


By mid-2026, most enterprise operations teams have at least one AI agent running in a live workflow. Some have dozens. A handful have hundreds, operating across procurement, finance, customer service, HR, and IT — each one capable of reading data, calling APIs, sending communications, and taking actions without human sign-off on every step.
And most of those agents were deployed before anyone wrote down who was responsible for them.
That oversight — not the models themselves, not the data pipelines, not the tooling budget — is the defining risk of enterprise AI in 2026. Gartner now projects that by 2027, 40% of enterprises will demote or decommission autonomous AI agents due to governance failures discovered after production incidents. Not because the agents were poorly built. Because no one built the infrastructure around them to keep them accountable.
This article is not about whether to deploy AI agents. That decision has largely been made across the market. It is about what has to exist around those agents — the policies, the identity controls, the escalation logic, the audit infrastructure, the operating model — so that when something goes wrong (and it will), you have a framework to catch it, contain it, and explain it. And so that the agents that are working well can be trusted, expanded, and measured.
Governance is not a compliance checkbox. It is the operating infrastructure that determines whether AI agents stay in production or get shut down. Here is how to build it.
The Adoption-Governance Mismatch That Is Defining 2026
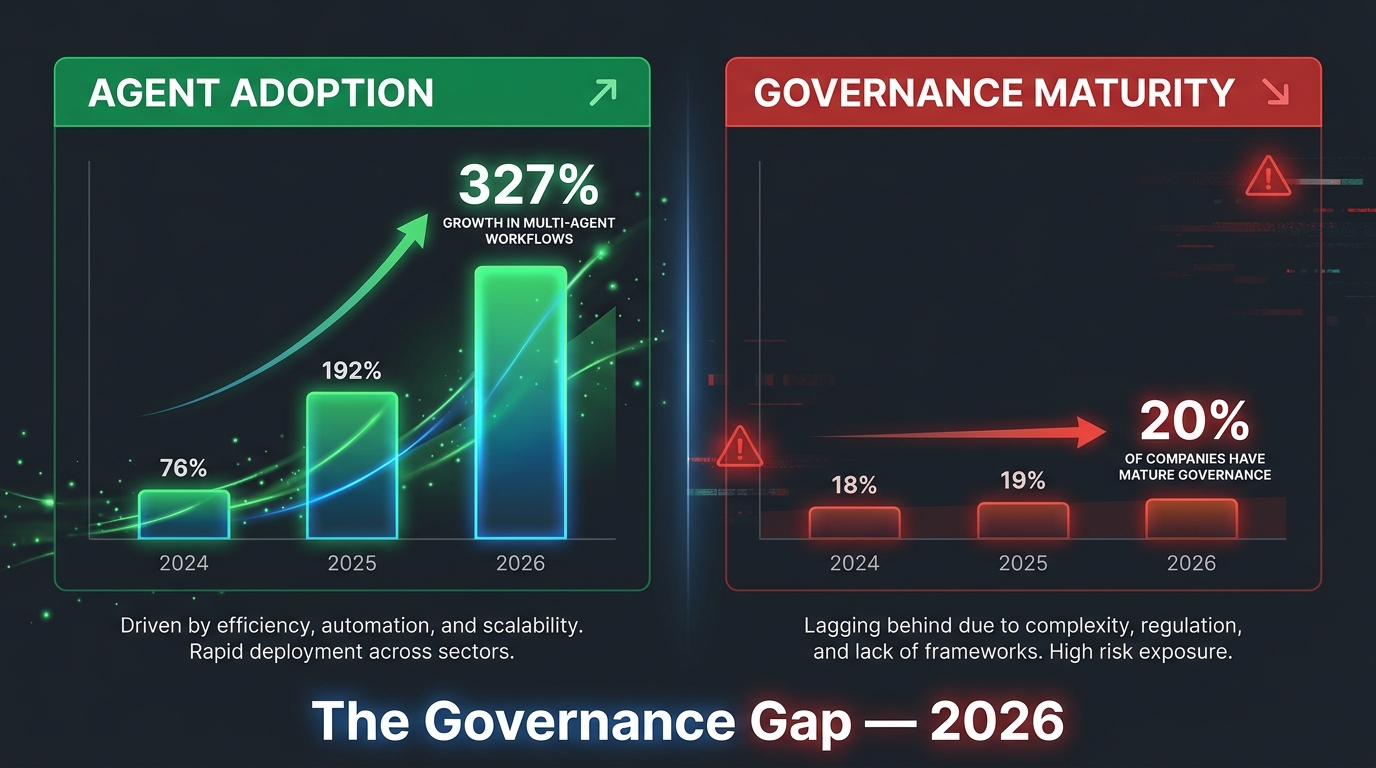
Databricks’ State of AI Agents 2026 report — drawn from anonymized telemetry across more than 20,000 enterprise customers — puts the adoption story in sharp relief. Multi-agent workflows grew 327% in a four-month period following the release of new orchestration capabilities. That is not a pilot trend. That is deployment at velocity.
But the same report finds that only 19% of audited organizations have deployed agents at scale. The rest are in the experiment-to-production gap — agents running in workflows, touching real systems, making real decisions, without the infrastructure to govern them reliably.
What “Governance” Actually Means for Agents
The term has been stretched thin across the AI industry. In the context of AI agents specifically, governance means something much more concrete than a policy document or an ethics committee. It means:
- Identity: Every agent has a unique, verifiable identity tied to an owner, a purpose, and a set of scoped permissions.
- Access control: Agents operate under least-privilege principles — they can access only the systems and data they need for their specific function, and nothing more.
- Decision accountability: Every autonomous decision has a named human accountable for its outcomes, even when no human was in the decision loop at the moment it was made.
- Escalation logic: Risk thresholds are defined in advance, and agents know when to pause and route to a human rather than proceed autonomously.
- Auditability: Every action an agent takes is logged with enough context to reconstruct what happened, why, and whether it was within policy.
- Lifecycle management: Agents are registered, reviewed, updated, and decommissioned in an orderly way — not abandoned in production indefinitely.
Most organizations in 2026 have some of these elements in place for some of their agents. Very few have all of them, consistently, across the full agent population. That gap is exactly where incidents originate.
The Maturity Statistics Are Stark
Independent surveys of enterprise operations and technology leaders in early 2026 found that only approximately 20% of companies have mature AI agent governance. Roughly 65% of organizations now use generative AI regularly in at least one business function — yet the governance infrastructure to manage autonomous agents at scale simply has not kept pace with deployment speed.
The consequences are not hypothetical. The Databricks data shows that companies using AI governance tools put 12 times more AI projects into production compared to those without structured governance. Organizations using systematic evaluation frameworks achieve nearly six times higher production success rates. Governance is not slowing things down. It is the thing that makes scale possible.
The Agent Identity Problem: You Cannot Govern What You Cannot See
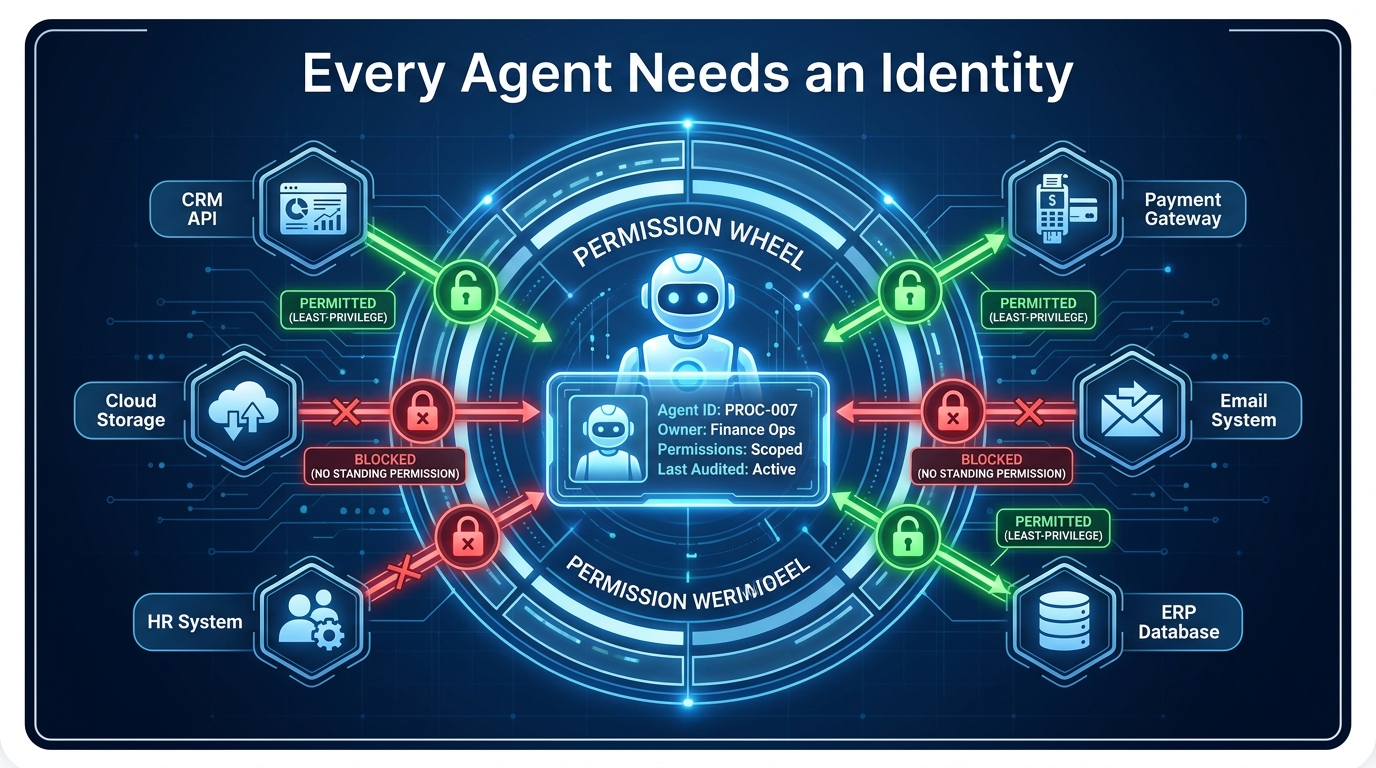
The most foundational governance failure in enterprise AI deployments right now is also the simplest: agents running without their own identity.
In most early deployments, AI agents authenticate to downstream systems using shared service accounts, user credentials, or static API keys belonging to a human operator. This was a shortcut that made sense in a proof-of-concept. It is an unacceptable risk in production. When an agent uses a shared credential, there is no way to distinguish its actions from those of any other system or person using the same credential. The audit trail is meaningless. The access cannot be scoped. If the agent is decommissioned, the credential persists, still valid, still usable.
What Agent Identity Actually Requires
Treating AI agents as first-class identities means giving each agent the same identity lifecycle that would apply to a human contractor or a privileged service account — with additional constraints specific to autonomous operation:
- Unique identity provisioning: Each agent gets its own credential set — ideally ephemeral tokens rather than standing credentials — that are tied to that agent’s specific purpose and owner.
- Named sponsorship: Every agent identity has a human or team designated as its owner and accountable sponsor. If that person leaves the organization, the agent identity is reviewed and re-assigned or decommissioned.
- Least-privilege scoping: The agent’s permissions are defined by what it needs to perform its function, not by what the deploying engineer happened to have access to. If a procurement agent needs to read vendor records but not modify payment terms, those permissions are explicitly separated.
- Lifecycle tracking: Every agent identity is registered in a central inventory with creation date, owner, purpose, systems accessed, and last audit date. Agents that are no longer active are formally deprovisioned.
The Over-Privilege Problem
Enterprise security research in 2026 found that organizations with excessive AI agent permissions reported 4.5 times more security incidents than those with least-privilege deployments. The risk is not abstract. An over-privileged agent — one that has write access to financial systems, customer records, and communication platforms because the deploying engineer used a broad service account — has a blast radius that extends across the organization if it behaves unexpectedly, is compromised, or is manipulated by a prompt injection attack.
The identity problem is also a visibility problem. You cannot build governance around agents you cannot enumerate. Before implementing any other control, organizations need a complete inventory of every agent currently running in production — what it is, what it does, what it has access to, and who owns it. In most enterprises, that inventory does not currently exist.
Zero-Standing Privilege as the Target State
Leading security teams are moving toward zero-standing-privilege models for AI agents — meaning that agents hold no persistent permissions, and instead request and receive time-bound, scoped credentials at the start of each task. This dramatically reduces the blast radius of any individual agent compromise and creates a natural audit trail of exactly what the agent accessed and when. It is more complex to implement than shared static credentials, but it is increasingly the only architecture that makes compliance and auditability tractable at scale.
Building the RACI for Autonomous Decisions
Ask most operations teams who is responsible for the decisions their AI agents make, and you will get one of three answers: the engineer who built it, the vendor who sold the platform, or a blank look. None of those answers is sufficient — especially when the decision causes a problem.
The shift happening across governance-mature organizations in 2026 is a move from component-level ownership (“the ML team owns the model”) to decision-lifecycle ownership. The question is not who built the system. It is who is accountable for each stage of an autonomous decision — and what their responsibility entails.
Mapping the Decision Lifecycle
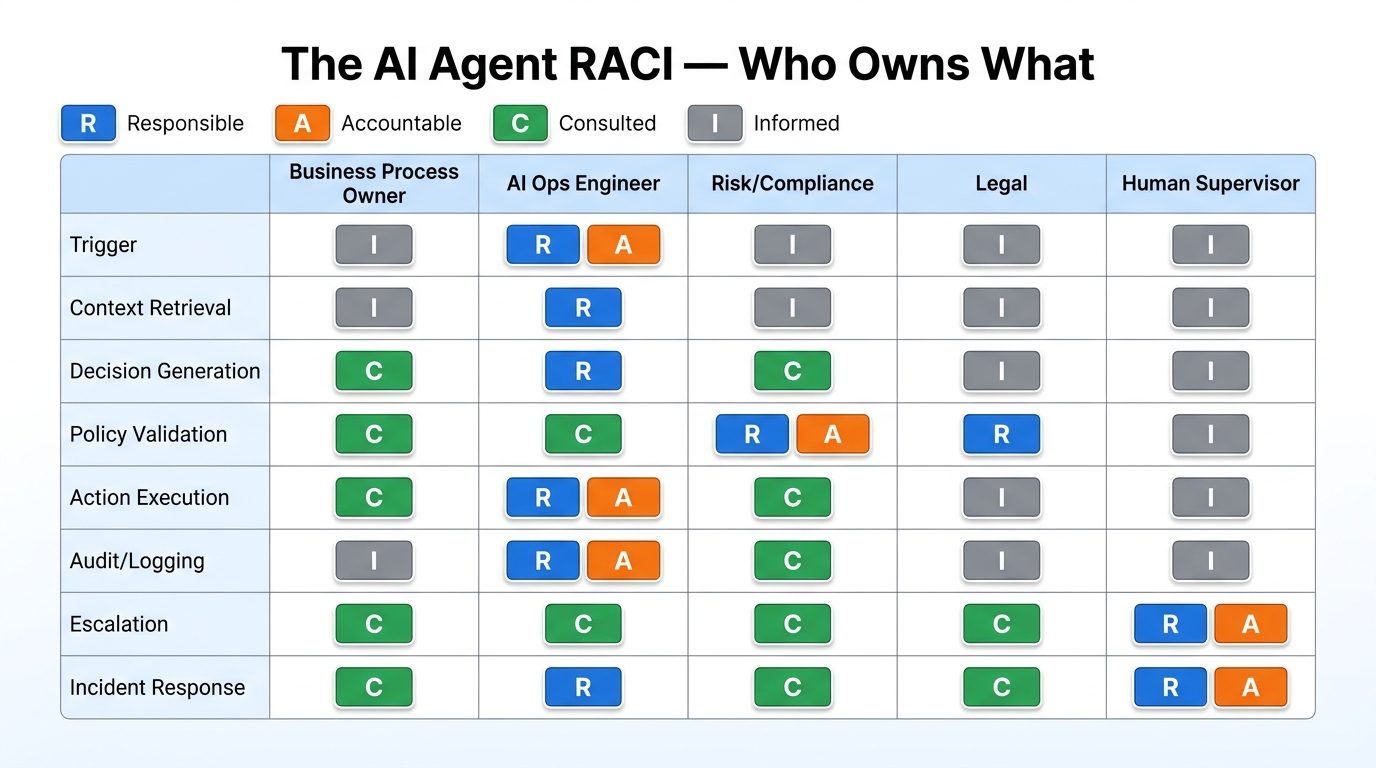
An AI agent making a decision moves through a series of stages, each of which requires clear ownership:
- Trigger: What event or condition activates the agent? Business process owners define acceptable triggers and are accountable for out-of-policy activations.
- Context retrieval: What data does the agent pull to inform its decision? Data governance teams are responsible for ensuring data quality, sensitivity classification, and access appropriateness.
- Decision generation: The model produces an output. AI/ML engineers are responsible for model behavior within defined parameters.
- Policy validation: The proposed action is checked against business rules and governance policies before execution. Risk and compliance teams define the policies; AI Ops teams implement the validation layer.
- Action execution: The agent takes the action — sends the message, creates the record, triggers the payment. Business process owners are accountable for what gets executed.
- Logging and audit: Every action is recorded with full context. AI Ops or platform engineering is responsible for log completeness and retention.
- Escalation: When the agent reaches a decision boundary, it routes to a human. Human supervisors and process owners define escalation paths and are responsible for responding within SLA.
- Incident response: When something goes wrong, who does what? Security, risk, legal, and business leadership all have defined roles.
The RACI Shift That Changes Everything
The most important change in how governance-mature organizations structure their RACI is who holds the Accountable designation for autonomous decisions. In immature models, accountability is diffuse — spread across the engineering team, the vendor, and the business stakeholder. In mature models, the Business Process Owner is accountable for workflow outcomes, period. The fact that an AI agent executed the decision does not transfer accountability from the human owner of the process. This matters enormously when something goes wrong, because it means there is always a named individual whose responsibility it is to explain, remediate, and improve.
This is not punitive. It is structural. Business Process Owners who hold accountability for agent decisions are the people who ensure that agents are tuned, that escalation thresholds reflect real risk, and that governance policies are kept current. They are the ones who push back when an agent’s scope creeps beyond its original purpose. Without that named accountability, agents drift — their scope expands informally, their policies go stale, and the first anyone knows about it is when something breaks.
Escalation Thresholds: The Policy Layer Most Teams Skip
One of the most common failures in enterprise AI agent governance is treating human oversight as a binary: either the agent is fully autonomous, or a human approves every action. Neither extreme serves operational needs. The answer is a tiered escalation model — defined before deployment, encoded in policy, and enforced at the execution layer.
The goal is not maximum human oversight. The goal is appropriate human oversight — calibrated to the risk of the specific decision the agent is making at that moment.
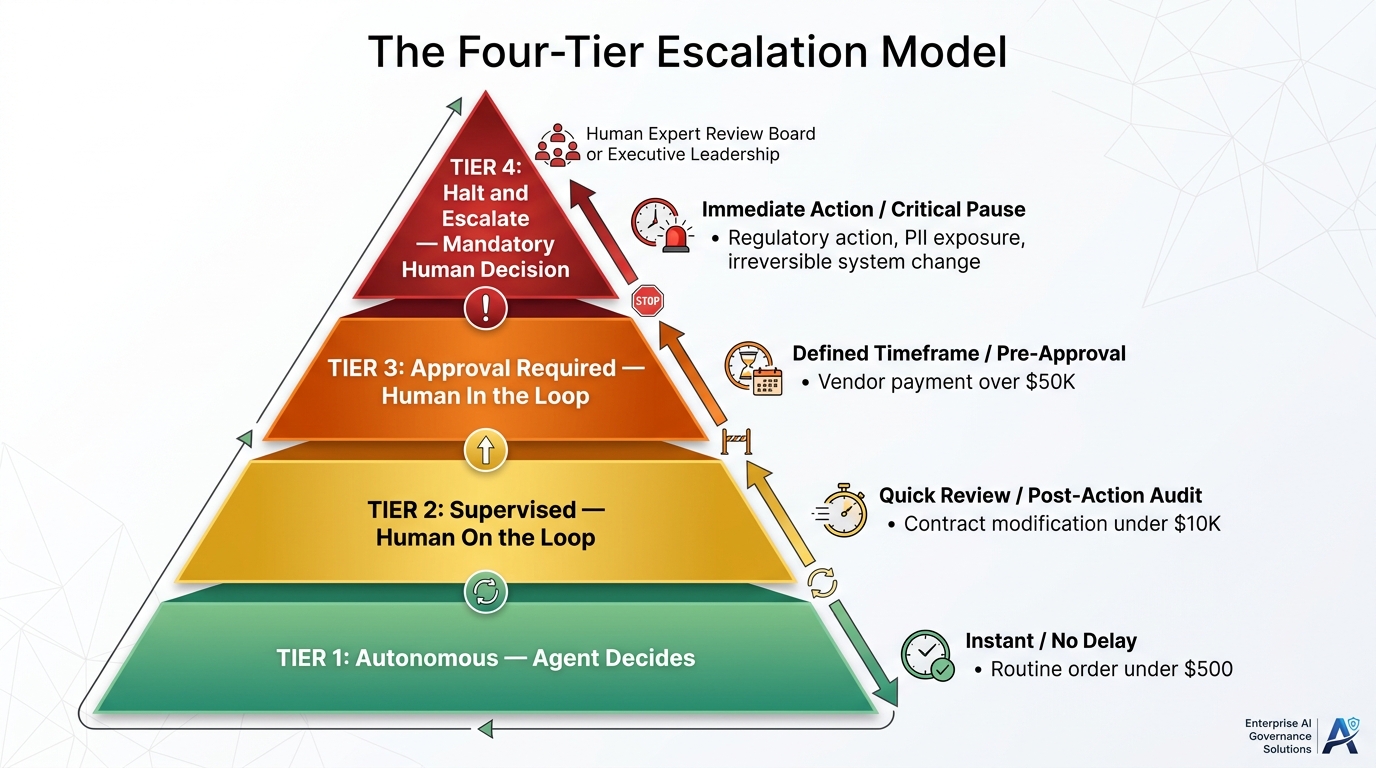
The Four-Tier Model
Governance-mature organizations are converging on a four-tier model that maps decision types to oversight requirements:
- Tier 1 — Autonomous: The agent decides and acts without human review. Reserved for low-risk, high-frequency, easily reversible decisions where the error cost is minimal. Example: routing a support ticket, applying a standard discount code, generating a draft document. Thresholds might include monetary limits below $500 and no PII modification.
- Tier 2 — Supervised (Human-on-the-Loop): The agent acts, but a human receives a notification and retains the ability to reverse the action within a defined window. The human does not approve before action — they review after. Example: contract amendment below a defined dollar threshold, customer escalation routing, vendor record update. Thresholds might span $500–$10,000 and low-sensitivity data.
- Tier 3 — Approval Required (Human-in-the-Loop): The agent pauses execution and waits for explicit human approval before proceeding. Reserved for moderate-to-high risk decisions or those above financial thresholds. Example: vendor payment above $50,000, customer refund above $5,000, external communication on a legally sensitive matter. SLA-bound approval windows are defined to prevent indefinite hangs.
- Tier 4 — Halt and Escalate: The agent stops entirely and escalates to a senior human decision-maker. Reserved for actions that are irreversible, legally significant, involve sensitive data exposure, or fall outside the agent’s defined scope. Example: any action touching PII at scale, regulatory filings, system-wide configuration changes, detection of a potential security incident.
The Policy Encoding Problem
Defining these tiers in a governance document is necessary but not sufficient. The policies have to be enforced at the execution layer — meaning the agent’s runtime environment has to check every proposed action against the escalation policy before allowing it to proceed. In organizations where escalation thresholds exist only in documentation, agents proceed autonomously because nothing in the technical stack enforces the pause. The policy gateway — the component that intercepts proposed actions and validates them against business rules before execution — is the missing piece in the majority of enterprise deployments.
Thresholds also need to be defined across multiple risk dimensions simultaneously, not just financial value. A $200 action that modifies 50,000 customer records is not a Tier 1 decision. Effective escalation policies combine monetary thresholds, data sensitivity classification, reversibility assessment, and regulatory scope — and the intersection of all four determines the actual tier.
Human-on-the-Loop vs. Human-in-the-Loop
The distinction matters operationally. Human-in-the-loop (HITL) means no action without human approval — it adds latency and cost but provides the strongest control. Human-on-the-loop (HOTL) means the agent acts but a human can observe and reverse — it preserves speed while maintaining accountability. The choice between them is not a philosophical preference; it is a function of reversibility. For decisions that can be cleanly undone, HOTL is usually appropriate and more operationally sustainable. For decisions that cannot be reversed — sent communications, executed payments, deleted records — HITL is the only defensible governance model.
Runtime Controls vs. Model-Level Controls: Why One Is Not Enough
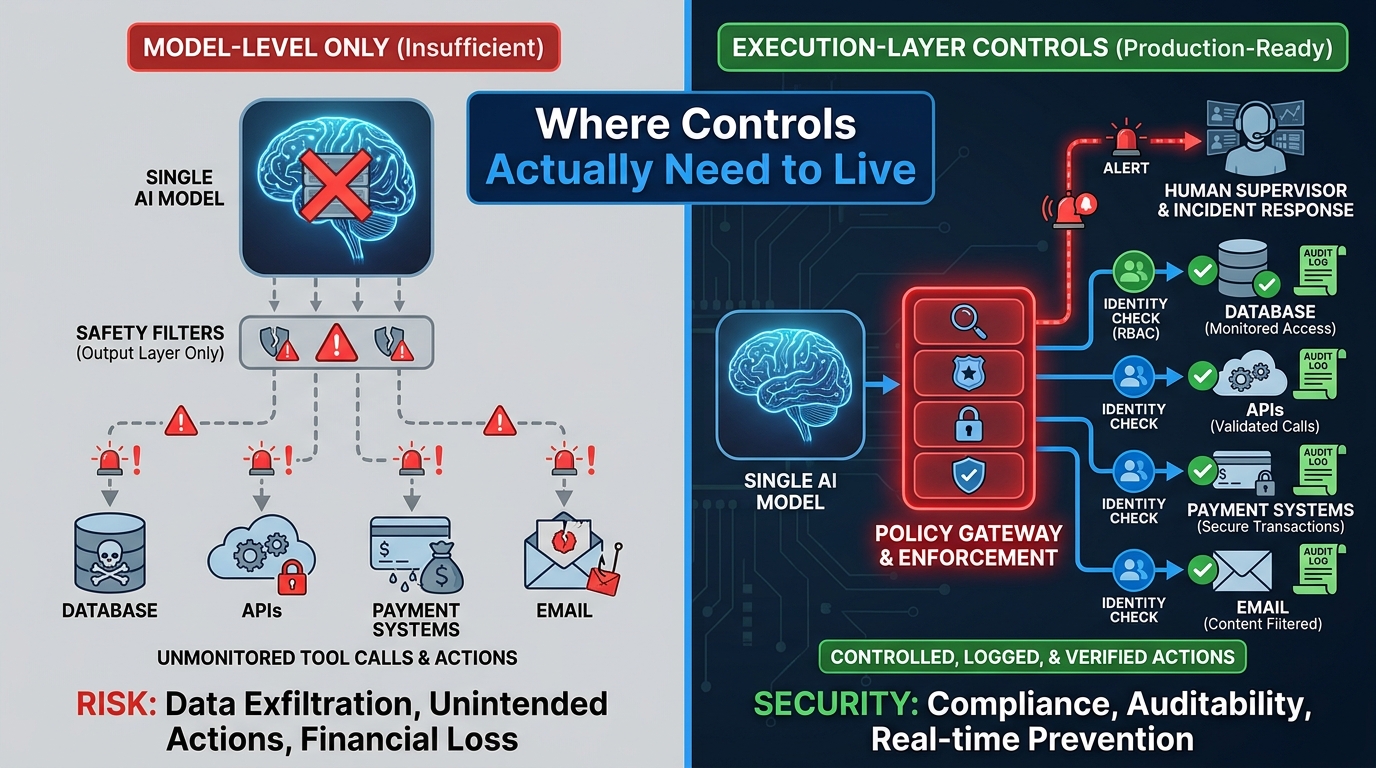
A common misconception in enterprise AI governance is that controlling the model — through system prompts, output filters, and fine-tuning — is sufficient to govern agent behavior. It is not, and the gap between model-level controls and execution-layer controls is where most serious governance failures occur.
Model-level controls shape what the agent says and intends to do. Execution-layer controls govern what the agent actually does when it calls tools, APIs, and external systems. These are different things, and treating the first as a substitute for the second leaves a substantial and largely invisible attack and failure surface.
What Model-Level Controls Actually Govern
System prompts, guardrails, and output filters work at the text/token level. They can:
- Constrain the language and format of agent outputs.
- Block certain types of responses (refusals, PII in plain text outputs).
- Shape the agent’s reasoning toward preferred approaches.
- Reduce the likelihood of off-topic or harmful text generation.
What they cannot do is prevent the agent from making an unauthorized API call, accessing a data store it was not intended to use, or executing an action that violates business policy — because those actions happen downstream of the model’s output, in the tool-call layer. The model can be perfectly compliant with its system prompt and still take a harmful action if the execution environment does not enforce boundaries on what the model is allowed to call.
The Execution Layer: Where Governance Has to Live
The execution-layer control stack for a production AI agent typically needs to include:
- A policy gateway: An intercept layer that evaluates every tool call or API request against defined business rules before allowing execution. If the agent attempts to call a payment API for an amount above the defined threshold, the gateway blocks the call and routes it for human approval — regardless of what the model intended.
- Per-action audit logging: Every tool call, API request, data read, and system action is logged with a timestamp, the agent’s identity, the action taken, the inputs provided, and the outcome. This is not optional. It is the audit trail that compliance, legal, and security will require when they come asking.
- Identity verification at the tool layer: Every downstream system the agent calls should verify that the calling identity (the agent’s credential) is authorized to make that specific request. Not “is this a valid credential” but “is this credential authorized to perform this action on this resource at this time.”
- Behavioral anomaly detection: Baseline the agent’s typical tool-call patterns — volume, targets, timing, sequence. Alert when behavior deviates significantly from baseline. This is how you detect prompt injection attacks, model drift, and unexpected scope expansion before they cause harm.
The Prompt Injection Risk
Execution-layer controls are particularly critical for defending against prompt injection — attacks where malicious content in data the agent reads attempts to hijack the agent’s behavior. A customer support agent that reads ticket text, a procurement agent that processes vendor invoices, a research agent that browses the web — all of these are surfaces where injected instructions can attempt to override the agent’s intended behavior. Model-level controls alone cannot reliably defend against this. Only execution-layer policy enforcement — where the gateway validates that the action being requested is within policy, regardless of how the agent was instructed to request it — provides consistent protection.
Multi-Agent Systems and the Trust Boundary Problem
Single-agent governance is tractable. Multi-agent governance — where orchestrator agents delegate tasks to sub-agents, agents collaborate in parallel workflows, and agent outputs become inputs to other agents — introduces a class of problems that do not exist in single-agent architectures.
The core issue is trust propagation. In a multi-agent system, an orchestrator agent may have high-privilege access and broad permissions. When it delegates a task to a sub-agent, how much of that privilege travels with the delegation? And when the sub-agent completes its task and passes results back to the orchestrator, how does the orchestrator know the results have not been manipulated in transit?
Inter-Agent Handoffs as Trust Boundaries
Governance-mature organizations are learning to treat every inter-agent handoff as a trust boundary — the same way they would treat a call from an external system. This means:
- Delegated permissions are scoped, not inherited: When an orchestrator delegates to a sub-agent, the sub-agent receives only the specific permissions needed for its delegated task — not the full permission set of the orchestrator. Privilege does not cascade down the delegation chain.
- Agent-to-agent communication is authenticated: Sub-agents verify that instructions come from an authorized orchestrator with a recognized identity, not an arbitrary source claiming to be one.
- Output validation at handoffs: Results passed between agents are validated against expected schemas and value ranges before being accepted. Anomalous outputs are flagged for review rather than automatically forwarded.
- End-to-end trace context: Multi-agent workflows maintain a trace ID that links all agent actions within a single workflow execution — so the full decision chain can be reconstructed from the audit log as a coherent sequence, not a collection of disconnected events across multiple agents.
The Governance Scaling Problem
As agent architectures grow more complex, governance risk scales with agent count. A three-agent workflow has a handful of trust boundaries. A fifty-agent system has hundreds — and each one is a potential failure point, privilege escalation path, or audit gap if controls are not explicitly applied. This is not a reason to avoid multi-agent architectures. It is a reason to design governance as a centralized control plane — a policy enforcement and observability layer that spans the entire agent system — rather than as per-agent controls that have to be individually maintained.
Audit Trails and Observability at the Execution Layer
If your agents cannot explain what they did, you cannot govern them. Audit trails are not a nice-to-have feature or a future-phase deliverable. They are the foundation of governance, the evidence base for compliance, and the primary tool for diagnosing failures when they occur.
The challenge with AI agent observability in 2026 is that traditional application logging — request/response logs, error traces — is not sufficient. Agent actions have context that standard logs do not capture: the reasoning state that led to the action, the data retrieved to inform the decision, the policy checks that were or were not applied, and the relationship between this action and the broader workflow it was part of.
What a Sufficient Audit Trail Actually Contains
Enterprise security and compliance teams reviewing AI agent audit trails in 2026 are converging on a minimum data set for each logged action:
- Agent identity: Which agent took the action, tied to the agent’s registry entry and current permission set.
- Workflow trace ID: The unique identifier for the workflow execution, allowing all related actions to be grouped and reconstructed in sequence.
- Action type and target: What the agent did, and to what system or data.
- Input context: What data or instructions the agent received that led to this action — sanitized to remove sensitive content where required by privacy policy.
- Policy validation result: Whether the action was checked against governance policy, the result of that check, and which policy rule applied.
- Human oversight events: If the action was escalated, who received the escalation, when they responded, and what they decided.
- Outcome: What the action resulted in — success, failure, partial execution — and any downstream effects.
- Timestamp and retention metadata: When the action occurred and the applicable retention period for compliance purposes.
OpenTelemetry and the Observability Stack
Many enterprise AI teams are extending OpenTelemetry (OTel) — the open-source observability standard widely used in cloud-native application monitoring — to cover AI agent traces. This allows agent activity to be captured in the same observability infrastructure that already monitors application performance, making it easier to correlate agent behavior with system-level events and to surface anomalies through existing alerting pipelines.
The practical challenge is that most AI orchestration frameworks do not emit OTel-compatible traces by default. Instrumentation typically requires custom spans around tool-call layers, which adds engineering effort. For most organizations, the investment is justified by the reduction in incident diagnosis time — the difference between knowing in minutes what a misbehaving agent did, versus spending days reconstructing events from scattered logs.
Behavioral Baseline and Drift Detection
Beyond individual action logging, effective observability for AI agents includes behavioral monitoring at the aggregate level. Baseline metrics — average number of tool calls per session, typical API targets, frequency distribution of action types, token consumption per workflow — establish what “normal” looks like for each agent. Deviations from baseline trigger alerts that warrant human review.
Behavioral drift is one of the earliest signals of several failure modes: model updates that change behavior unexpectedly, prompt injection attacks that redirect agent activity, gradual scope expansion as agents are informally given new tasks without governance review, and performance degradation as the data environment shifts. Catching drift early is almost always cheaper than remediating the damage after an incident.
Regulatory Alignment: EU AI Act, NIST, and ISO 42001
AI agent governance in 2026 is no longer just an internal operational concern. For enterprises operating in the EU, handling regulated data, or subject to industry-specific compliance requirements, the governance framework has to be designed with regulatory alignment built in — not retrofitted after the fact.
The EU AI Act and Autonomous Decision Systems
The EU AI Act’s risk-based classification framework has direct implications for AI agents used in business operations. Agents that make or substantially influence decisions in high-risk categories — including employment decisions, credit and insurance assessments, access to essential services, and law enforcement applications — face mandatory requirements for human oversight, transparency, accuracy standards, and technical documentation. The Act’s requirements are not aspirational. Non-compliance exposes organizations to fines of up to €30 million or 6% of global annual turnover, whichever is higher.
For most business operations teams, the key requirement is operationalizing the Act’s human oversight provisions — which map directly to the escalation threshold framework described above. Agents operating in high-risk categories need documented Tier 3 or Tier 4 escalation policies for decisions that substantially affect individuals, plus audit trails that demonstrate those policies were enforced.
NIST AI RMF and the Governance Architecture
The NIST AI Risk Management Framework provides the most operationally detailed guidance for enterprise AI governance, organized around four functions: Govern, Map, Measure, and Manage. For AI agents specifically, the Govern function — establishing organizational roles, policies, and processes for AI risk management — is the prerequisite that makes the other three functions tractable.
Organizations that have mapped their agent governance frameworks to the NIST AI RMF report two advantages beyond compliance: clearer internal communication about AI risk, because everyone is using the same vocabulary, and faster response to audit requests, because the framework provides a standard structure for documentation that regulators and auditors recognize.
ISO/IEC 42001 as the Management System Standard
ISO/IEC 42001, the AI management system standard published in late 2023 and increasingly referenced in contracts and procurement requirements through 2026, provides a certification-ready framework for AI governance that aligns closely with ISO 27001 (information security management) and ISO 9001 (quality management). For enterprises already operating under these standards, 42001 provides an extension path that integrates AI governance into existing management system infrastructure rather than requiring an entirely new framework.
The practical overlap with agent governance is strongest in 42001’s clauses covering AI system objectives (mapping to business purpose), risk treatment (mapping to escalation thresholds and access controls), and monitoring and measurement (mapping to audit trails and observability).
The Governance Maturity Model: From Ad Hoc to Embedded
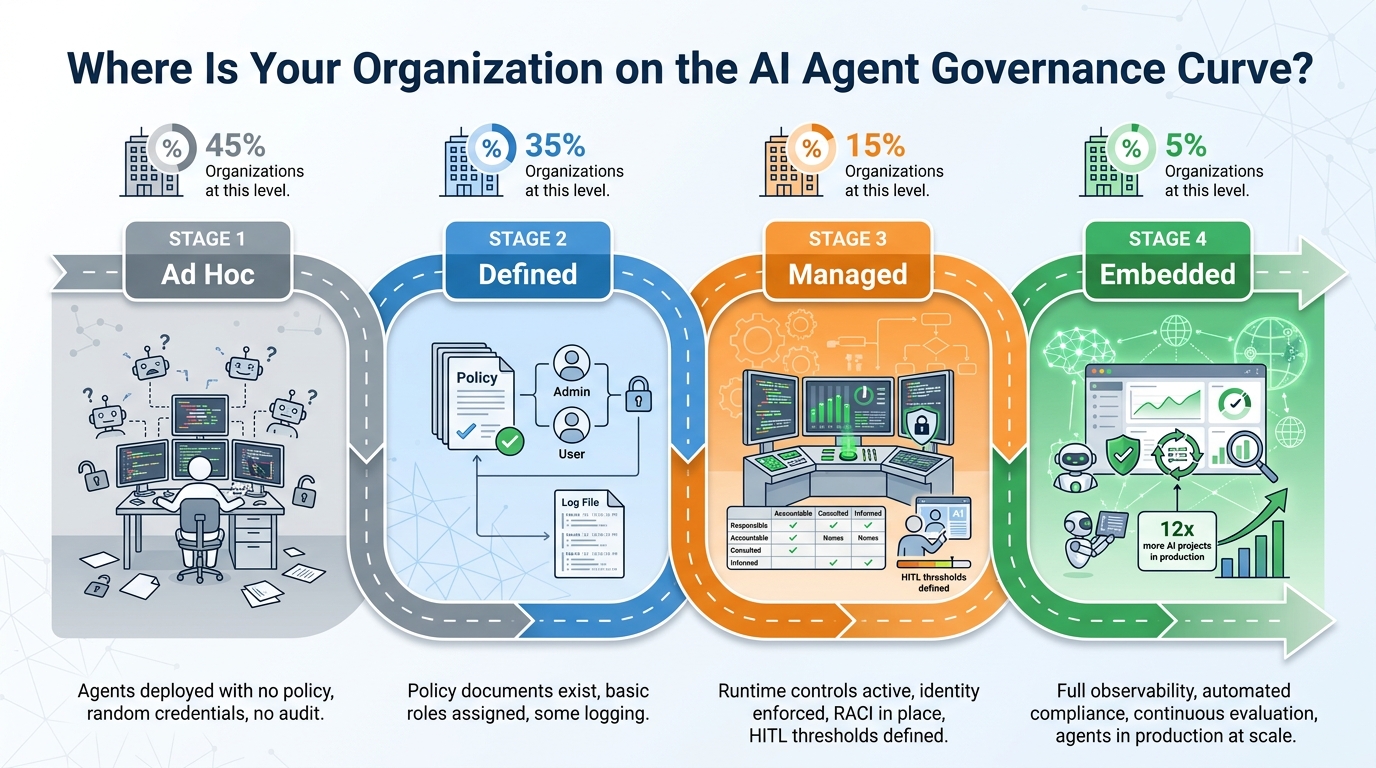
Not every organization needs to move to maximum governance maturity immediately — and trying to implement a full governance stack across an immature agent program simultaneously often fails because the organizational change required is too large. Understanding where your organization currently sits on the maturity curve is the prerequisite for planning a realistic path forward.
Stage 1: Ad Hoc
At this stage, agents are deployed by individual teams without central oversight. Credentials are shared, permissions are broad, ownership is informal, and there is no systematic audit trail. Most organizations discovering AI governance for the first time are here for at least some of their agent population. The primary risk at this stage is the unknown blast radius — because agent inventories are incomplete, no one knows the full extent of what could go wrong if a single agent misbehaves. Estimated at approximately 45% of organizations with agent deployments in 2026.
Stage 2: Defined
Governance policies exist in documentation. Basic roles are assigned. Some agents have individual identities. Logging exists but may be inconsistent. This stage represents real progress — the organizational intent to govern is present — but the gap between documented policy and enforced policy is large. Policies defined in documents that are not encoded in technical controls are not actually governing agent behavior. Approximately 35% of organizations fall here.
Stage 3: Managed
Runtime controls are active. Identity is enforced for most agents. A RACI is in place and maintained. Escalation thresholds are defined and encoded in policy gateways. Audit trails are consistent. Human oversight requirements are documented and enforced. This is where governance becomes operational rather than aspirational — and where the production success rate improvement begins to materialize. Approximately 15% of organizations are here.
Stage 4: Embedded
Governance is built into the agent development and deployment lifecycle from the start, not applied after deployment. New agents cannot go to production without passing governance review. Policy updates propagate automatically to running agents. Behavioral monitoring is continuous and automated. Governance metrics are part of operational reporting. This is where the 12x production advantage measured by Databricks is achieved — and where organizations can scale agent programs with confidence. Currently approximately 5% of organizations, and the competitive moat is significant. The organizations at Stage 4 are deploying agents faster, more reliably, and with lower incident rates than everyone else, precisely because governance enables speed rather than constraining it.
The Practical Path Between Stages
The move from Ad Hoc to Defined is primarily an organizational exercise: appoint ownership, write policies, build the agent inventory. The move from Defined to Managed is primarily a technical exercise: implement identity, deploy the policy gateway, build audit logging. The move from Managed to Embedded is primarily a process integration exercise: encode governance into CI/CD, make it part of the deployment checklist, wire monitoring into operational dashboards. Each transition has a clear primary driver and can be planned sequentially, which makes the overall journey tractable even when the full destination seems distant.
The Cost of Getting It Wrong: What Governance Failures Actually Look Like
Gartner’s prediction that 40% of enterprises will decommission or demote autonomous AI agents by 2027 due to governance failures is not a commentary on the technology. It is a commentary on the gap between deployment velocity and governance readiness. Understanding what governance failures actually look like in practice — not hypothetically, but as patterns already emerging in production environments — sharpens the business case for investment.
The Scope Creep Failure
An agent is deployed for a specific purpose — processing expense reports, routing customer inquiries, monitoring inventory. Over time, the team that owns it informally extends its scope: “Can it also handle refund requests?” “Let’s have it respond to vendor inquiries too.” Each extension seems small. Collectively, they transform an agent with a narrow, governed purpose into an agent with broad, ungoverned reach. Without a governance process that requires formal scope review for changes, no one has re-evaluated the escalation thresholds, updated the permission set, or assessed the new risk surface. The scope creep failure typically surfaces not when the agent is doing something new, but when the new thing goes wrong and no one can explain why the agent was authorized to do it.
The Abandoned Agent Failure
Agents are deployed during a project, the project ends, the team moves on, and the agent keeps running. Its credentials remain active. Its access to downstream systems persists. The model underpinning it may be updated by the vendor, changing its behavior without anyone noticing. No one is reviewing its audit logs. No one has updated its policies. This pattern — the abandoned production agent with no current owner, no governance oversight, and persistent access to business-critical systems — is far more common than most security teams realize, precisely because without a central identity registry, there is no mechanism to discover it.
The Confidence Threshold Failure
An agent is configured to escalate to a human when its confidence in a decision falls below a threshold. The threshold was set during testing, in a controlled data environment. In production, the data is messier, the edge cases are more varied, and the agent’s confidence scores are consistently higher than they should be because the confidence scoring was calibrated on clean data. The agent is proceeding autonomously on decisions it should be escalating, because the governance policy’s enforcement mechanism — the confidence threshold — is miscalibrated for real-world conditions. The agent appears to be performing well until a downstream audit reveals that a significant number of decisions were auto-approved that would have been reversed on human review.
The Regulatory Discovery Failure
A regulator or auditor requests evidence of human oversight for a specific class of decisions the organization’s agents have been making. The organization cannot provide it — not because the oversight did not happen, but because the audit trail does not capture it in a form that meets the regulator’s requirements. The penalty is not for the underlying decision-making. It is for the inability to demonstrate compliance. This failure is entirely preventable and entirely governance-related. The technical challenge of logging human oversight events is trivial. The organizational challenge of deciding in advance what format that logging needs to take, and ensuring it is consistently applied, is what most organizations have not yet done.
Building Your AI Agent Governance Stack: A Practical Starting Point
For operations leaders who recognize the governance gap and want to close it, the temptation is to begin with the most sophisticated controls — the full observability stack, the zero-standing-privilege identity architecture, the embedded governance CI/CD pipeline. That is the wrong starting point for most organizations, because it requires technical capabilities and organizational alignment that are typically not in place yet.
The more effective approach is sequenced: close the most urgent gaps first, build the foundation that makes subsequent layers tractable, and expand governance coverage progressively as the program matures.
Week 1–2: The Agent Inventory
Before any other governance work, conduct a complete audit of every AI agent currently running in production. For each agent, document: what it does, what systems it has access to, whose credential it uses, who on the business side owns the process, and when it was last reviewed. This inventory is the governance foundation. Nothing else works without it. Expect to find agents your security team did not know existed.
Month 1: Identity and Ownership Assignment
Assign a named owner to every agent in the inventory. Create individual agent identities where shared credentials are currently in use. Scope permissions to match actual functional requirements — remove any access that the agent does not demonstrably need. Establish a process (even a simple spreadsheet-based one initially) for approving new agents and tracking changes to existing ones.
Month 2–3: Escalation Policy Definition
For each agent, define the four-tier escalation model. Identify which of the agent’s decision types fall into which tiers. Define the specific thresholds — monetary, data sensitivity, reversibility — that trigger each tier. Document escalation routing: who receives the escalation, what their SLA is, and what their response options are. Even if you cannot encode these policies in a technical gateway immediately, having them documented means that human operators know when they should be receiving escalations and can audit whether they are getting them.
Month 3–6: Technical Control Implementation
Implement the policy gateway — the execution-layer intercept that validates tool calls against governance policy. Deploy consistent audit logging across all production agents. Establish behavioral baseline monitoring. Connect escalation routing to existing notification infrastructure (ticketing systems, communication platforms, on-call schedules). This is the phase that moves governance from documented intention to enforced reality.
Ongoing: Review, Refresh, and Scale
Governance is not a one-time implementation. Policies go stale as business conditions change. Models get updated and change behavior. New agents are deployed, often faster than governance processes can track. Build a regular cadence — quarterly at minimum — for reviewing active agents against current policy, updating escalation thresholds to reflect operational learning, and assessing new agents against the governance checklist before they go to production. Make this cadence visible to senior operations leadership, not just the technical team, so that governance investment is treated as an operational priority rather than an engineering backlog item.
What Separates the Organizations That Get This Right
The Databricks data point about 12x higher production output for organizations with mature governance is striking, but it is also specific: the organizations achieving those results are not the ones with the most sophisticated governance frameworks. They are the ones where governance is operational — where policy is enforced, not just documented; where ownership is named, not assumed; where observability is continuous, not retrospective; and where governance is treated as the enabler of scale, not an obstacle to it.
The differentiator is not the governance document. It is the organizational belief that agents without governance are liabilities, and that the investment required to make them trustworthy is worth making. Organizations that hold that belief deploy more agents, keep them in production longer, expand their scope deliberately and safely, and get material business value from them. Organizations that treat governance as a compliance cost find themselves in the Gartner 40% — decommissioning agents that were never governed well enough to be reliable.
AI agents are not a technology problem. They are an operating model problem. And the operating model question — who owns this, what are the rules, how do we know when it goes wrong, and who fixes it — is the question that separates the enterprises that will scale autonomous AI from those that will spend 2027 explaining why they shut it down.
Conclusion: Governance Is the Product
There is a persistent framing in enterprise AI that treats governance as a constraint on capability — the thing legal, compliance, and risk want to add that slows down the engineering teams who are trying to ship. That framing is backward, and the data is unambiguous about why.
Organizations with mature AI agent governance deploy more agents, get more of them to production, keep them running longer, and achieve better business outcomes from them. Governance is not the constraint on AI capability. It is the infrastructure that makes AI capability sustainable at enterprise scale.
The governance gap — the chasm between how fast AI agents are being deployed and how well they are being governed — is the defining operational risk of 2026 for enterprises that have moved beyond pilots. Closing that gap requires investment in identity, policy, observability, and operating model design. None of those investments are exotic or technically out of reach. All of them require organizational commitment to treat the question of who governs the agents as seriously as the question of what the agents can do.
The governance work is not done when the agent is deployed. The governance work is the prerequisite for deployment that lasts.
Actionable Checklist: AI Agent Governance for Business Ops
- ☐ Complete inventory of all production AI agents: identity, owner, access, purpose.
- ☐ Assign a named Business Process Owner accountable for each agent’s decisions.
- ☐ Replace shared credentials with individual agent identities scoped to least-privilege.
- ☐ Define four-tier escalation thresholds for each agent’s decision types.
- ☐ Implement an execution-layer policy gateway that enforces escalation rules in real time.
- ☐ Deploy consistent audit logging with the minimum required data set for each action.
- ☐ Establish behavioral baselines and anomaly alerts for all production agents.
- ☐ Build a RACI for the full autonomous decision lifecycle.
- ☐ Align governance documentation with EU AI Act, NIST AI RMF, and/or ISO 42001 as applicable.
- ☐ Schedule quarterly governance reviews: policy currency, access scoping, agent performance.
- ☐ Define incident response playbooks for governance failures before they are needed.
- ☐ Make governance metrics visible in operational reporting — not just the technical backlog.



