheap to address, rather than late, when they’re embedded in production code.
Pattern 2: Fail Fast at the Boundary
Validate handoff payloads at the receiving agent’s entry point, before the agent begins processing. Reject malformed payloads explicitly and route them to a defined handler, rather than allowing the agent to reason over incomplete or incorrect inputs. The short-term cost is higher visible error rates. The long-term benefit is that failures are surfaced at their source rather than propagating silently through the pipeline.
Pattern 3: Idempotent Handoffs
Design handoffs so they can be replayed without side effects. If a handoff payload is delivered twice — due to network retry logic, a system restart, or manual reprocessing — the receiving agent should produce the same outcome both times, and the state of the system should be consistent. This requires agents to check for duplicate correlation IDs and handle them gracefully. It’s extra engineering work, but it eliminates an entire class of race condition and double-processing failures that otherwise appear mysteriously in production.
Pattern 4: Minimum Necessary Context
Pass the minimum context the receiving agent needs to complete its task, not the maximum available. This sounds counterintuitive — more context seems safer — but it produces better systems in practice. Large context payloads create noise that models have to filter through. They also create privacy and compliance exposure, since sensitive information from early workflow steps travels further than necessary. Specifying exactly which fields each handoff must contain, and excluding everything else, improves both agent performance and system hygiene.
Pattern 5: Test Handoffs Independently
Treat each handoff interface as a testable unit, not just the agents on either side of it. Write tests that verify: correct payloads are accepted and processed; malformed payloads are rejected with the right error; edge cases in payload values are handled correctly; and schema version mismatches are detected. These tests should run in CI/CD alongside agent unit tests, so schema changes by either team trigger integration checks before reaching production.
Pattern 6: Introduce Fallback Agents
For critical workflow paths, define fallback handling for when a primary receiving agent is unavailable or returns an error. This might be a simplified version of the agent that handles common cases with reduced capability, or a human escalation path with a pre-formatted request. The key is that the fallback is defined in the handoff contract and triggered automatically, not discovered by the on-call engineer at 3am.
The Cross-Team Communication Problem Nobody Talks About
Technical architecture and protocol adoption address the machine-side of handoffs. There’s a corresponding human-side problem that receives far less attention: the communication patterns between the teams whose agents are connected by handoffs.
When teams are building in silos, handoff contracts tend to drift. Team A’s agent gets a model update that changes its output format slightly. Team B’s agent gets a new capability that requires an additional field in the incoming payload. Neither change is communicated proactively because neither team thinks of the interface as a shared artifact they’re responsible for maintaining together. The contract decays between the two teams’ separate roadmaps, and the failures that follow look like technical problems but are really coordination failures.
Shared Interface Review Processes
The most effective mitigation is treating handoff contract changes as a shared review process, similar to how API teams handle breaking changes for external consumers. When either team proposes a change to the handoff schema, the change is reviewed jointly, given a version increment, and deployed with appropriate lead time for the other team to adapt. This doesn’t require heavy process — a shared Slack channel and a brief async review is sufficient for most changes. What matters is the habit of treating the interface as jointly owned.
Some organizations formalize this with a lightweight “handoff review board” — a standing meeting or async review process where cross-team handoff changes are evaluated for compatibility. This sounds like more process than most engineering teams want, and it probably is for small organizations. But for enterprises running dozens of interconnected agents across multiple teams, the governance overhead is small compared to the cost of silent interface regressions in production.
Documentation as a Living Artifact
The other underrated practice is maintaining current documentation of every production handoff — not as a one-time specification document but as a living artifact that reflects the current state of the interface. This documentation should be co-located with the agent code, version-controlled, and linked from the observability dashboards so that anyone debugging a handoff failure can immediately access the current spec and the change history.
Teams that treat handoff documentation as a maintenance burden tend to let it fall out of date. Teams that treat it as an operational tool — something they actually use when things go wrong — tend to keep it current because the alternative (debugging without it) is worse.
Building Handoffs That Hold: A Practical Starting Point
If you’re operating multi-agent systems today and looking for a tractable entry point into improving handoff reliability, the most impactful interventions are not the most technically complex. They are the most foundational.
Start by auditing your existing handoffs. For each transition between agents, ask: Is there a documented contract specifying what passes across this boundary? Is it versioned? Is ownership assigned? Is it instrumented in your observability stack? Is there a defined failure path? Most engineering teams doing this audit for the first time discover that the answer to most of these questions is no, and that the handoffs they thought were solid are actually held together by convention and hope.
From that audit, triage by risk: which handoffs carry the highest consequence if they fail silently? Start there. Define contracts. Add runtime validation. Instrument spans. Assign owners. That’s a manageable sprint’s worth of work, and it produces a disproportionate improvement in system reliability — because handoffs, not model capability, are where production multi-agent systems fail.
The longer arc of this work is building a culture where handoffs are treated as first-class engineering artifacts: designed before implementation, tested independently, monitored continuously, and maintained as shared interfaces between teams. That cultural shift is harder than any technical change. But it’s what separates organizations that successfully scale multi-agent AI across teams from those that accumulate an increasingly fragile patchwork of agents that nobody fully trusts.
Conclusion: The Interface Is the System
The most important reframe for teams building multi-agent AI in 2026 is this: the system is not the collection of agents. The system is the collection of agents plus their interfaces. Optimizing the agents without optimizing the interfaces is like building a world-class relay team and then ignoring the baton handoffs. The race is won or lost at the exchange zone.
Multi-agent AI’s >50% production failure rate is not a verdict on the technology. It’s a verdict on how the technology has been deployed — with tremendous investment in the agents themselves and remarkably little investment in the transitions between them. The teams that are outperforming on reliability in 2026 have not necessarily built better models. They have built better seams.
“Most ‘agent failures’ are orchestration and context-transfer issues at handoff points, not model capability failures.” — Enterprise AI operations practitioners, 2026
The path forward is clear, if not always easy: define handoff contracts before writing agent code. Validate payloads at boundaries. Build queryable memory instead of compressing context. Choose orchestration topology based on workflow requirements. Instrument every handoff as an observable span. Assign explicit ownership to every interface. Test handoffs as independently deployable units.
None of these are exotic. All of them require sustained engineering discipline. Most of them require organizational alignment that cuts across team boundaries. And all of them, applied consistently, produce multi-agent systems that behave reliably when deployed into the entropy of production — which is, ultimately, the only environment that matters.
Actionable Takeaways
- Audit every handoff in your current multi-agent stack and identify which ones lack documented contracts, versioning, or ownership assignments.
- Define handoff contracts schema-first, starting with the receiving agent’s input requirements and working backwards to the producing agent’s output spec.
- Add runtime payload validation at each handoff entry point to fail fast on malformed inputs rather than letting errors compound downstream.
- Implement span-level distributed tracing across your agent workflow so that handoff transitions are inspectable as distinct observable events.
- Replace rolling text summaries with queryable memory for task state and tool outputs that need to persist across multiple agent steps.
- Assign named owners to every cross-team handoff interface, with documented escalation paths for failures.
- Version your handoff schemas and treat breaking changes as requiring joint review between sending and receiving teams.
- Choose orchestration topology (supervisor vs. swarm) based on whether your workflow is primarily parallel/independent or sequential/stateful.