Ask most engineering teams where their AI agent workflows are most likely to fail, and they’ll point to the model — a bad completion, a hallucinated fact, a tool call that misfires. They’re usually wrong. The failure almost never lives in the model. It lives between the model and the human.
The handoff — the moment an AI agent pauses, escalates, or transfers a task to a person — is where production workflows actually fall apart. It’s where state gets lost, context gets misread, queues grow unbounded, and human reviewers start rubber-stamping at speed because they’re overwhelmed. It’s where the careful architecture you built upstream meets the messy, asynchronous reality of human attention.
This isn’t a conceptual problem. It’s an engineering and workflow-design problem with real, reproducible failure modes. In 2026, as agentic systems push deeper into finance, legal, healthcare, and operations, those failure modes are causing SLA breaches, compliance gaps, and eroded trust in AI systems that were otherwise working just fine.
The good news: the failure patterns are well-understood enough now that teams who study them can design around them. This post is about what those patterns look like in production, why they’re so counterintuitive, and what the workflows that actually survive look like under the hood.
We’re not going to spend time arguing that human-in-the-loop is important. Everyone knows that. We’re going to talk about how to build it so it doesn’t break.
The Handoff is the Seam — and Seams Fail First
In structural engineering, the seam between two materials is where failure initiates. Not in the steel itself, not in the concrete itself — but in the joint. The same principle holds in agentic systems. The agent logic can be well-tested. The human reviewer can be capable. The interface between them is where things go wrong.
What exactly happens at a handoff? An agent, operating autonomously up to a decision point, must:
- Recognize that it has reached a boundary it cannot or should not cross alone
- Preserve all relevant state so a human can pick up from where it paused
- Surface that state in a form a human can actually understand and act on
- Wait — potentially for hours — without losing that state
- Resume correctly once the human has acted
Each of those five steps is a separate engineering challenge. Most teams solve one or two of them well. The production systems that work solve all five deliberately.
The Boundary Recognition Problem
Agents fail to recognize handoff boundaries in two opposite directions. The first is overconfidence: the agent proceeds through a decision it was never equipped to make alone, and the error only surfaces downstream when a human eventually audits the output. The second is over-escalation: the agent interrupts a human workflow for decisions well within its competence, creating noise that trains reviewers to ignore escalations.
Both failure modes have the same root cause: the handoff boundary was never explicitly defined at the design stage. Teams often treat the question of “when does the agent ask for help?” as something the model will figure out on its own through prompting. In low-stakes demos, this works. In production, it doesn’t hold. Boundary recognition needs to be externalized as a policy — a set of conditions, confidence thresholds, and risk classifications that live outside the model’s context and are enforced by the workflow engine.
Why Most Escalation Logic is Buried in the Prompt
This is where a lot of early-stage agentic systems make a critical mistake. They encode escalation behavior entirely in the system prompt: “If you’re unsure, ask the human.” That instruction competes with every other instruction in the context, degrades over long runs as the context fills, and can’t be audited or versioned independently from the model behavior. Escalation policy belongs in the orchestration layer, not the inference layer. It should be a graph edge, a rule, a threshold — something that can be logged, tested, and changed without rewriting a prompt.
The State Transfer Problem: Why Context Windows Make Terrible Handoff Packets
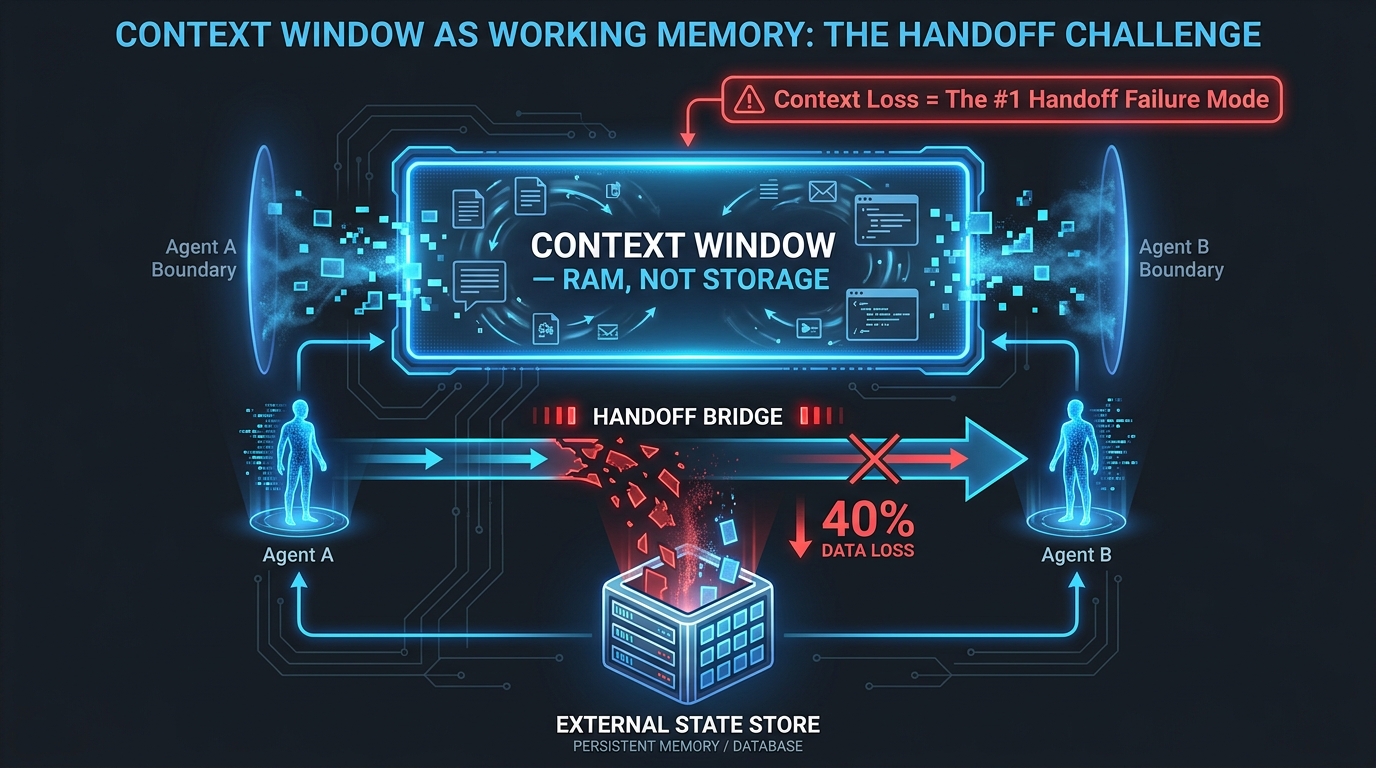
One of the most consistent failure patterns in multi-agent systems in 2026 is the naïve use of the context window as a shared state store. Teams build workflows where Agent A dumps its entire message history into Agent B’s context, or where the “handoff brief” is just a raw transcript of what the previous agent did. This seems sensible — give the next agent everything — but it introduces serious problems.
The Context Window is RAM, Not Storage
Recent engineering work across several agentic frameworks has converged on a useful reframing: treat the LLM context window as working memory, not long-term storage. Working memory is volatile, bounded, and ephemeral. It’s not a safe place to park critical state across agent boundaries or across time. When you hand off a task by passing a raw transcript, you are handing off working memory — and downstream agents inherit not just the facts, but the accumulated framing, assumptions, and reasoning errors of every prior step.
This is how automation bias propagates through multi-agent chains. If Agent A made a wrong classification in step three of a ten-step workflow, every subsequent agent — including the human reviewer who receives the handoff brief — inherits that wrong classification as implicit context. The error is baked into the way the task is framed, not surfaced as an explicit claim that can be challenged.
Structured Handoff Briefs vs. Raw Transcripts
Production-grade systems are moving toward structured handoff objects — distinct from the agent’s working context — that contain:
- What the agent accomplished: a terse, structured summary of completed steps, not a transcript
- What decision is required: the specific question or action being escalated
- Why the agent is escalating: the trigger — confidence score, risk threshold, policy rule, or tool failure
- Relevant evidence: the data, retrieved documents, or prior outputs that bear on the decision
- What the agent recommends (if anything): an explicit recommendation, flagged as an AI suggestion, not a conclusion
- What happens next: the expected resumption path based on each possible human response
The key design principle here is separation of concerns. The handoff brief is a purpose-built artifact for the human reviewer, engineered to minimize cognitive load and maximize decision quality. It is not a dump of the agent’s internal state.
External State Stores: The Infrastructure Layer Most Teams Skip
For a handoff to be reliable, the task state must be persisted outside the agent process — in a queryable, durable external store — before the escalation is triggered. If the agent crashes, times out, or is restarted between the escalation and the human’s response, the workflow must be able to resume cleanly from the last checkpoint. Teams that skip this infrastructure layer discover the problem in production when a human approves an action and nothing happens because the agent that issued the request is gone.
External state management is where frameworks like LangGraph, Apache Burr, and newer orchestration layers like Agentspan earn their value. They provide the checkpoint-and-resume semantics that make multi-hour human review loops viable. Without persistent state, any human-in-the-loop workflow that involves a wait of more than a few minutes is fragile.
Confidence Thresholds: How Production Systems Actually Decide When to Escalate
One of the most common questions in agentic system design is: “What confidence score should trigger a human review?” It’s a reasonable question with a deceptively simple-sounding answer: it depends on the cost of failure. The deceptive part is how rarely teams actually do the math.
Raw Confidence Scores Are Unsafe Alone
The expert consensus in 2026 is that raw model confidence — the probability the model assigns to its own output — is an insufficient trigger for escalation on its own. Models are systematically miscalibrated in ways that vary by domain, by task type, and by the distribution of the training data. A model can produce a high-confidence wrong answer on a document type it hasn’t seen frequently. It can produce a low-confidence correct answer on a question it knows well but that happens to involve unusual phrasing.
Production systems that work combine model confidence with at least two additional signals:
- Risk score: an assessment of how bad the outcome is if the agent is wrong — financial exposure, regulatory risk, irreversibility of the action
- Out-of-distribution signal: a measure of whether the current input resembles the inputs the system was calibrated on, typically via retrieval-quality scores, embedding distance, or anomaly detection
- Business rule flags: hard-coded conditions that trigger review regardless of confidence — amounts above a threshold, named entities in a watchlist, action types that require sign-off by policy
Tiered Autonomy, Not a Binary Switch
The most robust production architectures don’t have a single “escalate / don’t escalate” decision. They have a tiered system with typically three to five autonomy levels:
- Fully autonomous: agent acts, logs it, no human involvement
- Notify only: agent acts, human is notified asynchronously for audit
- Soft review: agent tentatively acts but flags for human confirmation within a defined window; action is rolled back if no confirmation arrives
- Hard approval: agent pauses, human must explicitly approve before action is taken
- Hard stop: agent cannot proceed at all; task is transferred to human queue
Mapping actions to these tiers requires explicit policy decisions that combine confidence ranges, risk categories, and domain-specific rules. It is not something you can delegate to the model. The escalation tier for a given action should be deterministic — given the same inputs, the same tier is always triggered — so the system is auditable and predictable.
Calibrating Thresholds Against Failure Cost, Not Model Accuracy
The practical calibration method used by experienced teams is to anchor thresholds to cost of failure, not to model accuracy metrics. A 95% accuracy model that makes errors on $500,000 transactions should have a different escalation threshold than a 95% accuracy model making errors on product categorization. The question isn’t “how often is the model right?” — it’s “what does it cost when the model is wrong, and at what volume?”
Teams that work backward from failure cost end up with tighter, more defensible threshold policies than teams that chase accuracy metrics. They also end up with fewer unnecessary escalations, which matters enormously for the operational cost of running human-in-the-loop systems at scale.
The Automation Bias Trap: When Human Oversight Becomes Theater

Of all the failure modes in human-in-the-loop design, automation bias may be the most dangerous precisely because it is invisible. The workflow appears to be working. Humans are reviewing escalations. Approval rates look normal. No one is filing incident reports. But the oversight is not real.
Automation bias is the tendency of human reviewers to defer to an automated system’s recommendation even when they have information that contradicts it. In the context of AI agent handoffs, it manifests as what practitioners now call rubber-stamp approval: the reviewer sees “AI recommends: approve,” clicks approve, and moves on — regardless of whether they actually examined the evidence.
How Approval Fatigue Creates Rubber-Stamp Conditions
The mechanism is straightforward and well-documented. Human reviewers, faced with a high volume of AI escalations where the AI recommendation is correct 90% of the time, quickly learn — consciously or not — that approving the recommendation is almost always right. Their average review time drops. Their error detection rate drops. They are now providing compliance cover, not substantive oversight.
The dynamics worsen if the escalation queue is unbounded. When reviewers arrive at a queue of hundreds of pending items, the psychological pressure to clear the queue overrides the cognitive investment needed to genuinely review each case. Studies of analogous situations — radiologists reviewing large case queues, financial auditors under time pressure — show that error detection rates drop sharply with queue length. The AI agent context is not fundamentally different.
Structural Fixes, Not Training
The expert consensus is that automation bias is a structural design problem, not a training or education problem. You cannot train reviewers out of it if the workflow itself creates fatigue conditions. The structural interventions that actually work include:
- Volume controls on human queues: hard limits on how many escalations route to a single reviewer in a given period, with overflow going to a secondary queue or a different reviewer tier
- Forced challenge interfaces: UI patterns that require the reviewer to explicitly articulate their reasoning before approving a high-risk action, not just click a button
- Blind disagreement tests: periodic injection of known-incorrect AI recommendations into the review queue, used to measure whether reviewers are catching errors — with results fed back to workflow designers, not used for performance management of individuals
- Withheld recommendations: for the highest-stakes decisions, presenting the evidence to the human reviewer before revealing the AI recommendation, so the human forms an independent judgment first
- Time minimums: hard enforcement of minimum review times for high-risk approvals, preventing sub-second rubber-stamping
The Governance Design Implication
Building real oversight — not the appearance of it — requires treating the human reviewer’s cognitive state as a system resource to be managed. That means auditing review time distributions, tracking challenge rates, measuring how often humans override AI recommendations, and building those metrics into the system’s operational dashboard. If no one is ever overriding the agent, that is not evidence the agent is always right. It is a red flag that oversight has collapsed.
Interruption Cost is Real: Designing for Operator Cognitive Load
Every escalation from an AI agent to a human is an interruption. Interruptions have costs that are non-trivial and often invisible in standard operational metrics. Research on knowledge worker interruptions consistently shows that the full cost of a context switch — setting aside current work, loading the new task into working memory, making the decision, and re-engaging with prior work — far exceeds the time spent on the interruption itself.
In AI agent handoff contexts, this creates a specific design tension: you want human oversight on the decisions that matter, but every interruption degrades the quality of whatever else the human was doing. If your agents generate 200 escalations per day to a team of five reviewers, each reviewer is being interrupted roughly every fifteen minutes throughout their workday. The cognitive load is unsustainable without deliberate design to mitigate it.
Batching and Timing as First-Class Design Decisions
One of the most underused tools for reducing interruption cost is batching. Rather than routing escalations to reviewers as they arrive — which creates continuous interruption — production systems can accumulate escalations within a defined time window (say, 30 minutes) and present them as a batch review task. The reviewer enters a focused review session, processes the batch, and returns to their primary work. This transforms 10 interruptions into one, at the cost of a modest latency increase.
Batching only works for escalations that can tolerate the wait — a decision about whether to extend a payment deadline can wait 30 minutes; a decision about whether to execute a financial transaction with a time constraint cannot. Escalation tier design must include a latency tolerance parameter that determines whether batching is appropriate.
What the Handoff UI Needs to Do in Under 30 Seconds
Given that reviewers under realistic working conditions will spend limited time on each escalation, the handoff interface must front-load the critical information. Experienced teams design for a “30-second understanding” target: a reviewer should be able to understand what the agent did, what it’s asking for, why it’s asking, and what each response option will do — all within 30 seconds of opening the escalation. This is not an arbitrary benchmark; it’s calibrated against the attention budget realistically available in a high-volume review environment.
Achieving 30-second understanding requires significant investment in the handoff brief design. It means ruthlessly eliminating boilerplate, surfacing the most decision-relevant information first, using structured fields instead of prose where possible, and providing direct links to the evidence rather than embedding it inline. It also means designing the response options to be action-oriented, not open-ended — “Approve transfer,” “Reject and return to agent,” “Escalate to senior reviewer” — not a free-text comment box.
Distinguishing Urgent from Time-Sensitive
Not all escalations that feel urgent actually are. A common mistake is routing everything as high-priority, which means nothing is high-priority. Teams that work well in production maintain a strict definition of what constitutes an urgent escalation — one where the workflow SLA will breach without a human response in a defined short window — and route everything else to standard review. This preserves the human reviewer’s capacity to give genuine attention to the escalations that actually need it.
The Four HITL Patterns That Actually Survive Production
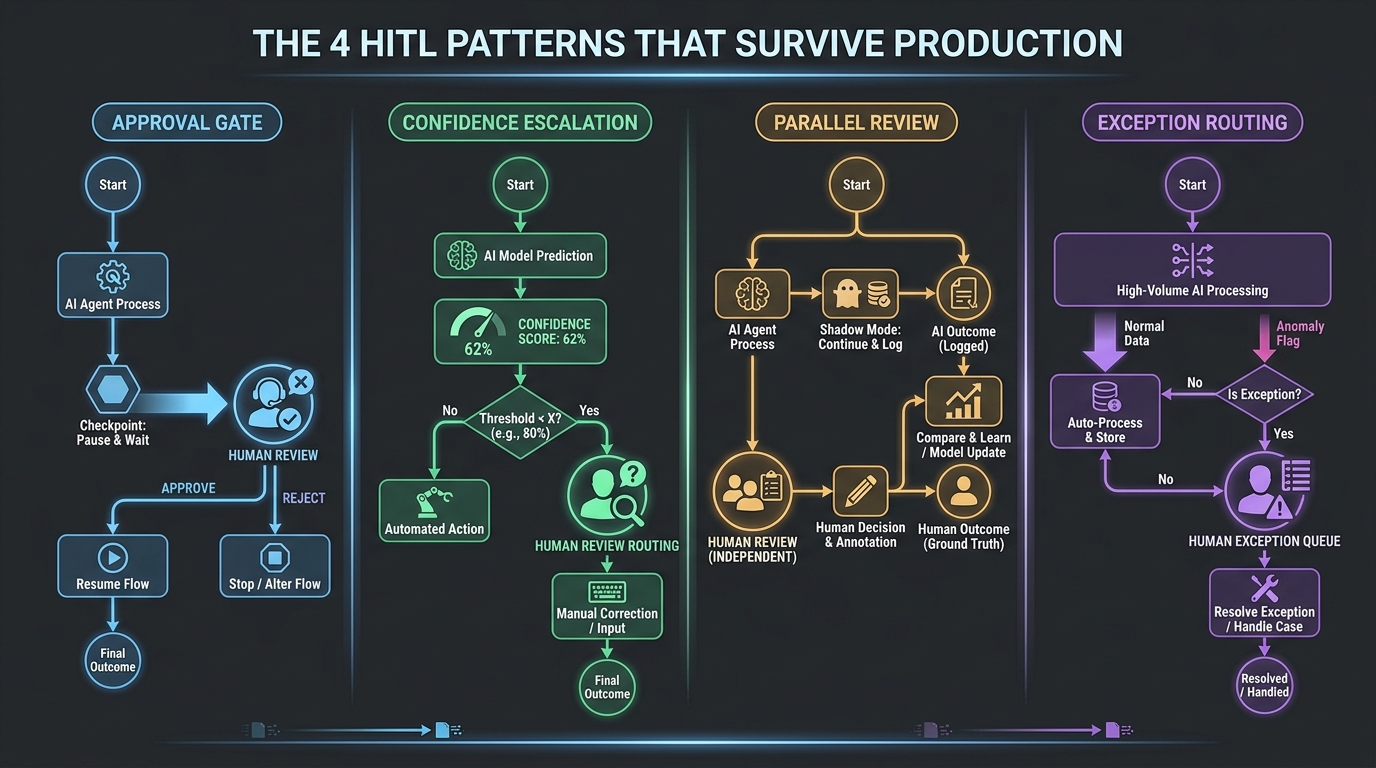
In practice, across diverse industries and agent types, human-in-the-loop workflows in 2026 have converged on four primary patterns. Each has a different profile of interruption cost, latency, reliability, and oversight depth. Choosing the right pattern for a given workflow segment is one of the most consequential design decisions in agentic system architecture.
Pattern 1: The Approval Gate
The agent reaches a predefined checkpoint, stops, and cannot proceed until a human explicitly approves or rejects. This is the most conservative pattern, the easiest to reason about, and the right choice for high-risk, low-frequency decisions where the cost of an error is severe. The downside is latency: the workflow is blocked until the human responds. Approval gates work best when the blocked workflow is not time-critical and when the decision genuinely requires human authority — contract signature, large financial commitment, policy exception.
The implementation requirement is a durable pause: the agent’s state must be persisted so that it survives crashes, restarts, and arbitrary delays while waiting for the human response. A non-durable approval gate is not an approval gate — it is a time bomb.
Pattern 2: Confidence-Based Escalation
The agent continues operating autonomously but monitors its own uncertainty. When a composite confidence score drops below a threshold (or a risk score rises above one), the agent escalates the specific decision point to human review. The rest of the workflow may continue in parallel for lower-risk steps. This is the most common pattern for high-volume workflows where most decisions are routine and only a fraction genuinely need human input.
The design challenge here is calibrating thresholds accurately enough that the escalation rate is manageable. An escalation rate above roughly 15–20% for a high-volume workflow will typically overwhelm the human review function; below roughly 1–2%, you may be missing decisions that warrant attention. The sweet spot varies by domain, but achieving it requires empirical calibration against real production data — not theoretical modeling.
Pattern 3: Parallel (Shadow) Review
The agent takes action immediately — the workflow is not blocked — but simultaneously routes the decision to a human reviewer for parallel audit. If the reviewer disagrees, they can trigger a rollback or correction within a defined window. This pattern minimizes latency impact and works well for reversible actions where the cost of a brief error is low and the cost of workflow delay is high. Customer communications, content classification, and non-financial recommendations are good candidates.
The catch is that it only works for genuinely reversible actions. Teams sometimes apply shadow review to actions that feel reversible but aren’t — a sent email, an executed database write, an API call to a third-party system. Reversibility must be confirmed at the infrastructure level, not assumed at the design level.
Pattern 4: Exception-Only Routing
The agent operates fully autonomously. Humans are not in the decision loop at all for normal cases. However, a separate anomaly detection layer monitors agent outputs and flags exceptions — statistical outliers, policy violations, out-of-distribution inputs — for human review after the fact. This is the highest-autonomy pattern and appropriate only for well-scoped, mature workflows with comprehensive monitoring. It is not a starting point; it is a destination reached after extensive calibration of the other patterns.
Exception-only routing requires strong observability infrastructure: you need to be able to detect anomalies reliably, route them appropriately, and close the feedback loop between human exception review and the agent’s calibration. Without that infrastructure, exception-only routing is just the agent operating with no real oversight.
Durable State Machines: Why Your Workflow Engine Matters More Than Your Model
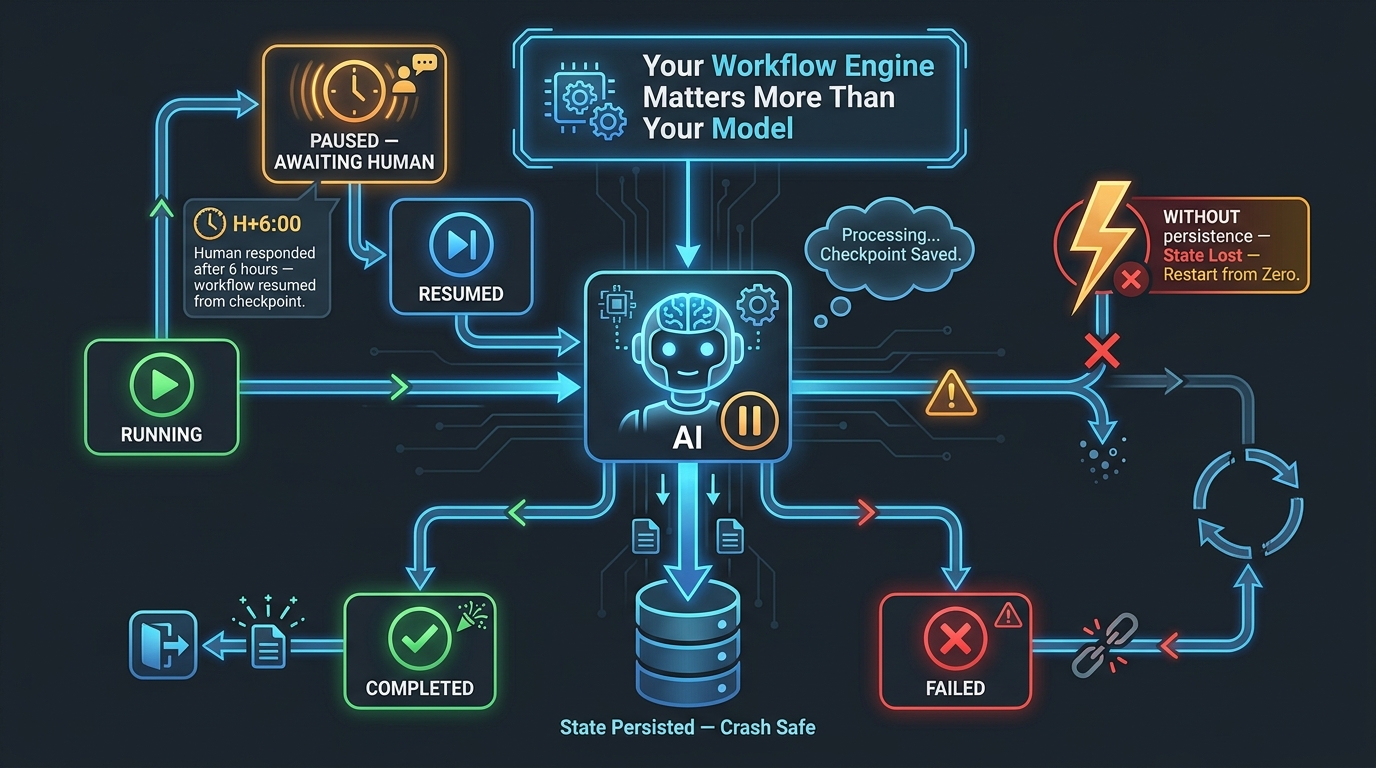
Among practitioners who have taken agentic systems through multiple production cycles, one lesson surfaces consistently: the model is rarely the bottleneck. The workflow engine is. Specifically, the inability of most naive agentic implementations to handle asynchronous human-in-the-loop pauses with durable state is the single biggest source of reliability problems in complex multi-step agent workflows.
What Durable Execution Actually Means
A durable workflow is one where the state of a running process is persisted at every meaningful transition point, such that the process can be interrupted — by a crash, a restart, a deployment, or an arbitrary-length wait for human input — and resume exactly where it left off without data loss or reprocessing. In the context of AI agent handoffs, this means that when an agent escalates to a human and then waits six hours for a response, the agent’s accumulated work, the handoff brief, the task context, and the expected resumption logic are all preserved and available when the human finally responds.
This sounds obvious. It is surprisingly uncommon in first-generation agentic implementations. Most LLM-based agent frameworks, when used naively, run as stateless request-response processes. The agent handles a task until it completes or errors. Pausing mid-task for human input — and reliably resuming hours later — requires explicit infrastructure that is separate from the model and separate from the agent runtime.
The State Machine Model for Agent Workflows
The pattern that has emerged in production-grade systems is to model the entire agentic workflow as an explicit state machine with labeled states and defined transitions:
- RUNNING: agent is executing autonomously
- PAUSED_PENDING_HUMAN: agent has escalated; waiting for human input
- HUMAN_RESPONDED: input received; validation in progress
- RESUMING: agent is reloading state and continuing
- COMPLETED: task finished successfully
- FAILED: unrecoverable error; task transferred
- TIMED_OUT: human did not respond within SLA window; escalation path triggered
The TIMED_OUT state is particularly important and often missing from first-draft designs. What happens if the human reviewer doesn’t respond? The workflow needs a defined fallback — escalate to a senior reviewer, route to a different team, fail the task with a clear error, or allow a default action if one is safe. Without a timeout policy, abandoned escalations sit in limbo indefinitely, creating invisible workflow debt that surfaces as mysterious task incompletions.
Tooling Landscape: LangGraph, Burr, and Durable Runtimes
LangGraph has emerged as the most widely adopted framework for stateful, graph-based agent workflows in 2026, and it handles human-in-the-loop interrupts natively through its interrupt API and checkpoint system. When an agent node triggers an interrupt, LangGraph serializes the current graph state to a configured backend (typically a database), and the workflow can be resumed from that checkpoint by any process that has access to the backend — including a process that starts up days later.
Apache Burr takes a more opinionated approach, modeling workflows explicitly as state machines from the ground up and providing built-in support for durable execution with hooks for human review steps. Agentspan and similar enterprise-grade runtimes add role-based approval routing, SLA tracking, and audit logging on top of the core durable execution capability.
The choice of workflow engine is a more consequential architectural decision than the choice of LLM for handoff-heavy workflows. A slightly weaker model running on a durable, well-instrumented workflow engine will outperform a state-of-the-art model running on fragile stateless infrastructure in any scenario that involves real-world delays and human interaction.
Risk Tiering: Mapping Actions to Autonomy Levels

Not all actions an AI agent takes carry the same risk. The amount of human oversight appropriate for a given action should be proportional to the severity and reversibility of the harm that could result from an error. Designing this proportionality explicitly — rather than applying a uniform policy — is one of the key differences between enterprise-grade agentic systems and demos that don’t scale.
The Two Axes of Risk Classification
Effective risk tiering classifies actions along two dimensions:
Action impact: How bad is the worst-case outcome if the agent errs? This includes financial magnitude, regulatory exposure, reputational harm, and physical or safety consequences. A miscategorized product tag is low impact. An incorrectly approved wire transfer is high impact.
Action reversibility: If the agent errs, how easily can the error be corrected? A sent notification is difficult to unsend. A database write is reversible with a compensating transaction if the schema supports it. A physical action initiated by an agent through an API (inventory commitment, contract execution, customer-facing change) may be practically irreversible within the relevant business context.
Plotting actions on a 2×2 of impact vs. reversibility gives a clear first-pass tiering: low impact, high reversibility actions are candidates for full autonomy; high impact, low reversibility actions require hard human approval. The other quadrants require judgment calls based on domain context.
Operationalizing the Risk Tier Map
A risk tier map only works if it is maintained as a living artifact and used actively in system design. Teams that build it once and never revisit it find that it drifts as the agent’s action space expands, new integrations are added, and regulatory context changes. Best practice is to treat the risk tier map as a versioned document under change control, reviewed by product, legal/compliance, and engineering at regular intervals and whenever a new agent capability is added.
The risk tier map should also drive testing strategy. High-tier actions — those that route to hard approval — should have test cases that verify the escalation fires correctly under all triggering conditions. It is not acceptable to test only the happy path (agent succeeds without escalating). The failure paths, the edge cases, and the escalation triggers are exactly what needs to be tested in a system where the cost of a miss is high.
Regulatory Alignment
In regulated industries, the risk tier map must align with external requirements. The EU AI Act’s risk classification framework creates legal obligations for human oversight on specific categories of AI decision. NIST’s AI Risk Management Framework provides a complementary structure for documenting and controlling AI system risks. For teams operating in financial services, healthcare, or any sector covered by sector-specific AI regulations, the internal risk tier map needs to be demonstrably coherent with these external frameworks — not just functionally similar, but traceable and auditable.
The Queue Problem: Why Unbounded HITL Creates New Failure Modes
Human-in-the-loop is often introduced as a safety mechanism. Teams add it to catch errors they’re worried about. What they don’t initially account for is that the human review queue is itself a system with failure modes — and if it’s not designed carefully, it creates new problems that can be worse than the ones it was supposed to fix.
Queue Depth and Review Quality
The relationship between queue depth and review quality is non-linear. Up to a moderate queue depth, reviewers perform comparably regardless of how many items are pending. Above a threshold — which varies by individual and by task complexity but is typically reached somewhere in the range of a 30–60 minute backlog — review quality degrades measurably. Speed increases, error detection drops, and reviewers begin to apply increasingly heuristic shortcuts.
This means that an escalation rate that was manageable at launch can become a quality problem as an agent system scales. If the agent starts handling five times as much volume, and the escalation rate stays constant, the human review queue grows five-fold. Without proportionate staffing or escalation rate reduction, the oversight that seemed robust at lower volume becomes unreliable at higher volume.
Queue Governance: Hard Limits and Overflow Routing
Production systems address this with explicit queue governance:
- Hard queue depth limits: when the queue exceeds a defined depth, new escalations are routed to a secondary reviewer pool or trigger a workflow pause rather than piling onto the primary queue
- SLA tracking per item: each escalation enters the queue with a timestamp and an SLA deadline; items approaching their deadline are promoted in priority and, if not reviewed in time, trigger automated escalation to a senior tier
- Escalation rate monitoring: the escalation rate is treated as a key operational metric, monitored on dashboards, and subject to alert thresholds — not just noted in post-hoc reports
- Reviewer load balancing: escalations are distributed across available reviewers based on current load, not just routed to the same team inbox, to prevent individual reviewer overload while others are underloaded
The Backpressure Mechanism
A technique borrowed from distributed systems design — backpressure — can be applied to HITL queues. When the human review queue is full, the agent system slows its processing rate rather than continuing to generate escalations that will not be reviewed promptly. This is counterintuitive (shouldn’t the agent keep working?) but correct: it is better to slow down than to create a backlog of stale escalations that eventually get rubber-stamped or ignored. The operational implication is that HITL queue capacity must be planned and provisioned like any other infrastructure resource — not assumed to be infinitely elastic.
Observability for Handoff Workflows: What to Instrument and Why
You cannot improve what you cannot see. Handoff workflows in 2026 that work well are heavily instrumented — not just for debugging, but as an operational management layer. The metrics that matter for handoff workflow health are different from the metrics that typically appear in standard LLM observability dashboards, and getting them requires deliberate instrumentation design.
The Metrics That Actually Matter
Beyond standard infrastructure metrics (latency, error rates, throughput), handoff workflows require specific instrumentation for:
- Escalation rate by action type: what fraction of each type of agent action triggers a human escalation, tracked over time to detect drift
- Mean time to human response (MTHR): how long escalations sit before a human acts, segmented by priority tier and reviewer pool
- Human override rate: what fraction of AI recommendations are rejected or modified by human reviewers — a critical signal of both oversight quality and model calibration
- Time-in-state distribution: how long workflows spend in each state machine state, to identify where bottlenecks and delays cluster
- State transition error rate: how often a workflow fails during a state transition, especially during PAUSED→RESUMING, which is where state persistence bugs surface
- Review time distribution: the distribution of time human reviewers spend per escalation — a flat distribution with a suspicious spike at sub-5-seconds is a rubber-stamp warning sign
- SLA compliance rate: what fraction of escalations receive a human response within their defined SLA window
Closed-Loop Feedback as an Operational Requirement
Observability without feedback loops is just data collection. The teams that build the best-performing handoff workflows treat their metrics as inputs to active calibration: if the escalation rate is drifting upward, they investigate whether the model distribution has shifted or whether a new action type is being misclassified. If the human override rate drops to near zero for an extended period, they investigate whether oversight has collapsed rather than assuming the model has gotten better.
This closed-loop approach — instrument, observe, investigate anomalies, calibrate thresholds and policies — is what separates handoff workflows that degrade over time from ones that improve. It requires organizational commitment to treating the HITL workflow as a system under active management, not a feature that was shipped and forgotten.
Getting Governance Right: Authority, Ownership, and SLA Design
The hardest problems in human-in-the-loop design are not technical. The workflow engine can be perfect. The confidence thresholds can be well-calibrated. The handoff briefs can be beautifully designed. And the whole system still fails if no one is clearly responsible for the escalation queue, no one has authority to make the decisions being escalated, and no one has agreed on what “reviewed in time” means.
The Authority Question
AI agent escalations often surface decisions that don’t fit neatly into existing organizational authority structures. Who approves an AI-generated contract clause? Who has sign-off authority on a risk assessment produced by an agent? In many organizations, these questions are genuinely unanswered — not because the org chart is unclear, but because the category of “AI agent recommendation requiring human approval” is new enough that authority hasn’t been formally assigned.
Launching a human-in-the-loop workflow without answering the authority question creates a predictable failure mode: the escalation arrives in someone’s queue, they’re not sure they have authority to approve it, they kick it to someone else, that person kicks it to someone else, and it eventually either expires or gets approved by whoever is least risk-averse. The resulting decision bears little relationship to what the governance design intended.
Fixing this requires pre-launch governance work: for each escalation type, define who has approval authority by role (not by name, since people change jobs), what the approval SLA is, and what happens if the SLA is breached. Document this in a workflow governance matrix that is visible to everyone involved — including the agents themselves, through their escalation routing logic.
SLA Design and Accountability
An escalation SLA is an agreement: the human reviewer will respond within X hours, the workflow will wait that long, and after that a defined fallback will trigger. Setting SLAs requires input from both the workflow design side (what latency can the workflow tolerate?) and the operations side (what review turnaround can the team realistically maintain?). SLAs that are technically correct but operationally unrealistic get breached constantly and create a culture of SLA meaninglessness.
SLA breach data should be visible to team leads and workflow owners — not just in aggregate dashboards, but at the individual workflow level, so that persistent SLA problems with specific escalation types can be investigated and addressed. SLA breaches are not just operational failures; in regulated contexts, they can constitute compliance failures that require documentation and remediation.
Ownership and Maintenance of the Handoff Workflow
Finally: someone has to own the handoff workflow as a system. Not just the agent, not just the human review process — the interface between them. In most organizations this falls uncomfortably between product, engineering, and operations, which means in practice it belongs to no one. The result is a workflow that works at launch and degrades gradually as the agent’s behavior shifts, the human team’s composition changes, and the business context evolves — with no one who has both the visibility and the mandate to detect and respond to the degradation.
Assigning explicit ownership — a person or team responsible for the health of the handoff workflow, with the observability access and the authority to change thresholds, routing logic, and review procedures — is an organizational decision, not a technical one. But it is among the most impactful decisions you can make for the long-term reliability of a human-in-the-loop system.
Building the Handoff Layer as a First-Class System
If there is one central lesson from the patterns and failures documented here, it is this: the handoff is not a feature. It is not a fallback. It is not something you add at the end to satisfy a compliance requirement or a nervous stakeholder. It is a first-class subsystem of your agentic architecture, with its own design requirements, its own infrastructure needs, its own operational metrics, and its own governance structure.
The teams that treat it that way build AI agent workflows that actually work in production — not just in demos, not just in the first week after launch, but at scale, over time, under the pressure of real organizational complexity. The teams that treat it as an afterthought build systems that look good in pilots and fall apart in deployment.
Actionable Takeaways
For teams designing or re-evaluating their human-in-the-loop workflows, here are the concrete decisions that matter most:
- Externalize escalation policy from the prompt. Encode handoff triggers as workflow-layer rules — thresholds, risk tiers, business rule flags — not as natural language instructions inside the model’s context.
- Design structured handoff briefs, not transcript dumps. Build purpose-specific escalation artifacts that tell the human what they need to know in 30 seconds, not everything the agent knows.
- Use a durable workflow engine with checkpoint-and-resume semantics. If your current agent runtime can’t survive a six-hour wait for human input without losing state, you don’t have a production-grade HITL system.
- Build a risk tier map and version it. Every action type in your agent’s repertoire should have an explicit autonomy level, reviewed and signed off by engineering, product, and compliance.
- Instrument the handoff layer specifically. Track escalation rate, MTHR, override rate, review time distribution, and SLA compliance. Treat anomalies as operational alerts, not data curiosities.
- Design against automation bias structurally. Volume limits, forced challenge interfaces, blind disagreement tests — the mechanisms that keep oversight real rather than theatrical need to be built in, not hoped for.
- Assign explicit ownership. Someone owns the health of the handoff workflow. That person has the access, the authority, and the accountability to maintain it over time.
The agents themselves will keep improving. Model capabilities will expand. Autonomous task completion will reach further into complex, high-stakes territory. But human judgment will remain necessary at defined decision boundaries for the foreseeable future — not as a limitation, but as a deliberate architectural choice that reflects the real distribution of risk and accountability in organizations.
The workflows that earn the right to expand their autonomy over time are the ones that demonstrate reliable, well-governed, measurably effective human-in-the-loop performance first. You earn autonomy by proving oversight works. And proving oversight works starts with building the handoff layer like it matters — because it does.