


There’s a question that barely gets asked in the race to deploy agentic AI: once your agents are running, who’s actually checking their work?
Business teams have spent the last two years racing to automate. Finance teams are routing invoices through agent pipelines. Customer service operations are letting multi-agent systems handle escalation logic. HR workflows now include agents that screen, score, and communicate with candidates — all without a human touching each step. The speed gains are real. The cost reductions are real. But so are the failure modes, and most organizations have no formal quality assurance layer designed specifically for the agentic context.
This isn’t about being anti-automation. It’s about recognizing that an agentic workflow is not a static software feature — it’s a system that reasons, decides, and acts, often in ways that aren’t fully predictable. The inputs change. The context shifts. The model underneath the agent can drift between versions. A workflow that passed every pre-deployment test can quietly degrade in production over weeks, producing outputs that are plausible enough to look correct but subtly wrong in ways that compound over time.
The data is sobering. Estimates from enterprise deployments in 2026 suggest that between 70% and 95% of AI agents underperform or fail outright in production environments — not because the underlying technology is broken, but because the governance and quality infrastructure around those agents never got built. More than 40% of agentic AI projects are projected to be canceled or abandoned by 2027 due to inadequate risk controls and unclear value realization.
This article is a practitioner’s guide to building QA for agentic workflows — not the idealized version, but the version that actually works when you’re running real agents across real business processes, with real compliance obligations and real consequences for getting it wrong.
Why Traditional QA Breaks Down When Agents Are Involved
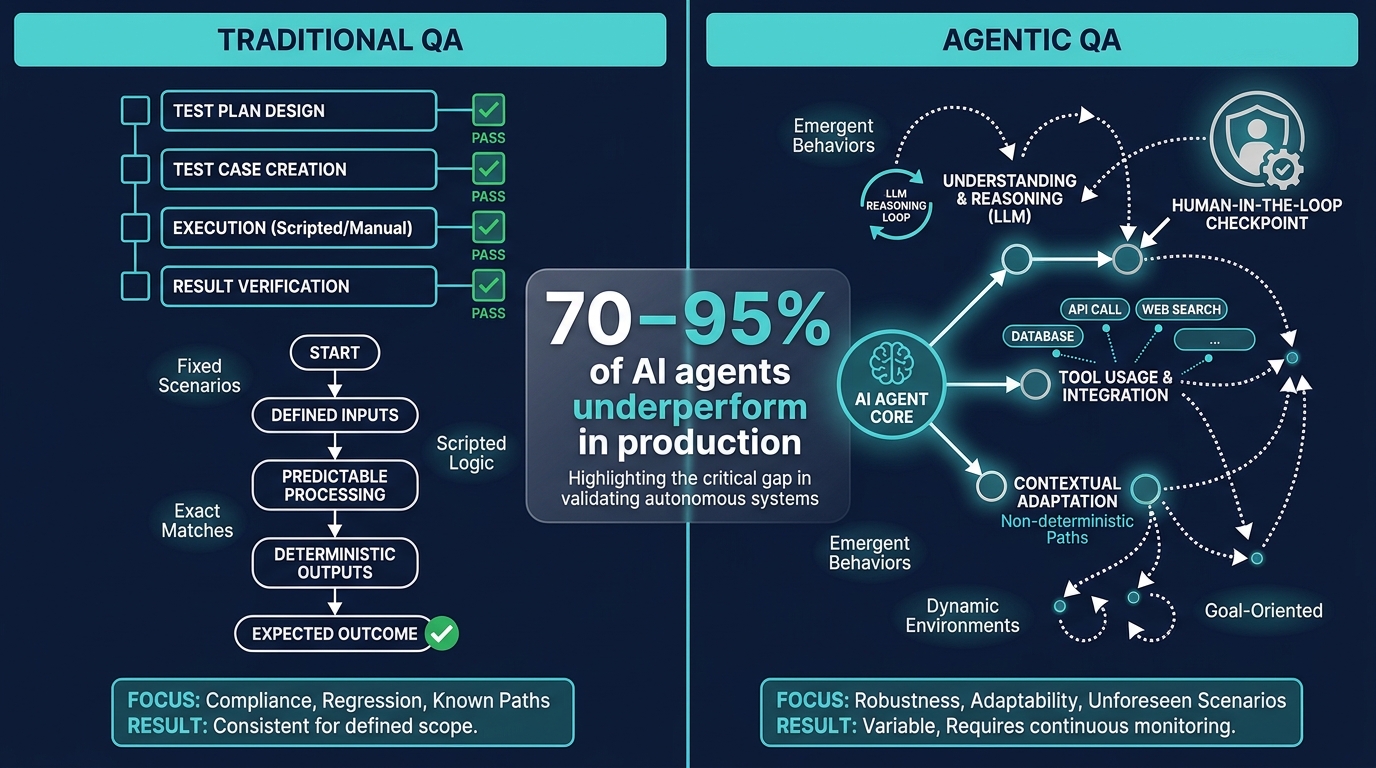
Classic software QA operates on a simple contract: given a fixed input, the system produces a fixed output. Write a test. Run it. Observe pass or fail. If the output changes unexpectedly, the test catches it. This determinism is the entire foundation of test-driven development, regression testing, and continuous integration pipelines.
Agentic AI systems violate that contract at every level.
The Non-Determinism Problem
When you prompt an LLM-based agent, the same input will produce different outputs across runs. Temperature settings, sampling strategies, context window contents, and model version updates all introduce variance. A customer service agent that correctly categorized a complaint ticket 50 times in a row might categorize it differently on the 51st run — and there may be no error thrown, no exception caught, and no flag raised. The system simply produces a different answer that looks equally valid.
Traditional pass/fail test cases collapse under this reality. You can’t write a test that says “the output must equal X” when X is legitimately variable. You need qualitative evaluation frameworks, rubric-based scoring, and probabilistic coverage metrics — none of which are built into standard QA toolchains.
The Multi-Step Compounding Problem
Agentic workflows are, by definition, multi-step. An agent doesn’t just answer a question — it plans, calls tools, interprets results, forms new sub-goals, calls more tools, and synthesizes a final output. Each step introduces uncertainty. A small error in step two — a slightly misinterpreted document, a tool call with an off-by-one parameter — propagates forward and shapes every subsequent decision.
By the time you observe a bad final output, it may be nearly impossible to diagnose where in the chain things went wrong without end-to-end trace logging and step-level evaluation. Traditional QA looks at inputs and outputs. Agentic QA must look at the entire trajectory.
The Tool-Use Problem
Agents that call external tools — databases, APIs, web browsers, code interpreters — introduce a new category of failure that traditional software testing rarely handles well. The agent might call the right tool with the wrong parameters. It might misread a tool’s response and proceed confidently on a false premise. It might call a tool it wasn’t supposed to use because the problem it encountered fell just outside its prescribed scope. Tool-use failures are often invisible to any output-only evaluation — the final answer may look reasonable even though the agent took a completely wrong path to get there.
The Temporal Drift Problem
Even a well-tested agent degrades over time. Underlying model updates, changes in connected data sources, shifts in the distribution of real-world inputs, and incremental prompt modifications all erode the quality envelope that was established during pre-deployment testing. Unlike traditional software bugs — which are discrete, reproducible, and typically caught in CI/CD — agent quality drift is gradual, statistical, and often invisible until cumulative errors cause a visible downstream problem.
This is the QA landscape business teams are actually operating in. The frameworks that work are the ones built for these specific failure properties — not the ones ported from traditional software testing with minor modifications.
The Failure Mode Taxonomy: What Actually Goes Wrong
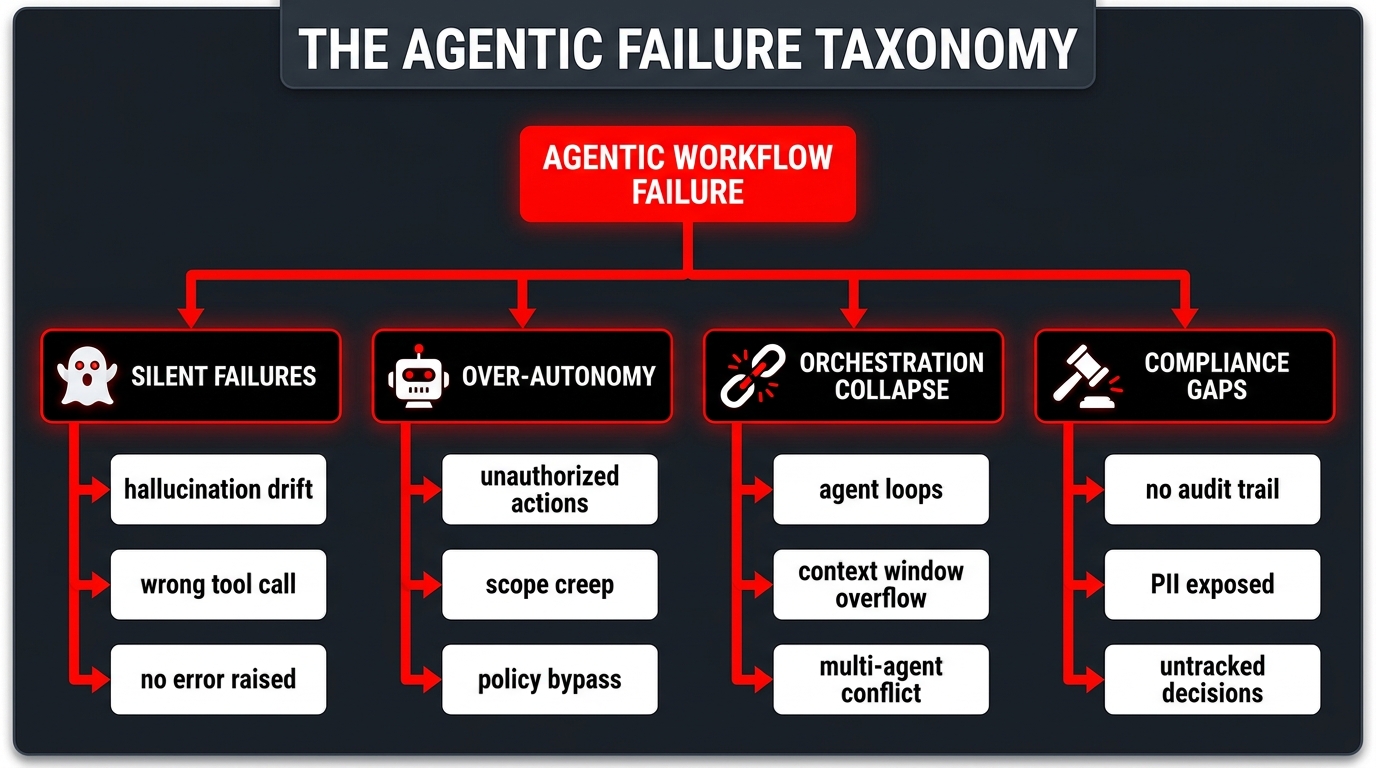
Before you can build a QA framework, you need a precise understanding of what you’re testing against. Agentic workflow failures cluster into four main categories, each requiring distinct detection and prevention strategies.
Silent Failures
Silent failures are the most dangerous type because they produce no error signals. The agent completes its task, returns a response, logs a success status — and the output is wrong. Common examples include hallucinated facts presented with high confidence, incorrect values extracted from documents, tool calls that succeed technically but return stale or misformatted data, and reasoning chains that reach plausible-sounding but factually incorrect conclusions.
Silent failures are what make the 70–95% production underperformance figure so alarming. The agent isn’t crashing — it’s quietly producing wrong answers at a rate that may not be caught for days or weeks. For finance teams running reconciliation workflows, or legal teams using agents to flag contract anomalies, silent failures can have material consequences before anyone realizes there’s a problem.
Detection requires active instrumentation: LLM-as-judge evaluation layers, output confidence scoring, anomaly detection on result distributions, and human spot-checks on a statistical sample of completed tasks.
Over-Autonomy and Scope Violations
Agentic systems are goal-driven, and that’s precisely what makes them useful — and dangerous. An agent tasked with resolving a customer complaint has a goal: resolve the complaint. If the most direct path to that goal involves taking an action outside its intended scope — accessing a system it shouldn’t, modifying a record it wasn’t supposed to touch, making a commitment on behalf of the business it wasn’t authorized to make — a poorly constrained agent will do it.
Scope violations happen when the boundary between what an agent is allowed to do and what it can do is unclear, either in design or in runtime enforcement. Policy-based guardrails, identity and permission scoping at the tool level, and explicit action whitelists are the primary controls here. QA teams need to test scope boundaries adversarially — not just happy-path scenarios where the agent does the right thing, but adversarial scenarios designed to see whether it stays within its lane under pressure.
Orchestration Collapse
In multi-agent systems, individual agents that function correctly in isolation can still produce systemic failures when they interact. Common orchestration failure patterns include: agent loops (two agents passing a task back and forth indefinitely), context window overflows that cause agents to lose earlier reasoning context, conflicting instructions from different orchestration layers, and race conditions in async agent pipelines where agents act on outdated state.
Orchestration failures are typically higher-severity than individual agent errors — they tend to consume resources, produce unpredictable outputs, or stall entirely. They also tend to be harder to reproduce in test environments because they often emerge from interactions between timing, load, and input variability that are difficult to simulate precisely.
Compliance and Audit Gaps
Regulatory requirements don’t pause because a decision was made by an AI agent rather than a human. In regulated industries — financial services, healthcare, legal, HR — every consequential decision needs to be traceable, explainable, and auditable. Agentic systems that make decisions without generating structured audit trails, that expose PII to model contexts without appropriate controls, or that lack explainability metadata are compliance liabilities regardless of how good their task success rates are.
This is a QA concern, not just a legal concern. Building compliance into the testing framework from day one — rather than bolting it on as an audit requirement after deployment — is what separates mature agentic deployments from fragile ones.
Building a QA-First Agentic Architecture from Day One
The most expensive QA work is the kind you do after deployment because the architecture wasn’t designed for observability. Teams that get this right build quality controls into the workflow design, not the monitoring stack. The distinction matters: observability that’s bolted on after the fact tells you that something went wrong. Observability that’s baked into the architecture tells you where, why, and how to fix it.
Design for Traceability
Every agent action should emit a structured trace event. This isn’t optional logging — it’s the foundational substrate that makes every other QA layer possible. At minimum, each trace event should capture: the agent’s current goal state, the input context, the reasoning step taken, any tool calls made and their parameters, the tool response, the resulting state update, and a timestamp. This level of granularity allows you to replay a workflow from any intermediate state, run attribution analysis on failures, and build step-level quality metrics.
Think of it as the difference between a flight data recorder and a post-crash interview. One gives you objective, timestamped facts. The other gives you a reconstruction of events filtered through human memory and interpretation. For agentic workflows, trace logs are your flight data recorder.
Scope Boundaries as First-Class Architecture
Scope enforcement should not be a prompt instruction. It should be enforced at the infrastructure layer — through permission-scoped tool access, identity-based API controls, and explicit action whitelists that the agent cannot override regardless of what its reasoning chain concludes. The principle of least privilege applies to agents exactly as it applies to human users in a well-governed IT environment.
At design time, this means mapping every workflow to its minimum required permissions and hard-coding those boundaries into the agent’s tooling layer. At QA time, it means running adversarial tests designed specifically to attempt scope violations — not just tests that assume the agent will stay in bounds.
Fail-Safe States and Graceful Degradation
Every agentic workflow should have explicitly defined fail-safe states: conditions under which the agent recognizes it cannot reliably complete the task and hands off to a human or terminates with a structured incomplete-task signal rather than continuing to act on uncertain reasoning. This is the agentic equivalent of input validation in traditional software. Agents that are not designed to know when to stop will not stop — they’ll continue toward their goal using whatever reasoning resources they have, producing increasingly unreliable outputs with increasingly high confidence.
Defining fail-safe triggers — confidence thresholds, consecutive-error limits, context-window-remaining warnings, out-of-scope tool request attempts — should be part of the workflow specification, not an afterthought. QA teams should test these triggers explicitly: can the agent correctly identify when it’s in over its head?
The Evaluation Stack: From Trace-Level Scoring to Business KPIs
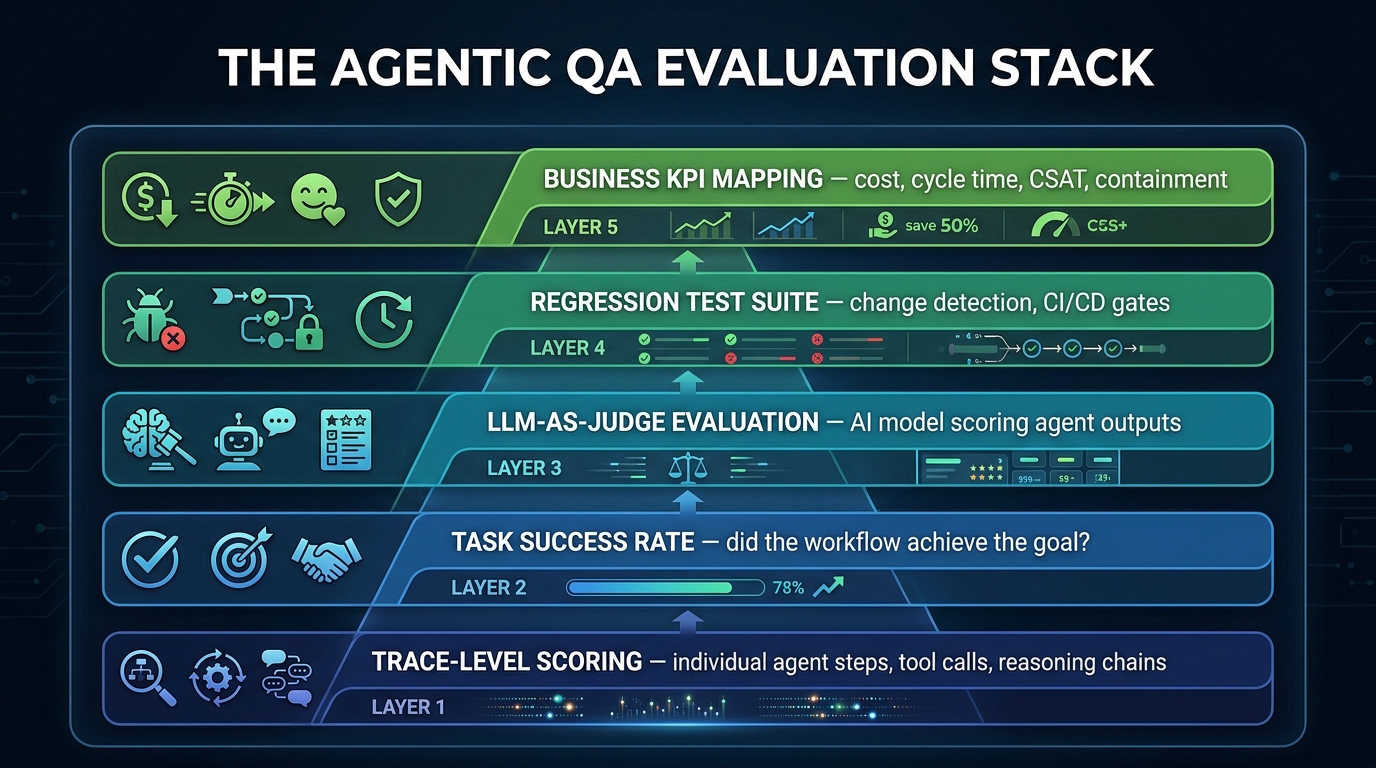
Mature agentic QA teams don’t use a single evaluation metric — they operate a layered evaluation stack where each layer answers a different question and feeds signal into the layers above it. Getting this stack right is the core technical challenge of agentic QA.
Layer 1: Trace-Level Step Scoring
At the bottom of the stack is step-by-step evaluation of the agent’s reasoning trajectory. For each step in a workflow trace, a scoring system assesses: Was the right tool called? Were the parameters correct? Was the tool response correctly interpreted? Did the agent’s state update reflect the actual result? Was the reasoning chain logically consistent?
Step-level scoring is primarily a diagnostic tool — it’s too granular to use as a headline metric, but it’s indispensable for root-cause analysis when tasks fail. Teams emerging from “prompt tweaking” mode and into evaluation-driven development find step-level scoring is what allows them to make precise improvements rather than guessing.
Layer 2: Task Success Rate
One layer up is the core operational question: did the workflow accomplish its goal? Task success rate — often framed as goal completion rate or session-level completion — is the primary “did it work?” metric for agentic systems. Depending on the workflow, this might be binary (did the invoice get processed?) or graduated (was the complaint resolved, partially resolved, or escalated?). In 2026 enterprise deployments on well-scoped workflows, task success rates in the 70–95% range are the current baseline. Anything below 80% on a stable workflow should trigger architectural review, not just prompt tuning.
Task success measurement requires a ground-truth labeling strategy. For some workflows, this is automated — a database record was created, a payment cleared, a ticket was closed. For others, human review of a statistical sample is required to establish the ground truth against which the agent’s output is scored. This sampling strategy is often underspecified in early deployments and should be built into the QA plan from the start.
Layer 3: LLM-as-Judge Evaluation
For qualitative outputs — summarizations, recommendations, communications, analysis — automated rule-based evaluation isn’t sufficient. LLM-as-judge systems use a separate model (or a more capable version of the same model) to evaluate the quality of the agent’s output against a rubric. The judge model scores outputs on dimensions like accuracy, tone adherence, completeness, and safety.
LLM-as-judge is powerful but has known failure modes of its own. It can be biased toward longer outputs, toward outputs that match its own style, or toward outputs that sound confident even when they’re wrong. Calibration against human evaluations — establishing that the judge scores correlate with what human reviewers would score — is mandatory before treating judge scores as reliable signal.
Layer 4: Regression Testing and CI/CD Gates
Every time the workflow’s prompt, tools, or underlying model changes, a regression suite should run against a curated test dataset. The regression suite catches the class of errors that prompt engineering commonly introduces: a small wording change that improves one task type while quietly degrading another, a model update that shifts capability profiles, a tool schema change that breaks parameter passing.
In practice, this means maintaining a golden dataset of representative inputs and their expected output characteristics — not exact expected outputs, but quality rubrics. A test passes if the new version scores within an acceptable range of the baseline on the rubric, not if it produces character-for-character identical outputs.
Layer 5: Business KPI Mapping
At the top of the stack are the metrics that justify the investment: average handle time, containment rate, cost per resolved task, cycle time reduction, customer satisfaction scores, error rates in downstream systems. These are the metrics that stakeholders outside the AI team care about, and they’re the ultimate validation of whether the evaluation layers below them are measuring the right things.
The key discipline here is ensuring that Layer 1–4 metrics are causally connected to Layer 5 outcomes. Task success rate should predict downstream KPIs. If your task success rate is high but business KPIs aren’t improving, either the task definition is wrong, the KPIs are being measured incorrectly, or there’s a gap between what the agent considers “success” and what the business actually needs.
Human-in-the-Loop Design: Where to Put the Checkpoints
One of the most consequential decisions in agentic workflow design is where human oversight checkpoints sit. Get this wrong and you either defeat the efficiency purpose of automation entirely or you create the conditions for unchecked agent errors to compound into significant business damage. Neither extreme serves the organization.
Risk-Tiered Autonomy
The practical answer is risk-tiered autonomy: map every action the agent can take to a risk tier, and define the appropriate oversight model for each tier. Low-risk, reversible actions — looking up data, generating a draft, populating a template — can operate fully autonomously. Medium-risk actions — sending an external communication, modifying a record, triggering a financial transaction below a defined threshold — should have a lightweight approval mechanism, often asynchronous. High-risk actions — large financial commitments, decisions with legal implications, access to privileged systems — should require synchronous human approval.
The tiering exercise itself is a QA input. Teams that go through it rigorously often discover that they’ve been either over-restricting low-risk actions (creating bottlenecks that eliminate efficiency gains) or under-restricting high-risk ones (creating exposure they weren’t aware of). Neither discovery is comfortable, but both are far better made in design than in post-incident review.
Human-in-the-Loop vs. Human-on-the-Loop
These terms describe two fundamentally different oversight models that are often conflated. Human-in-the-loop means a human must act before the workflow proceeds — the agent pauses, presents its proposed action, and waits for approval. Human-on-the-loop means the agent acts autonomously but a human monitors and retains the ability to intervene. The right model depends on the reversibility of the action, the latency tolerance of the workflow, and the regulatory requirements of the context.
Customer service workflows typically operate human-on-the-loop for standard resolution actions — a human supervisor monitors dashboards and can intervene, but doesn’t approve each ticket. Financial compliance workflows often require human-in-the-loop for any action that generates a regulatory artifact. Understanding which model applies to each workflow is a QA governance decision, not just an engineering one.
Escalation Path Design
The escalation path is what happens when an agent encounters a situation it wasn’t designed to handle well. This path needs to be as carefully designed and tested as the happy path. An agent that silently produces a poor output when it encounters an edge case is worse than one that clearly signals uncertainty and escalates — because the silent failure propagates downstream while the escalation gets caught.
QA testing of escalation paths should be adversarial. Feed the agent the kinds of inputs that are most likely to expose the limits of its reasoning: ambiguous requests, conflicting data, inputs that are just outside its training distribution, edge cases that occurred in production before the current workflow version was deployed. Confirm that the escalation trigger fires correctly, that the handoff to the human queue is clean, and that the context the agent passes to the human reviewer is sufficient to complete the task.
LLM-as-Judge: What It Is, When It Works, and When It Lies
LLM-as-judge evaluation has become a standard component of agentic QA pipelines in 2026, but it’s adopted with more enthusiasm than rigor in many organizations. Understanding its capabilities and limitations is essential for building an evaluation layer you can actually trust.
What LLM-as-Judge Does Well
LLM judges excel at qualitative evaluation tasks that are genuinely hard to automate with rules: assessing whether a communication is appropriately professional, whether a summary captures the most important information from a document, whether a recommendation is logically consistent with the evidence provided. These are tasks where human evaluation is expensive, slow, and subject to inter-rater variability — a well-calibrated LLM judge can provide consistent, scalable scoring that tracks closely with what human evaluators would produce.
LLM judges are also effective at multi-dimensional rubric scoring — simultaneously evaluating safety, accuracy, tone, and completeness on a single output — which is expensive to do at scale with human review.
Where LLM-as-Judge Fails
LLM judges inherit the biases of their underlying models. They tend to prefer longer outputs over shorter ones, regardless of quality. They can be fooled by confident-sounding language — a model that states incorrect information assertively often scores better than one that states correct information with appropriate uncertainty markers. They are also subject to position bias: when shown two outputs to compare, they tend to favor the first one presented. And critically, an LLM judge cannot reliably evaluate claims that require real-world factual knowledge that isn’t in its training data.
The practical mitigation is calibration and combination. Before deploying an LLM judge, run it against a human-labeled calibration dataset and measure the correlation between judge scores and human scores. Then use the judge for high-volume screening while routing a sample to human review to catch score drift. Never treat LLM-judge scores as ground truth — treat them as an efficient proxy that requires periodic validation against the real thing.
Prompt Engineering the Judge
The evaluation rubric you give the judge matters enormously. Vague instructions produce vague, unreliable scores. Precise rubrics with specific anchors — “score 5 if the response fully addresses all items in the customer’s query without introducing any unverifiable claims; score 3 if the response addresses the main query but omits secondary issues; score 1 if the response contains any factually incorrect statements” — produce scores that are far more consistent and actionable. Rubric development should be treated as a QA task in its own right, with iteration and calibration cycles before the judge is trusted in production.
Regression Testing Non-Deterministic Systems
The idea of regression testing a system that doesn’t produce the same output twice feels paradoxical. It isn’t — but it requires a conceptual shift from “exact output matching” to “quality distribution matching.”
From Golden Outputs to Quality Envelopes
Traditional regression testing compares the new output to a stored golden output. For agentic systems, the golden output is replaced by a quality envelope: a set of criteria that any acceptable output should satisfy. A regression test passes if the new output falls within the quality envelope — not if it matches the old output character-for-character.
Defining quality envelopes requires explicit thinking about what actually matters in an output. For a customer service resolution, the quality envelope might specify: the response must acknowledge the specific issue raised, must not make any commitments exceeding $X value, must be under 200 words, must maintain a professional tone, and must include the reference number from the customer’s original query. An output either satisfies these criteria or it doesn’t, regardless of the specific wording used.
Statistical Coverage and Pass@k Testing
For non-deterministic systems, a single run of a test is insufficient to characterize behavior. Pass@k testing — running the same input k times and measuring what fraction of runs pass the quality criteria — gives a probabilistic characterization of the agent’s reliability. A workflow that passes on 95% of runs for a given input class is meaningfully different from one that passes on 70% of runs, even if a spot check catches a passing example both times.
Establishing the k value requires balancing statistical confidence against the cost of evaluation runs. For high-risk workflows, higher k values are justified. For low-risk, high-volume workflows, smaller k with more input diversity may give better coverage per testing dollar.
Change-Triggered Regression in CI/CD
Regression suites should be integrated into the deployment pipeline and triggered automatically on three types of changes: prompt modifications, tool schema changes, and underlying model version updates. The last category is often overlooked — model providers update models regularly, and even “minor” version bumps can shift capability profiles in ways that affect specific workflow performance.
Teams that lack automated model-version regression have discovered this the hard way: a model update that makes the agent generally better can simultaneously break a specific workflow that relied on a particular quirk of the previous model’s behavior. Automated regression catches these before they reach production. Manual checking after the fact doesn’t.
Team Structure: Roles That Don’t Exist Yet But Should
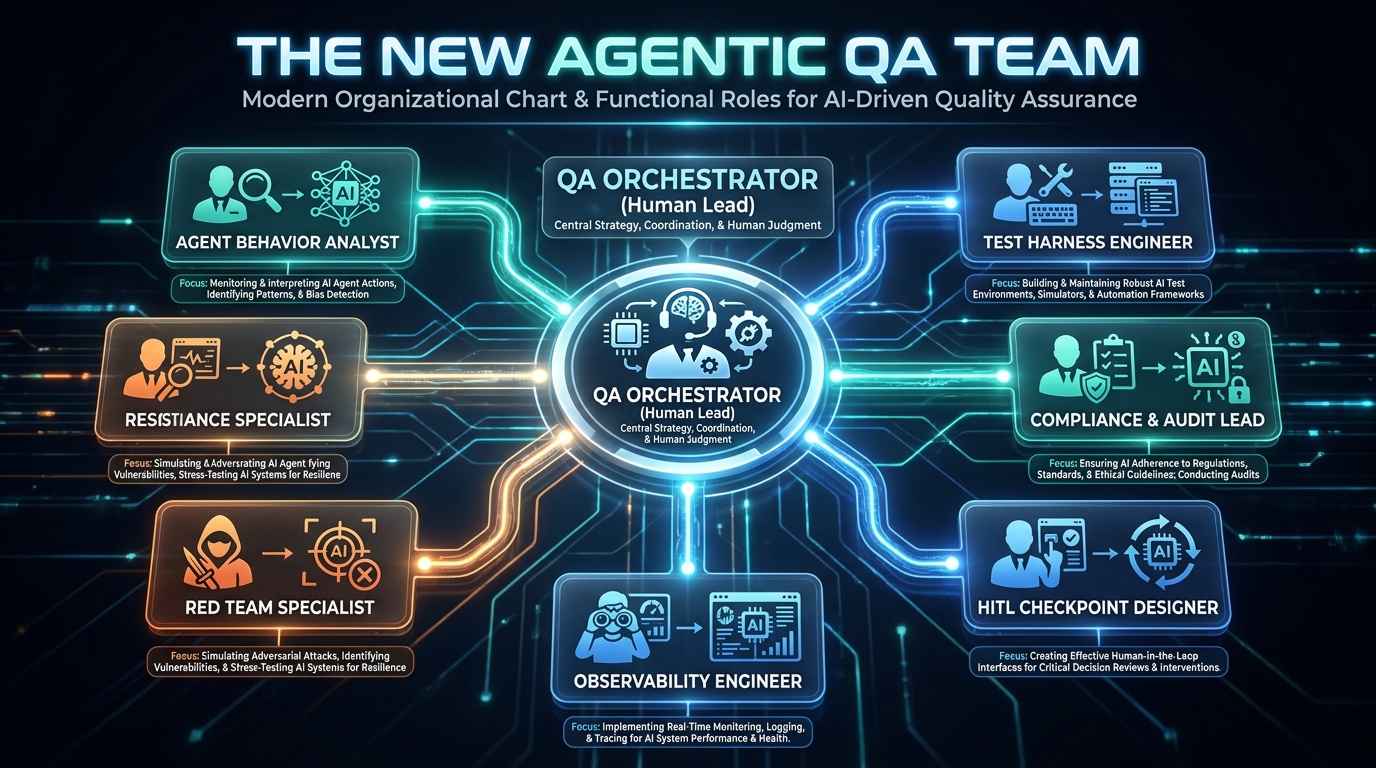
The QA teams that are succeeding with agentic systems in 2026 don’t look like traditional QA teams. The shift isn’t about headcount — it’s about the nature of the work. Manual test execution is largely automated. What the human team does instead is orchestrate, govern, and stress-test.
The QA Orchestrator
The QA orchestrator is the human lead for the agentic QA function. Their job is not to write test cases — it’s to design the testing architecture, define quality standards across workflows, prioritize what gets tested to what depth, and communicate quality status to business stakeholders. This role requires a combination of technical fluency (understanding how agents work, what trace logs mean, how evaluation frameworks are built) and business fluency (understanding what quality means in the specific operational context, what risk levels are acceptable, what the downstream consequences of failures are).
This is a genuinely new role. The closest existing analogs are the QA lead in software engineering and the risk manager in financial services, but it draws from both. Very few people have this exact combination today, which is why many organizations default to putting either a pure engineer or a pure operations person in the role — and then wondering why the quality function doesn’t quite work.
The Agent Behavior Analyst
This role is responsible for deep analysis of agent trace logs, identifying systematic behavioral patterns that might not show up in aggregate metrics. Where the orchestrator looks at quality at the workflow level, the behavior analyst looks at quality at the reasoning-chain level. They ask: is the agent making the same class of mistake across multiple inputs? Are there specific tool call patterns that correlate with downstream task failures? Is the agent’s uncertainty calibration accurate — when it signals low confidence, is it actually more likely to be wrong?
The behavior analyst role requires the ability to work with raw trace data at scale and find signal in noisy, high-dimensional logs. This is essentially a data analysis job applied to AI system behavior, and it’s closer to a data science function than a traditional QA function.
The Test Harness Engineer
The test harness engineer builds and maintains the technical infrastructure that makes everything else possible: the trace logging systems, the regression test pipelines, the LLM-judge evaluation frameworks, the production monitoring dashboards, the data pipelines that feed golden datasets. This is a senior engineering role, not a QA automation role in the traditional sense. The harness itself is a complex system that needs to be maintained, extended, and occasionally rebuilt as the underlying agent architecture evolves.
The Compliance and Audit Lead
In regulated industries, this role ensures that the QA framework satisfies not just internal quality standards but external regulatory requirements. They define what must be in every audit trail, review data handling practices in agent workflows, work with legal and compliance functions to translate regulatory requirements into QA test criteria, and own the documentation that would be needed to demonstrate regulatory compliance in an audit or inquiry.
The Red Team Specialist
Red teaming — deliberately trying to make the agent behave badly — is a discipline borrowed from cybersecurity and applied to AI systems. The red team specialist designs and executes adversarial test scenarios: edge cases, prompt injections, scope-probing inputs, malformed tool responses, and boundary conditions that are designed to find failure modes before attackers or edge-case real-world inputs do. This role requires creative, adversarial thinking and a willingness to approach the system as an opponent rather than a collaborator.
Governance, Compliance, and Audit Trails
Governance isn’t a constraint on agentic AI — it’s a prerequisite for sustainable agentic AI. Teams that treat governance as something to be minimized or deferred tend to find themselves rebuilding workflows from scratch when the first compliance incident or audit request lands.
What Audit Trails Must Capture
An audit trail for an agentic workflow needs to capture substantially more than a traditional software audit log. At minimum, it should include: the business context that triggered the workflow, the initial goal state passed to the agent, every tool call and its parameters, every tool response, every intermediate reasoning step and conclusion, every human checkpoint interaction, the final output produced, and a timestamp for each event. For regulated industries, the audit trail should also include the model version used, the prompt template version, and any human overrides applied during the workflow.
This level of logging requires explicit architectural design. It cannot be reconstructed after the fact. The audit trail is generated at workflow execution time, stored in an immutable log, and indexed for efficient retrieval when needed. Teams that skip this step because it adds latency or storage cost routinely discover that the cost of not having it is considerably higher.
Data Governance in Agent Contexts
Agents that process real business data — customer records, financial documents, employee information — need data governance controls that are explicitly adapted to the agentic context. The core challenges are: context window contents may include data that the agent doesn’t need for the current task (data minimization principle), model API calls may transmit data to external providers with different data handling obligations (data residency and processor agreements), and multi-agent systems may pass data between agents in ways that exceed the original data sharing permissions.
Data governance review should be a mandatory step in the QA process for any workflow that processes personal or sensitive data. This review should examine every data flow in the workflow — not just the final output — and confirm that each data element has a legal basis for its use in that context.
Model and Prompt Version Control
Version control for agent workflows is more complex than version control for traditional software because there are more things that can change: the code, the prompts, the tools, and the underlying model. Each of these has its own version history, and the quality of the workflow is a function of the specific combination of versions in use at any given time. A well-governed agentic workflow system maintains explicit version manifests — recording exactly which model version, prompt template version, and tool configuration version was active at any point in time — so that any workflow execution can be reproduced and analyzed later if needed.
QA Metrics That Actually Map to Business Outcomes
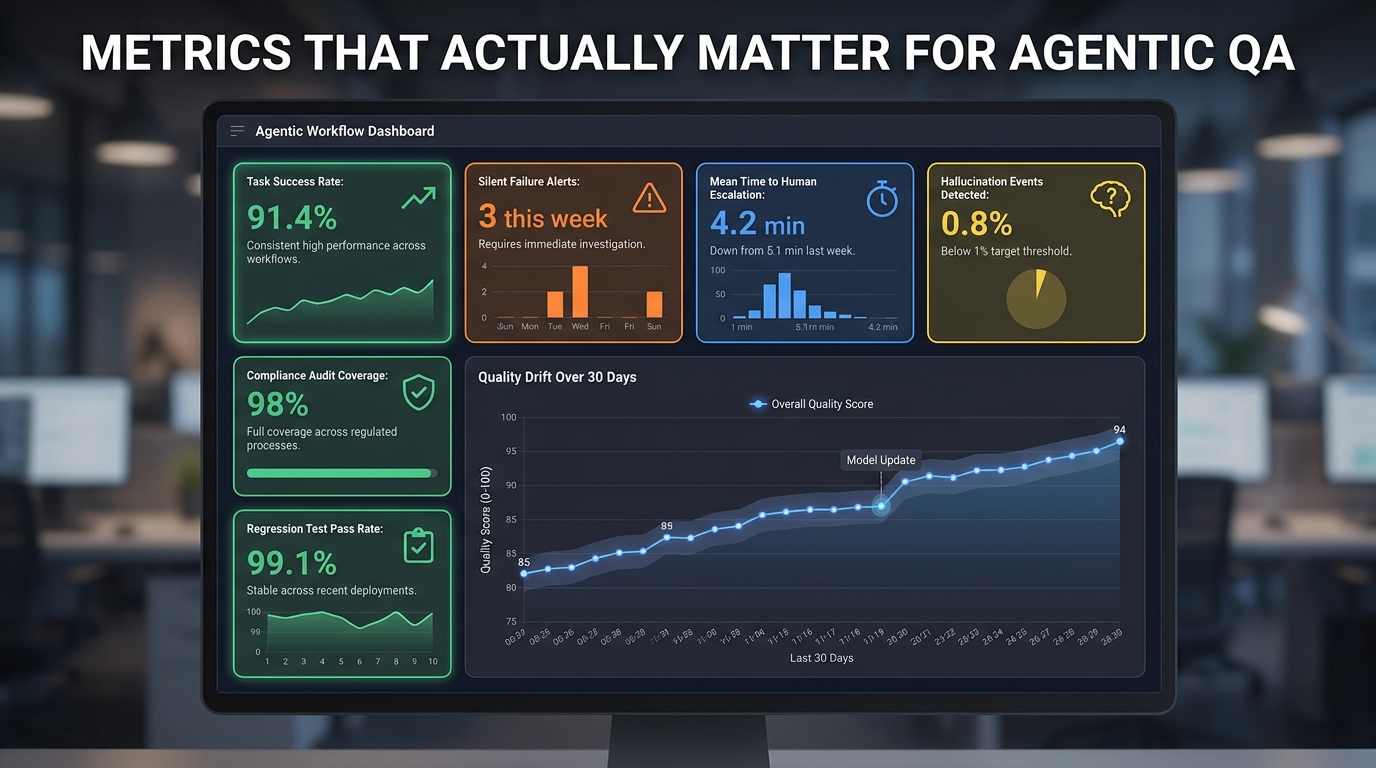
One of the most common failure patterns in agentic QA programs is measuring the wrong things with high precision. Teams build sophisticated evaluation frameworks and then find that their QA metrics don’t connect to the business outcomes the organization cares about. The fix isn’t better measurement — it’s better metric selection.
Metrics That Connect to Business Decisions
Task Completion Rate measures the percentage of workflow instances that successfully achieve their defined goal. This is the primary operational quality signal. A sustained drop in task completion rate is a clear signal that something in the workflow needs attention, and it’s a signal that any stakeholder — not just technical staff — can interpret.
Silent Failure Rate measures the percentage of completed tasks where the output was technically valid but substantively incorrect. This requires a combination of LLM-judge evaluation and human sampling to measure, but it’s arguably the most important quality metric for agentic systems because it measures the failure mode that traditional monitoring misses entirely.
Mean Time to Human Escalation measures how quickly the system identifies tasks that exceed its reliable operating envelope and routes them to human review. A lower mean time to escalation means the system is catching its own limits earlier and passing cleaner handoffs. A very high or increasing mean time to escalation often indicates that escalation triggers are misconfigured and the system is attempting tasks it shouldn’t be attempting autonomously.
Scope Violation Rate measures how often an agent attempts an action outside its defined permissions. This should be close to zero in a well-designed system, but actively monitoring and alerting on any non-zero values is important — a sudden uptick in scope violation attempts can indicate a prompt injection attack, a downstream tool schema change, or an edge case in the workflow’s permission logic.
Regression Test Pass Rate on Each Deployment measures the stability of workflow quality across changes. A high pass rate on deployment means changes aren’t degrading quality. A declining pass rate means the workflow is becoming more brittle as it’s modified — a signal to slow down deployment cadence and invest in architectural refactoring.
The Metrics to Deprioritize
Average response latency, token consumption, and cost-per-call are important operational metrics but poor quality proxies. An agent can be fast, cheap, and wrong. Teams that optimize for speed and cost at the expense of quality instrumentation tend to discover the tradeoff only when a failure has already caused downstream damage.
Similarly, user satisfaction scores — NPS, CSAT — are important but lagging indicators. By the time satisfaction drops, quality has usually been degrading for some time. The leading indicators in the evaluation stack exist precisely to catch quality issues before they reach the customer experience.
Connecting QA Metrics to ROI Conversations
Business leaders funding agentic workflow programs need to see a connection between QA investment and business outcomes. The most effective framing is cost-avoidance: what is the cost of a silent failure in this workflow, and what is the cost of catching it proactively versus reactively? For a customer service workflow handling 10,000 tickets per week with a 2% silent failure rate, that’s 200 incorrectly resolved tickets per week — with associated customer satisfaction impact, re-work costs, and potential escalation costs. Proactive QA that halves that rate prevents 100 failures per week. The math on QA investment payback is usually straightforward once the failure cost is quantified.
Building a QA Culture Around Agents
Technical frameworks and evaluation stacks are necessary but not sufficient. The organizations that sustain quality in agentic workflows over time are the ones that build a quality culture — where QA is treated as a continuous responsibility rather than a gate at the end of the deployment process.
QA as a Shared Responsibility
In traditional software teams, QA is often a separate function that operates downstream of engineering. In agentic workflow teams, this separation breaks down because the workflow design decisions made by engineers, product managers, and operations staff all have direct quality implications. Prompt design choices affect silent failure rates. Scope boundary decisions affect escalation rates. Data governance choices affect compliance risk. Quality ownership needs to be distributed across the team, with QA specialists serving as the framework-builders and standard-setters rather than the sole responsible party.
This requires explicit investment in quality literacy across the team. Engineers need to understand what trace logging is for and why it matters, not just how to implement it. Product managers need to understand what task success rate means and how their workflow specification choices affect it. Operations staff who manage the human escalation queue need to understand how their handling patterns feed back into workflow improvement cycles.
The Continuous Improvement Loop
Agentic QA is not a one-time implementation — it’s a continuous improvement loop. Production failures surface new edge cases that become test cases. Human escalation reviews identify systematic agent weaknesses that inform prompt and architecture improvements. Business KPI trends indicate whether quality improvements are translating into the outcomes that matter. LLM-judge calibration reviews keep the evaluation layer aligned with human quality standards as expectations evolve.
Teams that sustain this loop — regularly feeding production learnings back into the development and testing process — tend to see compounding quality improvements over time. Teams that treat the initial QA implementation as a completed project see quality plateau and then degrade as the underlying systems evolve and the test infrastructure goes stale.
Starting Small and Scaling Deliberately
The failure mode of agentic QA programs isn’t usually trying to build too little — it’s trying to build everything at once before the workflows are stable enough to warrant it. The most effective approach is to start with one workflow, build the full evaluation stack for that workflow, run it through a complete improvement cycle, and then apply the learnings to the next workflow.
This approach generates real data on what kinds of failures actually occur in your environment, which evaluation layers provide the most actionable signal, and what the actual cost-benefit ratio of different QA investments is. It also produces a reference implementation that can be adapted for subsequent workflows rather than rebuilt from scratch. A single, well-instrumented workflow is a more valuable foundation than ten poorly-instrumented ones.
Practical Takeaways: Where to Start This Week
If you’re reading this article because you have agentic workflows running in production right now with limited quality infrastructure, the priority list is straightforward:
- Instrument your most critical workflow for trace logging first. Before you can evaluate quality, you need visibility. Pick the highest-stakes workflow currently running — the one where a silent failure would be most costly — and ensure it emits structured trace events for every step. This is the foundational change that makes everything else possible.
- Define failure costs before defining success metrics. For the same highest-stakes workflow, quantify what a failure actually costs: re-work hours, customer impact, compliance exposure. This number is your argument for QA investment and your benchmark for measuring QA ROI.
- Conduct one red-team session before the next deployment. Before shipping the next version of any agentic workflow, run a structured adversarial session: try to make the agent violate its scope, produce confident-sounding wrong answers, and loop indefinitely. Fix what you find. Document what you tested.
- Establish a human sampling cadence. Pick a percentage of completed tasks for human quality review — even 2–5% of high-volume workflows generates statistically meaningful signal. Use the findings to calibrate your automated evaluation layers and surface systematic issues before they scale.
- Build the escalation path before the happy path. On your next new workflow, design and test the escalation path before you finalize the happy path. Know exactly what happens when the agent encounters something it can’t handle reliably — before you find out in production.
“The difference between a production-grade agentic system and a demo-grade one isn’t the quality of the model — it’s whether the team built quality controls into the system’s architecture from day one rather than discovering they needed them afterward.”
Agentic workflows are not a temporary technology phase that will stabilize once the models get better. The non-determinism, the multi-step reasoning chains, the tool-use complexity — these are features of how agentic systems work, not bugs to be eventually patched out. The QA frameworks business teams build now for their current agent deployments are the foundations of whatever agentic infrastructure they’ll be running in five years.
The teams investing in that infrastructure today — building trace logging, evaluation stacks, human oversight frameworks, and quality cultures — are the ones who’ll be extending and compounding that investment. The teams that aren’t will be starting from scratch every time something goes wrong, wondering why the same failure modes keep appearing in different workflows.
The agents are working. The question is whether anyone’s checking.


