There is a bill that most AI agent budgets never include. It does not show up in your model API invoice, your infrastructure spend, or your compute projections. It accrues quietly in the hours engineers spend debugging non-deterministic behavior, in the overnight token runaways that nobody caught until the credit card alert fired, in the SRE rotations stretched thin by a new category of alert that does not fit any existing playbook, and in the hard conversations about why a production agent just sent 4,000 emails to the wrong segment because it inherited DELETE permissions nobody intended to grant it.
This is the ops tax on AI agents. And in 2026, it is the primary reason that a staggering 80 to 88 percent of agent initiatives either never reach production or fail within weeks of getting there. The capability problem — building agents that can do useful things — has largely been solved. The operational problem — keeping those agents from burning your budget, your data, and your on-call rotation — has not.
This article is not about getting AI agents to work. It is about everything that happens after they start working: the permission explosions, the cost runaways, the observability blind spots, the staging environments that lie, and the human review workflows that quietly become bottlenecks. It is a field guide to the operational discipline that separates teams shipping agents to durable production from teams shipping agents to expensive outages.
Why Production AI Agents Are a Different Class of Infrastructure Problem
If you have been building software for long enough, you have a mental model for how production systems fail. Servers run out of memory. Queries slow down under load. APIs return unexpected status codes. These failures are deterministic enough that you can reproduce them, write a regression test, and ship a fix. The failure domain is bounded.
AI agents break that mental model in three distinct ways that demand a fundamentally different operational approach.
Non-Determinism Is Now a Production Property
Traditional services, given the same input, produce the same output. An AI agent given the same input might produce a subtly different action sequence depending on temperature settings, context window state, model version drift, or the particular phrasing of a retrieved document that shifted its reasoning path. You cannot unit-test your way to confidence when the system is, by design, probabilistic.
This means that passing a staging test does not guarantee passing the same scenario in production. It means that a prompt that worked fine at 100 invocations per day can exhibit new failure modes at 10,000. And it means that “the agent worked last week” is not evidence that it will work the same way next week, particularly after a model provider silently rolls out a new version of their base model.
Agents Take Actions With Real-World Consequences
A traditional microservice failing is self-contained: it returns an error code, logs an exception, and you fix it. An AI agent failing mid-workflow might have already sent the email, executed the database update, called the external API, or — in a documented 2026 incident — deleted and recreated an AWS Cost Explorer environment, triggering a 13-hour outage. The failure is not self-contained. It has side effects that exist outside the system.
This is qualitatively different from anything that standard SRE runbooks were designed to handle. The agent did not crash. It succeeded in doing exactly what it was technically authorized to do. The problem was that it was authorized to do far too much.
Cost Is a Dynamic Variable, Not a Fixed Resource
With traditional infrastructure, you provision capacity and run within it. An agent that gets stuck in a tool-call loop, or that has been given a task with unbounded scope, can run up thousands of dollars of API cost in a single overnight batch run. Production observability teams in 2026 report catching cost runaways that would have burned between $5,000 and $50,000 in a single night without early detection. There is no “out of memory” error to catch this. The agent just keeps running, happily spending, until a human or a hard budget cap stops it.
Each of these properties — non-determinism, consequential side effects, and dynamic cost — requires a distinct operational response. Traditional SRE tools and practices address none of them adequately on their own. Building the discipline around all three, simultaneously, is what the ops tax looks like in practice.
The Blast Radius Problem: How Over-Permissioned Agents Break Production

The fastest way to ship an AI agent to production is to give it broad tool access and see what it can do. This is also the fastest way to create a production incident that takes days to unwind. In 2026, the majority of reported AI agent production failures trace back not to model quality issues, but to over-permissioned tool access that allowed a single bad reasoning step to propagate into real-world consequences.
How Over-Permissioning Happens in Practice
It rarely happens through carelessness. It happens through iteration. A developer building an agent in a dev environment grants it broad access to make testing faster. The agent works well, so it moves to staging with those permissions roughly intact. Staging looks fine, so it ships to production. At no point did anyone sit down and ask: if this agent makes the worst possible valid tool call given its system prompt, what is the most damage it can do?
That question — what is the blast radius of a single bad tool call? — is the one that most agent teams are not asking early enough. The answer, for an agent with write access to a production database, send access to a customer email system, and execute access to a cloud infrastructure API, is: quite a lot.
Mapping Blast Radius Before You Ship
The practice that leading teams have converged on is explicit blast radius mapping as a pre-production gate. For each tool exposed to an agent, the team documents: what is the maximum scope of action this tool can take? Is that action reversible? What is the business impact if this tool is called incorrectly at maximum scope?
Tools are then categorized into risk tiers:
- Read-only tools — no write access, no external side effects. These can be granted broadly with minimal review.
- Limited-write tools — write access scoped to a specific resource type or ID range, with audit logging. These require per-task scoping.
- High-blast-radius tools — bulk operations, cross-service access, external communications, financial transactions. These require human approval gates before execution, or should not be exposed to autonomous agents at all until trust is established through a track record of safe operation.
The Principle of Least Privilege Is Not a Security Nicety — It Is an Ops Requirement
Security teams have been advocating for least-privilege access for decades. For AI agents, least privilege is not just about preventing malicious exploitation. It is about preventing well-intentioned agents from doing damage through confident-but-wrong reasoning. An agent that is correct 98% of the time and has broad production access will eventually hit that 2%. Least privilege is the engineering discipline that limits what “that 2%” costs you.
Concretely, this means: agents should be granted tool access per-task, not per-deployment. An agent running a data summarization workflow does not need write access to your production database, even if the same agent framework might use database writes in a different workflow. The tool scope should be defined at workflow registration time, reviewed, and not permitted to expand at runtime without an explicit authorization check.
Several enterprise security vendors, including CyberArk, have published formal guidance in 2026 on treating AI agents as non-human identities in identity and access management systems — meaning they need the same lifecycle controls as service accounts: provisioning, time-bounded credential scoping, access reviews, and deprovisioning.
Budget as Policy: Governing Token Spend Before It Governs You
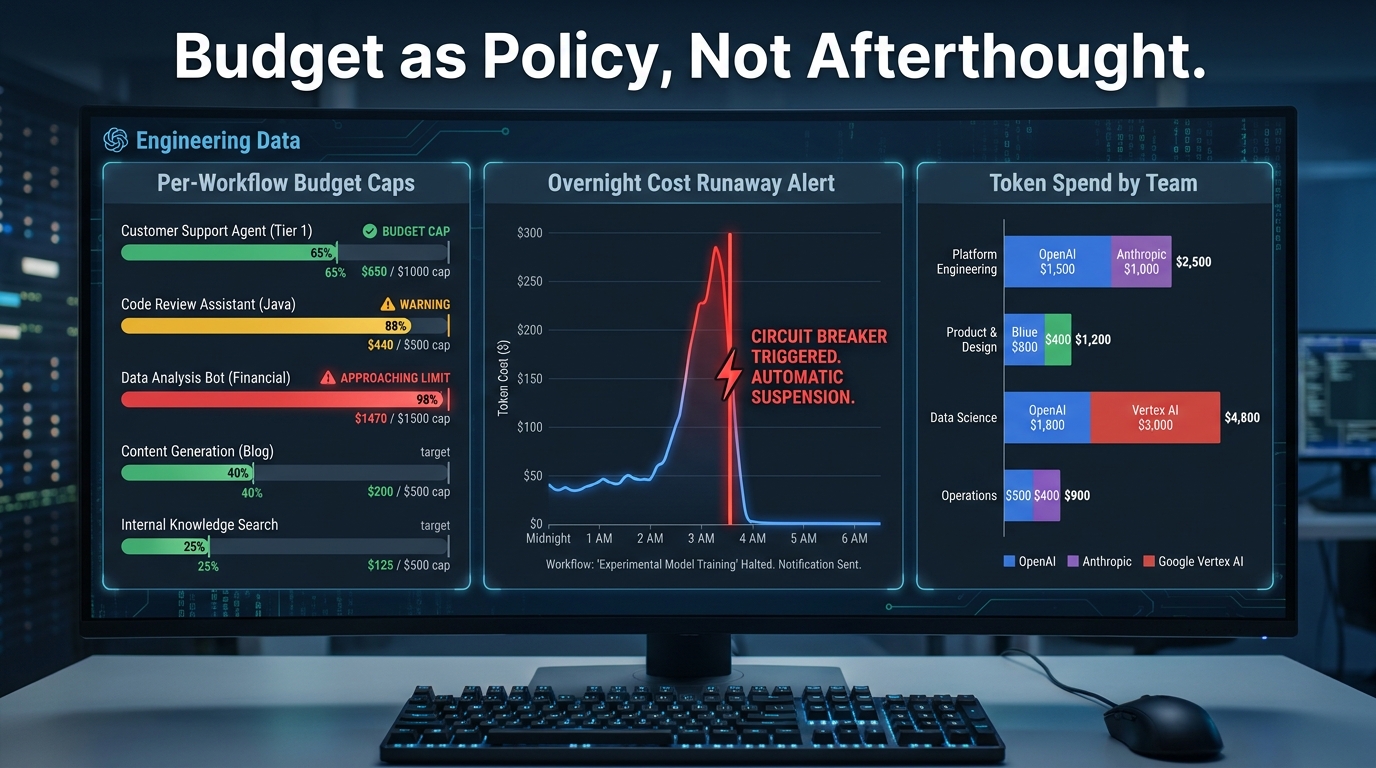
When an engineering team ships a new microservice, nobody expects it to autonomously decide to run more compute than was provisioned. But an AI agent with an unbounded loop, an inefficient retrieval chain, or a task that turned out to be far more complex than anticipated will consume as much API budget as it takes to complete its objective — or until it hits an error it cannot recover from.
The pattern that production teams have converged on in 2026 is treating token spend as a governed budget with policy-level controls, not as a billing line item you review after the fact.
FinOps Principles Applied to Agent Workloads
Cloud FinOps established the principle that you need to attribute compute costs to specific teams, features, or customers in order to manage them. The same principle now applies to AI agent workloads. When your entire organization’s agent infrastructure runs through a single API key, you have no way to know which workflow is responsible for a cost spike, which team owns the budget that just ran over, or which specific agent run produced the anomalous spend.
Leading teams are implementing per-workflow cost attribution from day one: each agent workflow has its own labeled cost tracking, its own budget threshold, and its own alert configuration. This is not optional complexity — it is the minimum structure required to operate a multi-agent organization safely.
The Three Layers of Cost Governance
Mature implementations stack three layers of control:
- Soft limits with alerts: When a workflow hits a defined percentage of its budget (commonly 70%), an alert fires to the team responsible. No agent is stopped; the alert is informational and allows human review before a threshold is breached.
- Hard limits with degradation: At 100% of budget, the agent does not throw an error and stop. It degrades gracefully: routes to a cheaper model, reduces context window size, or switches to a mode that returns partial results with a flag indicating budget constraints. This avoids both the cost overrun and the hard failure that would leave a workflow incomplete.
- Kill switches with escalation: At a separately configured maximum ceiling (typically 150–200% of expected budget, designed to catch pathological loop cases), the agent is halted entirely and the incident is escalated to a human for review. This is the “cost circuit breaker” — the last line of defense against the overnight $50,000 runaway.
Context Size Is a Cost Variable Most Teams Ignore
One of the most common sources of unexpected agent cost is context window bloat. Agents that accumulate tool call results across a long chain of steps can build context windows that are orders of magnitude larger than the original task appeared to require. A summarization workflow that hits a retrieval step returning 10,000 tokens, feeds those into a reasoning step, and loops three times has a cost profile that bears no resemblance to what a back-of-the-envelope calculation suggested.
Production teams are now treating context size monitoring as a first-class cost metric: tracking mean, p95, and p99 context sizes per workflow, setting alerts when they trend upward between deployments, and designing agent architectures that aggressively summarize and compress intermediate results rather than passing raw outputs through the full chain.
Observability Is Not Optional: Building Visibility for Non-Deterministic Systems
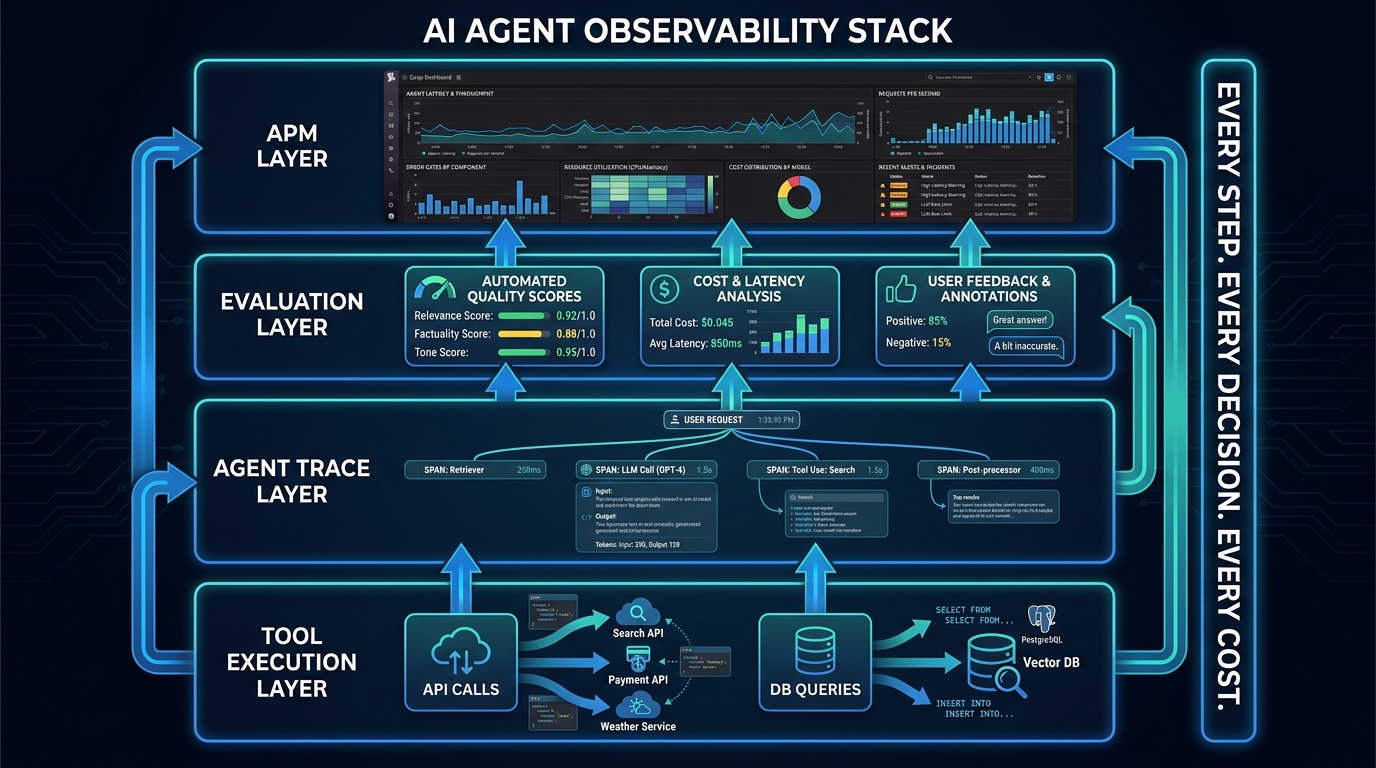
Traditional application observability rests on three pillars: logs, metrics, and traces. These pillars were designed for systems where a given input reliably produces a given output through a known, finite sequence of steps. AI agents violate all three assumptions: their output is probabilistic, their step sequence is dynamic, and the “steps” themselves include LLM reasoning that is opaque to standard tracing instrumentation.
This does not mean observability is impossible. It means that the tooling and the mental model both need to evolve.
Trace-First Observability for Agent Workflows
The most important shift is from metric-first to trace-first observability. A metric tells you that something went wrong (average response time increased, error rate spiked). A trace tells you what the agent was doing step-by-step when it went wrong — which tool calls it made, what the LLM reasoning looked like at each step, where the context was growing unusually large, and at which point in the chain the behavior diverged from expectation.
Tools like LangSmith, Langfuse, and Arize Phoenix have emerged as the specialist layer for this kind of agent-native tracing. They capture every LLM call, every tool invocation, every retrieval step, and every intermediate result in a structured trace tree that can be replayed, filtered, and analyzed post-hoc. This is not a replacement for Datadog or your existing APM infrastructure — it is a companion layer that covers the portion of the execution graph that standard APM is blind to.
In 2026, the recommended stack for production agent observability is a composite: a specialist agent tracing tool for the LLM-native layer, integrated with your existing APM platform for infrastructure-level metrics and alerts, connected through OpenTelemetry-compatible instrumentation so that agent traces can be correlated with infrastructure events when incidents cross both layers.
Online Evaluations: Automated Quality Monitoring in Production
Staging evaluations catch known failure modes. Production will find the unknown ones. This is why several teams that have been operating agents at scale for more than six months have introduced online evaluations: automated quality assessments that run against live production traffic on a sampling basis.
An online evaluation pipeline works by: sampling a percentage of production agent runs (typically 5–15%), running them through a battery of automated quality checks (factual consistency, action validity, output format compliance, safety policy adherence), and feeding the results into a quality dashboard that is reviewed weekly or alerted on when scores drop below a threshold.
This is the production equivalent of a staging eval harness, applied continuously to real traffic. It catches the gradual quality drift that occurs when model providers update base models, when production data distribution shifts from what was covered in staging, or when new edge cases emerge as the user base grows.
What to Instrument That Most Teams Miss
Beyond LLM calls and tool invocations, the instrumentation gaps that bite production teams most consistently are:
- Retry counts per step: an agent silently retrying a tool call three times before succeeding is masking reliability problems that will eventually become outages
- Tool call failure rates by tool: not just “did the agent succeed” but “which specific tool is the reliability bottleneck”
- Context window utilization per run: the leading indicator for cost runaways and context overflow errors
- Decision branch distribution: tracking which paths through the agent’s reasoning graph are being taken most frequently, to identify unexpected high-frequency edge cases
- Latency per reasoning step: individual step latency matters because agent workflows are sequential — one slow step blocks the entire chain
The Staging Gap: Why Your Agent Test Environment Is Lying to You
The most operationally dangerous gap in most AI agent deployment pipelines is not the one between dev and staging. It is the one between staging and production. Staging environments for AI agents have a structural flaw that does not exist for traditional services: they are too easy to pass.
Why Staging AI Agents Is Harder Than It Looks
For a traditional service, staging fidelity means: same code, same config, same database schema, representative data volume. For an AI agent, staging fidelity requires something much harder to achieve: representative task distribution. The question is not just whether your infrastructure handles the load — it is whether your agent handles the full diversity of tasks it will encounter in production.
A staging suite of 200 hand-crafted test cases almost certainly does not cover the long tail of edge cases that real users will generate. An agent that achieves 95% success on your curated test suite may achieve 70% success on the messy, ambiguous, adversarially phrased, and context-starved tasks that production surfaces.
Building a Production-Representative Eval Harness
The solution is not to write more test cases by hand. It is to harvest test cases from production and use them to continuously grow the staging suite. Teams doing this well have implemented a replay pipeline: a fraction of production traffic (after PII scrubbing) is captured and fed into the staging environment, used both to expand the eval harness and to surface new failure modes that the hand-crafted suite missed.
Alongside replay testing, well-structured staging pipelines for agents include:
- Adversarial test suites: specifically designed inputs intended to trigger edge cases, jailbreaks, off-policy tool use, and reasoning loops — not just happy-path scenarios
- Regression packs: every previous production incident should generate a regression test case that is permanently included in the staging suite, ensuring the same failure cannot recur without surfacing in staging first
- Shadow mode deployments: running a new agent version in production in shadow mode — processing real requests but not acting on the results — to observe behavior on live traffic before full deployment
- Model version pin testing: explicitly testing what happens when the underlying model provider updates their model version, since this can shift agent behavior in ways that pass unit tests but fail in production
Environment Separation That Actually Works
Staging environments for agents require strict access separation: the staging agent should have zero ability to call production tool APIs, access production databases, or communicate with real external services. This sounds obvious but is violated surprisingly often through shared API key management, shared secret stores, or infrastructure configurations that were copied from production without stripping live service endpoints.
One safe pattern is to build a staging “tool stub” layer: mock implementations of every tool that return realistic-looking responses drawn from anonymized production data, but that are completely isolated from live systems. This allows full behavioral testing without any risk of staging activity having production side effects.
Circuit Breakers, Rollbacks, and the Architecture of Reversible Autonomy
The microservices world solved the cascading failure problem with circuit breakers: a mechanism that detects repeated failures in a downstream dependency and stops sending traffic to it until the dependency recovers. AI agents need circuit breakers too, but for a broader set of conditions than just HTTP failures.
Designing Agent Circuit Breakers
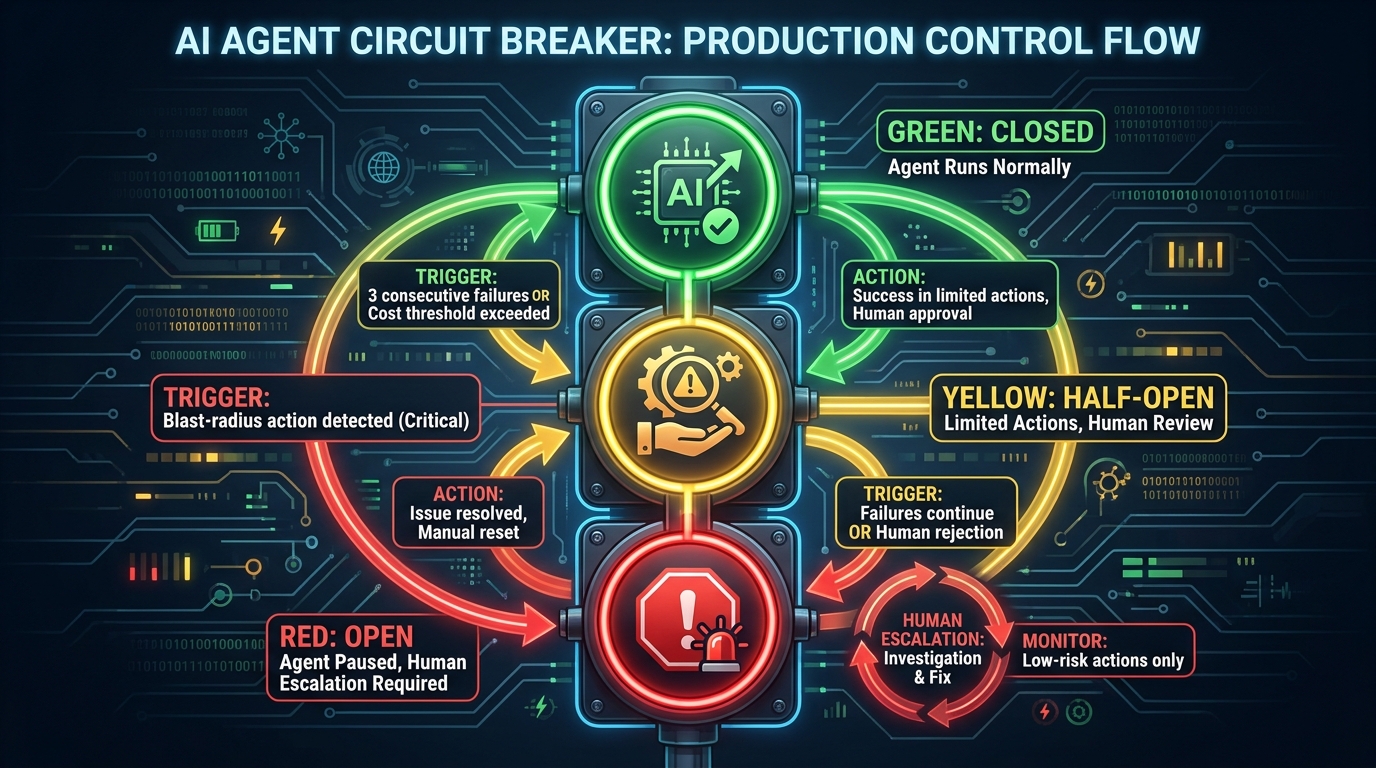
An agent circuit breaker is a deterministic enforcement mechanism — not a prompt instruction, not a soft guideline — that pauses or modifies agent behavior when predefined conditions are met. The conditions that trigger a circuit breaker in production agent systems differ from those in microservices:
- Consecutive tool call failures above threshold: if a tool has failed three times in a row, halt the workflow and escalate rather than continuing to retry
- Cost per run exceeding a defined ceiling: as described in the budget governance section, this is a hard stop, not a soft alert
- Confidence score below floor: for agents that produce evaluable outputs, if the output quality score drops below a minimum threshold across successive runs, pause the deployment
- High-blast-radius action detected: if the agent’s planned next action falls into the high-blast-radius tool category and no human approval has been received within a timeout window, pause and escalate
Circuit breakers for agents operate in three states borrowed from the microservices pattern: Closed (agent runs normally), Half-Open (agent operates in limited mode with human review of all non-trivial actions), and Open (agent is fully paused, incident is escalated to a human). Transitions between states are triggered by the conditions above, and recovery from Open back to Closed requires explicit human sign-off, not just the passage of time.
Reversibility as a Design Constraint
The most robust long-term defense against high-impact agent failures is designing workflows to be reversible from the start. For every action an agent can take, the team should ask at design time: can this action be undone? If yes, implement the compensating transaction. If no, require human approval before the action is executed.
Compensating transactions are standard practice in distributed systems — for every “do” action, you define a corresponding “undo” action that is idempotent and can be triggered automatically when a failure is detected. For agents, this means: instead of directly deleting a record, soft-delete it and schedule hard deletion after a confirmation step. Instead of sending a bulk email immediately, queue it with a delay and a cancellation endpoint. Instead of executing a financial transaction, create a pending transaction that requires a separate confirmation to settle.
This is not universally achievable — some actions are genuinely irreversible — but for the majority of agent workflows, thoughtful design can dramatically reduce the category of actions that carry existential blast radius risk.
Rollback for Agent Deployments
When a new agent version produces unexpected behavior in production, you need to roll it back. This sounds simple, but agent deployments have a complication that standard service deployments do not: the agent may have already taken actions in its live version that the previous version would not have taken. Rolling back the code does not undo the actions.
Teams handling this well treat agent deployment rollback as two separate operations: the code rollback (standard CI/CD) and the state rollback (the harder problem). They maintain a transaction log of all agent actions taken since the last stable deployment, and on rollback, a human reviews the log to determine which actions need to be manually compensated or flagged for follow-up. This is not automated — it is a deliberate human review process that trades some rollback speed for safety.
Human-in-the-Loop Without Killing Throughput
The canonical response to concerns about autonomous AI agents is to add human review checkpoints. This response is correct, but it comes with a trap: naive human-in-the-loop (HITL) implementations create approval queues that become the primary bottleneck in the entire agent workflow. You end up with an expensive AI system that cannot proceed faster than a human reviewer can clear a queue.
Calibrating Where Human Review Actually Adds Value
Not all human review is equally valuable. The insight that separates well-functioning HITL implementations from approval-queue nightmares is this: human review adds value when a human can materially improve the decision and when the cost of an error without review is high. It adds very little value — and a lot of friction — when it is applied uniformly to low-risk, easily-reversible actions where the agent is reliably correct.
The practical approach is a tiered autonomy model:
- Full autonomy tier: actions that are read-only, reversible, or have a track record of greater than 99% correctness over a meaningful sample. These execute without any human review gate.
- Asynchronous review tier: actions that are write operations with moderate blast radius, or that have a correctness track record between 95% and 99%. These execute but are logged and surfaced for post-hoc review on a daily digest. A human can flag and reverse within a defined window (e.g., 24 hours).
- Synchronous approval tier: actions with high blast radius, irreversibility, or that are operating in a low-confidence context. These require an explicit human approval before proceeding. The agent waits. The approval request is routed to a specific person with a defined SLA and an escalation path if that SLA is missed.
The key operational discipline is actively managing the boundary between these tiers over time. Actions that start in the synchronous approval tier should be candidates for promotion to asynchronous review as the agent’s track record accumulates evidence of reliability. This creates a progressive autonomy expansion path that is grounded in evidence rather than optimism.
Designing Approval Interfaces That Actually Get Used
Approval queues fail operationally not because people do not want to do reviews, but because the review interfaces are designed for engineers, not for the domain experts who should be doing the reviewing. A finance agent that needs approval for a vendor payment should surface that request in the tool the finance team already uses — not in a Slack channel that requires them to click through to a separate admin console.
Teams that have built durable HITL workflows have paid disproportionate attention to the approval UX: context-rich requests that present the relevant information without requiring the reviewer to dig for it, clear yes/no or approve/modify/reject actions, mobile-friendly interfaces that do not require a desktop session, and audit trails that record both the decision and the reasoning provided.
Alert Fatigue and the SRE Burden: When AI Agents Become the Noisy Neighbor
Before AI agents were in the picture, the median SRE team spent roughly 34% of their working week on toil — repetitive, non-creative operational work including alert triage, incident response, and manual remediation of known issues. AI agents in SRE workflows hold genuine promise to reduce this. But getting there requires navigating a period where the agents themselves become contributors to the problem they are meant to solve.
The Agent-Generated Alert Problem
Early production deployments of AI agents in engineering organizations reliably produce a wave of new alerts that existing on-call teams do not know how to triage. These are not infrastructure alerts in the traditional sense — they are behavioral anomalies in systems that were not present last quarter. The on-call engineer who gets paged at 2am because an agent’s success rate dropped from 94% to 81% needs a playbook that did not exist when the agent was deployed, because nobody wrote it.
The result, without deliberate intervention, is a net increase in on-call burden during the first several months of agent deployment, even if the long-term trajectory is a reduction. Teams that do not plan for this transition period end up with engineers who resent the agent rollout, skip alerts they do not understand, or add alert suppression rules that mask real problems.
Building Agent-Specific Runbooks Before Go-Live
The single most effective mitigation is requiring that every AI agent deployment be accompanied by a complete runbook before it is permitted to generate production alerts. The runbook should address, at minimum:
- What does a healthy agent look like? (baseline metrics: success rate, latency distribution, cost per run, tool call frequency)
- What are the most common failure modes and how should on-call respond to each?
- What is the escalation path if the on-call engineer cannot resolve the issue within a defined window?
- What is the rollback procedure?
- Who is the business owner who can be contacted for non-technical decision-making in an incident?
Teams implementing agent-first on-call — where an AI agent triages alerts before a human is paged — report 60 to 80 percent of routine pages being auto-resolved without human escalation. That is a genuine throughput gain, but only if the AI triage agent is itself well-instrumented, well-governed, and operating with a conservative autonomy posture. An AI agent triaging alerts from other AI agents without adequate oversight creates a recursive reliability problem that can be very hard to debug under incident pressure.
Controlling the Alert Surface Area
A new production AI agent deployment should start with a minimal alert configuration: a small number of high-confidence, high-severity alerts covering cost runaways, complete workflow failures, and sustained quality score drops. Additional alerts should be added incrementally as the team gains familiarity with the agent’s normal operational profile. Deploying a comprehensive alert suite on day one of production will generate a flood of alerts at various severity levels, most of which the team is not yet equipped to act on, and which will erode confidence in the alerting system as a whole.
The Agent Identity Problem: Governing Agents as Non-Human Principals

Most organizations manage their human employee access through mature identity and access management systems with well-defined provisioning workflows, access review cycles, and deprovisioning procedures. Most of those same organizations manage their AI agents through shared API keys stored in a secrets manager that nobody reviews, with permissions that were set during the initial proof-of-concept and have never been revisited.
This is the agent identity gap, and in 2026 it is one of the most consistently cited sources of serious production incidents.
Why Agents Need Identity Infrastructure
An AI agent that can call tools and access data is, from a security and governance perspective, a privileged principal in your system. It should have an identity, a defined permission scope, a credential that expires and must be rotated, an owner who is accountable for its behavior, and a deprovisioning procedure for when it is retired or replaced.
None of these things are exotic security requirements. They are standard practice for service accounts and API integrations. But agents have historically been treated as code rather than as identities, which means they have fallen outside the normal IAM governance process.
Treating agents as first-class non-human identities means:
- Every agent gets a distinct identity — not a shared identity with other agents or with the developer who built it
- Credentials are scoped and time-bounded — agents receive short-lived credentials for the specific tools they need for a specific workflow invocation, not long-lived credentials that work for everything
- There is a named human owner for every agent identity — this person is accountable for the agent’s behavior and is the escalation target for incidents
- Agent identities are included in periodic access reviews — the same quarterly or semi-annual review cycles that audit human and service account access should audit agent access
- Deprovisioning is prompt and complete — when an agent is retired, all associated credentials are revoked, all associated permissions are removed, and the identity is archived with an audit record
The Prompt Injection Threat to Agent Identities
One emerging threat specific to tool-using agents is prompt injection through tool outputs: an agent that retrieves content from an external source may encounter content crafted to manipulate its subsequent actions. For example, a document retrieval agent might fetch a web page that contains instructions designed to override the agent’s system prompt and cause it to exfiltrate data or perform unauthorized actions.
Defenses against this include: treating all tool outputs as untrusted data rather than trusted instructions, implementing input validation at the tool boundary that strips or flags content matching known prompt injection patterns, and maintaining a strict separation between the agent’s instruction context (trusted, from the system prompt) and its data context (untrusted, from tools and retrieval). This separation is as much an architectural decision as a security one, and it needs to be designed in before production deployment, not retrofitted after an incident.
What a Mature Agent Ops Stack Actually Looks Like
All of the practices described above sound significant in isolation. Together, they constitute what is emerging in 2026 as the “agent ops” discipline — the operational layer that organizations need to invest in to ship AI agents durably. It is useful to see how the components fit together as a complete stack.
The Infrastructure Layer
At the base of the stack is the compute and serving infrastructure: the environment where agents actually execute. In 2026, most production teams are running agent workloads on Kubernetes, with Ray or similar frameworks handling distributed scheduling for high-throughput workflows. The infrastructure layer is responsible for: horizontal scaling of agent workers, GPU/CPU allocation for locally-served models, and the networking isolation between agent environments (dev, staging, production).
The key ops requirement at this layer is environment parity with isolation: staging and production should run on comparable infrastructure so that performance characteristics are representative, but with strict network-level separation so that staging agents cannot reach production services.
The Observability and Governance Layer
Above the infrastructure layer sits the composite observability stack: agent-native tracing (LangSmith, Langfuse, or equivalent), connected to the organization’s existing APM platform (Datadog, Honeycomb, New Relic) through OpenTelemetry. This layer is also where cost attribution and budget governance tooling lives: per-workflow spend tracking, budget threshold enforcement, and the cost circuit breakers described earlier.
The governance components at this layer include the access control enforcement point for tool permissions (ideally integrated with the organization’s existing IAM infrastructure), the audit log for all agent actions, and the policy engine that evaluates proposed actions against blast radius rules and approval requirements before execution.
The Evaluation and Quality Layer
Above governance sits the evaluation layer: the tooling responsible for measuring whether agents are doing the right things, not just whether they are doing things. This includes the offline eval harness used in staging, the online evaluation pipeline running against sampled production traffic, and the quality dashboard that surfaces trends and alerts the team when quality scores drop.
The evaluation layer is also responsible for managing prompt versions: storing prompts in version control, supporting promotion across environments, and enabling rollback of a prompt change without a full code deployment. Prompt management is underinvested in by most teams shipping their first agent to production, and becomes acutely important the first time a prompt change causes a quality regression that needs to be reversed at 11pm on a Friday.
The Human Interface Layer
At the top of the stack sits the human interface layer: the tools and workflows through which humans interact with, review, and approve agent actions. This includes the approval interfaces for HITL workflows, the runbook management system, the on-call rotation and escalation configuration, and the dashboard through which business owners track agent performance against the business objectives the agents were deployed to serve.
This layer is often the last to be built and the first to cause operational pain. Building it well — with clear ownership, sensible UX, and genuine integration into the workflows that existing teams already use — is what makes the difference between agents that ops teams trust and agents that ops teams route around when they cause problems.
Paying the Ops Tax Upfront vs. Paying It in Outages
The operational failure rate for AI agents in production — somewhere between 70 and 88 percent across different measurements — is not primarily a technology problem. The underlying models are capable enough. The frameworks are mature enough. The cloud infrastructure is elastic enough. The failure is operational: teams building agents that work in demos and then shipping them into production environments that were never designed to sustain them.
Every capability invested in building an AI agent creates a corresponding operational obligation. The more tools the agent has access to, the more rigorous the blast radius mapping needs to be. The more autonomously it operates, the more robust the circuit breakers need to be. The more consequential its actions, the more carefully the human review gates need to be designed. The more continuously it runs, the more important the cost governance infrastructure becomes.
The Compounding Cost of Deferred Ops Investment
Teams that defer the ops investment — shipping fast and handling the operational discipline “once the agent is proven” — consistently pay a higher price than teams that invest upfront. The reason is compounding: an agent running in production without adequate observability accumulates unknown debt. When the first significant incident occurs, the debugging time is longer because the trace data does not exist. The root cause analysis is harder because the audit log was not capturing the right data. The rollback is riskier because the compensating transactions were not designed in. And the next incident is more likely because the first one did not produce the learnings needed to prevent it.
Investing in agent ops upfront — staging environments with production-representative eval harnesses, blast radius mapping before deployment, budget governance from day one, trace-based observability as a launch gate, and HITL workflows with calibrated tiers — costs real engineering time. In most production deployments, that investment is recouped within two to three months through reduced incident response time, avoided cost runaways, and faster iteration cycles enabled by reliable observability.
The Organizational Discipline That Makes It Stick
Technical infrastructure without organizational discipline does not hold. The teams running the most reliable agent deployments in 2026 share a common organizational pattern: they have explicitly designated someone as the operational owner of each agent — a named individual accountable for its behavior, its cost, and its quality. They run a weekly agent health review that checks key metrics across all deployed agents and flags any that are trending in the wrong direction before they produce an incident. And they treat every production incident involving an agent as a trigger for a structured post-incident review, with root cause analysis and a concrete action to prevent recurrence.
These are not AI-specific practices. They are standard engineering reliability practices applied to a new category of system. The teams that are getting AI agents right in production are, almost universally, the teams that recognized early that they were shipping a new class of infrastructure — and treated the operational discipline accordingly.
Actionable Takeaways
If you are preparing to ship AI agents to production, or trying to stabilize agents already running there, here are the most important places to focus your operational investment:
- Map blast radius before any agent goes live. For every tool your agent has access to, document the maximum scope of a single bad call and whether it is reversible. Gate high-blast-radius tools behind approval workflows until trust is established through a documented track record.
- Implement budget governance from day one. Set per-workflow cost caps, not just organization-level API limits. Implement three-tier budget controls: soft alert, hard degradation, kill switch. Monitor context window size as a leading indicator for cost runaways.
- Stand up a composite observability stack before launch. Pair agent-native tracing with your existing APM. Instrument retry counts, context window size, per-tool failure rates, and decision branch distribution — not just top-level success/failure metrics.
- Build staging eval harnesses from production traffic, not just hand-crafted cases. Implement shadow-mode deployments for new agent versions before full cutover. Test what happens when your model provider updates their base model.
- Design circuit breakers and compensating transactions at architecture time. Do not add these as retrofits. Build the three-state circuit breaker pattern and the compensating transaction framework before agents hit production.
- Treat agents as non-human identities in your IAM governance. Give each agent a distinct identity, scoped credentials, a named human owner, and an inclusion in periodic access review cycles.
- Write agent runbooks before generating production alerts. Every alert an agent can produce should have a corresponding runbook entry before that alert is enabled.
The ops tax on AI agents is real. The teams shipping agents that stay in production — and keep delivering value months after go-live — are the ones who paid it willingly at the start, rather than in emergency credit card alerts and post-incident reports at the end.