


There are now more AI headlines published every day than most people can read in a week. Announcements stack on top of announcements. Model releases follow model releases. Every benchmark looks like a record. Every company claims to be winning.
The result is a kind of informed paralysis — people who follow AI closely but feel less certain about what it all means than they did a year ago. That is not a coincidence. The volume of noise has grown faster than the volume of signal.
This briefing is an attempt to cut through it. Not to cover everything, but to cover what actually matters: the developments with real consequences for how AI gets built, deployed, regulated, and used in the world right now. It draws on benchmark data, market research, regulatory filings, and production deployment patterns to give a grounded picture of where things stand in 2026.
If you want hype, there is plenty of that elsewhere. If you want a clear-eyed account of the state of AI — the real capabilities, the genuine limitations, the economic shifts, and the decisions that are going to define the next 12 months — this is that.
The landscape has fractured. There are winners and losers. There are problems that have been solved and problems that remain stubbornly unsolved. There are trends that look important but are not, and a few that look boring but will matter enormously. Here is what to pay attention to.
The Model Wars: Where GPT-5.x, Claude 4.x, and Gemini 3.x Actually Stand
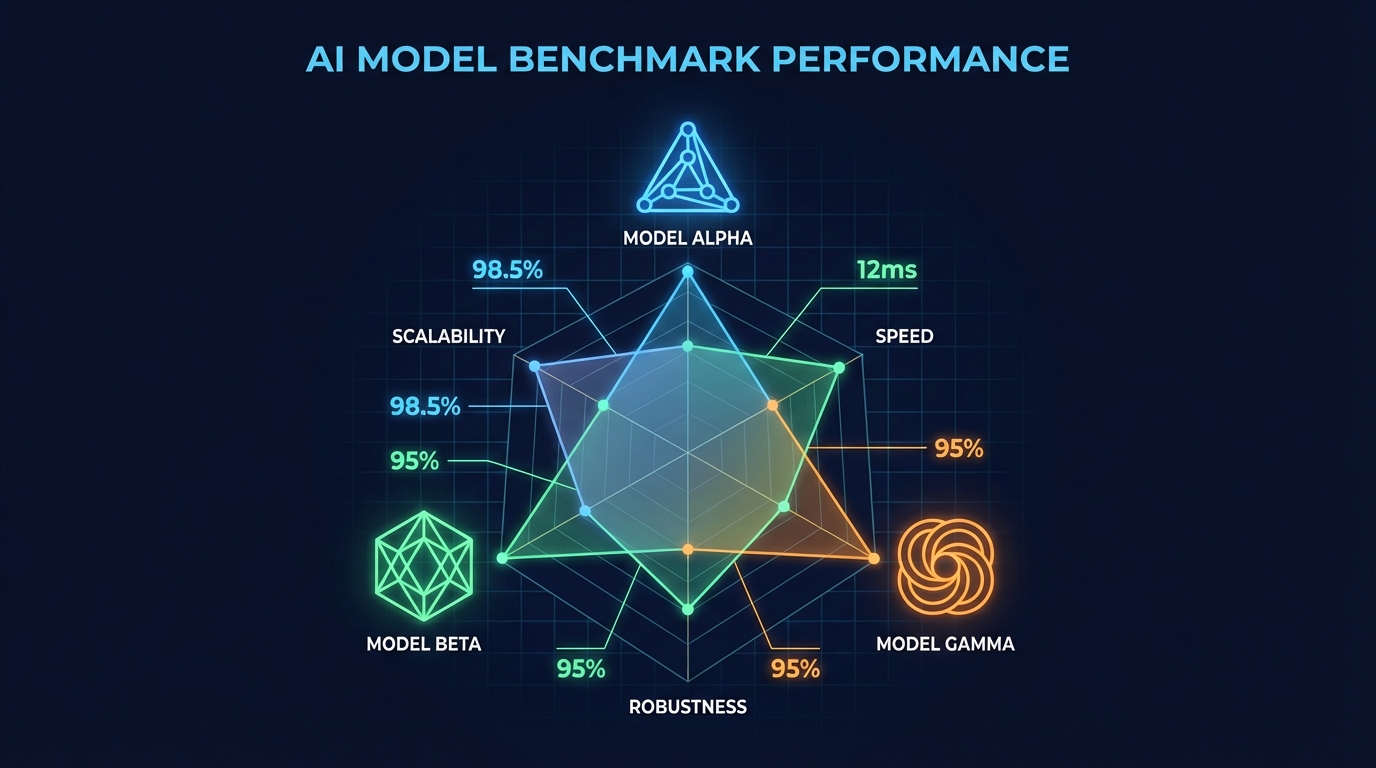
The flagship model comparison has shifted from a question of “which is best” to a more useful question: “best at what, for whom, and at what cost?” The 2026 model landscape has three dominant closed-source players — OpenAI’s GPT-5.x series, Anthropic’s Claude 4.x line, and Google’s Gemini 3.x family — each with a meaningfully different performance profile.
GPT-5.x: The Versatility Standard
OpenAI’s GPT-5 series has established itself as the benchmark standard for general versatility. GPT-5.2 and GPT-5.4 post some of the highest aggregate scores across multiple evaluation categories. On SWE-Bench Verified — the most rigorous real-world coding evaluation available — GPT-5.x scores hit 80%, making it the top performer in production software engineering tasks. On GPQA Diamond, a graduate-level science reasoning benchmark, the model scores 92.4% on GPT-5.2 and climbs to 96.1% on the 5.4 variant. On AIME (mathematics competition problems), GPT-5.4 reaches a near-perfect 100%.
The GDPVal benchmark, which evaluates economic reasoning and tasks that approximate expert-level analysis, shows GPT-5.4 at 83.0% — matching human expert performance. That single data point represents something that would have been difficult to believe as recently as 18 months ago.
GPT-5.4 “Thinking” also crossed the 75% mark on OSWorld-V, a benchmark that tests autonomous execution of multi-step workflows across real software environments. The human baseline for that benchmark sits at 72.4%, which means the model has technically surpassed humans on desktop task execution. The caveat, as always, is that benchmarks measure narrow performance under controlled conditions — but the trajectory is clear.
Claude 4.x: The Coding and Reliability Play
Anthropic’s Claude 4.x lineup has carved out a distinct position centered on coding quality, low hallucination rates, and what practitioners describe as “predictable behavior” in agentic contexts. Claude Opus 4.6 achieves 65.4% on Terminal-Bench, a coding evaluation that tests real terminal-level debugging and code execution tasks, and it powers Cursor — currently the most widely adopted AI coding environment among professional developers.
Where Claude differentiates is in the combination of accuracy and consistency. On the Humanity’s Last Exam (HLE) benchmark, a dataset of extremely difficult questions across disciplines, Claude Opus 4.6 reaches 53.1% when tool use is enabled — a notable result for a test designed to be near-unsolvable. Critically, Claude models post the lowest hallucination rates in standardized summarization evaluations, which has made them the default choice for regulated-industry applications where fabrication carries real legal and financial exposure.
Gemini 3.x: The Enterprise Scale Architecture
Google’s Gemini 3.x family has made a different bet: context, speed, and infrastructure integration. Gemini 3.1 Pro posts a 94.1% on reasoning benchmarks and processes up to 2 million tokens in a single context window — a capability that is not matched at scale by any competitor. For use cases involving extremely long documents, large codebases, or complex multi-source research synthesis, that context window is practically the only number that matters.
Gemini’s integration with Google Workspace through automated SpreadsheetBench scoring at 70.48% is also significant for enterprise teams already embedded in Google’s ecosystem. The competitive positioning is clear: Gemini is the choice when scale, speed, and native cloud integration matter more than raw benchmark performance on any single axis.
What This Means in Practice
The practical implication of all this is that model selection is no longer a question of finding the “best” AI. It is an architecture and use-case decision. Teams running coding agents should evaluate Claude or GPT-5.x. Teams doing large document analysis need to look seriously at Gemini’s context capabilities. Teams where hallucination risk in legal or medical contexts is a compliance issue should prioritize Claude’s reliability profile. The days of one model being right for everything are largely over.
From Chatbots to Agents: The Real Shift Happening in Production

The most consequential development in applied AI right now is not a new model. It is the shift from AI as a tool you query to AI as an agent that acts. This distinction sounds subtle but has profound operational implications.
What the Adoption Numbers Show
According to Gartner, fewer than 5% of enterprise applications embedded task-specific AI agents in 2025. That figure is forecast to reach 40% by the end of 2026. McKinsey data from late 2025 shows 62% of organizations are experimenting with AI agents, while only 23% have scaled in even one function. PwC’s figure puts enterprise AI agent adoption at 79% — a number that sounds high until you realize “adoption” in most surveys means “at least one pilot running somewhere.” The gap between piloting and scaling is where most organizations are stuck.
Among the Global 2000 companies, 72% have moved beyond pilots into at least some production deployments — but “production” at large enterprises often means one workflow in one business unit, not widespread integration. The headline adoption numbers obscure a more complicated reality on the ground.
Where agentic AI is genuinely scaling, the results are striking. High-performing deployments report 50-65% of customer support inquiries handled autonomously, 25-40% faster resolution times, and 20-30% cost reductions in the workflows where agents operate. One manufacturing company, Danfoss, reports automating 80% of certain operational decisions with near-instant response times — a result that would have required a significant human team to achieve manually.
What Is Actually Meant by “Agentic AI”
The term gets used loosely enough to be almost meaningless, so it is worth being precise. An AI agent, in the meaningful sense, is a system that: sets or receives a goal, devises a plan to achieve it, takes actions in the world (calling tools, APIs, or other systems), observes the results of those actions, and adjusts its behavior accordingly — all without requiring step-by-step human direction for each action.
This is distinct from a chatbot (which responds to queries), a code autocomplete tool (which suggests the next token), or an automated script (which executes a fixed sequence). An agent is goal-directed and adaptive. That capability introduces both its power and its risk. An agent that can achieve goals can also pursue them in ways you did not anticipate.
The Failure Pattern
Gartner has issued a significant warning alongside its adoption forecast: more than 40% of AI agent initiatives currently underway risk being abandoned by 2027. The reasons cited are governance gaps, unclear ROI, and cost management failures. This is consistent with a pattern visible across enterprise technology adoption cycles — wide experimentation, a painful winnowing, and then consolidation around what actually works.
The teams getting agentic AI into real production successfully share a few common traits. They start with workflows that are clearly bounded — not “improve our customer experience” but “handle tier-1 support tickets about order status.” They instrument heavily and monitor obsessively. And they design for human escalation from day one, treating human-in-the-loop not as a temporary crutch but as a permanent feature of the system architecture.
The Multi-Agent Architecture Moment
The conversation about AI agents has rapidly outgrown single-agent systems. In 2026, the leading edge of deployment is multi-agent architecture — networks of specialized agents coordinated by orchestrators to handle complex workflows that no single agent could manage alone.
Why Single Agents Hit Walls
A single AI agent working on a complex enterprise task runs into practical limits quickly. Context windows fill up. Errors compound. The combination of planning, execution, verification, and edge-case handling exceeds what one model can reliably sustain. Multi-agent systems address this by distributing work across agents that each have narrow, well-defined roles.
A common production pattern looks something like this: an orchestrator agent receives a high-level task, breaks it into sub-tasks, routes each to a specialist agent (one for data retrieval, one for analysis, one for drafting, one for validation), collects and assembles the outputs, and delivers a finished result. If any specialist agent fails or produces output below a confidence threshold, the orchestrator can retry, escalate, or flag for human review.
Forrester and Gartner both identify 2026 as the inflection point for multi-agent adoption. Current data shows 66.4% of the enterprise AI agent market now focusing on coordinated multi-agent architectures rather than single-agent solutions. The protocols enabling this — Agent-to-Agent (A2A) communication standards and the Model Context Protocol (MCP) — have matured enough to allow agents built on different underlying models to collaborate within shared workflows.
Production Examples and What They Show
In customer support, Microsoft and IBM have deployed multi-agent systems where one agent handles intent classification, a second retrieves relevant documentation or account data, a third generates a response, and a fourth validates tone and policy compliance before the message is sent. The process happens in seconds and handles what previously required three to five manual steps across different systems.
In sales, multi-agent pipelines are handling the full sequence from lead qualification (data gathering and scoring agent) to outreach (personalization agent) to scheduling (calendar management agent) to proposal generation (drafting agent) to contract review (legal check agent). Companies report cycle time reductions of 70-80% in these sequences while keeping humans in decision-making roles at the end of the pipeline.
The strategic implication is significant: the value of AI in 2026 is increasingly a function not of which model you use, but of how well you architect the system of agents around your specific workflows.
Open Source vs. Closed: The Economics Are No Longer a Debate
A year ago, the open source versus closed model debate was largely about performance. The argument was that open models were cheaper and more flexible but lagged meaningfully behind the frontier on capability. In 2026, that argument has mostly collapsed.
The Benchmark Convergence
Meta’s Llama 4, DeepSeek R1 and V3.2, and Alibaba’s Qwen 3.5 now match or exceed closed models on several key benchmarks. On MMLU (broad knowledge), open models score 92.0% versus approximately 92% for leading closed models. On MATH-500, open models reach 98.0% versus approximately 97% for closed. On GPQA Diamond, open models score 88.4% versus approximately 85% for leading closed alternatives.
The remaining performance advantages for closed models are real but narrowly defined. On SWE-Bench for production coding, closed models lead at approximately 80% versus 76.4% for the best open alternatives. On complex agentic tasks and human preference evaluations (Chatbot Arena), closed models retain a meaningful edge. In the categories that matter most for cutting-edge software development and open-ended reasoning, the frontier closed models are still ahead — but the gap is measured in percentage points, not categories.
The Cost Gap Is the Real Story
Where open source has won decisively is on economics. DeepSeek’s API pricing runs at $0.028 to $0.28 per million input tokens — 10 to 30 times cheaper than equivalent OpenAI pricing. Meta’s Llama 4 can be self-hosted at inference costs that fall to near-zero at sufficient volume. Open models now hold 62.8% of the enterprise AI market by deployment share, up from a minority position just 18 months ago.
DeepSeek’s architectural innovations deserve specific attention. Their Multi-Head Latent Attention (MLA) reduces KV cache memory requirements by 93% — a genuinely significant engineering achievement that makes running large models substantially cheaper. Their Group Relative Policy Optimization (GRPO) cuts reinforcement learning costs by 50%. These are not marginal efficiency gains; they represent a meaningful reduction in the infrastructure cost of running capable AI systems.
The strategic question has shifted from “should we use open or closed models?” to “for which specific use cases does the performance premium of closed models justify the cost difference?” For many applications — internal search, document summarization, classification, moderate-complexity code generation — the answer is that it does not. Closed models remain the clear choice for frontier research, complex reasoning tasks, and applications where marginal performance differences have outsized consequences.
The Sovereignty Dimension
There is a third consideration that has grown substantially in importance: data sovereignty and regulatory compliance. Sending data to a third-party API creates privacy exposure, creates jurisdictional questions under frameworks like GDPR and the EU AI Act, and introduces vendor dependency risk. For organizations in regulated industries — healthcare, financial services, government — self-hosting an open model is often the only viable architecture, regardless of performance comparisons. The open source movement’s growth in enterprise adoption is partly a performance story and partly a compliance and control story.
The Hallucination Problem Is Not Solved — It Has Just Become Situational
One of the most consequential misunderstandings circulating in 2026 is the belief that hallucinations have been solved, or are close to being solved. The actual picture is more complicated and more important to understand correctly.
The Task-Dependent Reality
On standardized summarization benchmarks, the best models now achieve hallucination rates below 1%. Google’s Gemini 2.0 Flash posts approximately 0.7% on Vectara’s summarization leaderboard. OpenAI and Gemini variants cluster around 0.8-1.5%. These are genuinely impressive numbers, and they represent real improvement over models from 18-24 months ago.
But hallucination rates are not a fixed property of a model. They vary dramatically by task type. Move from summarization to legal query answering, and rates jump to 18.7%. In medical information queries, the rate is 15.6%. In financial analysis, it reaches 17%. The tasks where hallucination is most damaging — regulated professional contexts, decisions with legal or financial consequences, medical information — are exactly the tasks where hallucination rates remain high.
The Enterprise Damage Is Real
The operational impact of this is not theoretical. Research from 2026 shows that 47% of enterprise AI users have made at least one major business decision based on hallucinated content. Industry losses attributed to AI fabrication were estimated at $67.4 billion globally in 2024, a figure that does not yet account for the expanded deployment of 2025 and 2026.
Real-world incidents document the exposure clearly. Deloitte’s AI-generated report containing fabricated citations triggered partial government contract refunds. Healthcare organizations report delaying AI adoption specifically because of hallucination risk — 64% of healthcare organizations have deferred implementation while waiting for reliability standards to improve. Legal drafting tools with hallucination rates in the 18% range create systematic liability exposure in contract generation workflows.
What Actually Reduces the Risk
There are two mitigations that have demonstrated real effectiveness in production. Retrieval-Augmented Generation (RAG) — anchoring the model’s responses to a specific, verified document set rather than allowing it to draw on its full training distribution — reduces hallucination rates by 40-71% depending on the implementation. Grounding AI outputs in source material that can be audited is the single most reliable method currently available.
The second effective mitigation is architectural: building verification layers into agentic pipelines so that outputs are checked by a separate validation process before being delivered. This means treating hallucination as a system design problem rather than a model quality problem. You cannot fully fix a model’s tendency to confabulate, but you can build pipelines that catch and reject confabulated outputs before they reach users or downstream processes.
The practical takeaway is this: any organization deploying AI in contexts where accuracy is a compliance or liability matter needs active hallucination mitigation built into the architecture. Trusting model-level improvement to solve the problem is not a defensible position given the current evidence.
AI Pricing Has Collapsed — What That Actually Means for Builders
One of the most underreported stories in AI right now is what has happened to inference costs. The economics of building with AI have changed so dramatically that many of the cost assumptions embedded in 2024-era business cases are now incorrect — often in a favorable direction.
The Scale of the Collapse
GPT-4-level performance cost approximately $30 per million tokens in early 2023. The same level of capability now runs at under $1 per million tokens — a roughly 30x reduction in under three years. GPT-4o currently prices at $2.50-$5.00 per million input tokens and $10.00-$15.00 per million output tokens, itself representing an 83% reduction from earlier GPT-4 pricing.
At the budget end of the market, the numbers are more striking. DeepSeek’s API prices start at $0.028 per million input tokens. Google’s Gemini Flash variants offer a 1 million token context window at approximately $0.38 per million total tokens. Claude Haiku 3 — a highly capable, fast model — runs at $0.25 input and $1.25 output per million tokens. In January 2026 alone, 109 of 302 tracked AI models reduced their prices.
Forecasts suggest a further 50% price reduction across the market over the course of 2026, driven by competition, infrastructure efficiency gains, and the sustained pressure from open-source alternatives. Nvidia’s latest generation of AI chips achieves 105,000 times lower energy use per token than a decade ago, and those gains are gradually flowing through to inference pricing.
What This Changes for Product Teams
The cost collapse has several direct consequences for anyone building AI-powered products. Use cases that were economically unviable at 2023 inference prices are now viable. AI-powered features that would have cost tens of thousands of dollars per month to run can now be offered at a cost that supports meaningful margins.
More importantly, the cost structure changes what kind of AI architectures are practical. Multi-step agentic pipelines — where a task might involve 10-20 separate model calls for planning, tool use, verification, and synthesis — were prohibitively expensive when tokens cost $30 per million. At current prices, a 20-step pipeline processing a moderate-complexity task might cost a few cents. That is a real architectural unlock that is not fully reflected in current product design thinking.
The flip side is that cheap inference has also made it easier to build low-quality AI products quickly. When cost is less of a constraint, the quality bar for what gets shipped tends to drop. Teams with the discipline to invest the lower costs in quality, reliability, and user experience will differentiate; teams that use the cost savings to move faster and ship more will find themselves competing in an increasingly crowded and undifferentiated space.
The Infrastructure Reality: Energy, Compute, and the $700B Build-Out

The AI compute build-out underway right now is among the largest capital investments in infrastructure in modern history. Understanding its scale — and its constraints — is necessary context for anyone thinking seriously about where AI capability goes from here.
The Numbers
The four major hyperscalers — Alphabet, Microsoft, Meta, and Amazon — have committed a combined $700 billion in AI infrastructure investment for 2026. This follows $580 billion spent in 2025. Global data center electricity consumption hit 415 TWh in 2024, representing 1.5% of total global electricity use. By 2026, that figure is projected to exceed 500 TWh — approximately 2% of global electricity. The IEA projects 15% annual growth through 2030, reaching 945 TWh — nearly doubling current consumption within four years.
In the United States, data centers’ share of national electricity consumption is forecast to reach 6.7% to 12% by 2028 depending on the growth scenario. That creates a structural problem: electricity grids were not designed for this rate of demand growth. The U.S. currently faces a projected power deficit of up to 25% by 2028, driven primarily by data center demand. This is not an abstract concern — it is already creating real siting constraints, permitting bottlenecks, and political pressure in every major data center market.
The Morgan Stanley Intelligence Forecast
Morgan Stanley’s early 2026 research forecast a 10x compute increase in the near term, with that scale of compute expansion potentially doubling the effective “intelligence” delivered by AI systems. If that relationship between compute and capability holds — and it is not guaranteed — then the systems available in 18-24 months could be substantially more capable than current flagship models on every dimension, including the complex reasoning tasks where improvements have recently slowed.
What makes this uncertain is the power constraint. The U.S. electricity infrastructure cannot currently support the compute build-out at the pace that investment suggests. Power access, not capital availability, is the binding constraint on AI scaling in 2026. Every major data center project is running into power availability as the primary limiting factor.
The Hardware Supply Chain
Nvidia remains the dominant supplier of AI accelerator chips, and its position in the supply chain gives it extraordinary leverage over the pace of AI deployment. The Blackwell generation of GPUs — deployed at scale in 2025 and 2026 — represents a significant efficiency advance, but demand has outpaced supply through most of the past 18 months. Alternative chip architectures from AMD, Intel, and a growing number of AI-specific startups are making progress, but the ecosystem of software, tooling, and deployment expertise built around Nvidia CUDA remains a substantial moat.
For organizations that are not hyperscalers, the infrastructure constraints mean that access to compute continues to flow primarily through cloud providers at variable pricing, or through a limited number of specialized AI cloud providers. The strategic implication is that compute efficiency — doing more with fewer tokens, building models that run well on smaller hardware, optimizing inference pipelines — is a significant competitive advantage that goes beyond pure cost management.
The EU AI Act Enforcement Clock Is Ticking

August 2, 2026 is the date that every organization deploying AI in or to the European Union needs to have on their calendar. That is when the EU AI Act’s core enforcement provisions come into effect — and the penalties for non-compliance are not symbolic.
What Comes Into Force on August 2
The August 2026 milestone activates the full range of obligations for high-risk AI systems (those covered under Annex III of the Act, including AI used in employment, education, law enforcement, healthcare, and critical infrastructure), transparency requirements under Article 50, and market surveillance obligations enforced at both national and EU levels. The EU AI Office assumes central oversight responsibilities for general-purpose AI (GPAI) models — the category that includes most large language models.
For GPAI model providers, the Act requires training data summaries, copyright compliance documentation, and incident reporting frameworks. For high-risk system deployers, the requirements are more extensive: risk assessments, data governance documentation, transparency disclosures to users, human oversight mechanisms, conformity assessments, and post-market monitoring programs.
The Penalties
Fines under the EU AI Act reach up to €35 million or 7% of global annual turnover for the most serious violations — placing prohibited AI systems on the market. Violations of high-risk system requirements attract fines up to €15 million or 3% of global turnover. For large AI companies, these are not rounding errors. They are existential-level penalties that require genuine compliance infrastructure, not a checkbox exercise.
What Organizations Consistently Underestimate
The compliance challenge for most organizations is not the prohibition on clearly banned systems — nobody who is paying attention is deploying social scoring or real-time biometric surveillance in public. The challenge is the documentation and governance infrastructure required for high-risk system compliance. Risk assessments need to be maintained and updated. Data governance needs to be auditable. Human oversight mechanisms need to be verifiable, not nominal.
For SMEs, the compliance cost is particularly acute. Early 2026 assessments indicate that small and medium-sized enterprises face disproportionate compliance burdens relative to their AI deployments. The regulatory sandbox provisions in the Act are intended to provide some relief, with national AI regulatory sandboxes required to be operational by August 2026 — but accessing them requires active engagement with national authorities that many smaller organizations have not yet made.
The practical advice for organizations operating in or selling to EU markets is straightforward: if you have not mapped your AI deployments against the Act’s risk classification framework, you are already behind schedule. The February 2, 2026 Commission guidance on Article 6 post-market monitoring was the last major guidance publication before enforcement begins. The window for strategic compliance preparation is closing.
What AI Is Actually Doing to Work and Jobs in 2026

The question of what AI is doing to employment is generating more heat than light in most public discourse. The alarmist framing (“AI is eliminating jobs”) and the dismissive framing (“AI just creates new jobs, it always has”) are both insufficient for understanding what is actually happening on the ground in 2026.
The Displacement Numbers
The data shows displacement is real, targeted, and concentrated in specific roles. In the United States, 55,000 AI-attributable job losses were tracked between January and November 2025. The first two months of 2026 saw 32,000 tech-sector layoffs. Salesforce eliminated 4,000 customer support positions citing AI capability. Among employers, 38% have reduced entry-level white-collar hiring, citing AI’s ability to handle work that previously justified those hires.
The roles at highest risk follow a consistent pattern: roles where the primary work involves codifiable, repeatable processing of information. Computer programmers at 45% displacement risk. Customer service representatives at 42%. Data entry clerks at 40%. Medical records professionals at 40%. The 65% of retail roles estimated to be automatable by end of 2026 represents a particularly large category.
AI-vulnerable sectors are already showing employment effects. Computer systems design employment is down approximately 5% from 2022, a trend running counter to the broader labor market. Young workers are disproportionately affected, because they cluster in the entry-level roles that AI is most capable of handling.
The Creation Side
The World Economic Forum’s analysis projects 170 million new jobs created by AI by 2030, against 92 million displaced — a net positive if the projections hold. But projections about job creation are structurally less reliable than projections about displacement, because the new roles require skills that are unevenly distributed and slow to develop.
What is observable now, not projected, is the wage premium on AI-augmented roles. Positions requiring AI skills carry a 23% wage premium over comparable non-AI roles across industries. In some technical specialties, that premium reaches 56%. The demand for mid-level talent — workers with 5-10 years of experience who can work effectively alongside AI tools — is particularly strong. “AI agent orchestrator” roles, which barely existed two years ago, are among the fastest-growing job categories in enterprise technology.
The Skills Gap Is Not About Technical Depth
A common assumption is that the skills gap between what employers need and what the workforce can provide is primarily a technical one — that the problem is a shortage of machine learning engineers and AI researchers. That is partially true but increasingly secondary. The more widespread scarcity is in workers who can do substantive professional work effectively alongside AI tools — who can evaluate AI outputs critically, identify errors and hallucinations, prompt effectively for their domain, and make judgment calls in situations where AI has high confidence but is wrong.
This is a problem that no amount of AI capability improvement solves, because it is fundamentally about human judgment. Organizations that invest in developing AI literacy — not just technical AI skills — across their professional workforce are building a competitive position that compounds over time and is not replicable by simply buying more AI tools.
The Signal vs. the Noise: What Actually Matters Over the Next 12 Months
Not every AI development that gets coverage is worth the attention it receives. Here are the specific trends and signals worth tracking over the next 12 months — and a few things that are consuming attention but likely matter less than they appear to.
Watch Closely: Agent Reliability Standards
The most important technical problem in applied AI right now is not capability — models are capable enough for most enterprise use cases. The problem is reliability. Agents that work well 90% of the time and fail unpredictably the other 10% are not deployable at scale in workflows that matter. The next 12 months will see significant work on agent reliability standards, error handling protocols, and the infrastructure needed to make agentic systems genuinely production-grade rather than impressive in demos.
Watch for the emergence of reliability benchmarks specifically designed for agentic systems — not accuracy on single queries but consistency, error recovery, and graceful degradation under adversarial or edge-case conditions. Organizations that can demonstrate reliable agentic performance on these measures will have a significant advantage in regulated-industry deployments.
Watch Closely: The MCP and A2A Protocol Ecosystem
The Model Context Protocol (MCP) and Agent-to-Agent (A2A) protocols are the plumbing of the multi-agent future. They are boring to read about and consequential in practice. As these protocols mature and adoption grows, the ability to compose agents from different providers into coherent workflows will become significantly easier. The organizations that build expertise in this layer now — before it becomes commoditized — will have a head start in multi-agent architecture that matters.
Watch Closely: Reasoning Model Costs
The current generation of frontier reasoning models — GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro — are expensive relative to their lighter-weight counterparts. The economics of complex reasoning at scale will be determined by how quickly reasoning capability can be achieved at lower inference costs. Expect significant competition here, driven by DeepSeek’s MLA and GRPO innovations and Meta’s continued push on Llama efficiency. If reasoning-quality outputs can be delivered at near-commodity prices, it will trigger another wave of previously uneconomic use cases becoming viable.
Probably Less Important Than It Looks: Benchmark Racing
The quarterly benchmark update cycle — where every major lab announces its latest score on MMLU, GPQA, AIME, and similar evaluations — receives substantial coverage but carries diminishing signal value. When multiple models score above 90% on any given benchmark, the benchmark stops discriminating meaningfully between them. The labs know this and work to stay ahead of the measurement curve, but the gap between benchmark performance and deployment performance remains significant in practice.
More useful than benchmark scores for most practitioners is direct testing on your specific use cases with your specific data. That is the only measure that matters for production decisions.
Probably Less Important Than It Looks: AI Companion and Consumer Features
Consumer-facing AI features — AI companions, AI search enhancements, AI-generated social media content — attract significant media coverage and represent real product revenue for the major labs. For practitioners thinking about enterprise AI deployment, they are largely irrelevant. The developments that matter for building AI into business processes are happening at the infrastructure, model reliability, and agent coordination layers — not in the consumer experience layer.
Conclusion: How to Read the Signal
The AI landscape in 2026 is genuinely complex in ways that resist simple characterization. It is not “early days” — production deployments are delivering real results across industries, and the foundational capabilities of current models would have seemed speculative as recently as 2023. But it is also not “solved” — hallucinations remain a genuine risk, agentic systems fail in unpredictable ways, regulatory compliance infrastructure is still being built, and the energy costs of scaling are increasingly a structural constraint.
The framework that makes the most sense for navigating this complexity is not to identify the most impressive capability or the most alarming risk and extrapolate from it. It is to maintain a clear-eyed view of what the evidence actually shows, distinguish between what has been demonstrated in production and what has been demonstrated in benchmarks, and make deployment decisions based on the specific demands of the use case rather than general excitement about the technology.
Practical Takeaways
- Model selection is a use-case decision, not a brand loyalty decision. Match the model’s strengths — GPT-5.x for versatility, Claude for reliability in regulated contexts, Gemini for large-context tasks — to the specific requirements of each workflow.
- Treat hallucination as a system design problem. Build RAG, verification layers, and human escalation paths into any pipeline deployed in high-stakes contexts. Do not rely on model-level improvements to solve this at your layer.
- The open-source economics have fundamentally shifted. Re-evaluate your model choices if cost and data sovereignty are constraints. The performance gap for most enterprise use cases no longer justifies premium pricing across the board.
- If you are in the EU or sell to EU customers, August 2, 2026 is a hard deadline. Map your AI deployments against the risk classification framework now. The documentation and governance infrastructure required for compliance takes time to build.
- Invest in AI literacy, not just AI tools. The wage premium and competitive advantage flowing to AI-augmented workers is real. The organizations that develop this capacity broadly — not just in a technical AI team — will compound that advantage.
- Agentic architecture is the medium-term value driver. The move from chatbots to coordinated agent systems is where the largest productivity and efficiency gains are being realized. Building capability and expertise in multi-agent system design now is building infrastructure for the next phase of AI value creation.
- Monitor inference pricing actively. The cost environment is changing fast enough that assumptions built into products or business cases from even 12 months ago may be significantly wrong. Revisit pricing assumptions quarterly.
The signal in AI right now is not in the loudest announcements or the most dramatic benchmark claims. It is in the production deployments that are quietly delivering measurable results, the infrastructure limitations that are constraining what gets built, the regulatory frameworks that are establishing the rules of the game, and the economic dynamics that are determining which approaches scale and which do not.
That is a less exciting story than the one that dominates the coverage. It is also a more accurate one — and in a field moving this fast, accuracy matters more than enthusiasm.

